ConCent: Contact-Centric Real-to-Sim-to-Real Learning from One Demonstration
Pith reviewed 2026-06-30 05:24 UTC · model grok-4.3
The pith
Reproducing task-relevant contact sequences from one real demonstration enables stable sim-to-real transfer in contact-rich manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Contact-centric fidelity—reproducing both the contact event sequence (when, where, and how contacts occur) and the local contact dynamics (how forces and motions evolve at each contact)—is a necessary condition for task success. The proposed framework extracts task-relevant contact event sequences from real demonstrations, approximates objects as groups of primitives, optimizes their contact geometry in simulation to explain observed state transitions, and uses the resulting sequence as a structured reward signal to guide policy learning toward physically plausible regimes.
What carries the argument
The contact event sequence extracted by replaying the demonstration, which serves as an automatic structured reward signal.
If this is right
- Policies avoid exploiting simulator contacts that have no real-world counterpart.
- Stable sim-to-real transfer occurs in contact-rich tasks without manual reward engineering.
- Learning is constrained to contact regimes already validated by the real demonstration.
- The approach operates from a single demonstration and produces more robust transfer than standard RL.
Where Pith is reading between the lines
- Focusing reward on contact matching may allow effective use of simulators whose global dynamics are only approximate.
- Increasing the number of primitives could extend the method to objects whose shapes deviate from simple groups.
- Contact-matched policies might tolerate moderate changes in object mass or friction as long as the sequence remains feasible.
Load-bearing premise
Objects can be approximated as groups of primitives whose contact geometry can be optimized in simulation to explain the observed state transitions from the demonstration.
What would settle it
A demonstration in which no set of primitive contact geometries reproduces the observed state transitions, or a policy that matches the contact sequence yet fails to succeed after real-world deployment.
Figures




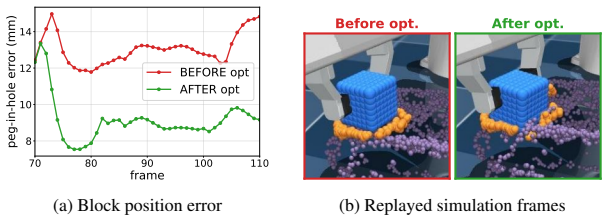
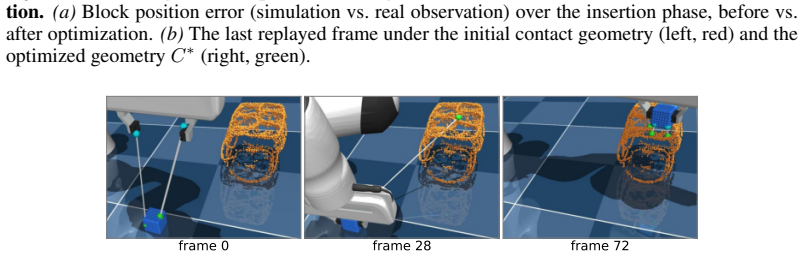
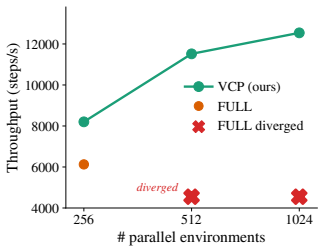

read the original abstract
Sim-to-real policy transfer -- deploying policies trained in simulation in the real world -- is a promising paradigm for scaling robot manipulation without large-scale real-world data. However, transferring simulation-trained policies remains challenging due to discrepancies in contact dynamics -- particularly in contact-rich tasks where subtle differences can alter task outcomes entirely. Because interaction between the manipulated object and the environment is mediated through contact, task success depends on accurately reproducing task-relevant contacts. Accordingly, in manipulation, contact-centric fidelity -- reproducing both the contact event sequence (when, where, and how contacts occur) and the local contact dynamics (how forces and motions evolve at each contact) -- is a necessary condition for task success. Based on this insight, we propose a contact-centric real-to-sim-to-real RL framework that uses task-relevant contact event sequences extracted from real demonstrations as the learning objective. We approximate objects as groups of primitives and optimize their contact geometry in simulation so that the resulting local contact dynamics explain the observed state transitions. The contact event sequence is automatically extracted by replaying the demonstration. This sequence serves as a structured reward signal, guiding the policy toward physically plausible contact regimes validated in reality and preventing exploitation of unrealistic simulator contacts. The signal is obtained automatically, requiring no per-task reward design. Experiments on contact-rich manipulation tasks demonstrate more stable and robust sim-to-real policy transfer compared to unconstrained RL baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ConCent, a contact-centric real-to-sim-to-real RL framework for robot manipulation. From a single real demonstration, it automatically extracts task-relevant contact event sequences, approximates objects as groups of primitives, optimizes their contact geometry in simulation to reproduce observed state transitions via local contact dynamics, and uses the resulting sequence as a structured reward signal. This guides policy learning toward physically plausible contact regimes and yields more stable sim-to-real transfer than unconstrained RL baselines on contact-rich tasks.
Significance. If the optimization step reliably produces unique, reality-validated contact rewards, the approach would offer a data-efficient alternative to manual reward design for sim-to-real transfer, directly targeting the contact discrepancies that dominate failure in manipulation. The automatic extraction of contact sequences from one demonstration and the focus on both event ordering and local dynamics are genuine strengths that could generalize across tasks. The significance is nevertheless conditional on whether the primitive-group fitting is sufficiently constrained to avoid simulator artifacts.
major comments (2)
- [Abstract] Abstract (and Method section on contact geometry optimization): the central claim that optimizing primitive contact geometry produces a reward signal enforcing 'physically plausible contact regimes validated in reality' is load-bearing, yet the description does not specify whether friction, stiffness, or restitution coefficients are held fixed during the optimization. If these remain free, multiple geometry-plus-parameter combinations can reproduce the same coarse state transitions, rendering the extracted reward non-unique and potentially rewarding simulator artifacts rather than true contact dynamics.
- [Abstract] Abstract (and Experiments): the assertion of 'more stable and robust sim-to-real policy transfer' compared to unconstrained RL baselines is presented without reported metrics, error bars, or ablations isolating the contribution of the contact-centric reward versus other implementation choices (e.g., primitive count, optimization objective). This makes it impossible to verify that improved transfer stems from contact fidelity rather than incidental factors.
minor comments (1)
- [Abstract] Abstract: the phrase 'the signal is obtained automatically, requiring no per-task reward design' is repeated; a single concise statement would suffice.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (and Method section on contact geometry optimization): the central claim that optimizing primitive contact geometry produces a reward signal enforcing 'physically plausible contact regimes validated in reality' is load-bearing, yet the description does not specify whether friction, stiffness, or restitution coefficients are held fixed during the optimization. If these remain free, multiple geometry-plus-parameter combinations can reproduce the same coarse state transitions, rendering the extracted reward non-unique and potentially rewarding simulator artifacts rather than true contact dynamics.
Authors: We agree this clarification is necessary. The optimization in ConCent is performed exclusively over primitive contact geometry (positions, orientations, and sizes), while friction, stiffness, and restitution coefficients are held fixed at simulator defaults. This constraint ensures the extracted contact sequence is tied to geometry that reproduces observed transitions under fixed material properties, avoiding non-uniqueness. We will revise the abstract and method section to state this explicitly. revision: yes
-
Referee: [Abstract] Abstract (and Experiments): the assertion of 'more stable and robust sim-to-real policy transfer' compared to unconstrained RL baselines is presented without reported metrics, error bars, or ablations isolating the contribution of the contact-centric reward versus other implementation choices (e.g., primitive count, optimization objective). This makes it impossible to verify that improved transfer stems from contact fidelity rather than incidental factors.
Authors: The experiments section reports quantitative success rates, transfer metrics, and baseline comparisons, including analysis varying primitive count. The abstract summarizes these without specific numbers or error bars. We will revise the abstract to include key quantitative results and error bars. Additional ablations isolating the reward signal will be added if space allows; the current primitive-count analysis already provides partial isolation of implementation choices. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain extracts contact event sequences directly from real demonstration data by replaying trajectories and optimizes primitive contact geometry to reproduce observed state transitions as an explicit fitting step to generate a reward signal for RL policy training. This is a data-driven procedure grounded in external real-world measurements rather than any self-definitional loop, fitted-input-renamed-as-prediction, or self-citation load-bearing premise. No equations or claims in the abstract or described method reduce the central result (improved transfer via contact-centric reward) to its own inputs by construction; the optimization serves as an intermediate mechanism whose output is then used for downstream policy learning, with validation against unconstrained RL baselines. The approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contact-centric fidelity is a necessary condition for task success in contact-rich manipulation because interaction is mediated through contact.
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. T. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. San- keti, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Jul...
2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. InConference on Robot Learning (CoRL), volume 270, pages 2679–2713, 2024
2024
-
[3]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control. InRobotics: Science and Systems (RSS), 2025
2025
-
[4]
W. Yu, J. Tan, C. K. Liu, and G. Turk. Preparing for the unknown: Learning a universal policy with online system identification. InRobotics: Science and Systems (RSS), 2017
2017
-
[5]
T. Lin, K. Sachdev, L. Fan, J. Malik, and Y . Zhu. Sim-to-real reinforcement learning for vision- based dexterous manipulation on humanoids. InConference on Robot Learning (CoRL), pages 4926–4940, 2025
2025
-
[6]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 23–30, 2017
2017
-
[7]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. InIEEE International Conference on Robotics and Automation (ICRA), pages 1–8, 2018
2018
-
[8]
Takamatsu, K
J. Takamatsu, K. Ogawara, H. Kimura, and K. Ikeuchi. Recognizing assembly tasks through human demonstration.Int. J. Robotics Res., 26(7):641–659, 2007
2007
-
[9]
Ikeuchi, N
K. Ikeuchi, N. Wake, J. Takamatsu, and K. Sasabuchi.Learning-from-Observation 2.0. 2025
2025
-
[10]
X. Li, M. Baum, and O. Brock. Augmentation enables one-shot generalization in learning from demonstration for contact-rich manipulation. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3656–3663, 2023
2023
-
[11]
Subramani, M
G. Subramani, M. R. Zinn, and M. Gleicher. Inferring geometric constraints in human demon- strations. InConference on Robot Learning (CoRL), volume 87, pages 223–236, 2018
2018
-
[12]
X. Zhu, J. Ke, Z. Xu, Z. Sun, B. Bai, J. Lv, Q. Liu, Y . Zeng, Q. Ye, C. Lu, M. Tomizuka, and L. Shao. Diff-lfd: Contact-aware model-based learning from visual demonstration for robotic manipulation via differentiable physics-based simulation and rendering. InConference on Robot Learning (CoRL), volume 229, pages 499–512, 2023
2023
- [13]
-
[14]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. InConference on Robot Learning (CoRL), volume 229, pages 1820–1864, 2023. 11
2023
-
[15]
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne. Deepmimic: example-guided deep reinforcement learning of physics-based character skills.ACM Trans. Graph., 37(4):143, 2018
2018
-
[16]
A. Y . Ng and S. Russell. Algorithms for inverse reinforcement learning. InInternational Conference on Machine Learning (ICML), pages 663–670, 2000
2000
-
[17]
Ho and S
J. Ho and S. Ermon. Generative adversarial imitation learning. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), pages 4565–4573, 2016
2016
-
[18]
Y . J. Ma, W. Liang, G. Wang, D. Huang, O. Bastani, D. Jayaraman, Y . Zhu, L. Fan, and A. Anandkumar. Eureka: Human-level reward design via coding large language models. In International Conference on Learning Representations (ICLR), 2024
2024
-
[19]
P. Dan, K. Kedia, A. Chao, E. W. Duan, M. A. Pace, W.-C. Ma, and S. Choudhury. X-sim: Cross-embodiment learning via real-to-sim-to-real. InConference on Robot Learning (CoRL), 2025
2025
-
[20]
T. G. W. Lum, O. Y . Lee, C. K. Liu, and J. Bohg. Crossing the human-robot embodiment gap with sim-to-real RL using one human demonstration. InConference on Robot Learning (CoRL), 2025
2025
-
[21]
Mildenhall, P
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: representing scenes as neural radiance fields for view synthesis.Commun. ACM, 65(1):99–106, 2022
2022
-
[22]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139:1–139:14, 2023
2023
- [23]
-
[24]
M. T. Villasevil, A. Simeonov, Z. Li, A. Chan, T. Chen, A. Gupta, and P. Agrawal. Recon- ciling reality through simulation: A real-to-sim-to-real approach for robust manipulation. In Robotics: Science and Systems (RSS), 2024
2024
-
[25]
X. Han, M. Liu, Y . Chen, J. Yu, X. Lyu, Y . Tian, B. Wang, W. Zhang, and J. Pang. Re 3sim: Generating high-fidelity simulation data via 3d-photorealistic real-to-sim for robotic manipu- lation. InIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[26]
T. Dai, J. Wong, Y . Jiang, C. Wang, C. Gokmen, R. Zhang, J. Wu, and L. Fei-Fei. Automated creation of digital cousins for robust policy learning. InConference on Robot Learning (CoRL), volume 270, pages 4912–4943, 2024
2024
-
[27]
B. Tang, M. A. Lin, I. Akinola, A. Handa, G. S. Sukhatme, F. Ramos, D. Fox, and Y . Narang. Industreal: Transferring contact-rich assembly tasks from simulation to reality. InRobotics: Science and Systems (RSS), 2023
2023
-
[28]
N. Ravi, V . Gabeur, Y . Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C. Wu, R. B. Girshick, P. Doll ´ar, and C. Feichtenhofer. SAM 2: Segment anything in images and videos. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[29]
Doersch, Y
C. Doersch, Y . Yang, M. Vecer´ık, D. Gokay, A. Gupta, Y . Aytar, J. Carreira, and A. Zisserman. TAPIR: tracking any point with per-frame initialization and temporal refinement. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 10027–10038, 2023
2023
-
[30]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5026– 5033, 2012. 12
2012
-
[31]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
C. D. Freeman, E. Frey, A. Raichuk, S. Girgin, I. Mordatch, and O. Bachem. Brax - A differen- tiable physics engine for large scale rigid body simulation. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
- [33]
-
[34]
Reuss, H
M. Reuss, H. Zhou, M. R ¨uhle, ¨O. E. Ya˘gmurlu, F. Otto, and R. Lioutikov. Flower: Democratiz- ing generalist robot policies with efficient vision-language-action flow policies. InConference on Robot Learning (CoRL), 2025
2025
-
[35]
Beyer and H
H. Beyer and H. Schwefel. Evolution strategies - A comprehensive introduction.Nat. Comput., 1(1):3–52, 2002
2002
-
[36]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5745–5753, 2019
2019
-
[37]
J. L. Sch ¨onberger and J. Frahm. Structure-from-motion revisited. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4104–4113, 2016
2016
-
[38]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention (MICCAI), volume 9351, pages 234–241, 2015
2015
-
[39]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[40]
B. T. Polyak and A. B. Juditsky. Acceleration of stochastic approximation by averaging.SIAM Journal on Control and Optimization, 30(4):838–855, 1992
1992
-
[41]
Perez, F
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. C. Courville. Film: Visual reasoning with a general conditioning layer. InAAAI Conference on Artificial Intelligence (AAAI), pages 3942–3951, 2018
2018
-
[42]
B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee. Enhanced deep residual networks for single image super-resolution. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1132–1140, 2017
2017
-
[43]
Ioffe and C
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InInternational Conference on Machine Learning (ICML), volume 37, pages 448–456, 2015
2015
-
[44]
W. Shi, J. Caballero, F. Huszar, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1874–1883, 2016. 13 Appendix A Contact Geometry Optimization: Implementation Det...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.