FlexTab: A Flexible Encoder-Decoder Architecture for In-Context Learning Across Diverse Tabular Tasks
Pith reviewed 2026-06-30 07:19 UTC · model grok-4.3
The pith
A single task-agnostic encoder paired with task-specific decoders serves as an effective general-purpose backbone for diverse tabular prediction problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
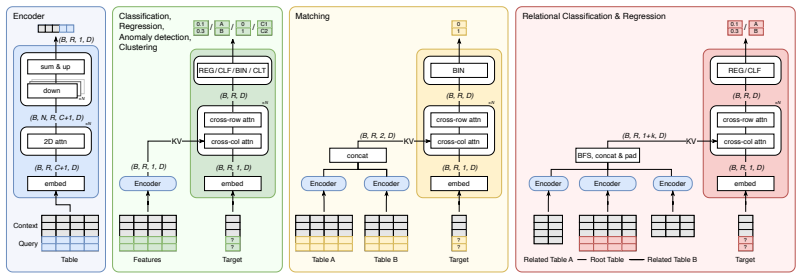
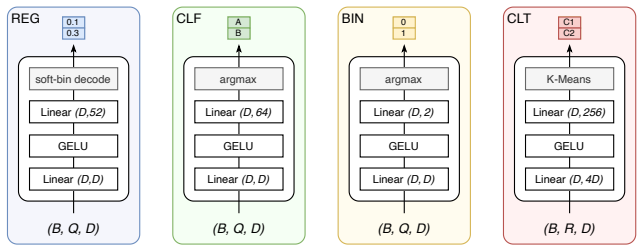
FlexTab shows that pairing a single task-agnostic encoder with task-specific decoders produces target-agnostic row embeddings that enable state-of-the-art performance on classification, regression, anomaly detection and entity matching while staying competitive on entity classification, proving the encoder-decoder design works as a general-purpose backbone for tabular tasks.
What carries the argument
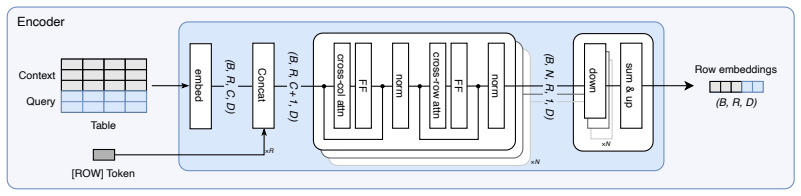
The shared task-agnostic encoder that generates target-agnostic row embeddings, combined with a suite of task-specific decoders.
If this is right
- The encoder can be reused across different tabular tasks without retraining from scratch.
- Pretraining occurs once on unlabeled tables to support multiple prediction problems.
- State-of-the-art results are achieved on four tasks and competitive performance on the remaining two.
- This design avoids the need for task-specific feature engineering in the encoder.
Where Pith is reading between the lines
- Such a flexible architecture might scale to additional tabular tasks beyond the six tested.
- It could lower the barrier for applying in-context learning in domains with limited labeled data per task.
- Future work might test if the embeddings transfer to new table structures not seen in pretraining.
Load-bearing premise
The target-agnostic row embeddings produced by the encoder remain sufficiently informative and transferable across the six listed tasks without requiring task-specific feature engineering or additional supervision during pretraining.
What would settle it
A direct comparison showing that task-specific encoders outperform the shared encoder on multiple tasks would falsify the claim that the shared design is effective as a general-purpose backbone.
Figures
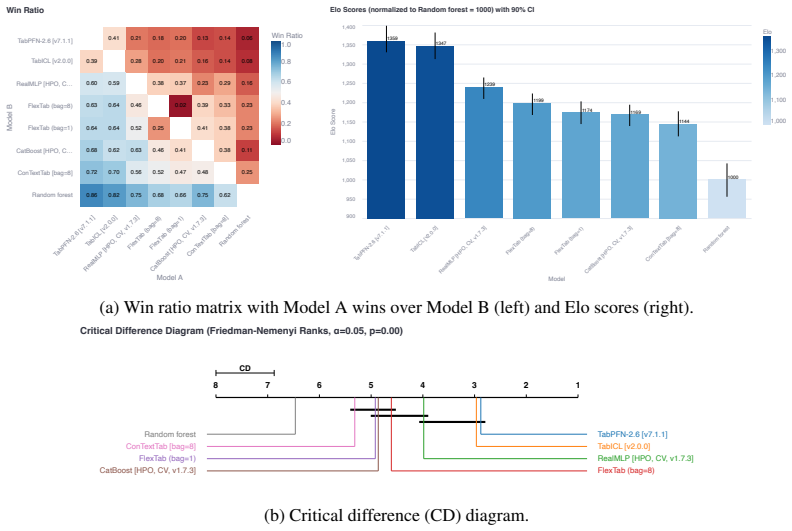
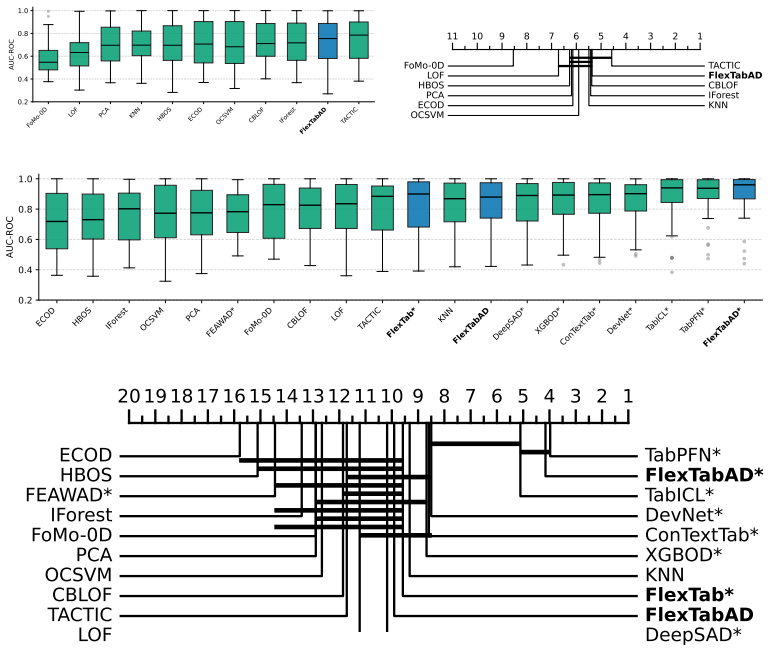
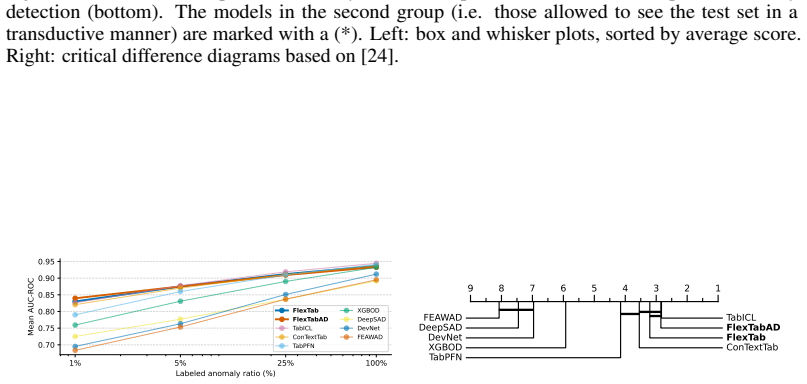

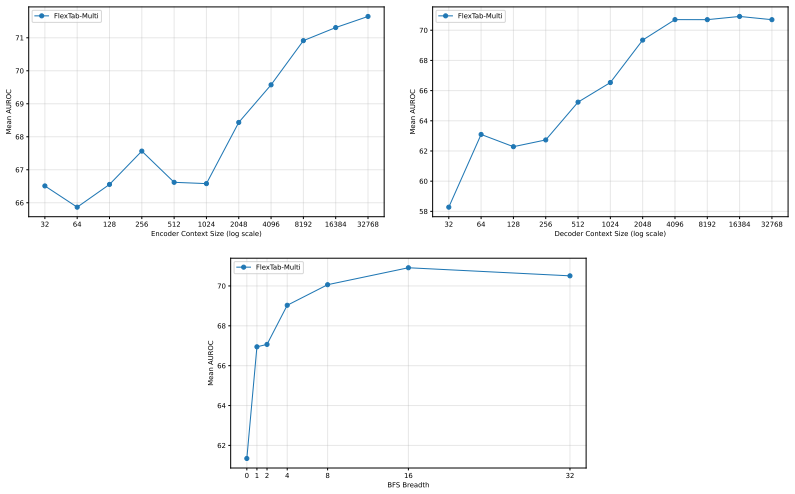
read the original abstract
We introduce FlexTab, a flexible encoder-decoder architecture for in-context learning on tabular data that pairs a single, task-agnostic encoder with a suite of task-specific decoders. Unlike existing tabular in-context learners, which entangle feature representations with a specific prediction target, our design produces \textit{target-agnostic} row embeddings that can be leveraged across a wide range of downstream tasks within a table-native in-context learning setup. We demonstrate this flexibility on six distinct problems: classification, regression, anomaly detection, clustering, entity matching, and entity classification in relational databases. Both the encoder and the task-specific decoders are trained on a large corpus of real-world, unlabeled tables. FlexTab achieves state-of-the-art performance on classification, regression, anomaly detection and entity matching, while remaining competitive with specialized models on entity classification in a relational setting. These results demonstrate that a single shared encoder, paired with task-specific decoders, can serve as an effective general-purpose backbone for diverse tabular prediction problems. The inference code and checkpoints will be made publicly available at https://github.com/SAP-samples/flextab.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlexTab, a flexible encoder-decoder architecture for in-context learning on tabular data. It pairs a single task-agnostic encoder, trained unsupervised on unlabeled tables to produce target-agnostic row embeddings, with a suite of task-specific decoders. The approach is evaluated on six tasks (classification, regression, anomaly detection, clustering, entity matching, and entity classification in relational databases) and claims state-of-the-art results on classification, regression, anomaly detection, and entity matching while remaining competitive on the relational entity classification task. The central claim is that this shared-encoder design serves as an effective general-purpose backbone for diverse tabular prediction problems. Inference code and checkpoints are promised to be released publicly.
Significance. If the empirical claims hold under detailed scrutiny, the work would be significant for tabular machine learning by demonstrating that target-agnostic embeddings from a shared encoder can transfer across heterogeneous tasks without task-specific pretraining or feature engineering. The explicit commitment to public release of code and checkpoints is a clear strength that supports reproducibility.
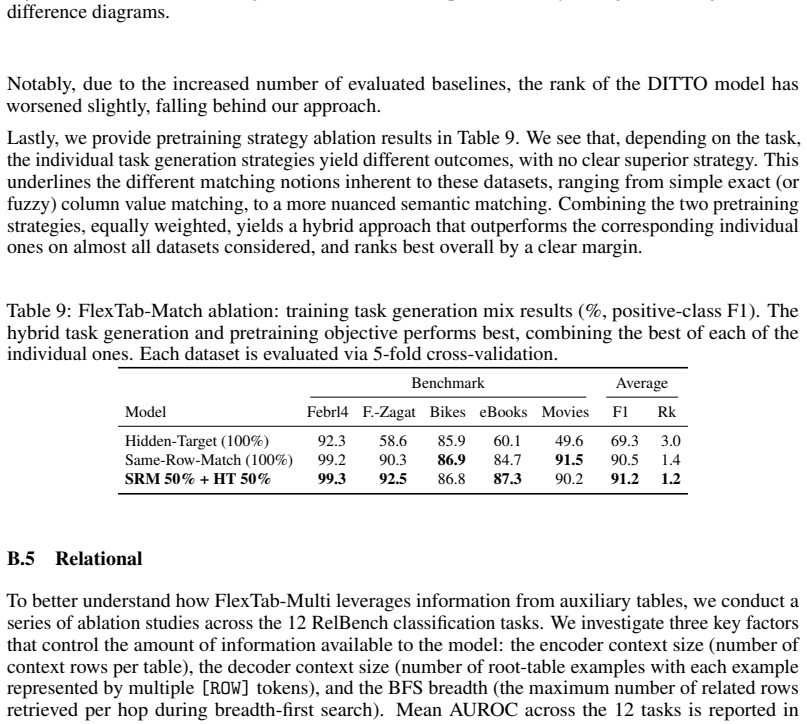
major comments (1)
- Abstract: the manuscript reports state-of-the-art and competitive results across six tasks but supplies no experimental details, baselines, metrics, dataset descriptions, ablation studies, or evaluation protocol. This absence prevents verification of the central claim that the shared encoder produces sufficiently informative and transferable embeddings across tasks.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify our work. We address the single major comment below.
read point-by-point responses
-
Referee: Abstract: the manuscript reports state-of-the-art and competitive results across six tasks but supplies no experimental details, baselines, metrics, dataset descriptions, ablation studies, or evaluation protocol. This absence prevents verification of the central claim that the shared encoder produces sufficiently informative and transferable embeddings across tasks.
Authors: Abstracts are intentionally concise high-level summaries and, per standard practice in machine learning venues, do not contain the full experimental details, baselines, metrics, dataset descriptions, ablation studies, or evaluation protocols. These elements are provided in the main body of the manuscript (Sections 3–5 and the appendix), including dataset statistics, baseline implementations, metrics (accuracy, RMSE, AUC, etc.), evaluation protocols (in-context learning setup, train/test splits), and ablation studies on encoder design and decoder variants. The central claim regarding transferable target-agnostic embeddings is supported by the reported results and ablations in those sections, which enable verification. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper introduces an empirical architecture (shared encoder + task-specific decoders) trained unsupervised on unlabeled tables and evaluated on downstream tasks. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on reported performance metrics rather than any self-referential reduction or ansatz smuggled via citation. This is a standard empirical contribution with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Michael Arbel, David Salinas, and Frank Hutter. 2025. EquiTabPFN: A target-permutation equivariant prior fitted network. InAdvances in Neural Information Processing Systems
2025
-
[2]
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. 2022. Data2vec: A general framework for self-supervised learning in speech, vision and language. InInternational Conference on Machine Learning, pages 1298–1312. PMLR
2022
-
[3]
Vahid Balazadeh, Hamidreza Kamkari, Valentin Thomas, Benson Li, Junwei Ma, Jesse C Cresswell, and Rahul G Krishnan. 2025. CausalPFN: Amortized causal effect estimation via in-context learning. In Advances in Neural Information Processing Systems
2025
-
[4]
Randall Balestriero and Yann LeCun. 2025. LeJEPA: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Gilles Blanchard, Gyemin Lee, and Clayton Scott. 2010. Semi-supervised novelty detection.Journal of Machine Learning Research, 11(99):2973–3009
2010
-
[6]
Markus M Breunig, Hans-Peter Kriegel, Raymond T Ng, and Jörg Sander. 2000. Lof: identifying density-based local outliers. InSIGMOD, pages 93–104
2000
-
[7]
Patricio Cerda, Gaël Varoquaux, and Balázs Kégl. 2018. Similarity encoding for learning with dirty categorical variables.Machine Learning, 107(8):1477–1494. Available at: https://skrub-data.org/
2018
-
[8]
Tianqi Chen and Carlos Guestrin. 2016. XGBoost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, pages 785–794
2016
-
[9]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot Arena: An open platform for evaluating llms by human preference.arXiv preprint arXiv:2403.04132
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Peter Christen. 2008. Febrl – an open source data cleaning, deduplication and record linkage system with a graphical user interface. InProceedings of the ACM SIGMOD International Conference on Knowledge Discovery and Data Mining
2008
-
[11]
Yann Collet. 2024. xxhash: Extremely fast non-cryptographic hash algorithm. https://github.com/ Cyan4973/xxHash. GitHub repository; accessed 2026-05-04
2024
-
[12]
C., Chaitanya Gokhale, Pradap Konda, Yash Govind, and Derek Paulsen
Sanjib Das, AnHai Doan, Paul Suganthan G. C., Chaitanya Gokhale, Pradap Konda, Yash Govind, and Derek Paulsen. The magellan data repository. https://sites.google.com/site/anhaidgroup/ projects/data
-
[13]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, pages 4171–4186
2019
- [14]
-
[15]
Dmitry Eremeev, Gleb Bazhenov, Oleg Platonov, Artem Babenko, and Liudmila Prokhorenkova. 2025. Turning tabular foundation models into graph foundation models. InNeurIPS Workshop on New Perspec- tives in Advancing Graph Machine Learning
2025
-
[16]
Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander Smola. 2020. AutoGluon-Tabular: Robust and accurate AutoML for structured data.arXiv preprint arXiv:2003.06505. 10
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[17]
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, Frank Hutter, et al. 2025. TabArena: A living benchmark for machine learning on tabular data. InAdvances in Neural Information Processing Systems
2025
-
[18]
Matthias Fey, Vid Kocijan, Federico Lopez, Jan Eric Lenssen, and Jure Leskovec. 2025. KumoRFM: A foundation model for in-context learning on relational data
2025
-
[19]
Joshua P Gardner, Juan Carlos Perdomo, and Ludwig Schmidt. 2024. Large scale transfer learning for tabular data via language modeling. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[20]
Marta Garnelo, Dan Rosenbaum, Christopher Maddison, Tiago Ramalho, David Saxton, Murray Shanahan, Danilo Rezende Yee Whye Teh, and SM Ali Eslami. 2018. Conditional neural processes. InInternational Conference on Machine Learning
2018
-
[21]
Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. 2025. TabM: Advancing tabular deep learning with parameter-efficient ensembling. InInternational Conference on Learning Representations
2025
-
[22]
Songqiao Han, Xiyang Hu, Hailiang Huang, Minqi Jiang, and Yue Zhao. 2022. ADBench: Anomaly detection benchmark. InThirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2022
-
[23]
Bronstein, and Ben Finkelshtein
Adrian Hayler, Xingyue Huang, Ismail Ilkan Ceylan, Michael M. Bronstein, and Ben Finkelshtein. 2025. Of graphs and tables: Zero-shot node classification with tabular foundation models. InNeurIPS Workshop on New Perspectives in Advancing Graph Machine Learning
2025
-
[24]
Steffen Herbold. 2020. Autorank: A Python package for automated ranking of classifiers.Journal of Open Source Software, 5(48):2173
2020
-
[25]
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. 2023. TabPFN: A transformer that solves small tabular classification problems in a second. InThe Eleventh International Conference on Learning Representations
2023
-
[26]
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. 2025. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326
2025
-
[27]
David Holzmüller, Léo Grinsztajn, and Ingo Steinwart. 2024. Better by default: Strong pre-tuned MLPs and boosted trees on tabular data.Advances in Neural Information Processing Systems, 37:26577–26658
2024
-
[28]
Shi Bin Hoo, Samuel Müller, David Salinas, and Frank Hutter. 2024. The tabular foundation model TabPFN outperforms specialized time series forecasting models based on simple features. InNeurIPS Workshop on Time Series in the Age of Large Models
2024
-
[29]
Valter Hudovernik, Federico López, Vid Kocijan, Akihiro Nitta, Jan Eric Lenssen, Jure Leskovec, and Matthias Fey. 2026. KumoRFM-2: Scaling foundation models for relational learning
2026
-
[30]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu
-
[31]
InAdvances in Neural Information Processing Systems
LightGBM: A highly efficient gradient boosting decision tree. InAdvances in Neural Information Processing Systems
-
[32]
Myung Jun Kim, Leo Grinsztajn, and Gael Varoquaux. 2024. CARTE: Pretraining and transfer for tabular learning. InForty-first International Conference on Machine Learning
2024
-
[33]
Pradap Konda, Sanjib Das, Paul Suganthan G C, AnHai Doan, Adel Ardalan, Jeffrey R Ballard, Han Li, Fatemah Panahi, Haojun Zhang, Jeff Naughton, et al. 2016. Magellan: Toward building entity matching management systems over data science stacks.Proceedings of the VLDB Endowment, 9(13):1581–1584
2016
-
[34]
Yuliang Li, Jinfeng Li, Yoshihiko Suhara, AnHai Doan, and Wang-Chiew Tan. 2020. Deep entity matching with pre-trained language models.Proceedings of the VLDB Endowment, 14(1):50–60
2020
-
[35]
Zheng Li, Yue Zhao, Xiyang Hu, Nicola Botta, Cezar Ionescu, and George Chen. 2022. Ecod: Unsupervised outlier detection using empirical cumulative distribution functions.TKDE, pages 1–1
2022
-
[36]
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. 2008. Isolation forest. InICDM, pages 413–422. IEEE
2008
-
[37]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A robustly optimized BERT pretraining approach.CoRR, abs/1907.11692. 11
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[38]
Junwei Ma, Nour Shaheen, Alex Labach, Amine Mhedhbi, Frank Hutter, Anthony L Caterini, and Valentin Thomas. 2025. Generalization can emerge in tabular foundation models from a single table. InEurIPS Workshop on AI for Tabular Data
2025
-
[39]
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Hamidreza Kamkari, Alex Labach, Jesse C Cresswell, Keyvan Golestan, Guangwei Yu, Maksims V olkovs, and Anthony L Caterini. 2025. TabDPT: Scaling tabular foundation models.Advances in Neural Information Processing Systems
2025
- [40]
-
[41]
Patryk Marszałek, Tomasz Ku´smierczyk, Witold Wydma´nski, Jacek Tabor, and Marek ´Smieja. 2025. Zeus: Zero-shot embeddings for unsupervised separation of tabular data. InAdvances in Neural Information Processing Systems
2025
- [42]
-
[43]
Martin Mráz, Breenda Das, Anshul Gupta, Lennart Purucker, and Frank Hutter. 2025. Towards bench- marking foundation models for tabular data with text. InICML 2025 Workshop on Foundation Models for Structured Data (FMSD)
2025
-
[44]
Sidharth Mudgal, Han Li, Theodoros Rekatsinas, AnHai Doan, Youngchoon Park, Ganesh Krishnan, Rohit Deep, Esteban Arcaute, and Vijay Raghavendra. 2018. Deep learning for entity matching: A design space exploration. InProceedings of the ACM SIGMOD International Conference on Management of Data, pages 19–34
2018
-
[45]
Samuel Müller, Noah Hollmann, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. 2022. Transformers can do Bayesian inference. InInternational Conference on Learning Representations
2022
-
[46]
Guansong Pang, Chunhua Shen, and Anton van den Hengel. 2019. Deep anomaly detection with deviation networks. InKDD, pages 353–362
2019
-
[47]
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. 2011. Scikit-learn: Machine learning in python.the Journal of Machine Learning Research, 12:2825–2830
2011
-
[48]
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin
-
[49]
CatBoost: Unbiased boosting with categorical features.Advances in Neural Information Processing Systems, 31
-
[50]
Francesco Pugnaloni, Luca Zecchini, Matteo Paganelli, Matteo Lissandrini, Felix Naumann, and Giovanni Simonini. 2025. Table overlap estimation through graph embeddings.Proceedings of the ACM on Management of Data, 3(3):1–25
2025
-
[51]
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. 2025. TabICL: A tabular foundation model for in-context learning on large data. InInternational Conference on Machine Learning
2025
- [52]
-
[53]
Sridhar Ramaswamy, Rajeev Rastogi, and Kyuseok Shim. 2000. Efficient algorithms for mining outliers from large data sets. InSIGMOD, pages 427–438
2000
-
[54]
Kanatsoulis, Roshan Reddy Upendra, Mahmoud Mohammadi, Joe Meyer, Tom Palczewski, Carlos Guestrin, and Jure Leskovec
Rishabh Ranjan, Valter Hudovernik, Mark Znidar, Charilaos I. Kanatsoulis, Roshan Reddy Upendra, Mahmoud Mohammadi, Joe Meyer, Tom Palczewski, Carlos Guestrin, and Jure Leskovec. 2026. Relational transformer: Toward zero-shot foundation models for relational data. InThe Fourteenth International Conference on Learning Representations
2026
-
[55]
Jake Robertson, Arik Reuter, Siyuan Guo, Noah Hollmann, Frank Hutter, and Bernhard Schölkopf. 2025. Do-PFN: In-context learning for causal effect estimation. InAdvances in Neural Information Processing Systems
2025
-
[56]
Robinson, R
J. Robinson, R. Ranjan, W. Hu, K. Huang, J. Han, A. Dobles, M. Fey, J. E. Lenssen, Y . Yuan, Z. Zhang, X. He, and J. Leskovec. 2024. RelBench: A benchmark for deep learning on relational databases. In NeurIPS. 12
2024
-
[57]
Vandermeulen, Nico Görnitz, Alexander Binder, Emmanuel Müller, Klaus-Robert Müller, and Marius Kloft
Lukas Ruff, Robert A. Vandermeulen, Nico Görnitz, Alexander Binder, Emmanuel Müller, Klaus-Robert Müller, and Marius Kloft. 2020. Deep semi-supervised anomaly detection. InICLR. OpenReview.net
2020
- [58]
-
[59]
Bernhard Schölkopf, Robert C Williamson, Alexander J Smola, John Shawe-Taylor, John C Platt, et al
-
[60]
InNIPS, volume 12, pages 582–588
Support vector method for novelty detection. InNIPS, volume 12, pages 582–588. Citeseer
-
[61]
Yuchen Shen, Haomin Wen, and Leman Akoglu. 2025. Fomo-0d: A foundation model for zero-shot tabular outlier detection.Transactions on Machine Learning Research
2025
-
[62]
Mei-Ling Shyu, Shu-Ching Chen, Kanoksri Sarinnapakorn, and LiWu Chang. 2003. A novel anomaly detection scheme based on principal component classifier. Technical report, Miami Univ Coral Gables Fl Dept of Electrical and Computer Engineering
2003
-
[63]
Marco Spinaci, Marek Polewczyk, Maximilian Schambach, and Sam Thelin. 2025. ConTextTab: A semantics-aware tabular in-context learner. InAdvances in Neural Information Processing Systems
2025
-
[64]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in Neural Information Processing Systems, 30
2017
-
[65]
Yanbo Wang, Xiyuan Wang, Quan Gan, Minjie Wang, Qibin Yang, David Wipf, and Muhan Zhang. 2025. Griffin: Towards a graph-centric relational database foundation model. InForty-second International Conference on Machine Learning
2025
- [66]
-
[67]
Linjie Xu, Yanlin Zhang, Quan Gan, Minjie Wang, and David Wipf. 2026. No need to train your RDB foundation model.arXiv preprint arXiv:2602.13697
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [68]
-
[69]
Xiyuan Zhang, Danielle C Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W Mahoney, et al. 2025. Mitra: Mixed synthetic priors for enhancing tabular foundation models. InAdvances in Neural Information Processing Systems
2025
-
[70]
Tianqi Zhao, Guanyang Wang, Yan Shuo Tan, and Qiong Zhang. 2026. TabClustPFN: A prior-fitted network for tabular data clustering.arXiv preprint arXiv:2601.21656
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[71]
Yue Zhao and Maciej K Hryniewicki. 2018. Xgbod: improving supervised outlier detection with unsuper- vised representation learning. InIJCNN, pages 1–8. IEEE
2018
-
[72]
same hidden class
Yingjie Zhou, Xucheng Song, Yanru Zhang, Fanxing Liu, Ce Zhu, and Lingqiao Liu. 2021. Feature encoding with autoencoders for weakly supervised anomaly detection.TNNLS. 13 Encoder Context Query Table ×N embed (B, R, D) ×N (B, R, D) Row embeddings (B, R, C + 1, D) down sum & up (B, N, R, 1, D) cross-row attn FF norm cross-col attn FF norm (B, R, C, D) Conca...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.