OLIVE: View-Augmented Latent Prediction with Waveform Reconstruction for Speech SSL
Pith reviewed 2026-06-30 06:15 UTC · model grok-4.3
The pith
OLIVE jointly optimizes view-augmented masked latent prediction with waveform reconstruction to produce speech representations that support both generation and recognition tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
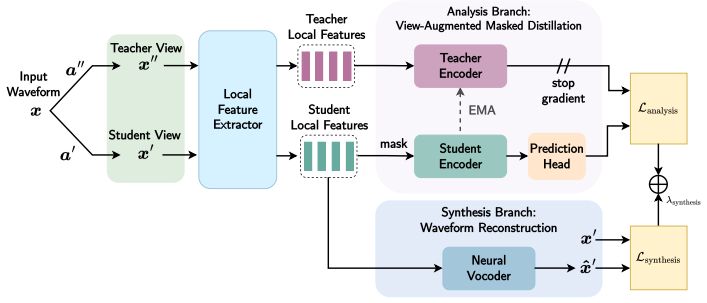
OLIVE combines view-augmented masked latent prediction with waveform reconstruction under a unified objective. Reconstruction constrains early encoder features to retain signal-level information, while masked latent prediction shapes later contextual representations toward invariance. This enables representations that support a broad range of tasks, improving results on generation and speaker tasks, maintaining competitive performance on recognition and semantic tasks, and improving waveform reconstruction.
What carries the argument
The unified objective of view-augmented masked latent prediction and waveform reconstruction, which assigns reconstruction the role of preserving signal details in early features and prediction the role of creating invariance in later features.
If this is right
- Generation tasks show improved results
- Speaker tasks show improved results
- Recognition and semantic tasks remain competitive
- Waveform reconstruction quality itself improves
Where Pith is reading between the lines
- The same joint-objective pattern might allow a single pretrained model to serve both analysis and synthesis speech applications without separate fine-tuning paths.
- Similar dual-objective designs could be tested in other audio domains such as music or environmental sound processing.
- The separation of early and late layer roles might generalize to other self-supervised frameworks that currently optimize only one type of objective.
Load-bearing premise
The reconstruction objective will constrain early encoder features to retain signal-level information while the masked prediction objective shapes later contextual representations toward invariance, without the two objectives interfering or requiring extensive hyperparameter tuning to balance.
What would settle it
An ablation experiment in which removing the waveform reconstruction term either improves recognition performance or fails to improve generation and speaker performance would falsify the claim that the joint objective produces non-interfering complementary features.
Figures
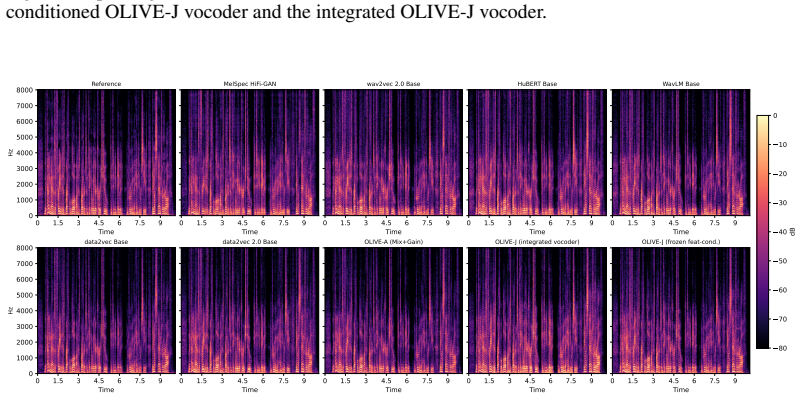
read the original abstract
We propose Online Latent prediction with Invariant Views and rEconstruction (OLIVE), a self-supervised speech representation learning framework that jointly optimizes analysis and synthesis objectives. OLIVE combines view-augmented masked latent prediction with waveform reconstruction under a unified objective. Reconstruction constrains early encoder features to retain signal-level information, while masked latent prediction shapes later contextual representations toward invariance for robust downstream performance. We show that these objectives enable representations that support a broad range of tasks. In particular, OLIVE improves results on generation and speaker tasks, maintains competitive performance on recognition and semantic tasks, and improves waveform reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OLIVE, a self-supervised speech representation learning framework that jointly optimizes view-augmented masked latent prediction and waveform reconstruction under a unified objective. Reconstruction is intended to constrain early encoder features to retain signal-level information, while masked latent prediction shapes later contextual representations toward invariance. The authors claim that this enables representations supporting a broad range of tasks, specifically improving results on generation and speaker tasks, maintaining competitive performance on recognition and semantic tasks, and improving waveform reconstruction.
Significance. If the empirical claims hold, the framework provides a principled way to balance local signal fidelity with contextual invariance in speech SSL without requiring separate models or extensive balancing of objectives. This could yield more versatile representations applicable across generation, speaker, recognition, and semantic tasks.
minor comments (1)
- [Abstract] Abstract: the abstract asserts specific performance improvements and mechanistic separation of roles between the two objectives but supplies no quantitative results, baselines, ablation studies, error bars, or layer-wise diagnostics to support these claims.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the assessment of its potential significance, and the recommendation for minor revision. We are glad that the unified objective and its intended effects on early and later layers are viewed as a principled contribution.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, parameter fits, self-citations, or derivation steps that reduce a claimed prediction or result to its own inputs by construction. The framework is described as jointly optimizing two objectives with intended separation of roles for early vs. later layers, but this is presented as a design choice without any mathematical reduction, uniqueness theorem, or fitted-input-as-prediction pattern. No load-bearing self-referential elements appear, so the derivation chain (such as it is) remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Joint optimization of reconstruction and masked prediction will produce representations that simultaneously retain signal detail and achieve invariance without destructive interference.
Reference graph
Works this paper leans on
-
[1]
Havtorn, Joakim Edin, Christian Igel, Katrin Kirchhoff, Shang-Wen Li, Karen Livescu, Lars Maaløe, et al
Abdelrahman Mohamed, Hung-yi Lee, Lasse Borgholt, Jakob D. Havtorn, Joakim Edin, Christian Igel, Katrin Kirchhoff, Shang-Wen Li, Karen Livescu, Lars Maaløe, et al. Self-supervised speech representation learning: A review.IEEE Journal of Selected Topics in Signal Processing, 16(6):1179–1210, 2022
2022
-
[2]
Schuller
Shuo Liu, Adria Mallol-Ragolta, Emilia Parada-Cabaleiro, Kun Qian, Xin Jing, Alexander Kathan, Bin Hu, and Bjoern W. Schuller. Audio self-supervised learning: A survey.Patterns, 3(12), 2022
2022
-
[3]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. InNeurIPS, 2020
2020
-
[4]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021
2021
-
[5]
WavLM: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. WavLM: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
2022
-
[6]
data2vec: A general framework for self-supervised learning in speech, vision and language
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. data2vec: A general framework for self-supervised learning in speech, vision and language. InICML, 2022
2022
-
[7]
Efficient self-supervised learning with contextualized target representations for vision, speech and language
Alexei Baevski, Arun Babu, Wei-Ning Hsu, and Michael Auli. Efficient self-supervised learning with contextualized target representations for vision, speech and language. InICML, 2023
2023
-
[8]
Lin, Andy T
Shu-wen Yang, Po-Han Chi, Yung-Sung Chuang, Cheng-I Jeff Lai, Kushal Lakhotia, Yist Y . Lin, Andy T. Liu, Jiatong Shi, Xuankai Chang, Guan-Ting Lin, Tzu-Hsien Huang, Wei-Cheng Tseng, Ko-tik Lee, Da-Rong Liu, Zili Huang, Shuyan Dong, Shang-Wen Li, Shinji Watanabe, Abdelrahman Mohamed, and Hung-yi Lee. SUPERB: Speech processing universal performance benchma...
2021
-
[9]
Specializing self-supervised speech representations for speaker segmentation
Séverin Baroudi, Thomas Pellegrini, and Hervé Bredin. Specializing self-supervised speech representations for speaker segmentation. InInterspeech, 2024
2024
-
[10]
Yingzhi Wang, Abdelmoumene Boumadane, and Abdelwahab Heba. A fine-tuned wav2vec 2.0/HuBERT benchmark for speech emotion recognition, speaker verification and spoken language understanding.arXiv preprint arXiv:2111.02735, 2021
-
[11]
Evaluating self-supervised speech representations for speech emotion recognition.IEEE Access, 10:124396–124407, 2022
Bagus Tris Atmaja and Akira Sasou. Evaluating self-supervised speech representations for speech emotion recognition.IEEE Access, 10:124396–124407, 2022
2022
-
[12]
Emotion information recovery potential of a wav2vec 2.0 network fine-tuned for speech recognition
Tilak Purohit and Mathew Magimai-Doss. Emotion information recovery potential of a wav2vec 2.0 network fine-tuned for speech recognition. InICASSP, 2025
2025
-
[13]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
wav2vec: Unsupervised pre- training for speech recognition
Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. wav2vec: Unsupervised pre- training for speech recognition. InInterspeech, 2019
2019
-
[15]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InNAACL, 2019
2019
-
[16]
Shaoshi Ling and Yuzong Liu. DeCoAR 2.0: Deep contextualized acoustic representations with vector quantization.arXiv preprint arXiv:2012.06659, 2020
-
[17]
Liu, Shu-wen Yang, Po-Han Chi, Po-chun Hsu, and Hung-yi Lee
Andy T. Liu, Shu-wen Yang, Po-Han Chi, Po-chun Hsu, and Hung-yi Lee. Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders. InICASSP, 2020
2020
-
[18]
Generative pre-training for speech with autoregressive predictive coding
Yu-An Chung and James Glass. Generative pre-training for speech with autoregressive predictive coding. InICASSP, 2020. 10
2020
-
[19]
Liu, Yu-An Chung, and James Glass
Alexander H. Liu, Yu-An Chung, and James Glass. Non-autoregressive predictive coding for learning speech representations from local dependencies. InInterspeech, 2021
2021
-
[20]
Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, et al
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning. InNeurIPS, 2020
2020
-
[21]
BYOL for audio: Self-supervised learning for general-purpose audio representation
Daisuke Niizumi, Daiki Takeuchi, Yasunori Ohishi, Noboru Harada, and Kunio Kashino. BYOL for audio: Self-supervised learning for general-purpose audio representation. InIJCNN, 2021
2021
-
[22]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InICCV, 2021
2021
-
[23]
Atal and Suzanne L
Bishnu S. Atal and Suzanne L. Hanauer. Speech analysis and synthesis by linear prediction of the speech wave.Journal of the Acoustical Society of America, 50(2B):637–655, 1971
1971
-
[24]
McAulay and Thomas F
Robert J. McAulay and Thomas F. Quatieri. Speech analysis/synthesis based on a sinusoidal representation. IEEE Transactions on Acoustics, Speech, and Signal Processing, 34(4):744–754, 1986
1986
-
[25]
Speech analysis/synthesis based on matching the synthesized and the original representations in the auditory nerve level
Oded Ghitza. Speech analysis/synthesis based on matching the synthesized and the original representations in the auditory nerve level. InICASSP, 1986
1986
-
[26]
Mouton, The Hague, 1960
Gunnar Fant.Acoustic Theory of Speech Production. Mouton, The Hague, 1960
1960
-
[27]
Titze.Principles of V oice Production
Ingo R. Titze.Principles of V oice Production. Prentice Hall, Englewood Cliffs, NJ, 1994
1994
-
[28]
Mechanics of human voice production and control.The Journal of the Acoustical Society of America, 140(4):2614–2635, 2016
Zhaoyan Zhang. Mechanics of human voice production and control.The Journal of the Acoustical Society of America, 140(4):2614–2635, 2016
2016
-
[29]
Neural analysis and synthesis: Reconstructing speech from self-supervised representations
Hyeong-Seok Choi, Juheon Lee, Wansoo Kim, Jie Hwan Lee, Hoon Heo, and Kyogu Lee. Neural analysis and synthesis: Reconstructing speech from self-supervised representations. InNeurIPS, 2021
2021
-
[30]
Speech resynthesis from discrete disentangled self-supervised representations
Adam Polyak, Yossi Adi, Jade Copet, Eugene Kharitonov, Kushal Lakhotia, Wei-Ning Hsu, Abdelrah- man Mohamed, and Emmanuel Dupoux. Speech resynthesis from discrete disentangled self-supervised representations. InInterspeech, 2021
2021
-
[31]
WavThruVec: Latent speech representation as intermediate features for neural speech synthesis
Hubert Siuzdak, Piotr Dura, Pol van Rijn, and Nori Jacoby. WavThruVec: Latent speech representation as intermediate features for neural speech synthesis. InInterspeech, 2022
2022
-
[32]
Yiwei Guo, Zhihan Li, Junjie Li, Chenpeng Du, Hankun Wang, Shuai Wang, Xie Chen, and Kai Yu. vec2wav 2.0: Advancing voice conversion via discrete token vocoders.arXiv preprint arXiv:2409.01995, 2024
-
[33]
V oice conversion with just nearest neighbors
Matthew Baas, Benjamin van Niekerk, and Herman Kamper. V oice conversion with just nearest neighbors. InInterspeech, 2023
2023
-
[34]
kNN retrieval for simple and effective zero-shot multi-speaker text-to-speech
Karl El Hajal, Ajinkya Kulkarni, Enno Hermann, and Mathew Magimai-Doss. kNN retrieval for simple and effective zero-shot multi-speaker text-to-speech. InNAACL, 2025
2025
-
[35]
Self-supervised learning for speech enhancement through synthesis
Bryce Irvin, Marko Stamenovic, Mikolaj Kegler, and Li-Chia Yang. Self-supervised learning for speech enhancement through synthesis. InICASSP, 2023
2023
-
[36]
data2vec-SG: Improving self-supervised learning representations for speech generation tasks
Heming Wang, Yao Qian, Hemin Yang, Nauyuki Kanda, Peidong Wang, Takuya Yoshioka, Xiaofei Wang, Yiming Wang, Shujie Liu, Zhuo Chen, et al. data2vec-SG: Improving self-supervised learning representations for speech generation tasks. InICASSP, 2023
2023
-
[37]
Liu, Sang-gil Lee, Chao-Han Huck Yang, Yuan Gong, Yu-Chiang Frank Wang, James R
Alexander H. Liu, Sang-gil Lee, Chao-Han Huck Yang, Yuan Gong, Yu-Chiang Frank Wang, James R. Glass, Rafael Valle, and Bryan Catanzaro. UniWav: Towards unified pre-training for speech representation learning and generation. InICLR, 2025
2025
-
[38]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. In NIPS, 2017
2017
-
[39]
vq-wav2vec: Self-supervised learning of discrete speech representations
Alexei Baevski, Steffen Schneider, and Michael Auli. vq-wav2vec: Self-supervised learning of discrete speech representations. InICLR, 2020
2020
-
[40]
An unsupervised autoregressive model for speech representation learning
Yu-An Chung, Wei-Ning Hsu, Hao Tang, and James Glass. An unsupervised autoregressive model for speech representation learning. InInterspeech, 2019. 11
2019
-
[41]
Discovering predictable classifications.Neural Computation, 5 (4):625–635, 1993
Jürgen Schmidhuber and Daniel Prelinger. Discovering predictable classifications.Neural Computation, 5 (4):625–635, 1993
1993
-
[42]
BYOL-S: Learning self-supervised speech representations by bootstrapping
Gasser Elbanna, Neil Scheidwasser-Clow, Mikolaj Kegler, Pierre Beckmann, Karl El Hajal, and Milos Cernak. BYOL-S: Learning self-supervised speech representations by bootstrapping. InHEAR: Holistic Evaluation of Audio Representations, volume 166 ofProceedings of Machine Learning Research, 2022
2022
-
[43]
WaveBYOL: Self-supervised learning for audio representation from raw waveforms.IEEE Access, 11:8968–8977, 2023
Sunghyun Kim and Yong-Hoon Choi. WaveBYOL: Self-supervised learning for audio representation from raw waveforms.IEEE Access, 11:8968–8977, 2023
2023
-
[44]
Goksenin Yuksel, Pierre Guetschel, Michael Tangermann, Marcel van Gerven, and Kiki van der Heijden. WavJEPA: Semantic learning unlocks robust audio foundation models for raw waveforms.arXiv preprint arXiv:2509.23238, 2025
-
[45]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InCVPR, 2023
2023
-
[46]
WaveNet: A Generative Model for Raw Audio
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W. Senior, and Koray Kavukcuoglu. WaveNet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
WaveGlow: A flow-based generative network for speech synthesis
Ryan Prenger, Rafael Valle, and Bryan Catanzaro. WaveGlow: A flow-based generative network for speech synthesis. InICASSP, 2019
2019
-
[48]
Courville
Kundan Kumar, Rithesh Kumar, Thibault de Boissiere, Lucas Gestin, Wei Zhen Teoh, Jose Sotelo, Alexandre de Brébisson, Yoshua Bengio, and Aaron C. Courville. MelGAN: Generative adversarial networks for conditional waveform synthesis. InNeurIPS, 2019
2019
-
[49]
Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram
Ryuichi Yamamoto, Eunwoo Song, and Jae-Min Kim. Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. InICASSP, 2020
2020
-
[50]
HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. InNeurIPS, 2020
2020
-
[51]
SoundStream: An end-to-end neural audio codec.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2021
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. SoundStream: An end-to-end neural audio codec.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2021
2021
-
[52]
High fidelity neural audio compression
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression. Transactions on Machine Learning Research, 2023
2023
-
[53]
Liu, Qirui Wang, Yuan Gong, and James R
Alexander H. Liu, Qirui Wang, Yuan Gong, and James R. Glass. A closer look at neural codec resynthesis: Bridging the gap between codec and waveform generation. InAudio Imagination: NeurIPS 2024 Workshop on AI-Driven Speech, Music, and Sound Generation, 2024
2024
-
[54]
NanoCodec: Towards high-quality ultra fast speech LLM inference
Edresson Casanova, Paarth Neekhara, Ryan Langman, Shehzeen Hussain, Subhankar Ghosh, Xuesong Yang, Ante Jukic, Jason Li, and Boris Ginsburg. NanoCodec: Towards high-quality ultra fast speech LLM inference. InInterspeech, 2025
2025
-
[55]
JEPA as a neural tokenizer: Learning robust speech representations with density adaptive attention
Georgios Ioannides, Christos Constantinou, Aman Chadha, Aaron Elkins, Linsey Pang, Ravid Shwartz-Ziv, and Yann LeCun. JEPA as a neural tokenizer: Learning robust speech representations with density adaptive attention. InNeurIPS 2025 Workshop UniReps: Unifying Representations in Neural Models, 2025
2025
-
[56]
Metis: A foundation speech generation model with masked generative pre-training
Yuancheng Wang, Jiachen Zheng, Junan Zhang, Xueyao Zhang, Huan Liao, and Zhizheng Wu. Metis: A foundation speech generation model with masked generative pre-training. InNeurIPS, 2025
2025
-
[57]
LibriSpeech: An ASR corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. LibriSpeech: An ASR corpus based on public domain audio books. InICASSP, 2015
2015
-
[58]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNIPS, 2017
2017
-
[59]
Dauphin, and David Lopez-Paz
Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. InICLR, 2018
2018
-
[60]
SUPERB-SG: Enhanced speech processing universal performance benchmark for semantic and generative capabilities
Hsiang-Sheng Tsai, Heng-Jui Chang, Wen-Chin Huang, Zili Huang, Kushal Lakhotia, Shu-wen Yang, Shuyan Dong, Andy Liu, Cheng-I Lai, Jiatong Shi, et al. SUPERB-SG: Enhanced speech processing universal performance benchmark for semantic and generative capabilities. InACL, 2022. 12
2022
-
[61]
SUPERB@SLT 2022: Challenge on generalization and efficiency of self-supervised speech representation learning
Tzu-hsun Feng, Annie Dong, Ching-Feng Yeh, Shu-wen Yang, Tzu-Quan Lin, Jiatong Shi, Kai-Wei Chang, Zili Huang, Haibin Wu, Xuankai Chang, et al. SUPERB@SLT 2022: Challenge on generalization and efficiency of self-supervised speech representation learning. InIEEE SLT, 2023
2022
-
[62]
Taal, Richard C
Cees H. Taal, Richard C. Hendriks, Richard Heusdens, and Jesper Jensen. An algorithm for intelligibility prediction of time–frequency weighted noisy speech.IEEE Transactions on Audio, Speech, and Language Processing, 19(7):2125–2136, 2011
2011
-
[63]
Rix, John G
Antony W. Rix, John G. Beerends, Michael P. Hollier, and Andries P. Hekstra. Perceptual evaluation of speech quality (PESQ): A new method for speech quality assessment of telephone networks and codecs. In ICASSP, 2001
2001
-
[64]
arXiv preprint arXiv:2204.02152 , year=
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. UTMOS: UTokyo-SaruLab system for V oiceMOS challenge 2022.arXiv preprint arXiv:2204.02152, 2022
-
[65]
Andrew Hines, Jan Skoglund, Anil C. Kokaram, and Naomi Harte. ViSQOL: An objective speech quality model.EURASIP Journal on Audio, Speech, and Music Processing, 2015(1):13, 2015. 13 A Model and Pre-training Details Table 5 consolidates the main optimization, encoder, and synthesis-branch configurations used for OLIVE pre-training. Table 5: OLIVE model arch...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.