On the Vulnerability of Parameter-Level Defenses to Model Merging
Pith reviewed 2026-06-30 07:11 UTC · model grok-4.3
The pith
Linear parameter transformations meant to block unauthorized model merging can be analytically reversed using the original pretrained model as an anchor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
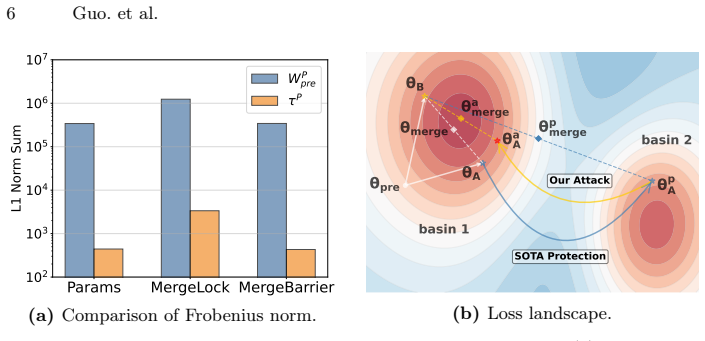
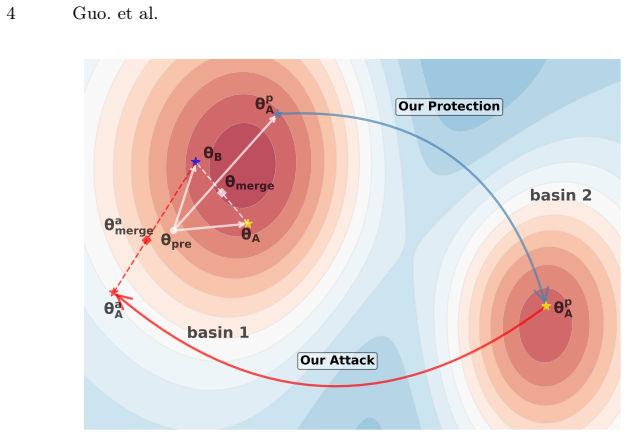
The protected task vectors are inherently small in magnitude. Consequently, the protected weights remain overwhelmingly dominated by the pretrained model. Designating the pretrained model as a static reference anchor allows analytic recovery of the transformation matrix, bypassing the defenses.
What carries the argument
Anchor-Guided Attack (AGA) that aligns the protected model with the pretrained anchor to recover the transformation matrix analytically.
Load-bearing premise
The magnitude of the protected task vectors is small enough for the pretrained model to serve as a reliable static reference anchor allowing analytic recovery of the transformation matrix under realistic defense-agnostic conditions.
What would settle it
A counter-example where task vector magnitudes are comparable to the base model and AGA fails to recover the exact transformation matrix.
Figures
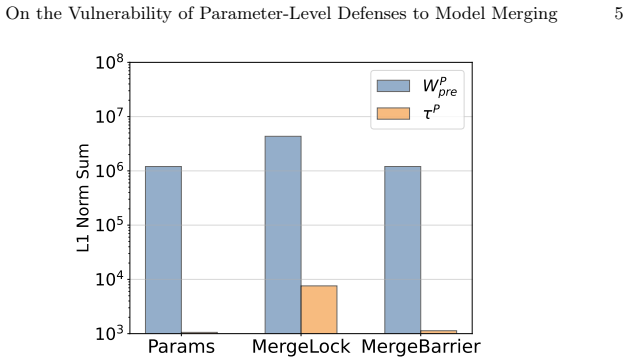
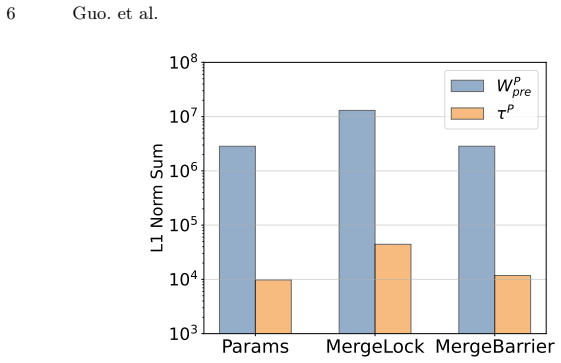
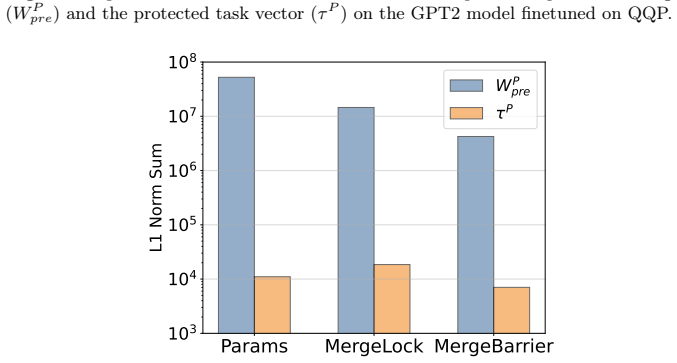
read the original abstract
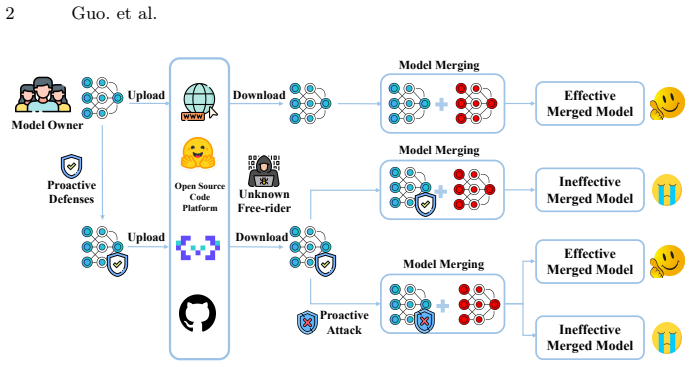
The training-free integration of expert models via model merging has exposed significant security risks, enabling free-riders to combine specialized models without authorization. Recent works propose parameter-level defenses that employ linear parameter transformations to neutralize this threat. In this paper, we systematically analyze such defenses and reveal that their protected task vectors are inherently small in magnitude. Consequently, the protected weights remain overwhelmingly dominated by the pretrained model. Based on this observation, we designate the pretrained model as a static reference anchor and propose the Anchor-Guided Attack (AGA) to circumvent existing safeguards. Specifically, AGA aligns the protected model with this anchor to recover the transformation matrix analytically. Extensive evaluations validate that AGA consistently bypasses both individual and composite defenses under realistic defense-agnostic scenarios. Furthermore, we provide Anchor-Repulsive Fine-tuning (ARF), a defense method to mitigate the anchor dominance leveraged by AGA. Empirical results confirm that ARF effectively defeats the proposed attack. Our code is available at https://github.com/krumpguo/secure-merge-attack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
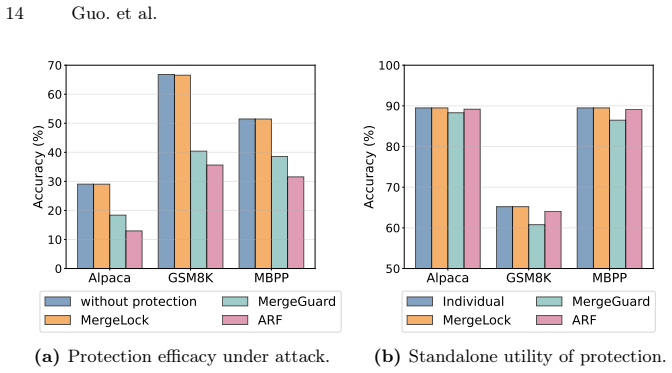
Summary. The paper claims that parameter-level defenses against unauthorized model merging, which rely on linear transformations of task vectors, produce protected task vectors that are inherently small in magnitude. As a result, the defended weights remain dominated by the pretrained model, which can be used as a static reference anchor. The authors propose the Anchor-Guided Attack (AGA) that analytically recovers the unknown linear transformation matrix by alignment with this anchor, bypassing both individual and composite defenses in defense-agnostic settings. They further introduce Anchor-Repulsive Fine-tuning (ARF) as a countermeasure that mitigates the anchor dominance exploited by AGA. The claims are supported by extensive empirical evaluations and publicly released code.
Significance. If the magnitude observation and analytic recovery hold under the stated conditions, the work identifies a structural vulnerability in linear parameter-level defenses for model merging and supplies both an attack (AGA) and a mitigation (ARF). The availability of code supports reproducibility. The result is significant for the security of model merging but is currently limited by the lack of a general theoretical characterization of when the anchor assumption holds.
major comments (2)
- [Abstract] Abstract: the central claim that protected task vectors are 'inherently small in magnitude' (and therefore that the pretrained model can serve as a static reference anchor enabling analytic recovery of arbitrary linear transformations) is presented as a general property of linear defenses. No theoretical bound, sensitivity analysis, or proof is supplied showing why this must hold for any linear map that neutralizes merging; the claim therefore rests on an empirical observation whose scope is unclear.
- [Anchor-Guided Attack] AGA derivation (implicit in the abstract and attack description): the closed-form recovery of the transformation matrix T assumes that the protected weights remain overwhelmingly dominated by the pretrained model under defense-agnostic conditions. If a linear defense applies scaling or rotation that makes the effective task-vector magnitude comparable to the base weights while still preventing merging, the approximation fails and the analytic guarantee no longer applies; no analysis of this regime is provided.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects regarding the theoretical grounding of our observations. We address each major comment below, clarifying the empirical basis of our claims while agreeing to strengthen the manuscript with additional discussion and analysis where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that protected task vectors are 'inherently small in magnitude' (and therefore that the pretrained model can serve as a static reference anchor enabling analytic recovery of arbitrary linear transformations) is presented as a general property of linear defenses. No theoretical bound, sensitivity analysis, or proof is supplied showing why this must hold for any linear map that neutralizes merging; the claim therefore rests on an empirical observation whose scope is unclear.
Authors: We agree that our central observation is grounded in systematic empirical evaluation across existing linear parameter-level defenses rather than a formal proof that the property holds for every conceivable linear map. The term 'inherently' in the manuscript reflects the consistent pattern that effective neutralization of unauthorized merging requires transformations that keep task-vector magnitudes small relative to the pretrained weights. We will revise the abstract to emphasize the empirical scope and add a dedicated discussion subsection on the conditions and sensitivity of the anchor assumption, including any available bounds derived from the merging objective. revision: yes
-
Referee: [Anchor-Guided Attack] AGA derivation (implicit in the abstract and attack description): the closed-form recovery of the transformation matrix T assumes that the protected weights remain overwhelmingly dominated by the pretrained model under defense-agnostic conditions. If a linear defense applies scaling or rotation that makes the effective task-vector magnitude comparable to the base weights while still preventing merging, the approximation fails and the analytic guarantee no longer applies; no analysis of this regime is provided.
Authors: The AGA derivation and its closed-form recovery are predicated on the dominance observed in current defenses, which our extensive experiments confirm holds in defense-agnostic settings. We acknowledge that hypothetical linear transformations achieving comparable magnitudes while still blocking merging would fall outside the analyzed regime. We will incorporate a new subsection analyzing boundary cases, including synthetic experiments that vary task-vector magnitude ratios and measure when the analytic recovery remains accurate versus when it degrades. revision: yes
- A complete general theoretical characterization proving the anchor assumption for arbitrary linear maps that neutralize merging.
Circularity Check
No significant circularity; derivation rests on empirical observation rather than self-referential construction.
full rationale
The paper's load-bearing premise is the empirical finding that protected task vectors have small magnitude, allowing the pretrained model to act as a static anchor for analytic recovery of the transformation matrix T via alignment. This is explicitly framed as an observation from analyzing existing defenses, not a mathematical identity or fitted parameter renamed as a prediction. No equations are provided that reduce the attack derivation to its own inputs by construction, and no self-citation chain is invoked to justify uniqueness or the ansatz. The subsequent proposal of ARF as a countermeasure further indicates independent content outside any circular loop. The result is therefore self-contained against external benchmarks of the evaluated defenses.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al.: Program synthesis with large language models. arXiv preprint arXiv:2108.07732 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
In: Assignment and Matching Problems: Solution Methods with FORTRAN-Programs, pp
Burkard, R.E., Derigs, U.: The linear sum assignment problem. In: Assignment and Matching Problems: Solution Methods with FORTRAN-Programs, pp. 1–15 (1980)
1980
-
[3]
Machine learning pp
Caruana, R.: Multitask learning. Machine learning pp. 41–75 (1997)
1997
-
[4]
In: Proceedings of the 11th International Workshop on Semantic Evaluation (2017)
Cer, D., Diab, M., Agirre, E., Lopez-Gazpio, I., Specia, L.: Semeval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In: Proceedings of the 11th International Workshop on Semantic Evaluation (2017)
2017
-
[5]
In: Proc
Chen, W.J., Tsai, M.Y., Lee, C.Y., Yu, C.M.: Defending unauthorized model merg- ing via dual-stage weight protection. In: Proc. CVPR (2026)
2026
-
[6]
Chen, Z., Zhang, H., Zhang, X., Zhao, L.: Quora question pairs (2018)
2018
-
[7]
Proceedings of the IEEE pp
Cheng, G., Han, J., Lu, X.: Remote sensing image scene classification: Benchmark and state of the art. Proceedings of the IEEE pp. 1865–1883 (2017)
2017
-
[8]
In: Proc
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., Vedaldi, A.: Describing textures in the wild. In: Proc. CVPR (2014)
2014
-
[9]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
In: Proceedings of the 1st ACM Workshop on Large AI Systems and Models with Privacy and Safety Analysis (2023)
Cong, T., Ran, D., Liu, Z., He, X., Liu, J., Gong, Y., Li, Q., Wang, A., Wang, X.: Have you merged my model? on the robustness of large language model ip protec- tion methods against model merging. In: Proceedings of the 1st ACM Workshop on Large AI Systems and Models with Privacy and Safety Analysis (2023)
2023
-
[11]
IEEE Signal Processing Magazine pp
Deng, L.: The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine pp. 141–142 (2012)
2012
-
[12]
arXiv preprint arXiv:2506.09446 (2025)
Ding, Y., Liang, J., Jiang, B., Wang, Z., Zheng, A., Luo, B.: Harmonizing and merging source models for clip-based domain generalization. arXiv preprint arXiv:2506.09446 (2025)
-
[13]
In: Third International Workshop on Paraphrasing (2005)
Dolan, B., Brockett, C.: Automatically constructing a corpus of sentential para- phrases. In: Third International Workshop on Paraphrasing (2005)
2005
-
[14]
In: Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing (2007)
Giampiccolo, D., Magnini, B., Dagan, I., Dolan, W.B.: The third pascal recognizing textual entailment challenge. In: Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing (2007)
2007
-
[15]
In: Proc
Guo, K., Yu, A., Liang, J., Ding, Y., Wang, Z., He, R., Tan, T.: Stay unique, stay efficient: Preserving model personality in multi-task merging. In: Proc. ECCV (2026)
2026
-
[16]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing pp
Helber, P., Bischke, B., Dengel, A., Borth, D.: Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing pp. 2217–2226 (2019)
2019
-
[17]
In: Proc
Ilharco, G., Ribeiro, M.T., Wortsman, M., Gururangan, S., Schmidt, L., Hajishirzi, H., Farhadi, A.: Editing models with task arithmetic. In: Proc. ICLR (2023)
2023
-
[18]
In: Proc
Junhao, W., Zhe, Y., Sakuma, J.: Disrupting model merging: A parameter-level defense without sacrificing accuracy. In: Proc. ICCV (2025)
2025
-
[19]
In: Proc
Krause, J., Stark, M., Deng, J., Fei-Fei, L.: 3d object representations for fine- grained categorization. In: Proc. ICCV (2013) On the Vulnerability of Parameter-Level Defenses to Model Merging 17
2013
-
[20]
Naval research logistics quarterly pp
Kuhn, H.W.: The hungarian method for the assignment problem. Naval research logistics quarterly pp. 83–97 (1955)
1955
-
[21]
In: Proc
Li, L., Zhang, T., Bu, Z., Wang, S., He, H., Fu, J., Wu, Y., Bian, J., Chen, Y., Bengio, Y.: Map: Low-compute model merging with amortized pareto fronts via quadratic approximation. In: Proc. ICLR (2025)
2025
-
[22]
In: Proc
Li, Q., Pan, M., Chen, J., Teng, F., Shen, Z., Su, G., Peng, H., Zhang, X.: Do not merge my model! safeguarding open-source llms against unauthorized model merging. In: Proc. AAAI (2026)
2026
-
[23]
Li, X., Zhang, T., Dubois, Y., Taori, R., Gulrajani, I., Guestrin, C., Liang, P., Hashimoto, T.B.: Alpacaeval: An automatic evaluator of instruction-following models (2023)
2023
-
[24]
In: Proc
Lu, Z., Fan, C., Wei, W., Qu, X., Chen, D., Cheng, Y.: Twin-merging: Dynamic integration of modular expertise in model merging. In: Proc. NeurIPS (2024)
2024
-
[25]
https://modelscope.cn/ (2025)
ModeScope: Modelscope: Open-source model platform. https://modelscope.cn/ (2025)
2025
-
[26]
In: Proc
Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., Ng, A.Y., et al.: Reading digits in natural images with unsupervised feature learning. In: Proc. NeurIPS (2011)
2011
-
[27]
In: Proc
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: Proc. ICML (2021)
2021
-
[28]
OpenAI blog p
Radford,A.,Wu,J.,Child,R.,Luan,D.,Amodei,D.,Sutskever,I.,etal.:Language models are unsupervised multitask learners. OpenAI blog p. 9 (2019)
2019
-
[29]
In: Proc
Rajpurkar, P., Zhang, J., Lopyrev, K., Liang, P.: Squad: 100,000+ questions for machine comprehension of text. In: Proc. EMNLP (2016)
2016
-
[30]
In: Proc
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C.D., Ng, A.Y., Potts, C.: Recursive deep models for semantic compositionality over a sentiment treebank. In: Proc. EMNLP (2013)
2013
-
[31]
In: Proc
Stallkamp, J., Schlipsing, M., Salmen, J., Igel, C.: The german traffic sign recogni- tion benchmark: a multi-class classification competition. In: Proc. IJCNN (2011)
2011
-
[32]
In: Proc
Sun, W., Li, Q., Geng, Y.a., Li, B.: Cat merging: A training-free approach for resolving conflicts in model merging. In: Proc. ICML (2025)
2025
-
[33]
In: Proc
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Proc. NeurIPS (2017)
2017
-
[34]
In: Proc
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., Bowman, S.R.: Glue: A multi- task benchmark and analysis platform for natural language understanding. In: Proc. ICLR (2018)
2018
-
[35]
In: Proc
Wang, K., Dimitriadis, N., Ortiz-Jimenez, G., Fleuret, F., Frossard, P.: Localizing task information for improved model merging and compression. In: Proc. ICML (2025)
2025
-
[36]
arXiv preprint arXiv:2509.01548 (2025)
Wang, Z., Yang, E., Yin, L., Liu, S., Shen, L.: Model unmerging: Making your models unmergeable for secure model sharing. arXiv preprint arXiv:2509.01548 (2025)
-
[37]
In: Proc
Warstadt, A., Singh, A., Bowman, S.R.: Neural network acceptability judgments. In: Proc. ACL (2019)
2019
-
[38]
The Annals of Mathematical Statis- tics pp
Watson, G.S.: Linear least squares regression. The Annals of Mathematical Statis- tics pp. 1679–1699 (1967)
1967
-
[39]
In: Proc
Williams, A., Nangia, N., Bowman, S.R.: A broad-coverage challenge corpus for sentence understanding through inference. In: Proc. ACL (2018) 18 Guo. et al
2018
-
[40]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al.: Huggingface’s transformers: State-of- the-art natural language processing. arXiv preprint arXiv:1910.03771 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[41]
Big Data and Cognitive Computing p
Wu, X.K., Chen, M., Li, W., Wang, R., Lu, L., Liu, J., Hwang, K., Hao, Y., Pan, Y., Meng, Q., et al.: Llm fine-tuning: Concepts, opportunities, and challenges. Big Data and Cognitive Computing p. 87 (2025)
2025
-
[42]
In: Proc
Xiao, J., Hays, J., Ehinger, K.A., Oliva, A., Torralba, A.: Sun database: Large-scale scene recognition from abbey to zoo. In: Proc. CVPR (2010)
2010
-
[43]
In: Proc
Yadav, P., Tam, D., Choshen, L., Raffel, C.A., Bansal, M.: Ties-merging: Resolving interference when merging models. In: Proc. NeurIPS (2023)
2023
-
[44]
In: Proc
Yamabe, S., Waseda, F.K., Takahashi, T., Wataoka, K.: Mergeprint: Merge- resistant fingerprints for robust black-box ownership verification of large language models. In: Proc. ACL (2025)
2025
-
[45]
Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., Dong, G., Wei, H., Lin, H., Tang, J., Wang, J., Yang, J., Tu, J., Zhang, J., Ma, J., Yang, J., Xu, J., Zhou, J., Bai, J., He, J., Lin, J., Dang, K., Lu, K., Chen, K., Yang, K., Li, M., Xue, M., Ni, N., Zhang, P., Wang, P., Peng, R., Men, R., Gao, R., Lin, R., Wan...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
In: Proc
Yu, L., Yu, B., Yu, H., Huang, F., Li, Y.: Language models are super mario: Absorbing abilities from homologous models as a free lunch. In: Proc. ICML (2024)
2024
-
[47]
arXiv preprint arXiv:2505.22271 (2025)
Yu, Y., Wang, Y., He, R., Liang, J.: Test-time immunization: A universal de- fense framework against jailbreaks for (multimodal) large language models. arXiv preprint arXiv:2505.22271 (2025)
-
[48]
arXiv preprint arXiv:2402.17193 (2024)
Zhang,B.,Liu,Z.,Cherry,C.,Firat,O.:Whenscalingmeetsllmfinetuning:Theef- fect of data, model and finetuning method. arXiv preprint arXiv:2402.17193 (2024)
-
[49]
National Science Review pp
Zhang, Y., Yang, Q.: An overview of multi-task learning. National Science Review pp. 30–43 (2018)
2018
-
[50]
IEEE Transactions on Knowledge and Data Engineering pp
Zhang, Y., Yang, Q.: A survey on multi-task learning. IEEE Transactions on Knowledge and Data Engineering pp. 5586–5609 (2021)
2021
-
[51]
In: Proc
Zhao, Z., Shen, T., Zhu, D., Li, Z., Su, J., Wang, X., Wu, F.: Merging loras like playing lego: Pushing the modularity of lora to extremes through rank-wise clus- tering. In: Proc. ICLR (2025) On the Vulnerability of Parameter-Level Defenses to Model Merging 1 7 The Proof Theorem 3 (Error Bound of Attention Module Recovery).LetW f t = Wpre +τ∈R N×D (where...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.