MUSE: Unlocking Timestep as Native Task Steering for One-Step Dense Prediction
Pith reviewed 2026-06-30 06:15 UTC · model grok-4.3
The pith
Fixed sinusoidal timestep embeddings in one-step diffusion models can steer multiple dense prediction tasks without added parameters or adapters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In one-step diffusion models repurposed for monocular dense prediction, the native fixed sinusoidal timestep embedding functions as an endogenous steering signal: assigning a distinct discrete timestep value to each task deterministically routes the denoising process onto a separate task-specific manifold in latent space, enabling a single model to perform multiple predictions without parameter additions.
What carries the argument
Native fixed sinusoidal timestep embedding, repurposed as endogenous task steering signal via manifold decoupling.
If this is right
- A single model reaches competitive accuracy on both monocular depth and surface normal estimation across ten datasets.
- The same steering pattern works without modification on U-Net and DiT architectures.
- Multi-task dense prediction requires no extra adapters, experts, or learnable tokens.
- The approach supplies an efficient route to generalist models by using only the existing diffusion pipeline.
Where Pith is reading between the lines
- If manifold decoupling generalizes, the same fixed-timestep assignment could support additional dense tasks such as semantic segmentation or edge detection inside one model.
- The method might allow rapid switching between tasks at inference time simply by changing the timestep scalar rather than reloading model weights.
- Testing whether continuous or learned timestep schedules preserve the decoupling would clarify whether the discrete fixed values are strictly necessary.
Load-bearing premise
Assigning different fixed discrete timestep values will reliably drive the model to produce outputs belonging to separate, decoupled task manifolds rather than mixed or collapsed results.
What would settle it
Run the same input image through the model twice using two different assigned timesteps and observe whether the outputs match the corresponding ground-truth tasks; if swapping the timesteps produces no change in task alignment or if performance collapses, the steering claim fails.
Figures

read the original abstract
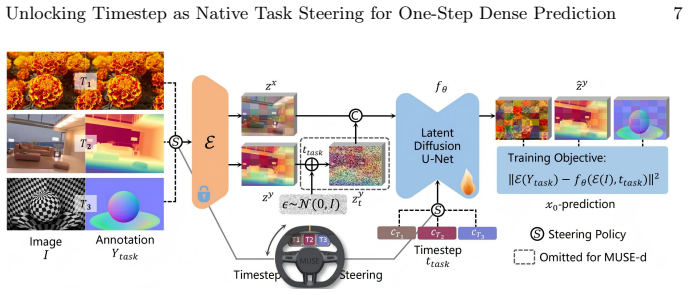
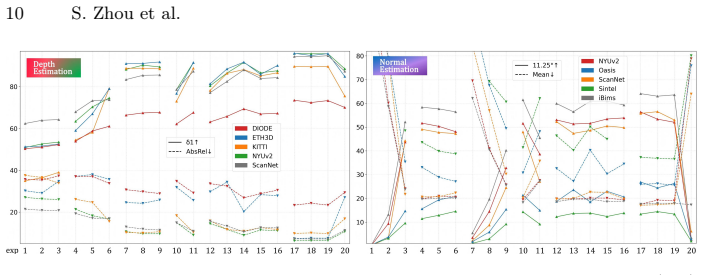
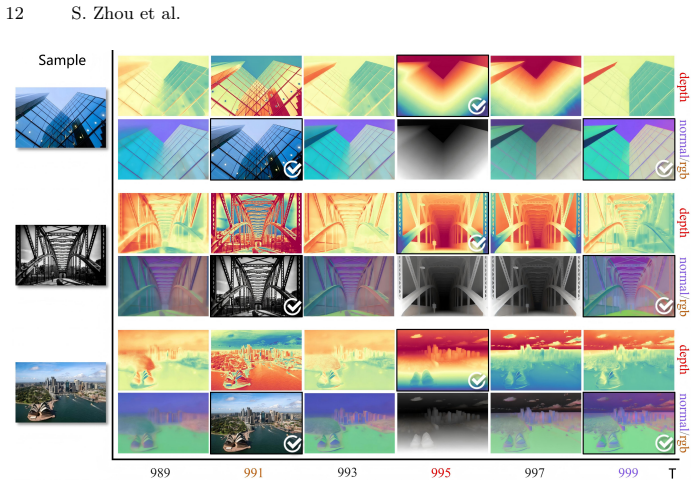
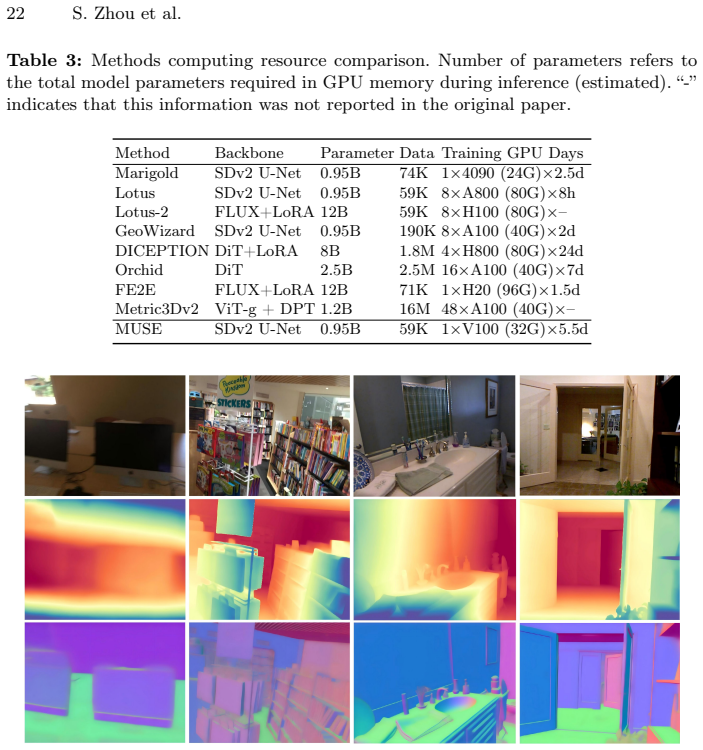
Monocular dense prediction has recently seen remarkable success by repurposing pre-trained diffusion models. This opens a promising yet challenging avenue for more efficient multi-task learning paradigm. However, existing multi-task diffusion methods often introduce parameter-heavy adapters, experts, or learnable task tokens, leading to computational redundancy. In this paper, we reveal an inherent mechanism within one-step diffusion models: the native, fixed sinusoidal timestep embedding can be repurposed as an endogenous task steering signal. Based on this discovery, we propose Multi-task Unified eStimation via timestep Embedding (MUSE), a parameter-free, single-model multi-tasking approach for dense prediction. We interpret this mechanism via Manifold Decoupling, where discrete, fixed timestep values deterministically steer the generation process towards decoupled, task-specific manifolds in the latent space. Extensive experiments across 10 datasets demonstrate that MUSE achieves highly competitive performance on both monocular depth and normal estimation, and its efficacy generalizes across U-Net and DiT architectures. Our work offers a concise and efficient path toward generalist vision models by simply unlocking the latent potential of existing generation infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in one-step diffusion models for monocular dense prediction, the native fixed sinusoidal timestep embedding can be repurposed as a parameter-free endogenous task steering signal for multi-task learning (e.g., depth and normals estimation). It introduces MUSE based on this observation and interprets the effect via 'Manifold Decoupling,' where discrete timestep values steer the denoising process onto decoupled task-specific manifolds in latent space. Experiments across 10 datasets and two architectures (U-Net, DiT) report competitive performance without added parameters or adapters.
Significance. If the central empirical finding holds, the work provides a concise, zero-parameter route to multi-task dense prediction by leveraging existing diffusion infrastructure, which could simplify generalist vision models. The evaluation spans multiple datasets and architectures, offering some evidence of generality; this is a positive aspect of the submission.
major comments (2)
- [Manifold Decoupling interpretation] Interpretation section (Manifold Decoupling): The claim that fixed sinusoidal timestep values 'deterministically steer the generation process towards decoupled, task-specific manifolds' is presented as the explanatory mechanism but receives only post-hoc support from performance tables. No derivation from the sinusoidal embedding formula or the diffusion ODE is provided, nor are direct tests (e.g., latent-space trajectory analysis or manifold separability metrics) reported. This interpretation is load-bearing for the 'inherent mechanism' and 'endogenous steering' framing; an alternative account—that timestep simply serves as a learned index for task-specific heads—remains viable on the presented evidence.
- [Experiments] Experiments section: The abstract states competitive results on 10 datasets, yet the manuscript provides insufficient detail on exact baselines, full ablation controls for the timestep choice, error bars, or statistical significance tests. Without these, it is difficult to isolate whether gains arise specifically from the timestep-as-steering effect versus standard multi-task training.
minor comments (2)
- [Methods] Notation for the sinusoidal embedding and its reuse as a task index should be made explicit early in the methods section to avoid ambiguity with standard diffusion conditioning.
- [Figures] Figure captions for any latent-space or trajectory visualizations (if present) should clarify whether they constitute direct evidence for manifold decoupling or illustrative examples.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We provide point-by-point responses to the major comments below, clarifying our interpretation and enhancing the experimental section.
read point-by-point responses
-
Referee: [Manifold Decoupling interpretation] Interpretation section (Manifold Decoupling): The claim that fixed sinusoidal timestep values 'deterministically steer the generation process towards decoupled, task-specific manifolds' is presented as the explanatory mechanism but receives only post-hoc support from performance tables. No derivation from the sinusoidal embedding formula or the diffusion ODE is provided, nor are direct tests (e.g., latent-space trajectory analysis or manifold separability metrics) reported. This interpretation is load-bearing for the 'inherent mechanism' and 'endogenous steering' framing; an alternative account—that timestep simply serves as a learned index for task-specific heads—remains viable on the presented evidence.
Authors: We appreciate this comment. Importantly, the sinusoidal timestep embedding used is the fixed, non-learnable embedding from the pre-trained diffusion model, not a learned parameter. This makes the alternative account of it serving as a 'learned index' less applicable, as no task-specific learning occurs in the embedding itself. The steering emerges from the interaction with the fixed embedding during the one-step denoising. That said, we acknowledge the need for more direct evidence. In the revision, we have added latent trajectory analysis and manifold separability metrics to support the decoupling claim. We also include a brief derivation sketch based on the properties of sinusoidal embeddings in the diffusion process. revision: partial
-
Referee: [Experiments] Experiments section: The abstract states competitive results on 10 datasets, yet the manuscript provides insufficient detail on exact baselines, full ablation controls for the timestep choice, error bars, or statistical significance tests. Without these, it is difficult to isolate whether gains arise specifically from the timestep-as-steering effect versus standard multi-task training.
Authors: We agree that more details are necessary. In the revised manuscript, we have expanded the experiments section to include: (1) exact specifications of all baselines with references, (2) comprehensive ablations on the effect of different timestep values for task steering, (3) error bars computed over 3 random seeds, and (4) p-values from statistical tests comparing MUSE to baselines. These additions demonstrate that the performance gains are attributable to the timestep steering mechanism rather than generic multi-task training. revision: yes
Circularity Check
No circularity: empirical observation validated on external datasets
full rationale
The paper's central claim—that the fixed sinusoidal timestep embedding functions as an endogenous task-steering signal—is presented as an empirical discovery tested across 10 external datasets rather than a quantity defined in terms of fitted parameters or self-referential equations. The Manifold Decoupling interpretation is offered post-hoc to explain observed performance differences between depth and normal estimation tasks; it is not used to derive the method itself. No load-bearing step reduces by construction to the inputs, no self-citation chain substitutes for independent evidence, and the approach is parameter-free by design with results reported on held-out benchmarks. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Sinusoidal timestep embeddings are fixed and native components of diffusion model architectures
invented entities (1)
-
Manifold Decoupling
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[2]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[4]
The Principles of Diffusion Models
Lai, C.H., Song, Y., Kim, D., Mitsufuji, Y., Ermon, S.: The principles of diffusion models. arXiv preprint arXiv:2510.21890 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[6]
arXiv preprint arXiv:2302.14816 (2023)
Saxena, S., Kar, A., Norouzi, M., Fleet, D.J.: Monocular depth estimation using diffusion models. arXiv preprint arXiv:2302.14816 (2023)
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ji, Y., Chen, Z., Xie, E., Hong, L., Liu, X., Liu, Z., Lu, T., Li, Z., Luo, P.: Ddp: Diffusion model for dense visual prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21741–21752 (2023)
2023
-
[8]
In: European Conference on Computer Vision
Duan, Y., Guo, X., Zhu, Z.: Diffusiondepth: Diffusion denoising approach for monocular depth estimation. In: European Conference on Computer Vision. pp. 432–449. Springer (2024)
2024
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Ke, B., Obukhov, A., Huang, S., Metzger, N., Daudt, R.C., Schindler, K.: Re- purposing diffusion-based image generators for monocular depth estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 9492–9502 (2024)
2024
-
[10]
arXiv preprint arXiv:2409.18124 (2024)
He, J., Li, H., Yin, W., Liang, Y., Li, L., Zhou, K., Zhang, H., Liu, B., Chen, Y.C.: Lotus: Diffusion-based visual foundation model for high-quality dense prediction. arXiv preprint arXiv:2409.18124 (2024)
-
[11]
arXiv preprint arXiv:2501.13087 (2025)
Krishnan, A., Yan, X., Casser, V., Kundu, A.: Orchid: Image latent diffusion for joint appearance and geometry generation. arXiv preprint arXiv:2501.13087 (2025)
-
[12]
Lotus-2: Advancing Geometric Dense Prediction with Powerful Image Generative Model
He, J., Li, H., Sheng, M., Chen, Y.C.: Lotus-2: Advancing geometric dense pre- diction with powerful image generative model. arXiv preprint arXiv:2512.01030 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
arXiv preprint arXiv:2503.15905 (2025)
Wang, J., Lin, C., Guan, C., Nie, L., He, J., Li, H., Liao, K., Zhao, Y.: Jasmine: Harnessing diffusion prior for self-supervised depth estimation. arXiv preprint arXiv:2503.15905 (2025)
-
[14]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Ye, H., Xu, D.: Diffusionmtl: Learning multi-task denoising diffusion model from partially annotated data. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 27960–27969 (2024)
2024
-
[15]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Dong, L., Zhai, W., Zha, Z.J.: Unidense: Unleashing diffusion models with meta- routers for universal few-shot dense prediction. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 10525–10534 (2024) 16 S. Zhou et al
2024
-
[16]
In: European Conference on Computer Vision
Zhang, M., Song, G., Shi, X., Liu, Y., Li, H.: Three things we need to know about transferring stable diffusion to visual dense prediction tasks. In: European Conference on Computer Vision. pp. 128–145. Springer (2024)
2024
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Long, X., Guo, Y.C., Lin, C., Liu, Y., Dou, Z., Liu, L., Ma, Y., Zhang, S.H., Habermann, M., Theobalt, C., et al.: Wonder3d: Single image to 3d using cross- domain diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9970–9980 (2024)
2024
-
[18]
In: European Conference on Computer Vision
Fu, X., Yin, W., Hu, M., Wang, K., Ma, Y., Tan, P., Shen, S., Lin, D., Long, X.: Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. In: European Conference on Computer Vision. pp. 241–258. Springer (2024)
2024
-
[19]
Advances in Neural Information Processing Systems36, 27199– 27222 (2023)
Go, H., Lee, Y., Lee, S., Oh, S., Moon, H., Choi, S.: Addressing negative transfer in diffusion models. Advances in Neural Information Processing Systems36, 27199– 27222 (2023)
2023
-
[20]
In: Proceedings of the IEEE/CVF international conference on computer vision
Hang, T., Gu, S., Li, C., Bao, J., Chen, D., Hu, H., Geng, X., Guo, B.: Efficient diffusion training via min-snr weighting strategy. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7441–7451 (2023)
2023
-
[21]
arXiv preprint arXiv:2103.02631 (2021)
Javaloy, A., Valera, I.: Rotograd: Gradient homogenization in multitask learning. arXiv preprint arXiv:2103.02631 (2021)
-
[22]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition
Lee, H.Y., Tseng, H.Y., Yang, M.H.: Exploiting diffusion prior for generalizable dense prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition. pp. 7861–7871 (2024)
2024
- [24]
-
[25]
DepthMaster: Taming Diffusion Models for Monocular Depth Estimation
Song, Z., Wang, Z., Li, B., Zhang, H., Zhu, R., Liu, L., Jiang, P.T., Zhang, T.: Depthmaster: Taming diffusion models for monocular depth estimation. arXiv preprint arXiv:2501.02576 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
arXiv preprint arXiv:2505.09358 (2025)
Ke, B., Qu, K., Wang, T., Metzger, N., Huang, S., Li, B., Obukhov, A., Schindler, K.: Marigold: Affordable adaptation of diffusion-based image generators for image analysis. arXiv preprint arXiv:2505.09358 (2025)
-
[27]
One Step Diffusion via Shortcut Models
Frans,K.,Hafner,D.,Levine,S.,Abbeel,P.:Onestepdiffusionviashortcutmodels. arXiv preprint arXiv:2410.12557 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Mean Flows for One-step Generative Modeling
Geng,Z.,Deng,M.,Bai,X.,Kolter,J.Z.,He,K.:Meanflowsforone-stepgenerative modeling. arXiv preprint arXiv:2505.13447 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
arXiv preprint arXiv:2508.04979 (2025)
Chen, Z., Zhou, M., Guo, J., Yuan, J., Ji, Y., Zhang, Y.: Steering one-step diffu- sion model with fidelity-rich decoder for fast image compression. arXiv preprint arXiv:2508.04979 (2025)
-
[30]
arXiv preprint arXiv:2508.17426 (2025)
You, H., Liu, B., He, H.: Modular meanflow: Towards stable and scalable one-step generative modeling. arXiv preprint arXiv:2508.17426 (2025)
-
[31]
In: European Conference on Computer Vision
Park, B., Go, H., Kim, J.Y., Woo, S., Ham, S., Kim, C.: Switch diffusion trans- former: Synergizing denoising tasks with sparse mixture-of-experts. In: European Conference on Computer Vision. pp. 461–477. Springer (2024)
2024
-
[32]
In: The Thirteenth International Conference on Learning Representations (2024)
Yang, Y., Jiang, P.T., Hou, Q., Zhang, H., Chen, J., Li, B.: Multi-task dense predictions via unleashing the power of diffusion. In: The Thirteenth International Conference on Learning Representations (2024)
2024
-
[33]
Zhao,C.,Sun,Y.,Liu,M.,Zheng,H.,Zhu,M.,Zhao,Z.,Chen,H.,He,T.,Shen,C.: Diception: A generalist diffusion model for visual perceptual tasks. arXiv preprint arXiv:2502.17157 (2025) Unlocking Timestep as Native Task Steering for One-Step Dense Prediction 17
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ma, Q., Ning, X., Liu, D., Niu, L., Zhang, L.: Decouple-then-merge: Finetune diffusion models as multi-task learning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23281–23291 (2025)
2025
-
[35]
arXiv preprint arXiv:2009.09796 (2020)
Crawshaw, M.: Multi-task learning with deep neural networks: A survey. arXiv preprint arXiv:2009.09796 (2020)
-
[36]
science290(5500), 2268– 2269 (2000)
Seung, H.S., Lee, D.D.: The manifold ways of perception. science290(5500), 2268– 2269 (2000)
2000
-
[37]
Advances in Neural Information Processing Systems35, 25683–25696 (2022)
Chung, H., Sim, B., Ryu, D., Ye, J.C.: Improving diffusion models for inverse problems using manifold constraints. Advances in Neural Information Processing Systems35, 25683–25696 (2022)
2022
-
[38]
arXiv preprint arXiv:2311.16424 (2023)
He, Y., Murata, N., Lai, C.H., Takida, Y., Uesaka, T., Kim, D., Liao, W.H., Mitsu- fuji,Y.,Kolter,J.Z.,Salakhutdinov,R.,etal.:Manifoldpreservingguideddiffusion. arXiv preprint arXiv:2311.16424 (2023)
- [39]
-
[40]
arXiv preprint arXiv:2509.20201 (2025)
Jacobsen, A.K., Gegenfurtner, J.M., Arvanitidis, G.: Staying on the manifold: Geometry-aware noise injection. arXiv preprint arXiv:2509.20201 (2025)
-
[41]
Back to Basics: Let Denoising Generative Models Denoise
Li, T., He, K.: Back to basics: Let denoising generative models denoise. arXiv preprint arXiv:2511.13720 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
In: Forty-first International Conference on Machine Learning (2024)
Stanczuk, J.P., Batzolis, G., Deveney, T., Schönlieb, C.B.: Diffusion models encode the intrinsic dimension of data manifolds. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[43]
Annual Review of Statistics and Its Application11(1), 393–417 (2024)
Meilă, M., Zhang, H.: Manifold learning: What, how, and why. Annual Review of Statistics and Its Application11(1), 393–417 (2024)
2024
-
[44]
In: Proceedings of the IEEE/CVF international conference on computer vision
Roberts, M., Ramapuram, J., Ranjan, A., Kumar, A., Bautista, M.A., Paczan, N., Webb, R., Susskind, J.M.: Hypersim: A photorealistic synthetic dataset for holis- tic indoor scene understanding. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10912–10922 (2021)
2021
-
[45]
Cabon, Y., Murray, N., Humenberger, M.: Virtual kitti 2 (2020)
2020
-
[46]
In: European conference on computer vision
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: European conference on computer vision. pp. 746–
-
[47]
The international journal of robotics research32(11), 1231–1237 (2013)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. The international journal of robotics research32(11), 1231–1237 (2013)
2013
-
[48]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5828–5839 (2017)
2017
-
[49]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schops, T., Schonberger, J.L., Galliani, S., Sattler, T., Schindler, K., Pollefeys, M., Geiger, A.: A multi-view stereo benchmark with high-resolution images and multi-camera videos. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3260–3269 (2017)
2017
-
[50]
arXiv preprint arXiv:1908.00463 (2019)
Vasiljevic, I., Kolkin, N., Zhang, S., Luo, R., Wang, H., Dai, F.Z., Daniele, A.F., Mostajabi, M., Basart, S., Walter, M.R., et al.: Diode: A dense indoor and outdoor depth dataset. arXiv preprint arXiv:1908.00463 (2019)
-
[51]
In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops
Koch, T., Liebel, L., Fraundorfer, F., Korner, M.: Evaluation of cnn-based single- image depth estimation methods. In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops. pp. 0–0 (2018)
2018
-
[52]
In: European conference on computer vision
Butler, D.J., Wulff, J., Stanley, G.B., Black, M.J.: A naturalistic open source movie for optical flow evaluation. In: European conference on computer vision. pp. 611–
-
[53]
Zhou et al
Springer (2012) 18 S. Zhou et al
2012
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, W., Qian, S., Fan, D., Kojima, N., Hamilton, M., Deng, J.: Oasis: A large- scale dataset for single image 3d in the wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 679–688 (2020)
2020
-
[55]
science290(5500), 2319–2323 (2000)
Tenenbaum, J.B., Silva, V.d., Langford, J.C.: A global geometric framework for nonlinear dimensionality reduction. science290(5500), 2319–2323 (2000)
2000
-
[56]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[57]
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) Unlocking Timestep as Native Task Steering for One-Step Dense Prediction 19 Supplementary Materials A Deconstructing Diffusion Conditioning Rather than operating solely on noisy latent and the timesteps, the denoising U-N...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.