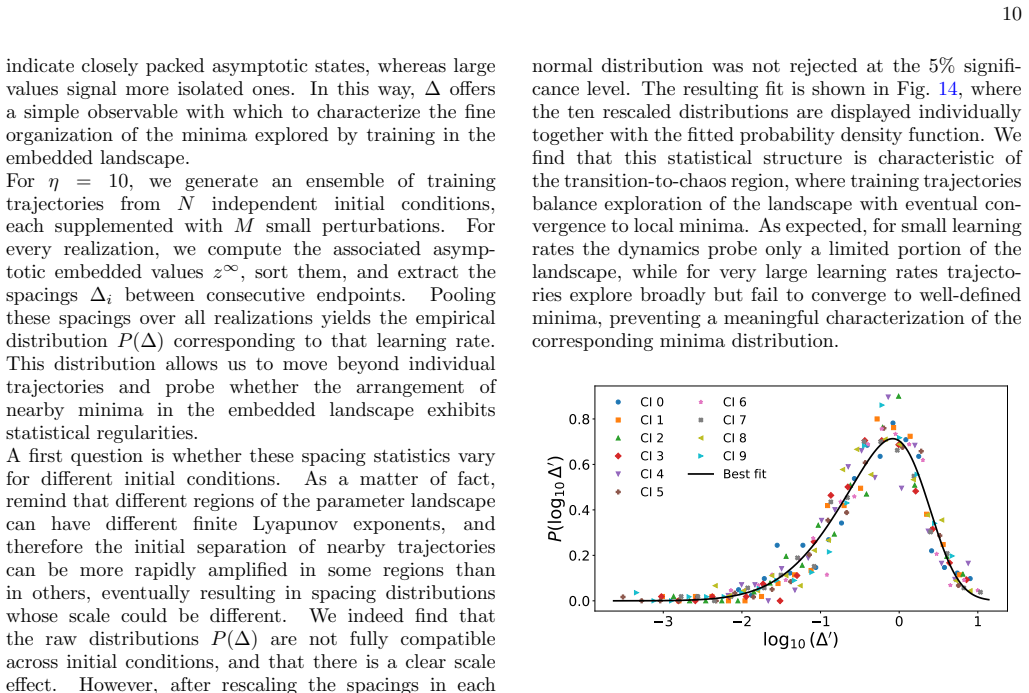
Scalar Representations of Neural Network Training Dynamics
Pith reviewed 2026-06-30 07:04 UTC · model grok-4.3
The pith
Scalar embeddings of neural network training trajectories preserve key dynamical features including Lyapunov exponents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
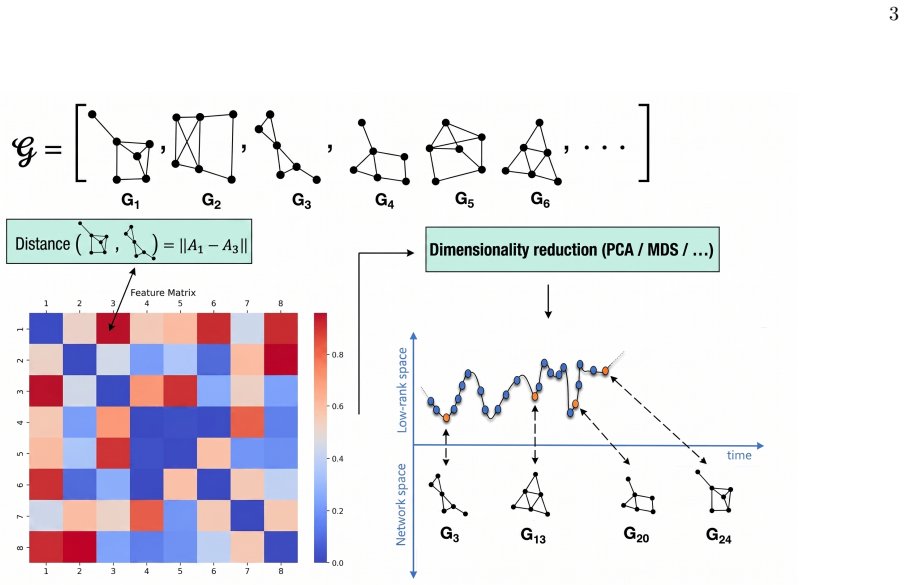
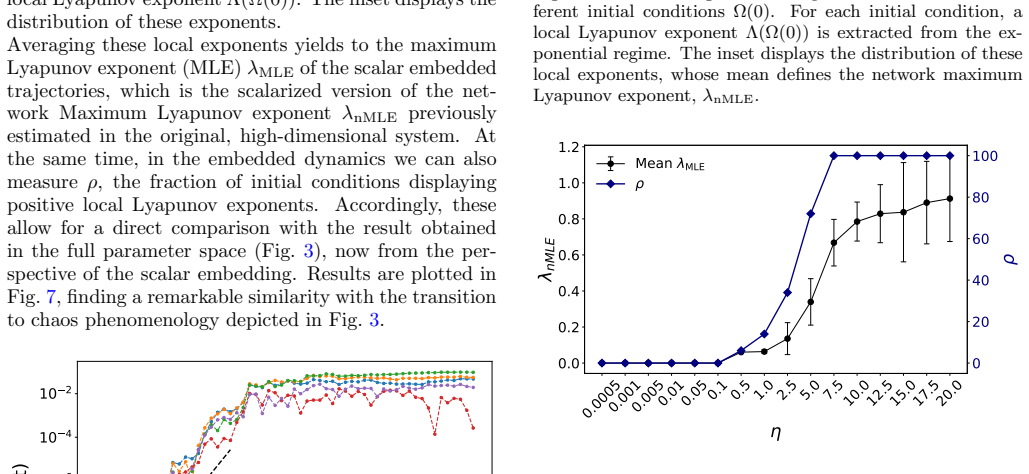
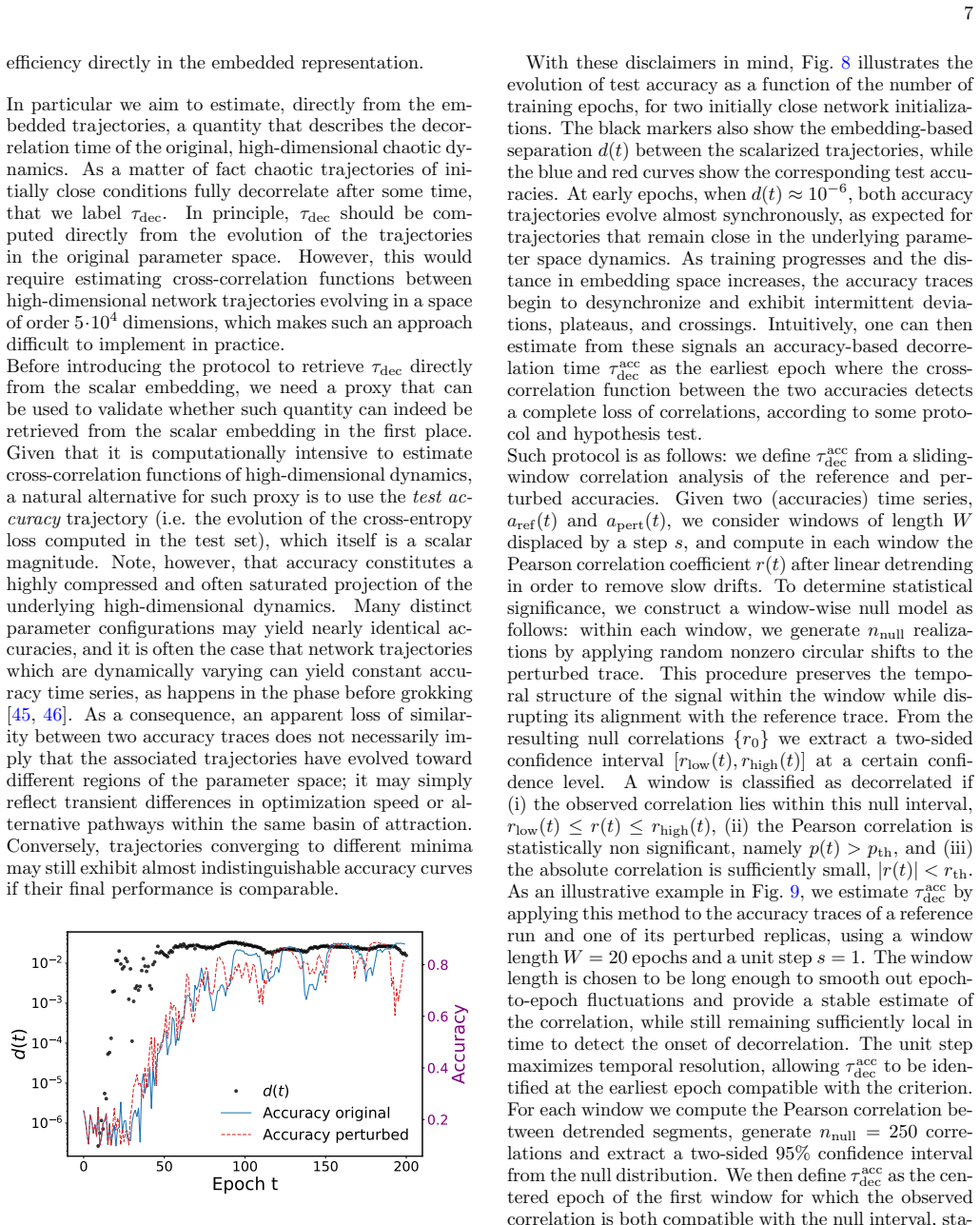
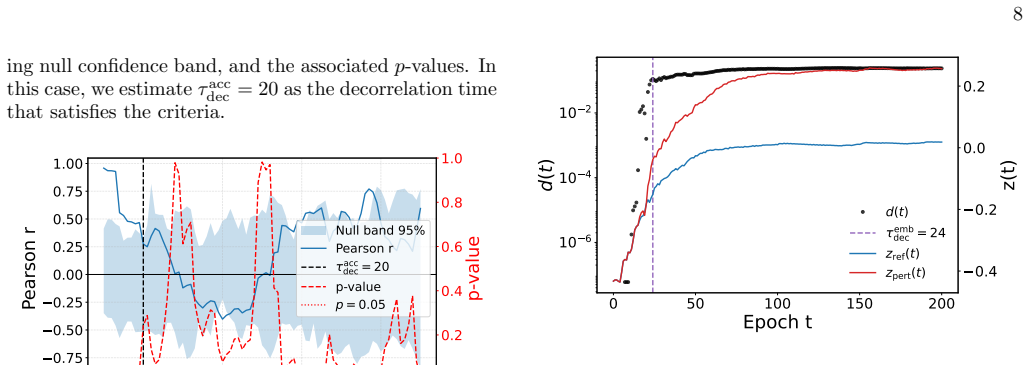
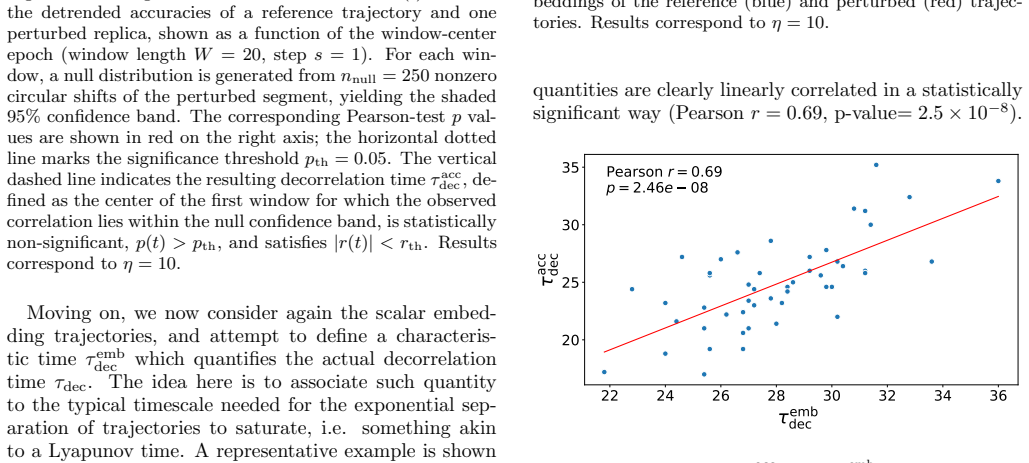
By embedding the training trajectories of a multilayer perceptron on MNIST as scalar time series using temporal network methods, the resulting low-dimensional representation preserves the main dynamical features observed in the original parameter space, including the emergence of sensitivity to initial conditions for specific learning rate regimes and an accurate reconstruction of the network's maximum Lyapunov exponent. The embedded space also yields a characteristic time analogous to a Lyapunov time that captures the typical decorrelation between initially close trajectories in the high-dimensional system, and the distributions of rescaled asymptotic spacings collapse onto a common skew lo
What carries the argument
The scalar embedding of the training trajectory viewed as a temporal network, which reduces the high-dimensional parameter dynamics to a one-dimensional time series while retaining invariants such as the maximum Lyapunov exponent.
If this is right
- The embedded trajectory defines a characteristic time after which exponential separation saturates, corresponding to the decorrelation time between close trajectories in the original system.
- Rescaled spacings of asymptotic training states produce distributions that collapse onto a skew lognormal form independent of initial conditions.
- The method supplies a practical framework for visualizing and quantifying chaotic properties of optimization without operating in the full parameter space.
- Statistical organization of long-term training states can be probed through observables defined solely in the embedded space.
Where Pith is reading between the lines
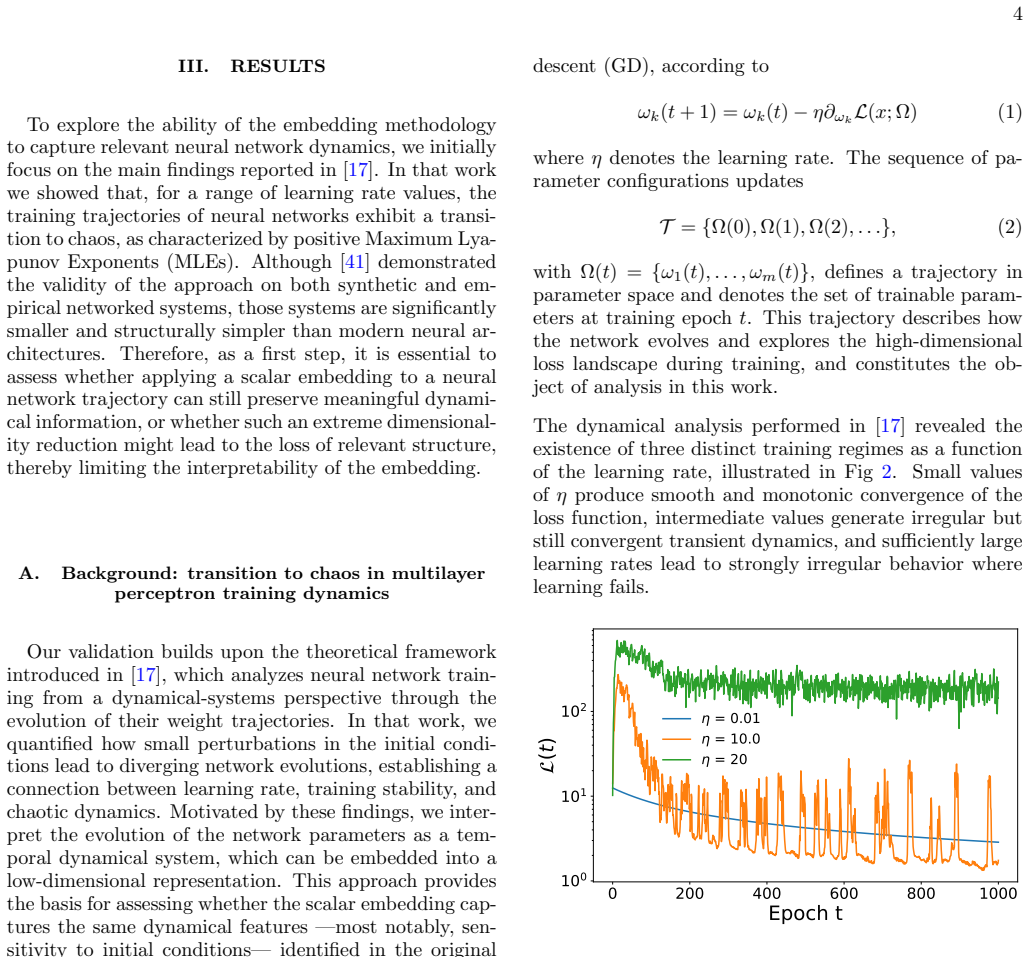
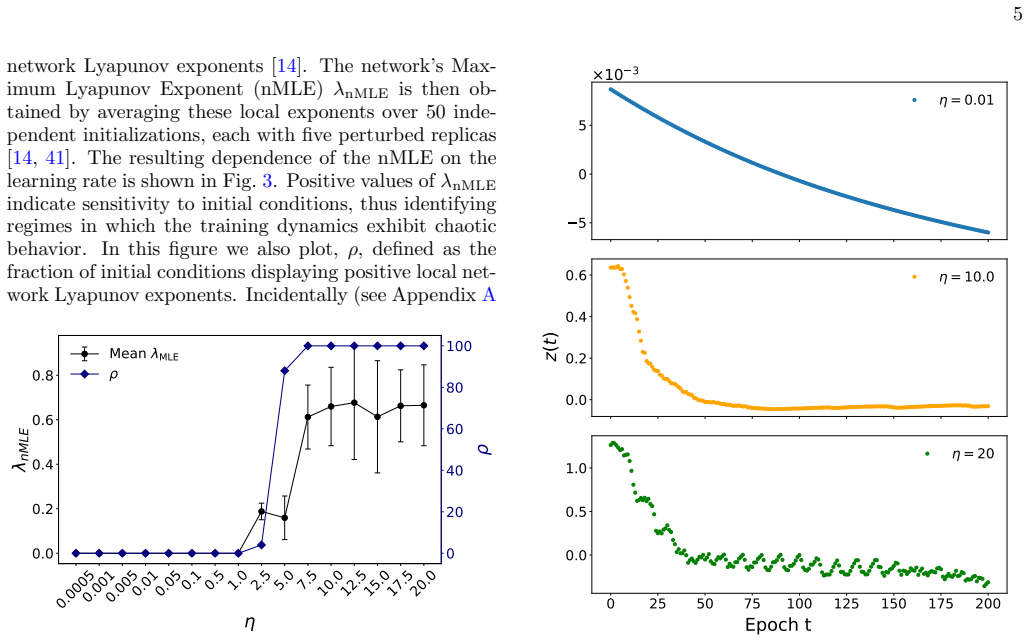
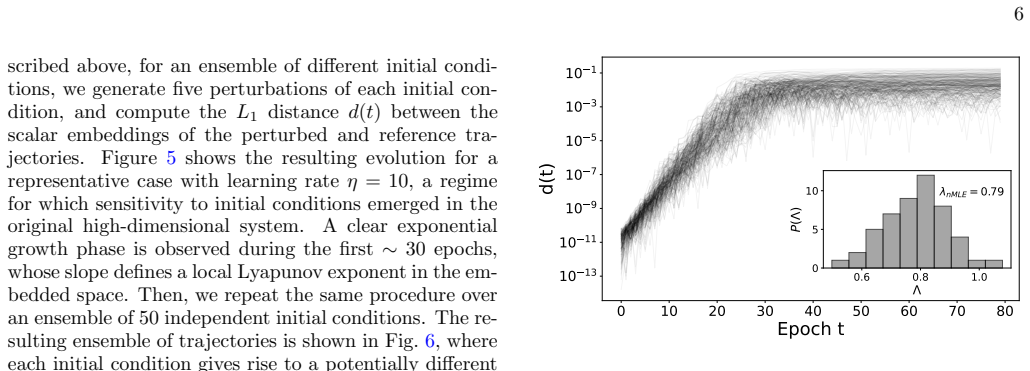
- If the embedding preserves dynamics across architectures, it could enable real-time monitoring of chaotic regimes during training using only reduced-dimensional projections.
- The collapse to a common spacing distribution hints that asymptotic optimization states may obey universal statistical laws independent of starting point or task details.
- Applying the same embedding to recurrent or transformer models would test whether the reported Lyapunov preservation and skew-lognormal spacing are architecture-independent features.
Load-bearing premise
That scalar embedding methods developed for general temporal networks can be applied to neural-network parameter trajectories while retaining the dynamical quantities such as Lyapunov exponents and decorrelation times that are treated as ground truth.
What would settle it
Direct computation of the maximum Lyapunov exponent in the full high-dimensional parameter space for the same network and learning rates, followed by comparison to the exponent extracted from the scalar embedding; a statistically significant mismatch would falsify the preservation claim.
Figures

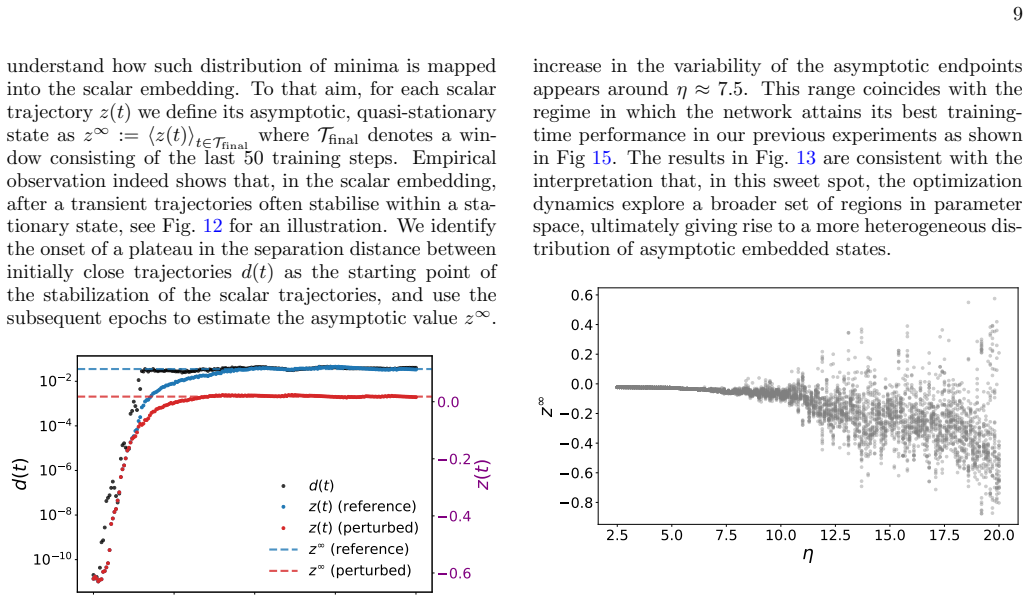

read the original abstract
Training in artificial neural networks can be viewed as a trajectory evolving through a high-dimensional loss landscape. However, the large number of trainable parameters makes the direct analysis of these dynamics challenging. In this work, we treat such training trajectories as temporal networks and apply recently proposed strategies for the scalar embedding of temporal networks. We investigate whether such a scalar embedding provides a meaningful low-dimensional representation of neural network training dynamics. Using a multilayer perceptron trained on the MNIST classification task, we show that the embedding preserves the main dynamical features observed in the original parameter space, including the emergence of sensitivity to initial conditions for specific learning rate regimes and an accurate reconstruction of the network's maximum Lyapunov exponent. We then use the embedded scalar trajectory to define a characteristic time, analogous to a Lyapunov time, after which the exponential separation between initially close embedded trajectories saturates. This characteristic time captures the typical decorrelation time between initially close network trajectories in the original high-dimensional system. Finally, we investigate the statistical organization of asymptotic training states through a spacing observable defined in the embedded space. We find that the distributions of rescaled asymptotic spacings collapse onto a common form across initial conditions and are compatible with a skew lognormal distribution. Altogether, our results suggest that scalar low-dimensional embeddings provide a useful framework for studying and visualizing the dynamical properties of neural network optimization trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that treating neural network training trajectories as temporal networks and applying scalar embedding techniques yields a low-dimensional representation that preserves key dynamical features. Specifically, for an MLP on MNIST, the embedding captures sensitivity to initial conditions in certain learning rate regimes, accurately reconstructs the maximum Lyapunov exponent, defines a characteristic decorrelation time, and shows that asymptotic spacing distributions collapse to a skew lognormal form.
Significance. Should the embedding method prove faithful, it would provide a valuable tool for analyzing and visualizing the high-dimensional dynamics of neural network training, potentially uncovering universal statistical properties in the organization of training trajectories. The approach bridges concepts from temporal networks and dynamical systems with machine learning optimization.
major comments (2)
- [Abstract] The assertion of an 'accurate reconstruction' of the maximum Lyapunov exponent lacks any quantitative error metrics, ablation checks on embedding parameters, or description of the validation procedure against the high-dimensional trajectory. This is central to the claim that the embedding preserves dynamical features and prevents assessment of its soundness.
- [Results] No explicit cross-validation, such as comparing divergence rates of nearby trajectories in the original versus embedded space, is described to support the preservation of the Lyapunov exponent and decorrelation time. This leaves the central claim dependent on the untested assumption that the embedding map is dynamically faithful for parameter trajectories.
minor comments (1)
- [Abstract] The abstract introduces 'temporal networks' and 'scalar embedding' without a short definition or citation, which could hinder accessibility for readers outside the subfield.
Simulated Author's Rebuttal
We thank the referee for their constructive comments highlighting the need for stronger quantitative validation of the embedding's dynamical faithfulness. We address each point below and have revised the manuscript accordingly to include the requested metrics, ablations, and cross-validations.
read point-by-point responses
-
Referee: [Abstract] The assertion of an 'accurate reconstruction' of the maximum Lyapunov exponent lacks any quantitative error metrics, ablation checks on embedding parameters, or description of the validation procedure against the high-dimensional trajectory. This is central to the claim that the embedding preserves dynamical features and prevents assessment of its soundness.
Authors: We agree that the original manuscript presented the reconstruction primarily through visual comparison without quantitative error metrics or ablations. In the revision we will add the relative error between the maximum Lyapunov exponent computed from the embedded trajectory and the value obtained directly from the high-dimensional parameter trajectory. We will also include ablation studies varying the embedding dimension and time delay, together with an explicit description of the validation procedure used to compare against the original dynamics. revision: yes
-
Referee: [Results] No explicit cross-validation, such as comparing divergence rates of nearby trajectories in the original versus embedded space, is described to support the preservation of the Lyapunov exponent and decorrelation time. This leaves the central claim dependent on the untested assumption that the embedding map is dynamically faithful for parameter trajectories.
Authors: We acknowledge that explicit cross-validation strengthens the central claim. The revised manuscript will report direct comparisons of the divergence rates between pairs of nearby trajectories evaluated both in the original high-dimensional parameter space and in the scalar embedded space. These comparisons will be used to confirm preservation of the Lyapunov exponent and the characteristic decorrelation time. revision: yes
Circularity Check
No significant circularity; derivations are self-contained empirical comparisons
full rationale
The paper applies existing scalar embedding techniques for temporal networks to NN parameter trajectories and validates preservation of dynamical features (e.g., Lyapunov exponent reconstruction, decorrelation times, spacing statistics) via direct comparison on an MLP trained on MNIST. No equations, procedures, or self-citations in the provided text reduce any reported prediction or reconstruction to a quantity defined by fitting the same data or by the embedding map itself. The validations are presented as independent checks against the original high-dimensional trajectory, and the central claims do not rely on load-bearing self-citations or ansatzes that collapse by construction. This is the normal case of an externally benchmarked application study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scalar embedding strategies for temporal networks preserve the main dynamical features of neural-network training trajectories
Reference graph
Works this paper leans on
-
[1]
Goodfellow, Yoshua Bengio, and Aaron Courville
Ian J. Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, Cambridge, MA, USA, 2016. http://www.deeplearningbook.org
2016
-
[2]
Neural networks and physical systems with emergent collective computational abilities.Pro- ceedings of the national academy of sciences, 79(8):2554– 2558, 1982
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Pro- ceedings of the national academy of sciences, 79(8):2554– 2558, 1982
1982
-
[3]
Machine learning and the physical sciences.Reviews of Modern Physics, 91(4):045002, 2019
Giuseppe Carleo, Ignacio Cirac, Kyle Cranmer, Lau- rent Daudet, Maria Schuld, Naftali Tishby, Leslie Vogt- Maranto, and Lenka Zdeborov´ a. Machine learning and the physical sciences.Reviews of Modern Physics, 91(4):045002, 2019
2019
-
[4]
Cambridge University Press, 2022
Steven L Brunton and J Nathan Kutz.Data-driven sci- ence and engineering: Machine learning, dynamical sys- tems, and control. Cambridge University Press, 2022
2022
-
[5]
Statistical physics for artificial neural net- works.Applied Physics Reviews, 13(1), 2026
Zongrui Pei. Statistical physics for artificial neural net- works.Applied Physics Reviews, 13(1), 2026
2026
-
[6]
Application of complex systems topologies in artificial neural networks optimiza- tion: An overview.Expert Systems with Applications, 180:115073, 2021
Sara Kaviani and Insoo Sohn. Application of complex systems topologies in artificial neural networks optimiza- tion: An overview.Expert Systems with Applications, 180:115073, 2021
2021
-
[7]
Correlations of network trajectories.Physical Review Re- search, 4(4):L042008, 2022
Lucas Lacasa, Jorge P Rodriguez, and Victor M Eguiluz. Correlations of network trajectories.Physical Review Re- search, 4(4):L042008, 2022
2022
-
[8]
Complex networks: principles, methods and applications
Vito Latora, Vincenzo Nicosia, and Giovanni Russo. Complex networks: principles, methods and applications. Cambridge University Press, 2017
2017
-
[9]
World Scientific, 2016
Naoki Masuda and Renaud Lambiotte.A guide to tem- poral networks. World Scientific, 2016
2016
-
[10]
Springer, 2019
Petter Holme and Jari Saram¨ aki.Temporal network the- ory, volume 2. Springer, 2019
2019
-
[11]
Characterizing the dynamics of unlabeled temporal net- works.Chaos: An Interdisciplinary Journal of Nonlinear Science, 35(5), 2025
Annalisa Caligiuri, Tobias Galla, and Lucas Lacasa. Characterizing the dynamics of unlabeled temporal net- works.Chaos: An Interdisciplinary Journal of Nonlinear Science, 35(5), 2025
2025
-
[12]
Character- ization of interactions’ persistence in time-varying net- works.Scientific Reports, 13(1):765, 2023
Francisco Bauz´ a Mingueza, Mario Flor´ ıa, Jes´ us G´ omez- Garde˜ nes, Alex Arenas, and Alessio Cardillo. Character- ization of interactions’ persistence in time-varying net- works.Scientific Reports, 13(1):765, 2023
2023
-
[13]
Autocorrelation properties of temporal networks governed by dynamic node variables.Physical Review Research, 7(1):013083, 2025
Harrison Hartle and Naoki Masuda. Autocorrelation properties of temporal networks governed by dynamic node variables.Physical Review Research, 7(1):013083, 2025
2025
-
[14]
Lyapunov ex- ponents for temporal networks.Physical Review E, 107(4):044305, 2023
Annalisa Caligiuri, Victor M Egu´ ıluz, Leonardo Di Gae- tano, Tobias Galla, and Lucas Lacasa. Lyapunov ex- ponents for temporal networks.Physical Review E, 107(4):044305, 2023
2023
-
[15]
Predictability of temporal network dynamics in normal ageing and brain pathology.Journal of Complex Networks, 14(1):cnaf058, 2026
Annalisa Caligiuri, David Papo, G¨ orsev Yener, Bahar G¨ untekin, Tobias Galla, Lucas Lacasa, and Massimiliano Zanin. Predictability of temporal network dynamics in normal ageing and brain pathology.Journal of Complex Networks, 14(1):cnaf058, 2026
2026
-
[16]
Dynamical stability and chaos in artificial neural net- work trajectories along training.Frontiers in Complex Systems, 2:1367957, 2024
Kaloyan Danovski, Miguel C Soriano, and Lucas Lacasa. Dynamical stability and chaos in artificial neural net- work trajectories along training.Frontiers in Complex Systems, 2:1367957, 2024
2024
-
[17]
Leveraging chaotic transients in the training of artificial neural networks.Physical Review Research, 8(2):L022032, 2026
Pedro Jim´ enez-Gonz´ alez, Miguel C Soriano, and Lucas Lacasa. Leveraging chaotic transients in the training of artificial neural networks.Physical Review Research, 8(2):L022032, 2026
2026
-
[18]
Optimal in- put representation in neural systems at the edge of chaos
Guillermo B Morales and Miguel A Mu˜ noz. Optimal in- put representation in neural systems at the edge of chaos. Biology, 10(8):702, 2021
2021
-
[19]
Finite-time lyapunov expo- nents of deep neural networks.Physical Review Letters, 132(5):057301, 2024
L Storm, Hampus Linander, J Bec, Kristian Gustavs- son, and Bernhard Mehlig. Finite-time lyapunov expo- nents of deep neural networks.Physical Review Letters, 132(5):057301, 2024
2024
-
[20]
Local lyapunov exponents of deep echo state networks
Claudio Gallicchio, Alessio Micheli, and Luca Silvestri. Local lyapunov exponents of deep echo state networks. Neurocomputing, 298:34–45, 2018
2018
-
[21]
Visualising basins of attraction for the cross-entropy and the squared error neural network loss functions.Neurocomputing, 400:113–136, 2020
Anna Sergeevna Bosman, Andries Engelbrecht, and Mard´ e Helbig. Visualising basins of attraction for the cross-entropy and the squared error neural network loss functions.Neurocomputing, 400:113–136, 2020
2020
-
[22]
Quali- tatively characterizing neural network optimization prob- lems
Ian Goodfellow, Oriol Vinyals, and Andrew Saxe. Quali- tatively characterizing neural network optimization prob- lems. InInternational Conference on Learning Represen- tations, 2015
2015
-
[23]
Visualizing the loss landscape of neural nets.Advances in neural information processing systems, 31, 2018
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the loss landscape of neural nets.Advances in neural information processing systems, 31, 2018
2018
-
[24]
Towards under- standing the generalization of deep learning: Perspective of loss landscapes
Lei Wu, Zhanxing Zhu, and Weinan E. Towards under- standing the generalization of deep learning: Perspective of loss landscapes. InICML 2017 Workshop on Princi- pled Approaches to Deep Learning, 2017
2017
-
[25]
An investigation into neural net optimization via hessian eigenvalue density
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net optimization via hessian eigenvalue density. InInternational Conference on Ma- chine Learning, pages 2232–2241. PMLR, 2019
2019
-
[26]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Levent Sagun, Utku Evci, V Ugur Guney, Yann Dauphin, and Leon Bottou. Empirical analysis of the hessian of over-parametrized neural networks.arXiv preprint arXiv:1706.04454, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Jonathan Frankle. Revisiting ”qualitatively character- izing neural network optimization problems”.arXiv preprint arXiv:2012.06898, 2020
-
[28]
What can linear interpolation of neural network loss landscapes tell us? InInternational Conference on Machine Learning, pages 22325–22341
Tiffany J Vlaar and Jonathan Frankle. What can linear interpolation of neural network loss landscapes tell us? InInternational Conference on Machine Learning, pages 22325–22341. PMLR, 2022
2022
-
[29]
On mono- tonic linear interpolation of neural network parameters
James R Lucas, Juhan Bae, Michael R Zhang, Stanislav Fort, Richard Zemel, and Roger B Grosse. On mono- tonic linear interpolation of neural network parameters. InInternational Conference on Machine Learning, pages 7168–7179. PMLR, 2021
2021
-
[30]
Optimization on multifrac- tal loss landscapes explains a diverse range of geometrical and dynamical properties of deep learning.Nature Com- munications, 16(1):3252, 2025
Andrew Ly and Pulin Gong. Optimization on multifrac- tal loss landscapes explains a diverse range of geometrical and dynamical properties of deep learning.Nature Com- munications, 16(1):3252, 2025
2025
-
[31]
Measuring the intrinsic dimension of objec- tive landscapes
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objec- tive landscapes. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[32]
Gradient Descent Happens in a Tiny Subspace
Guy Gur-Ari, Daniel A Roberts, and Ethan Dyer. Gra- dient descent happens in a tiny subspace.arXiv preprint arXiv:1812.04754, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Does sgd really happen in tiny subspaces? InInternational Conference on Learning Representations, volume 2025, pages 8086–8120, 2025
Minhak Song, Kwangjun Ahn, and Chulhee Yun. Does sgd really happen in tiny subspaces? InInternational Conference on Learning Representations, volume 2025, pages 8086–8120, 2025
2025
-
[34]
The training process of many deep networks explores the same low-dimensional manifold.Proceedings of the National Academy of Sci- ences, 121(12):e2310002121, 2024
Jialin Mao, Itay Griniasty, Han Kheng Teoh, Rahul 13 Ramesh, Rubing Yang, Mark K Transtrum, James P Sethna, and Pratik Chaudhari. The training process of many deep networks explores the same low-dimensional manifold.Proceedings of the National Academy of Sci- ences, 121(12):e2310002121, 2024
2024
-
[35]
Visualizing deep network training trajec- tories with pca
Eliana Lorch. Visualizing deep network training trajec- tories with pca. InICML Workshop on Visualization for Deep Learning, 2016
2016
-
[36]
Pca of high dimensional random walks with comparison to neural network training.Advances in Neural Information Pro- cessing Systems, 31, 2018
Joseph Antognini and Jascha Sohl-Dickstein. Pca of high dimensional random walks with comparison to neural network training.Advances in Neural Information Pro- cessing Systems, 31, 2018
2018
-
[37]
Classifying the classifier: dissecting the weight space of neural networks
Gabriel Eilertsen, Daniel J¨ onsson, Timo Ropinski, Jonas Unger, and Anders Ynnerman. Classifying the classifier: dissecting the weight space of neural networks. InEuro- pean Conference on Artificial Intelligence (ECAI 2020), volume 325, pages 1119–1126. IOS PRESS, 2020
2020
-
[38]
Self-supervised representation learning on neu- ral network weights for model characteristic prediction
Konstantin Sch¨ urholt, Dimche Kostadinov, and Damian Borth. Self-supervised representation learning on neu- ral network weights for model characteristic prediction. Advances in Neural Information Processing Systems, 34:16481–16493, 2021
2021
-
[39]
A survey of weight space learning: Understanding, representation, and generation
Xiaolong Han, Zehong Wang, Bo Zhao, Binchi Zhang, Jundong Li, Damian Borth, Rose Yu, Haggai Maron, Yanfang Ye, Lu Yin, et al. A survey of weight space learning: Understanding, representation, and generation. arXiv preprint arXiv:2603.10090, 2026
-
[40]
Embedding and trajectories of temporal networks
Chanon Thongprayoon, Lorenzo Livi, and Naoki Ma- suda. Embedding and trajectories of temporal networks. IEEE Access, 11:41426–41443, 2023
2023
-
[41]
Scalar embedding of tem- poral network trajectories.Chaos, Solitons & Fractals, 199:116599, 2025
Lucas Lacasa, F Javier Mar´ ın-Rodr´ ıguez, Naoki Masuda, and Llu´ ıs Arola-Fern´ andez. Scalar embedding of tem- poral network trajectories.Chaos, Solitons & Fractals, 199:116599, 2025
2025
-
[42]
Fluid dynamics reduction methods for temporal networks.Scientific Reports, 2026
Lucas Lacasa. Fluid dynamics reduction methods for temporal networks.Scientific Reports, 2026
2026
-
[43]
Review of the development of multidi- mensional scaling methods.Journal of the Royal Statis- tical Society: Series D (The Statistician), 41(1):27–39, 1992
Andrew Mead. Review of the development of multidi- mensional scaling methods.Journal of the Royal Statis- tical Society: Series D (The Statistician), 41(1):27–39, 1992
1992
-
[44]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, L´ eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[45]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generaliza- tion beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
Kenzo Clauw, Sebastiano Stramaglia, and Daniele Mari- nazzo. Information-theoretic progress measures reveal grokking is an emergent phase transition.arXiv preprint arXiv:2408.08944, 2024
-
[47]
K-sample anderson–darling tests.Journal of the American Statis- tical Association, 82(399):918–924, 1987
Fritz W Scholz and Michael A Stephens. K-sample anderson–darling tests.Journal of the American Statis- tical Association, 82(399):918–924, 1987
1987
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.