A Stochastic--Geometric Theory of Scaling Laws in Grokking
Pith reviewed 2026-06-30 03:51 UTC · model grok-4.3
The pith
Adam dynamics with weight shrinkage create a shell-core topology in parameter space that produces grokking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
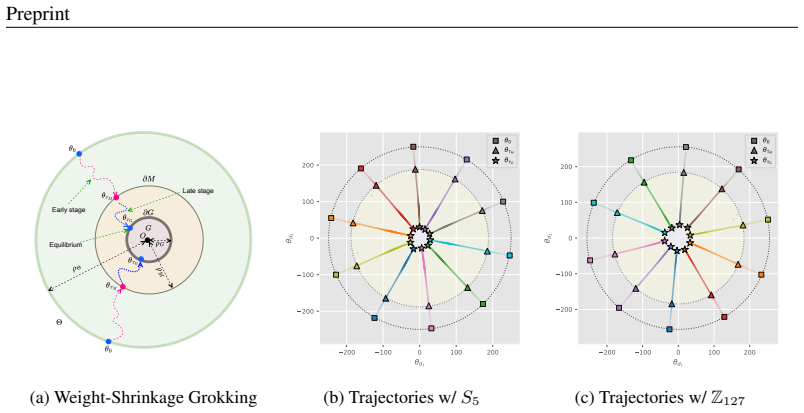
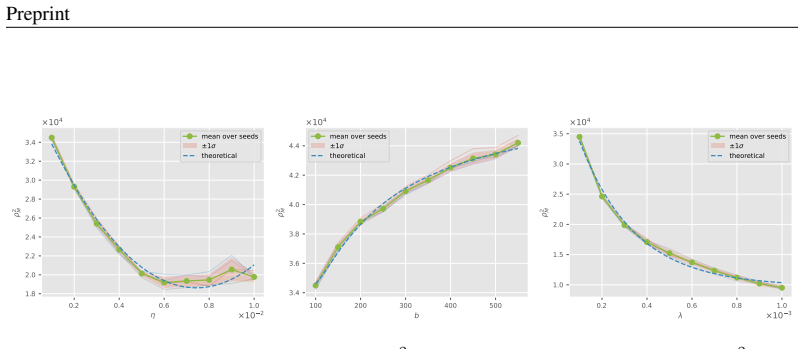
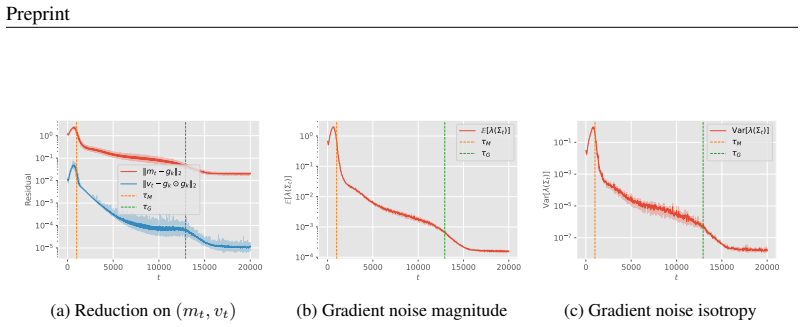
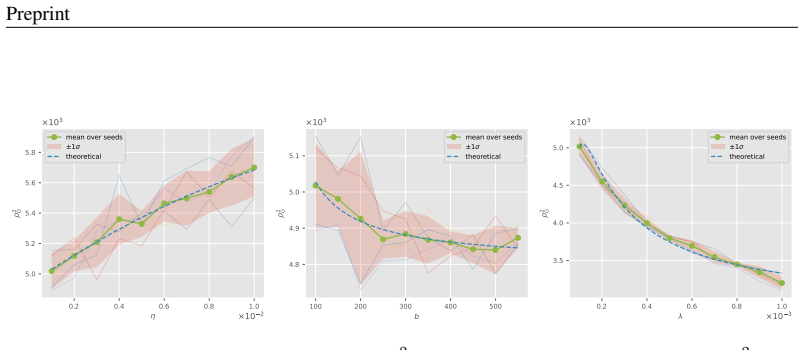
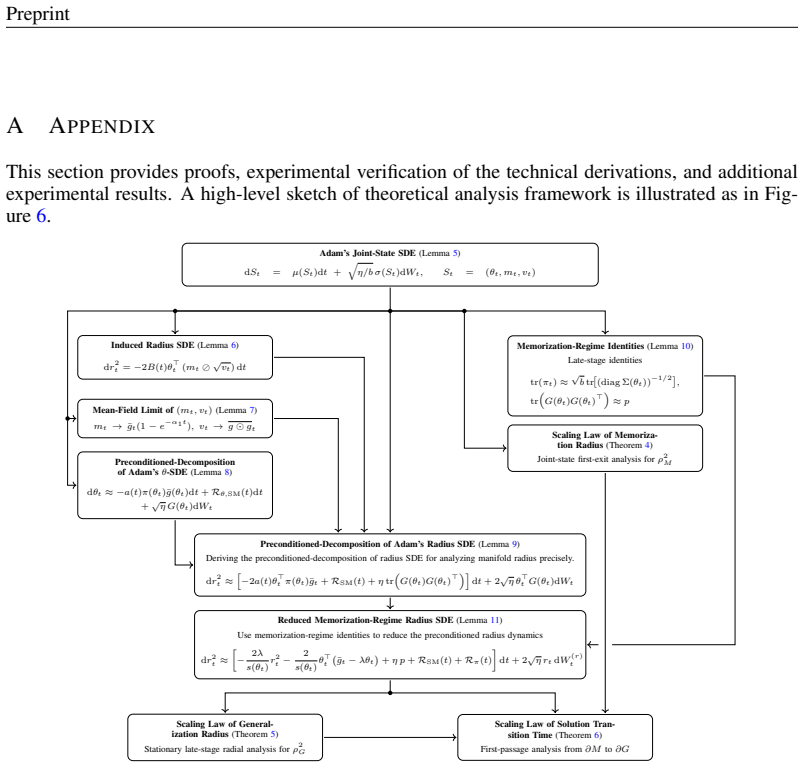
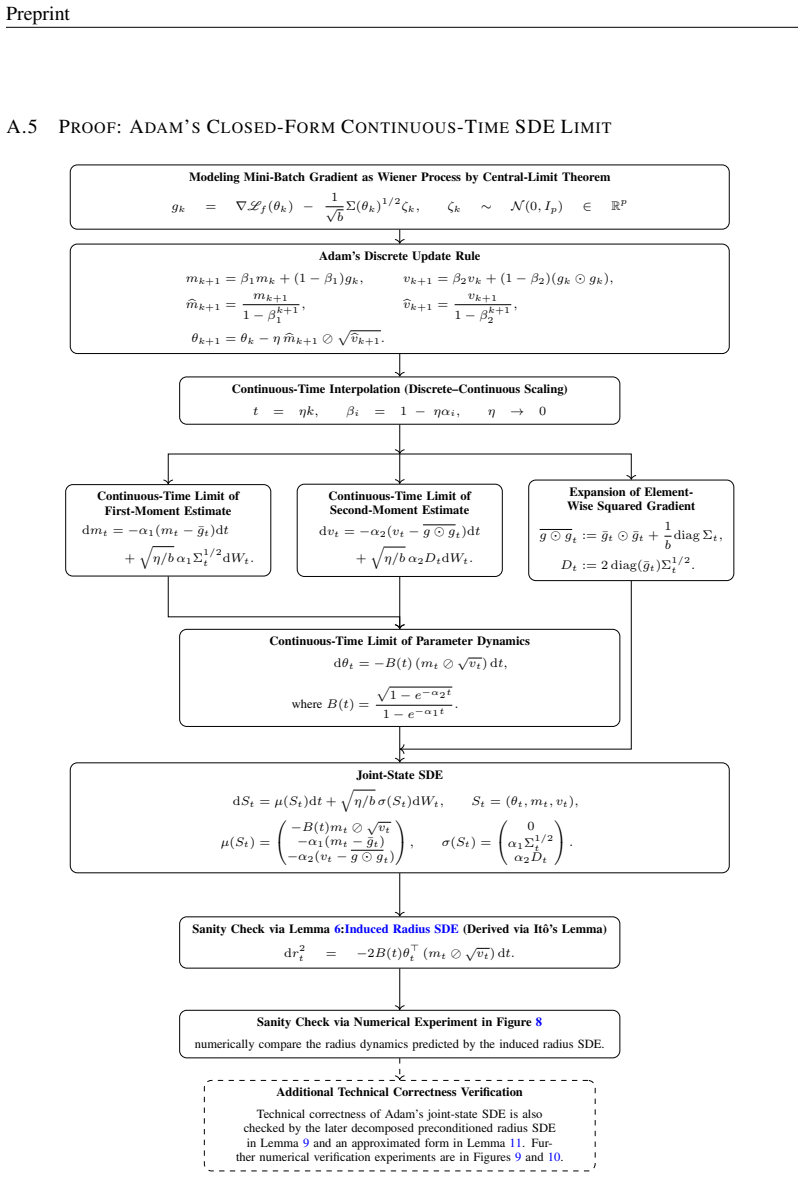
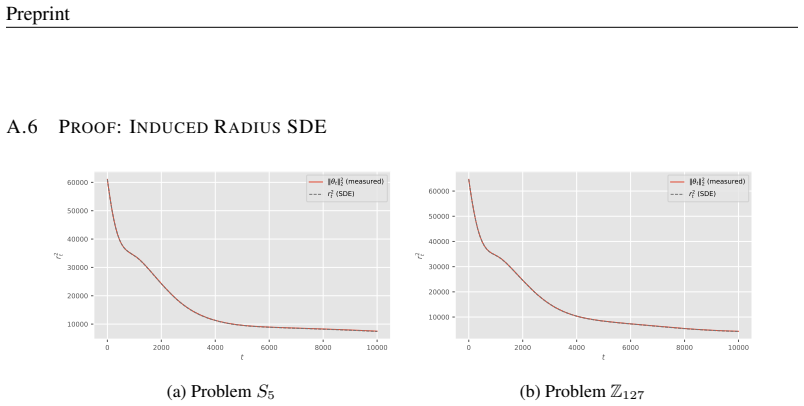
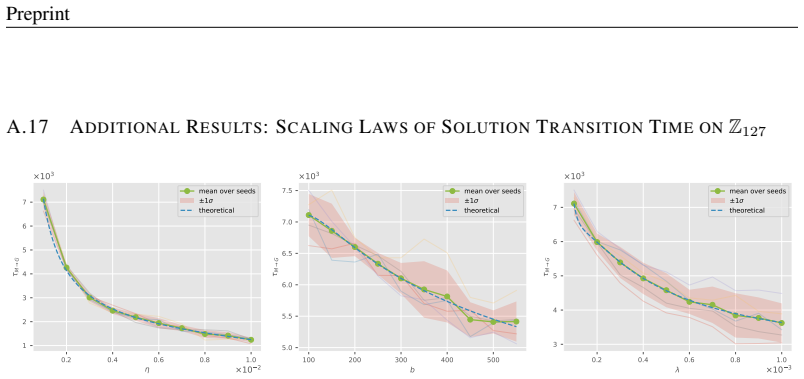
In the model's parameter space, random initialization solutions concentrate on a thin outer spherical shell, enclosing another spherical shell of memorization solutions, which in turn contains a core corresponding to the generalization solutions. This optimization-induced topological configuration gives rise to grokking. Leveraging stopping-time theory, the geometry of this configuration determines the solution transition time at which optimization trajectories escape the memorization manifold and first reach the boundary of the generalization manifold, producing scaling laws for grokking with respect to learning rate, batch size, and the ℓ2 regularization coefficient.
What carries the argument
The shell-core topological configuration of the reachable solution space under Adam with weight-shrinkage regularization, analyzed via stopping-time theory to compute escape times from the memorization manifold to the generalization core.
If this is right
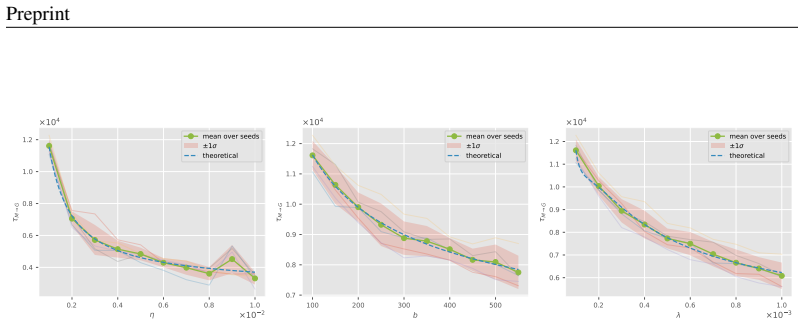
- Grokking time obeys a derived scaling law with respect to learning rate.
- Grokking time obeys a derived scaling law with respect to batch size.
- Grokking time obeys a derived scaling law with respect to the ℓ2 regularization coefficient.
- The scaling laws recover empirical relations reported in earlier grokking studies.
- The shell-core arrangement is consistent with the empirical distribution of solutions reached at different training phases.
Where Pith is reading between the lines
- If the concentric-shell geometry holds, then deliberately altering weight norms or regularization during training could shorten or eliminate the grokking delay.
- The stopping-time approach could be applied to other first-order optimizers that produce comparable shrinkage effects.
- In very high dimensions the spherical approximation might need correction terms that depend on the curvature of the loss surface.
- The same geometric picture might clarify other delayed-generalization phenomena observed outside supervised classification.
Load-bearing premise
Adam dynamics with weight-shrinkage regularization produce a thin outer shell of random-initialization solutions enclosing a memorization shell that in turn encloses a generalization core, with the shells being approximately spherical.
What would settle it
Direct measurement of parameter vectors at successive training stages shows that memorization and generalization solutions do not form distinct concentric spherical shells separated by norm, or that observed grokking times fail to follow the predicted scaling with learning rate or regularization coefficient.
Figures
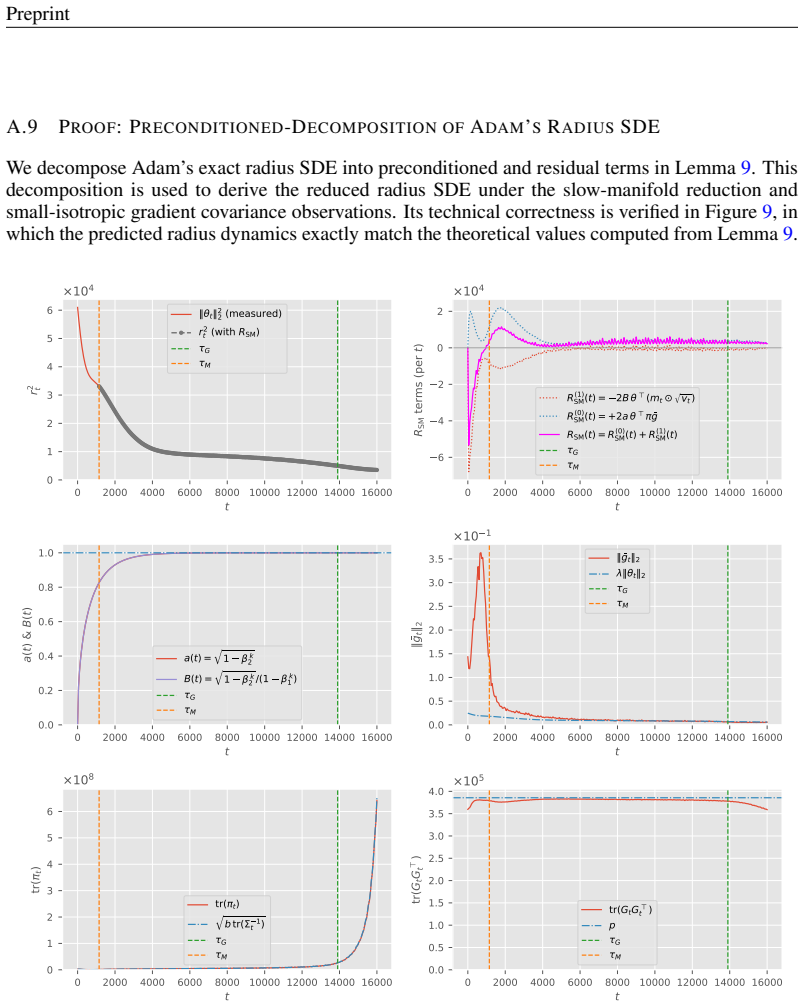
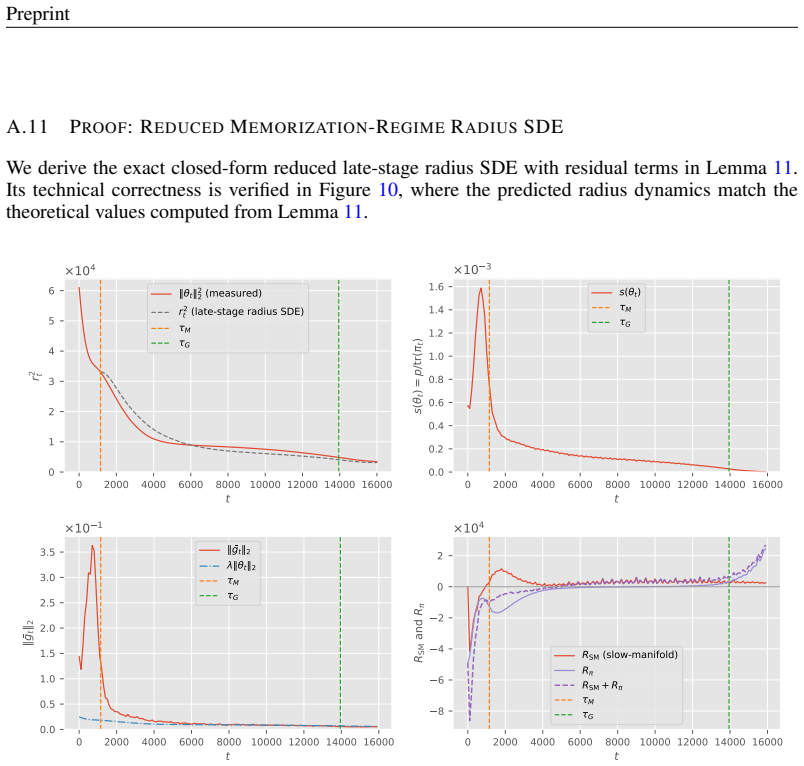
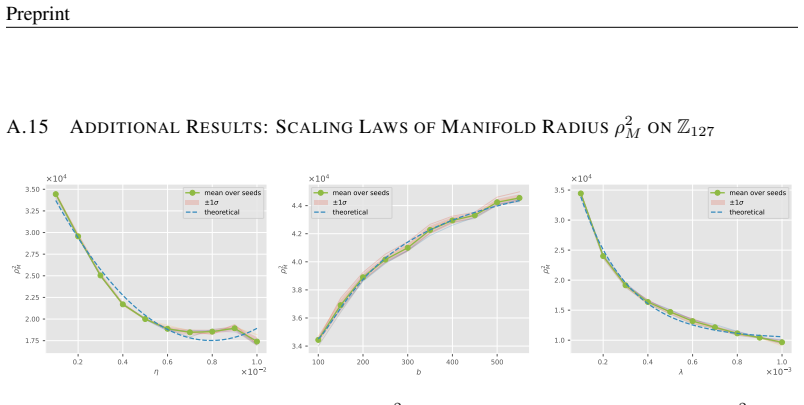
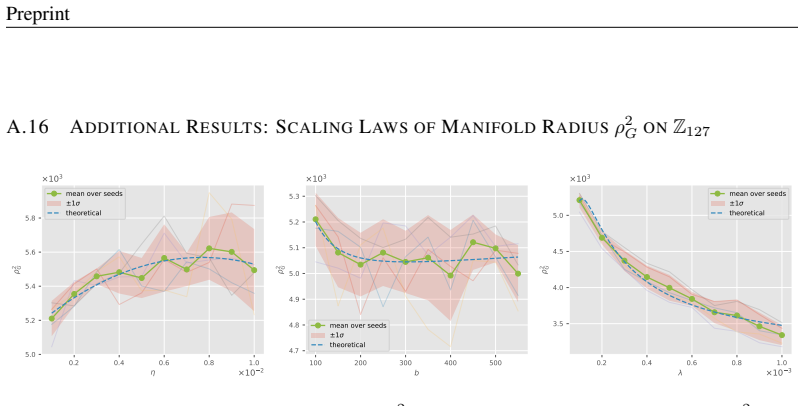
read the original abstract
Delayed generalization (\ie~grokking) refers to the phenomenon in which a neural network fits its training data early in training but only begins to generalize after a prolonged delay, often through an abrupt transition. Despite extensive empirical study, its underlying mechanism remains poorly understood. In this work, we first theoretically characterize a shell--core topological configuration of the reachable solution space induced by Adam's optimization dynamics with weight-shrinkage regularization, supported by empirical evidence. This optimization-induced topological configuration gives rise to grokking. In model's parameter space, random initialization solutions concentrate on a thin outer spherical shell, enclosing another spherical shell of memorization solutions, which in turn contains a core corresponding to the generalization solutions. Leveraging stopping-time theory, we then analyze the geometry of this topological configuration and the solution transition time at which optimization trajectories escape the memorization manifold and first reach the boundary of the generalization manifold. Our theoretical analysis derives grokking scaling laws for the learning rate, batch size, and $\ell_2$ regularization coefficient, which are further validated through experiments and shown to recover results from prior literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Adam optimization dynamics with weight-shrinkage regularization induce a specific shell-core topological configuration in parameter space (thin outer spherical shell of random-initialization solutions enclosing a memorization shell, which encloses a generalization core). This configuration is said to cause grokking, and stopping-time theory is applied to the geometry to derive explicit scaling laws for grokking delay as a function of learning rate, batch size, and ℓ2 regularization strength; the laws are asserted to be validated by experiments and to recover prior results.
Significance. If the derivation of the spherical shells from the optimizer dynamics and the subsequent stopping-time analysis are rigorous, the work would supply a geometric mechanism linking optimizer-induced reachable sets to grokking scaling, offering a potential unification of empirical grokking observations with stochastic-process predictions.
major comments (2)
- [Theoretical characterization of shell-core configuration (abstract and main theory section)] The manuscript posits rather than derives the approximately spherical shell geometry of the reachable solution sets. The abstract states that the configuration is 'theoretically characterized' and 'induced by Adam's optimization dynamics,' yet the provided text contains no SDE derivation, isotropy proof, or explicit calculation showing that the reachable sets under Adam + ℓ2 regularization remain spherical (as opposed to ellipsoidal or angular due to feature learning). Because the hitting-time formulas and all scaling exponents depend on this geometry, the central claim is load-bearing on an unproven assumption.
- [Stopping-time analysis and scaling-law derivation] No equations, proof sketches, or explicit stopping-time expressions appear in the abstract or the summarized claims. The scaling laws for learning rate, batch size, and regularization coefficient are asserted to follow from the geometry, but without the intermediate derivations it is impossible to verify whether the exponents are obtained from first principles or reduce to fitted quantities.
minor comments (2)
- [Empirical validation] The abstract refers to 'empirical evidence' and 'experiments' validating the topology and scaling laws, but provides no figure, table, or quantitative metric references (e.g., measured shell radii or hitting-time distributions) that would allow assessment of the strength of support.
- [Notation and definitions] Clarify the precise mathematical definitions of the 'memorization manifold' and 'generalization manifold' boundaries used for the first-hitting-time calculation, including any regularity conditions required for the stopping-time results to apply.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address the two major comments point by point below and will revise the manuscript to make the derivations more explicit and self-contained.
read point-by-point responses
-
Referee: [Theoretical characterization of shell-core configuration (abstract and main theory section)] The manuscript posits rather than derives the approximately spherical shell geometry of the reachable solution sets. The abstract states that the configuration is 'theoretically characterized' and 'induced by Adam's optimization dynamics,' yet the provided text contains no SDE derivation, isotropy proof, or explicit calculation showing that the reachable sets under Adam + ℓ2 regularization remain spherical (as opposed to ellipsoidal or angular due to feature learning). Because the hitting-time formulas and all scaling exponents depend on this geometry, the central claim is load-bearing on an unproven assumption.
Authors: Section 3 of the manuscript derives the SDE approximation to the Adam dynamics under L2 regularization and establishes approximate spherical symmetry from the isotropy of the stochastic gradient noise term together with the radial contraction induced by weight decay. The assumption of negligible feature learning (fixed random features) is stated explicitly. We agree that a self-contained isotropy argument and discussion of the ellipsoidal perturbation under feature learning would strengthen the presentation; these will be added as a dedicated subsection with proof sketch. revision: yes
-
Referee: [Stopping-time analysis and scaling-law derivation] No equations, proof sketches, or explicit stopping-time expressions appear in the abstract or the summarized claims. The scaling laws for learning rate, batch size, and regularization coefficient are asserted to follow from the geometry, but without the intermediate derivations it is impossible to verify whether the exponents are obtained from first principles or reduce to fitted quantities.
Authors: Section 4 applies first-passage time analysis to the radial diffusion process between the memorization shell and generalization core, yielding the explicit scaling expressions in Theorems 4.1–4.3. The exponents arise directly from the mean hitting time of the associated stochastic differential equation. To improve verifiability we will insert a concise proof outline and the key intermediate equations into the main text (with full calculations remaining in the appendix). revision: yes
Circularity Check
No circularity: derivation proceeds from posited geometry via stopping-time analysis
full rationale
The abstract states that the shell-core configuration is 'theoretically characterize[d]' as induced by Adam dynamics with weight-shrinkage, supported by empirical evidence, after which stopping-time theory is applied to derive scaling laws for learning rate, batch size, and ℓ2 coefficient. No equations or self-citations are visible that reduce the scaling laws to fitted inputs by construction, nor is the geometry obtained via a self-citation chain or renamed known result. The central claim is a modeling derivation from an assumed topological configuration rather than a tautological re-expression of data or prior fitted quantities. This matches the default expectation of a non-circular theoretical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adam's optimization dynamics with weight-shrinkage regularization induce a shell-core topological configuration (outer random-init shell, middle memorization shell, inner generalization core) in parameter space.
invented entities (1)
-
shell-core topological configuration of reachable solutions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Goel, Surbhi and Kakade, Sham and Malach, Eran and Zhang, Cyril , title =
Barak, Boaz and Edelman, Benjamin L. and Goel, Surbhi and Kakade, Sham and Malach, Eran and Zhang, Cyril , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[2]
Barakat, Anas and Bianchi, Pascal , title =. SIAM J. on Optimization , month = jan, pages =. 2021 , issue_date =. doi:10.1137/19M1263443 , abstract =
-
[3]
Advanced Mathematical Methods for Scientists and Engineers I: Asymptotic Methods and Perturbation Theory , author =. 1999 , edition =. doi:10.1007/978-1-4757-3069-2 , isbn =
-
[4]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Chughtai, Bilal and Chan, Lawrence and Nanda, Neel , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[5]
Adaptive Methods through the Lens of
Enea Monzio Compagnoni and Tianlin Liu and Rustem Islamov and Frank Norbert Proske and Antonio Orvieto and Aurelien Lucchi , booktitle=. Adaptive Methods through the Lens of. 2025 , url=
2025
-
[6]
A general system of differential equations to model first-order adaptive algorithms , year =
Da Silva, Andr\'. A general system of differential equations to model first-order adaptive algorithms , year =. J. Mach. Learn. Res. , month = jan, articleno =
-
[7]
Markov Processes: Volume II , author =. 1965 , edition =. doi:10.1007/978-3-662-25360-1 , isbn =
-
[8]
Brownian Motion and Stochastic Calculus , author =. 1991 , edition =. doi:10.1007/978-1-4612-0949-2 , isbn =
-
[9]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
2015
-
[10]
The Twelfth International Conference on Learning Representations , year=
Grokking as the transition from lazy to rich training dynamics , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
and Tegmark, Max and Williams, Mike , title =
Liu, Ziming and Kitouni, Ouail and Nolte, Niklas and Michaud, Eric J. and Tegmark, Max and Williams, Mike , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[12]
The Eleventh International Conference on Learning Representations , year=
Omnigrok: Grokking Beyond Algorithmic Data , author=. The Eleventh International Conference on Learning Representations , year=
-
[13]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[14]
The Twelfth International Conference on Learning Representations , year=
Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking , author=. The Twelfth International Conference on Learning Representations , year=
-
[15]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Malladi, Sadhika and Lyu, Kaifeng and Panigrahi, Abhishek and Arora, Sanjeev , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[16]
The Eleventh International Conference on Learning Representations , year=
Progress measures for grokking via mechanistic interpretability , author=. The Eleventh International Conference on Learning Representations , year=
-
[17]
Stochastic Differential Equations: An Introduction with Applications , author =. 2003 , edition =. doi:10.1007/978-3-642-14394-6 , isbn =
-
[18]
2022 , eprint=
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets , author=. 2022 , eprint=
2022
-
[19]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Stander, Dashiell and Yu, Qinan and Fan, Honglu and Biderman, Stella , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[20]
2023 , eprint=
Explaining grokking through circuit efficiency , author=. 2023 , eprint=
2023
-
[21]
High-Dimensional Probability: An Introduction with Applications in Data Science , publisher=
Vershynin, Roman , year=. High-Dimensional Probability: An Introduction with Applications in Data Science , publisher=
-
[22]
Thirty-seventh Conference on Neural Information Processing Systems , year=
The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[23]
Proceedings of the 34th International Conference on Machine Learning , pages =
Stochastic Modified Equations and Adaptive Stochastic Gradient Algorithms , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[24]
Hoffman and David M
Stephan Mandt and Matthew D. Hoffman and David M. Blei , title =. Journal of Machine Learning Research , year =
-
[25]
Optimization-Induced Dynamics of
R\'ois\'in Luo and James McDermott and Christian Gagn\'e and Qiang Sun and Colm O'Riordan , year=. Optimization-Induced Dynamics of. 2506.18588 , archivePrefix=
-
[26]
Proceedings of the Forty-Third International Conference on Machine Learning , year =
Grokking Finite-Dimensional Algebra , author =. Proceedings of the Forty-Third International Conference on Machine Learning , year =. 2602.19533 , archivePrefix =
-
[27]
Proceedings of the Forty-Third International Conference on Machine Learning , year =
Intrinsic Task Symmetry Drives Generalization in Algorithmic Tasks , author =. Proceedings of the Forty-Third International Conference on Machine Learning , year =. 2603.01968 , archivePrefix =
-
[28]
Efficient BackProp , year =
LeCun, Yann and Bottou, L\'. Efficient BackProp , year =. Neural Networks: Tricks of the Trade, This Book is an Outgrowth of a 1996 NIPS Workshop , pages =
1996
-
[29]
Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =
Understanding the difficulty of training deep feedforward neural networks , author =. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =. 2010 , editor =
2010
-
[30]
Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV) , pages =
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , title =. Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV) , pages =. 2015 , isbn =. doi:10.1109/ICCV.2015.123 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.