Experience Augmented Policy Optimization for LLM Reasoning
Pith reviewed 2026-06-30 06:50 UTC · model grok-4.3
The pith
EAPO improves LLM reasoning by selectively injecting experience from a prior policy at critical rollout points with adapted importance sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By using a prior RL-optimized policy as an action-level experience prior and selectively injecting that experience at critical decision points during rollout together with an adapted importance sampling scheme, EAPO achieves more efficient use of accumulated experience in RLVR and produces stable policy updates that improve LLM reasoning performance.
What carries the argument
The experience-augmented rollout that selectively inserts action-level experience from a prior policy at critical decision points, combined with adapted importance sampling to preserve unbiased updates.
If this is right
- Sampling costs fall because experience is reused instead of regenerating everything from scratch on every update.
- Policy mismatch is avoided because experience is expressed in a policy-adaptive form rather than as fixed trajectories.
- Learning remains stable because the adapted importance sampling keeps updates unbiased.
- Reasoning accuracy rises consistently on math and related benchmarks for the tested model sizes.
- The same mechanism can be applied to other base models beyond the two Qwen variants evaluated.
Where Pith is reading between the lines
- The selective-injection idea could be tested in non-LLM sequential tasks where policies also evolve during training.
- If the critical-point detection proves robust, it might reduce the frequency of full policy retraining when capabilities shift.
- Applying EAPO to much larger models would test whether the efficiency gains scale with parameter count.
- Combining the adaptive prior with other variance-reduction techniques might produce further sample-efficiency improvements.
Load-bearing premise
That selectively injecting prior-policy experience at chosen points during rollout plus the adapted importance sampling correction together produce stable updates without introducing new mismatch or bias.
What would settle it
Reproducing the five-benchmark experiments with the same Qwen models and finding that EAPO yields no improvement or a drop relative to the baseline RLVR methods would falsify the performance claim.
Figures
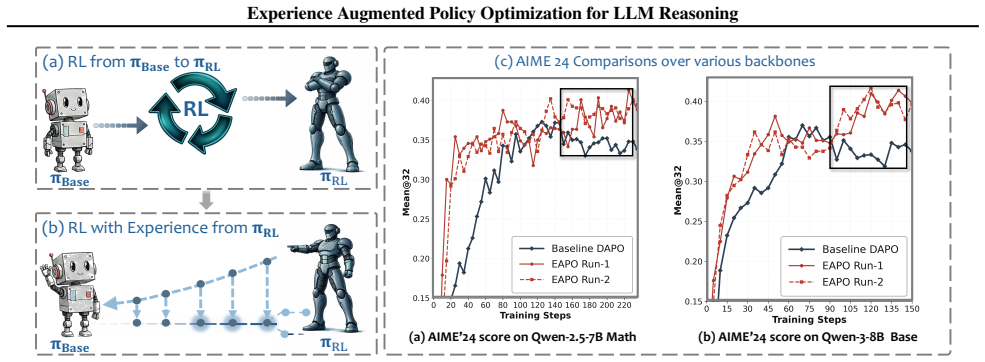
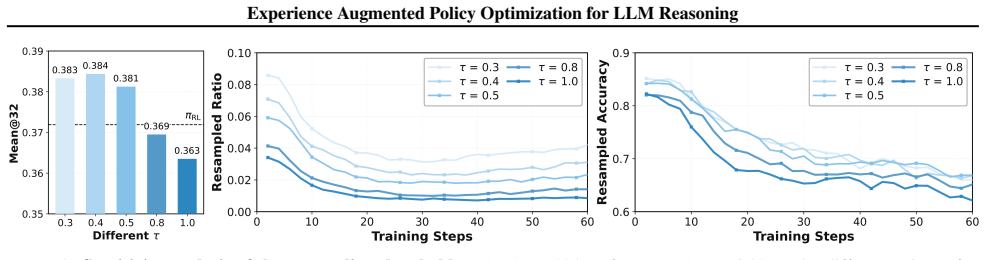
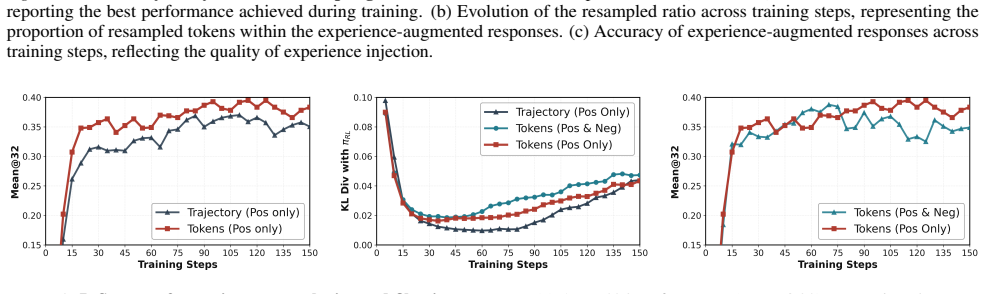
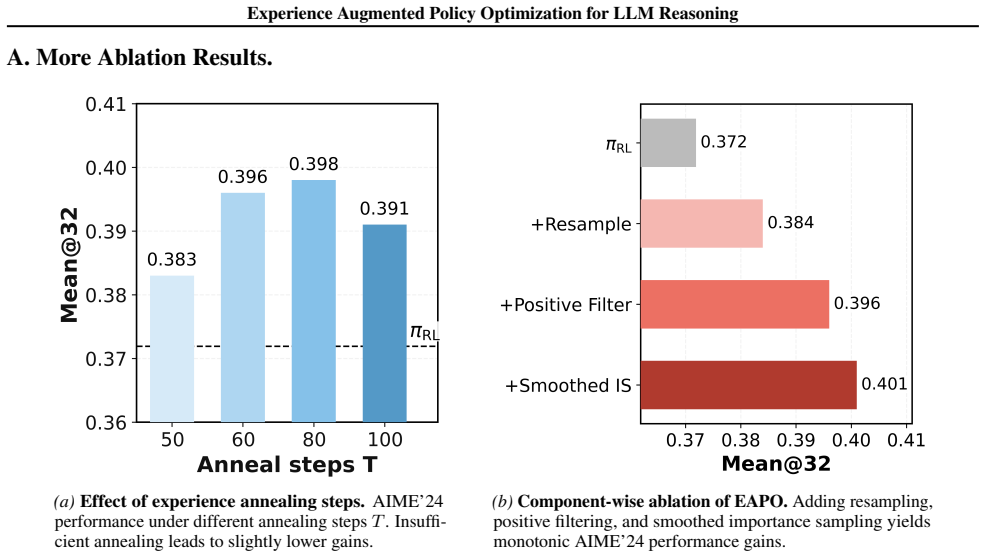
read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) is a powerful paradigm for improving the reasoning capabilities of large language models (LLMs). However, existing RLVR methods typically rely on on-policy optimization from scratch, resulting in high sampling costs and inefficient utilization of accumulated experience. As model capabilities and policy behaviors evolve during training, recent attempts to reuse experience via fixed reasoning trajectories further suffer from policy mismatch. Motivated by these limitations, we argue that experience in RLVR should not be reused as fixed reasoning trajectories, but instead expressed in a policy-adaptive manner. In this work, we propose Experience-Augmented Policy Optimization (EAPO), which leverages a prior RL-optimized policy as an action-level experience prior and selectively injects experience at critical decision points during rollout. To ensure stable and unbiased learning from experience-augmented rollouts, EAPO further incorporates an adapted importance sampling scheme. Experiments on using Qwen-2.5-math 7b and Qwen-3-8B on five different benchmarks demonstrate that EAPO consistently improves reasoning performance over state-of-the-art RLVR methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Experience-Augmented Policy Optimization (EAPO) for RLVR-based LLM reasoning. It critiques on-policy-from-scratch methods for high sampling cost and fixed-trajectory reuse for policy mismatch, instead using a prior RL-optimized policy to selectively inject actions at critical decision points during rollout, combined with an adapted importance-sampling correction claimed to yield stable, unbiased updates. Experiments with Qwen-2.5-math 7B and Qwen-3-8B on five benchmarks report consistent gains over SOTA RLVR baselines.
Significance. If the adapted importance sampling provably removes bias under selective injection, EAPO would address a genuine inefficiency in experience reuse for RLVR and could reduce sampling costs while improving reasoning performance. The multi-model, multi-benchmark empirical results would then constitute a practically relevant advance, provided the gains are not artifacts of uncorrected bias.
major comments (2)
- [Abstract, §3] Abstract and §3 (method): the central claim that the adapted importance sampling 'ensures stable and unbiased learning from experience-augmented rollouts' is load-bearing for all reported gains, yet no derivation, bias analysis, or verification is supplied showing that the correction re-weights both the selective-injection probability and the policy shift at the chosen decision points. Without this, the effective objective may remain biased and the performance improvements cannot be attributed to experience augmentation.
- [§4] §4 (experiments): the reported consistent improvements over SOTA RLVR methods on five benchmarks rest on the assumption that the EAPO updates are unbiased; if the importance-sampling adaptation fails under selective injection, the cross-method comparison is confounded and the empirical claim is undermined.
minor comments (2)
- [§3] Notation for the 'critical decision points' and the exact form of the adapted importance weights should be defined explicitly with equations rather than prose descriptions.
- [Abstract, §1] The abstract and introduction should cite the specific prior RLVR works whose fixed-trajectory reuse is being critiqued.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which correctly identify that the unbiasedness of the adapted importance sampling is central to our claims. We address each major comment below and commit to revisions that supply the requested analysis.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the central claim that the adapted importance sampling 'ensures stable and unbiased learning from experience-augmented rollouts' is load-bearing for all reported gains, yet no derivation, bias analysis, or verification is supplied showing that the correction re-weights both the selective-injection probability and the policy shift at the chosen decision points. Without this, the effective objective may remain biased and the performance improvements cannot be attributed to experience augmentation.
Authors: We agree that the manuscript lacks an explicit derivation and bias analysis for the adapted importance sampling under selective injection. The current text describes the scheme but does not derive how the weights correct for both injection probability and policy shift. In the revision we will add a formal derivation and bias analysis to §3, together with a verification on a controlled toy problem, to establish that the objective remains unbiased. revision: yes
-
Referee: [§4] §4 (experiments): the reported consistent improvements over SOTA RLVR methods on five benchmarks rest on the assumption that the EAPO updates are unbiased; if the importance-sampling adaptation fails under selective injection, the cross-method comparison is confounded and the empirical claim is undermined.
Authors: The empirical comparisons do rest on the unbiasedness of the updates. By incorporating the derivation and verification described above, we will substantiate this assumption in the revised manuscript. We will also update the discussion in §4 to explicitly link the reported gains to the corrected objective and to note the supporting analysis. revision: yes
Circularity Check
No circularity: empirical gains rest on external benchmarks, not self-defined quantities
full rationale
The provided abstract and description contain no equations, derivations, or self-citations that reduce the claimed performance improvements to quantities defined only by the authors' own fitted parameters or prior work. EAPO is presented as a methodological extension of existing RLVR with selective injection and adapted importance sampling, with gains asserted via experiments on five benchmarks using Qwen models. No load-bearing step equates a 'prediction' to its input by construction, and the central claim remains externally falsifiable against standard RLVR baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accelerating Large Language Model Decoding with Speculative Sampling
Chen, C., Borgeaud, S., Irving, G., Lespiau, J.-B., Sifre, L., and Jumper, J. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Reasoning with Exploration: An Entropy Perspective
Cheng, D., Huang, S., Zhu, X., Dai, B., Zhao, W. X., Zhang, Z., and Wei, F. Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://openreview.net/forum ?id=r6Pw3RiMYL. Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Leviathan, Y ., Kalman, M., and Matias, Y
URL https://arxiv.org/ abs/2510.04140. Leviathan, Y ., Kalman, M., and Matias, Y . Fast inference from transformers via speculative decoding. InInter- national Conference on Machine Learning, pp. 19274– 19286. PMLR,
-
[6]
Li, S., Zhou, Z., Lam, W., Yang, C., and Lu, C
URL https://openreview.net/forum?id= jyOgpu5wfC. Li, S., Zhou, Z., Lam, W., Yang, C., and Lu, C. Repo: Replay-enhanced policy optimization.arXiv preprint arXiv:2506.09340, 2025b. Liang, J., Tang, H., Ma, Y ., Liu, J., Zheng, Y ., Hu, S., Bai, L., and Hao, J. Squeeze the soaked sponge: Efficient off-policy reinforcement finetuning for large language model....
-
[7]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al. Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Rethinking visual content refinement in low-shot clip adaptation.arXiv preprint arXiv:2407.14117,
Lu, J., Wang, S., Hao, Y ., Liu, H., Wang, X., and Wang, M. Rethinking visual content refinement in low-shot clip adaptation.arXiv preprint arXiv:2407.14117,
-
[9]
Adavip: Aligning multi-modal llms via adaptive vision- enhanced preference optimization, 2025a
Lu, J., Li, J., Gao, Y ., Wu, J., Wu, J., Wang, X., and He, X. Adavip: Aligning multi-modal llms via adaptive vision- enhanced preference optimization, 2025a. URL https: //arxiv.org/abs/2504.15619. Lu, J., Wu, J., Li, J., Jia, X., Wang, S., Zhang, Y ., Fang, J., Wang, X., and He, X. Dama: Data-and model-aware alignment of multi-modal llms. InInternational...
-
[10]
https://thinkingmachines.ai/blog/on-policy- distillation
doi: 10.64434/tml .20251026. https://thinkingmachines.ai/blog/on-policy- distillation. Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y ., Dirani, J., Michael, J., and Bowman, S. R. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling,
-
[11]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Kimi K2: Open Agentic Intelligence
Team, K., Bai, Y ., Bao, Y ., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y ., Chen, Y ., Chen, Y ., et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Wang, S., Yu, L., Gao, C., Zheng, C., Liu, S., Lu, R., Dang, K., Chen, X., Yang, J., Zhang, Z., et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Quantile advantage estimation for entropy-safe reasoning
Wu, J., Huang, K., Wu, J., Zhang, A., Wang, X., and He, X. Quantile advantage estimation for entropy-safe reasoning. arXiv preprint arXiv:2509.22611,
-
[16]
URL ht tps://openreview.net/forum?id=vO8LLo NWWk. Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024a. Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., et al. Qwen2. 5-math techni- cal report: Toward...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Zhan, R., Li, Y ., Wang, Z., Qu, X., Liu, D., Shao, J., Wong, D. F., and Cheng, Y . Exgrpo: Learning to reason from experience.arXiv preprint arXiv:2510.02245,
-
[19]
Jixiao Zhang and Chunsheng Zuo
Zhang, H., Fu, J., Zhang, J., Fu, K., Wang, Q., Zhang, F., and Zhou, G. Rlep: Reinforcement learning with experience replay for llm reasoning.arXiv preprint arXiv:2507.07451, 2025a. Zhang, K., Chen, X., Liu, B., Xue, T., Liao, Z., Liu, Z., Wang, X., Ning, Y ., Chen, Z., Fu, X., et al. Agent learning via early experience.arXiv preprint arXiv:2510.08558, 20...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.