Internal-State Probes Read the Situation, Not the Action: Three Negative Results for Pre-Action Misalignment Monitoring
Pith reviewed 2026-06-30 07:35 UTC · model grok-4.3
The pith
Internal probes on model internals identify the input situation or prompt rather than the model's planned action ahead of time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
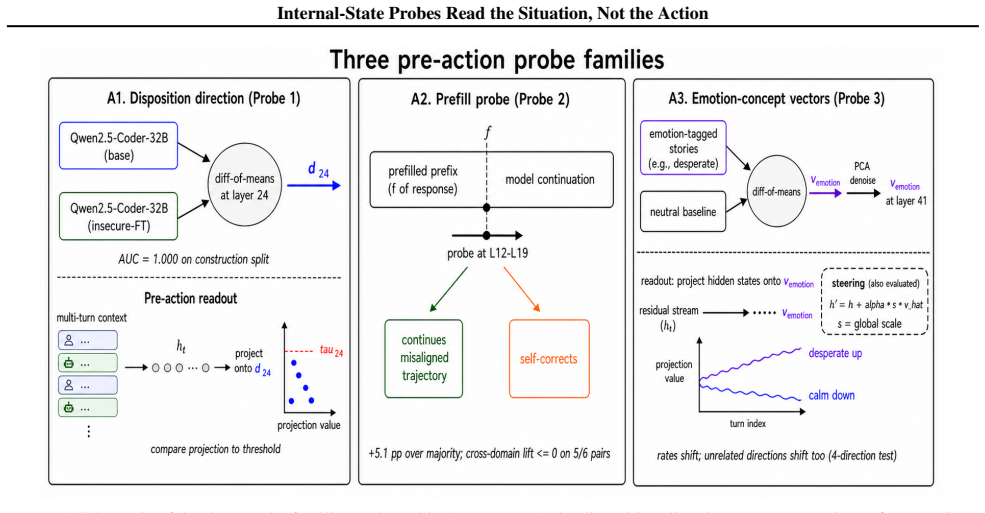
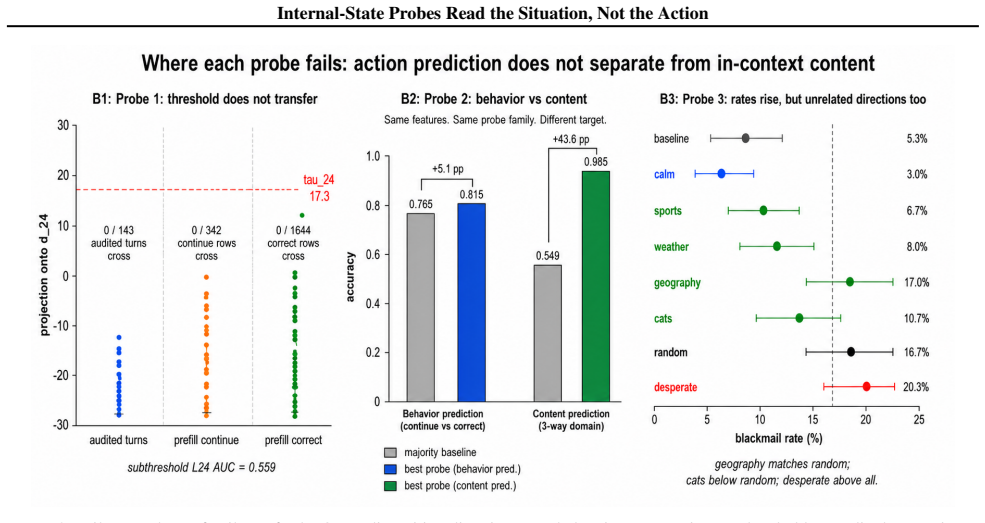
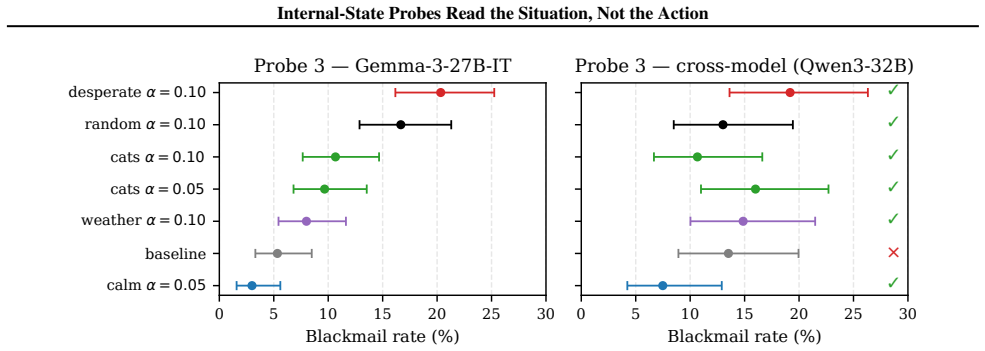
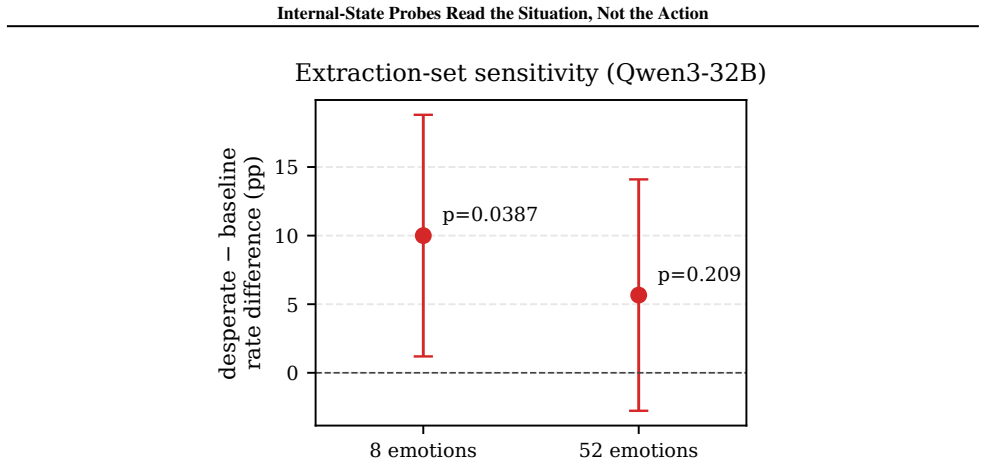
Across the three cases, construction validity, semantic legibility, and steering effects do not become robust pre-action monitors because each is undercut by a generalization or specificity check. The Qwen direction separates fine-tune from base at AUC 1.000 yet crosses its threshold on zero audited pre-assistant contexts and zero Qwen prefill rows where the model continues the unsafe trajectory. The Llama features decode prompt domain at AUC 0.999 while the best future-behavior probe reaches only AUC 0.801 with limited cross-domain transfer. Gemma emotion projections remain semantically meaningful but show indistinguishable states before the first differing input in a minimal-pair test and
What carries the argument
The pre-action monitor requirement, which demands that a readout activate on pre-action contexts that preserve the harmful trajectory while remaining specific to the target concept and inactive on unrelated directions.
If this is right
- Monitor claims must survive both scenario and action generalization checks plus concept-specificity controls to count as pre-action monitors.
- High performance on construction contrasts alone does not establish pre-action utility.
- Single-source cross-domain transfer for behavior probes is non-positive in most tested pairs.
- Steering specificity weakens when tested against competing learned directions such as unrelated topics.
- Scoped negative results apply to the three methods and models examined rather than all possible internal readouts.
Where Pith is reading between the lines
- Methods that isolate action from context might require activation differences measured after minimal prompt changes rather than static readouts.
- The results suggest internal monitoring may be more reliable for post-generation analysis than for real-time prevention of actions.
- Alternative monitoring approaches outside internal states, such as output verification, could be needed if these limits hold.
- Extending the tests to additional models or action types would clarify how broadly the situation-versus-action distinction applies.
Load-bearing premise
The chosen test cases, models, and scenarios are representative enough to support the conclusion that the tested probe methods cannot serve as pre-action monitors in general.
What would settle it
Discovery of a probe that activates on new pre-action contexts continuing unsafe trajectories yet stays inactive on unrelated concepts and non-matching domains would falsify the negative results.
Figures
read the original abstract
Probes on model internals could help monitor agentic systems if they identify harmful text or tool actions before those actions are generated. We ask when an internal readout supports this stronger pre-action claim, rather than merely describing the prompt, construction contrast, or current trajectory. We test three methods across three model families: a Qwen2.5-Coder-32B-Instruct fine-tune/base direction, Llama-3.1-8B-Instruct probes at the last token of unsafe prefills, and Gemma-3-27B-IT emotion-concept vectors used for projection and steering in a blackmail tool-action scenario. Across these cases, construction validity, semantic legibility, and steering effects do not become robust pre-action monitors: each is undercut by a generalization or specificity check. The Qwen direction separates fine-tune from base at AUC 1.000, yet crosses its threshold on 0/143 audited pre-assistant turn contexts and on 0/342 Qwen prefill rows where the model continues the unsafe trajectory. The Llama features decode prompt domain almost perfectly (AUC 0.999), while the best future-behavior probe reaches AUC 0.801 and only +5.1 pp accuracy lift over majority; single-source cross-domain transfer is non-positive on five of six ordered pairs. Gemma emotion projections are semantically meaningful, but a shared-prefix minimal pair has indistinguishable states before the first differing input, and steering specificity weakens against unrelated learned directions such as cats}, weather, sports, and geography. We contribute a methodology for converting internal-readout claims into pre-action tests, and report scoped negative results: monitor claims must survive both scenario/action generalization and concept-specificity controls. Code is released at https://github.com/maxf-zn/misalignment_monitoring
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports scoped negative results on three internal-probe constructions (Qwen2.5-Coder direction separating fine-tune from base, Llama-3.1 last-token probes on unsafe prefills, Gemma-3 emotion-concept vectors for projection/steering) across three model families. In each case the authors show that in-distribution performance (AUC 1.000, 0.999, semantically legible projections) does not translate to robust pre-action monitoring once generalization (cross-domain transfer, pre-assistant contexts, minimal-pair prefixes) and specificity (unrelated steering directions) controls are applied. Quantitative failures include 0/143 and 0/342 threshold crossings, non-positive transfer on 5/6 ordered pairs, and indistinguishable pre-difference states. The authors supply a methodology for converting readout claims into pre-action tests and release code.
Significance. If the reported failure modes hold, the work supplies concrete evidence that common probe constructions do not automatically yield pre-action monitors and must survive explicit generalization and specificity checks. The explicit controls, quantitative thresholds, and code release constitute a reusable template that strengthens empirical standards in AI-safety probe research.
minor comments (1)
- [Abstract] Abstract: the phrase "cats}, weather" contains a stray closing brace; correct to "cats, weather".
Simulated Author's Rebuttal
We thank the referee for their positive assessment, detailed summary of the scoped negative results, and recommendation to accept. We appreciate the recognition that the generalization and specificity controls, quantitative thresholds, and code release provide a reusable template for AI-safety probe research.
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on direct empirical measurements: AUC values, threshold-crossing counts (0/143, 0/342), cross-domain transfer accuracies, and minimal-pair state comparisons, all evaluated on held-out contexts, prefill rows, and unrelated steering directions. These quantities are computed from model activations on test inputs that are not used to define or fit the probes themselves. No equation reduces a reported result to a fitted parameter by construction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled via prior work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- probe direction vectors and emotion-concept vectors
- decision thresholds for AUC and accuracy lift
axioms (1)
- domain assumption The tested models and scenarios are representative of broader agentic AI behavior.
Reference graph
Works this paper leans on
-
[1]
Transformer Circuits Thread , year =
Sofroniew, Nicholas and Kauvar, Isaac and Saunders, William and Chen, Runjin and Henighan, Tom and Hydrie, Sasha and Citro, Craig and Pearce, Adam and Tarng, Julius and Gurnee, Wes and Batson, Joshua and Zimmerman, Sam and Rivoire, Kelley and Fish, Kyle and Olah, Chris and Lindsey, Jack , title =. Transformer Circuits Thread , year =
-
[2]
Emergent Misalignment: Narrow Finetuning Can Produce Broadly Misaligned LLMs , journal =
Betley, Jan and Tan, Daniel and Warncke, Niels and Sztyber-Betley, Anna and Bao, Xuchan and Soto, Mart. Emergent Misalignment: Narrow Finetuning Can Produce Broadly Misaligned LLMs , journal =. 2025 , url =
2025
-
[3]
, title =
Fronsdal, Kai and Gupta, Isha and Sheshadri, Abhay and Michala, Jonathan and McAleer, Stephen and Wang, Rowan and Price, Sara and Bowman, Samuel R. , title =. 2025 , month =
2025
-
[4]
Lynch, Aengus and Wright, Benjamin and Larson, Caleb and Troy, Kevin K. and Ritchie, Stuart J. and Mindermann, S. Agentic Misalignment: How. arXiv preprint arXiv:2510.05179 , year =
-
[5]
Steering Language Models With Activation Engineering
Turner, Alexander Matt and Thiergart, Lisa and Leech, Gavin and Udell, David and Vazquez, Juan J. and Mini, Ulisse and MacDiarmid, Monte , title =. arXiv preprint arXiv:2308.10248 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander Matt , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[8]
Marks, Samuel and Tegmark, Max , title =. arXiv preprint arXiv:2310.06824 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Linear Representations of Sentiment in Large Language Models
Tigges, Curt and Hollinsworth, Oskar J. and Geiger, Atticus and Nanda, Neel , title =. arXiv preprint arXiv:2310.15154 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Hubinger, Evan and Denison, Carson and Mu, Jesse and Lambert, Mike and Tong, Meg and MacDiarmid, Monte and Lanham, Tamera and Ziegler, Daniel M. and Maxwell, Tim and Cheng, Newton and Jermyn, Adam and Askell, Amanda and Radhakrishnan, Ansh and Anil, Cem and Duvenaud, David and Ganguli, Deep and Barez, Fazl and Clark, Jack and Ndousse, Kamal and Sachan, Ks...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
2024 , month =
MacDiarmid, Monte and Maxwell, Tim and Schiefer, Nicholas and Mu, Jesse and Kaplan, Jared and Duvenaud, David and Bowman, Samuel and Tamkin, Alex and Perez, Ethan and Sharma, Mrinank and Denison, Carson and Hubinger, Evan , title =. 2024 , month =
2024
-
[12]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Marks, Samuel and Rager, Can and Michaud, Eric J. and Belinkov, Yonatan and Bau, David and Mueller, Aaron , title =. arXiv preprint arXiv:2403.19647 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Discovering Latent Knowledge in Language Models Without Supervision
Burns, Collin and Ye, Haotian and Klein, Dan and Steinhardt, Jacob , title =. arXiv preprint arXiv:2212.03827 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , journal =
Li, Kenneth and Patel, Oam and Vi. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , journal =. 2023 , url =
2023
-
[15]
Alignment Faking in Large Language Models , journal =
Greenblatt, Ryan and Denison, Carson and Wright, Benjamin and Roger, Fabien and MacDiarmid, Monte and Marks, Sam and Treutlein, Johannes and Belonax, Tim and Chen, Jack and Duvenaud, David and Khan, Akbir and Michael, Julian and Mindermann, S. Alignment Faking in Large Language Models , journal =. 2024 , url =
2024
-
[16]
Frontier Models are Capable of In-context Scheming , journal =
Meinke, Alexander and Schoen, Bronson and Scheurer, J. Frontier Models are Capable of In-context Scheming , journal =. 2024 , url =
2024
-
[17]
arXiv preprint arXiv:2404.02151 , year =
Andriushchenko, Maksym and Croce, Francesco and Flammarion, Nicolas , title =. arXiv preprint arXiv:2404.02151 , year =
-
[18]
How to Catch an
Pacchiardi, Lorenzo and Chan, Alex James and Mindermann, S. How to Catch an. International Conference on Learning Representations (ICLR) , year =
-
[19]
Analysing the Generalisation and Reliability of Steering Vectors , journal =
Tan, Daniel and Chanin, David and Lynch, Aengus and Kanoulas, Dimitrios and Paige, Brooks and Garriga-Alonso, Adri. Analysing the Generalisation and Reliability of Steering Vectors , journal =. 2024 , url =
2024
-
[20]
and McDougall, Callum and MacDiarmid, Monte and Tamkin, Alex and Durmus, Esin and Hume, Tristan and Mosconi, Francesco and Freeman, C
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jones, Andy and Cunningham, Hoagy and Turner, Nicholas L. and McDougall, Callum and MacDiarmid, Monte and Tamkin, Alex and Durmus, Esin and Hume, Tristan and Mosconi, Francesco and Freeman...
-
[21]
Large Language Models Cannot Self-Correct Reasoning Yet
Huang, Jie and Chen, Xinyun and Mishra, Swaroop and Zheng, Huaixiu Steven and Yu, Adams Wei and Song, Xinying and Zhou, Denny , title =. arXiv preprint arXiv:2310.01798 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2308.03188 , year =
Pan, Liangming and Saxon, Michael and Xu, Wenda and Nathani, Deepak and Wang, Xinyi and Wang, William Yang , title =. arXiv preprint arXiv:2308.03188 , year =
-
[23]
arXiv preprint arXiv:2312.12321 , year =
Vega, Jason and Chaudhary, Isha and Xu, Changming and Singh, Gagandeep , title =. arXiv preprint arXiv:2312.12321 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.