Self-Evolving World Models for LLM Agent Planning
Pith reviewed 2026-06-30 05:46 UTC · model grok-4.3
The pith
A self-evolving world model revises its deployment-time context through memory modules to raise prediction accuracy and LLM agent planning success without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
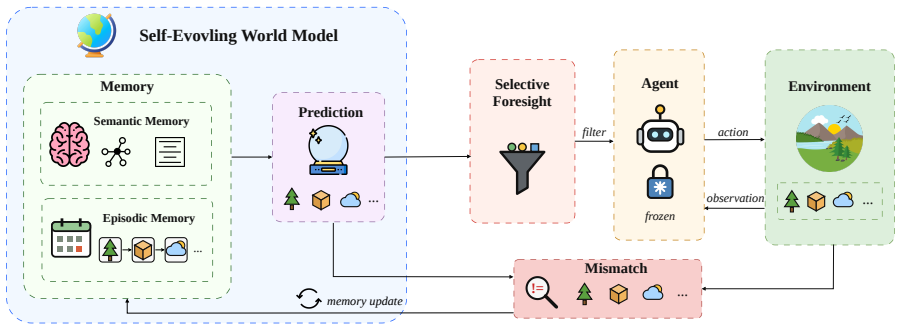
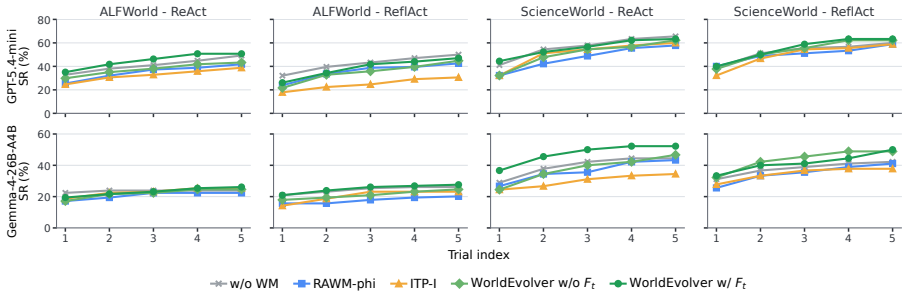
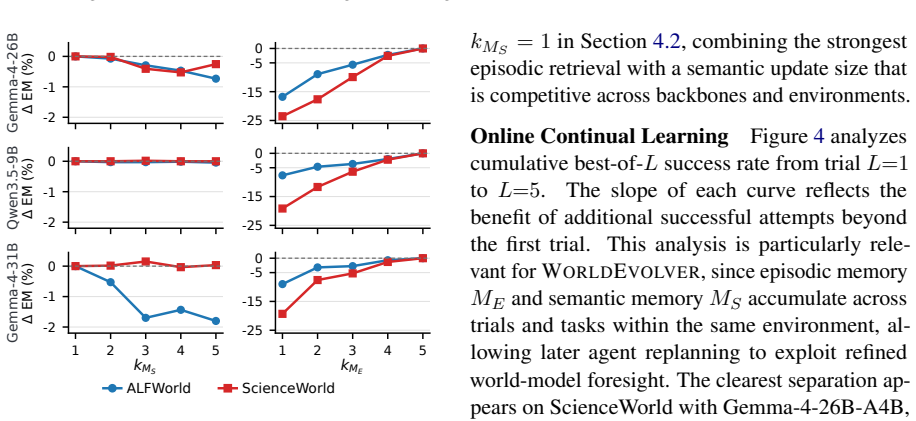
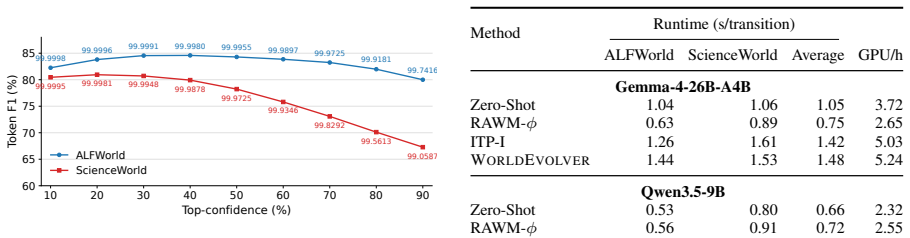
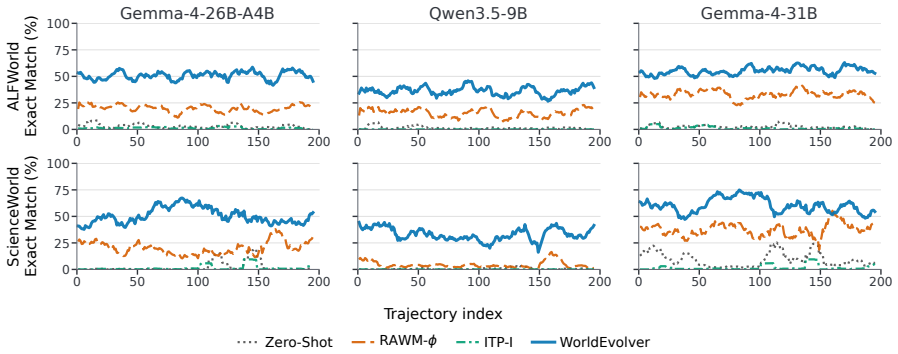
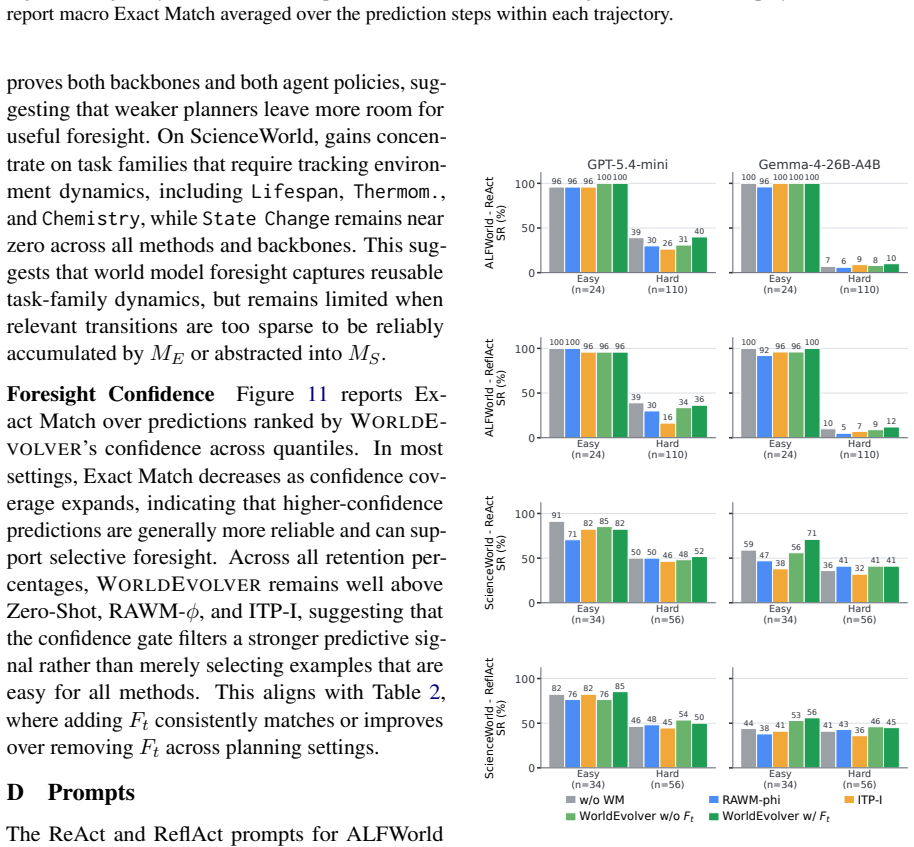
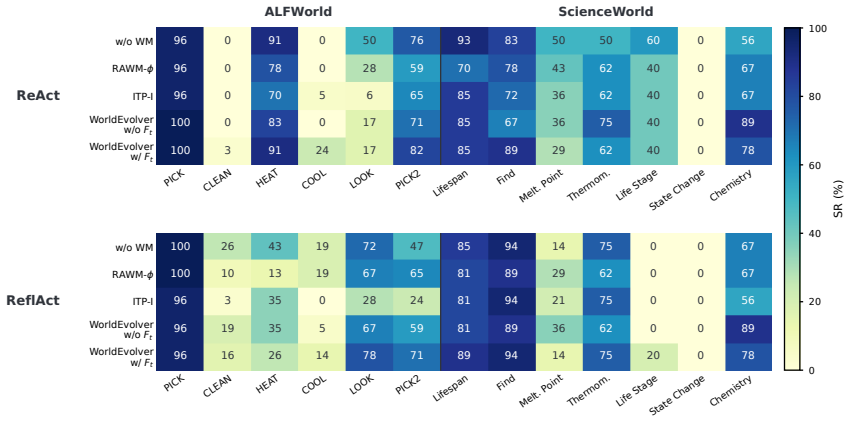
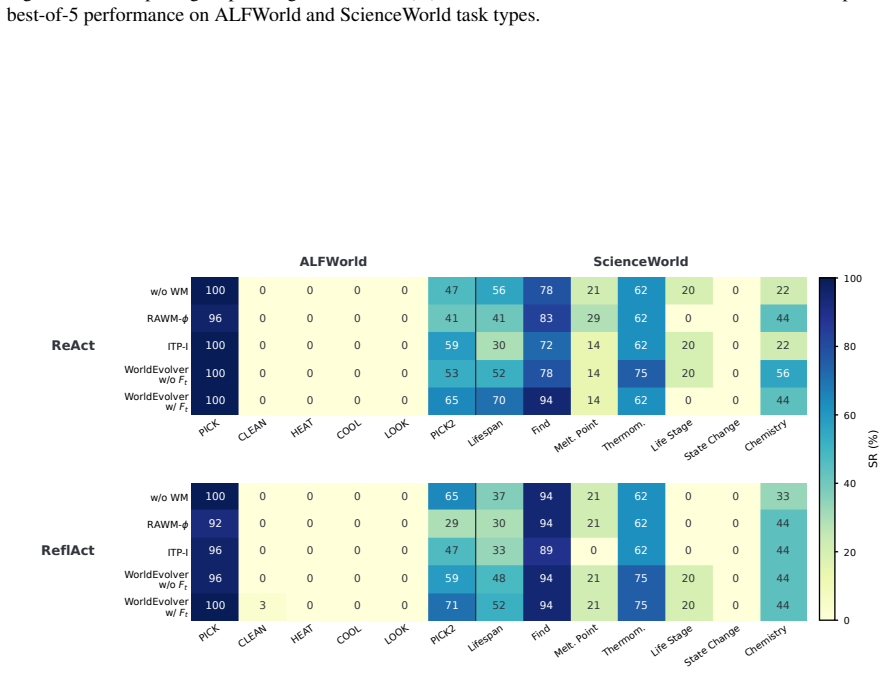
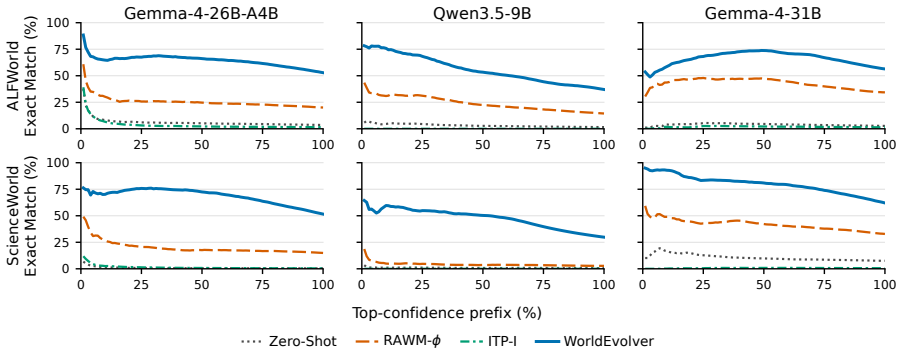
WorldEvolver integrates three modules while keeping the downstream agent and all model parameters frozen: Episodic Memory exploits real action transitions through retrieval-based simulation, Semantic Memory extracts persistent heuristic rules from prediction-observation mismatches, and Selective Foresight filters low-confidence predictions before they enter the agent reasoning context. Experiments on ALFWorld and ScienceWorld, evaluated via Word2World for prediction accuracy and AgentBoard for agent success rate, show that WorldEvolver achieves the highest prediction accuracy across three backbones and leads other world model baselines on downstream agent success rate.
What carries the argument
WorldEvolver framework with its Episodic Memory, Semantic Memory, and Selective Foresight modules that enable test-time context revision.
If this is right
- World model prediction accuracy reaches the highest levels across three different LLM backbones on Word2World.
- Downstream agent success rate exceeds other world model baselines on AgentBoard tasks in ALFWorld and ScienceWorld.
- Test-time memory revision improves both predictive fidelity and planning performance while parameters stay frozen.
- The approach outperforms static world models by incorporating real transitions and error-derived rules selectively.
Where Pith is reading between the lines
- The separation of world model revision from agent reasoning could reduce context overload in longer-horizon tasks.
- This test-time approach might extend to environments where new observations arrive continuously without requiring full model updates.
- If the modules scale, agents could maintain performance in changing settings by evolving only the memory components.
Load-bearing premise
The three modules integrate into the agent's reasoning context without causing the agent to ignore or misuse the updated information, and the benchmarks represent real planning challenges.
What would settle it
If WorldEvolver produces no improvement or lower prediction accuracy on Word2World and no gain in agent success rate on AgentBoard compared to non-evolving world model baselines across the same backbones.
Figures












read the original abstract
World models offer a principled way to equip long-horizon LLM agents with foresight: predictions of action consequences before execution. However, unreliable foresight can be ignored, misused, or even degrade downstream decision-making. In this paper, we introduce WorldEvolver, a self-evolving world model framework that revises its deployment-time context while keeping the downstream agent and all model parameters frozen. WorldEvolver integrates three modules: (i) Episodic Memory, which exploits real action transitions through retrieval-based simulation; (ii) Semantic Memory, which extracts persistent heuristic rules from prediction-observation mismatches; and (iii) Selective Foresight, which filters low-confidence predictions before integrating them into agent reasoning context. We evaluate WorldEvolver on ALFWorld and ScienceWorld, measuring world model prediction accuracy on Word2World and downstream agent success rate on AgentBoard. Extensive experiments show that WorldEvolver achieves the highest prediction accuracy across three backbones and leads other world model baselines on downstream agent success rate, demonstrating that test-time memory revision enhances both predictive fidelity and planning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WorldEvolver, a self-evolving world model for LLM agents consisting of Episodic Memory (retrieval-based simulation of action transitions), Semantic Memory (extraction of heuristic rules from prediction-observation mismatches), and Selective Foresight (filtering low-confidence predictions). With the downstream agent and all parameters kept frozen, the framework revises deployment-time context and is evaluated on ALFWorld and ScienceWorld using Word2World for prediction accuracy and AgentBoard for agent success rate. The central claim is that this test-time memory revision yields the highest prediction accuracy across three backbones and superior downstream planning performance relative to other world-model baselines.
Significance. If the results hold, the work would demonstrate a practical mechanism for improving foresight reliability in long-horizon LLM agents without retraining. Credit is due for grounding the evaluation in the standard external benchmarks ALFWorld and ScienceWorld, testing across multiple backbones, and focusing on the interaction between world-model revision and frozen-agent planning.
major comments (3)
- [Experiments / Evaluation] The central claim that inserting the outputs of the three modules into the agent's context produces the observed gains requires evidence that the agent actually conditions on the revised memory. No ablation that removes the memory content while preserving other prompt changes, and no analysis (e.g., attention maps or forced-reference prompts) showing the agent attends to the inserted information, is described.
- [Abstract / Experiments] The abstract states that WorldEvolver 'achieves the highest prediction accuracy across three backbones and leads other world model baselines on downstream agent success rate,' yet the provided text supplies no quantitative numbers, error bars, statistical significance tests, or details on baseline implementations and hyper-parameters, making it impossible to verify the magnitude or robustness of the reported improvements.
- [Method / Evaluation] The assumption that the three modules can be integrated into the agent's reasoning context without causing the agent to ignore or misuse the updated information is load-bearing for the performance claims, but the manuscript provides no diagnostic experiments or failure-case analysis addressing this integration risk.
minor comments (2)
- [Abstract] The abstract references 'Word2World' and 'AgentBoard' without defining them or citing their sources.
- [Method] Notation for the three modules (Episodic Memory, Semantic Memory, Selective Foresight) is introduced without an accompanying diagram or pseudocode showing data flow and insertion points into the frozen agent's prompt.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for direct evidence of agent conditioning on memory and clearer quantitative reporting. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments / Evaluation] The central claim that inserting the outputs of the three modules into the agent's context produces the observed gains requires evidence that the agent actually conditions on the revised memory. No ablation that removes the memory content while preserving other prompt changes, and no analysis (e.g., attention maps or forced-reference prompts) showing the agent attends to the inserted information, is described.
Authors: We agree that isolating the contribution of the memory content itself is important for validating the central claim. In the revised version, we will add an ablation that substitutes neutral placeholder text for the actual memory outputs while preserving prompt length, structure, and all other elements. We will also include qualitative analysis of agent reasoning traces demonstrating explicit references to the inserted memory content. revision: yes
-
Referee: [Abstract / Experiments] The abstract states that WorldEvolver 'achieves the highest prediction accuracy across three backbones and leads other world model baselines on downstream agent success rate,' yet the provided text supplies no quantitative numbers, error bars, statistical significance tests, or details on baseline implementations and hyper-parameters, making it impossible to verify the magnitude or robustness of the reported improvements.
Authors: The results section contains tables reporting quantitative metrics with means and standard deviations across multiple runs, along with baseline details. To address the concern directly, we will revise the abstract to include key numerical improvements and ensure the main text and appendix explicitly list hyper-parameters, baseline implementations, and any statistical tests performed. revision: yes
-
Referee: [Method / Evaluation] The assumption that the three modules can be integrated into the agent's reasoning context without causing the agent to ignore or misuse the updated information is load-bearing for the performance claims, but the manuscript provides no diagnostic experiments or failure-case analysis addressing this integration risk.
Authors: We acknowledge that the integration assumption requires explicit support. We will add a dedicated subsection with diagnostic metrics (e.g., frequency of memory references in generated plans) and a failure-case analysis covering instances of ignoring or misusing the memory, including examples and discussion of observed patterns. revision: yes
Circularity Check
No circularity; empirical framework on external benchmarks
full rationale
The paper introduces WorldEvolver as an empirical framework with three described modules (Episodic Memory, Semantic Memory, Selective Foresight) whose outputs are inserted into a frozen agent's context. Claims rest on prediction accuracy and success-rate measurements on the independent external benchmarks ALFWorld, ScienceWorld, Word2World and AgentBoard. No equations, fitted parameters renamed as predictions, self-definitional relations, or load-bearing self-citations appear in the provided text; the derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption World models are useful for equipping LLM agents with foresight in long-horizon tasks.
- domain assumption Real action transitions and prediction-observation mismatches provide useful information for improving the world model.
invented entities (3)
-
Episodic Memory
no independent evidence
-
Semantic Memory
no independent evidence
-
Selective Foresight
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2023 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[2]
OpenAI Blog , year =
Language Models are Unsupervised Multitask Learners , author =. OpenAI Blog , year =
-
[3]
arXiv preprint arXiv:1803.10122 , year =
World Models , author =. arXiv preprint arXiv:1803.10122 , year =
-
[4]
Nature , volume =
Mastering diverse control tasks through world models , author =. Nature , volume =. 2025 , doi =
2025
-
[5]
2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages =
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World , author =. 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages =. 2017 , publisher =
2017
-
[6]
Transactions on Machine Learning Research (TMLR) , year =
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. Transactions on Machine Learning Research (TMLR) , year =
-
[7]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , journal =. 2023 , url =
2023
-
[8]
Transactions on Machine Learning Research , year =
Cognitive Architectures for Language Agents , author =. Transactions on Machine Learning Research , year =
-
[9]
2025 , url =
Kim, Jeonghye and Rhee, Sojeong and Kim, Minbeom and Kim, Dohyung and Lee, Sangmook and Sung, Youngchul and Jung, Kyomin , booktitle =. 2025 , url =
2025
-
[10]
Proceedings of the 34th International Conference on Machine Learning (ICML) , year =
Neural Episodic Control , author =. Proceedings of the 34th International Conference on Machine Learning (ICML) , year =
-
[11]
arXiv preprint arXiv:1606.04460 , year =
Model-Free Episodic Control , author =. arXiv preprint arXiv:1606.04460 , year =
-
[12]
, journal =
Kumaran, Dharshan and Hassabis, Demis and McClelland, James L. , journal =. What Learning Systems do Intelligent Agents Need?
-
[13]
Efficient Integration of External Knowledge to
Yang, Chang and Wang, Xinrun and Zhang, Qinggang and Jiang, Qi and Huang, Xiao , booktitle =. Efficient Integration of External Knowledge to. 2025 , pages =
2025
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[15]
The Ninth International Conference on Learning Representations (ICLR) , year =
Shridhar, Mohit and Yuan, Xingdi and C. The Ninth International Conference on Learning Representations (ICLR) , year =
-
[16]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Wang, Ruoyao and Jansen, Peter and C. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2022
-
[17]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Reasoning with Language Model is Planning with World Model , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2023
-
[18]
2025 , url =
Fang, Tianqing and Zhang, Hongming and Zhang, Zhisong and Ma, Kaixin and Yu, Wenhao and Mi, Haitao and Yu, Dong , booktitle =. 2025 , url =
2025
-
[19]
Gu, Yu and Zhang, Kai and Ning, Yuting and Zheng, Boyuan and Gou, Boyu and Xue, Tianci and Chang, Cheng and Srivastava, Sanjari and Xie, Yanan and Qi, Peng and Sun, Huan and Su, Yu , journal =. Is Your. 2025 , url =
2025
-
[20]
arXiv preprint arXiv:2601.03905 , year =
Current Agents Fail to Leverage World Model as Tool for Foresight , author =. arXiv preprint arXiv:2601.03905 , year =
-
[21]
Xia, Peng and Zeng, Kaide and Liu, Jiaqi and Qin, Can and Wu, Fang and Zhou, Yiyang and Xiong, Caiming and Yao, Huaxiu , journal =
-
[22]
2025 , url =
Qi, Zehan and Liu, Xiao and Iong, Iat Long and Lai, Hanyu and Sun, Xueqiao and Zhao, Wenyi and Yang, Yu and Yang, Xinyue and Sun, Jiadai and Yao, Shuntian and Zhang, Tianjie and Xu, Wei and Tang, Jie and Dong, Yuxiao , booktitle =. 2025 , url =
2025
-
[23]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation , author =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[24]
2025 , url =
Fu, Dayuan and Huang, Jianzhao and Lu, Siyuan and Dong, Guanting and Wang, Yejie and He, Keqing and Xu, Weiran , booktitle =. 2025 , url =
2025
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Agent Planning with World Knowledge Model , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[26]
2025 , url =
Zhou, Siyu and Zhou, Tianyi and Yang, Yijun and Long, Guodong and Ye, Deheng and Jiang, Jing and Zhang, Chengqi , journal =. 2025 , url =
2025
-
[27]
arXiv preprint arXiv:2512.18832 , year =
From Word to World: Can Large Language Models be Implicit Text-based World Models? , author =. arXiv preprint arXiv:2512.18832 , year =
-
[28]
Reinforcement World Model Learning for
Yu, Xiao and Peng, Baolin and Xu, Ruize and Shen, Yelong and He, Pengcheng and Nath, Suman and Singh, Nikhil and Gao, Jiangfeng and Yu, Zhou , journal =. Reinforcement World Model Learning for
-
[29]
2026 , url =
Ding, Hang and Liu, Peidong and Wang, Junqiao and Ji, Ziwei and Cao, Meng and Zhang, Rongzhao and Ai, Lynn and Yang, Eric and Shi, Tianyu and Yu, Lei , journal =. 2026 , url =
2026
-
[30]
arXiv preprint arXiv:2601.08955 , year =
Imagine-then-Plan: Agent Learning from Adaptive Lookahead with World Models , author =. arXiv preprint arXiv:2601.08955 , year =
-
[31]
Zero: Self-Evolving Search Agents without Training Data , author =
Dr. Zero: Self-Evolving Search Agents without Training Data , author =. arXiv preprint arXiv:2601.07055 , year =
-
[32]
Guo, Jiacheng and Yang, Ling and Chen, Peter and Xiao, Qixin and Wang, Yinjie and Juan, Xinzhe and Qiu, Jiahao and Shen, Ke and Wang, Mengdi , journal =
-
[33]
arXiv preprint arXiv:2604.22748 , year =
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond , author =. arXiv preprint arXiv:2604.22748 , year =
-
[34]
2024 , doi =
Ma, Chang and Zhang, Junlei and Zhu, Zhihao and Yang, Cheng and Yang, Yujiu and Jin, Yaohui and Lan, Zhenzhong and Kong, Lingpeng and He, Junxian , booktitle =. 2024 , doi =
2024
-
[35]
arXiv preprint arXiv:2510.16732 , year=
A comprehensive survey on world models for embodied ai , author=. arXiv preprint arXiv:2510.16732 , year=
-
[36]
ACM Computing Surveys , volume=
Understanding world or predicting future? a comprehensive survey of world models , author=. ACM Computing Surveys , volume=. 2025 , publisher=. doi:10.1145/3746449 , url=
-
[37]
arXiv preprint arXiv:2602.06130 , year=
Self-Improving World Modelling with Latent Actions , author=. arXiv preprint arXiv:2602.06130 , year=
-
[38]
2024 , doi=
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , booktitle=. 2024 , doi=
2024
-
[39]
Huang, Chengsong and Yu, Wenhao and Wang, Xiaoyang and Zhang, Hongming and Li, Zongxia and Li, Ruosen and Huang, Jiaxin and Mi, Haitao and Yu, Dong , journal=
-
[40]
arXiv preprint arXiv:2510.08558 , year=
Agent Learning via Early Experience , author=. arXiv preprint arXiv:2510.08558 , year=
-
[41]
arXiv preprint arXiv:2511.03773 , year=
Scaling Agent Learning via Experience Synthesis , author=. arXiv preprint arXiv:2511.03773 , year=
-
[42]
arXiv preprint arXiv:2511.22254 , year=
Co-Evolving Agents: Learning from Failures as Hard Negatives , author=. arXiv preprint arXiv:2511.22254 , year=
-
[43]
Co-Evolving
Wang, Yinjie and Yang, Ling and Tian, Ye and Shen, Ke and Wang, Mengdi , booktitle =. Co-Evolving. 2025 , note =
2025
-
[44]
2025 , url =
Kim, Minsoo and Hwang, Seung-won , booktitle =. 2025 , url =
2025
-
[45]
arXiv preprint arXiv:2602.10480 , year=
Neuro-Symbolic Synergy for Interactive World Modeling , author=. arXiv preprint arXiv:2602.10480 , year=
-
[46]
arXiv preprint arXiv:2512.02472 , year=
Guided self-evolving llms with minimal human supervision , author=. arXiv preprint arXiv:2512.02472 , year=
-
[47]
Maes, Lucas and Lidec, Quentin Le and Scieur, Damien and LeCun, Yann and Balestriero, Randall , journal=
-
[48]
Organization of Memory , editor=
Episodic and Semantic Memory , author=. Organization of Memory , editor=
-
[49]
TextGrad: Automatic "Differentiation" via Text
Y. arXiv preprint arXiv:2406.07496 , year=. doi:10.48550/arXiv.2406.07496 , eprint=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.07496
-
[50]
arXiv preprint arXiv:2603.09400 , year=
Reward Prediction with Factorized World States , author=. arXiv preprint arXiv:2603.09400 , year=. doi:10.48550/arXiv.2603.09400 , eprint=
-
[51]
The Twelfth International Conference on Learning Representations (ICLR) , year=
Synapse: Trajectory-as-Exemplar Prompting with Memory for Computer Control , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[52]
2024 , url=
Zhou, Ruiwen and Yang, Yingxuan and Wen, Muning and Wen, Ying and Wang, Wenhao and Xi, Chunling and Xu, Guoqiang and Yu, Yong and Zhang, Weinan , booktitle=. 2024 , url=
2024
-
[53]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Contextual Experience Replay for Self-Improvement of Language Agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , doi=
2025
-
[54]
Deng, Yang and Zhang, Xuan and Zhang, Wenxuan and Yuan, Yifei and Ng, See Kiong and Chua, Tat-Seng , booktitle=. On the. 2024 , doi=
2024
-
[55]
Advances in Neural Information Processing Systems (NeurIPS) , year=
When to Trust Your Model: Model-Based Policy Optimization , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[56]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Can We Edit Factual Knowledge by In-Context Learning? , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , doi=
2023
-
[57]
arXiv preprint arXiv:2412.03624 , year=
How to correctly do semantic backpropagation on language-based agentic systems , author=. arXiv preprint arXiv:2412.03624 , year=
-
[58]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Editing Large Language Models: Problems, Methods, and Opportunities , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , address=. doi:10.18653/v1/2023.emnlp-main.632 , url=
-
[59]
Aging with
Hartvigsen, Thomas and Sankaranarayanan, Swami and Palangi, Hamid and Kim, Yoon and Ghassemi, Marzyeh , booktitle=. Aging with. 2023 , url=
2023
-
[60]
2026 , url=
Introducing. 2026 , url=
2026
-
[61]
2025 , doi=
Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren , journal=. 2025 , doi=
2025
-
[62]
2024 , url=
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , booktitle=. 2024 , url=
2024
-
[63]
2024 , url=
Chen, Minghao and Li, Yihang and Yang, Yanting and Yu, Shiyu and Lin, Binbin and He, Xiaofei , booktitle=. 2024 , url=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.