Deep Reinforcement Learning for Individual Atomic Control and Cooling
Pith reviewed 2026-07-01 01:49 UTC · model grok-4.3
The pith
Deep reinforcement learning cools a single atom's motion in 388 microseconds using only cavity transmission feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
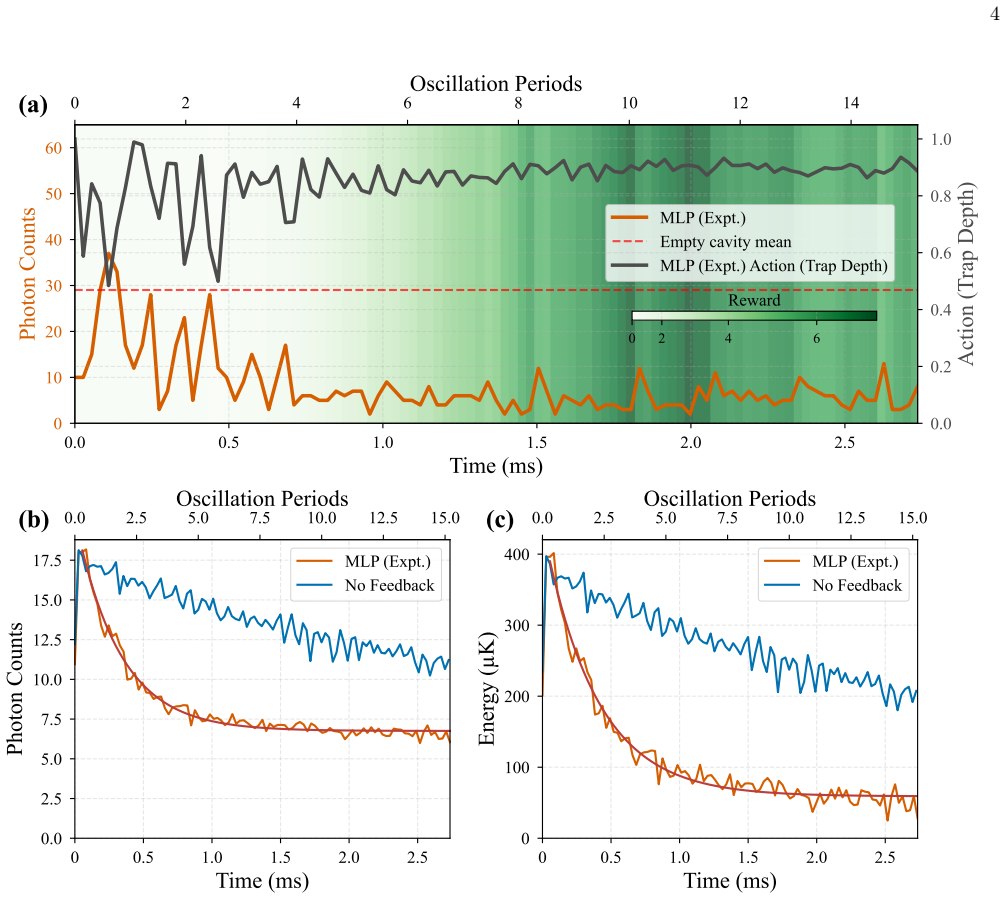
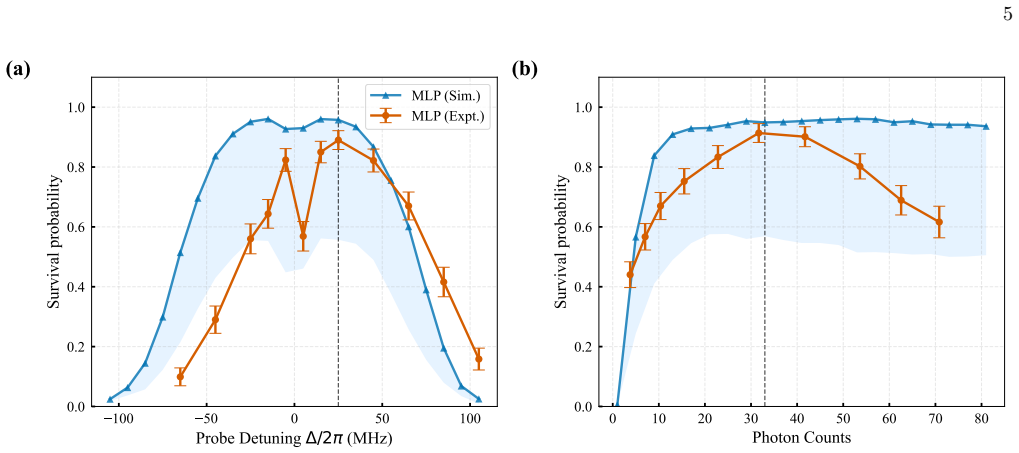
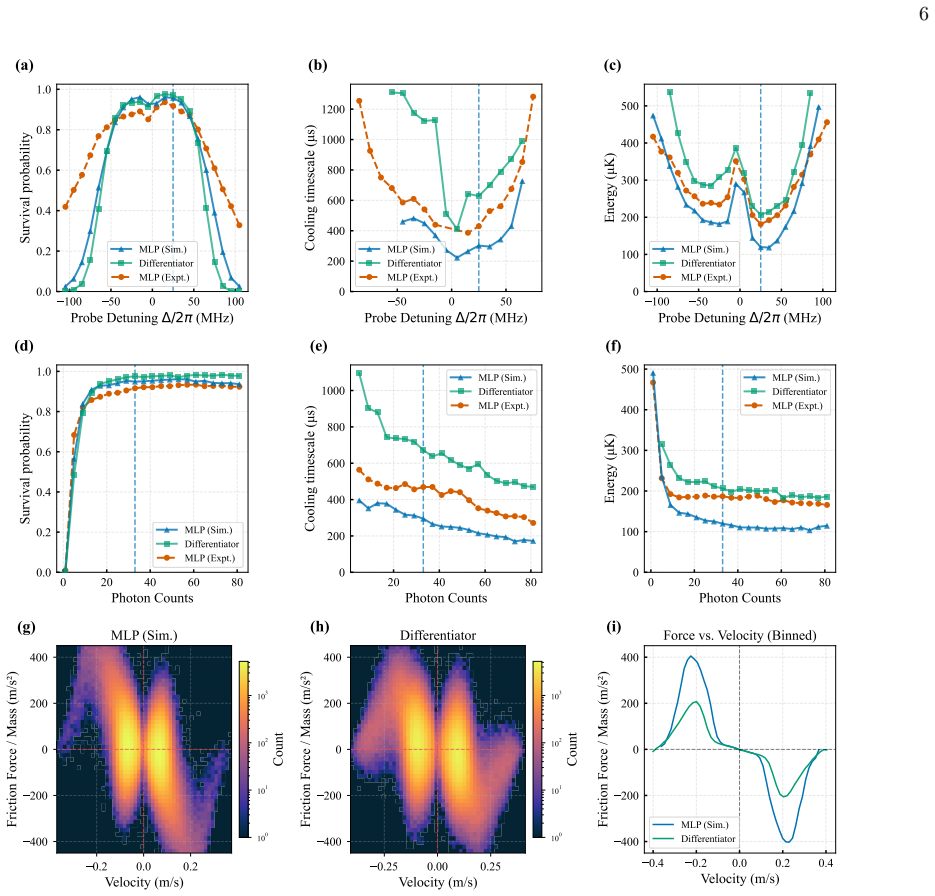
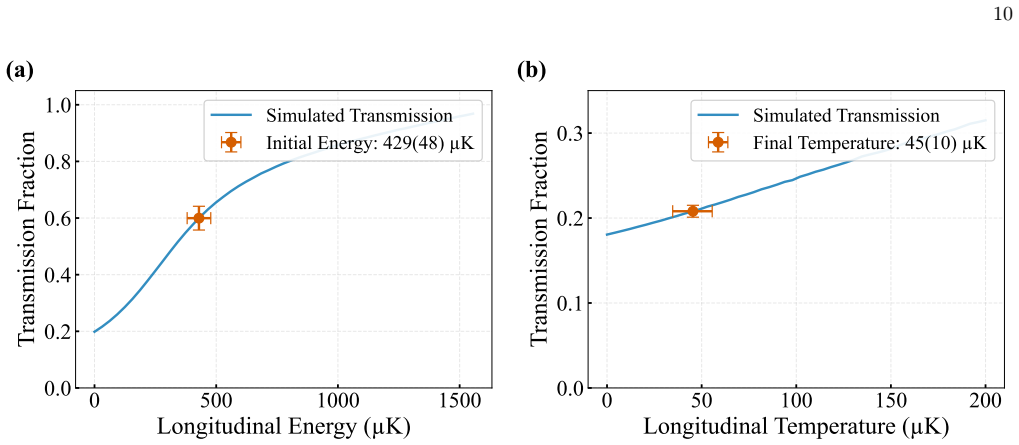
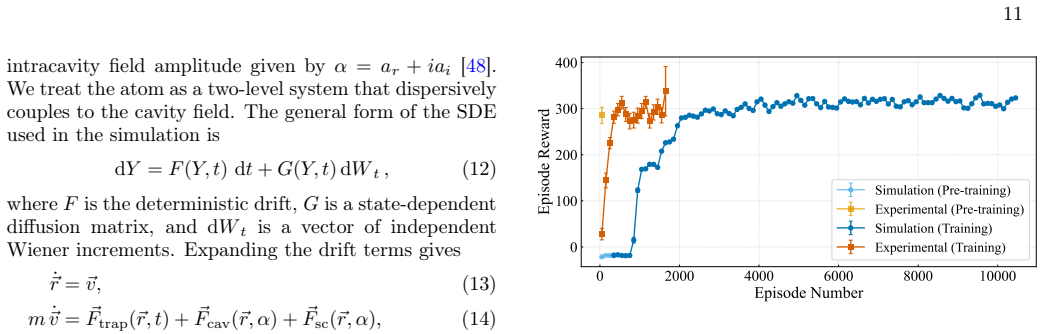
A deep reinforcement learning policy trained in simulation and then fine-tuned online damps the motion of a single neutral atom coupled to a high-finesse cavity using only the continuously monitored transmission; the policy reaches a cooling time constant of 388 plus or minus 14 microseconds (two motional periods) and cools faster than a linear differentiator controller while retaining atoms at comparable rates across operating conditions.
What carries the argument
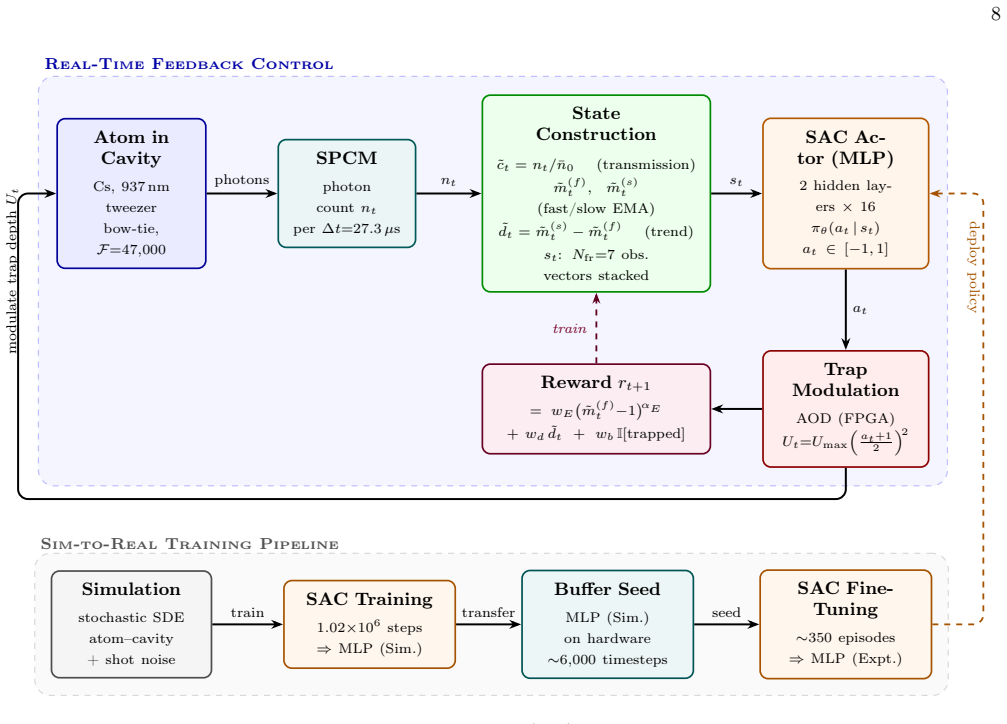
Deep reinforcement learning policy that maps continuous cavity transmission measurements to real-time control actions for atom motional damping.
If this is right
- The learned policy damps atom motion faster than a standard linear differentiator controller.
- Atom retention remains comparable to the linear controller over a broad range of operating conditions.
- Online fine-tuning can adapt the policy to unmodeled experimental dynamics without causing instability.
- Reinforcement learning supplies a route to feedback control in quantum-limited experiments where compact analytical models are incomplete.
Where Pith is reading between the lines
- The same training-and-transfer pipeline could be tested on systems with multiple atoms or additional degrees of freedom.
- Online adaptation might allow the controller to track slow drifts in cavity parameters or trap frequencies without retuning by hand.
- If the approach generalizes, it could reduce reliance on detailed first-principles modeling for other cavity-QED feedback tasks.
Load-bearing premise
The simulation of the atom-cavity system must be accurate enough for a policy trained in it to transfer to the experiment after online fine-tuning without instability or loss of performance.
What would settle it
If the transferred policy after online fine-tuning produces a cooling time constant much longer than 388 microseconds or loses atoms at a markedly higher rate than the linear controller across the tested conditions, the claim of successful sim-to-real transfer and practical advantage would not hold.
Figures
read the original abstract
Real-time feedback control of quantum systems is often limited by partial observations, nonlinear dynamics and measurement noise, which make accurate model-based controllers difficult to design. Here we show that deep reinforcement learning can cool the motion of a single neutral atom coupled to a high-finesse optical cavity using only the continuously monitored cavity transmission. We first train the controller in simulation and then transfer it to the experiment, where online fine-tuning adapts it to unmodeled experimental dynamics. The learned policy damps the atom's motion in real time and achieves a cooling time constant of 388 +/- 14 microseconds, corresponding to only two motional periods in the trap. It also outperforms a standard linear differentiator controller in cooling speed while maintaining comparable atom retention over a broad range of operating conditions. These results establish reinforcement learning as a practical strategy for feedback control in quantum-limited experiments where compact analytical models are incomplete.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript demonstrates the application of deep reinforcement learning to real-time feedback cooling of a single neutral atom coupled to a high-finesse optical cavity, using only continuously monitored cavity transmission. The policy is first trained in simulation and transferred to the experiment, where online fine-tuning adapts it to unmodeled dynamics. Reported results include a cooling time constant of 388 ± 14 μs (two motional periods in the trap) and superior cooling speed compared to a standard linear differentiator controller, with comparable atom retention across operating conditions.
Significance. If the experimental outcomes hold under scrutiny, the work provides concrete evidence that deep RL can serve as a practical controller for quantum-limited systems with partial observations and incomplete analytical models. The achieved cooling timescale near the fundamental motional period and the successful sim-to-real transfer with online adaptation would strengthen the case for RL in atomic physics and quantum optics experiments.
major comments (2)
- [Abstract] The central experimental claim (cooling time constant of 388 ± 14 μs and outperformance of the linear controller) rests on the successful transfer from simulation to experiment via online fine-tuning, yet the abstract provides no quantitative metrics on simulation fidelity, reward function details, or stability during adaptation; this is load-bearing for the transfer claim.
- [Training and transfer process] The weakest assumption—that the atom-cavity simulation is accurate enough for initial training to transfer without instability—requires explicit validation (e.g., direct comparison of simulated vs. experimental trajectories or ablation of fine-tuning effects); without this, the reported performance cannot be fully assessed.
minor comments (2)
- Clarify the statistical basis for the reported uncertainty (±14 μs) and the number of experimental runs or fitting procedure used to obtain the cooling time constant.
- The comparison to the linear differentiator controller should specify the exact implementation and parameter tuning of the baseline to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address the two major comments point by point below. Where the comments identify opportunities to strengthen the presentation of the sim-to-real transfer, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] The central experimental claim (cooling time constant of 388 ± 14 μs and outperformance of the linear controller) rests on the successful transfer from simulation to experiment via online fine-tuning, yet the abstract provides no quantitative metrics on simulation fidelity, reward function details, or stability during adaptation; this is load-bearing for the transfer claim.
Authors: We agree that the abstract can be strengthened by briefly signaling the transfer process. The revised abstract now includes a short clause noting that online fine-tuning successfully adapts the policy to unmodeled dynamics, enabling the reported performance. Quantitative details on simulation fidelity, reward design, and adaptation stability remain in the main text (Sections III and IV) and supplementary material, as is conventional for concise abstracts; we believe this balances brevity with the load-bearing nature of the claim. revision: yes
-
Referee: [Training and transfer process] The weakest assumption—that the atom-cavity simulation is accurate enough for initial training to transfer without instability—requires explicit validation (e.g., direct comparison of simulated vs. experimental trajectories or ablation of fine-tuning effects); without this, the reported performance cannot be fully assessed.
Authors: We acknowledge that explicit side-by-side validation would make the transfer claim more robust. The original manuscript already reports that the policy is trained in simulation and then fine-tuned online, with performance metrics measured in the experiment. To directly address the request, the revised version adds (i) a comparison of representative simulated and experimental motional trajectories under the transferred policy and (ii) an ablation showing cooling performance with and without the fine-tuning stage. These additions confirm that the initial policy transfers without instability and that fine-tuning provides further improvement. revision: yes
Circularity Check
No significant circularity; experimental results independent of internal definitions
full rationale
The paper applies deep reinforcement learning to atom cooling via cavity transmission feedback, training first in simulation then transferring with online fine-tuning. Central claims rest on measured cooling time constants (388 ± 14 μs) and experimental comparisons to a linear differentiator controller, with no mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations. The simulation-to-experiment transfer is presented as an empirical process rather than a closed derivation, and no equations reduce to their own inputs by construction. This is the expected non-finding for an applied experimental ML paper whose validity is externally falsifiable via lab outcomes.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL training hyperparameters and reward function weights
axioms (1)
- domain assumption The atom-cavity dynamics admit a sufficiently accurate simulation for policy pre-training that can be transferred and adapted experimentally
Reference graph
Works this paper leans on
-
[1]
Deep Reinforcement Learning for Individual Atomic Control and Cooling
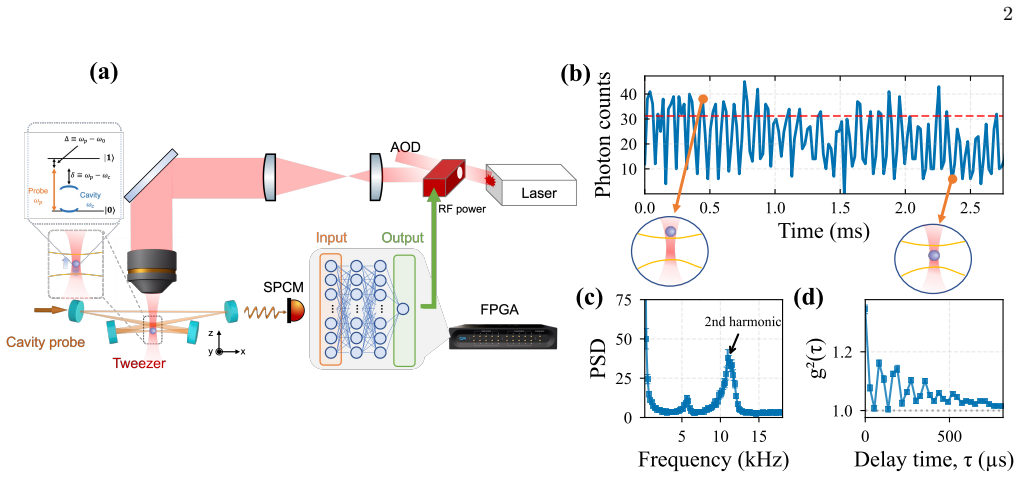
while maintaining comparable atom retention, and we later trace this advantage to a learned force profile with a twice-larger peak damping force. EXPERIMENTAL APPARATUS Our goal is to cool the motional degree of freedom of a single trapped atom by inferring its position and using real-time modulation of the trapping potential to remove arXiv:2606.30765v1 ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Labuhn, D
H. Labuhn, D. Barredo, S. Ravets, S. de Léséleuc, T. Macrì, T. Lahaye, and A. Browaeys, Tunable two- dimensional arrays of single rydberg atoms for realizing quantum ising models, Nature534, 667 (2016)
2016
-
[3]
Bernien, S
H. Bernien, S. Schwartz, A. Keesling, H. Levine, A. Om- ran, H. Pichler, S. Choi, A. S. Zibrov, M. Endres, 13 M. Greiner, V. Vuletić, and M. D. Lukin, Probing many- body dynamics on a 51-atom quantum simulator, Nature 551, 579 (2017)
2017
-
[4]
M. A. Norcia, A. W. Young, W. J. Eckner, E. Oelker, J. Ye, and A. M. Kaufman, Seconds- scale coherence on an optical clock transition in a tweezer array, Science366, 93 (2019), https://www.science.org/doi/pdf/10.1126/science.aay0644
-
[5]
Gefen, J
R.Finkelstein, R.B.-S.Tsai, X.Sun, P.Scholl, S.Direkci, T. Gefen, J. Choi, A. L. Shaw, and M. Endres, Univer- sal quantum operations and ancilla-based read-out for tweezer clocks, Nature634, 321 (2024)
2024
-
[6]
B. W. Reichardt, A. Paetznick, D. Aasen, I. Basov, J. M. Bello-Rivas, P. Bonderson, R. Chao, W. van Dam, M. B. Hastings, A. Paz, M. P. da Silva, A. Sundaram, K. M. Svore, A. Vaschillo, Z. Wang, M. Zanner, W. B. Cairn- cross, C.-A. Chen, D. Crow, H. Kim, J. M. Kindem, J. King, M. McDonald, M. A. Norcia, A. Ryou, M. Stone, L. Wadleigh, K. Barnes, P. Battagl...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Bluvstein, S
D. Bluvstein, S. J. Evered, A. A. Geim, S. H. Li, H. Zhou, T. Manovitz, S. Ebadi, M. Cain, M. Kalinowski, D. Hangleiter, J. P. Bonilla Ataides, N. Maskara, I. Cong, X. Gao, P. S. Rodriguez, T. Karolyshyn, G. Semeghini, M. J. Gullans, M. Greiner, V. Vuletić, and M. D. Lukin, Logical quantum processor based on reconfigurable atom arrays, Nature626, 58 (2024)
2024
-
[8]
Deist, Y.-H
E. Deist, Y.-H. Lu, J. Ho, M. K. Pasha, J. Zeiher, Z. Yan, and D. M. Stamper-Kurn, Mid-Circuit Cavity Measure- ment in a Neutral Atom Array, Phys. Rev. Lett.129, 203602 (2022)
2022
-
[9]
Grinkemeyer, E
B. Grinkemeyer, E. Guardado-Sanchez, I. Dimitrova, D. Shchepanovich, G. E. Mandopoulou, J. Borregaard, V. Vuletić, and M. D. Lukin, Error-detected quantum operations with neutral atoms mediated by an optical cavity, Science387, 1301 (2025)
2025
-
[10]
Welte, B
S. Welte, B. Hacker, S. Daiss, S. Ritter, and G. Rempe, Cavity carving of atomic bell states, Phys. Rev. Lett. 118, 210503 (2017)
2017
-
[11]
T. Dorđević, P. Samutpraphoot, P. L. Ocola, H. Bernien, B. Grinkemeyer, I. Dimitrova, V. Vuletić, and M. D. Lukin, Entanglement trans- port and a nanophotonic interface for atoms in optical tweezers, Science373, 1511 (2021), https://www.science.org/doi/pdf/10.1126/science.abi9917
-
[12]
Mabuchi, Q
H. Mabuchi, Q. A. Turchette, M. S. Chapman, and H. J. Kimble, Real-time detection of individual atoms falling through a high-finesse optical cavity, Opt. Lett.21, 1393 (1996)
1996
-
[13]
C. J. Hood, M. S. Chapman, T. W. Lynn, and H. J. Kimble, Real-time cavity qed with single atoms, Phys. Rev. Lett.80, 4157 (1998)
1998
-
[14]
Münstermann, T
P. Münstermann, T. Fischer, P. Maunz, P. W. H. Pinkse, and G. Rempe,Dynamicsof single-atom motion observed in a high-finesse cavity, Phys. Rev. Lett.82, 3791 (1999)
1999
-
[15]
P. W. H. Pinkse, T. Fischer, P. Maunz, and G. Rempe, Trapping an atom with single photons, Nature404, 365 (2000)
2000
-
[16]
Mabuchi, J
H. Mabuchi, J. Ye, and H. J. Kimble, Full observation of single-atom dynamics in cavity qed, Applied Physics B 68, 1095 (1999)
1999
-
[17]
C. J. Hood, T. W. Lynn, A. C. Doherty, A. S. Parkins, and H. J. Kimble, The atom-cavity microscope: Single atoms bound in orbit by single photons, Science287, 1447 (2000)
2000
-
[18]
M. Koch, C. Sames, A. Kubanek, M. Apel, M. Balbach, A. Ourjoumtsev, P. W. H. Pinkse, and G. Rempe, Feed- back cooling of a single neutral atom, Phys. Rev. Lett. 105, 173003 (2010)
2010
-
[19]
Diehl, E
R. Diehl, E. Hebestreit, R. Reimann, F. Tebbenjohanns, M. Frimmer, and L. Novotny, Optical levitation and feed- back cooling of a nanoparticle at subwavelength distances from a membrane, Phys. Rev. A98, 013851 (2018)
2018
-
[20]
Tebbenjohanns, M
F. Tebbenjohanns, M. Frimmer, A. Militaru, V. Jain, and L. Novotny, Cold damping of an optically levitated nanoparticle to microkelvin temperatures, Phys. Rev. Lett.122, 223601 (2019)
2019
-
[21]
Y. Zheng, G.-C. Guo, and F.-W. Sun, Cool- ing of a levitated nanoparticle with digital para- metric feedback, Applied Physics Letters115, 101105 (2019), https://pubs.aip.org/aip/apl/article- pdf/doi/10.1063/1.5099284/13270163/101105_1_online.pdf
work page doi:10.1063/1.5099284/13270163/101105_1_online.pdf 2019
-
[22]
Kamba, H
M. Kamba, H. Kiuchi, T. Yotsuya, and K. Aikawa, Recoil-limited feedback cooling of single nanoparticles near the ground state in an optical lattice, Phys. Rev. A103, L051701 (2021)
2021
-
[23]
Magrini, P
L. Magrini, P. Rosenzweig, , C. Bach, A. Deutschmann- Olek, S. G. Hofer, S. Hong, N. Kiesel, A. Kugi, and M. Aspelmeyer, Real-time optimal quantum control of mechanical motion at room temperature, Nature595, 373 (2021)
2021
-
[24]
S. Dago, J. Rieser, M. A. Ciampini, V. Mlynář, A. Kugi, M. Aspelmeyer, A. Deutschmann-Olek, and N. Kiesel, Stabilizing nanoparticles in the intensity minimum: feed- back levitation on an inverted potential, Optics Express 32, 45133 (2024)
2024
-
[25]
Fischer, P
T. Fischer, P. Maunz, P. W. H. Pinkse, T. Puppe, and G. Rempe, Feedback on the motion of a single atom in an optical cavity, Phys. Rev. Lett.88, 163002 (2002)
2002
-
[26]
D. A. Steck, K. Jacobs, H. Mabuchi, T. Bhattacharya, and S. Habib, Quantum feedback control of atomic mo- tion in an optical cavity, Phys. Rev. Lett.92, 223004 (2004)
2004
-
[27]
D. A. Steck, K. Jacobs, H. Mabuchi, S. Habib, and T. Bhattacharya, Feedback cooling of atomic motion in cavity qed, Phys. Rev. A74, 012322 (2006)
2006
-
[28]
P. B. Wigley, P. J. Everitt, A. van den Hengel, J. W. Bastian, M. A. Sooriyabandara, G. D. McDonald, K. S. Hardman, C. D. Quinlivan, P. Manju, C. C. N. Kuhn, I.R.Petersen, A.N.Luiten, J.J.Hope, N.P.Robins,and M. R. Hush, Fast machine-learning online optimization of ultra-cold-atom experiments, Scientific Reports6, 25890 (2016), arXiv:1507.04964 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
Vendeiro, J
Z. Vendeiro, J. Ramette, A. Rudelis, M. Chong, J. Sin- clair, L. Stewart, A. Urvoy, and V. Vuletić, Machine- learning-accelerated bose-einstein condensation, Phys. 14 Rev. Res.4, 043216 (2022)
2022
-
[30]
W. Xu, T. Šumarac, E. H. Qiu, M. L. Peters, S. H. Cantú, Z. Li, A. Menssen, M. D. Lukin, S. Colombo, and V. Vuletić, Bose-einstein condensation by polariza- tion gradient laser cooling, Phys. Rev. Lett.132, 233401 (2024)
2024
-
[31]
Fösel, P
T. Fösel, P. Tighineanu, T. Weiss, and F. Marquardt, Re- inforcement learning with neural networks for quantum feedback, Phys. Rev. X8, 031084 (2018)
2018
-
[32]
Reinschmidt, J
M. Reinschmidt, J. Fortágh, A. Günther, and V. Volchkov, Reinforcement learning in cold atom ex- periments, Nature Communications15, 8532 (2024)
2024
-
[33]
Milson, A
N. Milson, A. Tashchilina, T. Ooi, A. Czarnecka, Z. F. Ahmad, and L. J. LeBlanc, High-dimensional reinforce- ment learning for optimization and control of ultracold quantum gases, Machine Learning: Science and Technol- ogy4, 045057 (2023)
2023
-
[34]
Vuletić, J
V. Vuletić, J. K. Thompson, A. T. Black, and J. Simon, External-feedback laser cooling of molecular gases, Phys. Rev. A75, 051405 (2007)
2007
-
[35]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, Soft actor-critic: Off-policy maximum entropy deep re- inforcement learning with a stochastic actor (2018), arXiv:1801.01290 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Jakobi, P
N. Jakobi, P. Husbands, and I. Harvey, Noise and the re- ality gap: The use of simulation in evolutionary robotics, inAdvances in Artificial Life, Lecture Notes in Artificial Intelligence, Vol. 929 (1995) pp. 704–720
1995
-
[37]
A. A. Rusu, M. Vecerik, T. Rothörl, N. Heess, R. Pas- canu, and R. Hadsell, Sim-to-real robot learning from pixels with progressive nets (2018), arXiv:1610.04286 [cs.RO]
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [38]
- [39]
- [40]
-
[41]
Ueberholz, S
B. Ueberholz, S. Kuhr, D. Frese, D. Meschede, and V. Gomer, Counting cold collisions, Journal of Physics B: Atomic, Molecular and Optical Physics33, L135 (2000)
2000
-
[42]
Weiner, V
J. Weiner, V. S. Bagnato, S. Zilio, and P. S. Julienne, Experiments and theory in cold and ultracold collisions, Rev. Mod. Phys.71, 1 (1999)
1999
-
[43]
Schlosser, G
N. Schlosser, G. Reymond, I. Protsenko, and P. Grangier, Sub-poissonian loading of single atoms in a microscopic dipole trap, Nature411, 1024 (2001)
2001
-
[44]
J. Kim, J. Lee, J. Han, and D. Cho, Optical dipole trap without inhomogeneous ac stark broadening, Journal of the Korean Physical Society42, 483 (2003)
2003
-
[45]
J. Ye, D. W. Vernooy, and H. J. Kimble, Trapping of single atoms in cavity qed, Phys. Rev. Lett.83, 4987 (1999)
1999
- [46]
-
[47]
A. G. Barto, R. S. Sutton, and C. W. Anderson, Neuron- like adaptive elements that can solve difficult learning control problems, IEEE Transactions on Systems, Man, and CyberneticsSMC-13, 834 (1983)
1983
-
[48]
I. H. Witten, An adaptive optimal controller for discrete- time markov environments, Information and Control34, 286 (1977)
1977
-
[49]
Domokos, P
P. Domokos, P. Horak, and H. Ritsch, Semiclassical the- ory of cavity-assisted atom cooling, Journal of Physics B: Atomic, Molecular and Optical Physics34, 187 (2001)
2001
-
[50]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, Decoupled weight decay reg- ularization (2019), arXiv:1711.05101 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[51]
Raffin, A
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernes- tus, and N. Dormann, Stable-baselines3: Reliable rein- forcement learning implementations, Journal of Machine Learning Research22, 1 (2021). AUTHOR CONTRIBUTIONS M. Peters, G. Wang, and D. Spierings contributed equally to this work. M. Peters, V. Vuletić, and I. Chuang conceived the experiment. M. Pe...
2021
-
[52]
+ Re(a0a∗ −1) =|a 0|2 z0A w2c 16κU ′ 0(κ2 + 4˜δ2 + 4ω2 t ) (κ2 + 4˜δ2 + 4ω2 t )2 + (8˜δωt)2 =|a 0|2 z0A w2c F ′(ωt, δ).(S23) The dipole force that the atom experiences is given by f(t) =− ∂ ∂z n(t)U(t) = 4(z(t)−z 0) w2c n(t)U(t)(S24) = 4AU ′ 0 w2c sin(ωtt) (1− A2 w2c ) + A2 w2c cos(2ωtt) + 4z0A w2c sin(ωtt) n(t)(S25) − 4z0U ′ 0 w2c (1− A2 w2c ) + A2 w2c c...
-
[53]
+ Re(a0a∗ −1)) =−8π z0A w2c U ′ 0 × z0A w2c |a0|2 ×F ′(ωt, δ).(S35) Now instead the energy change depends quadratically on the oscillation amplitude of the atomic position, thus an exponential decay of energy is expected. Further analyzing the time-dependence of the atomic energyE=mA2ω2 t 2 , we can obtain the time dependence dE dt ≈ −4ω tU ′ 0E z2 0 w4c ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.