When Calibration Rankings Reverse: Accuracy-Controlled Evaluation for Fair Comparison of LLMs
Pith reviewed 2026-07-01 02:14 UTC · model grok-4.3
The pith
Raw global calibration metrics for LLMs are confounded by accuracy differences, making cross-model comparisons unreliable without accuracy control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
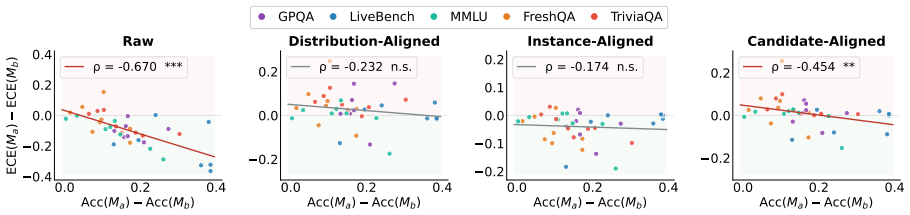
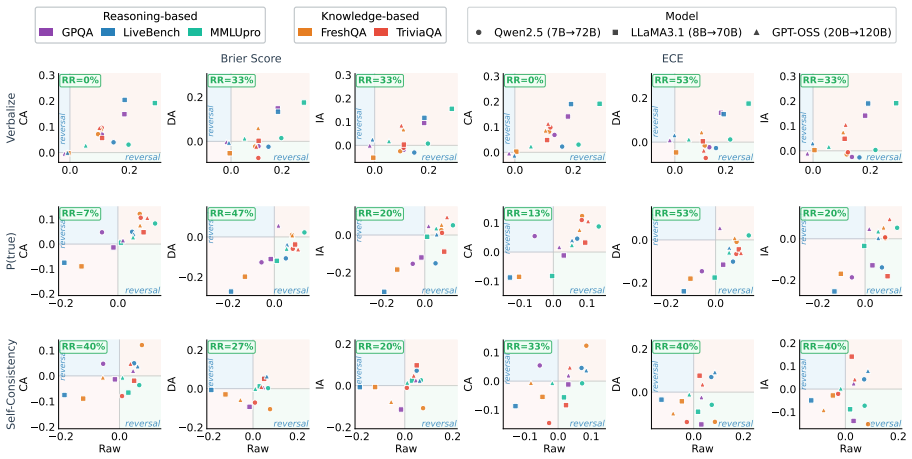
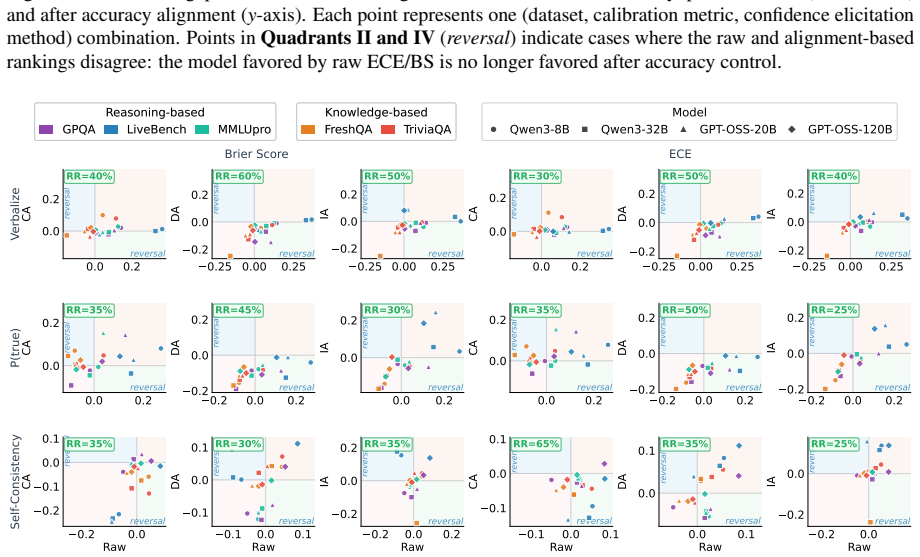
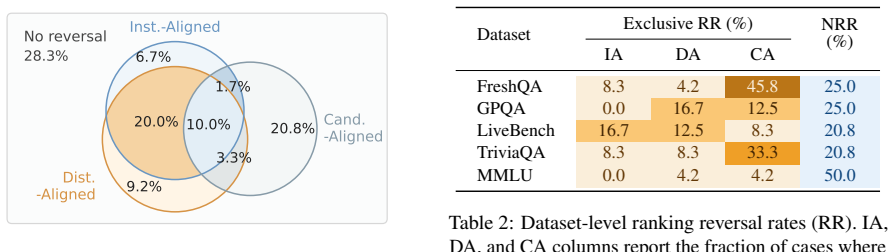
Comparisons of LLM calibration using raw global metrics such as Expected Calibration Error and Brier Score are confounded by model accuracy differences. For fair comparison, the ACE framework provides three complementary accuracy-controlled views of calibration: Instance-Aligned, Distribution-Aligned, and Candidate-Aligned. Across benchmarks, model families, and confidence elicitation methods, accuracy control substantially weakens previously reported calibration advantages and produces frequent ranking reversals between models favored by raw metrics and those favored after control.
What carries the argument
The ACE accuracy-controlled evaluation framework with its three complementary views (Instance-Aligned, Distribution-Aligned, Candidate-Aligned) that adjust comparisons to isolate calibration quality from accuracy differences.
If this is right
- Many previously reported calibration advantages weaken substantially after accuracy control.
- Ranking reversal is frequent: models favored by raw metrics often cease to be favored once accuracy is controlled.
- Comparisons along axes such as small versus large models and thinking versus non-thinking models change under ACE.
- Raw global calibration metrics are not robust for cross-model comparison.
Where Pith is reading between the lines
- Benchmarking practices for LLMs should shift toward accuracy-controlled methods to avoid systematically biased conclusions about calibration.
- The same accuracy-control principle could apply to other secondary properties such as uncertainty quantification or refusal behavior where primary performance differences may confound results.
- Model selection decisions that rely on published calibration numbers may need re-examination using controlled views.
Load-bearing premise
The three views in ACE isolate calibration quality from accuracy differences without introducing new confounding factors or selection biases.
What would settle it
Re-running the same model comparisons with the three ACE views and finding that model rankings remain unchanged from raw global metrics across multiple benchmarks would show that accuracy control is unnecessary.
Figures
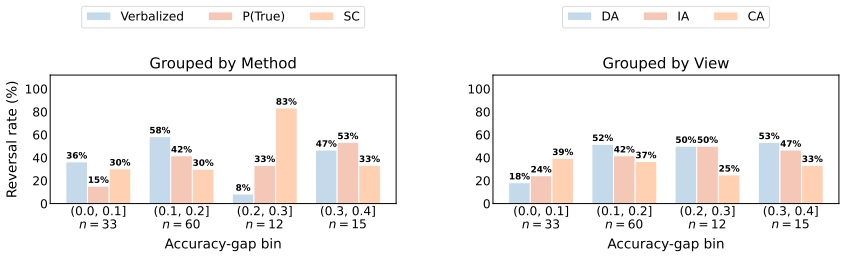
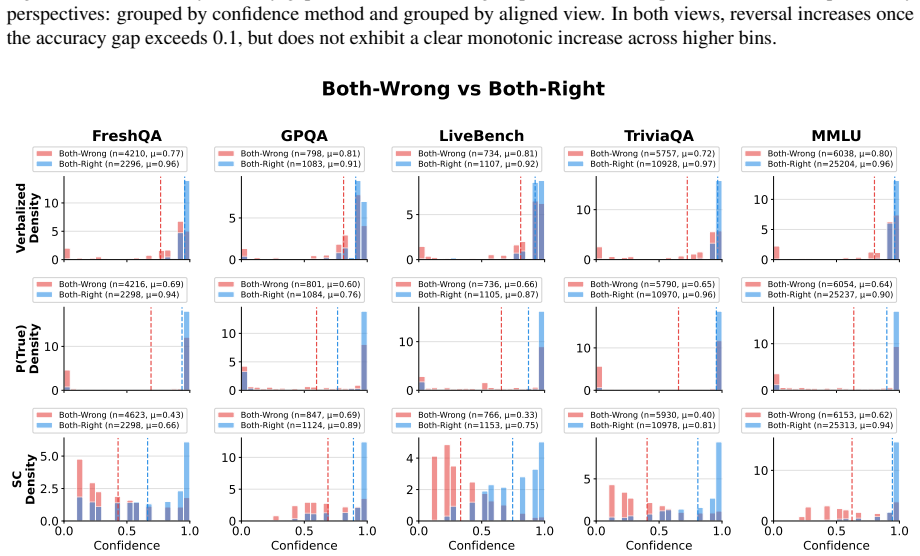
read the original abstract
Calibration evaluates whether a model confidence aligns with its empirical accuracy. Existing studies often compare the calibration of different large language models using global calibration metrics such as Expected Calibration Error and Brier Score. We begin by showing, both theoretically and empirically, that such comparisons are confounded by differences in model accuracy. For fairer cross-model comparison, we then propose ACE, an accuracy-controlled evaluation framework with three complementary views: Instance-Aligned, Distribution-Aligned, and Candidate-Aligned calibration. Across multiple benchmarks, model families, and confidence elicitation methods, we use ACE to study two practically important comparison axes, small versus large models and thinking versus non-thinking models. We find that many previously reported calibration advantages under raw global metrics weaken substantially after accuracy control. We also find that ranking reversal is frequent: models favored by raw metrics often cease to be favored once accuracy is controlled. Our results show that raw global calibration metrics are not robust for cross-model comparison, and that fair calibration comparison requires accuracy-aware evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that global calibration metrics such as ECE and Brier Score are confounded by model accuracy differences when comparing LLMs, as shown both theoretically and empirically. It proposes the ACE framework with three complementary views (Instance-Aligned, Distribution-Aligned, and Candidate-Aligned calibration) to enable accuracy-controlled evaluation. Experiments across benchmarks, model families, and confidence elicitation methods reveal frequent ranking reversals, with many reported calibration advantages weakening after accuracy control, implying that raw global metrics are not robust for cross-model comparison.
Significance. If the confounding result and the isolation provided by the three ACE views hold, the work would require re-examination of prior LLM calibration comparisons and establish accuracy-aware evaluation as a standard practice. The empirical demonstration of ranking reversals for small-vs-large and thinking-vs-non-thinking models supplies concrete, falsifiable evidence on two practically relevant axes.
minor comments (3)
- [§3] §3 (ACE definitions): the three alignment views are introduced via prose; adding a short algorithmic outline or pseudocode for each would improve reproducibility of the accuracy-control procedure.
- [Table 2, Figure 3] Table 2 and Figure 3: axis labels and legend entries use inconsistent abbreviations for the three ACE views; standardize notation across text, tables, and figures.
- [§5.2] §5.2 (ranking reversal analysis): the statistical test for reversal significance is described only in the caption; move the exact procedure and multiple-comparison correction into the main text.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The paper first establishes confounding of global metrics (ECE, Brier) by accuracy via separate theoretical and empirical arguments, then introduces ACE as a subsequent control framework. No quoted step reduces the central claim to a self-definition, fitted input renamed as prediction, or load-bearing self-citation chain. The three ACE views are presented as new constructs rather than tautological with the confounding demonstration. The derivation is self-contained and does not rely on ansatz smuggling or renaming of known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Calibration is the alignment between a model's reported confidence and its empirical accuracy on held-out data.
Reference graph
Works this paper leans on
-
[1]
A Survey of Large Language Models
A Survey of Large Language Models , year =. arXiv , author =:2303.18223 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
2025 , eprint=
Beyond the Final Layer: Intermediate Representations for Better Multilingual Calibration in Large Language Models , author=. 2025 , eprint=
2025
-
[3]
2023 , eprint=
LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models , author=. 2023 , eprint=
2023
-
[4]
A survey on evaluation of large language models , volume =
Chang, Yupeng and Wang, Xu and Wang, Jindong and Wu, Yuan and Yang, Linyi and Zhu, Kaijie and Chen, Hao and Yi, Xiaoyuan and Wang, Cunxiang and Wang, Yidong and others , journal =. A survey on evaluation of large language models , volume =
-
[5]
A survey on large language models: Applications, challenges, limitations, and practical usage , year =
Hadi, Muhammad Usman and Qureshi, Rizwan and Shah, Abbas and Irfan, Muhammad and Zafar, Anas and Shaikh, Muhammad Bilal and Akhtar, Naveed and Wu, Jia and Mirjalili, Seyedali and others , journal =. A survey on large language models: Applications, challenges, limitations, and practical usage , year =
-
[6]
Siren's song in the AI ocean: a survey on hallucination in large language models , url =
Zhang, Yue and Li, Yafu and Cui, Leyang and Cai, Deng and Liu, Lemao and Fu, Tingchen and Huang, Xinting and Zhao, Enbo and Zhang, Yu and Chen, Yulong and others , journal =. Siren's song in the AI ocean: a survey on hallucination in large language models , url =
-
[7]
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , year =. arXiv , author =:2311.05232 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Weinberger , bibsource =
Chuan Guo and Geoff Pleiss and Yu Sun and Kilian Q. Weinberger , bibsource =. On Calibration of Modern Neural Networks , url =. Proceedings of the 34th International Conference on Machine Learning,
-
[9]
arXiv , author =:2405.20974 , primaryclass =
SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales , year =. arXiv , author =:2405.20974 , primaryclass =
-
[10]
Mistral 7. arXiv , author =:2310.06825 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open Foundation and Fine-Tuned Chat Models , year =. arXiv , author =:2307.09288 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv , author =:2307.15703 , primaryclass =
Uncertainty in Natural Language Generation: From Theory to Applications , year =. arXiv , author =:2307.15703 , primaryclass =
-
[13]
arXiv , author =:2404.03163 , primaryclass =
Uncertainty in Language Models: Assessment through Rank-Calibration , year =. arXiv , author =:2404.03163 , primaryclass =
-
[14]
Andrey Malinin and Mark J. F. Gales , bibsource =. Uncertainty Estimation in Autoregressive Structured Prediction , url =. 9th International Conference on Learning Representations,
-
[15]
The measurement of observer agreement for categorical data , year =
Landis, J Richard and Koch, Gary G , journal =. The measurement of observer agreement for categorical data , year =
-
[16]
arXiv , author =:2402.06544 , primaryclass =
Calibrating Long-form Generations from Large Language Models , year =. arXiv , author =:2402.06544 , primaryclass =
-
[17]
Verification of forecasts expressed in terms of probability , volume =
Brier, Glenn W , journal =. Verification of forecasts expressed in terms of probability , volume =
-
[18]
Cooper and Milos Hauskrecht , bibsource =
Mahdi Pakdaman Naeini and Gregory F. Cooper and Milos Hauskrecht , bibsource =. Obtaining Well Calibrated Probabilities Using Bayesian Binning , url =. Proceedings of the Twenty-Ninth
-
[19]
arXiv , author =:2306.04459 , primaryclass =
Uncertainty in Natural Language Processing: Sources, Quantification, and Applications , year =. arXiv , author =:2306.04459 , primaryclass =
-
[20]
GPT-4 Technical Report , url =
OpenAI , journal =. GPT-4 Technical Report , url =
-
[21]
A survey of uncertainty in deep neural networks , url =
Gawlikowski, Jakob and Tassi, Cedrique Rovile Njieutcheu and Ali, Mohsin and Lee, Jongseok and Humt, Matthias and Feng, Jianxiang and Kruspe, Anna and Triebel, Rudolph and Jung, Peter and Roscher, Ribana and others , journal =. A survey of uncertainty in deep neural networks , url =
-
[22]
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? , url =
Alex Kendall and Yarin Gal , bibsource =. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? , url =. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA,
2017
-
[23]
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods , url =
H. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods , url =. Machine Learning , pages =
-
[24]
Look before you leap: An exploratory study of uncertainty measurement for large language models , url =
Huang, Yuheng and Song, Jiayang and Wang, Zhijie and Chen, Huaming and Ma, Lei , journal =. Look before you leap: An exploratory study of uncertainty measurement for large language models , url =
-
[25]
Aleatory and epistemic uncertainty in probability elicitation with an example from hazardous waste management , url =
Hora, Stephen C , journal =. Aleatory and epistemic uncertainty in probability elicitation with an example from hazardous waste management , url =
-
[26]
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries , url =
Wenting Zhao and Tanya Goyal and Yu Ying Chiu and Liwei Jiang and Benjamin Newman and Abhilasha Ravichander and Khyathi Chandu and Ronan Le Bras and Claire Cardie and Yuntian Deng and Yejin Choi , journal =. WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries , url =
-
[27]
Aleatory or epistemic? Does it matter? , url =
Der Kiureghian, Armen and Ditlevsen, Ove , journal =. Aleatory or epistemic? Does it matter? , url =
-
[28]
Qwen2 Technical Report , url =
An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jianxin Yang and Jin Xu and Jingren Zhou and Jinze Bai and Jinzh...
-
[29]
Linguistic Calibration of Long-Form Generations , url =
Neil Band and Xuechen Li and Tengyu Ma and Tatsunori Hashimoto , bibsource =. Linguistic Calibration of Long-Form Generations , url =. Forty-first International Conference on Machine Learning,
-
[30]
LoGU: Long-form Generation with Uncertainty Expressions , url =
Ruihan Yang and Caiqi Zhang and Zhisong Zhang and Xinting Huang and Sen Yang and Nigel Collier and Dong Yu and Deqing Yang , journal =. LoGU: Long-form Generation with Uncertainty Expressions , url =
-
[31]
Language Models (Mostly) Know What They Know
Language Models (Mostly) Know What They Know , year =. arXiv , author =:2207.05221 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Self-critiquing models for assisting human evaluators
Self-critiquing models for assisting human evaluators , year =. arXiv , author =:2206.05802 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Atomic Calibration of LLMs in Long-Form Generations , url =
Caiqi Zhang and Ruihan Yang and Zhisong Zhang and Xinting Huang and Sen Yang and Dong Yu and Nigel Collier , journal =. Atomic Calibration of LLMs in Long-Form Generations , url =
-
[34]
arXiv , author =:2406.19276 , primaryclass =
VERISCORE: Evaluating the factuality of verifiable claims in long-form text generation , year =. arXiv , author =:2406.19276 , primaryclass =
-
[35]
Le , bibsource =
Jerry Wei and Chengrun Yang and Xinying Song and Yifeng Lu and Nathan Hu and Jie Huang and Dustin Tran and Daiyi Peng and Ruibo Liu and Da Huang and Cosmo Du and Quoc V. Le , bibsource =. Long-form factuality in large language models , url =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2...
2024
-
[36]
Metrics for evaluating performance and uncertainty of Bayesian network models , volume =
Marcot, Bruce G , journal =. Metrics for evaluating performance and uncertainty of Bayesian network models , volume =
-
[37]
Classification uncertainty of deep neural networks based on gradient information , url =
Oberdiek, Philipp and Rottmann, Matthias and Gottschalk, Hanno , journal =. Classification uncertainty of deep neural networks based on gradient information , url =
-
[38]
Gradients as a measure of uncertainty in neural networks , url =
Lee, Jinsol and AlRegib, Ghassan , journal =. Gradients as a measure of uncertainty in neural networks , url =
-
[39]
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning , url =
Yarin Gal and Zoubin Ghahramani , bibsource =. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning , url =. Proceedings of the 33nd International Conference on Machine Learning,
-
[40]
Bayesian Learning via Stochastic Gradient Langevin Dynamics , url =
Max Welling and Yee Whye Teh , bibsource =. Bayesian Learning via Stochastic Gradient Langevin Dynamics , url =. Proceedings of the 28th International Conference on Machine Learning,
-
[41]
Estimating Model Uncertainty of Neural Networks in Sparse Information Form , url =
Jongseok Lee and Matthias Humt and Jianxiang Feng and Rudolph Triebel , bibsource =. Estimating Model Uncertainty of Neural Networks in Sparse Information Form , url =. Proceedings of the 37th International Conference on Machine Learning,
-
[42]
BatchEnsemble: an Alternative Approach to Efficient Ensemble and Lifelong Learning , url =
Yeming Wen and Dustin Tran and Jimmy Ba , bibsource =. BatchEnsemble: an Alternative Approach to Efficient Ensemble and Lifelong Learning , url =. 8th International Conference on Learning Representations,
-
[43]
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles , url =
Balaji Lakshminarayanan and Alexander Pritzel and Charles Blundell , bibsource =. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles , url =. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA,
2017
-
[44]
Vetrov , bibsource =
Alexander Lyzhov and Yuliya Molchanova and Arsenii Ashukha and Dmitry Molchanov and Dmitry P. Vetrov , bibsource =. Greedy Policy Search:. Proceedings of the Thirty-Sixth Conference on Uncertainty in Artificial Intelligence,
-
[45]
Learning Loss for Test-Time Augmentation , url =
Ildoo Kim and Younghoon Kim and Sungwoong Kim , bibsource =. Learning Loss for Test-Time Augmentation , url =. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , editor =
2020
-
[46]
A Survey of Language Model Confidence Estimation and Calibration , url =
Geng, Jiahui and Cai, Fengyu and Wang, Yuxia and Koeppl, Heinz and Nakov, Preslav and Gurevych, Iryna , journal =. A Survey of Language Model Confidence Estimation and Calibration , url =
-
[47]
arXiv , author =:2310.07521 , primaryclass =
Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity , year =. arXiv , author =:2310.07521 , primaryclass =
-
[48]
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , url =
Lorenz Kuhn and Yarin Gal and Sebastian Farquhar , bibsource =. Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , url =. The Eleventh International Conference on Learning Representations,
-
[49]
Shifting attention to relevance: Towards the uncertainty estimation of large language models , url =
Duan, Jinhao and Cheng, Hao and Wang, Shiqi and Wang, Chenan and Zavalny, Alex and Xu, Renjing and Kailkhura, Bhavya and Xu, Kaidi , journal =. Shifting attention to relevance: Towards the uncertainty estimation of large language models , url =
-
[50]
Teaching models to express their uncertainty in words , url =
Lin, Stephanie and Hilton, Jacob and Evans, Owain , journal =. Teaching models to express their uncertainty in words , url =
-
[51]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs , url =
Miao Xiong and Zhiyuan Hu and Xinyang Lu and Yifei Li and Jie Fu and Junxian He and Bryan Hooi , bibsource =. Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs , url =. The Twelfth International Conference on Learning Representations,
-
[52]
Combining Confidence Elicitation and Sample-based Methods for Uncertainty Quantification in Misinformation Mitigation , url =
Rivera, Mauricio and Godbout, Jean-Fran. Combining Confidence Elicitation and Sample-based Methods for Uncertainty Quantification in Misinformation Mitigation , url =. Proceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024) , editor =
2024
-
[53]
arXiv , author =:2305.19187 , primaryclass =
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models , year =. arXiv , author =:2305.19187 , primaryclass =
-
[54]
A Survey of Large Language Models , url =
Zhao, Wayne Xin and Zhou, Kun and Li, Junyi and Tang, Tianyi and Wang, Xiaolei and Hou, Yupeng and Min, Yingqian and Zhang, Beichen and Zhang, Junjie and Dong, Zican and Du, Yifan and Yang, Chen and Chen, Yushuo and Chen, Zhipeng and Jiang, Jinhao and Ren, Ruiyang and Li, Yifan and Tang, Xinyu and Liu, Zikang and Liu, Peiyu and Nie, Jian-Yun and Wen, Ji-R...
-
[55]
A survey on evaluation of large language models , url =
Chang, Yupeng and Wang, Xu and Wang, Jindong and Wu, Yuan and Yang, Linyi and Zhu, Kaijie and Chen, Hao and Yi, Xiaoyuan and Wang, Cunxiang and Wang, Yidong and others , journal =. A survey on evaluation of large language models , url =
-
[56]
Know the Unknown: An Uncertainty-Sensitive Method for LLM Instruction Tuning , url =
Jiaqi Li and Yixuan Tang and Yi Yang , journal =. Know the Unknown: An Uncertainty-Sensitive Method for LLM Instruction Tuning , url =
-
[57]
Sheng. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , editor =
2024
-
[58]
Gemini: A Family of Highly Capable Multimodal Models , type =
-
[59]
Introducing Claude 2.1 , year =
Anthropic , note =. Introducing Claude 2.1 , year =
-
[60]
arXiv , author =:2308.16175 , primaryclass =
Quantifying Uncertainty in Answers from any Language Model and Enhancing their Trustworthiness , year =. arXiv , author =:2308.16175 , primaryclass =
-
[61]
Weinberger and Yoav Artzi , bibsource =
Tianyi Zhang and Varsha Kishore and Felix Wu and Kilian Q. Weinberger and Yoav Artzi , bibsource =. BERTScore: Evaluating Text Generation with. 8th International Conference on Learning Representations,
-
[62]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks , url =
Dan Hendrycks and Kevin Gimpel , bibsource =. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks , url =. 5th International Conference on Learning Representations,
-
[63]
Selective Classification for Deep Neural Networks , url =
Yonatan Geifman and Ran El. Selective Classification for Deep Neural Networks , url =. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA,
2017
-
[64]
Comparison of values of Pearson's and Spearman's correlation coefficients on the same sets of data , volume =
Hauke, Jan and Kossowski, Tomasz , journal =. Comparison of values of Pearson's and Spearman's correlation coefficients on the same sets of data , volume =
-
[65]
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing , url =
Pengcheng He and Jianfeng Gao and Weizhu Chen , bibsource =. DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing , url =. The Eleventh International Conference on Learning Representations,
-
[66]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference , url =
Williams, Adina and Nangia, Nikita and Bowman, Samuel , booktitle =. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference , url =. doi:10.18653/v1/N18-1101 , editor =
work page internal anchor Pith review doi:10.18653/v1/n18-1101
-
[67]
Correlation coefficients: appropriate use and interpretation , url =
Schober, Patrick and Boer, Christa and Schwarte, Lothar A , journal =. Correlation coefficients: appropriate use and interpretation , url =
-
[68]
arXiv , author =:2311.15451 , primaryclass =
Uncertainty-aware Language Modeling for Selective Question Answering , year =. arXiv , author =:2311.15451 , primaryclass =
-
[69]
ChatGPT Blog Post , year =
OpenAI , howpublished =. ChatGPT Blog Post , year =
-
[70]
Building the Next Generation of Open-Source and Bilingual LLMs , year =
-
[71]
arXiv , author =:2311.10702 , primaryclass =
Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2 , year =. arXiv , author =:2311.10702 , primaryclass =
-
[72]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Lianmin Zheng and Wei. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , editor =
2023
-
[73]
Unfamiliar finetuning examples control how language models hallucinate , url =
Kang, Katie and Wallace, Eric and Tomlin, Claire and Kumar, Aviral and Levine, Sergey , journal =. Unfamiliar finetuning examples control how language models hallucinate , url =
-
[74]
Detecting hallucinations in large language models using semantic entropy , volume =
Farquhar, Sebastian and Kossen, Jannik and Kuhn, Lorenz and Gal, Yarin , journal =. Detecting hallucinations in large language models using semantic entropy , volume =
-
[75]
Manning and Chelsea Finn , bibsource =
Katherine Tian and Eric Mitchell and Huaxiu Yao and Christopher D. Manning and Chelsea Finn , bibsource =. Fine-Tuning Language Models for Factuality , url =. The Twelfth International Conference on Learning Representations,
-
[76]
Alignment for Honesty , url =
Yuqing Yang and Ethan Chern and Xipeng Qiu and Graham Neubig and Pengfei Liu , bibsource =. Alignment for Honesty , url =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , editor =
2024
-
[77]
Manning and Stefano Ermon and Chelsea Finn , bibsource =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , bibsource =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orl...
2023
-
[78]
Self-Refine: Iterative Refinement with Self-Feedback , url =
Aman Madaan and Niket Tandon and Prakhar Gupta and Skyler Hallinan and Luyu Gao and Sarah Wiegreffe and Uri Alon and Nouha Dziri and Shrimai Prabhumoye and Yiming Yang and Shashank Gupta and Bodhisattwa Prasad Majumder and Katherine Hermann and Sean Welleck and Amir Yazdanbakhsh and Peter Clark , bibsource =. Self-Refine: Iterative Refinement with Self-Fe...
2023
-
[79]
Kingma and Jimmy Ba , bibsource =
Diederik P. Kingma and Jimmy Ba , bibsource =. Adam:. 3rd International Conference on Learning Representations,
-
[80]
Editing Factual Knowledge in Language Models , url =
De Cao, Nicola and Aziz, Wilker and Titov, Ivan , booktitle =. Editing Factual Knowledge in Language Models , url =. doi:10.18653/v1/2021.emnlp-main.522 , editor =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.