A Stationary-Distribution Theory for Triplet-Based Plateau Search in Random Forest Ensemble-Size Selection
Pith reviewed 2026-07-01 06:25 UTC · model grok-4.3
The pith
Triplet plateau search for random forest ensemble size reaches a stationary distribution centered at scale O(ε^{-2}).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
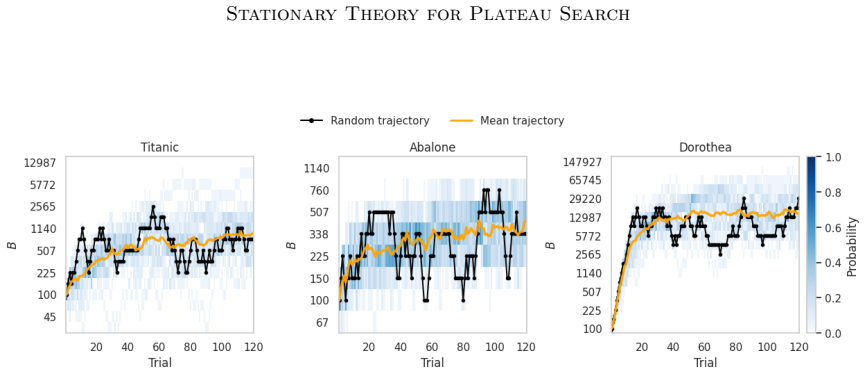
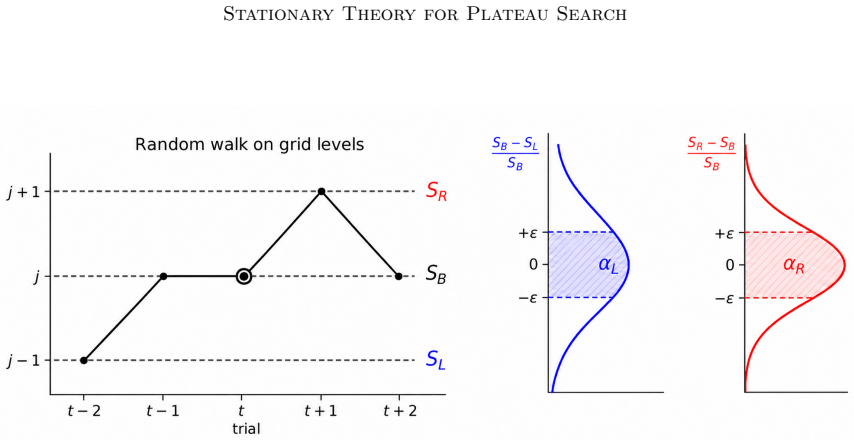
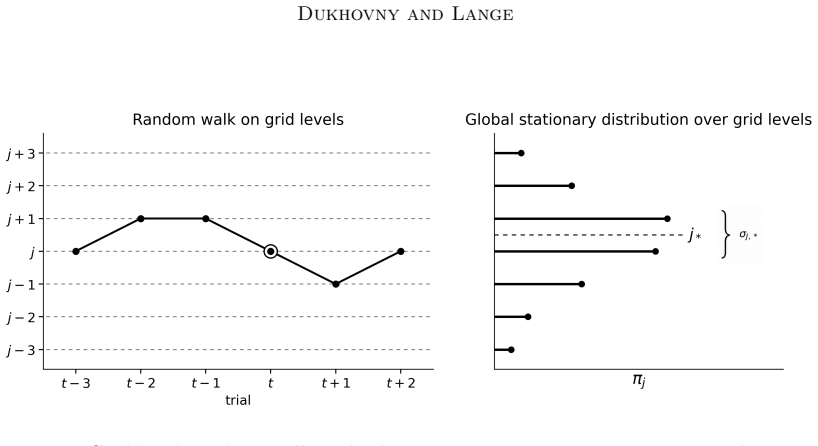
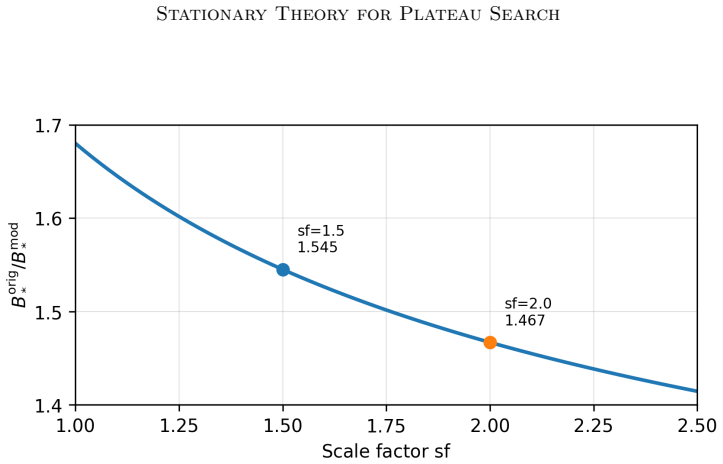
The central ensemble size B_t is modeled as a birth-death Markov chain on a geometric grid, and its stationary distribution is derived through local balance. Under a leading centered folded-normal approximation, equilibrium equations are obtained for the original update rule and a symmetric modified variant, implying that the stationary center B_* = O(ε^{-2}) as ε ↓ 0. The stationary spread is also characterized: a local Gaussian approximation and a Fokker-Planck interpretation give grid-level variance constants. After conversion to the ensemble-size scale, σ_{B,*} = O(ε^{-2}), while the variance is O(ε^{-4}). The leading relative spread is independent of ε and controlled by the scale factor
What carries the argument
Birth-death Markov chain on a geometric grid whose local balance yields the stationary distribution under a leading centered folded-normal approximation
If this is right
- The selected ensemble size grows proportionally to 1/ε² as the accuracy tolerance ε decreases.
- The variance of the selected size grows as 1/ε⁴, so relative fluctuations remain constant regardless of how small ε becomes.
- A symmetric variant of the update rule yields different equilibrium equations but preserves the same leading scaling.
- The continuous approximation via Fokker-Planck equation supplies explicit constants for the grid-level variance.
Where Pith is reading between the lines
- Designers of plateau search rules could tune the scale factor to reduce the constant relative spread without changing the ε scaling.
- The same birth-death modeling approach might extend directly to other local-comparison hyperparameter searches that use geometric steps.
- For very small ε the theory predicts that even after the hyperparameters stabilize, the chosen tree count will still wander over a wide range whose width is a fixed fraction of the center.
- Implementations could monitor the empirical distribution of B_t over many runs to estimate the update-rule-specific spread constant in practice.
Load-bearing premise
The central ensemble size can be modeled as a birth-death Markov chain on a geometric grid whose local balance yields the stationary distribution under a leading centered folded-normal approximation.
What would settle it
Running the triplet plateau search many times on a fixed dataset and fixed ε, then checking whether the long-run histogram of chosen ensemble sizes centers near a value proportional to 1/ε² with relative spread independent of ε.
Figures
read the original abstract
The number of trees is a central computational parameter in Random Forests: increasing it reduces finite-ensemble variability but increases training and prediction cost. Plateau-based tuning adapts this parameter through local comparisons of out-of-bag scores at a geometric triplet of tree counts. After the remaining hyperparameters have stabilized, however, the central triplet point need not converge to a deterministic value; instead, it fluctuates around a stationary regime. This paper develops a stationary-distribution theory for this process. The central ensemble size $B_t$ is modeled as a birth-death Markov chain on a geometric grid, and its stationary distribution is derived through local balance. Under a leading centered folded-normal approximation, equilibrium equations are obtained for the original update rule and a symmetric modified variant, implying that the stationary center $B_*=O(\varepsilon^{-2})$ as $\varepsilon\downarrow 0$. The stationary spread is also characterized. A local Gaussian approximation and a Fokker-Planck interpretation give grid-level variance constants. After conversion to the ensemble-size scale, $\sigma_{B,*}=O(\varepsilon^{-2})$, while the variance is $O(\varepsilon^{-4})$. The leading relative spread is independent of $\varepsilon$ and controlled by the scale factor and update rule. These results interpret plateau-based Random Forest tuning as a stochastic process rather than a deterministic stopping rule.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a stationary-distribution theory for triplet-based plateau search in random forest ensemble-size selection. It models the central ensemble size B_t as a birth-death Markov chain on a geometric grid, derives its stationary distribution through local balance under a leading centered folded-normal approximation, and obtains equilibrium equations implying the stationary center B_* = O(ε^{-2}) as ε ↓ 0. It further characterizes the stationary spread via local Gaussian and Fokker-Planck approximations, yielding σ_{B,*} = O(ε^{-2}) and variance O(ε^{-4}), with the leading relative spread independent of ε and controlled by the scale factor and update rule.
Significance. If the local-balance derivation and folded-normal approximation hold with controlled error as ε ↓ 0, the results would provide a rigorous stochastic-process interpretation of plateau-based ensemble-size tuning, replacing deterministic stopping rules with explicit scaling laws for center and spread; this could guide practical hyperparameter selection in random forests by quantifying expected fluctuations.
major comments (2)
- [Abstract, paragraph 2] Abstract, paragraph 2: the leading centered folded-normal approximation is used to close the local-balance equations and extract B_* ∼ c ε^{-2}, but no error bounds or asymptotic analysis of the approximation error are supplied; an O(ε) bias in the mode location would change the claimed scaling, making this load-bearing for the central O(ε^{-2}) result.
- [Abstract] Abstract: equilibrium equations are stated to be obtained for both the original update rule and a symmetric variant, yet the manuscript provides neither the explicit transition probabilities p_{k,k+1}(B) nor a validation that the folded-normal ansatz reproduces the exact detailed-balance stationary mass to the required order.
minor comments (1)
- The geometric grid {B(1+ε)^k} and the precise definition of the scale factor ε should be introduced with an explicit equation before the Markov-chain construction.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on the manuscript. The points raised concern the rigor of the approximation and the explicitness of the derivations. We address each major comment below and commit to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract, paragraph 2] Abstract, paragraph 2: the leading centered folded-normal approximation is used to close the local-balance equations and extract B_* ∼ c ε^{-2}, but no error bounds or asymptotic analysis of the approximation error are supplied; an O(ε) bias in the mode location would change the claimed scaling, making this load-bearing for the central O(ε^{-2}) result.
Authors: We agree that explicit error bounds would increase rigor. The centered folded-normal arises as the leading local limit of the birth-death chain near equilibrium under the model assumptions; the scaling B_* = O(ε^{-2}) follows from the mode location at this order. An O(ε) bias would affect only sub-leading corrections. To address the concern directly, the revised manuscript will include an asymptotic analysis of the approximation error confirming that any bias is o(ε) and does not change the leading scaling. revision: yes
-
Referee: [Abstract] Abstract: equilibrium equations are stated to be obtained for both the original update rule and a symmetric variant, yet the manuscript provides neither the explicit transition probabilities p_{k,k+1}(B) nor a validation that the folded-normal ansatz reproduces the exact detailed-balance stationary mass to the required order.
Authors: The transition probabilities p_{k,k+1}(B) are defined explicitly from the triplet comparison rule in Section 2 of the manuscript. The local-balance equations are closed with the folded-normal ansatz to obtain the equilibrium scaling for both update rules. We will add the explicit expressions for p_{k,k+1}(B) together with a numerical validation (or supporting lemma) showing that the ansatz reproduces the stationary mass to the order needed for the leading asymptotics. revision: yes
Circularity Check
No circularity: derivation is self-contained under explicit modeling assumptions
full rationale
The paper models B_t explicitly as a birth-death chain on the geometric grid and derives the stationary distribution via local balance equations closed by a stated leading centered folded-normal approximation. This produces the claimed O(ε^{-2}) scaling as a direct consequence of those assumptions rather than by re-using fitted data, self-citations, or renaming prior results. No load-bearing step reduces to its own inputs by construction, and the abstract and derivation chain contain no self-citation chains or ansatzes imported from the authors' prior work. The result is therefore a standard modeling exercise whose validity rests on the accuracy of the approximation, not on circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- ε
axioms (2)
- domain assumption Central ensemble size B_t is a birth-death Markov chain on a geometric grid
- ad hoc to paper Leading centered folded-normal approximation suffices for equilibrium equations
Reference graph
Works this paper leans on
-
[1]
Simon Bernard, Laurent Heutte, and S´ ebastien Adam
URLhttps://proceedings.neurips.cc/paper_files/ paper/2011/file/86e8f7ab32cfd12577bc2619bc635690-Paper.pdf. Simon Bernard, Laurent Heutte, and S´ ebastien Adam. Influence of hyperparameters on random forest accuracy. In J´ on Atli Benediktsson, Josef Kittler, and Fabio Roli, editors, Multiple Classifier Systems, pages 171–180, Berlin, Heidelberg,
2011
-
[2]
Adversarial examples: Attacks and defenses for deep learning
doi: 10.1109/TNNLS. 2022.3229161. Leo Breiman. Random forests.Machine Learning, 45(1):5–32,
-
[3]
Rich Caruana, Alexandru Niculescu-Mizil, Geoff Crew, and Alex Ksikes
doi: 10.1023/A: 1010933404324. Rich Caruana, Alexandru Niculescu-Mizil, Geoff Crew, and Alex Ksikes. Ensemble selection from libraries of models. InProceedings of the Twenty-First International Conference on Machine Learning, ICML ’04, page 18, New York, NY, USA,
-
[4]
Association for Computing Machinery. ISBN 1581138385. doi: 10.1145/1015330.1015432. URLhttps: //doi.org/10.1145/1015330.1015432. Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794. ACM,
-
[5]
Xgboost: A scalable tree boosting system,
doi: 10.1145/2939672.2939785. 31 Dukhovny and Lange Alfredo Cuzzocrea, Shane Leo Francis, and Mohamed Medhat Gaber. An information- theoretic approach for setting the optimal number of decision trees in random forests. In2013 IEEE International Conference on Systems, Man, and Cybernetics, pages 1013– 1019,
-
[6]
Liliya Demidova and Maria Ivkina
doi: 10.1109/SMC.2013.177. Liliya Demidova and Maria Ivkina. Approach to determining the boundaries of the search range for the number of trees in the random forest algorithm. In2020 9th Mediterranean Conference on Embedded Computing (MECO), pages 1–4,
-
[7]
Fiona Katharina Ewald, Ludwig Bothmann, Marvin N
doi: 10.1109/MECO49872.2020.9134342. Fiona Katharina Ewald, Ludwig Bothmann, Marvin N. Wright, Bernd Bischl, Giuseppe Casalicchio, and Gunnar K¨ onig. A guide to feature importance methods for scientific inference. In Luca Longo, Sebastian Lapuschkin, and Christin Seifert, editors,Explainable Artificial Intelligence, pages 440–464, Cham,
-
[8]
doi: 10.1007/978-3-031-63797-1
Springer Nature Switzerland. doi: 10.1007/978-3-031-63797-1
-
[9]
Robin Genuer, Jean-Michel Poggi, and Christine Tuleau
doi: 10.1214/aos/1013203451. Robin Genuer, Jean-Michel Poggi, and Christine Tuleau. Random forests: some method- ological insights,
-
[10]
Random Forests: some methodological insights
URLhttps://arxiv.org/abs/0811.3619. L´ eo Grinsztajn, Edouard Oyallon, and Ga¨ el Varoquaux. Why do tree-based mod- els still outperform deep learning on typical tabular data? InAdvances in Neu- ral Information Processing Systems, volume 35, pages 507–520. Curran Associates, Inc.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Daniel Hern´ andez-Lobato, Gonzalo Mart´ ınez-Mu˜ noz, and Alberto Su´ arez
URLhttps://proceedings.neurips.cc/paper_files/paper/2022/file/ 0378c7692da36807bdec87ab043cdadc-Paper-Datasets_and_Benchmarks.pdf. Daniel Hern´ andez-Lobato, Gonzalo Mart´ ınez-Mu˜ noz, and Alberto Su´ arez. How large should ensembles of classifiers be?Pattern Recognition, 46(5):1323–1336,
2022
-
[12]
doi: 10.1186/s12859-025-06097-1
ISSN 1471-2105. doi: 10.1186/s12859-025-06097-1. URL https://doi.org/10.1186/s12859-025-06097-1. Patrice Latinne, Olivier Debeir, and Christine Decaestecker. Limiting the number of trees in random forests. In Josef Kittler and Fabio Roli, editors,Multiple Classifier Systems, pages 178–187, Berlin, Heidelberg,
-
[13]
URLhttps://doi.org/10.1214/18-BA1110
doi: 10.1214/18-BA1110. URLhttps://doi.org/10.1214/18-BA1110. Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization.Journal of Machine Learning Research, 18(185):1–52,
-
[14]
URLhttps://doi.org/10.1214/18-AOS1707
doi: 10.1214/18-AOS1707. URLhttps://doi.org/10.1214/18-AOS1707. Gilles Louppe, Louis Wehenkel, Antonio Sutera, and Pierre Geurts. Understanding vari- able importances in forests of randomized trees. In C.J. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K.Q. Weinberger, editors,Advances in Neural Information Process- ing Systems, volume
-
[15]
doi: 10.1007/978-3-642-31537-4
-
[16]
URLhttps: //ieeexplore.ieee.org/document/11571780
doi: 10.1109/ACCESS.2026.3705574. URLhttps: //ieeexplore.ieee.org/document/11571780. Philipp Probst, Anne-Laure Boulesteix, and Bernd Bischl. Tunability: Importance of hy- perparameters of machine learning algorithms.Journal of Machine Learning Research, 20(53):1–32,
-
[17]
Carolin Strobl, Anne-Laure Boulesteix, Achim Zeileis, and Torsten Hothorn
doi: 10.1016/j.inffus.2021.11.011. Carolin Strobl, Anne-Laure Boulesteix, Achim Zeileis, and Torsten Hothorn. Bias in ran- dom forest variable importance measures: Illustrations, sources and a solution.BMC Bioinformatics, 8:25,
-
[18]
33 Dukhovny and Lange Laura Tolosi and Thomas Lengauer
doi: 10.1186/1471-2105-8-25. 33 Dukhovny and Lange Laura Tolosi and Thomas Lengauer. Classification with correlated features: unreliability of feature ranking and solutions.Bioinformatics, 27 14:1986–94,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.