Training Therapeutic Judges and Multi-Agent Systems for Human-Aligned Mental Health Support
Pith reviewed 2026-07-01 01:54 UTC · model grok-4.3
The pith
Mental health LLMs improve when a human-preference-trained evaluator actively drives response refinement rather than serving only as a passive score.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
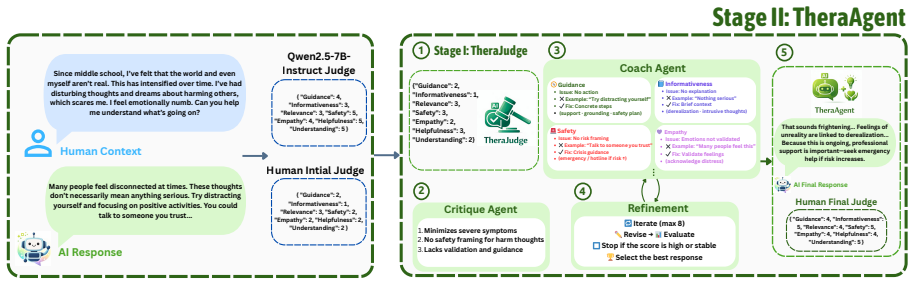
The authors claim that therapeutic response generation should be treated as a decision-refinement problem in which multi-dimensional human-aligned evaluation supplies the control signal for iterative improvement. TheraJudge, trained via preference optimization on clinician annotations, produces judgments that correlate strongly with expert ratings. TheraAgent then coordinates specialized agents to translate those judgments into revisions, producing measurable gains in blind human evaluations and high recovery of initially poor outputs.
What carries the argument
TheraJudge, the preference-optimized multi-dimensional evaluator, and TheraAgent, the coordinated Critic-Coach-Therapist refinement loop that converts evaluative signals into response changes.
If this is right
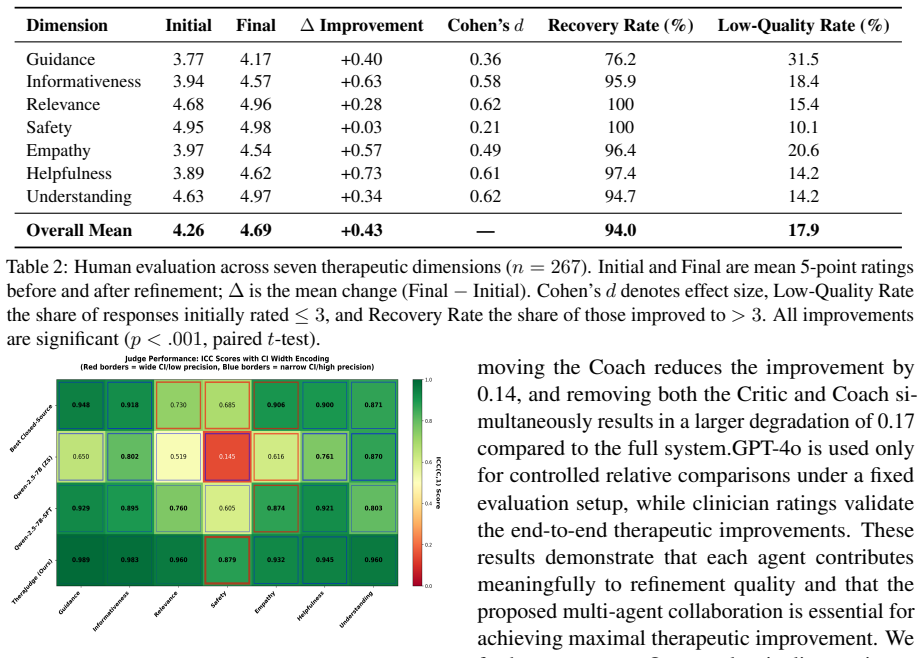
- Responses initially rated low on safety, relevance, or empathy can be lifted by more than two points through the refinement process.
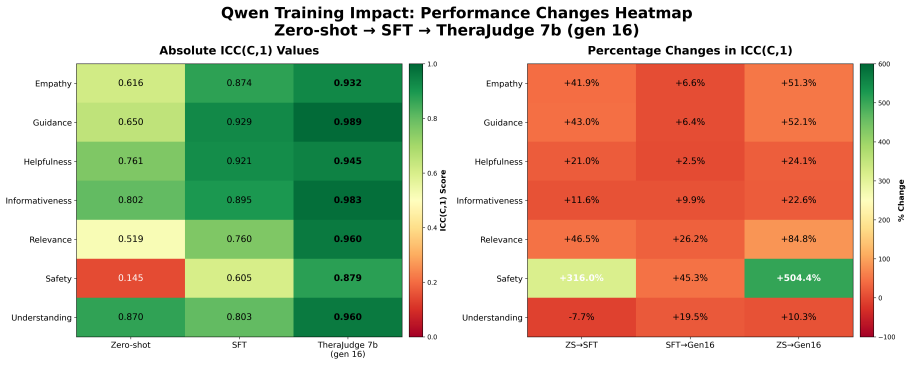
- TheraJudge can replace or augment closed-source judges for therapeutic dimensions while maintaining clinician-level agreement.
- The same evaluation-as-control pattern can be applied to other safety-critical generation tasks beyond mental health.
- Multi-agent refinement yields higher human-rated quality than generation improvements alone.
Where Pith is reading between the lines
- The approach suggests that preference data collection should prioritize coverage of failure modes over volume of standard cases.
- Similar judge-plus-refiner pipelines could be tested in adjacent domains such as legal or medical advice where evaluation must remain clinically grounded.
- If the evaluator generalizes, it could serve as a reusable training signal for future open models rather than requiring repeated human annotation rounds.
Load-bearing premise
The human preference annotations collected for training TheraJudge already capture every clinically relevant therapeutic quality and will generalize to responses, users, and edge cases outside the annotation set.
What would settle it
A new set of clinician ratings on responses generated by models or from user populations absent from the original training annotations; if TheraJudge's agreement with clinicians falls substantially below the reported ICC range, the framework's reliability claim would be undermined.
Figures

read the original abstract
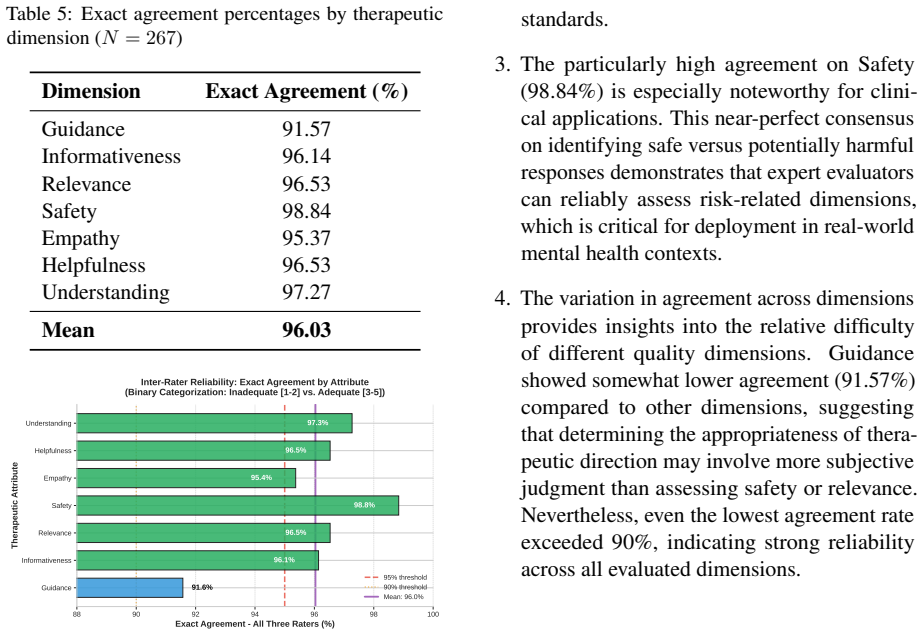
Large language models show promise for mental health support, yet therapeutic quality improves only when evaluation functions as an actionable control signal rather than a passive metric. We introduce a framework that formulates therapeutic response generation as a decision-refinement problem driven by multi-dimensional, human-aligned evaluation. In Stage I, we introduce TheraJudge, an open-source therapeutic evaluator trained via preference-based optimization on human-annotated data to produce reliable judgments across 7 psychological dimensions. In Stage II, we introduce TheraAgent, which operationalizes TheraJudge's evaluations through a coordinated refinement process with specialized Critic, Coach, and Therapist roles that translate evaluative signals into targeted response revisions. Empirically, TheraJudge achieves strong agreement with clinician ratings, with intraclass correlation coefficients (ICC = 0.87-0.95), surpassing supervised baselines and strong closed-source judges, particularly on critical dimensions such as Safety, Relevance, and Empathy. Acting on these evaluations, TheraAgent yields a +0.43 improvement in human-rated therapeutic quality (on a 5-point scale) under blind evaluation, with 96\% clinician inter-rater reliability. Low-quality responses ($\leq 3$) improve by +2.45 points with a 94\% recovery rate, demonstrating targeted correction of unsafe outputs. Overall, our results indicate that effective alignment of mental-health LLMs stems from acting on human-aligned evaluation, rather than relying solely on stronger generation. We release code at https://github.com/vis-nlp/TheraAlign.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that therapeutic alignment in LLMs is best achieved by training TheraJudge—an open-source multi-dimensional evaluator on human preference data across 7 psychological dimensions—and then using its outputs to drive TheraAgent, a multi-agent refinement system with Critic, Coach, and Therapist roles. It reports that TheraJudge reaches ICC 0.87-0.95 with clinicians (outperforming baselines), while TheraAgent produces a +0.43 lift in blind human-rated quality (with 96% inter-rater reliability) and 94% recovery for low-quality inputs, concluding that acting on human-aligned evaluation outperforms stronger generation alone. Code is released.
Significance. If the central results hold under proper validation, the work would provide concrete evidence that evaluation-driven refinement can deliver targeted, clinically relevant gains in mental-health support systems. The public code release is a clear positive for reproducibility and follow-on research.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the ICC range (0.87-0.95), +0.43 quality lift, and 94% recovery rate are presented without any description of the annotation protocol, data splits, training objective details, hyperparameters, or statistical tests used to obtain them; these omissions are load-bearing because the numerical claims cannot be assessed or reproduced without them.
- [Experiments] Experiments section: all reported agreement and improvement metrics are computed on held-out splits drawn from the same human-annotated preference pool used to train TheraJudge; no results are shown for responses from unseen demographics, cultural contexts, crisis-level inputs, or therapeutic scenarios absent from the annotation set, which directly tests the weakest assumption that the evaluator generalizes to the full range of clinically relevant cases.
minor comments (2)
- The abstract states both '96% clinician inter-rater reliability' and ICC values; the main text should explicitly distinguish these two quantities and report how the former was computed.
- A per-dimension breakdown table comparing TheraJudge against all baselines (including the closed-source judges) would improve clarity of the 'particularly on Safety, Relevance, and Empathy' claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of methodological transparency and evaluation scope. We have revised the manuscript to address these points directly while preserving the integrity of our reported results.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the ICC range (0.87-0.95), +0.43 quality lift, and 94% recovery rate are presented without any description of the annotation protocol, data splits, training objective details, hyperparameters, or statistical tests used to obtain them; these omissions are load-bearing because the numerical claims cannot be assessed or reproduced without them.
Authors: We agree these details are necessary for reproducibility. The annotation protocol (clinician annotators, guidelines, and collection process), data splits, preference optimization objective, hyperparameters, and statistical procedures (ICC computation with confidence intervals and significance testing) are described in the Methods section and Appendix A. To make this information more accessible, we have added a dedicated 'Evaluation Protocol' subsection in Experiments that summarizes these elements with pointers to the full details, and we have updated the abstract to reference the supplementary materials. revision: yes
-
Referee: [Experiments] Experiments section: all reported agreement and improvement metrics are computed on held-out splits drawn from the same human-annotated preference pool used to train TheraJudge; no results are shown for responses from unseen demographics, cultural contexts, crisis-level inputs, or therapeutic scenarios absent from the annotation set, which directly tests the weakest assumption that the evaluator generalizes to the full range of clinically relevant cases.
Authors: We acknowledge that our primary metrics are on held-out data from the annotated pool, which was constructed to span multiple therapeutic dimensions but does not exhaustively cover all possible unseen demographics, cultural contexts, or crisis-level inputs. We have added an explicit 'Generalization and Limitations' subsection that describes the dataset composition, the scenarios represented, and the rationale for the current scope. We also report preliminary checks on a small set of external crisis examples drawn from public resources. Comprehensive OOD testing on all such cases would require additional targeted data collection, which we identify as a priority for future work. revision: partial
Circularity Check
No significant circularity; derivation relies on independent human ratings
full rationale
The paper trains TheraJudge via preference optimization on human-annotated data, then uses its outputs to drive TheraAgent refinements, and reports gains (+0.43 quality, 94% recovery) via separate blind human ratings on a 5-point scale with 96% clinician reliability. ICC (0.87-0.95) is measured on held-out splits from the annotation pool, which constitutes standard validation rather than a reduction of the final metric to the training objective by construction. No self-citations, uniqueness theorems, or ansatzes appear as load-bearing steps in the abstract or described chain; the central claim is supported by post-refinement human evaluation that is not equivalent to the fitted inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human preference annotations on the seven therapeutic dimensions are reliable ground truth that generalizes beyond the annotated set.
invented entities (2)
-
TheraJudge
no independent evidence
-
TheraAgent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[13]
Jama , year=
Testing and evaluation of health care applications of large language models: a systematic review , author=. Jama , year=
-
[14]
medRxiv , pages=
Automating evaluation of AI text generation in healthcare with a large language model (LLM)-as-a-judge , author=. medRxiv , pages=. 2025 , publisher=
2025
-
[16]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
From generation to judgment: Opportunities and challenges of llm-as-a-judge , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[17]
JMIR mental health , volume=
Large language models for mental health applications: systematic review , author=. JMIR mental health , volume=. 2024 , publisher=
2024
-
[18]
Advances in Neural Information Processing Systems , volume=
Apathetic or empathetic? evaluating llms' emotional alignments with humans , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Communications Psychology , volume=
Third-party evaluators perceive AI as more compassionate than expert humans , author=. Communications Psychology , volume=. 2025 , publisher=
2025
-
[21]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Mentalchat16k: A benchmark dataset for conversational mental health assistance , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[22]
NPJ Mental Health Research , volume=
Large language models could change the future of behavioral healthcare: a proposal for responsible development and evaluation , author=. NPJ Mental Health Research , volume=. 2024 , publisher=
2024
-
[24]
The Lancet , volume=
Barriers to improvement of mental health services in low-income and middle-income countries , author=. The Lancet , volume=. 2007 , publisher=
2007
-
[25]
Jama , volume=
Health care privacy risks of AI chatbots , author=. Jama , volume=. 2023 , publisher=
2023
-
[26]
The Lancet Digital Health , volume=
Ethical and regulatory challenges of large language models in medicine , author=. The Lancet Digital Health , volume=. 2024 , publisher=
2024
-
[27]
Academic Radiology , volume=
Large language models in health systems: governance, challenges, and solutions , author=. Academic Radiology , volume=. 2025 , publisher=
2025
-
[28]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Safe rlhf: Safe reinforcement learning from human feedback , author=. arXiv preprint arXiv:2310.12773 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
BioMedInformatics , volume=
Supporting the demand on mental health services with AI-based conversational large language models (LLMs) , author=. BioMedInformatics , volume=. 2023 , publisher=
2023
-
[31]
JMIR Mental Health , volume=
The opportunities and risks of large language models in mental health , author=. JMIR Mental Health , volume=. 2024 , publisher=
2024
-
[32]
Proceedings of the ACM Web Conference 2024 , pages=
MentaLLaMA: interpretable mental health analysis on social media with large language models , author=. Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[34]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[37]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[38]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[39]
ACM Computing Surveys (CSUR) , volume=
Reinforcement learning in healthcare: A survey , author=. ACM Computing Surveys (CSUR) , volume=. 2021 , publisher=
2021
-
[40]
2024 8th International Conference on Computing, Communication, Control and Automation (ICCUBEA) , pages=
Optimization Techniques in Reinforcement Learning for Healthcare: A Review , author=. 2024 8th International Conference on Computing, Communication, Control and Automation (ICCUBEA) , pages=. 2024 , organization=
2024
-
[42]
2024 , type =
The Claude 3 Model Family: Opus, Sonnet, Haiku , institution =. 2024 , type =
2024
-
[44]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
A systematic study and comprehensive evaluation of ChatGPT on benchmark datasets , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[46]
Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies , volume=
Mental-llm: Leveraging large language models for mental health prediction via online text data , author=. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies , volume=. 2024 , publisher=
2024
-
[47]
Transactions of the Association for Computational Linguistics , year =
Bridging the Gap: A Survey on Integrating (Human) Feedback for Natural Language Generation , author =. Transactions of the Association for Computational Linguistics , year =
-
[49]
, title =
Wang, X. , title =. PubMed Central (PMC) , year =
-
[50]
Ettman, C. K. , title =. PubMed Central (PMC) , year =
-
[51]
and others , title =
Hua, Y. and others , title =. npj Digital Medicine , year =
-
[52]
Proceedings of the AAAI 2026 Workshop on Secure and Responsible AI for Health (SECUREAI4H) , year =
Assessing the Quality of Mental Health Support in LLM Responses through Multi-Attribute Human Evaluation , author =. Proceedings of the AAAI 2026 Workshop on Secure and Responsible AI for Health (SECUREAI4H) , year =
2026
-
[54]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Are LLMs Effective Psychological Assessors? Leveraging Adaptive RAG for Interpretable Mental Health Screening through Psychometric Practice , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[56]
TherapyGym: Evaluating and Aligning Clinical Fidelity and Safety in Therapy Chatbots , author=
-
[57]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Text2vis: A challenging and diverse benchmark for generating multimodal visualizations from text , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[60]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Dahiru Adamu Aliyu, Emelia Akashah Patah Akhir, Nurul Aida Osman, Jabir Abubakar Salisu, Yahaya Saidu, and Jameel Shehu Yalli. 2024. Optimization techniques in reinforcement learning for healthcare: A review. In 2024 8th International Conference on Computing, Communication, Control and Automation (ICCUBEA), pages 1--6. IEEE
2024
-
[62]
Anthropic . 2024. https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf The claude 3 model family: Opus, sonnet, haiku . Technical report, Anthropic. Accessed: 2024
2024
-
[63]
Abeer Badawi, Will Aitken, Lydia Sequeira, Jocelyn Rankin, Maia Norman, and Elham Dolatabadi. 2026 a . https://doi.org/10.48550/arXiv.2605.27546 Keyphrase generative representation of youth crisis conversations beyond static taxonomies . arXiv preprint arXiv:2605.27546
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.27546 2026
- [64]
-
[65]
Abeer Badawi, Md Tahmid Rahman Laskar, Elahe Rahimi, Sheri Grach, Lindsay Bertrand, Lames Danok, Frank Rudzicz, Jimmy Huang, and Elham Dolatabadi. 2026 b . Assessing the quality of mental health support in llm responses through multi-attribute human evaluation. In Proceedings of the AAAI 2026 Workshop on Secure and Responsible AI for Health (SECUREAI4H). ...
2026
-
[66]
Abeer Badawi, Elahe Rahimi, Md Tahmid Rahman Laskar, Sheri Grach, Lindsay Bertrand, Lames Danok, Jimmy Huang, Frank Rudzicz, and Elham Dolatabadi. 2025 b . When can we trust llms in mental health? large-scale benchmarks for reliable llm evaluation. arXiv preprint arXiv:2510.19032
-
[67]
Miguel Baidal, Erik Derner, and Nuria Oliver. 2025. https://doi.org/10.18653/v1/2025.nlp4pi-1.2 Guardians of trust: Risks and opportunities for llms in mental health . In Proceedings of the Fourth Workshop on NLP for Positive Impact (NLP4PI), pages 11--22, Vienna, Austria. Association for Computational Linguistics
-
[68]
Suhana Bedi, Yutong Liu, Lucy Orr-Ewing, Dev Dash, Sanmi Koyejo, Alison Callahan, Jason A Fries, Michael Wornow, Akshay Swaminathan, Lisa Soleymani Lehmann, and 1 others. 2025. Testing and evaluation of health care applications of large language models: a systematic review. Jama
2025
-
[69]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Emma Croxford, Yanjun Gao, Elliot First, Nicholas Pellegrino, Miranda Schnier, John Caskey, Madeline Oguss, Graham Wills, Guanhua Chen, Dmitriy Dligach, and 1 others. 2025. Automating evaluation of ai text generation in healthcare with a large language model (llm)-as-a-judge. medRxiv, pages 2025--04
2025
-
[71]
Patrick Fernandes, Mark Dras, Diana McCarthy, and Andreas Vlachos. 2023. https://aclanthology.org/2023.tacl-1.92/ Bridging the gap: A survey on integrating (human) feedback for natural language generation . Transactions of the Association for Computational Linguistics, 11:1515--1536
2023
- [72]
-
[73]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Zhijun Guo, Alvina Lai, Johan H Thygesen, Joseph Farrington, Thomas Keen, Kezhi Li, and 1 others. 2024. Large language models for mental health applications: systematic review. JMIR mental health, 11(1):e57400
2024
-
[75]
Therapygym: Evaluating and aligning clinical fidelity and safety in therapy chatbots
Fangrui Huang, Souhad Chbeir, Sheng Wang, Sijun Tan, Ryan Louie, Merryn Daniel, and Ehsan Adeli. Therapygym: Evaluating and aligning clinical fidelity and safety in therapy chatbots
- [76]
-
[77]
Tin Lai, Yukun Shi, Zicong Du, Jiajie Wu, Ken Fu, Yichao Dou, and Ziqi Wang. 2023. Supporting the demand on mental health services with ai-based conversational large language models (llms). BioMedInformatics, 4(1):8--33
2023
-
[78]
Md Tahmid Rahman Laskar, M Saiful Bari, Mizanur Rahman, Md Amran Hossen Bhuiyan, Shafiq Joty, and Jimmy Huang. 2023. A systematic study and comprehensive evaluation of chatgpt on benchmark datasets. In Findings of the Association for Computational Linguistics: ACL 2023, pages 431--469
2023
-
[79]
Hannah R Lawrence, Renee A Schneider, Susan B Rubin, Maja J Matari \'c , Daniel J McDuff, and Megan Jones Bell. 2024. The opportunities and risks of large language models in mental health. JMIR Mental Health, 11(1):e59479
2024
-
[80]
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, and 1 others. 2025. From generation to judgment: Opportunities and challenges of llm-as-a-judge. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2757--2791
2025
- [81]
-
[82]
Stephen et al. Obadinma. 2025. https://doi.org/10.1038/s41746-025-01647-6 The faiir conversational ai agent assistant for youth mental health service provision . npj Digital Medicine, 8(1):1--13
- [83]
-
[84]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
-
[85]
Dariya Ovsyannikova, Victoria Oldemburgo de Mello, and Michael Inzlicht. 2025. Third-party evaluators perceive ai as more compassionate than expert humans. Communications Psychology, 3(1):4
2025
-
[86]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728--53741
2023
- [87]
- [88]
-
[89]
Mizanur Rahman, Md Tahmid Rahman Laskar, Shafiq Joty, and Enamul Hoque. 2025 b . Text2vis: A challenging and diverse benchmark for generating multimodal visualizations from text. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 31837--31862
2025
-
[90]
Federico Ravenda, Seyed Ali Bahrainian, Andrea Raballo, Antonietta Mira, and Noriko Kando. 2025. https://doi.org/10.18653/v1/2025.acl-long.440 Are llms effective psychological assessors? leveraging adaptive rag for interpretable mental health screening through psychometric practice . In Proceedings of the 63rd Annual Meeting of the Association for Computa...
-
[91]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[92]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[93]
Elizabeth C Stade, Shannon Wiltsey Stirman, Lyle H Ungar, Cody L Boland, H Andrew Schwartz, David B Yaden, Jo \ a o Sedoc, Robert J DeRubeis, Robb Willer, and Johannes C Eichstaedt. 2024. Large language models could change the future of behavioral healthcare: a proposal for responsible development and evaluation. NPJ Mental Health Research, 3(1):12
2024
-
[94]
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Y Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica. 2024. Judgebench: A benchmark for evaluating llm-based judges. arXiv preprint arXiv:2410.12784
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[95]
Zhichao Wang, Bin Bi, Shiva Kumar Pentyala, Kiran Ramnath, Sougata Chaudhuri, Shubham Mehrotra, Xiang-Bo Mao, Sitaram Asur, and 1 others. 2024. A comprehensive survey of llm alignment techniques: Rlhf, rlaif, ppo, dpo and more. arXiv preprint arXiv:2407.16216
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[96]
Jia Xu, Tianyi Wei, Bojian Hou, Patryk Orzechowski, Shu Yang, Ruochen Jin, Rachael Paulbeck, Joost Wagenaar, George Demiris, and Li Shen. 2025. Mentalchat16k: A benchmark dataset for conversational mental health assistance. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, pages 5367--5378
2025
-
[97]
Xuhai Xu, Bingsheng Yao, Yuanzhe Dong, Saadia Gabriel, Hong Yu, James Hendler, Marzyeh Ghassemi, Anind K Dey, and Dakuo Wang. 2024. Mental-llm: Leveraging large language models for mental health prediction via online text data. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(1):1--32
2024
-
[98]
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, and 1 others. 2025. Qwen2. 5-1m technical report. arXiv preprint arXiv:2501.15383
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[99]
Kailai Yang, Tianlin Zhang, Ziyan Kuang, Qianqian Xie, Jimin Huang, and Sophia Ananiadou. 2024. Mentallama: interpretable mental health analysis on social media with large language models. In Proceedings of the ACM Web Conference 2024, pages 4489--4500
2024
-
[100]
Chao Yu, Jiming Liu, Shamim Nemati, and Guosheng Yin. 2021. Reinforcement learning in healthcare: A survey. ACM Computing Surveys (CSUR), 55(1):1--36
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.