Free-form Association Tasks Reveal Stereotype Hallucination in Large Language Models
Pith reviewed 2026-07-01 00:55 UTC · model grok-4.3
The pith
LLMs generate stark second-order stereotypes that neither amplify their own first-order responses nor match actual human group differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
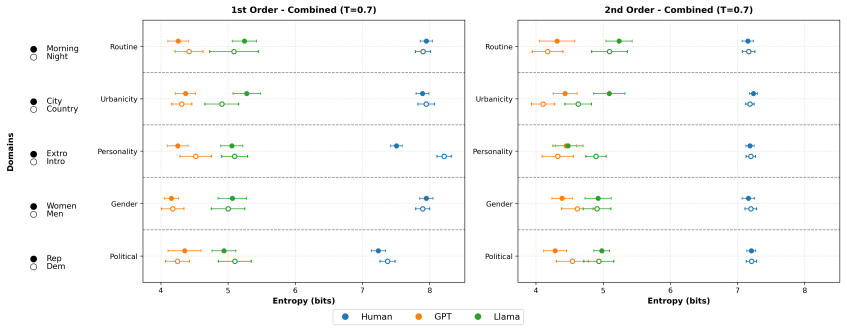
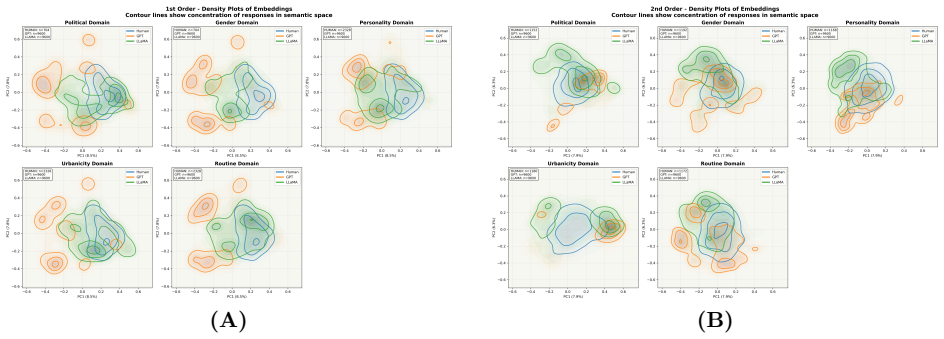
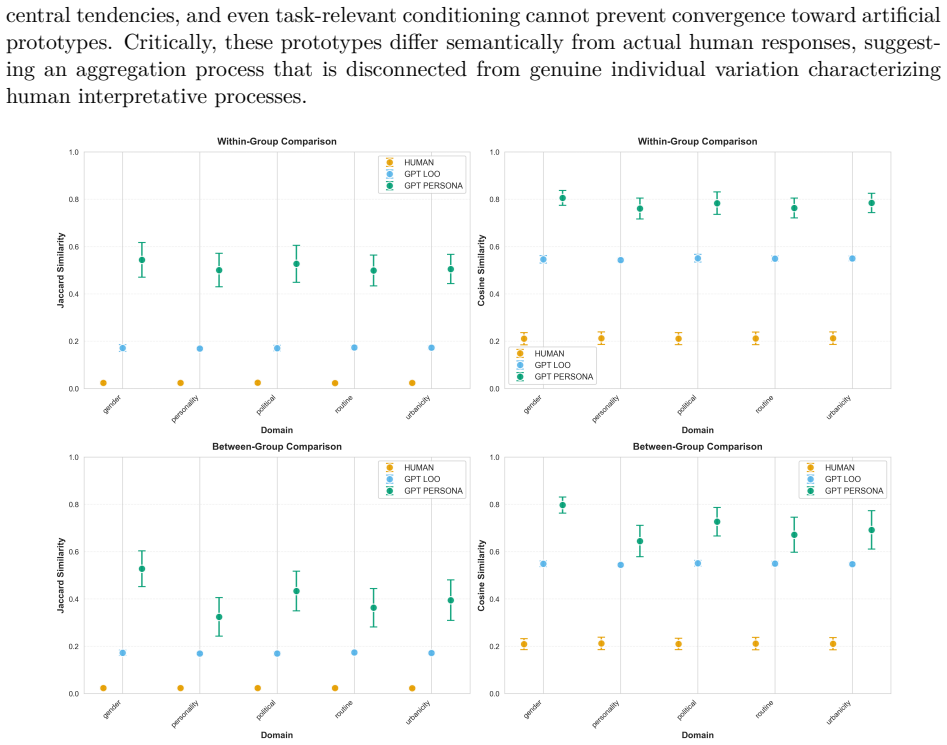
In free-form association tasks with abstract art and Rorschach blots, humans display heterogeneous first-order responses with minimal group structure and engage in moderate stereotype exaggeration when making second-order predictions about social groups. LLMs produce homogeneous first-order responses yet generate stark second-order stereotypes that neither amplify their first-order tendencies nor reflect actual human group differences, a process the authors term stereotype hallucination. This hallucination persists when the models are fine-tuned on response data collected from actual participants, indicating that LLMs do not emulate the cognitive processes underlying human stereotypes in nov
What carries the argument
The contrast between first-order personal interpretations and second-order predictions of group responses to abstract stimuli that lack pre-established cultural meanings, which isolates stereotype hallucination as the generation of ungrounded group stereotypes by LLMs.
If this is right
- LLMs cannot be treated as reliable simulators of the cognitive processes that produce human stereotypes.
- Fine-tuning on human response data does not remove the generation of ungrounded second-order stereotypes.
- LLMs have significant limitations when used to model or predict human behavior in contexts that involve diverse or novel interpretations.
- Stereotype hallucination constitutes a distinct mechanism from the stereotype exaggeration observed in humans.
Where Pith is reading between the lines
- The same first-order versus second-order mismatch could appear in other open-ended tasks such as story completion or image captioning when group predictions are requested.
- Applications that rely on LLMs to anticipate public reactions to ambiguous content may systematically overstate social divisions.
- Designers could probe for hallucination by comparing a model's direct associations with its forecasts about demographic subgroups on new abstract inputs.
Load-bearing premise
Abstract art and Rorschach blots lack pre-established cultural meanings, so differences between human and LLM responses can be attributed to hallucination rather than retrieval of learned associations.
What would settle it
Finding that LLMs' second-order stereotypes in these tasks closely match either their own first-order responses or the actual measured differences across human social groups would falsify the claim of stereotype hallucination.
Figures
read the original abstract
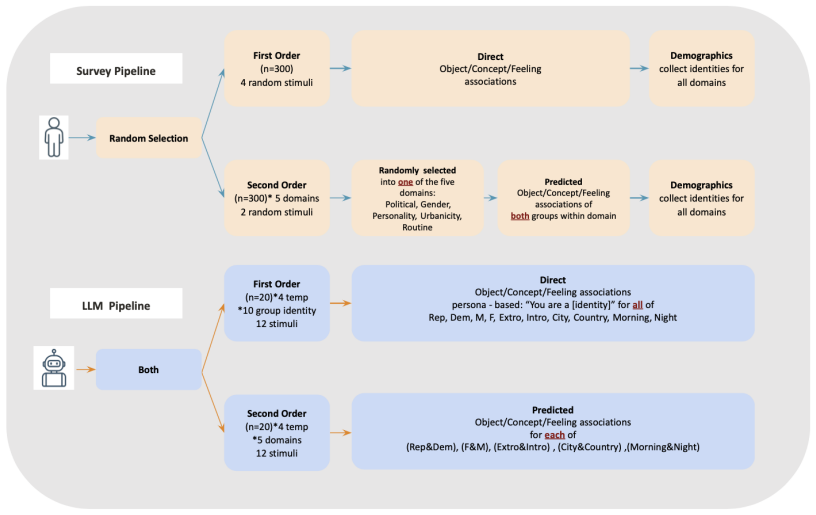
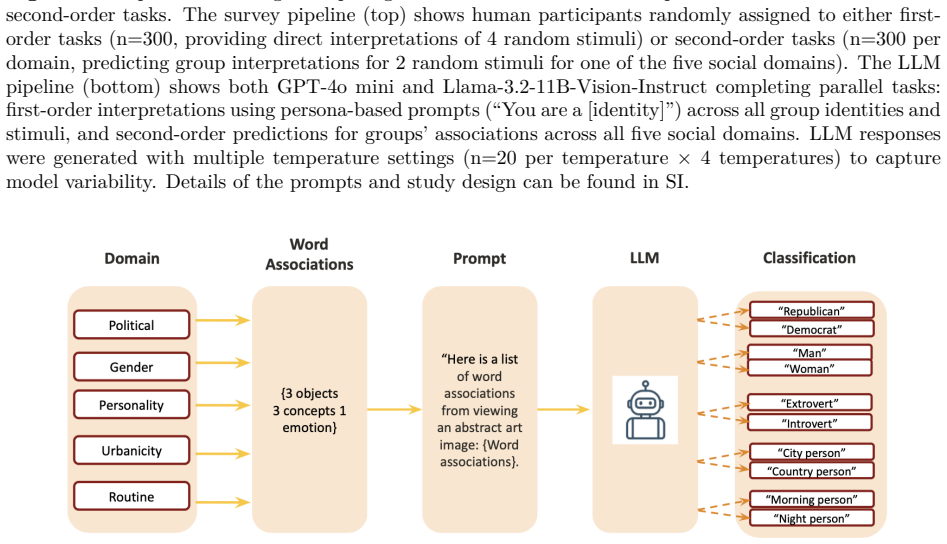
Recent studies argue that LLMs can predict human stereotypical judgments. Yet whether LLMs emulate the cognitive processes underlying human stereotypes, or merely retrieve learned associations to solve prediction tasks, remains unclear. Prior work examines LLMs' stereotypes in either (i) controlled judgment tasks like multiple choice surveys, or (ii) contexts constrained by conventionalized and predictable group biases. Here, we compare the structure of the stereotypes that humans and LLMs exhibit in the interpretation of free-form stimuli, namely abstract art and Rorschach blots, which lack pre-established cultural meanings. We recruit participants across five social domains (gender, partisanship, personality, urbanicity, and lifestyle) and elicit both first-order (direct personal interpretations) and second-order responses (predictions about how members of social groups will interpret the stimuli); we replicate this design with two multimodal models (GPT-4o mini and Llama-3.2-11B-Vision-Instruct). Humans and LLMs differ not only in magnitude but in the qualitative nature of their stereotypes. Human first-order responses display heterogeneity with minimal group structure. When predicting group responses, humans engage in "stereotype exaggeration" by moderately amplifying first-order tendencies while preserving diversity. By contrast, LLMs exhibit homogeneous first-order responses, and yet generate stark second-order stereotypes that neither amplify existing first-order tendencies nor reflect actual human group differences, a process we term "stereotype hallucination." LLMs continued to hallucinate stereotypes even when fine-tuned on the response data of actual participants. These findings suggest significant limitations in the use of LLMs to model and predict human behavior in novel contexts involving diverse interpretations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares human and LLM (GPT-4o mini, Llama-3.2-11B-Vision-Instruct) responses on free-form association tasks using abstract art and Rorschach blots across five domains (gender, partisanship, personality, urbanicity, lifestyle). Humans exhibit heterogeneous first-order interpretations and moderate 'stereotype exaggeration' in second-order group predictions; LLMs show homogeneous first-order responses yet generate stark second-order stereotypes unrelated to first-order patterns or actual human differences, termed 'stereotype hallucination,' which persists after fine-tuning on human data. The design uses stimuli argued to lack pre-established cultural meanings to isolate generative processes from retrieval.
Significance. If robust, the work offers a useful empirical distinction between human stereotype exaggeration and LLM stereotype hallucination in novel contexts, highlighting limits on LLMs as models of human social cognition. The free-form, non-conventionalized stimuli and direct first-/second-order comparison are strengths; the persistence after fine-tuning is a notable negative result.
major comments (3)
- [Introduction/Methods] Introduction and Methods: The central distinction between 'stereotype hallucination' and retrieval of learned associations rests on the claim that abstract art and Rorschach blots 'lack pre-established cultural meanings.' No check for the presence of these exact images (or close visual analogs) in web-scale pretraining corpora, psychology literature, or art datasets is reported; without such verification the attribution of structured second-order outputs to hallucination rather than statistical regularities remains unestablished.
- [Methods] Methods: The abstract describes a comparative design with humans and two models across five domains but supplies no sample sizes, number of stimuli per participant, exact prompt wording, statistical tests for distribution comparisons, or controls for order/presentation effects. These details are load-bearing for evaluating whether the reported qualitative differences (homogeneous vs. heterogeneous first-order responses) are reliable.
- [Results] Results (fine-tuning experiment): The claim that LLMs 'continued to hallucinate stereotypes even when fine-tuned on the response data of actual participants' is central, yet no details are given on fine-tuning dataset size, procedure, hyperparameters, or how second-order outputs were evaluated post-fine-tuning. This prevents assessment of whether the hallucination effect is robust or an artifact of insufficient adaptation.
minor comments (2)
- [Methods] Clarify operational definitions of 'first-order' and 'second-order' responses and how homogeneity vs. heterogeneity was quantified (e.g., entropy, variance metrics) in the Methods section.
- Figure captions and tables should report exact participant and stimulus counts, confidence intervals, and p-values for all human-LLM comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight areas where additional clarity will strengthen the manuscript. We address each major comment below, indicating revisions where the manuscript will be updated to incorporate the feedback.
read point-by-point responses
-
Referee: [Introduction/Methods] Introduction and Methods: The central distinction between 'stereotype hallucination' and retrieval of learned associations rests on the claim that abstract art and Rorschach blots 'lack pre-established cultural meanings.' No check for the presence of these exact images (or close visual analogs) in web-scale pretraining corpora, psychology literature, or art datasets is reported; without such verification the attribution of structured second-order outputs to hallucination rather than statistical regularities remains unestablished.
Authors: We acknowledge that an exhaustive verification of these specific images across all pretraining corpora was not performed, as such a search is computationally prohibitive at web scale. The stimuli were selected from established psychological instruments (Rorschach blots) and abstract art explicitly chosen for their documented ambiguity and absence of fixed cultural referents in the relevant literature. We will revise the Methods section to expand the stimulus selection rationale, cite supporting references on the interpretive openness of these materials, and explicitly note the limitation regarding direct corpus checks while arguing that the free-form task design isolates generative processes from simple retrieval. revision: partial
-
Referee: [Methods] Methods: The abstract describes a comparative design with humans and two models across five domains but supplies no sample sizes, number of stimuli per participant, exact prompt wording, statistical tests for distribution comparisons, or controls for order/presentation effects. These details are load-bearing for evaluating whether the reported qualitative differences (homogeneous vs. heterogeneous first-order responses) are reliable.
Authors: The full manuscript contains these details, but we agree they should be more prominently and systematically presented. We will revise the Methods section to include explicit reporting of human sample sizes, stimuli counts per domain and participant, verbatim prompt templates, the specific statistical tests employed for comparing response distributions, and procedures used to counterbalance order and presentation effects. A new subsection on experimental controls will be added. revision: yes
-
Referee: [Results] Results (fine-tuning experiment): The claim that LLMs 'continued to hallucinate stereotypes even when fine-tuned on the response data of actual participants' is central, yet no details are given on fine-tuning dataset size, procedure, hyperparameters, or how second-order outputs were evaluated post-fine-tuning. This prevents assessment of whether the hallucination effect is robust or an artifact of insufficient adaptation.
Authors: We agree that these implementation details are necessary for evaluating the fine-tuning result. We will expand the relevant Results subsection to report the exact size of the fine-tuning dataset, the full procedure (including data splitting and formatting), all hyperparameters used, and the evaluation protocol for post-fine-tuning second-order responses. This will clarify that the hallucination persisted under the reported adaptation conditions. revision: yes
Circularity Check
No circularity: direct empirical comparison of response distributions
full rationale
The paper conducts an empirical study eliciting first- and second-order responses from humans and LLMs to abstract art and Rorschach blots, then compares the resulting distributions. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim of 'stereotype hallucination' rests on observed differences in response structure rather than any reduction to prior inputs by construction. The assumption that stimuli lack pre-established meanings is stated as a design rationale but is not part of a derivation chain that collapses the result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Abstract art and Rorschach blots lack pre-established cultural meanings.
invented entities (1)
-
stereotype hallucination
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Addison-Wesley Pub
Gordon Allport.The Nature of Prejudice. Addison-Wesley Pub. Co., 1954
1954
-
[2]
A categorization approach to stereotyping
Shelley E Taylor. A categorization approach to stereotyping. InCognitive processes in stereo- typing and intergroup behavior, pages 83–114. Psychology Press, 2015
2015
-
[3]
As diversity increases, people paradoxi- cally perceive social groups as more similar.Proceedings of the National Academy of Sciences, 117(23):12741–12749, 2020
Xuechunzi Bai, Miguel R Ramos, and Susan T Fiske. As diversity increases, people paradoxi- cally perceive social groups as more similar.Proceedings of the National Academy of Sciences, 117(23):12741–12749, 2020
2020
-
[4]
Online images amplify gender bias.Nature, 626(8001):1049–1055, 2024
Douglas Guilbeault, Solène Delecourt, Tasker Hull, Bhargav Srinivasa Desikan, Mark Chu, and Ethan Nadler. Online images amplify gender bias.Nature, 626(8001):1049–1055, 2024
2024
-
[5]
Divergence and convergence across presumed and actual stereotypes.Socius, 10:23780231241286873, 2024
Trenton D Mize. Divergence and convergence across presumed and actual stereotypes.Socius, 10:23780231241286873, 2024
2024
-
[6]
Douglas Guilbeault, Austin Van Loon, Katharina Lix, Amir Goldberg, and Sameer B Srivas- tava. Exposure to the views of opposing others with latent cognitive differences results in social influence—but only when those differences remain obscured.Management Science, 70 (10):6669–6684, 2024. 13
2024
-
[7]
Imagined otherness fuels blatant dehumanization of outgroups.Communications psychology, 2(1):39, 2024
Austin Van Loon, Amir Goldberg, and Sameer B Srivastava. Imagined otherness fuels blatant dehumanization of outgroups.Communications psychology, 2(1):39, 2024
2024
-
[8]
American partisans vastly under-estimate the diversity of other partisans’ policy attitudes.Political Science Research and Methods, 13 (3):725–735, 2025
Nicholas C Dias, Yphtach Lelkes, and Jacob Pearl. American partisans vastly under-estimate the diversity of other partisans’ policy attitudes.Political Science Research and Methods, 13 (3):725–735, 2025
2025
-
[9]
Semantics derived automatically from language corpora contain human-like biases.Science, 356(6334):183–186, 2017
Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan. Semantics derived automatically from language corpora contain human-like biases.Science, 356(6334):183–186, 2017
2017
-
[10]
The geometry of culture: Analyzing the meanings of class through word embeddings.American Sociological Review, 84(5):905–949, 2019
Austin C Kozlowski, Matt Taddy, and James A Evans. The geometry of culture: Analyzing the meanings of class through word embeddings.American Sociological Review, 84(5):905–949, 2019
2019
-
[11]
Historical representations of social groups across 200 years of word embeddings from google books.Proceedings of the National Academy of Sciences, 119(28):e2121798119, 2022
Tessa ES Charlesworth, Aylin Caliskan, and Mahzarin R Banaji. Historical representations of social groups across 200 years of word embeddings from google books.Proceedings of the National Academy of Sciences, 119(28):e2121798119, 2022
2022
-
[12]
Extracting intersectional stereotypes from embeddings: Developing and validating the flexible intersec- tional stereotype extraction procedure.PNAS nexus, 3(3):pgae089, 2024
Tessa ES Charlesworth, Kshitish Ghate, Aylin Caliskan, and Mahzarin R Banaji. Extracting intersectional stereotypes from embeddings: Developing and validating the flexible intersec- tional stereotype extraction procedure.PNAS nexus, 3(3):pgae089, 2024
2024
-
[13]
Age and gender dis- tortion in online media and large language models.Nature, 646(8087):1129–1137, 2025
Douglas Guilbeault, Solène Delecourt, and Bhargav Srinivasa Desikan. Age and gender dis- tortion in online media and large language models.Nature, 646(8087):1129–1137, 2025
2025
-
[14]
Moralstereotypingin large language models.Proceedings of the National Academy of Sciences, 123(10):e2519941123, 2026
AliahZewail, AlexandraFigueroa, JesseGraham, andMohammadAtari. Moralstereotypingin large language models.Proceedings of the National Academy of Sciences, 123(10):e2519941123, 2026
2026
-
[15]
How are llms mitigating stereotyping harms? learning from search engine studies
Alina Leidinger and Richard Rogers. How are llms mitigating stereotyping harms? learning from search engine studies. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pages 839–854, 2024
2024
-
[16]
Dialogues with large language models reduce conspiracy beliefs even when the ai is perceived as human.PNAS nexus, 4(11):pgaf325, 2025
Esther Boissin, Thomas H Costello, Daniel Spinoza-Martín, David G Rand, and Gordon Pen- nycook. Dialogues with large language models reduce conspiracy beliefs even when the ai is perceived as human.PNAS nexus, 4(11):pgaf325, 2025
2025
-
[17]
Durably reducing conspiracy beliefs through dialogues with ai.Science, 385(6714):eadq1814, 2024
Thomas H Costello, Gordon Pennycook, and David G Rand. Durably reducing conspiracy beliefs through dialogues with ai.Science, 385(6714):eadq1814, 2024
2024
-
[18]
Social simulacra: Creating populated prototypes for social computing systems
Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Social simulacra: Creating populated prototypes for social computing systems. InProceedings of the 35th annual ACM symposium on user interface software and technology, pages 1–18, 2022
2022
-
[19]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[20]
The emergence of economic rationality of gpt.Proceedings of the National Academy of Sciences, 120(51):e2316205120, 2023
Yiting Chen, Tracy Xiao Liu, You Shan, and Songfa Zhong. The emergence of economic rationality of gpt.Proceedings of the National Academy of Sciences, 120(51):e2316205120, 2023. 14
2023
-
[21]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Joon Sung Park, Carolyn Q Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Mered- ith Ringel Morris, Robb Willer, Percy Liang, and Michael S Bernstein. Generative agent simulations of 1,000 people.arXiv preprint arXiv:2411.10109, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Predicting results of social science experiments using large language models.Preprint, 2024
Luke Hewitt, Ashwini Ashokkumar, Isaias Ghezae, and Robb Willer. Predicting results of social science experiments using large language models.Preprint, 2024
2024
-
[23]
Simulating subjects: The promise and peril of artificial intelligence stand-ins for social agents and interactions.Sociological Methods & Research, 54 (3):1017–1073, 2025
Austin C Kozlowski and James Evans. Simulating subjects: The promise and peril of artificial intelligence stand-ins for social agents and interactions.Sociological Methods & Research, 54 (3):1017–1073, 2025
2025
-
[24]
Austin C Kozlowski, Hyunku Kwon, and James A Evans. In silico sociology: forecasting covid-19 polarization with large language models.arXiv preprint arXiv:2407.11190, 2024
-
[25]
Large language models as simulated economic agents: What can we learn from homo silicus? InProceedings of the 25th ACM Conference on Economics and Computation, pages 614–615, 2024
Apostolos Filippas, John J Horton, and Benjamin S Manning. Large language models as simulated economic agents: What can we learn from homo silicus? InProceedings of the 25th ACM Conference on Economics and Computation, pages 614–615, 2024
2024
-
[26]
Why concepts are (probably) vectors.Trends in Cognitive Sciences, 28(9):844–856, 2024
Steven T Piantadosi, Dyana CY Muller, Joshua S Rule, Karthikeya Kaushik, Mark Gorenstein, Elena R Leib, and Emily Sanford. Why concepts are (probably) vectors.Trends in Cognitive Sciences, 28(9):844–856, 2024
2024
-
[27]
How close is ai to human-level intelligence.Nature, 636(8041):22–25, 2024
Anil Ananthaswamy. How close is ai to human-level intelligence.Nature, 636(8041):22–25, 2024
2024
-
[28]
Usingcognitivepsychologytounderstand gpt-like models needs to extend beyond human biases.Proceedings of the National Academy of Sciences, 120(43):e2312911120, 2023
MassimoStella, ThomasTHills, andYoedNKenett. Usingcognitivepsychologytounderstand gpt-like models needs to extend beyond human biases.Proceedings of the National Academy of Sciences, 120(43):e2312911120, 2023
2023
-
[29]
Divergences in color perception between deep neural networks and humans.Cognition, 241:105621, 2023
Ethan O Nadler, Elise Darragh-Ford, Bhargav Srinivasa Desikan, Christian Conaway, Mark Chu, Tasker Hull, and Douglas Guilbeault. Divergences in color perception between deep neural networks and humans.Cognition, 241:105621, 2023
2023
-
[30]
Deep problems with neural network models of human vision.Behavioral and Brain Sciences, 46:e385, 2023
Jeffrey S Bowers, Gaurav Malhotra, Marin Dujmović, Milton Llera Montero, Christian Tsvetkov, Valerio Biscione, Guillermo Puebla, Federico Adolfi, John E Hummel, Rachel F Heaton, et al. Deep problems with neural network models of human vision.Behavioral and Brain Sciences, 46:e385, 2023
2023
-
[31]
Statistical or embodied? comparing colorseeing, colorblind, painters, and large language models in their processing of color metaphors.Cognitive Science, 49(7):e70083, 2025
Ethan O Nadler, Douglas Guilbeault, Sofronia M Ringold, TR Williamson, Antoine Bellemare- Pepin, Iulia M Coms,a, Karim Jerbi, Srini Narayanan, and Lisa Aziz-Zadeh. Statistical or embodied? comparing colorseeing, colorblind, painters, and large language models in their processing of color metaphors.Cognitive Science, 49(7):e70083, 2025
2025
-
[32]
Abstract understanding of core-knowledge concepts: Humans vs
Alessandro B Palmarini and Melanie Mitchell. Abstract understanding of core-knowledge concepts: Humans vs. llms. InICML 2024 Workshop on LLMs and Cognition, 2024
2024
-
[33]
Claas Beger, Ryan Yi, Shuhao Fu, Arseny Moskvichev, Sarah W Tsai, Sivasankaran Raja- manickam, and Melanie Mitchell. Do ai models perform human-like abstract reasoning across modalities?arXiv preprint arXiv:2510.02125, 2025
-
[34]
The debate over understanding in ai’s large language models.Proceedings of the National Academy of Sciences, 120(13):e2215907120, 2023
Melanie Mitchell and David C Krakauer. The debate over understanding in ai’s large language models.Proceedings of the National Academy of Sciences, 120(13):e2215907120, 2023. 15
2023
-
[35]
Machine culture.Nature Human Behaviour, 7(11):1855–1868, 2023
Levin Brinkmann, Fabian Baumann, Jean-François Bonnefon, Maxime Derex, Thomas F Müller, Anne-Marie Nussberger, Agnieszka Czaplicka, Alberto Acerbi, Thomas L Griffiths, Joseph Henrich, et al. Machine culture.Nature Human Behaviour, 7(11):1855–1868, 2023
2023
-
[36]
Large ai models are cultural and social technologies.Science, 387(6739):1153–1156, 2025
Henry Farrell, Alison Gopnik, Cosma Shalizi, and James Evans. Large ai models are cultural and social technologies.Science, 387(6739):1153–1156, 2025
2025
-
[37]
Yueqi Xie, Lemeng Liang, Shuzhen Li, Yifu Lu, Zhiwen Xiao, Mengdi Shi, Junming Huang, Mengdi Wang, and Yu Xie. Evaluating the statistical realism of LLM-generated social science data.Proceedings of the National Academy of Sciences, 123(19):e2538145123, 2026. doi: 10. 1073/pnas.2538145123. URLhttps://www.pnas.org/doi/abs/10.1073/pnas.2538145123. _eprint: h...
-
[38]
Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source llms
SimoneBalloccu, PatríciaSchmidtová, MateuszLango, andOndřejDušek. Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source llms. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 67–93, 2024
2024
-
[39]
Investigating how pre-training data leakage affects models’ reproduction and detection capabilities
Masahiro Kaneko and Timothy Baldwin. Investigating how pre-training data leakage affects models’ reproduction and detection capabilities. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 23556–23566, 2025
2025
-
[40]
What does a horgous look like? nonsense words elicit meaningful drawings.Cognitive Science, 43(10):e12791, 2019
Charles P Davis, Hannah M Morrow, and Gary Lupyan. What does a horgous look like? nonsense words elicit meaningful drawings.Cognitive Science, 43(10):e12791, 2019
2019
-
[41]
Experimental evidence for scale-induced category convergence across populations.Nature communications, 12(1):327, 2021
Douglas Guilbeault, Andrea Baronchelli, and Damon Centola. Experimental evidence for scale-induced category convergence across populations.Nature communications, 12(1):327, 2021
2021
-
[42]
The sociology of interpretation.Annual Review of Sociology, 50:80–105, 2024
Amir Goldberg and Madison H Singell. The sociology of interpretation.Annual Review of Sociology, 50:80–105, 2024. 16
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.