When Reranking Hurts: Uncertainty-Based Gating for Few-Shot Reranking
Pith reviewed 2026-07-01 05:52 UTC · model grok-4.3
The pith
Reranking few-shot examples can degrade performance, but gating the step by model uncertainty cuts costs and raises accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
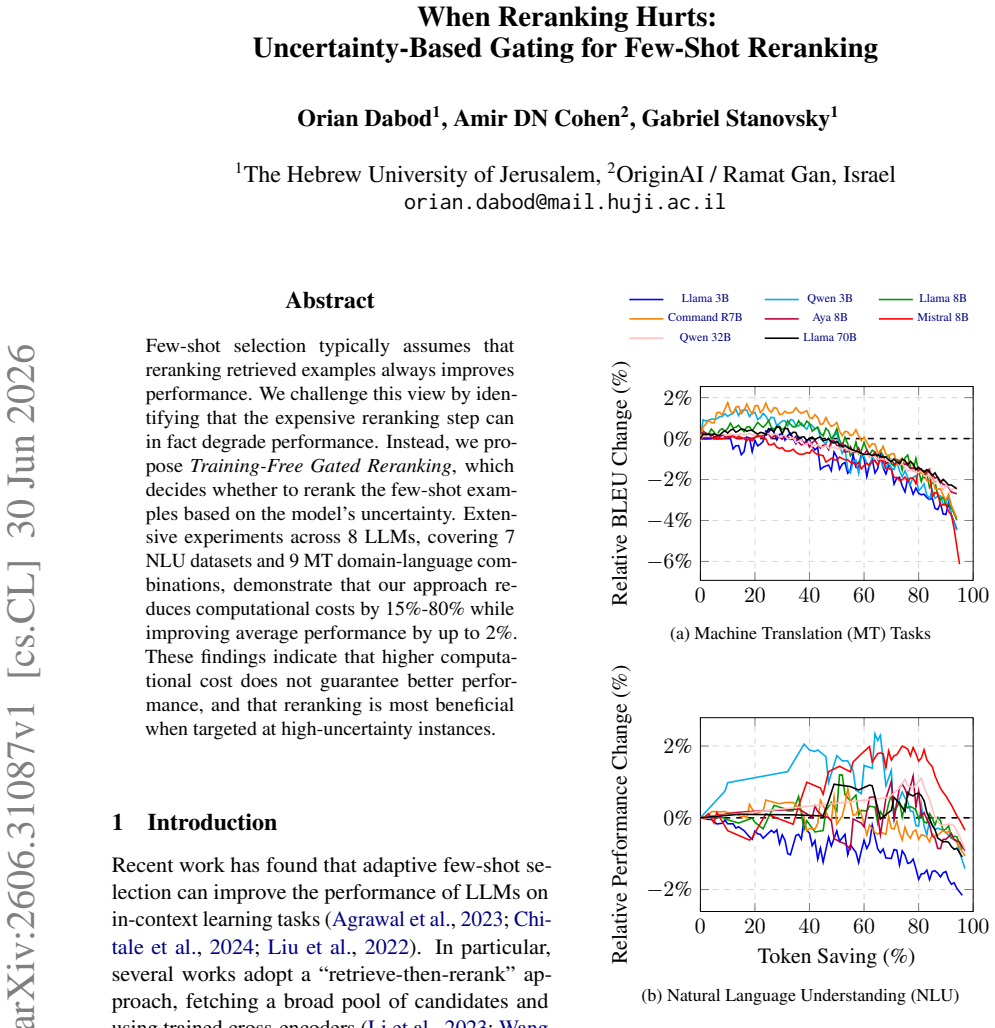
Reranking retrieved examples in few-shot selection does not always improve performance and can degrade it on certain instances; deciding whether to rerank based on the model's uncertainty produces lower computational cost and higher average performance across the tested models and datasets.
What carries the argument
Training-Free Gated Reranking, which decides whether to rerank few-shot examples based on the model's uncertainty.
If this is right
- Reranking should be applied selectively rather than to every retrieved set.
- Higher computational cost in few-shot prompting does not guarantee better results.
- Uncertainty can serve as a practical filter for when extra processing steps are useful.
- Computational savings of 15-80% are achievable without loss of accuracy and sometimes with gains.
Where Pith is reading between the lines
- The same gating idea could be tested on other costly refinement steps such as chain-of-thought verification.
- Different ways to measure uncertainty might change how often the gate opens or closes.
- The pattern may appear in retrieval-augmented generation pipelines outside the few-shot setting.
Load-bearing premise
Model uncertainty is a reliable signal for whether reranking will help or hurt on a given instance.
What would settle it
Finding that reranking improves performance on low-uncertainty instances or degrades it on high-uncertainty instances would falsify the gating approach.
Figures
read the original abstract
Few-shot selection typically assumes that reranking retrieved examples always improves performance. We challenge this view by identifying that the expensive reranking step can in fact degrade performance. Instead, we propose \emph{Training-Free Gated Reranking}, which decides whether to rerank the few-shot examples based on the model's uncertainty. Extensive experiments across 8 LLMs, covering 7 NLU datasets and 9 MT domain-language combinations, demonstrate that our approach reduces computational costs by 15\%-80\% while improving average performance by up to 2\%. These findings indicate that higher computational cost does not guarantee better performance, and that reranking is most beneficial when targeted at high-uncertainty instances.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper challenges the assumption that reranking retrieved few-shot examples always improves LLM performance. It identifies cases where reranking degrades results and proposes Training-Free Gated Reranking, which uses the model's uncertainty to decide whether to apply reranking on a per-instance basis. Experiments across 8 LLMs, 7 NLU datasets, and 9 MT domain-language pairs report 15-80% cost reductions and up to 2% average performance gains, concluding that reranking should be applied selectively to high-uncertainty instances.
Significance. If the uncertainty signal reliably identifies instances where reranking helps versus hurts, the work would provide a practical, training-free way to reduce inference cost while avoiding performance regressions in few-shot prompting. The empirical scope (multiple models and tasks) is a strength, but the result hinges on the unvalidated correlation between uncertainty and reranking benefit.
major comments (2)
- [Abstract] Abstract and method description: the central claim requires that the (unspecified) uncertainty metric predicts the sign of the reranking delta on a per-instance basis. No definition (entropy, token variance, etc.), no binned performance analysis, and no ablation removing the gate are described, leaving open whether the gate tracks harm/benefit or simply acts as a difficulty proxy.
- [Experiments] Experimental section: the reported 15-80% cost savings and +2% gains are presented as averages across 8 LLMs and 16 settings, but no per-dataset or per-model breakdowns, statistical significance tests, or controls for confounders (prompt length, retrieval method) are mentioned, making it impossible to assess whether the gating effect is robust or driven by a subset of conditions.
minor comments (2)
- Notation for uncertainty and gating threshold should be introduced with an equation or pseudocode for reproducibility.
- [Abstract] The abstract states 'improving average performance by up to 2%' without clarifying whether this is absolute or relative accuracy/F1/BLEU.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and provide additional supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central claim requires that the (unspecified) uncertainty metric predicts the sign of the reranking delta on a per-instance basis. No definition (entropy, token variance, etc.), no binned performance analysis, and no ablation removing the gate are described, leaving open whether the gate tracks harm/benefit or simply acts as a difficulty proxy.
Authors: We agree that the abstract and method description should more explicitly define the uncertainty metric and provide supporting analyses. In the revision we will specify the metric (entropy over the model's output token distribution) directly in the abstract, add a binned analysis of reranking deltas stratified by uncertainty quantiles to demonstrate the correlation with benefit versus harm, and include an ablation that removes the gate entirely. These changes will clarify that the gate is not merely a difficulty proxy but selectively applies reranking where it improves outcomes. revision: yes
-
Referee: [Experiments] Experimental section: the reported 15-80% cost savings and +2% gains are presented as averages across 8 LLMs and 16 settings, but no per-dataset or per-model breakdowns, statistical significance tests, or controls for confounders (prompt length, retrieval method) are mentioned, making it impossible to assess whether the gating effect is robust or driven by a subset of conditions.
Authors: We acknowledge that aggregated averages alone limit assessment of robustness. The revised manuscript will include full per-dataset and per-model tables reporting accuracy, cost savings, and deltas for all 8 LLMs and 16 settings. We will add paired statistical significance tests across conditions and report controls for prompt length (with and without reranking) as well as confirmation that the underlying retrieval method remains fixed. These additions will allow readers to verify that gains are not driven by outliers. revision: yes
Circularity Check
No circularity: purely empirical method with no derivation or fitted parameters
full rationale
The paper proposes Training-Free Gated Reranking as an empirical technique that gates reranking based on model uncertainty, validated through experiments on 8 LLMs across 7 NLU and 9 MT settings. No equations, parameter fitting, self-definitional claims, or load-bearing self-citations appear in the provided text. The central result (cost reduction + performance gain) is presented as an observed outcome of the gating rule rather than a quantity derived from or equivalent to its own inputs by construction. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Way, Andy , booktitle =
Moslem, Yasmin and Haque, Rejwanul and Kelleher, John D. and Way, Andy , booktitle =. Adaptive Machine Translation with Large Language Models , url =
-
[2]
Nearest Neighbor Machine Translation , url =
Urvashi Khandelwal and Angela Fan and Dan Jurafsky and Luke Zettlemoyer and Mike Lewis , bibsource =. Nearest Neighbor Machine Translation , url =. 9th International Conference on Learning Representations,
-
[3]
Neural Machine Translation with Monolingual Translation Memory , url =
Cai, Deng and Wang, Yan and Li, Huayang and Lam, Wai and Liu, Lemao , booktitle =. Neural Machine Translation with Monolingual Translation Memory , url =. doi:10.18653/v1/2021.acl-long.567 , editor =
-
[4]
Narrowing the Gap between Zero- and Few-shot Machine Translation by Matching Styles , url =
Tan, Weiting and Xu, Haoran and Shen, Lingfeng and Li, Shuyue Stella and Murray, Kenton and Koehn, Philipp and Van Durme, Benjamin and Chen, Yunmo , booktitle =. Narrowing the Gap between Zero- and Few-shot Machine Translation by Matching Styles , url =
-
[5]
RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs , url =
Yue Yu and Wei Ping and Zihan Liu and Boxin Wang and Jiaxuan You and Chao Zhang and Mohammad Shoeybi and Bryan Catanzaro , bibsource =. RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs , url =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, V...
2024
-
[6]
Adaptive-
Jeong, Soyeong and Baek, Jinheon and Cho, Sukmin and Hwang, Sung Ju and Park, Jong , booktitle =. Adaptive-
-
[7]
TARG: Training-Free Adaptive Retrieval Gating for Efficient RAG , url =
Yufeng Wang and Lu wei and Haibin Ling , journal =. TARG: Training-Free Adaptive Retrieval Gating for Efficient RAG , url =
-
[8]
Dynamic and Parametric Retrieval-Augmented Generation , url =
Weihang Su and Qingyao Ai and Jingtao Zhan and Qian Dong and Yiqun Liu , journal =. Dynamic and Parametric Retrieval-Augmented Generation , url =
-
[9]
Revisiting Demonstration Selection Strategies in In-Context Learning , url =
Keqin Peng and Liang Ding and Yancheng Yuan and Xuebo Liu and Min Zhang and Yuanxin Ouyang and Dacheng Tao , journal =. Revisiting Demonstration Selection Strategies in In-Context Learning , url =
-
[10]
Andrey Malinin and Mark J. F. Gales , bibsource =. Uncertainty Estimation in Autoregressive Structured Prediction , url =. 9th International Conference on Learning Representations,
-
[11]
Weinberger , bibsource =
Chuan Guo and Geoff Pleiss and Yu Sun and Kilian Q. Weinberger , bibsource =. On Calibration of Modern Neural Networks , url =. Proceedings of the 34th International Conference on Machine Learning,
-
[12]
Witbrock, Michael and Padriac Amato Tahua O
Pistotti, Timothy and J. Witbrock, Michael and Padriac Amato Tahua O. The Benefits of Being Uncertain: Perplexity as a Signal for Naturalness in Multilingual Machine Translation , url =. Proceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025) , doi =
2025
-
[13]
Revisiting Logit Distributions for Reliable Out-of-Distribution Detection , url =
Jiachen Liang and Ruibing Hou and Minyang Hu and Hong Chang and Shiguang Shan and Xilin Chen , journal =. Revisiting Logit Distributions for Reliable Out-of-Distribution Detection , url =
-
[14]
Aaron Grattafiori and Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Alex Vaughan and Amy Yang and Angela Fan and Anirudh Goyal and Anthony Hartshorn and Aobo Yang and Archi Mitra and Archie Sravankumar and Artem Korenev and Arthur Hinsvark and Arun Rao ...
-
[15]
Qwen2.5 Technical Report , url =
Qwen and : and An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu an...
-
[16]
Qwen3 Technical Report , url =
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and...
-
[17]
Albert Q. Jiang and Alexandre Sablayrolles and Arthur Mensch and Chris Bamford and Devendra Singh Chaplot and Diego de las Casas and Florian Bressand and Gianna Lengyel and Guillaume Lample and Lucile Saulnier and Lélio Renard Lavaud and Marie-Anne Lachaux and Pierre Stock and Teven Le Scao and Thibaut Lavril and Thomas Wang and Timothée Lacroix and Willi...
-
[18]
Shivalika Singh and Freddie Vargus and Daniel Dsouza and Börje F. Karlsson and Abinaya Mahendiran and Wei-Yin Ko and Herumb Shandilya and Jay Patel and Deividas Mataciunas and Laura OMahony and Mike Zhang and Ramith Hettiarachchi and Joseph Wilson and Marina Machado and Luisa Souza Moura and Dominik Krzemiński and Hakimeh Fadaei and Irem Ergün and Ifeoma ...
-
[19]
Parallel Data, Tools and Interfaces in
Tiedemann, J. Parallel Data, Tools and Interfaces in. Proceedings of the Eighth International Conference on Language Resources and Evaluation (
-
[20]
Steinberger, Ralf and Pouliquen, Bruno and Widiger, Anna and Ignat, Camelia and Erjavec, Toma. The. Proceedings of the Fifth International Conference on Language Resources and Evaluation (
-
[21]
BLEU : a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , booktitle =. doi:10.3115/1073083.1073135 , editor =
-
[22]
and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C
Rei, Ricardo and Treviso, Marcos and Guerreiro, Nuno M. and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C. de Souza, Jos. Proceedings of the Seventh Conference on Machine Translation (WMT) , editor =
-
[23]
Popovi. chr. Proceedings of the Tenth Workshop on Statistical Machine Translation , doi =
-
[24]
Text Embeddings by Weakly-Supervised Contrastive Pre-training , url =
Liang Wang and Nan Yang and Xiaolong Huang and Binxing Jiao and Linjun Yang and Daxin Jiang and Rangan Majumder and Furu Wei , journal =. Text Embeddings by Weakly-Supervised Contrastive Pre-training , url =
-
[25]
Robertson and Hugo Zaragoza , journal =
Stephen E. Robertson and Hugo Zaragoza , journal =. The Probabilistic Relevance Framework: BM25 and Beyond , url =
-
[26]
Six Challenges for Neural Machine Translation , url =
Koehn, Philipp and Knowles, Rebecca , booktitle =. Six Challenges for Neural Machine Translation , url =. doi:10.18653/v1/W17-3204 , editor =
-
[27]
Multilingual E5 Text Embeddings: A Technical Report , url =
Liang Wang and Nan Yang and Xiaolong Huang and Linjun Yang and Rangan Majumder and Furu Wei , journal =. Multilingual E5 Text Embeddings: A Technical Report , url =
-
[28]
In-Context Example Selection via Similarity Search Improves Low-Resource Machine Translation , url =
Zebaze, Armel Randy and Sagot, Beno. In-Context Example Selection via Similarity Search Improves Low-Resource Machine Translation , url =. Findings of the Association for Computational Linguistics: NAACL 2025 , doi =
2025
-
[29]
Efficiently Scaling Transformer Inference , url =
Reiner Pope and Sholto Douglas and Aakanksha Chowdhery and Jacob Devlin and James Bradbury and Anselm Levskaya and Jonathan Heek and Kefan Xiao and Shivani Agrawal and Jeff Dean , journal =. Efficiently Scaling Transformer Inference , url =
-
[30]
Chitale and Jay Gala and Raj Dabre , journal =
Pranjal A. Chitale and Jay Gala and Raj Dabre , journal =. An Empirical Study of In-context Learning in LLMs for Machine Translation , url =
-
[31]
Is ChatGPT A Good Translator? Yes With GPT-4 As The Engine , url =
Wenxiang Jiao and Wenxuan Wang and Jen-tse Huang and Xing Wang and Shuming Shi and Zhaopeng Tu , journal =. Is ChatGPT A Good Translator? Yes With GPT-4 As The Engine , url =
-
[32]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , url =. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Informa...
2020
-
[33]
Vilar, David and Freitag, Markus and Cherry, Colin and Luo, Jiaming and Ratnakar, Viresh and Foster, George , booktitle =. Prompting. doi:10.18653/v1/2023.acl-long.859 , editor =
-
[34]
Prompting Large Language Model for Machine Translation:
Biao Zhang and Barry Haddow and Alexandra Birch , bibsource =. Prompting Large Language Model for Machine Translation:. International Conference on Machine Learning,
-
[35]
In-context Examples Selection for Machine Translation , url =
Agrawal, Sweta and Zhou, Chunting and Lewis, Mike and Zettlemoyer, Luke and Ghazvininejad, Marjan , booktitle =. In-context Examples Selection for Machine Translation , url =. doi:10.18653/v1/2023.findings-acl.564 , editor =
-
[36]
What Makes Good In-Context Examples for
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu , booktitle =. What Makes Good In-Context Examples for. doi:10.18653/v1/2022.deelio-1.10 , editor =
-
[37]
Adaptive Few-shot Prompting for Machine Translation with Pre-trained Language Models , url =
Lei Tang and Jinghui Qin and Wenxuan Ye and Hao Tan and Zhijing Yang , journal =. Adaptive Few-shot Prompting for Machine Translation with Pre-trained Language Models , url =
-
[38]
Improving Passage Retrieval with Zero-Shot Question Generation , url =
Sachan, Devendra and Lewis, Mike and Joshi, Mandar and Aghajanyan, Armen and Yih, Wen-tau and Pineau, Joelle and Zettlemoyer, Luke , booktitle =. Improving Passage Retrieval with Zero-Shot Question Generation , url =. doi:10.18653/v1/2022.emnlp-main.249 , editor =
-
[39]
Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , journal =
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , journal =. Scaling Laws for Neural Language Models , url =
-
[40]
Learning to Retrieve In-Context Examples for Large Language Models , url =
Wang, Liang and Yang, Nan and Wei, Furu , booktitle =. Learning to Retrieve In-Context Examples for Large Language Models , url =
-
[41]
Unified Demonstration Retriever for In-Context Learning , url =
Li, Xiaonan and Lv, Kai and Yan, Hang and Lin, Tianyang and Zhu, Wei and Ni, Yuan and Xie, Guotong and Wang, Xiaoling and Qiu, Xipeng , booktitle =. Unified Demonstration Retriever for In-Context Learning , url =. doi:10.18653/v1/2023.acl-long.256 , editor =
-
[42]
Demystifying Prompts in Language Models via Perplexity Estimation , url =
Gonen, Hila and Iyer, Srini and Blevins, Terra and Smith, Noah and Zettlemoyer, Luke , booktitle =. Demystifying Prompts in Language Models via Perplexity Estimation , url =. doi:10.18653/v1/2023.findings-emnlp.679 , editor =
-
[43]
and Ng, Andrew and Potts, Christopher , booktitle =
Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D. and Ng, Andrew and Potts, Christopher , booktitle =. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank , url =
-
[44]
Bowman , bibsource =
Alex Wang and Amanpreet Singh and Julian Michael and Felix Hill and Omer Levy and Samuel R. Bowman , bibsource =. 7th International Conference on Learning Representations,
-
[45]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference , url =
Williams, Adina and Nangia, Nikita and Bowman, Samuel , booktitle =. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference , url =. doi:10.18653/v1/N18-1101 , editor =
work page internal anchor Pith review doi:10.18653/v1/n18-1101
-
[46]
M\'elange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity , url =
Tyler Griggs and Xiaoxuan Liu and Jiaxiang Yu and Doyoung Kim and Wei-Lin Chiang and Alvin Cheung and Ion Stoica , journal =. M\'elange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity , url =
-
[47]
Learning To Retrieve Prompts for In-Context Learning , url =
Rubin, Ohad and Herzig, Jonathan and Berant, Jonathan , booktitle =. Learning To Retrieve Prompts for In-Context Learning , url =. doi:10.18653/v1/2022.naacl-main.191 , editor =
-
[48]
Wu, Zhiyong and Wang, Yaoxiang and Ye, Jiacheng and Kong, Lingpeng , booktitle =. Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering , url =. doi:10.18653/v1/2023.acl-long.79 , editor =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.