Towards Flexible, Natural, Efficient Interaction for Conversational Talking Face Generation
Pith reviewed 2026-07-01 06:24 UTC · model grok-4.3
The pith
InterTalk generates conversational talking faces for arbitrary numbers of participants at 30 FPS by modeling multi-round dynamics and disentangling facial motions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
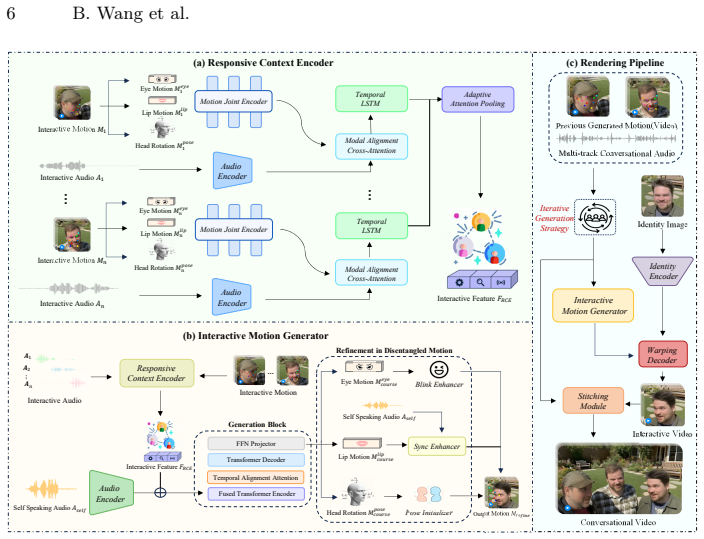
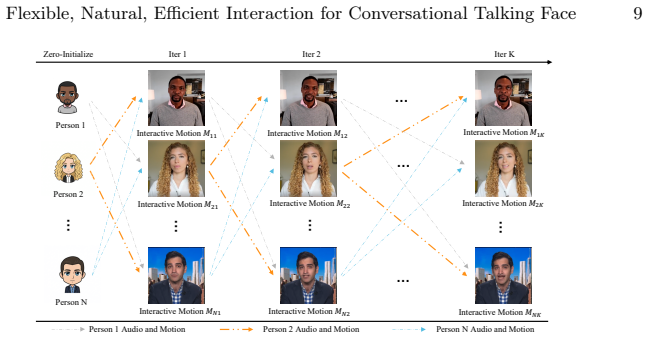
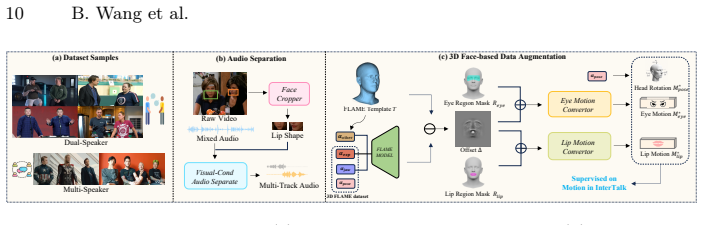
InterTalk, built upon a motion-based architecture, supports real-time conversation synthesis by explicitly modeling multi-round conversational dynamics among each participant without constraints on their numbers, incorporating motion feedback from multiple participants along with an iterative generation strategy for natural behaviors, and disentangling motion into several facial components to enable targeted refinements such as precise lip sync and realistic eye blinking, while introducing a new multi-person conversational dataset with 3D face-based data augmentation.
What carries the argument
InterTalk framework that disentangles motion into facial components while incorporating multi-participant motion feedback and iterative generation to handle multi-round dynamics.
If this is right
- Supports conversations with any number of participants without fixed limits.
- Maintains coherent motion and appropriate non-verbal feedback across multi-round exchanges.
- Delivers real-time performance at 30 FPS with low computation for continuous online use.
- Enables targeted refinements for specific facial actions such as lip synchronization and eye blinking.
- Relies on the introduced dataset to achieve superior interaction quality over prior methods.
Where Pith is reading between the lines
- The component disentanglement could be applied to control other animation elements like head pose or gesture in extended systems.
- The dataset construction approach might serve as a template for creating benchmarks in related multi-agent visual interaction tasks.
- Real-time capability opens direct paths to deployment in live virtual environments without additional optimization steps.
- Explicit dynamics modeling might reduce the need for post-processing corrections in generated sequences.
Load-bearing premise
The new multi-person conversational dataset and 3D face-based data augmentation suffice to train models that generalize to arbitrary participant counts and natural non-verbal behaviors.
What would settle it
A controlled test where the trained model produces unnatural or incoherent responses when the number of conversation participants or the variety of non-verbal cues exceeds the range seen in the augmented training data.
Figures




read the original abstract
Conversational talking face generation has recently attracted increasing attention, aiming to synthesize interactive talking videos where characters speak, listen, and respond dynamically to each other. This task presents three core challenges: 1) Flexibility: enabling multi-round dialogues with an arbitrary number of participants; 2) Naturalness: maintaining coherent motion and appropriate non-verbal feedback throughout the interaction; and 3) Efficiency: achieving real-time generation and low computation overhead for long-term continuous online conversation. Despite recent advances, existing methods still fall short in balancing all three requirements. To bridge this gap, we introduce InterTalk, a novel and efficient framework designed for highly interactive conversational talking face generation. Built upon a motion-based architecture, InterTalk supports real-time conversation synthesis. Our method achieves strong flexibility by explicitly modeling multi-round conversational dynamics among each participant, eliminating constraints on their numbers. To enhance interactivity, we incorporate motion feedback from multiple participants and introduce an iterative generation strategy for more natural behaviors. Besides, we disentangle motion into several facial components, enabling targeted refinements for natural response such as precise lip sync and realistic eye blinking. Finally, we construct a new multi-person conversational dataset and enrich it with 3D face-based data augmentation. Extensive experiments demonstrate that InterTalk achieves superior interaction quality while maintaining real-time performance at 30 FPS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes InterTalk, a motion-based framework for conversational talking face generation supporting multi-round dialogues among an arbitrary number of participants. It incorporates motion feedback, an iterative generation strategy, and disentangles motion into facial components (e.g., for lip sync and eye blinking) to improve naturalness, while claiming real-time performance at 30 FPS. A new multi-person conversational dataset is introduced along with 3D face-based data augmentation, and experiments are said to demonstrate superior interaction quality over prior methods.
Significance. If the central claims hold after addressing validation gaps, the work would advance conversational avatar synthesis by tackling flexibility for variable participant counts, natural non-verbal feedback, and real-time efficiency in a unified framework. The introduction of a dedicated multi-person dataset and 3D augmentation technique represent concrete contributions that could support future research, provided the dataset is released with clear licensing and documentation.
major comments (2)
- [§4.2] §4.2 (Dataset and Augmentation): The central flexibility claim—that explicit multi-round modeling plus the new dataset enables generalization to arbitrary participant counts and natural non-verbal behaviors without post-hoc tuning—rests entirely on internal evaluations; no cross-dataset testing or external benchmarks are reported, leaving open whether the modeling choices transfer beyond the training distribution's participant statistics and behavior patterns.
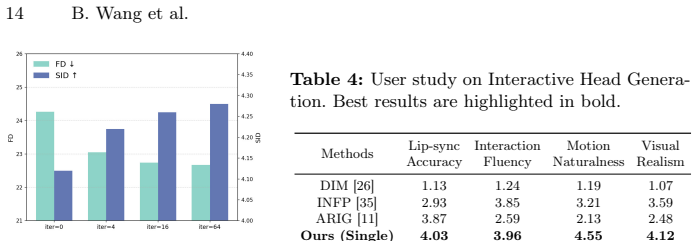
- [§5.1] §5.1 (Quantitative Results): The reported superiority in interaction quality and the 30 FPS real-time claim are presented without ablation studies isolating the contribution of motion feedback, iterative generation, or component disentanglement, nor with error bars or statistical tests on the metrics; this weakens the ability to attribute gains specifically to the proposed components rather than dataset differences.
minor comments (2)
- The related work section would benefit from explicit comparison tables contrasting prior methods on the three axes (flexibility, naturalness, efficiency) to better position the contributions.
- Figure captions for qualitative results should specify the exact number of participants and dialogue rounds shown to allow readers to assess the flexibility claim visually.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications on our design choices and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Dataset and Augmentation): The central flexibility claim—that explicit multi-round modeling plus the new dataset enables generalization to arbitrary participant counts and natural non-verbal behaviors without post-hoc tuning—rests entirely on internal evaluations; no cross-dataset testing or external benchmarks are reported, leaving open whether the modeling choices transfer beyond the training distribution's participant statistics and behavior patterns.
Authors: The new dataset is the first dedicated multi-person conversational resource, which precludes direct cross-dataset testing against prior single-person or non-conversational benchmarks. The flexibility claim is supported by the architecture's explicit per-participant multi-round modeling, which is independent of participant count; this is validated through controlled experiments on our dataset that vary the number of participants while maintaining performance. We will add a dedicated paragraph in §4.2 and the discussion section acknowledging the limitation of external benchmarks and explaining why the modeling choices promote generalization. revision: partial
-
Referee: [§5.1] §5.1 (Quantitative Results): The reported superiority in interaction quality and the 30 FPS real-time claim are presented without ablation studies isolating the contribution of motion feedback, iterative generation, or component disentanglement, nor with error bars or statistical tests on the metrics; this weakens the ability to attribute gains specifically to the proposed components rather than dataset differences.
Authors: We agree that isolating the contributions of motion feedback, iterative generation, and component disentanglement via ablations, along with error bars and statistical tests, would strengthen the quantitative section. In the revised manuscript we will add these ablation studies (removing each component in turn) and report standard deviations across runs with paired statistical tests on the primary metrics. revision: yes
Circularity Check
No significant circularity; claims rest on new dataset and experimental comparisons
full rationale
The paper introduces InterTalk with explicit modeling of multi-round dynamics, motion feedback, and component disentanglement, then reports results after constructing a new multi-person dataset with 3D augmentation. No equations, fitted parameters, or self-citations are described that reduce performance claims to self-referential definitions or force predictions by construction. Results are internal to the introduced dataset, but this is standard practice and does not constitute circularity under the specified patterns (no self-definitional relations, no fitted-input predictions, no load-bearing self-citation chains). The derivation chain is self-contained against its own benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems33, 12449–12460 (2020)
Baevski, A., Zhou, Y., Mohamed, A., Auli, M.: wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems33, 12449–12460 (2020)
2020
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Z., Cao, J., Chen, Z., Li, Y., Ma, C.: Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2403–2410 (2025) 16 B. Wang et al
2025
-
[4]
In: Work- shop on Multi-view Lip-reading, ACCV (2016)
Chung, J.S., Zisserman, A.: Out of time: automated lip sync in the wild. In: Work- shop on Multi-view Lip-reading, ACCV (2016)
2016
-
[5]
arXiv preprint arXiv:2410.07718 (2024)
Cui, J., Li, H., Yao, Y., Zhu, H., Shang, H., Cheng, K., Zhou, H., Zhu, S., Wang, J.: Hallo2: Long-duration and high-resolution audio-driven portrait image animation. arXiv preprint arXiv:2410.07718 (2024)
-
[6]
Daněček, R., Black, M.J., Bolkart, T.: Emoca: Emotion driven monocular face captureandanimation.In:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition. pp. 20311–20322 (2022)
2022
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fan, Y., Lin, Z., Saito, J., Wang, W., Komura, T.: Faceformer: Speech-driven 3d facial animation with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18770–18780 (2022)
2022
-
[8]
Advances in neural in- formation processing systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural in- formation processing systems27(2014)
2014
-
[9]
Google: Veo 3.https://aistudio.google.com/models/veo-3(2025),https:// aistudio.google.com/models/veo-3
2025
-
[10]
Liveportrait: Efficient portrait animation with stitching and retargeting control,
Guo, J., Zhang, D., Liu, X., Zhong, Z., Zhang, Y., Wan, P., Zhang, D.: Liveportrait: Efficient portrait animation with stitching and retargeting control. arXiv preprint arXiv:2407.03168 (2024)
-
[11]
arXiv preprint arXiv:2507.00472 (2025)
Guo, Y., Liu, X., Zhen, C., Yan, P., Wei, X.: Arig: Autoregressive interactive head generation for real-time conversations. arXiv preprint arXiv:2507.00472 (2025)
-
[12]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ji, X., Hu, X., Xu, Z., Zhu, J., Lin, C., He, Q., Zhang, J., Luo, D., Chen, Y., Lin, Q., et al.: Sonic: Shifting focus to global audio perception in portrait animation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 193–203 (2025)
2025
-
[13]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[14]
arXiv preprint arXiv:2505.22647 (2025)
Kong, Z., Gao, F., Zhang, Y., Kang, Z., Wei, X., Cai, X., Chen, G., Luo, W.: Let them talk: Audio-driven multi-person conversational video generation. arXiv preprint arXiv:2505.22647 (2025)
-
[15]
In: Proceedings of the 41st International Conference on Machine Learning
Li, K., Yang, R., Sun, F., Hu, X.: Iianet: an intra-and inter-modality attention net- work for audio-visual speech separation. In: Proceedings of the 41st International Conference on Machine Learning. pp. 29181–29200 (2024)
2024
-
[16]
ACM Transactions on Graphics, (Proc
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)36(6), 194:1–194:17 (2017),https://doi.org/10.1145/3130800.3130813
-
[17]
completely blind
Mittal, A., Soundararajan, R., Bovik, A.C.: Making a “completely blind” image quality analyzer. IEEE Signal processing letters20(3), 209–212 (2012)
2012
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ng, E., Joo, H., Hu, L., Li, H., Darrell, T., Kanazawa, A., Ginosar, S.: Learning to listen: Modeling non-deterministic dyadic facial motion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20395– 20405 (2022)
2022
-
[19]
OpenAI: Sora: Creating video from text.https://sora.chatgpt.com(2024), https://sora.chatgpt.com, accessed: 2024-11-05
2024
-
[20]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[21]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Peng,Z.,Fan,Y.,Wu,H.,Wang,X.,Liu,H.,He,J.,Fan,Z.:Dualtalk:Dual-speaker interaction for 3d talking head conversations. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21055–21064 (2025) Flexible, Natural, Efficient Interaction for Conversational Talking Face 17
2025
-
[22]
In: Proceedings of the 28th ACM international conference on multimedia
Prajwal, K., Mukhopadhyay, R., Namboodiri, V.P., Jawahar, C.: A lip sync expert is all you need for speech to lip generation in the wild. In: Proceedings of the 28th ACM international conference on multimedia. pp. 484–492 (2020)
2020
-
[23]
Seitzer, M.: pytorch-fid: FID Score for PyTorch.https://github.com/mseitzer/ pytorch-fid(August 2020), version 0.3.0
2020
-
[24]
Physica D: Nonlinear Phenomena404, 132306 (2020)
Sherstinsky, A.: Fundamentals of recurrent neural network (rnn) and long short- term memory (lstm) network. Physica D: Nonlinear Phenomena404, 132306 (2020)
2020
-
[25]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Song, L., Yin, G., Jin, Z., Dong, X., Xu, C.: Emotional listener portrait: Neural listener head generation with emotion. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 20839–20849 (2023)
2023
-
[26]
In: European Conference on Computer Vision
Tran, M., Chang, D., Siniukov, M., Soleymani, M.: Dim: Dyadic interaction mod- eling for social behavior generation. In: European Conference on Computer Vision. pp. 484–503. Springer (2024)
2024
-
[27]
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Fvd: A new metric for video generation (2019)
2019
-
[28]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[29]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
PC-Talk: Precise Facial Animation Control for Audio-Driven Talking Face Generation
Wang, B., Zhu, X., Shen, F., Xu, H., Lei, Z.: Pc-talk: Precise facial animation control for audio-driven talking face generation. arXiv preprint arXiv:2503.14295 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
In: European Conference on Computer Vision
Wang,D.,Dai,B.,Deng,Y.,Wang,B.:Disentanglingplanning,drivingandrender- ing for photorealistic avatar agents. In: European Conference on Computer Vision. pp. 137–147. Springer (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, W., Cun, X., Wang, X., Zhang, Y., Shen, X., Guo, Y., Shan, Y., Wang, F.: Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8652–8661 (2023)
2023
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, Z., Li, L., Ding, Y., Fan, C.: Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3661–3670 (2021)
2021
-
[34]
In: European conference on computer vision
Zhou, M., Bai, Y., Zhang, W., Yao, T., Zhao, T., Mei, T.: Responsive listening head generation: a benchmark dataset and baseline. In: European conference on computer vision. pp. 124–142. Springer (2022)
2022
-
[35]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhu, Y., Zhang, L., Rong, Z., Hu, T., Liang, S., Ge, Z.: Infp: Audio-driven inter- active head generation in dyadic conversations. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10667–10677 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.