Seeing Through Multiple Views: Parameter-Efficient Fine-Tuning via Selective Neurons for Consistent Radiology Report Generation
Pith reviewed 2026-07-01 06:08 UTC · model grok-4.3
The pith
Updating only view-specific neurons produces consistent radiology reports from different X-ray views at lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
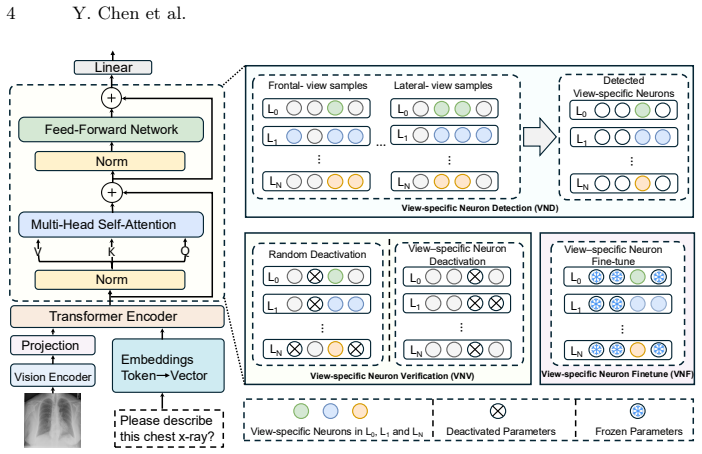
View-PNDF detects view-specific neurons with a dedicated module, confirms them via a verification step, and applies selective fine-tuning to strengthen only those neurons; the result is consistent report generation across views without full retraining, followed by LLM consolidation of the outputs.
What carries the argument
View-specific Pattern Neuron Detection and Fine-tuning (View-PNDF), which isolates and strengthens neurons responsive to individual views while preserving the rest of the network.
Load-bearing premise
The verification module can reliably identify view-specific neurons so that strengthening them reduces inconsistencies without degrading shared representations or overall accuracy.
What would settle it
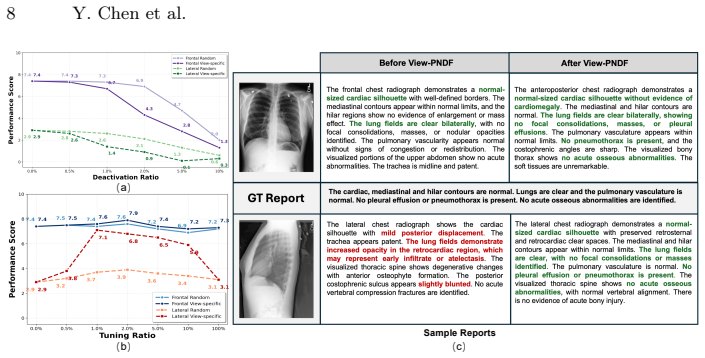
Run the same backbone on multi-view inputs with both full fine-tuning and the selective neuron update, then compare LLM-based consistency scores and parameter counts; equal or better consistency under full tuning would falsify the selective benefit.
Figures
read the original abstract
Recent years have seen substantial advances in radiology report generation (RRG), yet existing approaches predominantly adopt direct feature fusion when handling multi-view X-ray images. Such approaches overlook the potential clinical inconsistencies and inaccuracies arising when a single model processes different views, adversely impacting performance and clinical reliability. To this end, we introduce View-PNDF (View-specific Pattern Neuron Detection and Fine-tuning), a parameter-efficient framework that fosters view-consistent report generation from a neuronal perspective. Specifically, View-PNDF comprises: (i) a view-specific neuron detection module identifying neurons responsive to particular views, (ii) a verification module quantifying the existence of these neurons, and (iii) a selective fine-tuning strategy strengthening detected neurons while preserving view-agnostic representations. By updating only view-specific neurons, View-PNDF achieves consistent diagnoses across different views with reduced computational costs. Subsequently, we employ Large Language Models (LLMs) to consolidate the view-specific reports into a complete radiology report. Furthermore, we use traditional Natural Language Generation (NLG) metrics-based assessment on integrated reports for baseline comparison and employ LLM-based assessment (e.g., GPT-4o) on view-specific reports to capture clinical significance. Extensive experiments on two medical RRG benchmarks demonstrate that View-PNDF substantially improves view-specific chest X-ray report generation quality while maintaining robust general-view performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes View-PNDF, a parameter-efficient fine-tuning framework for multi-view radiology report generation. It detects view-specific neurons, verifies their existence, selectively strengthens only those neurons while aiming to preserve view-agnostic representations, generates view-specific reports, and consolidates them via LLMs. Evaluation combines traditional NLG metrics on integrated reports with LLM-based (e.g., GPT-4o) clinical assessment on view-specific outputs, claiming substantial improvements in consistency and quality on two RRG benchmarks with reduced computational cost.
Significance. If the neuron detection, verification, and selective update steps prove reliable, the method could advance parameter-efficient adaptation for multi-view medical imaging by addressing view inconsistencies at the neuronal level rather than through feature fusion, with potential benefits for clinical reliability and efficiency.
major comments (3)
- [Abstract] Abstract (verification module): the description states that the module 'quantif[ies] the existence of these neurons' but supplies no equations, thresholds, correlation metrics, statistical tests, or validation criteria for this quantification step. This is load-bearing for the central claim, as unreliable detection would invalidate both the consistency gains and the parameter-efficiency argument.
- [Abstract] Abstract (selective fine-tuning strategy): the claim that strengthening view-specific neurons 'preserv[es] view-agnostic representations' is asserted without any reported ablation measuring post-tuning performance on view-agnostic tasks or degradation of shared circuitry. If this preservation fails, the consistency and efficiency claims both collapse.
- [Abstract] Abstract (experimental validation): the text asserts 'substantial improvements' and 'robust general-view performance' on two benchmarks yet provides no baselines, exact metrics, statistical significance tests, or ablation results in the provided description, preventing verification that the data support the central claims.
minor comments (1)
- [Abstract] The abstract would benefit from explicit definitions or references to how 'view-specific neurons' are operationally identified (e.g., activation thresholds or response criteria) to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the abstract for greater precision while preserving its summary nature. Full technical details and empirical results appear in the manuscript body.
read point-by-point responses
-
Referee: [Abstract] Abstract (verification module): the description states that the module 'quantif[ies] the existence of these neurons' but supplies no equations, thresholds, correlation metrics, statistical tests, or validation criteria for this quantification step. This is load-bearing for the central claim, as unreliable detection would invalidate both the consistency gains and the parameter-efficiency argument.
Authors: The abstract provides a high-level summary. Section 3.2 of the manuscript details the verification module, including the exact equations for neuron activation scoring, chosen thresholds, Pearson correlation metrics, and statistical tests (e.g., t-tests) used to quantify and validate view-specific neuron existence. We will revise the abstract to briefly reference these quantification criteria. revision: yes
-
Referee: [Abstract] Abstract (selective fine-tuning strategy): the claim that strengthening view-specific neurons 'preserv[es] view-agnostic representations' is asserted without any reported ablation measuring post-tuning performance on view-agnostic tasks or degradation of shared circuitry. If this preservation fails, the consistency and efficiency claims both collapse.
Authors: Ablation studies in Section 4.4 measure post-tuning performance on view-agnostic tasks and confirm no degradation of shared representations. We will revise the abstract to note that preservation is supported by these ablations. revision: yes
-
Referee: [Abstract] Abstract (experimental validation): the text asserts 'substantial improvements' and 'robust general-view performance' on two benchmarks yet provides no baselines, exact metrics, statistical significance tests, or ablation results in the provided description, preventing verification that the data support the central claims.
Authors: The abstract summarizes outcomes; Section 4 reports full baselines, exact NLG and clinical metrics, statistical significance (p-values), and ablations on the two benchmarks. We will revise the abstract to include specific improvement magnitudes (e.g., percentage gains in consistency) to better anchor the claims. revision: yes
Circularity Check
No significant circularity; empirical method validated on external benchmarks
full rationale
The paper presents an empirical framework (View-PNDF) consisting of detection, verification, and selective fine-tuning modules for multi-view radiology report generation. It reports performance gains on two medical RRG benchmarks using standard NLG metrics and LLM-based evaluation (GPT-4o), with no equations, parameter-fitting steps, or derivations that reduce to fitted inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claims rest on external experimental outcomes rather than internal redefinitions or renamings, satisfying the criteria for a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks trained on radiology data contain identifiable view-specific neurons whose selective update produces view-consistent outputs while preserving general performance.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Bau, D., Zhou, B., Khosla, A., Oliva, A., Torralba, A.: Network dissection: Quan- tifying interpretability of deep visual representations. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6541–6549 (2017)
2017
-
[4]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., et al.: Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
2024
-
[6]
arXiv preprint arXiv:2204.13258 (2022) 3 16 Taratynova et al
Chen, Z., Shen, Y., Song, Y., Wan, X.: Cross-modal memory networks for radiology report generation. arXiv preprint arXiv:2204.13258 (2022)
-
[7]
Generating radiology reports via memory-driven transformer.arXiv preprint arXiv:2010.16056, 2020
Chen, Z., Song, Y., Chang, T.H., Wan, X.: Generating radiology reports via memory-driven transformer. arXiv preprint arXiv:2010.16056 (2020)
-
[8]
arXiv preprint arXiv:2104.08696 , year=
Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., Wei, F.: Knowledge neurons in pretrained transformers. arXiv preprint arXiv:2104.08696 (2021)
-
[9]
Journal of the American Medical Informatics Association23(2), 304–310 (2015)
Demner-Fushman, D., Kohli, M.D., Rosenman, M.B., Shooshan, S.E., Rodriguez, L., Antani, S., Thoma, G.R., McDonald, C.J.: Preparing a collection of radiol- ogy examinations for distribution and retrieval. Journal of the American Medical Informatics Association23(2), 304–310 (2015)
2015
-
[10]
In: Proceedings of the sixth work- shop on statistical machine translation
Denkowski, M., Lavie, A.: Meteor 1.3: Automatic metric for reliable optimization and evaluation of machine translation systems. In: Proceedings of the sixth work- shop on statistical machine translation. pp. 85–91 (2011) 10 Y. Chen et al
2011
-
[11]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Hamamci, I.E., Er, S., Menze, B.: Ct2rep: Automated radiology report generation for 3d medical imaging. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 476–486. Springer (2024)
2024
-
[12]
Huang, X., Chen, W., Liu, J., Lu, Q., Luo, X., Shen, L.: Damper: A dual-stage medical report generation framework with coarse-grained mesh alignment and fine- grainedhypergraphmatching.In:ProceedingsoftheAAAIConferenceonArtificial Intelligence. vol. 39, pp. 3769–3778 (2025)
2025
-
[13]
Respiratory medicine case reports22, 257–259 (2017)
Ittyachen, A.M., Vijayan, A., Isac, M.: The forgotten view: Chest x-ray-lateral view. Respiratory medicine case reports22, 257–259 (2017)
2017
-
[14]
arXiv preprint arXiv:2510.08668 (2025)
Jiang, S., Wang, Y., Song, S., Hu, T., Zhou, C., Pu, B., Zhang, Y., Yang, Z., Feng, Y., Zhou, J.T., et al.: Hulu-med: A transparent generalist model towards holistic medical vision-language understanding. arXiv preprint arXiv:2510.08668 (2025)
-
[15]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Jin, H., Che, H., Lin, Y., Chen, H.: Promptmrg: Diagnosis-driven prompts for medical report generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 2607–2615 (2024)
2024
-
[16]
arXiv preprint arXiv:2004.12274 (2020)
Jing, B., Wang, Z., Xing, E.: Show, describe and conclude: On exploiting the struc- ture information of chest x-ray reports. arXiv preprint arXiv:2004.12274 (2020)
-
[17]
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs
Johnson, A.E., Pollard, T.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Peng, Y., Lu, Z., Mark, R.G., Berkowitz, S.J., Horng, S.: Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs. arXiv preprint arXiv:1901.07042 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[18]
Advances in Neural Information Processing Systems36, 28541–28564 (2023)
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems36, 28541–28564 (2023)
2023
-
[19]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Liang, X., Zhang, Y., Wang, D., Zhong, H., Li, R., Wang, Q.: Divide and conquer: Isolating normal-abnormal attributes in knowledge graph-enhanced radiology re- port generation. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 4967–4975 (2024)
2024
-
[20]
In: Text sum- marization branches out
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Text sum- marization branches out. pp. 74–81 (2004)
2004
-
[21]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Liu, C., Tian, Y., Chen, W., Song, Y., Zhang, Y.: Bootstrapping large language models for radiology report generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 18635–18643 (2024)
2024
-
[22]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, K., Ma, Z., Kang, X., Li, Y., Xie, K., Jiao, Z., Miao, Q.: Enhanced con- trastive learning with multi-view longitudinal data for chest x-ray report genera- tion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10348–10359 (2025)
2025
-
[23]
IEEE Transactions on Multimedia26, 5987–5995 (2023)
Liu,Z.,Zhu,Z.,Zheng,S.,Zhao,Y.,He,K.,Zhao,Y.:Fromobservationtoconcept: A flexible multi-view paradigm for medical report generation. IEEE Transactions on Multimedia26, 5987–5995 (2023)
2023
-
[24]
European Heart Journal- Digital Health3(1), 49–55 (2022)
Loh, D.R., Yeo, S.Y., Tan, R.S., Gao, F., Koh, A.S.: Explainable machine learning predictions to support personalized cardiology strategies. European Heart Journal- Digital Health3(1), 49–55 (2022)
2022
-
[25]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
arXiv preprint arXiv:2411.10224 (2024)
Miao, Q., Liu, K., Ma, Z., Li, Y., Kang, X., Liu, R., Liu, T., Xie, K., Jiao, Z.: Evoke: Elevating chest x-ray report generation via multi-view contrastive learning and patient-specific knowledge. arXiv preprint arXiv:2411.10224 (2024)
-
[27]
Advances in Neural Information Processing Systems33, 17153–17163 (2020) Seeing Through Multiple Views: View-PNDF 11
Mu, J., Andreas, J.: Compositional explanations of neurons. Advances in Neural Information Processing Systems33, 17153–17163 (2020) Seeing Through Multiple Views: View-PNDF 11
2020
-
[28]
Artificial intelligence in medicine144, 102633 (2023)
Nicolson, A., Dowling, J., Koopman, B.: Improving chest x-ray report generation by leveraging warm starting. Artificial intelligence in medicine144, 102633 (2023)
2023
-
[29]
In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics. pp. 311–318 (2002)
2002
-
[30]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical report. arXiv preprint arXiv:2507.05201 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tanida,T.,Müller,P.,Kaissis,G.,Rueckert,D.:Interactiveandexplainableregion- guided radiology report generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7433–7442 (2023)
2023
-
[32]
In: European Conference on Computer Vision
Wang,J.,Bhalerao,A.,He,Y.:Cross-modalprototypedrivennetworkforradiology report generation. In: European Conference on Computer Vision. pp. 563–579. Springer (2022)
2022
-
[33]
IEEE Journal of Biomed- ical and Health Informatics28(4), 2199–2210 (2024)
Wang, J., Bhalerao, A., Yin, T., See, S., He, Y.: Camanet: class activation map guided attention network for radiology report generation. IEEE Journal of Biomed- ical and Health Informatics28(4), 2199–2210 (2024)
2024
-
[34]
Medical Image Analysis86, 102798 (2023)
Yang, S., Wu, X., Ge, S., Zheng, Z., Zhou, S.K., Xiao, L.: Radiology report gen- eration with a learned knowledge base and multi-modal alignment. Medical Image Analysis86, 102798 (2023)
2023
-
[35]
IET Computer Vision10(1), 79–86 (2016)
Yang, X., Su, Y., Duan, R., Fan, H., Yeo, S.Y., Lim, C., Zhong, L., Tan, R.S.: Cardiac image segmentation by random walks with dynamic shape constraint. IET Computer Vision10(1), 79–86 (2016)
2016
-
[36]
In: 2011 18th IEEE International Conference on Image Processing
Yeo, S.Y., Xie, X., Sazonov, I., Nithiarasu, P.: Level set segmentation with robust image gradient energy and statistical shape prior. In: 2011 18th IEEE International Conference on Image Processing. pp. 3397–3400. IEEE (2011)
2011
-
[37]
Advances in neural information processing systems36, 46595–46623 (2023)
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems36, 46595–46623 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.