One Retrieval to Cover Them All: Co-occurrence-Aware Knowledge Base Reorganization for Session-Level RAG
Pith reviewed 2026-07-01 04:38 UTC · model grok-4.3
The pith
Reorganizing the knowledge base with co-occurrence clusters raises single-retrieval session coverage from 41% to 58%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
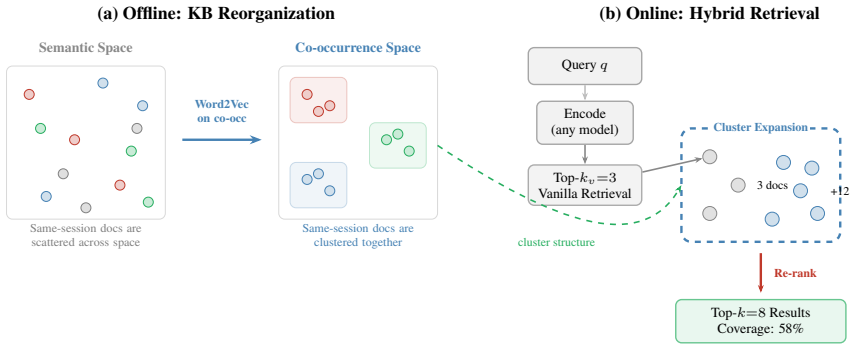
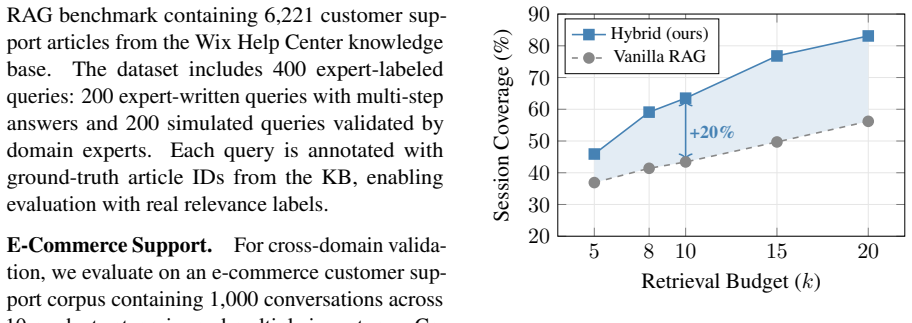
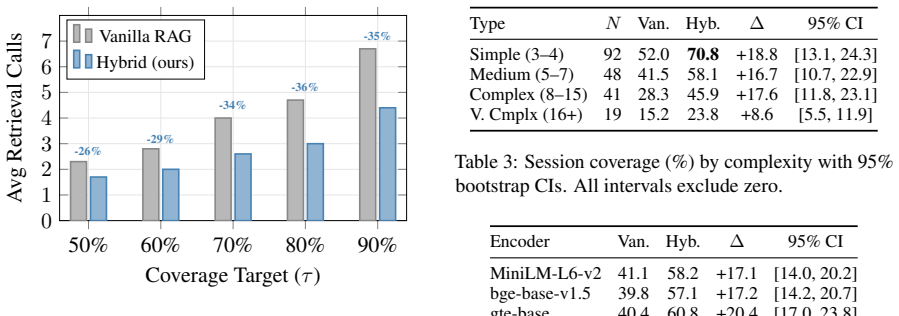
A single retrieval over a standard knowledge base covers only 41% of a user's session-level information need. Reorganizing the KB offline using co-occurrence-aware clustering and expanding retrieval candidates through cluster neighborhoods at query time raises single-query session coverage to 58%, reduces retrieval calls to 70% coverage by 34%, and compresses the KB to 20% of its original size, consistently across four embedding models and six functional domains on the WixQA dataset.
What carries the argument
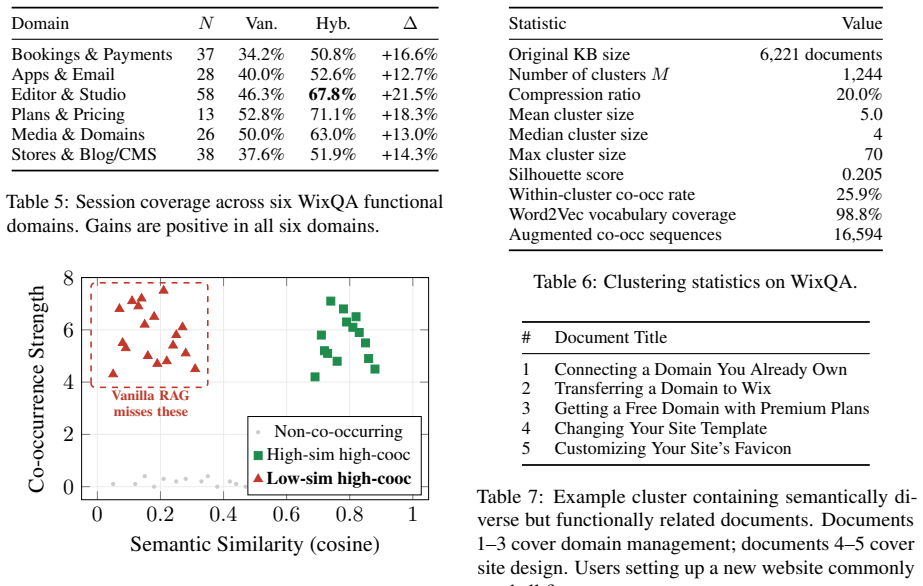
Co-occurrence-aware clustering, which identifies groups of articles that frequently appear together in user sessions so retrieval can include neighboring documents from the same cluster.
If this is right
- Session-level coverage becomes the recommended primary metric for evaluating enterprise RAG systems.
- Knowledge bases can be compressed substantially while improving session coverage.
- The number of retrieval operations per session decreases.
- Results remain stable regardless of the embedding model chosen.
Where Pith is reading between the lines
- This method may lower overall latency in RAG applications by requiring fewer retrieval rounds.
- It suggests that static knowledge bases could benefit from periodic reorganization based on usage logs.
- The approach might generalize to non-enterprise settings with logged user sessions.
Load-bearing premise
Co-occurrence patterns from the observed enterprise sessions are representative enough that expanding to cluster neighborhoods adds relevant documents without introducing harmful noise.
What would settle it
Running the reorganization method on a different set of user sessions and measuring no gain in session coverage or a drop in final answer quality would show the claim does not hold.
Figures

read the original abstract
RAG systems retrieve documents optimized for answering one query at a time. Yet enterprise users arrive with sessions, that is, coherent episodes of related questions that span semantically distant parts of the knowledge base. We show that a single retrieval call over a standard knowledge base covers only 41% of a user's session-level information need. To close this gap, we reorganize the KB offline using co-occurrence-aware clustering and expand retrieval candidates through cluster neighborhoods at query time. On WixQA (6,221 enterprise support articles), our method raises single-query session coverage to 58% (+17% absolute; 95% CI: [14.1, 20.4]), reduces retrieval calls to 70% coverage by 34%, and compresses the KB to 20% of its original size, all consistently across four embedding models and six functional domains. We argue that session-level coverage, not single-query recall, should be the primary metric for enterprise RAG evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a single retrieval over a standard KB covers only 41% of session-level information needs in enterprise RAG. It introduces offline co-occurrence-aware clustering to reorganize the KB and expands retrieval to cluster neighborhoods at query time. On the WixQA dataset of 6,221 articles, this raises single-query session coverage to 58% (+17% absolute, 95% CI [14.1, 20.4]), reduces the number of retrieval calls needed for 70% coverage by 34%, and compresses the KB to 20% of original size, with results consistent across four embedding models and six functional domains. The authors argue that session-level coverage should replace single-query recall as the primary RAG evaluation metric.
Significance. If the coverage gains translate to improved end-to-end performance without introducing noise, the work could meaningfully shift enterprise RAG evaluation practices toward session-aware metrics and yield efficiency gains via KB compression. The reported cross-model and cross-domain consistency strengthens the empirical case, but the absence of any downstream answer-quality evaluation limits the assessed significance.
major comments (1)
- [Experiments] Experiments (results on WixQA): the central claim that the reorganization improves practical RAG utility rests on coverage and call-reduction numbers alone; no experiments evaluate whether cluster-neighborhood expansion improves, preserves, or harms final answer correctness, relevance, or hallucination rates. This is load-bearing for the recommendation to adopt session coverage as the primary metric.
minor comments (1)
- [Abstract] Abstract: the 95% CI is reported for the coverage gain, which is a positive detail, but the paper should state the exact statistical procedure and whether the CI accounts for multiple embedding models.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback. We address the major comment on experiments below.
read point-by-point responses
-
Referee: Experiments (results on WixQA): the central claim that the reorganization improves practical RAG utility rests on coverage and call-reduction numbers alone; no experiments evaluate whether cluster-neighborhood expansion improves, preserves, or harms final answer correctness, relevance, or hallucination rates. This is load-bearing for the recommendation to adopt session coverage as the primary metric.
Authors: We agree that end-to-end evaluation of answer correctness, relevance, and hallucination rates would provide stronger evidence for practical utility. Our work focuses on retrieval coverage as a necessary precondition for answer quality in session-based RAG, since missing documents cannot be used by the generator. The co-occurrence clustering is designed to group semantically related content, which we expect to limit noise, but we did not measure downstream effects. In the revised manuscript we will add an explicit limitations section discussing this gap, its implications for the proposed metric, and planned future experiments with answer-quality metrics across multiple generators. revision: yes
Circularity Check
No circularity; empirical measurements only
full rationale
The paper presents a clustering-based KB reorganization method evaluated via direct coverage measurements on WixQA sessions. No equations, fitted parameters, or predictions are described that reduce by construction to inputs. No self-citation load-bearing steps or ansatz smuggling appear in the provided text. Results are framed as empirical observations across embedding models and domains, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Documents that co-occur in user sessions are semantically close enough that retrieving from their cluster neighborhoods improves session coverage without adding harmful noise.
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. 2021 , eprint=
2021
-
[2]
2013 , eprint=
Efficient Estimation of Word Representations in Vector Space , author=. 2013 , eprint=
2013
-
[3]
Dvir Cohen and Lin Burg and Sviatoslav Pykhnivskyi and Hagit Gur and Stanislav Kovynov and Olga Atzmon and Gilad Barkan , year=. 2505.08643 , archivePrefix=
-
[4]
Findings of the Association for Computational Linguistics: EMNLP 2025 , month=nov, year=
Efficient Dynamic Clustering-Based Document Compression for Retrieval-Augmented-Generation , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , month=nov, year=. doi:10.18653/v1/2025.findings-emnlp.522 , pages=
-
[5]
Cluster-based Adaptive Retrieval: Dynamic Context Selection for
Yifan Xu and Vipul Gupta and Rohit Aggarwal and Varsha Mahadevan and Bhaskar Krishnamachari , year=. Cluster-based Adaptive Retrieval: Dynamic Context Selection for. 2511.14769 , archivePrefix=
-
[6]
Simon Akesson and Frances A. Santos , year=. Clustered Retrieved Augmented Generation (. 2406.00029 , archivePrefix=
-
[7]
RAGA s: Automated Evaluation of Retrieval Augmented Generation
Es, Shahul and James, Jithin and Espinosa Anke, Luis and Schockaert, Steven , booktitle=. 2024 , address=. doi:10.18653/v1/2024.eacl-demo.16 , pages=
-
[8]
In: Proceedings of the 2018 Conference on Empirical Methods in Natu- ral Language Processing
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle=. 2018 , address=. doi:10.18653/v1/D18-1259 , pages=
-
[9]
Xueguang Ma and Liang Wang and Nan Yang and Furu Wei and Jimmy Lin , year=. Fine-Tuning. 2310.08319 , archivePrefix=
-
[10]
2026 , eprint=
On the Theoretical Limitations of Embedding-Based Retrieval , author=. 2026 , eprint=
2026
-
[11]
2017 , eprint=
Item2Vec: Neural Item Embedding for Collaborative Filtering , author=. 2017 , eprint=
2017
-
[12]
Rousseeuw, Peter J. , year=. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis , journal=
-
[13]
Transactions of the Association for Computational Linguistics , volume=
Lost in the Middle: How Language Models Use Long Contexts , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , doi=
2024
-
[14]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
Parth Sarthi and Salman Abdullah and Aditi Tuli and Shubh Khanna and Anna Goldie and Christopher D. Manning , year=. 2401.18059 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Precise Zero-Shot Dense Retrieval without Relevance Labels , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month=jul, year=. doi:10.18653/v1/2023.acl-long.99 , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.