LLM-Powered Interactive Robotic Action Synthesis from Multimodal Speech, Gestures, and Music
Pith reviewed 2026-07-01 05:36 UTC · model grok-4.3
The pith
An LLM fuses speech, gestures and music into coherent robot action sequences
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
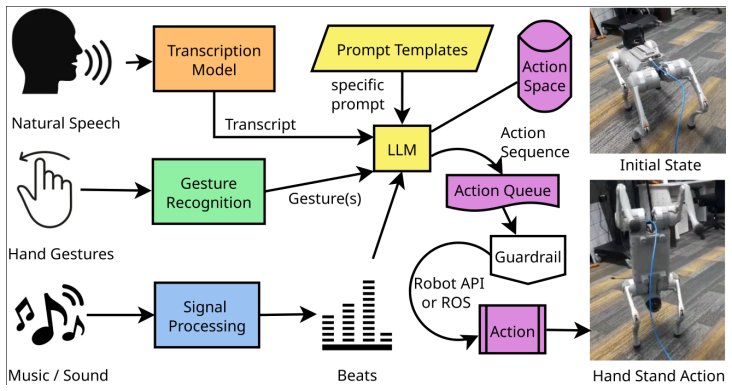
The framework integrates speech transcription, gesture recognition, and beat detection to provide contextualized inputs to an LLM. Informed by prompt templates and a predefined robot action space, the LLM reasons over the combined multimodal inputs to generate a coherent sequence of actions dispatched to a quadruped robot over ROS. The system interprets and fuses semantic commands from speech, deictic information from gestures, and rhythmic cues from music.
What carries the argument
The LLM that reasons over prompt templates containing the multimodal inputs to produce an action sequence from the predefined robot action space
If this is right
- The system can produce actions that respond to pointing gestures
- Music rhythm can affect the timing of robot movements
- Actions are sent to the robot via ROS for execution
- Multiple input types are fused into one coherent plan
Where Pith is reading between the lines
- Extending this to other robot platforms would require only changing the action space definition
- Adding error correction might be needed if LLM outputs are unreliable on complex inputs
- Real-time performance depends on the speed of the transcription and recognition modules
Load-bearing premise
The large language model will reliably combine the different types of input information into correct and safe robot action sequences using only the given prompts and action list
What would settle it
A test where the speech command, gesture direction, and music beat are deliberately conflicting, and checking whether the generated action sequence follows one input, another, or produces inconsistent commands
Figures
read the original abstract
The quest for intuitive and natural human-robot interaction (HRI) remains a significant challenge in robotics. Traditional methods often rely on rigid, pre-programmed commands that limit the robot's expressiveness and adaptability. This paper introduces a novel framework that leverages the reasoning capabilities of Large Language Models (LLMs) to synthesize complex robotic actions from a rich tapestry of multimodal human inputs: natural speech, hand gestures, and music/sound beats. Our system architecture integrates a speech transcription model, a gesture recognition module, and a signal processing pipeline for beat detection. These processed inputs are contextualized using prompt templates and fed into a LLM. The LLM, informed by a predefined robot action space, reasons over the combined inputs to generate a coherent sequence of actions. This sequence is dispatched to an action queue for execution on a quadruped robot over ROS. The framework has ability to interpret and fuse semantic commands from speech, deictic information from gestures, and rhythmic cues from music. This work represents a step towards creating robots that can interact with humans in a more fluid, creative, and context-aware manner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes an architectural framework for human-robot interaction in which speech is transcribed, gestures are recognized for deictic cues, and music beats are detected; these multimodal signals are combined via prompt templates and passed to an LLM that, given a predefined robot action space, is asserted to produce coherent action sequences dispatched over ROS to a quadruped robot.
Significance. If the central claim were demonstrated, the work would represent a potentially useful direction for fluid, multimodal HRI that integrates semantic, spatial, and rhythmic information. However, the manuscript supplies no experiments, implementation details, error analysis, or validation of the LLM's fusion behavior, so the significance cannot be assessed from the provided material.
major comments (2)
- [Abstract] Abstract: The assertion that the framework 'has ability to interpret and fuse semantic commands from speech, deictic information from gestures, and rhythmic cues from music' to generate coherent executable sequences rests entirely on an untested architectural description; no experiments, datasets, success rates, or failure-mode analysis are supplied anywhere in the manuscript.
- [Architecture description] Architecture description (throughout): The pipeline contains no output validation, consistency checks, fallback mechanisms, or handling of LLM hallucinations/inconsistencies before actions are placed in the ROS queue; this omission is load-bearing because the central claim depends on reliable multimodal reasoning by the LLM.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The manuscript presents a high-level architectural framework for multimodal HRI and does not include experiments or implementation details. We address each major comment below and indicate planned revisions to align claims with the provided content.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the framework 'has ability to interpret and fuse semantic commands from speech, deictic information from gestures, and rhythmic cues from music' to generate coherent executable sequences rests entirely on an untested architectural description; no experiments, datasets, success rates, or failure-mode analysis are supplied anywhere in the manuscript.
Authors: We agree that the abstract overstates the framework as having demonstrated abilities. The paper is a conceptual description of the pipeline. We will revise the abstract to state that the framework is designed to interpret and fuse these inputs through LLM-based reasoning to produce action sequences, removing the claim of proven ability and clarifying that empirical validation is future work. revision: yes
-
Referee: [Architecture description] Architecture description (throughout): The pipeline contains no output validation, consistency checks, fallback mechanisms, or handling of LLM hallucinations/inconsistencies before actions are placed in the ROS queue; this omission is load-bearing because the central claim depends on reliable multimodal reasoning by the LLM.
Authors: This observation is correct. The manuscript describes the core fusion pipeline but omits robustness considerations. We will add a dedicated paragraph in the architecture section acknowledging the risks of unvalidated LLM outputs (including hallucinations) and noting that consistency checks and fallbacks are important directions for future refinement, while keeping the focus on the initial integration approach. revision: partial
Circularity Check
No circularity; no derivations or fitted quantities present
full rationale
The paper is a descriptive system architecture for LLM-based multimodal fusion in robotics. It contains no equations, no parameter fitting, no derivation chains, and no load-bearing self-citations or ansatzes. The central claim is an engineering description of prompt templates feeding an LLM with predefined action space; this is presented as a design choice rather than a derived result that reduces to its inputs by construction. No patterns from the enumerated list apply.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Deuerlein, M
C. Deuerlein, M. Langer, J. Seßner, P. Heß, and J. Franke. Human-robot- interaction using cloud-based speech recognition systems.Procedia Cirp, 97:130–135, 2021
2021
-
[3]
F. Foscarin, J. Schl ¨uter, and G. Widmer. Beat this! accurate beat tracking without dbn postprocessing.arXiv preprint arXiv:2407.21658, 2024
-
[4]
Kapitanov, K
A. Kapitanov, K. Kvanchiani, A. Nagaev, R. Kraynov, and A. Makhliarchuk. Hagrid–hand gesture recognition image dataset. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4572–4581, 2024
2024
-
[5]
Y . Kim, D. Kim, J. Choi, J. Park, N. Oh, and D. Park. A survey on integration of large language models with intelligent robots.Intelligent Service Robotics, 17(5):1091–1107, 2024
2024
-
[6]
X. Wang, H. Shen, H. Yu, J. Guo, and X. Wei. Hand and arm gesture- based human-robot interaction: a review. InProceedings of the 6th International Conference on Algorithms, Computing and Systems, pages 1–7, 2022
2022
-
[7]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.