Beyond Single Character: Evaluating MLLMs for Sentence-Level Oracle Bone Inscription Understanding
Pith reviewed 2026-07-01 06:26 UTC · model grok-4.3
The pith
Current MLLMs remain dependent on character-level recognition when attempting sentence-level understanding of oracle bone inscriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
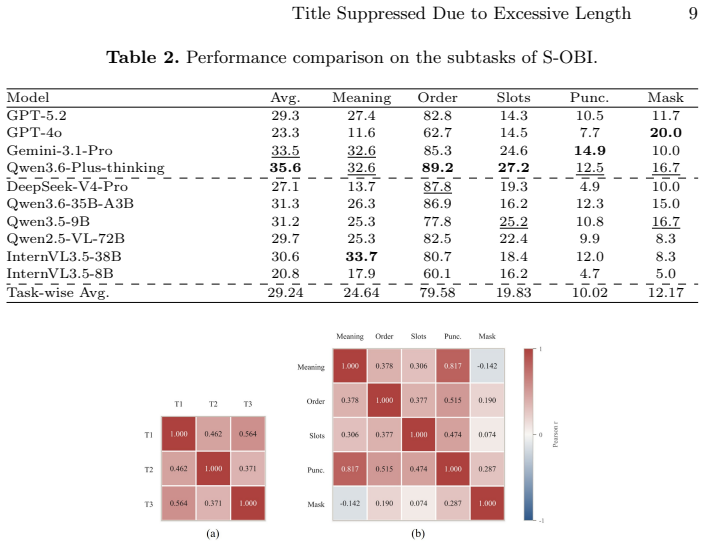
Experiments reveal the inferiority of contemporary MLLMs on sentence-level OBI understanding. In particular, visual perception errors in unmasked regions propagate through the reasoning chain, leading to erroneous predictions for masked characters, which indicates that sentence-level OBI understanding in current models remains strongly dependent on character-level recognition.
What carries the argument
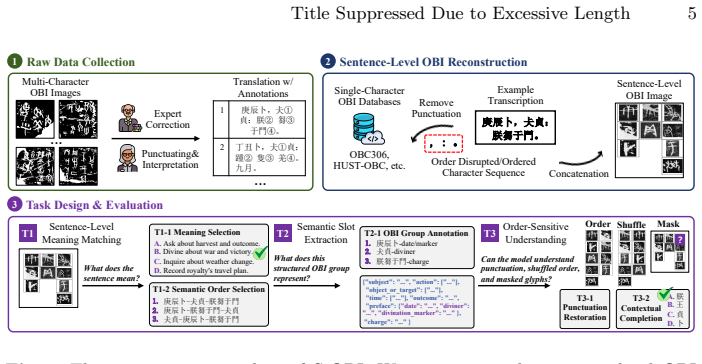
The S-OBI benchmark, which creates sentence-level OBI instances by glyph substitution and composition on 95 original rubbings to isolate contextual understanding from low-level visual noise.
If this is right
- Models that succeed on S-OBI would need to integrate long-form textual coherence and contextual dependencies rather than processing characters in isolation.
- The three tasks demonstrate that current errors arise specifically from propagation of perception mistakes across the sentence.
- S-OBI separates evaluation of inscription-level understanding from the effects of noisy rubbings.
- The 695 QA pairs supply concrete test cases for measuring whether models can move past single-character reliance.
Where Pith is reading between the lines
- The synthesis approach could be applied to other damaged historical scripts to create controlled tests of contextual reasoning.
- If dependence on character recognition persists, real-world use on incomplete archaeological finds would remain limited.
- Architectures that explicitly model inscription layout or semantic slots might reduce the observed error propagation.
- Improved performance on S-OBI could indicate readiness for broader ancient-text interpretation tasks beyond oracle bones.
Load-bearing premise
Replacing characters in original rubbings with clean glyph samples while preserving overall structure and semantics creates instances that test sentence-level understanding rather than low-level visual distortions.
What would settle it
An MLLM that correctly infers masked characters in S-OBI sentences despite making clear visual errors on the surrounding unmasked characters would falsify the claim of strong dependence on character-level recognition.
Figures


read the original abstract
Existing AI-assisted oracle bone inscription (OBI) visual recognition and understanding studies mainly focus on character-level, ignoring the long-form textual coherence and contextual dependencies embedded in complete divination charges. Recently, the powerful visual perception capabilities of multimodal large language models (MLLMs) have opened new possibilities for OBI information processing. In this work, we introduce S-OBI, a novel benchmark for evaluating MLLMs in Sentence-level OBI understanding. Instead of using noisy and incomplete rubbings as the visual input, S-OBI synthesizes clear and standardized sentence-level OBI instances through glyph substitution and composition. According to 95 original rubbings with translations that have been identified, corrected, and verified by experts, we replace characters in the original rubbings with corresponding clean glyph samples sourced from existing OBI datasets while preserving the overall inscriptional structure and semantic organization. This mitigates the influence of low-level distortions and enables a more focused evaluation of sentence-level OBI understanding. Based on this, we design semantic matching, semantic slot extraction, and contextual reasoning tasks and obtain 695 question-answer pairs. Experiments reveal the inferiority of contemporary MLLMs on sentence-level OBI understanding. In particular, visual perception errors in unmasked regions propagate through the reasoning chain, leading to erroneous predictions for masked characters, which indicates that sentence-level OBI understanding in current models remains strongly dependent on character-level recognition. Overall, S-OBI provides a diagnostic benchmark for evaluating whether MLLMs can move beyond isolated character recognition toward structured inscription-level understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the S-OBI benchmark for evaluating multimodal large language models (MLLMs) on sentence-level oracle bone inscription (OBI) understanding. It constructs 695 QA pairs from 95 expert-verified rubbings by synthesizing clear instances via glyph substitution (replacing characters with clean samples from existing datasets while preserving structure and semantics), then evaluates on semantic matching, semantic slot extraction, and contextual reasoning tasks. The central experimental finding is that contemporary MLLMs perform poorly, with visual perception errors on unmasked regions propagating to incorrect predictions on masked characters, indicating that sentence-level OBI understanding remains strongly dependent on character-level recognition rather than contextual reasoning.
Significance. If the results hold after addressing the synthesis validation, S-OBI would serve as a useful diagnostic benchmark for probing whether MLLMs can achieve structured, inscription-level understanding beyond isolated character recognition in a specialized historical domain. The expert verification of the 95 source rubbings and the explicit design to isolate sentence-level factors (by mitigating low-level distortions) are concrete strengths. The work is purely empirical with no machine-checked proofs, reproducible code releases, or parameter-free derivations noted.
major comments (1)
- [S-OBI Construction (glyph substitution procedure)] The central claim that error propagation demonstrates dependence on character-level recognition (rather than sentence-level deficits) rests on the assumption that the glyph-substitution synthesis produces visually unambiguous unmasked glyphs. The construction procedure (replacing characters in the 95 rubbings with clean samples while preserving overall structure) provides no quantitative evidence—such as human clarity ratings, style-consistency metrics, or comparison against MLLM training distributions—that the composed images are free of rendering artifacts, scale inconsistencies, or domain mismatches. This is load-bearing for the interpretation of the experimental outcomes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [S-OBI Construction (glyph substitution procedure)] The central claim that error propagation demonstrates dependence on character-level recognition (rather than sentence-level deficits) rests on the assumption that the glyph-substitution synthesis produces visually unambiguous unmasked glyphs. The construction procedure (replacing characters in the 95 rubbings with clean samples while preserving overall structure) provides no quantitative evidence—such as human clarity ratings, style-consistency metrics, or comparison against MLLM training distributions—that the composed images are free of rendering artifacts, scale inconsistencies, or domain mismatches. This is load-bearing for the interpretation of the experimental outcomes.
Authors: We agree that the original submission lacks quantitative validation of the synthesized images and that this is a substantive gap for the central interpretation. The construction uses clean glyphs from existing datasets and preserves structure from expert-verified rubbings, but no explicit metrics (clarity ratings, artifact checks, or distribution comparisons) were reported. In the revised manuscript we will add an appendix containing: (1) expert clarity ratings (1-5 scale) on a random sample of 50 synthesized sentences, (2) simple style-consistency statistics (stroke-width variance across substituted glyphs), and (3) a brief comparison of glyph sources against common OBI training distributions. We will also release the synthesis code. These additions directly address the load-bearing assumption. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivation chain
full rationale
The paper introduces an empirical benchmark (S-OBI) via glyph substitution on 95 expert-verified rubbings to create 695 QA pairs for three tasks. No equations, fitted parameters, predictions, or uniqueness theorems appear. The central claim rests on observed MLLM performance differences rather than any self-referential reduction or self-citation load-bearing step. The synthesis method is a one-time data construction step, not a derivation that collapses to its inputs by construction. This matches the default expectation for non-circular empirical evaluation work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Chen, Z., Chen, T., Zhang, W., Zhai, G.: OBI-Bench: Can LMMs aid in the study of ancient script on oracle bones? In: Proceedings of the International Conference on Learning Representations (2025)
2025
-
[3]
arXiv preprint arXiv:2509.05773 (2025)
Chen, Z., Hua, W., Li, J., Deng, L., Du, F., Chen, T., Zhai, G.: PictOBI-20k: Unveiling large multimodal models in visual decipherment for pictographic oracle bone characters. arXiv preprint arXiv:2509.05773 (2025)
-
[4]
npj Heritage Science14, 220 (2026)
Chen, Z., Hua, W., Li, J., Zhu, Y., Zhi, X., Liu, Z., Chen, T., Zhang, W., Zhai, G.: Oracle bone inscriptions information processing: A comprehensive survey. npj Heritage Science14, 220 (2026). https://doi.org/10.1038/s40494-026-02511-w
-
[5]
arXiv preprint arXiv:2507.00490 (2025) 12 Li et al
Chen, Z., Tian, Y., Sun, Y., Sun, W., Zhang, Z., Lin, W., Zhai, G., Zhang, W.: Just noticeable difference for large multimodal models. arXiv preprint arXiv:2507.00490 (2025) 12 Li et al
-
[6]
https://huggingface.co/deepseek-ai/ DeepSeek-V4-Pro (2026), accessed 22 June 2026
DeepSeek-AI: DeepSeek-V4-Pro model card. https://huggingface.co/deepseek-ai/ DeepSeek-V4-Pro (2026), accessed 22 June 2026
2026
-
[7]
International Journal of Digital Humanities5(2), 65–79 (2023)
Fujikawa, Y., Li, H., Yue, X., Aravinda, C., Prabhu, G.A., Meng, L.: Recognition of oracle bone inscriptions by using two deep learning models. International Journal of Digital Humanities5(2), 65–79 (2023)
2023
-
[8]
https://ai.google.dev/gemini-api/docs/ models (2026), accessed 22 June 2026
Google: Gemini model documentation. https://ai.google.dev/gemini-api/docs/ models (2026), accessed 22 June 2026
2026
-
[9]
An open dataset for the evolution of oracle bone characters: Evobc
Guan, H., Wan, J., Liu, Y., Wang, P., Zhang, K., Kuang, Z., Wang, X., Bai, X., Jin, L.: An open dataset for the evolution of oracle bone characters: EVOBC. arXiv preprint arXiv:2401.12467 (2024)
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, S., Price, B., Fan, Y., Morse, B.: Beyond single images: A comprehensive benchmark for album-level vision-language understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 38564– 38573 (2026)
2026
-
[11]
In: Proceedings of the International Conference on Document Analysis and Recognition
Huang, S., Wang, H., Liu, Y., Shi, X., Jin, L.: OBC306: A large-scale oracle bone character recognition dataset. In: Proceedings of the International Conference on Document Analysis and Recognition. pp. 681–688 (2019)
2019
-
[12]
arXiv preprint arXiv:2411.17837 (2024)
Jiang, H., Pan, Y., Chen, J., Liu, Z., Zhou, Y., Shu, P., Li, Y., Zhao, H., Mihm, S., Howe, L.C., Liu, T.: OracleSage: Towards unified visual-linguistic understand- ing of oracle bone scripts through cross-modal knowledge fusion. arXiv preprint arXiv:2411.17837 (2024)
-
[13]
(ed.): Sources of Shang History: The Oracle-Bone Inscriptions of Bronze Age China
Keightley, D.N. (ed.): Sources of Shang History: The Oracle-Bone Inscriptions of Bronze Age China. University of California Press, Berkeley (1978)
1978
-
[14]
arXiv preprint arXiv:2510.26114 (2025)
Li, C., Ding, Z., Hu, X., Li, B., Luo, D., Peng, X., Jin, T., Liu, Y., Han, S., Yang, J., et al.: Oracleagent: A multimodal reasoning agent for oracle bone script research. arXiv preprint arXiv:2510.26114 (2025)
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, C., Ding, Z., Hu, X., Li, B., Luo, D., Wu, A., Wang, C., Wang, C., Jin, T., Shu, S., et al.: Oraclefusion: Assisting the decipherment of oracle bone script with structurally constrained semantic typography. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19893–19902 (2025)
2025
-
[16]
Pattern Recognition169, 111824 (2026)
Li, J., Chi, X., Wang, Q., Huang, K., Wang, D.H., Liu, Y., Liu, C.L.: A compre- hensive survey of oracle character recognition: Challenges, datasets, methodology, and beyond. Pattern Recognition169, 111824 (2026)
2026
-
[17]
Displays89, 103059 (2025)
Li, J., Chen, Z., Chen, T., Liu, Z., Wang, C.: Obiformer: A fast attentive denoising framework for oracle bone inscriptions. Displays89, 103059 (2025)
2025
-
[18]
In: Pro- ceedings of the 33rd ACM International Conference on Multimedia
Li, J., Chen, Z., Jiang, R., Chen, T., Wang, C., Zhai, G.: Mitigating long-tail distribution in oracle bone inscriptions: Dataset, model, and benchmark. In: Pro- ceedings of the 33rd ACM International Conference on Multimedia. pp. 7729–7738 (2025)
2025
-
[19]
https://doi.org/10.21203/ rs.3.rs-9733608/v1
Li, Z., Chen, Z., Yang, Z., Liu, Z., Zhai, G., Chen, T.: Roots: Recognizing oracle bone inscriptions via an organized tree structure (2026). https://doi.org/10.21203/ rs.3.rs-9733608/v1
2026
-
[20]
Journal of image and graphics8(4), 114–119 (2020)
Liu, M., Liu, G., Liu, Y., Jiao, Q.: Oracle bone inscriptions recognition based on deep convolutional neural network. Journal of image and graphics8(4), 114–119 (2020)
2020
-
[21]
The Innovation (2026)
Liu, Y., Guan, H., Wang, P., Wang, X., Wan, J., Zhang, K., Zheng, H., Liu, X., Kuang, Z., Yang, H., et al.: Alphaoracle: Oracle bone script decipherment via human-workflow-inspired deep learning. The Innovation (2026)
2026
-
[22]
Guangxi Education Press (11 2005) Title Suppressed Due to Excessive Length 13
Liu, Z., Zhang, D., Takashima, K.i., Zang, K., et al.: A Classified Collection of Oracle Bone Inscriptions with Modern Chinese and English Translations. Guangxi Education Press (11 2005) Title Suppressed Due to Excessive Length 13
2005
-
[23]
OpenAI: GPT-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
https://openai.com/index/introducing-gpt-5-2/ (2026), accessed 22 June 2026
OpenAI: Introducing GPT-5.2. https://openai.com/index/introducing-gpt-5-2/ (2026), accessed 22 June 2026
2026
-
[25]
Qwen Team: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
https://huggingface.co/Qwen/Qwen3.5-9B (2026), accessed 22 June 2026
Qwen Team: Qwen3.5-9B model card. https://huggingface.co/Qwen/Qwen3.5-9B (2026), accessed 22 June 2026
2026
-
[27]
https://qwen.ai/models (2026), ac- cessed 22 June 2026
Qwen Team: Qwen3.6 model documentation. https://qwen.ai/models (2026), ac- cessed 22 June 2026
2026
-
[28]
Scientific Data11, 87 (2024)
Wang, M., Deng, W.: A dataset of oracle characters for benchmarking machine learning algorithms. Scientific Data11, 87 (2024)
2024
-
[29]
Scientific Data11, 976 (2024)
Wang, P., Zhang, K., Wang, X., Han, S., Liu, Y., Wan, J., Guan, H., Kuang, Z., Jin, L., Bai, X., Liu, Y.: An open dataset for oracle bone script recognition and decipherment. Scientific Data11, 976 (2024)
2024
-
[30]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
ACM Journal on Computing and Cultural Heritage15(4), 1–20 (2022)
Yue, X., Li, H., Fujikawa, Y., Meng, L.: Dynamic dataset augmentation for deep learning-based oracle bone inscriptions recognition. ACM Journal on Computing and Cultural Heritage15(4), 1–20 (2022)
2022
-
[32]
In: Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Zhang, J., Li, R., Pang, H., Xia, D., Zhu, Z., Zhang, Q., Li, C., Yang, X.: Special- izing large models for oracle bone script interpretation via component-grounded multimodal knowledge augmentation. In: Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 35221–35236 (2026)
2026
-
[33]
In: Findings of the Association for Computational Linguistics: ACL 2026
Zhou, Z., Shi, D., Shi, L., Song, R., Qiu, P., Diao, X., Xu, H.: Acse: An ancient character semantic-aware embedding for large language models. In: Findings of the Association for Computational Linguistics: ACL 2026. pp. 9000–9012 (2026)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.