A Multi-Dimensional, Per-Pass Empirical Study of the LLVM Optimization Pipeline
Pith reviewed 2026-07-01 04:50 UTC · model grok-4.3
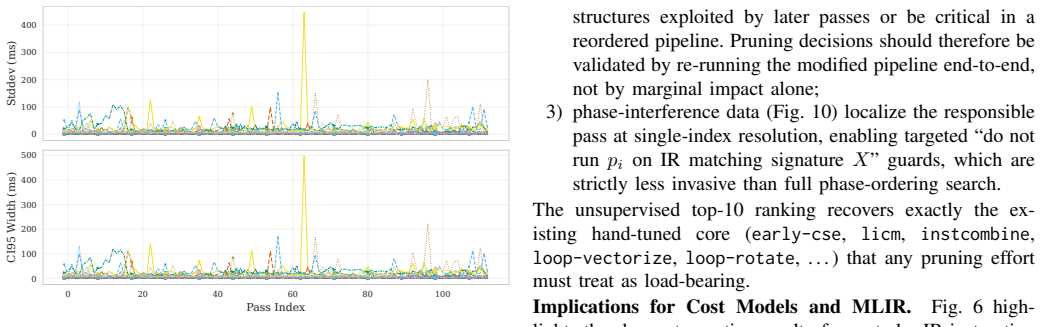
The pith
The LLVM -O3 pipeline is non-monotone with regressions in 6.6-9.7% of transitions and strongly back-loaded on compute-bound kernels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
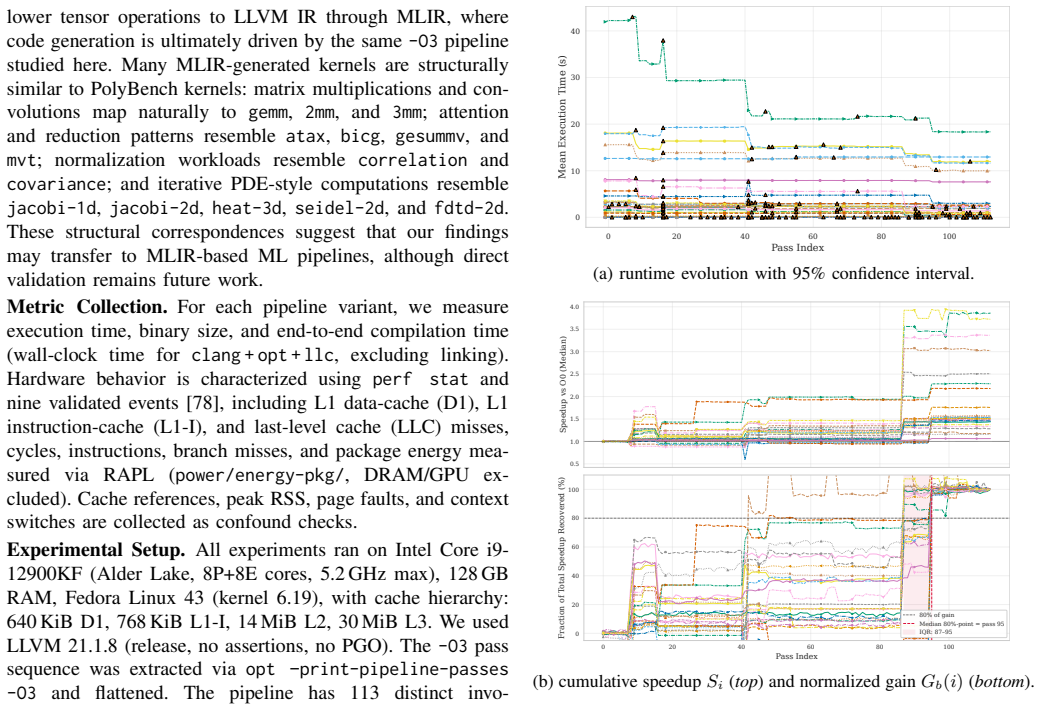
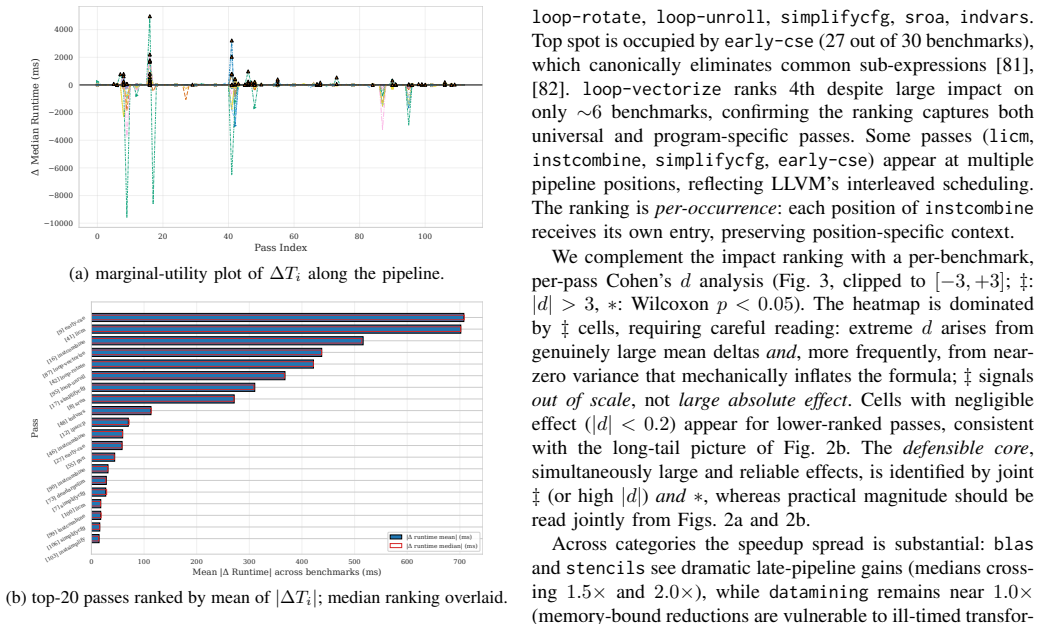
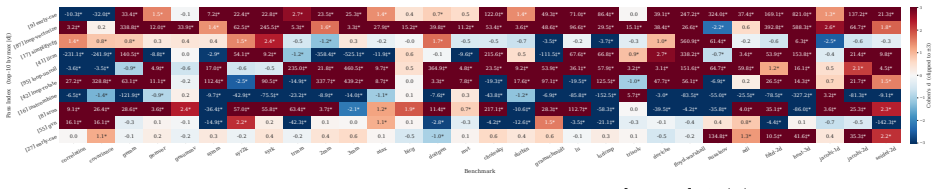
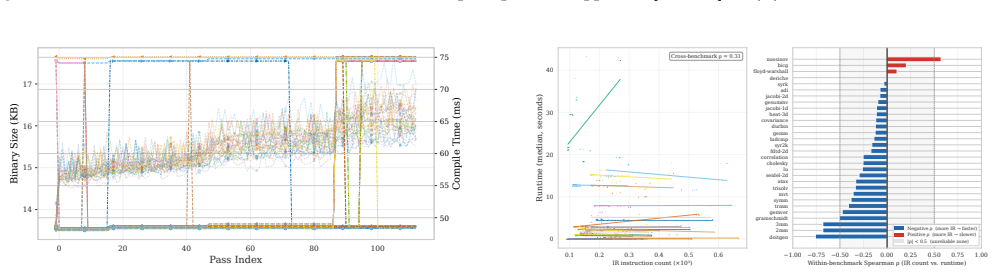
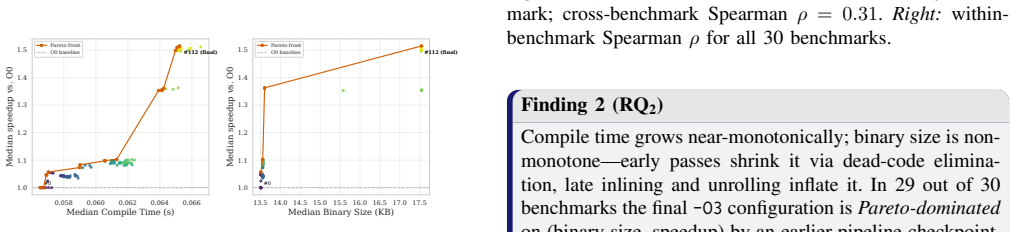
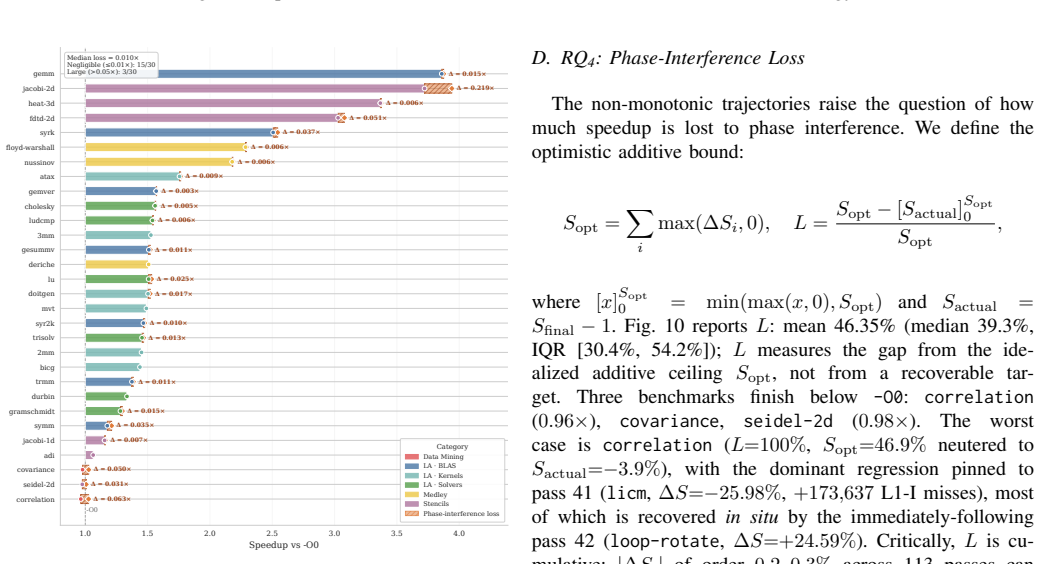
By evaluating 113 cumulative prefixes of the -O3 pipeline on 30 PolyBench/C kernels under controlled noise mitigation, the pipeline exhibits non-monotonicity (6.6-9.7% of transitions regress) and strong back-loading (median non-regressing kernel needs 84.8% of the pipeline for 80% of speedup). Most gains come from a small Pareto-dominant set of passes, the final -O3 point is Pareto-dominated on (size, speedup) for 29 of 30 kernels, IR instruction count fails to predict runtime, runtime passes also deliver 30-60% energy savings, and the idealized-additive upper bound on losses from phase interference is 46.35%.
What carries the argument
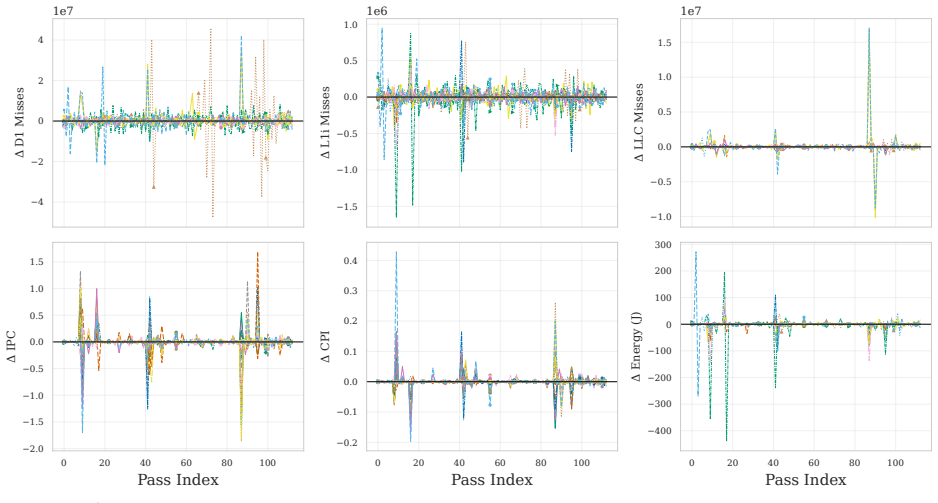
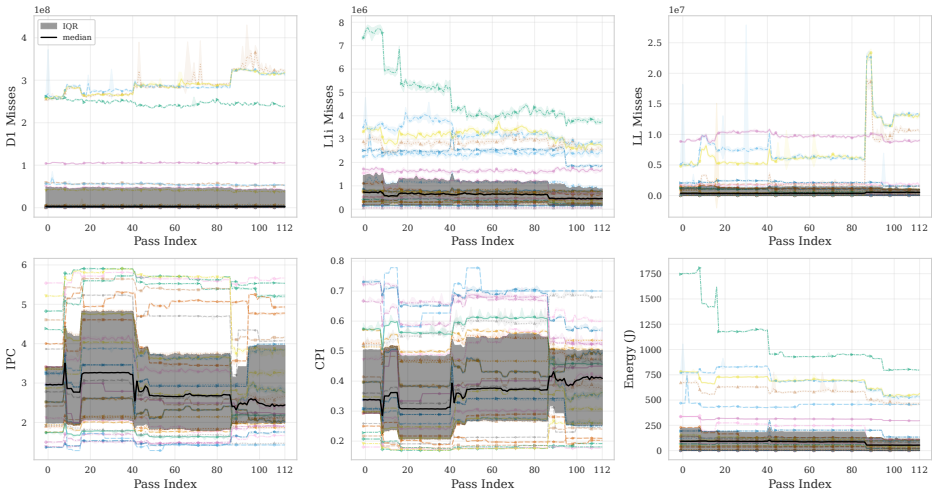
The cumulative per-pass prefix decomposition of the -O3 pipeline that isolates the marginal contribution of each pass through repeated execution-time, size, energy, and counter measurements.
If this is right
- Pass selection and pruning can focus on the small Pareto-dominant core rather than the entire pipeline.
- Cost models and autotuners must account for non-monotonic effects rather than assume additive gains.
- IR instruction count cannot be used as a reliable proxy for runtime improvements.
- Passes chosen for runtime also produce substantial energy reductions without separate targeting.
- The 46.35% idealized upper bound on interference losses sets a concrete target for improved phase ordering.
Where Pith is reading between the lines
- Similar per-pass prefix measurements could be applied to other compiler backends or to MLIR dialects to test whether the same back-loading pattern appears.
- The Pareto dominance of intermediate points suggests that production compilers could expose earlier stopping points as additional optimization levels.
- If the interference bound is tight, search-based phase ordering has a quantifiable headroom to improve on the current static -O3 sequence.
Load-bearing premise
The 30 PolyBench/C kernels and the chosen noise-mitigation protocol are representative enough that the observed non-monotonicity, back-loading, and 46.35% interference bound generalize beyond this benchmark set and measurement setup.
What would settle it
Re-running the full per-pass prefix experiment on a different benchmark suite or compiler version and observing monotonic improvement with no regressions or different back-loading percentages would falsify the reported non-monotonicity and back-loading claims.
Figures

read the original abstract
Quantifying the marginal impact of individual optimization passes underpins phase ordering, pass selection, optimization design, and analysis of pass/hardware interactions. In LLVM -- the standard backend for C/C++, Rust, and ML stacks via MLIR -- interactions among optimization passes, measurement noise, and pipeline scale make this difficult. We present a systematic, empirical study of the LLVM -O3 optimization pipeline. We decompose the pipeline into cumulative per-pass prefixes. We then measure execution time, compile time, binary size, hardware counters, and RAPL energy across 84,750 measurements covering 113 cumulative prefixes of the -O3 pipeline evaluated on 30 PolyBench/C kernels under rigorous noise mitigation. On these compute-bound affine kernels, the pipeline is non-monotone (6.6-9.7% of transitions regress) and strongly back-loaded (the median non-regressing kernel needs 84.8% of the pipeline for 80% of its speedup). Most gains are driven by a small Pareto-dominant core of passes, while the final -O3 configuration is Pareto-dominated on (size, speedup) for 29 of 30 kernels. We further show that IR instruction count is an unreliable predictor of runtime, that runtime-targeted passes are de facto energy-targeted (30-60% savings), and that the search-free idealized-additive upper bound on losses due to phase interference is 46.35%. These findings enable more informed pass pruning, cost-model calibration, and autotuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a large-scale empirical study of the LLVM -O3 pipeline by decomposing it into 113 cumulative per-pass prefixes and collecting 84,750 measurements of execution time, compile time, binary size, hardware counters, and RAPL energy on 30 PolyBench/C kernels under noise mitigation. It reports that the pipeline is non-monotone (6.6-9.7% of transitions regress), strongly back-loaded (median non-regressing kernel requires 84.8% of the pipeline for 80% of speedup), driven by a small Pareto-dominant core of passes, with the final -O3 configuration Pareto-dominated on (size, speedup) for 29 of 30 kernels; it also finds IR instruction count unreliable for runtime prediction, runtime-targeted passes yield 30-60% energy savings, and computes a search-free idealized-additive upper bound of 46.35% on losses from phase interference.
Significance. If the reported measurements hold under the described protocol, the work supplies concrete, multi-dimensional data on pass interactions and ordering effects within LLVM that can directly inform pass pruning, cost-model calibration, and autotuning research. Notable strengths include the scale of the measurement campaign, the explicit scoping to the 30 kernels, the Pareto analysis, and the derivation of a search-free interference bound from the prefix data.
major comments (2)
- [Methods / Experimental Setup] The description of the noise-mitigation protocol, the exact statistical tests used to identify regressions, and the procedure for computing the 46.35% idealized-additive upper bound from the 113 prefix measurements are insufficiently detailed; these elements are load-bearing for all central quantitative claims (non-monotonicity rates, back-loading statistic, and interference bound).
- [Results / Pareto Analysis] The claim that the final -O3 configuration is Pareto-dominated on (size, speedup) for 29 of 30 kernels rests on the specific choice of the 30 PolyBench/C kernels and the measurement protocol; the manuscript should explicitly state the sensitivity of this dominance count to alternative noise thresholds or kernel subsets.
minor comments (2)
- [Figures] Several figures would benefit from explicit error bars or confidence intervals derived from the repeated measurements to convey variability.
- [Background] The manuscript should include a short table summarizing the exact pass sequence and the 113 prefix points for reference.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and recommendation for minor revision. The comments highlight opportunities to improve methodological transparency and contextualize key claims. We address each point below and will incorporate the suggested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] The description of the noise-mitigation protocol, the exact statistical tests used to identify regressions, and the procedure for computing the 46.35% idealized-additive upper bound from the 113 prefix measurements are insufficiently detailed; these elements are load-bearing for all central quantitative claims (non-monotonicity rates, back-loading statistic, and interference bound).
Authors: We agree that expanded methodological detail is warranted for reproducibility. In the revision we will augment the Methods section with a complete description of the noise-mitigation protocol (repetition counts, outlier handling, and hardware counter collection), the precise statistical tests and thresholds used to classify regressions, and the algebraic derivation of the idealized-additive interference bound directly from the 113 prefix measurements. These additions will not change any reported numbers but will make the central claims fully verifiable. revision: yes
-
Referee: [Results / Pareto Analysis] The claim that the final -O3 configuration is Pareto-dominated on (size, speedup) for 29 of 30 kernels rests on the specific choice of the 30 PolyBench/C kernels and the measurement protocol; the manuscript should explicitly state the sensitivity of this dominance count to alternative noise thresholds or kernel subsets.
Authors: The 29-of-30 dominance result is scoped to the PolyBench/C kernels and our measurement protocol. We will add an explicit caveat in the Results section stating that the count is protocol-dependent and that sensitivity to different noise thresholds or kernel subsets is not quantified in the present study. This addition provides the requested context without requiring new experiments. revision: yes
Circularity Check
No significant circularity; purely empirical measurement study
full rationale
The paper is an empirical measurement study that decomposes the LLVM -O3 pipeline into 113 cumulative prefixes and reports direct observations (regression rates 6.6-9.7%, median back-loading 84.8%, Pareto dominance on 29/30 kernels, 46.35% idealized-additive interference bound) from 84,750 measurements on 30 PolyBench/C kernels. All central quantities are computed from the raw per-prefix execution times, sizes, and counters under the stated noise-mitigation protocol. No equations, fitted parameters, or predictions reduce by construction to quantities defined by the same measurements. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The claims are explicitly scoped to the measured set, making the derivation chain self-contained and externally replicable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On Programming of Arithmetic Operations,
A. P. Ershov, “On Programming of Arithmetic Operations,”Communica- tions of the ACM, vol. 1, no. 8, pp. 3–6, Aug. 1958
1958
-
[2]
Sequencing Aspects of Multiprogramming,
J. Heller, “Sequencing Aspects of Multiprogramming,”Journal of ACM, vol. 8, no. 3, pp. 426–439, Jul. 1961
1961
-
[3]
Peephole Optimization,
W. M. McKeeman, “Peephole Optimization,”Communications of the ACM, vol. 8, no. 7, pp. 443–444, Jul. 1965
1965
-
[4]
High Speed Compilation of Efficient Object Code,
C. W. Gear, “High Speed Compilation of Efficient Object Code,”Com- munications of the ACM, vol. 8, no. 8, pp. 483–488, Aug. 1965
1965
-
[5]
Object Code Optimization,
E. S. Lowry and C. W. Medlock, “Object Code Optimization,”Commu- nications of the ACM, vol. 12, no. 1, pp. 13–22, Jan. 1969
1969
-
[6]
Optimization of Expressions in For- tran,
V . A. Busam and D. E. Englund, “Optimization of Expressions in For- tran,”Commu. of the ACM, vol. 12, no. 12, pp. 666–674, Dec. 1969
1969
-
[7]
Program Optimization,
F. E. Allen, “Program Optimization,” inAnnual Review of Automatic Programming. Pergamon Press, 1969, vol. 5, pp. 239–307
1969
-
[8]
W. A. Wulf,The Design of an Optimizing Compiler. CMU, Dec. 1973
1973
-
[9]
K. D. Cooper and L. Torczon,Engineering a Compiler, Nov. 2022
2022
-
[10]
Kennedy and J
K. Kennedy and J. R. Allen,Optimizing Compilers for Modern Architec- tures: A Dependence-Based Approach. Morgan Kaufmann, Oct. 2001
2001
-
[11]
Future Directions in Program Transformations,
R. Paige, “Future Directions in Program Transformations,”ACM Com- puting Surveys, vol. 28, no. 4, pp. 170–174, Dec. 1996
1996
-
[12]
Compiler Transformations for High-Performance Computing,
D. F. Bacon, S. L. Graham, and O. J. Sharp, “Compiler Transformations for High-Performance Computing,”ACM Computing Surveys, vol. 26, no. 4, pp. 345–420, Dec. 1994
1994
-
[13]
Compositional Verification of Compiler Optimisations on Relaxed Memory,
M. Dodds, M. Batty, and A. Gotsman, “Compositional Verification of Compiler Optimisations on Relaxed Memory,” inProc. ESOP’18, LNCS 10801, Thessaloniki, Greece: Springer, Apr. 2018, pp. 1027–1055
2018
-
[14]
A. V . Aho, M. S. Lam, R. Sethi, and J. D. Ullman,Compilers: Principles, Techniques, and Tools, 2nd ed. Addison-Wesley, 2006
2006
-
[15]
LLVM: A Compilation Framework for Lifelong Program Analysis and Transformation,
C. Lattner and V . Adve, “LLVM: A Compilation Framework for Lifelong Program Analysis and Transformation,” inProc. CGO’04, San José, CA, USA: IEEE, Mar. 2004, pp. 75–86
2004
-
[16]
The Rust Language,
N. D. Matsakis and F. S. Klock, “The Rust Language,”ACM SIGAda Letters, vol. 34, no. 3, pp. 103–104, Oct. 2014
2014
-
[17]
Julia: A Fast Dynamic Language for Technical Computing
J. Bezanson, S. Karpinski, V . B. Shah, and A. Edelman, “Julia: A Fast Dynamic Language for Technical Computing,”arXiv e-prints, arXiv:1209.5145, pp. 1–27, Sep. 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[18]
MLIR: Scal- ing Compiler Infrastructure for Domain Specific Computation,
C. Lattner, M. Amini, U. Bondhugula, A. Cohen, A. Davis, J. Pienaar, R. Riddle, T. Shpeisman, N. Vasilache, and O. Zinenko, “MLIR: Scal- ing Compiler Infrastructure for Domain Specific Computation,” in Proc. CGO’21. Virtual: IEEE, Feb./Mar. 2021, pp. 2–14
2021
-
[19]
PyTorch: An Imperative Style, High- Performance Deep Learning Library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “PyTorch: An Imperative Style, High- Performance Deep Learning Library,” inProc. NeurIPS’19. Vancouver, Canada: Curran...
2019
-
[20]
TensorFlow: A System for Large-Scale Machine Learning,
M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, M. Kudlur, J. Levenberg, R. Monga, S. Moore, D. G. Murray, B. Steiner, P. Tucker, V . Vasudevan, P. Warden, M. Wicke, Y . Yu, and X. Zheng, “TensorFlow: A System for Large-Scale Machine Learning,” inProc. OSDI’16. Savannah, GA, USA: USENIX, Nov. 2016, pp. 265–283
2016
-
[21]
The Deep Learning Compiler: A Comprehensive Survey,
M. Li, Y . Liu, X. Liu, Q. Sun, X. You, H. Yang, Z. Luan, L. Gan, G. Yang, and D. Qian, “The Deep Learning Compiler: A Comprehensive Survey,” IEEE Trans. Par. and Distr. Syst., vol. 32, no. 3, pp. 708–727, Mar. 2021
2021
-
[22]
An In-Depth Comparison of Compilers for Deep Neural Networks on Hardware,
Y . Xing, J. Weng, Y . Wang, L. Sui, Y . Shan, and Y . Wang, “An In-Depth Comparison of Compilers for Deep Neural Networks on Hardware,” in Proc. ICESS’19. Las Vegas, NV , USA: IEEE, Jun. 2019, pp. 1–8
2019
-
[23]
Hardware Compi- lation of Deep Neural Networks: An Overview,
R. Zhao, S. Liu, H.-C. Ng, E. Wang, J. J. Davis, X. Niu, X. Wang, H. Shi, G. A. Constantinides, P. Y . K. Cheung, and W. Luk, “Hardware Compi- lation of Deep Neural Networks: An Overview,” inProc. ASAP’18. Milan, Italy: IEEE, Jul. 2018, pp. 1–8
2018
-
[24]
TinyIREE: An ML Execution Environment for Embedded Systems from Compilation to Deployment,
H.-I. C. Liu, M. Brehler, M. Ravishankar, N. Vasilache, B. Vanik, and S. Laurenzo, “TinyIREE: An ML Execution Environment for Embedded Systems from Compilation to Deployment,”IEEE Micro, vol. 42, no. 5, pp. 9–16, Sep. 2022
2022
-
[25]
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
T. Chen, T. Moreau, Z. Jiang, H. Shen, E. Q. Yan, L. Wang, Y . Hu, L. Ceze, C. Guestrin, and A. Krishnamurthy, “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning,”arXiv e-prints, arXiv:1802.04799, pp. 1–16, Oct. 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Optimizing for Re- duced Code Space Using Genetic Algorithms,
K. D. Cooper, P. J. Schielke, and D. Subramanian, “Optimizing for Re- duced Code Space Using Genetic Algorithms,” inProc. LCTES’99, Atlanta, GA, USA: ACM, May 1999, pp. 1–9
1999
-
[27]
Adaptive Optimizing Compilers for the 21st Century,
K. D. Cooper, D. Subramanian, and L. Torczon, “Adaptive Optimizing Compilers for the 21st Century,”J. Supercomputing, vol. 23, no. 1, pp. 7– 22, Aug. 2002
2002
-
[28]
Compiler Optimization-Space Exploration,
S. Triantafyllis, M. Vachharajani, N. Vachharajani, and D. I. August, “Compiler Optimization-Space Exploration,” inProc. CGO’03, San Francisco, CA, USA: IEEE, Mar. 2003, pp. 204–215
2003
-
[29]
On the Decidability of Phase Ordering Problem in Optimizing Compilation,
S.-A.-A. Touati and D. Barthou, “On the Decidability of Phase Ordering Problem in Optimizing Compilation,” inProc. CF’06, Ischia, Italy: ACM, May 2006, pp. 147–156
2006
-
[30]
Phase Ordering of Register Allocation and Instruction Scheduling,
S. M. Freudenberger and J. C. Ruttenberg, “Phase Ordering of Register Allocation and Instruction Scheduling,” inProc. WoCC’92. Daghstul, Germany: Springer, May 1991, pp. 146–170
1991
-
[31]
Leveraging Compilation Statistics for Compiler Phase Ordering,
J. Zhao, C. Xia, and Z. Wang, “Leveraging Compilation Statistics for Compiler Phase Ordering,” inProc. IPDPS’25. Milan, Italy: IEEE, Jun. 2025, pp. 533–545
2025
-
[32]
MiCOMP: Mitigating the Compiler Phase-Ordering Prob- lem Using Optimization Sub-Sequences and Machine Learning,
A. H. Ashouri, A. Bignoli, G. Palermo, C. Silvano, S. Kulkarni, and J. Cavazos, “MiCOMP: Mitigating the Compiler Phase-Ordering Prob- lem Using Optimization Sub-Sequences and Machine Learning,”ACM Trans. Arch. Code Opt., vol. 14, no. 3, pp. 29:1–29:28, Sep. 2017
2017
-
[33]
Eval- uating Heuristic Optimization Phase Order Search Algorithms,
J. W. Davidson, G. S. Tyson, D. B. Whalley, and P. A. Kulkarni, “Eval- uating Heuristic Optimization Phase Order Search Algorithms,” in Proc. CGO’07. San José, CA, USA: IEEE, Mar. 2007, pp. 157–169
2007
-
[34]
Phase Coupling and Constant Generation in an Optimiz- ing Microcode Compiler,
S. R. Vegdahl, “Phase Coupling and Constant Generation in an Optimiz- ing Microcode Compiler,” inProc. MICRO’82, Oct. 1982, pp. 125–133
1982
-
[35]
A Graph-Based Iterative Compiler Pass Selection and Phase Ordering Approach,
R. Nobre, L. G. A. Martins, and J. a. M. P. Cardoso, “A Graph-Based Iterative Compiler Pass Selection and Phase Ordering Approach,” in Proc. LCTES’16. Santa Barbara, USA: ACM, Jun. 2016, pp. 21–30
2016
-
[36]
Using Machine Learning to Focus Iterative Optimization,
F. Agakov, E. V . Bonilla, J. Cavazos, B. Franke, G. Fursin, M. F. P. O’Boyle, J. Thomson, M. Toussaint, and C. K. I. Williams, “Using Machine Learning to Focus Iterative Optimization,” in Proc. CGO’06, New York, NY , USA: IEEE, Mar. 2006, pp. 305–315
2006
-
[37]
An Approach to Ordering Optimizing Transformations,
D. L. Whitfield and M. L. Soffa, “An Approach to Ordering Optimizing Transformations,” inProc. PPoPP’90, ACM, Mar. 1990, pp. 137–146
1990
-
[38]
Towards Efficient Compiler Auto-tuning: Leveraging Synergistic Search Spaces,
H. Pan, Y . Wei, M. Xing, Y . Wu, and C. Zhao, “Towards Efficient Compiler Auto-tuning: Leveraging Synergistic Search Spaces,” in Proc. CGO’25. Las VEgas, NV , USA: IEEE, Mar. 2025, pp. 614–627
2025
-
[39]
Compiler Autotuning through Multiple- phase Learning,
M. Zhu, D. Hao, and J. Chen, “Compiler Autotuning through Multiple- phase Learning,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 4, pp. 1–38, May 2024
2024
-
[40]
A Survey on Compiler Autotuning using Machine Learning,
A. H. Ashouri, W. Killian, J. Cavazos, G. Palermo, and C. Silvano, “A Survey on Compiler Autotuning using Machine Learning,”ACM Com- puting Surveys, vol. 51, no. 5, pp. 96:1–96:42, Sep. 2018
2018
-
[41]
A Scalable Auto-Tuning Framework for Compiler Optimization,
A. Tiwari, C. Chen, J. Chame, M. Hall, and J. K. Hollingsworth, “A Scalable Auto-Tuning Framework for Compiler Optimization,” in Proc. IPDPS’09, Rome, Italy: IEEE, May 2009, pp. 1–12
2009
-
[42]
PEAK—A Fast and Effective Perfor- mance Tuning System via Compiler Optimization Orchestration,
Z. Pan and R. Eigenmann, “PEAK—A Fast and Effective Perfor- mance Tuning System via Compiler Optimization Orchestration,”ACM Transactions on Programming Languages and Systems, vol. 30, no. 3, pp. 17:1–17:43, May 2008
2008
-
[43]
Fast and Effective Orchestration of Compiler Optimizations for Automatic Performance Tuning,
——, “Fast and Effective Orchestration of Compiler Optimizations for Automatic Performance Tuning,” inProc. CGO’06, 2006, pp. 319–332
2006
-
[44]
Fast Searches for Effective Optimization Phase Sequences,
P. Kulkarni, S. Hines, J. Hiser, D. Whalley, J. Davidson, and D. Jones, “Fast Searches for Effective Optimization Phase Sequences,” in Proc. PLDI’04, Washington, DC, USA: ACM, Jun. 2004, pp. 171–182
2004
-
[45]
Finding Good Optimization Sequences Covering Program Space,
S. Purini and L. Jain, “Finding Good Optimization Sequences Covering Program Space,”ACM Trans. Arch. Code Opt., vol. 9, no. 4, Jan. 2013
2013
-
[46]
Mitigating the Compiler Optimization Phase-Ordering Problem Using Machine Learning,
S. Kulkarni and J. Cavazos, “Mitigating the Compiler Optimization Phase-Ordering Problem Using Machine Learning,” inProc. OOP- SLA’12. Tucson, AZ, USA: ACM, Oct. 2012, pp. 147–162
2012
-
[47]
Finding Effective Optimization Phase Sequences,
P. Kulkarni, W. Zhao, H. Moon, K. Cho, D. Whalley, J. Davidson, M. Bailey, Y . Paek, and K. Gallivan, “Finding Effective Optimization Phase Sequences,” inProc. LCTES’03, ACM, Jun. 2003, pp. 12–23
2003
-
[48]
An Approach for Exploring Code Improving Transformations,
D. L. Whitfield and M. L. Soffa, “An Approach for Exploring Code Improving Transformations,”ACM Transactions on Programming Lan- guages and Systems, vol. 19, no. 6, pp. 1053–1084, Nov. 1997
1997
-
[49]
Finding Effective Compilation Se- quences,
L. Almagor, K. Cooper, A. Grosul, T. Harvey, S. Reeves, D. Subramanian, L. Torczon, and T. Waterman, “Finding Effective Compilation Se- quences,” inProc. LCTES’04, ACM, Jun. 2004, pp. 231–239
2004
-
[50]
An Approach Toward Profit- Driven Optimization,
M. Zhao, B. R. Childers, and M. L. Soffa, “An Approach Toward Profit- Driven Optimization,”ACM Transactions on Architecture and Code Optimization, vol. 3, no. 3, pp. 231–262, Sep. 2006
2006
-
[51]
Efficient Com- piler Optimization by Modeling Passes Dependence,
J. Liu, J. Fang, T. Wang, J. Xie, C. Huang, and Z. Wang, “Efficient Com- piler Optimization by Modeling Passes Dependence,”CCF Transactions on High Performance Computing, vol. 6, no. 6, pp. 588–607, Dec. 2024
2024
-
[52]
Less is More: Exploiting the Standard Compiler Optimization Levels for Better Performance and Energy Consumption,
K. Georgiou, C. Blackmore, S. Xavier-de Souza, and K. Eder, “Less is More: Exploiting the Standard Compiler Optimization Levels for Better Performance and Energy Consumption,” inProc. SCOPES’18, Sankt Goar, Germany: ACM, May 2018, pp. 35–42
2018
-
[53]
What Every Scientific Program- mer Should Know about Compiler Optimizations?
J. Tan, S. Jiao, M. Chabbi, and X. Liu, “What Every Scientific Program- mer Should Know about Compiler Optimizations?” inProc. ICS’20. Barcelona, Spain: ACM, Jun./Jul. 2020, pp. 1–12
2020
-
[54]
Exploiting Undefined Behavior in C/C++ Programs for Optimization: A Study on the Performance Impact,
L. Popescu and N. P. Lopes, “Exploiting Undefined Behavior in C/C++ Programs for Optimization: A Study on the Performance Impact,” in Proc. PLDI’25, Seoul, South Korea: ACM, Jun. 2025, pp. 348–371
2025
-
[55]
Analyzing the Effects of Compiler Optimizations on Application Reliability,
M. Demertzi, M. Annavaram, and M. Hall, “Analyzing the Effects of Compiler Optimizations on Application Reliability,” inProc. IISWC’11, Austin, TX, USA: IEEE, Nov. 2011, pp. 184–193
2011
-
[56]
Rapidly Selecting Good Compiler Optimizations using Performance Counters,
J. Cavazos, G. Fursin, F. Agakov, E. Bonilla, M. F. P. O’Boyle, and O. Temam, “Rapidly Selecting Good Compiler Optimizations using Performance Counters,” inProc. CGO’07, Mar. 2007, pp. 185–197
2007
-
[57]
Analyzing the Influence of LLVM Code Optimization Passes on Software Perfor- mance,
J. C. de la Torre, P. Ruiz, B. Dorronsoro, and P. L. Galindo, “Analyzing the Influence of LLVM Code Optimization Passes on Software Perfor- mance,” inProc. IPMU’18, CCIS 855. Springer, Jun. 2018, pp. 272–283
2018
-
[58]
Evaluating End-to-End Optimization for Data Analytics Applications in Weld,
S. Palkar, J. Thomas, D. Narayanan, P. Thaker, R. Palamuttam, P. Negi, A. Shanbhag, M. Schwarzkopf, H. Pirk, S. Amarasinghe, S. Madden, and M. Zaharia, “Evaluating End-to-End Optimization for Data Analytics Applications in Weld,” inProc. VLDB’18, May 2018, pp. 1002–1015
2018
-
[59]
It’s Not Easy Being Green: On the Energy Efficiency of Programming Lan- guages,
N. van Kempen, H.-J. Kwon, D. T. Nguyen, and E. D. Berger, “It’s Not Easy Being Green: On the Energy Efficiency of Programming Lan- guages,” inProc. ASE’25, IEEE, Nov. 2025, pp. 1553–1565
2025
-
[60]
A Survey of Energy Concerns for Software Engineering,
S. U. Lee, N. Fernando, K. Lee, and J.-G. Schneider, “A Survey of Energy Concerns for Software Engineering,”J. Syst. Soft., vol. 210, Apr. 2024
2024
-
[61]
Energy Efficiency Across Programming Languages,
R. Pereira, M. Couto, F. Ribeiro, R. Rua, J. Cunha, J. P. Fernandes, and J. Saraiva, “Energy Efficiency Across Programming Languages,” in Proc. SLE’17. Vancouver, BC, Canada: ACM, Oct. 2017, pp. 256–267
2017
-
[62]
Deconstructing Iterative Optimization,
Y . Chen, S. Fang, Y . Huang, L. Eeckhout, G. Fursin, O. Temam, and C. Wu, “Deconstructing Iterative Optimization,”ACM Trans. Arch. Code Opt., vol. 9, no. 3, pp. 21:1–21:30, Oct. 2012
2012
-
[63]
Global Value Numbers and Redundant Computations,
B. K. Rosen, M. N. Wegman, and F. K. Zadeck, “Global Value Numbers and Redundant Computations,” inProc. PoPL’88, Jan. 1988, pp. 12–27
1988
-
[64]
Detecting Equality of Variables in Programs,
B. Alpern, M. N. Wegman, and F. K. Zadeck, “Detecting Equality of Variables in Programs,” inProc. PoPL’88, ACM, Jan. 1988, pp. 1–11
1988
-
[65]
An Efficient Method of Computing Static Single Assignment Form,
R. Cytron, J. Ferrante, B. K. Rosen, M. N. Wegman, and F. K. Zadeck, “An Efficient Method of Computing Static Single Assignment Form,” inProc. POPL’89, Austin, TX, USA: ACM, Jan. 1989, pp. 25–35
1989
-
[66]
Interprocedural Constant Propagation,
D. Callahan, K. D. Cooper, K. Kennedy, and L. Torczon, “Interprocedural Constant Propagation,” inProc. SCC’86, ACM, Jun. 1986, pp. 152–161
1986
-
[67]
Constant Propagation with Condi- tional Branches,
M. N. Wegman and F. K. Zadeck, “Constant Propagation with Condi- tional Branches,”ACM Transactions on Programming Languages and Systems, vol. 13, no. 2, pp. 181–210, Apr. 1991
1991
-
[68]
Efficiently Computing Static Single Assignment Form and the Control Dependence Graph,
R. Cytron, J. Ferrante, B. K. Rosen, M. N. Wegman, and F. K. Zadeck, “Efficiently Computing Static Single Assignment Form and the Control Dependence Graph,”ACM Transactions on Programming Languages and Systems, vol. 13, no. 4, pp. 451–490, Oct. 1991
1991
-
[69]
S. S. Muchnick,Advanced Compiler Design and Implementation, 1st ed. Morgan Kaufmann, Aug. 1997
1997
-
[70]
Scalar Replacement in the Presence of Condi- tional Control Flow,
S. Carr and K. Kennedy, “Scalar Replacement in the Presence of Condi- tional Control Flow,”Software—Practice and Experience, vol. 24, no. 1, pp. 51–77, Jan. 1994
1994
-
[71]
Register Promotion in C Programs,
J. Lu and K. D. Cooper, “Register Promotion in C Programs,” in Proc. PLDI’97, Las Vegas, NV , USA: ACM, Jun. 1997, pp. 308–319
1997
-
[72]
Inline Function Expansion for Compiling C Programs,
P. P. Chang and W.-W. Hwu, “Inline Function Expansion for Compiling C Programs,” inProc. PLDI’89, Portland, USA: Jun. 1989, pp. 246–257
1989
-
[73]
Unrolling loops in Fortran,
J. J. Dongarra and A. R. Hinds, “Unrolling loops in Fortran,”Software— Practice and Experience, vol. 9, no. 3, pp. 219–226, Mar. 1979
1979
-
[74]
An Aggressive Approach to Loop Unrolling,
J. W. Davidson and S. Jinturkar, “An Aggressive Approach to Loop Unrolling,” University of Virginia, V A, USA, TR-CS-95-26, Jan. 1995
1995
-
[75]
Partial Dead Code Elimination,
J. Knoop, O. Rüthing, and B. Steffen, “Partial Dead Code Elimination,” inProc. PLDI’94, Orlando, FL, USA: ACM, Jun. 1994, pp. 147–158
1994
-
[76]
A Catalogue of Optimizing Transformations,
F. E. Allen and J. Cocke, “A Catalogue of Optimizing Transformations,” inDesign and Optimization of Compilers, Prentice-Hall, 1972, pp. 1–30
1972
-
[77]
Understanding PolyBench/C 3.2 Kernels,
T. Yuki, “Understanding PolyBench/C 3.2 Kernels,” inProc. IM- PACT’14, Wien, Austria, Jan. 2014, pp. 1–5
2014
-
[78]
Can Hardware Performance Counters Be Trusted?
V . M. Weaver and S. A. McKee, “Can Hardware Performance Counters Be Trusted?” inProc. IISWC’08, IEEE, Sep. 2008, pp. 141–150
2008
-
[79]
Statistically Rigorous Java Performance Evaluation,
A. Georges, D. Buytaert, and L. Eeckhout, “Statistically Rigorous Java Performance Evaluation,” inProc. OOPSLA’07, Montréal, Canada: ACM, Oct. 2007, pp. 57–76
2007
-
[80]
Produc- ing Wrong Data Without Doing Anything Obviously Wrong!
T. Mytkowicz, A. Diwan, M. Hauswirth, and P. F. Sweeney, “Produc- ing Wrong Data Without Doing Anything Obviously Wrong!” in Proc. ASPLOS’09, Washington, USA: ACM, Mar. 2009, pp. 265–276
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.