MOA: A Profiling-Guided LLM Framework for Memory-Optimization Automation at Codebase Scale
Pith reviewed 2026-07-01 04:14 UTC · model grok-4.3
The pith
MOA uses three LLM agents guided by profiling data to detect memory anti-patterns and generate patches that reduce heap usage by 42.2 percent on average in large codebases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
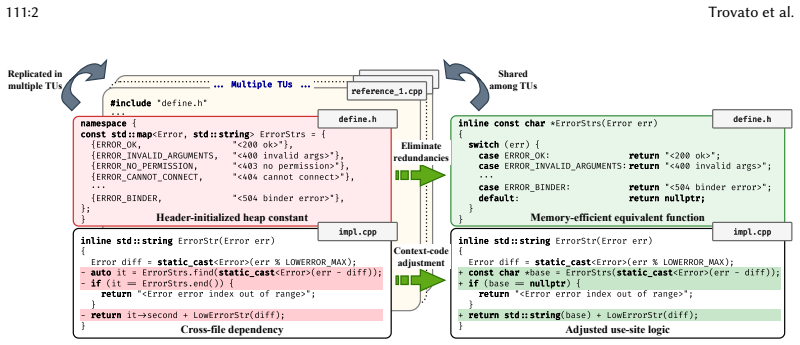
MOA identifies 13 memory anti-patterns, nine of them previously unknown, from three profiled services in OpenHarmony, then detects more than 10,000 inefficiencies across seven services and produces 769 patches that receive 92.5 percent expert acceptance while delivering average heap reductions of 42.2 percent and binary-size reductions of 10.6 percent.
What carries the argument
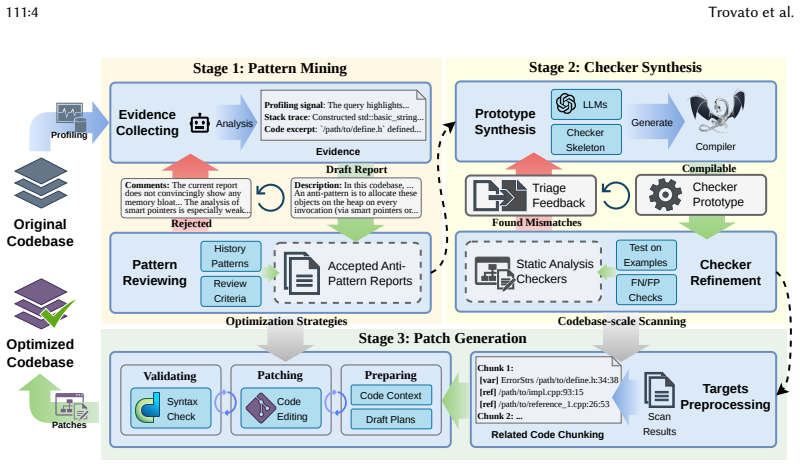
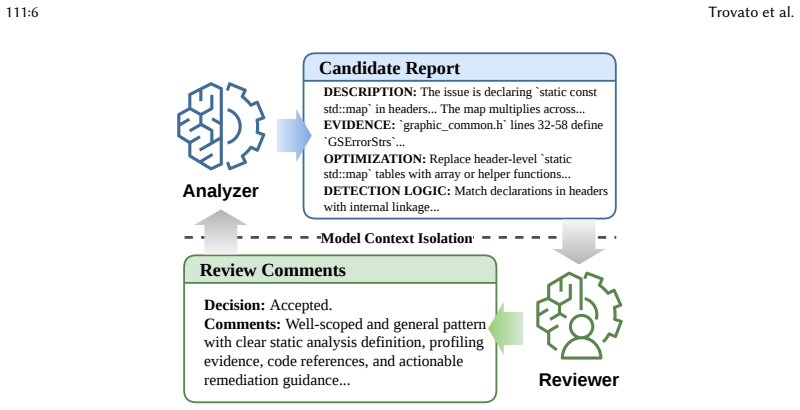
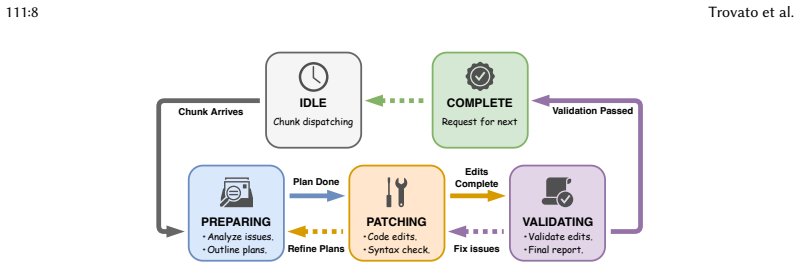
Three-agent LLM pipeline in which the Analyzer mines anti-patterns from profiling data, the Checker Generator synthesizes static analyzers through template-guided refinement, and the Patcher generates optimization patches through state-machine-driven workflows.
If this is right
- MOA scales memory optimization to codebases larger than 100 million lines of C/C++ code.
- The framework detects over 10,000 distinct memory inefficiencies across multiple production services.
- Generated patches achieve a 92.5 percent expert acceptance rate.
- Average measured improvements include 42.2 percent heap reduction and 10.6 percent binary size reduction.
Where Pith is reading between the lines
- The anti-pattern mining step could be rerun periodically as code evolves to keep optimizations current.
- The same agent structure might be repurposed for other resource problems such as CPU or I/O inefficiencies.
- If the generated checkers are integrated into continuous integration, they could prevent reintroduction of known inefficiencies.
- The approach could be tested on additional large C/C++ systems to determine how many of the 13 anti-patterns recur elsewhere.
Load-bearing premise
Expert acceptance of the generated patches is treated as sufficient proof that the changes preserve original program semantics and introduce no new bugs or regressions.
What would settle it
Run the 769 patched services against their original regression test suites and workload traces, then compare outputs and resource metrics to confirm identical behavior and no introduced slowdowns or crashes.
Figures
read the original abstract
Modern large-scale software systems often suffer from pervasive memory inefficiencies (e.g., bloat, churn), leading to excessive resource costs and performance degradation. Existing optimization workflows lack end-to-end automation, forcing developers to manually synthesize complex tool outputs into actionable and semantics-preserving fixes, precluding scalability in large codebases. To address this, this paper presents MOA, an LLM-driven framework that automatically detects and repairs recurring memory inefficiencies across production-scale codebases. Specifically, MOA operates through three agents: an Analyzer that mines anti-patterns from profiling data, a Checker Generator that synthesizes static analyzers through template-guided refinement, and a Patcher that generates optimization patches via state-machine-driven workflows. Our evaluation on OpenHarmony, an open-source operating system with over 100 million lines of C/C++ code, shows that MOA identifies 13 anti-patterns (9 previously unknown) from 3 profiled services, detects over 10,000 inefficiencies across a broader set of 7 services, and generates 769 patches with 92.5% expert acceptance rate, achieving 42.2% heap reduction and 10.6% binary size reduction on average. We envision MOA as a valuable tool for performance engineering at production scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MOA, an LLM-driven framework with three agents (Analyzer for mining anti-patterns from profiling data, Checker Generator for synthesizing static analyzers, and Patcher for generating optimization patches via state-machine workflows) to automate detection and repair of memory inefficiencies in large C/C++ codebases. Evaluated on OpenHarmony (>100M LOC), it claims identification of 13 anti-patterns (9 previously unknown) from 3 services, detection of >10,000 inefficiencies across 7 services, generation of 769 patches at 92.5% expert acceptance, and average reductions of 42.2% heap usage and 10.6% binary size.
Significance. If the reported outcomes are confirmed with rigorous validation of semantic preservation and performance gains, the work would represent a meaningful advance in scaling automated performance engineering to production codebases using LLMs, potentially reducing manual effort in identifying and fixing memory bloat and churn. The combination of profiling-guided anti-pattern mining with LLM-based checker and patch generation is a promising direction, though current evidence strength limits immediate impact assessment.
major comments (3)
- [Evaluation (abstract and results description)] Abstract and Evaluation section: The central claims of 769 patches at 92.5% expert acceptance, 42.2% average heap reduction, and 10.6% binary size reduction rest on expert acceptance as the primary correctness gate, but no details are provided on regression test execution, differential testing against unpatched baselines, formal verification, or how semantic preservation and absence of new bugs/performance regressions were validated. This directly affects the reliability of the quantitative outcomes.
- [Evaluation] Evaluation section: No information is supplied on baselines used for the reported reductions, statistical significance of the 42.2% and 10.6% figures, blinding or measurement protocol for the 92.5% expert acceptance rate, or exclusion criteria for the 769 patches. These omissions make it impossible to assess whether the results reflect verified end-to-end improvements or optimistic selection.
- [Patcher and Checker Generator (framework description)] Patcher agent description: The state-machine-driven workflow is outlined at a high level, but without concrete examples of how the Patcher ensures patches are semantics-preserving or how the Checker Generator's static analyzers are validated for soundness, the scalability claims for 10,000+ detected inefficiencies cannot be fully evaluated.
minor comments (2)
- [Abstract] The abstract would benefit from briefly noting the total lines of code or number of services profiled to contextualize the scale.
- [Framework overview] Notation for the three agents (Analyzer, Checker Generator, Patcher) could be introduced with a diagram or table for clarity in the framework overview.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing the need for rigorous validation details. We address each major comment point-by-point below and will make revisions to the manuscript to incorporate the suggested clarifications.
read point-by-point responses
-
Referee: [Evaluation (abstract and results description)] Abstract and Evaluation section: The central claims of 769 patches at 92.5% expert acceptance, 42.2% average heap reduction, and 10.6% binary size reduction rest on expert acceptance as the primary correctness gate, but no details are provided on regression test execution, differential testing against unpatched baselines, formal verification, or how semantic preservation and absence of new bugs/performance regressions were validated. This directly affects the reliability of the quantitative outcomes.
Authors: We concur that the manuscript would benefit from explicit details on validation procedures. In the revised version, we will add a new subsection under Evaluation describing the validation process: expert reviewers assessed semantic preservation by reviewing patch diffs against original code semantics; all 769 patches were applied to the codebase and subjected to the project's regression test suites; differential testing compared heap and binary metrics on patched versus baseline builds. Formal verification was not applied owing to the scale of OpenHarmony. These additions will clarify the reliability of the reported outcomes. revision: yes
-
Referee: [Evaluation] Evaluation section: No information is supplied on baselines used for the reported reductions, statistical significance of the 42.2% and 10.6% figures, blinding or measurement protocol for the 92.5% expert acceptance rate, or exclusion criteria for the 769 patches. These omissions make it impossible to assess whether the results reflect verified end-to-end improvements or optimistic selection.
Authors: We will expand the Evaluation section to provide the requested information. Baselines are the original unpatched versions of the 7 services. Reductions are reported as averages with standard deviations to indicate variability. The expert acceptance involved a protocol where three independent experts reviewed patches in a blinded manner (unaware of patch origin), with acceptance requiring consensus on correctness and lack of regressions. Exclusion criteria encompassed patches that failed to compile cleanly or were rejected by experts for introducing behavioral changes. This information will be included to allow proper assessment of the results. revision: yes
-
Referee: [Patcher and Checker Generator (framework description)] Patcher agent description: The state-machine-driven workflow is outlined at a high level, but without concrete examples of how the Patcher ensures patches are semantics-preserving or how the Checker Generator's static analyzers are validated for soundness, the scalability claims for 10,000+ detected inefficiencies cannot be fully evaluated.
Authors: We agree that concrete examples would strengthen the framework description. In the revision, we will include specific examples in the Patcher and Checker Generator sections. For the Patcher, we will describe the state transitions for one anti-pattern (e.g., unnecessary string copies), showing how it generates a patch that reuses buffers while the workflow includes a verification step using the synthesized checker to confirm no semantic changes. For the Checker Generator, we will detail validation against a set of manually verified anti-pattern instances from the profiling data, reporting precision and recall metrics. These examples will support the scalability evaluation. revision: yes
Circularity Check
No circularity: empirical measurements on external codebase
full rationale
The paper describes an LLM-based framework (Analyzer, Checker Generator, Patcher) evaluated via direct measurements on the external OpenHarmony codebase: 13 anti-patterns identified from 3 services, >10k inefficiencies across 7 services, 769 patches at 92.5% expert acceptance, and reported heap/binary reductions. No equations, fitted parameters, predictions derived from inputs, self-definitional constructs, or load-bearing self-citations appear in the abstract or described workflow. All central claims are presented as empirical outcomes on independent code, with no reduction of results to the framework's own definitions or prior author work by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Christian Bird, Adrian Bachmann, Eirik Aune, John Duffy, Abraham Bernstein, Vladimir Filkov, and Premkumar Devanbu. 2009. Fair and balanced? bias in bug-fix datasets. InProceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering (Amsterdam, The Netherlands)(E...
-
[2]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2025. RepairAgent: An Autonomous, LLM-Based Agent for Program Repair. InProceedings of the IEEE/ACM 47th International Conference on Software Engineering(Ottawa, Ontario, Canada)(ICSE ’25). IEEE Press, 2188–2200. doi:10.1109/ICSE55347.2025.00157
-
[3]
Stuart Byma and James R. Larus. 2018. Detailed heap profiling(ISMM 2018). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/3210563.3210564
-
[4]
Milind Chabbi and John Mellor-Crummey. 2012. DeadSpy: a tool to pinpoint program inefficiencies. InProceedings of the Tenth International Symposium on Code Generation and Optimization(San Jose, California)(CGO ’12). Association for Computing Machinery, New York, NY, USA, 124–134. doi:10.1145/2259016.2259033 J. ACM, Vol. 37, No. 4, Article 111. Publication...
-
[5]
Ting Dai, Daniel Dean, Peipei Wang, Xiaohui Gu, and Shan Lu. 2019. Hytrace: A Hybrid Approach to Performance Bug Diagnosis in Production Cloud Infrastructures.IEEE Transactions on Parallel and Distributed Systems30, 1 (2019), 107–118. doi:10.1109/TPDS.2018.2858800
-
[6]
Spandan Garg, Roshanak Zilouchian Moghaddam, and Neel Sundaresan. 2025. RAPGen: An Approach for Fixing Code Inefficiencies in Zero-Shot. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 124–135. doi:10.1109/ICSE-SEIP66354.2025.00017
-
[7]
Github. 2025. CodeQL. https://codeql.github.com/. Accessed: 2025-01-29
2025
-
[8]
Google gperftools contributors. 2025. gperftools. https://github.com/gperftools/gperftools. Accessed: 2025-01-29
2025
-
[9]
Susan L. Graham, Peter B. Kessler, and Marshall K. Mckusick. 1982. Gprof: A call graph execution profiler. InProceedings of the 1982 SIGPLAN Symposium on Compiler Construction(Boston, Massachusetts, USA)(SIGPLAN ’82). Association for Computing Machinery, New York, NY, USA, 120–126. doi:10.1145/800230.806987
-
[10]
Guo, Thomas Zimmermann, Nachiappan Nagappan, and Brendan Murphy
Philip J. Guo, Thomas Zimmermann, Nachiappan Nagappan, and Brendan Murphy. 2010. Characterizing and predicting which bugs get fixed: an empirical study of Microsoft Windows. InProceedings of the 32nd ACM/IEEE International Conference on Software Engineering - Volume 1(Cape Town, South Africa)(ICSE ’10). Association for Computing Machinery, New York, NY, U...
-
[11]
Xue Han, Tingting Yu, and David Lo. 2018. PerfLearner: learning from bug reports to understand and generate performance test frames. InProceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering(Montpellier, France)(ASE ’18). Association for Computing Machinery, New York, NY, USA, 17–28. doi:10.1145/3238147.3238204
- [12]
-
[13]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2026. A Survey on Large Language Models for Code Generation.ACM Trans. Softw. Eng. Methodol.35, 2, Article 58 (Jan. 2026), 72 pages. doi:10.1145/3747588
-
[14]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. SWE-bench: Can language models resolve real-world GitHub issues? (Oct. 2023). arXiv:2310.06770 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Guoliang Jin, Linhai Song, Xiaoming Shi, Joel Scherpelz, and Shan Lu. 2012. Understanding and detecting real- world performance bugs. InProceedings of the 33rd ACM SIGPLAN Conference on Programming Language Design and Implementation(Beijing, China)(PLDI ’12). Association for Computing Machinery, New York, NY, USA, 77–88. doi:10.1145/2254064.2254075
-
[16]
Wu Jingwen, Hanyang Guo, Hong-Ning Dai, and Xiapu Luo. 2026. XRFix: Exploring Performance Bug Repair of Extended Reality Applications with Large Language Models. doi:10.1145/3744916.3773120
-
[17]
Li Li, Xiang Gao, Hailong Sun, Chunming Hu, Carolyn Sun, Haoyu Wang, Haipeng Cai, Ting Su, Xiapu Luo, Tegawendé Bissyande, Jacques Klein, John Grundy, Tao Xie, Haibo Chen, and Huaimin Wang. 2025. Software Engineering for OpenHarmony: A Research Roadmap.ACM Comput. Surv.58, 2, Article 34 (Sept. 2025), 36 pages. doi:10.1145/3720538
- [18]
-
[19]
Hannah Lin, Martin Maas, Maximilian Roquemore, Arman Hasanzadeh, Fred Lewis, Yusuf Simonson, Tzu-Wei Yang, Amir Yazdanbakhsh, Deniz Altinbüken, Florin Papa, et al. 2025. ECO: An LLM-driven efficient code optimizer for warehouse scale computers.arXiv preprint arXiv:2503.15669(2025)
-
[20]
LLVM Project. 2025. Clang Static Analyzer. https://clang.llvm.org/docs/ClangStaticAnalyzer.html. Accessed: 2025-01- 29
2025
-
[21]
Meta Infer contributors. 2025. Infer. https://github.com/facebook/infer. Accessed: 2025-01-29
2025
-
[22]
Nicholas Nethercote and Julian Seward. 2007. Valgrind: a framework for heavyweight dynamic binary instrumentation. InProceedings of the 28th ACM SIGPLAN Conference on Programming Language Design and Implementation(San Diego, California, USA)(PLDI ’07). Association for Computing Machinery, New York, NY, USA, 89–100. doi:10.1145/1250734. 1250746
-
[23]
Adrian Nistor, Po-Chun Chang, Cosmin Radoi, and Shan Lu. 2015. CARAMEL: Detecting and Fixing Performance Problems That Have Non-Intrusive Fixes. In2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Vol. 1. 902–912. doi:10.1109/ICSE.2015.100
- [24]
-
[25]
Oswaldo Olivo, Isil Dillig, and Calvin Lin. 2015. Static detection of asymptotic performance bugs in collection traversals. SIGPLAN Not.50, 6 (June 2015), 369–378. doi:10.1145/2813885.2737966
-
[26]
OpenAtom Foundation. 2025. OpenHarmony: A Comprehensive Open Source Project for All-Scenario, Fully-Connected, and Intelligent Era. https://gitee.com/openharmony. Accessed: 2025-01-29. J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018. MOA: A Profiling-Guided LLM Framework for Memory-Optimization Automation at Codebase Scale 111:19
2025
-
[27]
Michael Pradel, Markus Huggler, and Thomas R. Gross. 2014. Performance regression testing of concurrent classes. In Proceedings of the 2014 International Symposium on Software Testing and Analysis(San Jose, CA, USA)(ISSTA 2014). Association for Computing Machinery, New York, NY, USA, 13–25. doi:10.1145/2610384.2610393
-
[28]
Marija Selakovic and Michael Pradel. 2015. Automatically fixing real-world JavaScript performance bugs. InProceedings of the 37th International Conference on Software Engineering - Volume 2(Florence, Italy)(ICSE ’15). IEEE Press, 811–812
2015
-
[29]
Semgrep. 2025. Semgrep. https://github.com/semgrep/semgrep. Accessed: 2025-01-29
2025
-
[30]
Ze Sheng, Zhicheng Chen, Shuning Gu, Heqing Huang, Guofei Gu, and Jeff Huang. 2025. LLMs in Software Security: A Survey of Vulnerability Detection Techniques and Insights.ACM Comput. Surv.58, 5, Article 134 (Nov. 2025), 35 pages. doi:10.1145/3769082
-
[31]
Linhai Song and Shan Lu. 2014. Statistical debugging for real-world performance problems.SIGPLAN Not.49, 10 (Oct. 2014), 561–578. doi:10.1145/2714064.2660234
-
[32]
The YARA contributors. 2025. YARA. https://github.com/virustotal/yara. Accessed: 2025-01-29
2025
- [33]
-
[34]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated Program Repair via Conversation: Fixing 162 out of 337 Bugs for $0.42 Each using ChatGPT. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vienna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 819–831. doi:10.1145/3650212.3680323
-
[35]
Wenda Xu, Guanglei Zhu, Xuandong Zhao, Liangming Pan, Lei Li, and William Wang. 2024. Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement. InProceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Lingu...
-
[36]
Boyang Yang, Zijian Cai, Fengling Liu, Bach Le, Lingming Zhang, Tegawendé F Bissyandé, Yang Liu, and Haoye Tian
- [37]
-
[38]
Chenyuan Yang, Zijie Zhao, Zichen Xie, Haoyu Li, and Lingming Zhang. 2025. KNighter: Transforming Static Analysis with LLM-Synthesized Checkers. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles (Seoul, Republic of Korea)(SOSP ’25). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3731569. 3764827
-
[39]
Zezhou Yang, Sirong Chen, Cuiyun Gao, Zhenhao Li, Xing Hu, Kui Liu, and Xin Xia. 2025. An Empirical Study of Retrieval-Augmented Code Generation: Challenges and Opportunities.ACM Trans. Softw. Eng. Methodol.34, 7 (2025), 188:1–188:28
2025
-
[40]
Xin Yin, Chao Ni, Shaohua Wang, Zhenhao Li, Limin Zeng, and Xiaohu Yang. 2024. ThinkRepair: Self-Directed Automated Program Repair. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vienna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 1274–1286. doi:10.1145/3650212.3680359
-
[41]
Zheng Yu, Ziyi Guo, Yuhang Wu, Jiahao Yu, Meng Xu, Dongliang Mu, Yan Chen, and Xinyu Xing. 2025. PATCHAGENT: a practical program repair agent mimicking human expertise. InProceedings of the 34th USENIX Conference on Security Symposium(Seattle, WA, USA)(SEC ’25). USENIX Association, USA, Article 226, 20 pages
2025
-
[42]
Shahed Zaman, Bram Adams, and Ahmed E. Hassan. 2012. A qualitative study on performance bugs(MSR ’12). IEEE Press, 199–208
2012
-
[43]
Dmitrijs Zaparanuks and Matthias Hauswirth. 2012. Algorithmic profiling.SIGPLAN Not.47, 6 (June 2012), 67–76. doi:10.1145/2345156.2254074
- [44]
-
[45]
Quanjun Zhang, Chunrong Fang, Yang Xie, Yaxin Zhang, Yun Yang, Weisong Sun, Shengcheng Yu, and Zhenyu Chen
- [46]
-
[47]
XiangRui Zhang, XueJie Du, HaoYu Chen, Yongzhong He, Wenjia Niu, and Qiang Li. 2025. Automatically Generating Rules of Malicious Software Packages via Large Language Model. In2025 55th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). 734–747. doi:10.1109/DSN64029.2025.00072
-
[48]
Yuwei Zhao, Yuan-An Xiao, Qianyu Xiao, Zhao Zhang, and Yingfei Xiong. 2025. SemOpt: LLM-Driven Code Optimiza- tion via Rule-Based Analysis.arXiv preprint arXiv:2510.16384(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Fida Zubair, Maryam Al-Hitmi, and Cagatay Catal. 2025. The use of large language models for program repair.Computer Standards & Interfaces93 (2025), 103951. doi:10.1016/j.csi.2024.103951 J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.