Mixture-of-Control: State-Aware Fine-Tuning for Transformer-based Models
Pith reviewed 2026-07-01 06:51 UTC · model grok-4.3
The pith
Mixture-of-Control routes block-wise control states as experts in a sparse mixture-of-experts process to enable efficient cross-block communication during state-based fine-tuning of transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
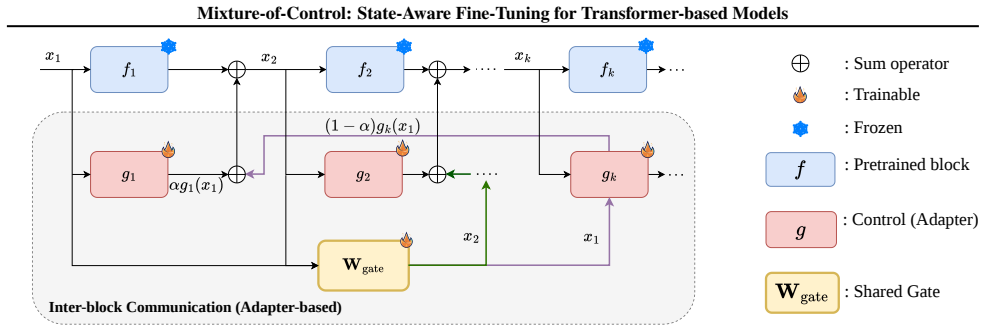
We introduce Mixture-of-Control (MoC), a lightweight fine-tuning framework that adaptively integrates local and global control signals to enhance representation learning. MoC treats block-wise control states as experts in a sparse mixture-of-experts process, enabling efficient communication across transformer blocks. Empirical results across diverse transformer-based benchmarks demonstrate that MoC outperforms state-based methods while maintaining a comparable memory and computational efficiency.
What carries the argument
Mixture-of-Control (MoC) mechanism that treats block-wise control states as experts inside a sparse mixture-of-experts routing process to integrate local and global control signals adaptively.
Load-bearing premise
Treating block-wise control states as experts in a sparse mixture-of-experts process enables efficient cross-block communication without the computational overhead of prior cross-block mechanisms.
What would settle it
Running the reported benchmarks and finding that MoC shows no accuracy gain over per-block state-based baselines or that its memory or compute cost exceeds those baselines would falsify the central claim.
Figures
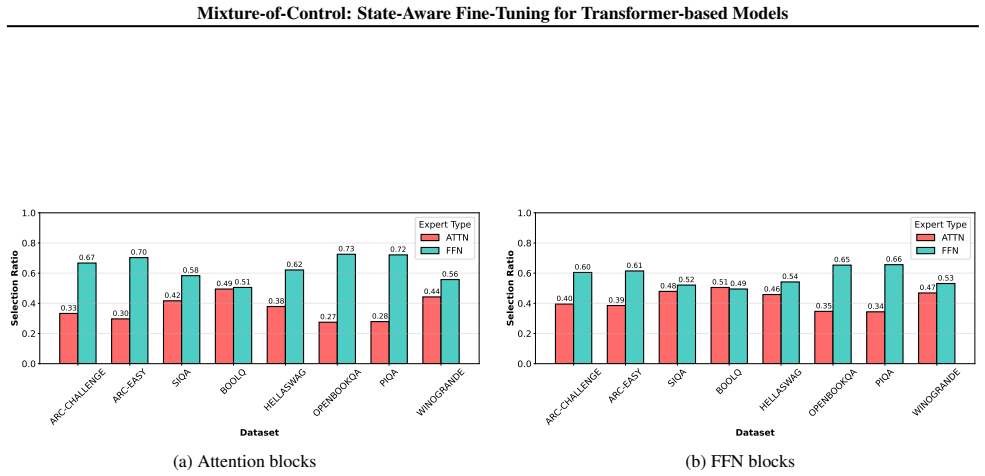
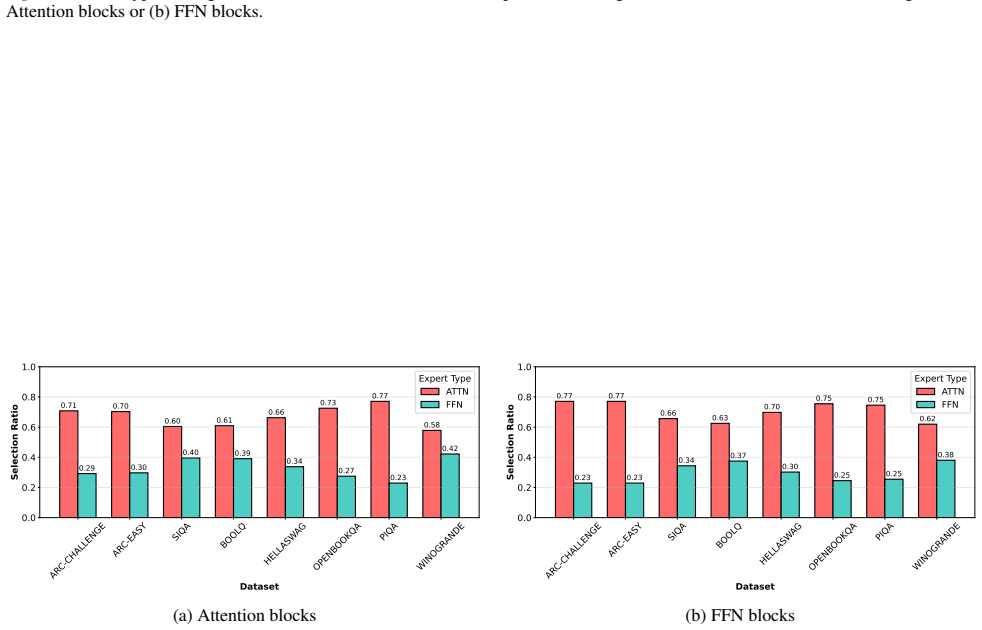
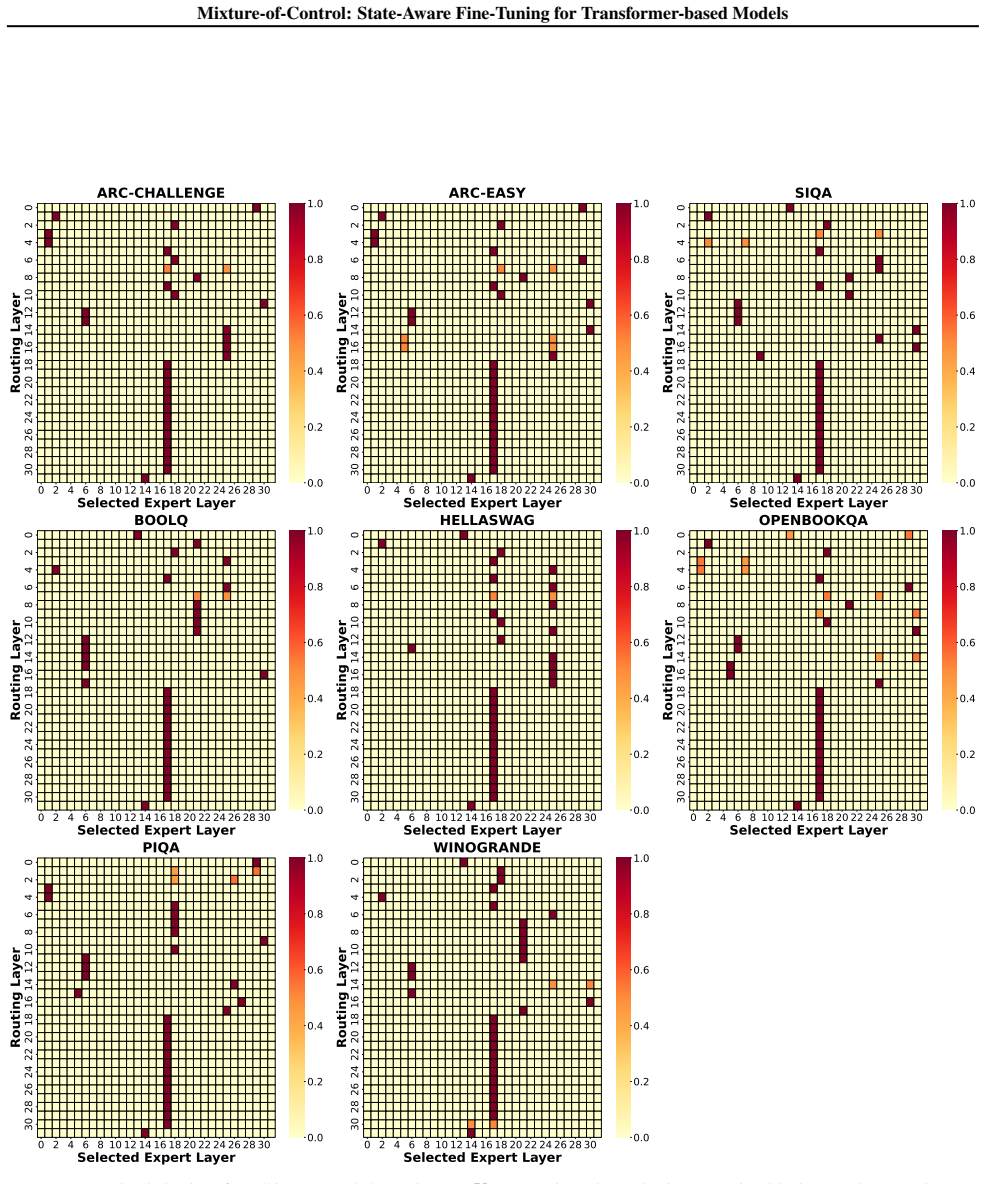
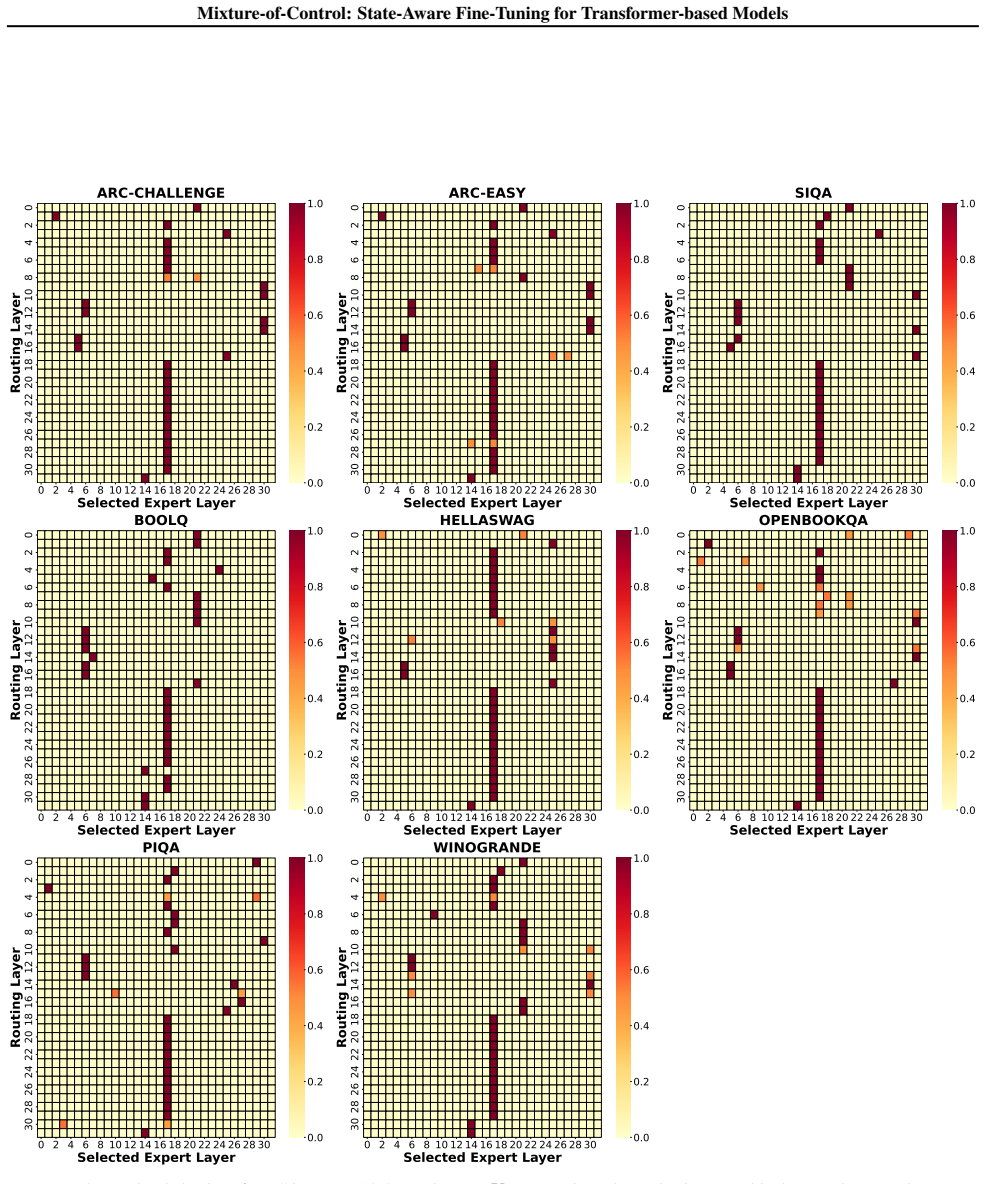
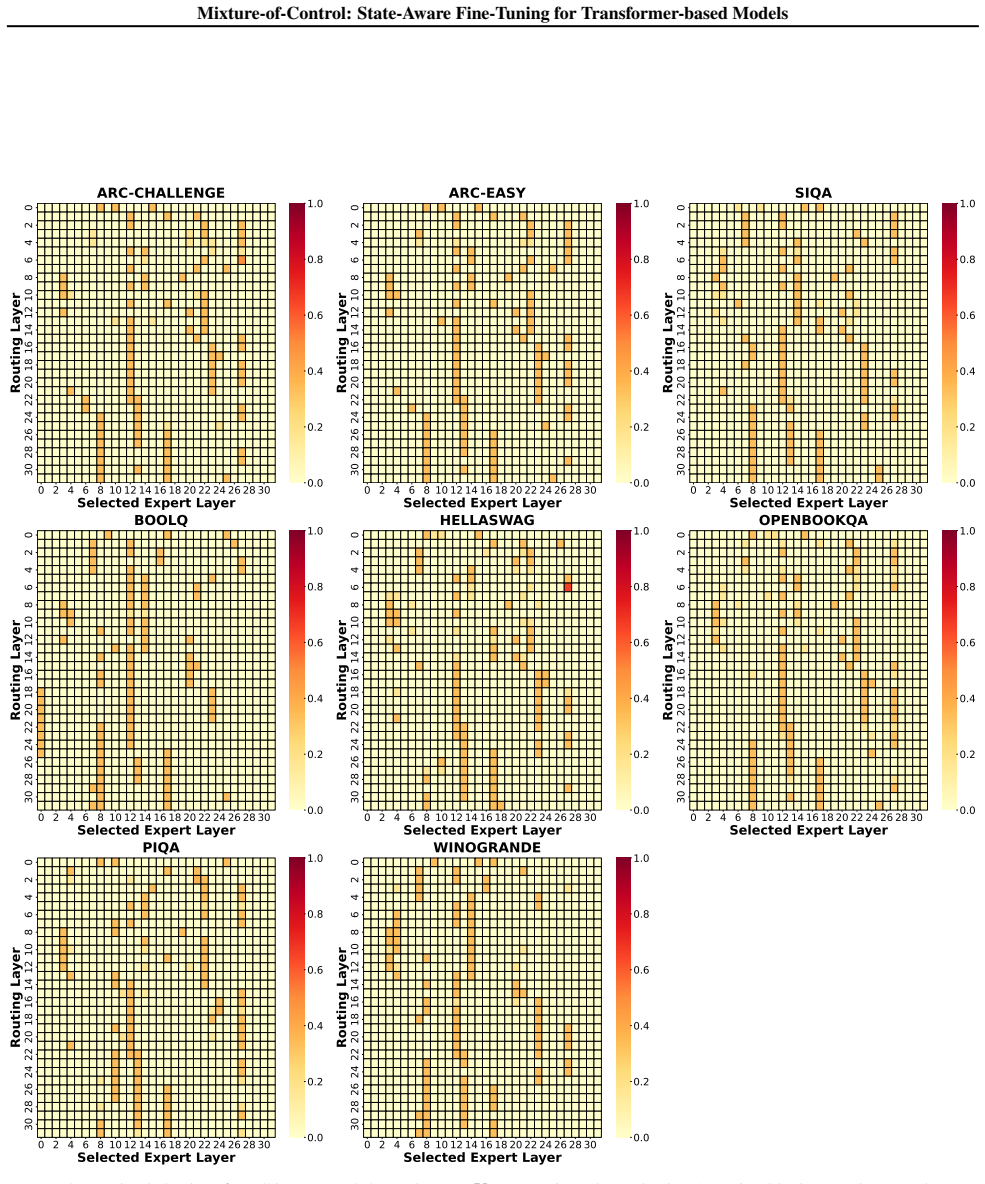
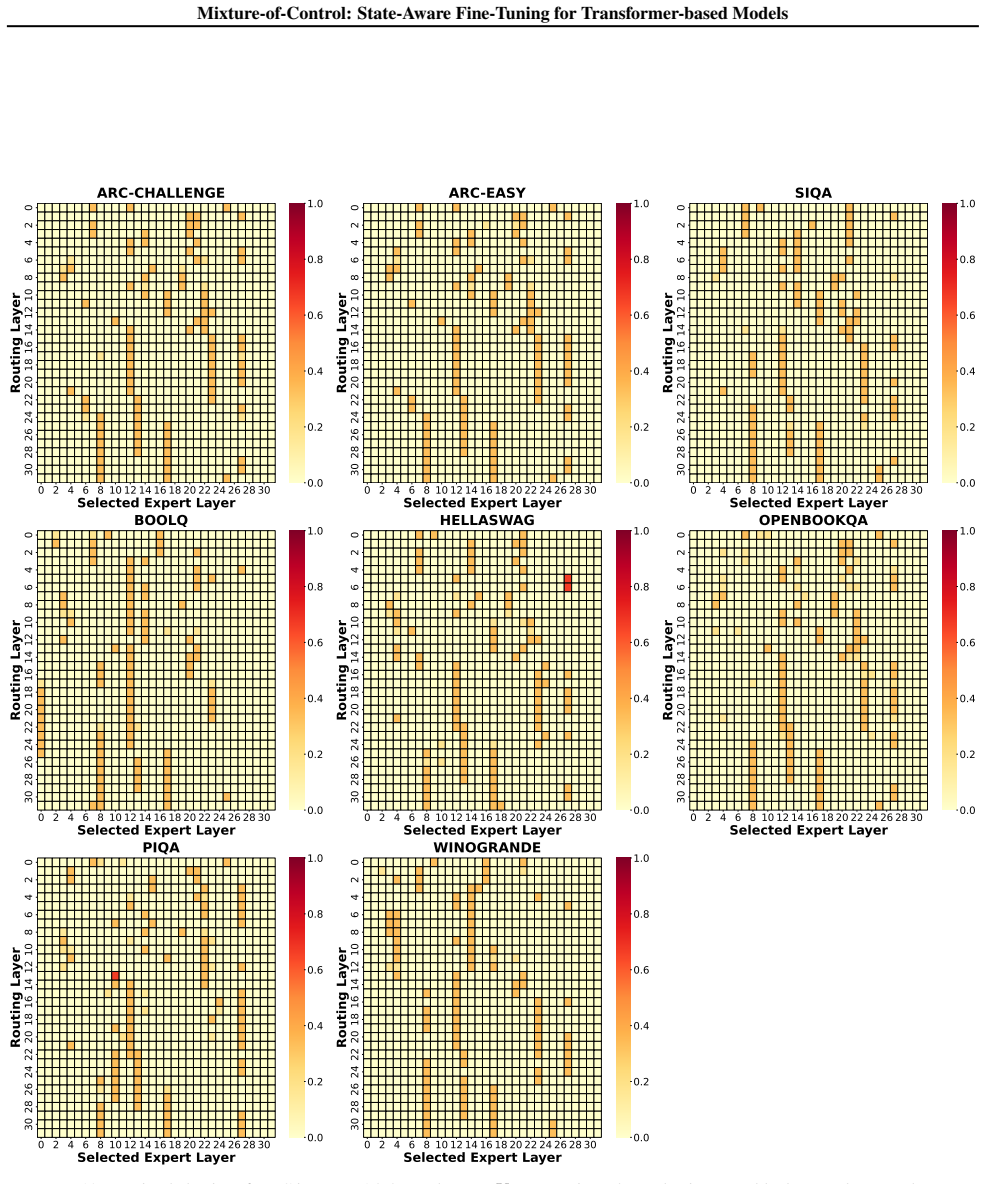
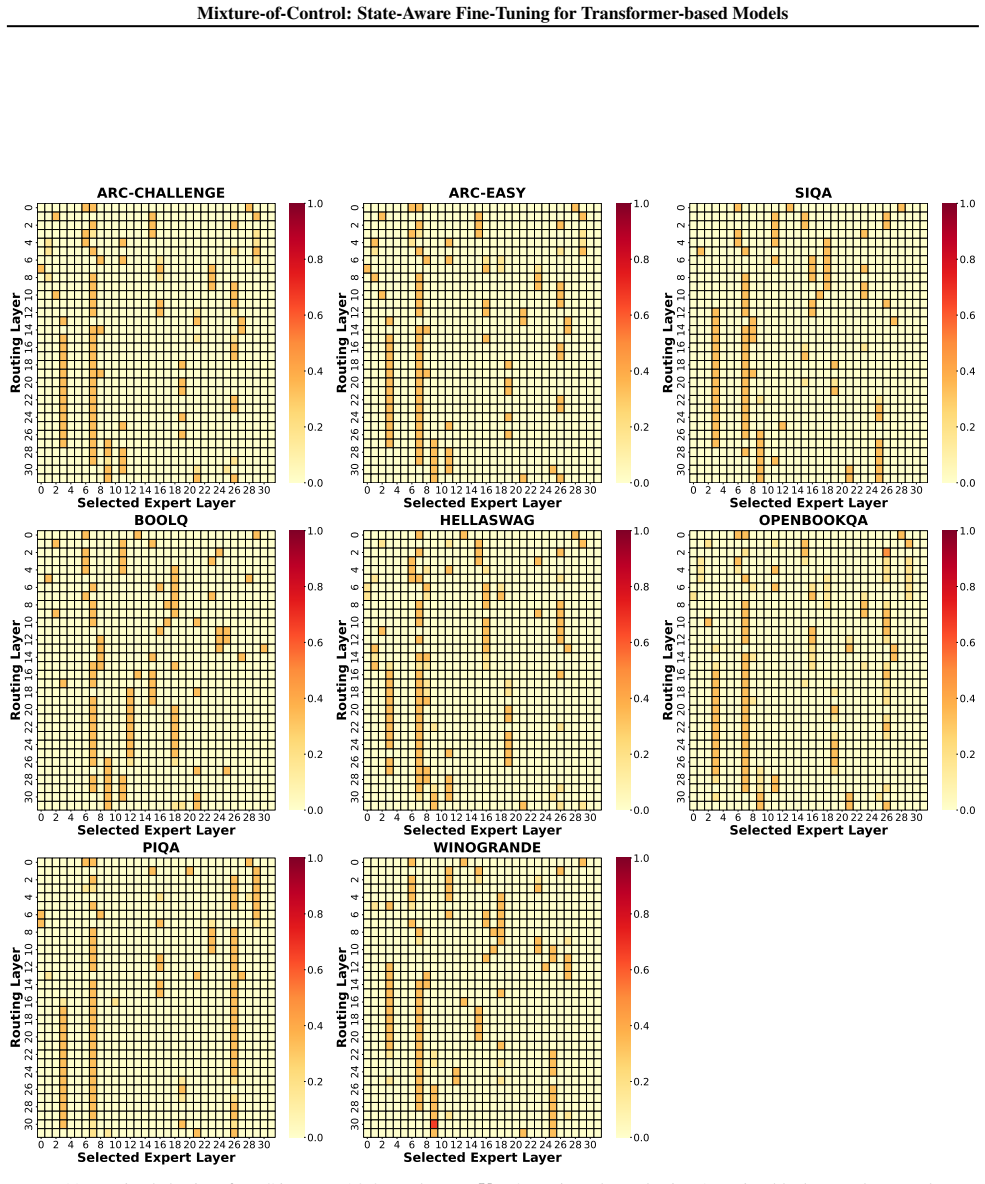
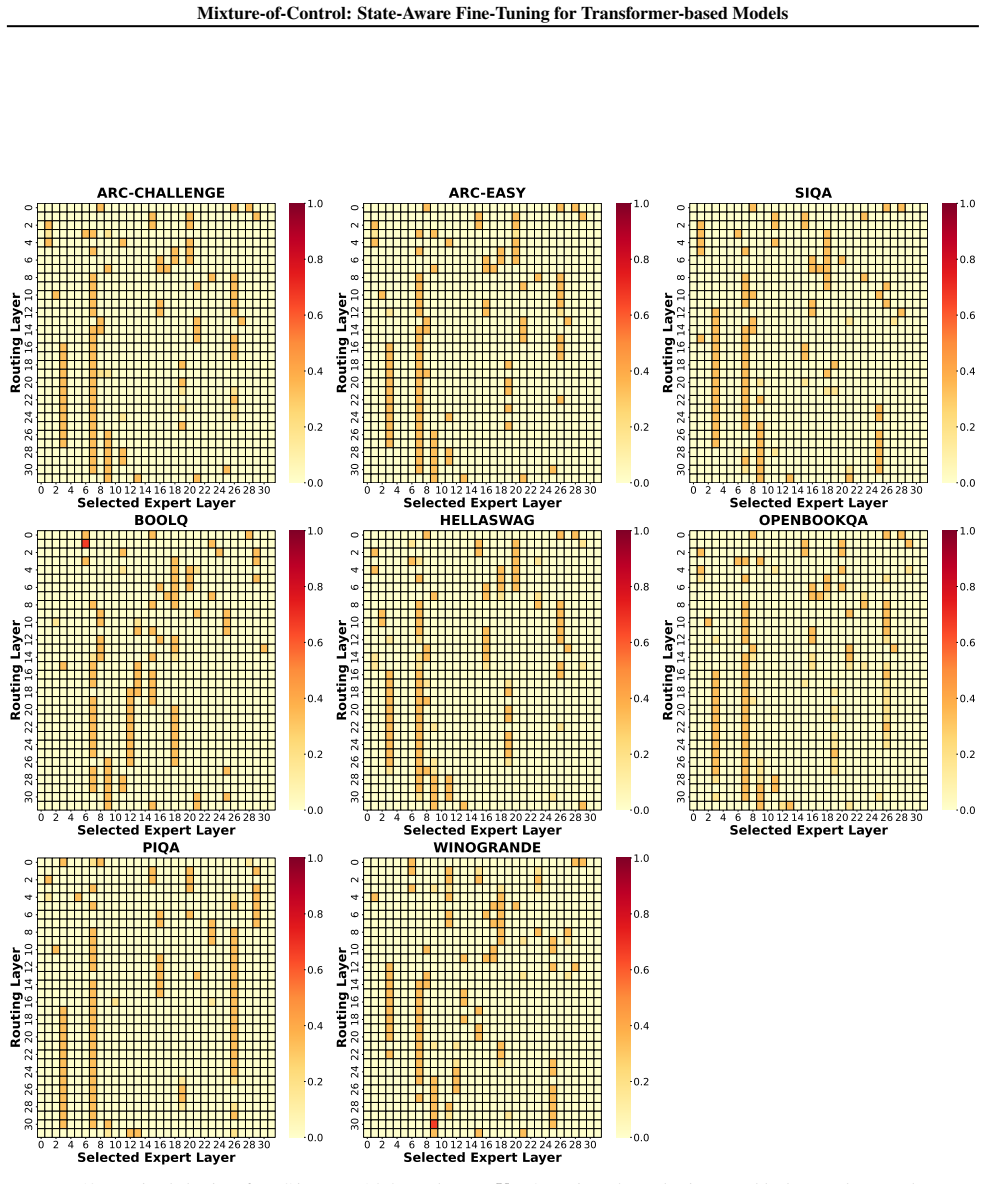
read the original abstract
State-based fine-tuning has emerged as a compelling alternative to weight-based adaptation for transformers, updating lightweight controls into states rather than model weights, offering substantial memory savings while retaining parameter efficiency. However, most existing state-based methods typically apply only per-block control updates, which limits inter-block information exchange and restricts representational adaptation. Meanwhile, prior mechanisms that enable cross-block communication often introduce considerable computational overhead, reducing their practicality for efficient fine-tuning. We introduce Mixture-of-Control (MoC), a lightweight fine-tuning framework that adaptively integrates local and global control signals to enhance representation learning. MoC treats block-wise control states as experts in a sparse mixture-of-experts process, enabling efficient communication across transformer blocks. Empirical results across diverse transformer-based benchmarks demonstrate that MoC outperforms state-based methods while maintaining a comparable memory and computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Mixture-of-Control (MoC), a lightweight state-based fine-tuning framework for transformers. It treats per-block control states as experts in a sparse mixture-of-experts routing process to adaptively combine local and global signals, thereby enabling cross-block communication. The central claim is that this yields better empirical performance than prior state-based methods on diverse benchmarks while preserving comparable memory and computational efficiency.
Significance. If the efficiency and performance claims can be substantiated with explicit analysis and reproducible results, the work would offer a practical advance in parameter-efficient fine-tuning by addressing the inter-block communication limitation of per-block state updates without the overhead of prior cross-block mechanisms. The sparse-MoE treatment of control states is a distinctive technical choice that could generalize to other state-based adaptation settings.
major comments (3)
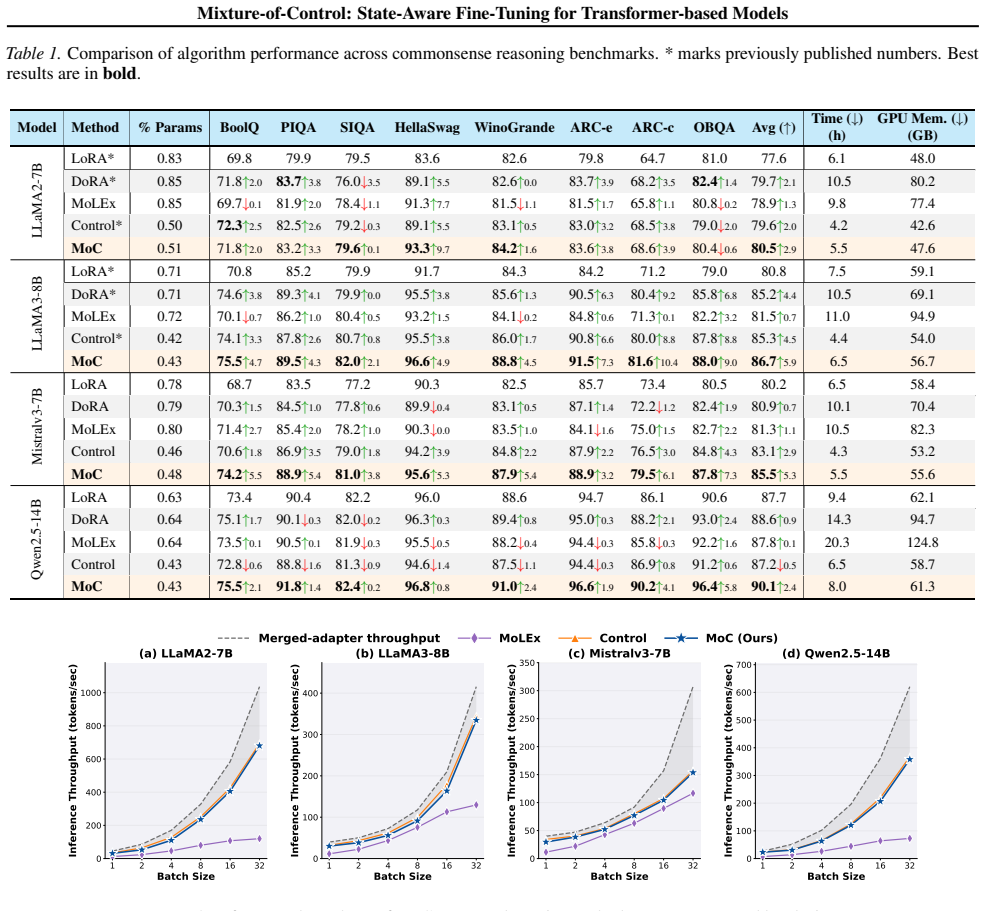
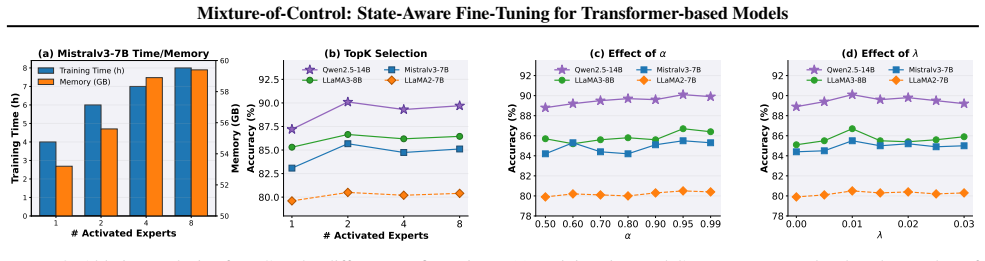
- [Abstract] Abstract: the central empirical claim that MoC 'outperforms state-based methods while maintaining a comparable memory and computational efficiency' is asserted without any reported numbers, baselines, error bars, tables, or figures, rendering the claim impossible to evaluate from the provided text.
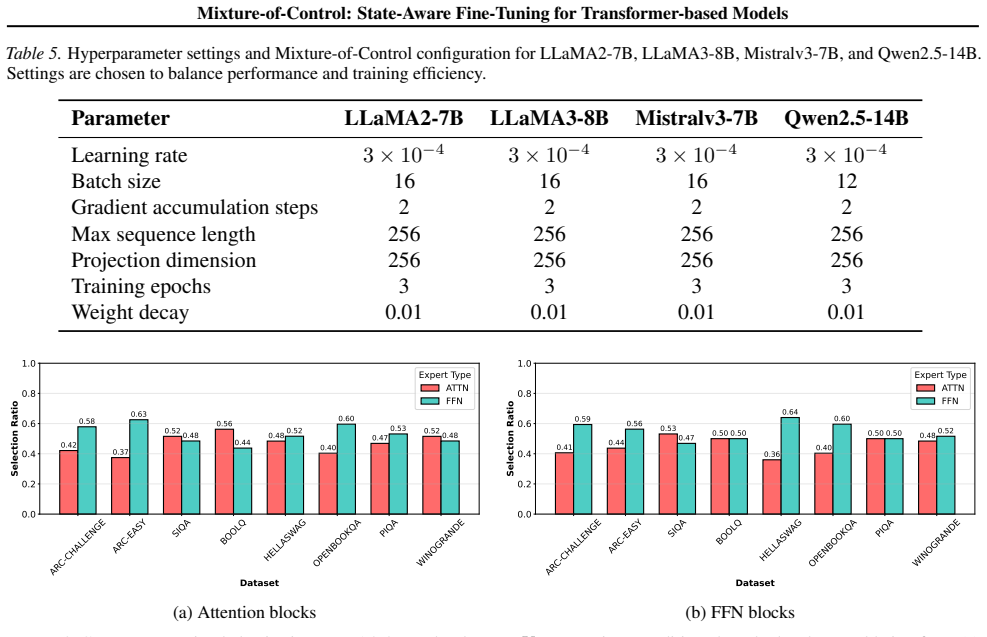
- [Abstract / Method] The description of the sparse MoE router (block-wise control states as experts) supplies no complexity bound, parameter count for the gating network, or FLOPs analysis, leaving the 'comparable efficiency' assertion (contrasted with prior cross-block mechanisms) dependent on an unverified implementation detail.
- [Abstract / Experiments] No ablation isolating the routing overhead versus a simple per-block baseline is referenced, which is load-bearing for the claim that the MoE process enables efficient cross-block communication without considerable additional cost.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the abstract and efficiency claims can be strengthened with more explicit evidence. We will revise the manuscript to address each point directly while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that MoC 'outperforms state-based methods while maintaining a comparable memory and computational efficiency' is asserted without any reported numbers, baselines, error bars, tables, or figures, rendering the claim impossible to evaluate from the provided text.
Authors: We agree that the abstract would be strengthened by including concrete results. In the revision we will add key quantitative findings (e.g., average accuracy gains and memory/FLOPs ratios versus baselines) with references to the corresponding tables and figures that already contain error bars and full baseline comparisons. revision: yes
-
Referee: [Abstract / Method] The description of the sparse MoE router (block-wise control states as experts) supplies no complexity bound, parameter count for the gating network, or FLOPs analysis, leaving the 'comparable efficiency' assertion (contrasted with prior cross-block mechanisms) dependent on an unverified implementation detail.
Authors: We will add an explicit analysis. The gating network consists of a single linear projection whose parameter count is O(d_model) and whose sparse top-k routing incurs O(B k d) additional cost for B blocks; we will include these bounds, exact parameter counts, and a FLOPs table contrasting MoC with prior cross-block methods in a new methods subsection. revision: yes
-
Referee: [Abstract / Experiments] No ablation isolating the routing overhead versus a simple per-block baseline is referenced, which is load-bearing for the claim that the MoE process enables efficient cross-block communication without considerable additional cost.
Authors: We will incorporate a new ablation table that directly compares MoC against its per-block (non-routed) counterpart on the same benchmarks, reporting the incremental memory, latency, and accuracy differences to quantify the routing overhead. revision: yes
Circularity Check
No circularity; empirical claims with no derivation chain or self-referential reductions visible
full rationale
The provided abstract and description contain no equations, fitted parameters, or derivation steps. The core contribution is presented as an empirical framework (MoC as sparse MoE over per-block states) whose performance is asserted via benchmarks rather than any mathematical reduction to prior inputs. No self-citation load-bearing, ansatz smuggling, or renaming of known results appears. The efficiency claim is an unverified assertion but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal name , volume=
Article Title , author=. Journal name , volume=. 2023 , publisher=
2023
-
[2]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[3]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[4]
M. J. Kearns , title =
-
[5]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[6]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[7]
Suppressed for Anonymity , author=
-
[8]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[9]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[10]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
International Conference on Machine Learning , pages=
Glam: Efficient scaling of language models with mixture-of-experts , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[12]
Advances in Neural Information Processing Systems , volume=
On the representation collapse of sparse mixture of experts , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
International conference on machine learning , pages=
Unified scaling laws for routed language models , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[14]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[15]
Advances in Neural Information Processing Systems , volume=
Mixture-of-experts with expert choice routing , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
2022 , eprint=
ST-MoE: Designing Stable and Transferable Sparse Expert Models , author=. 2022 , eprint=
2022
-
[17]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Xue, Fuzhao and Zheng, Zian and Fu, Yao and Ni, Jinjie and Zheng, Zangwei and Zhou, Wangchunshu and You, Yang , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2025 , publisher =
2025
-
[18]
Neural computation , volume=
Hierarchical mixtures of experts and the EM algorithm , author=. Neural computation , volume=. 1994 , publisher=
1994
-
[19]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[20]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[21]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[22]
Liu , title =
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. Journal of Machine Learning Research , year =
-
[23]
Proceedings of the 37th International Conference on Machine Learning , pages =
Generative Pretraining From Pixels , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[24]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. CoRR , volume =. 2020 , url =. 2010.11929 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[25]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[26]
CoRR , volume=
Bin Lin and Zhenyu Tang and Yang Ye and Jiaxi Cui and Bin Zhu and Peng Jin and Junwu Zhang and Munan Ning and Li Yuan , title=. CoRR , volume=. 2024 , cdate=
2024
-
[27]
and Xing, Eric and Yang, Ming-Hsuan and Khan, Fahad S
Rasheed, Hanoona and Maaz, Muhammad and Shaji, Sahal and Shaker, Abdelrahman and Khan, Salman and Cholakkal, Hisham and Anwer, Rao M. and Xing, Eric and Yang, Ming-Hsuan and Khan, Fahad S. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[28]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Multi-Head Mixture-of-Experts , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[29]
Momentum
Rachel Teo and Tan Minh Nguyen , booktitle=. Momentum. 2024 , url=
2024
-
[30]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[31]
Large text compression benchmark , author=
-
[32]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
-
[33]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
The many faces of robustness: A critical analysis of out-of-distribution generalization , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[34]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Natural adversarial examples , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[35]
Morris, John and Lifland, Eli and Yoo, Jin Yong and Grigsby, Jake and Jin, Di and Qi, Yanjun. T ext A ttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020. doi:10.18653/v1/2020.emnlp-demos.16
-
[36]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[37]
arXiv preprint arXiv:2407.06204 , year=
A survey on mixture of experts , author=. arXiv preprint arXiv:2407.06204 , year=
-
[38]
NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future , year=
Do ImageNet Classifiers Generalize to ImageNet? , author=. NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future , year=
2021
- [39]
-
[40]
Scaling vision with sparse mixture of experts , year =
Riquelme, Carlos and Puigcerver, Joan and Mustafa, Basil and Neumann, Maxim and Jenatton, Rodolphe and Pinto, Andr\'. Scaling vision with sparse mixture of experts , year =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =
-
[41]
arXiv preprint arXiv:2401.15969 , year=
Routers in vision mixture of experts: An empirical study , author=. arXiv preprint arXiv:2401.15969 , year=
-
[42]
arXiv preprint arXiv:2209.15466 , year=
Sparsity-constrained optimal transport , author=. arXiv preprint arXiv:2209.15466 , year=
-
[43]
arXiv preprint arXiv:2109.11817 , year=
Unbiased gradient estimation with balanced assignments for mixtures of experts , author=. arXiv preprint arXiv:2109.11817 , year=
-
[44]
International Conference on Machine Learning , pages=
Base layers: Simplifying training of large, sparse models , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[45]
arXiv preprint arXiv:2402.02526 , year=
CompeteSMoE--Effective Training of Sparse Mixture of Experts via Competition , author=. arXiv preprint arXiv:2402.02526 , year=
-
[46]
2024 , eprint=
Layerwise Recurrent Router for Mixture-of-Experts , author=. 2024 , eprint=
2024
-
[47]
Sinkhorn Distances: Lightspeed Computation of Optimal Transport , url =
Cuturi, Marco , booktitle =. Sinkhorn Distances: Lightspeed Computation of Optimal Transport , url =
-
[48]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Auxiliary-loss-free load balancing strategy for mixture-of-experts , author=. arXiv preprint arXiv:2408.15664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
2002 , publisher=
Feedback control of dynamic systems , author=. 2002 , publisher=
2002
-
[50]
2004 , publisher=
Optimal control theory: an introduction , author=. 2004 , publisher=
2004
-
[51]
Forty-second International Conference on Machine Learning , year=
From Weight-Based to State-Based Fine-Tuning: Further Memory Reduction on LoRA with Parallel Control , author=. Forty-second International Conference on Machine Learning , year=
-
[52]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[53]
arXiv preprint arXiv:2310.11454 , year=
Vera: Vector-based random matrix adaptation , author=. arXiv preprint arXiv:2310.11454 , year=
-
[54]
Mixture of lora experts , author=. arXiv preprint arXiv:2404.13628 , year=
-
[55]
European Conference on Computer Vision , pages=
An Optimal Control View of LoRA and Binary Controller Design for Vision Transformers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[56]
Forty-first International Conference on Machine Learning , year=
Dora: Weight-decomposed low-rank adaptation , author=. Forty-first International Conference on Machine Learning , year=
-
[57]
arXiv preprint arXiv:2503.11144 , year=
MoLEx: Mixture of Layer Experts for Finetuning with Sparse Upcycling , author=. arXiv preprint arXiv:2503.11144 , year=
-
[58]
Forty-first International Conference on Machine Learning , year=
Parameter-efficient fine-tuning with controls , author=. Forty-first International Conference on Machine Learning , year=
-
[59]
Learning and Transferring Mid-level Image Representations Using Convolutional Neural Networks , year=
Oquab, Maxime and Bottou, Leon and Laptev, Ivan and Sivic, Josef , booktitle=. Learning and Transferring Mid-level Image Representations Using Convolutional Neural Networks , year=
-
[60]
2018 , eprint=
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
2018
-
[61]
2023 , eprint=
Surgical Fine-Tuning Improves Adaptation to Distribution Shifts , author=. 2023 , eprint=
2023
-
[62]
2019 , eprint=
Parameter-Efficient Transfer Learning for NLP , author=. 2019 , eprint=
2019
-
[63]
2021 , eprint=
Compacter: Efficient Low-Rank Hypercomplex Adapter Layers , author=. 2021 , eprint=
2021
-
[64]
2021 , eprint=
The Power of Scale for Parameter-Efficient Prompt Tuning , author=. 2021 , eprint=
2021
-
[65]
P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks
Liu, Xiao and Ji, Kaixuan and Fu, Yicheng and Tam, Weng and Du, Zhengxiao and Yang, Zhilin and Tang, Jie. P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022. doi:10.18653/v1/2022.acl-short.8
-
[66]
2021 , eprint=
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author=. 2021 , eprint=
2021
-
[67]
2023 , eprint=
Progressive Prompts: Continual Learning for Language Models , author=. 2023 , eprint=
2023
-
[68]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[69]
2023 , eprint=
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning , author=. 2023 , eprint=
2023
-
[70]
2024 , eprint=
VeRA: Vector-based Random Matrix Adaptation , author=. 2024 , eprint=
2024
-
[71]
2023 , eprint=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. 2023 , eprint=
2023
-
[72]
2024 , eprint=
DoRA: Weight-Decomposed Low-Rank Adaptation , author=. 2024 , eprint=
2024
-
[73]
2023 , eprint=
FedPara: Low-Rank Hadamard Product for Communication-Efficient Federated Learning , author=. 2023 , eprint=
2023
-
[74]
2024 , eprint=
Tied-Lora: Enhancing parameter efficiency of LoRA with weight tying , author=. 2024 , eprint=
2024
-
[75]
2024 , eprint=
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author=. 2024 , eprint=
2024
-
[76]
2018 , eprint=
Maximum Principle Based Algorithms for Deep Learning , author=. 2018 , eprint=
2018
-
[77]
2024 , eprint=
Universal Approximation Power of Deep Residual Neural Networks via Nonlinear Control Theory , author=. 2024 , eprint=
2024
-
[78]
2020 , eprint=
Beyond Finite Layer Neural Networks: Bridging Deep Architectures and Numerical Differential Equations , author=. 2020 , eprint=
2020
-
[79]
2024 , eprint=
PIDformer: Transformer Meets Control Theory , author=. 2024 , eprint=
2024
-
[80]
2018 , eprint=
An Optimal Control Approach to Deep Learning and Applications to Discrete-Weight Neural Networks , author=. 2018 , eprint=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.