No Prompt, No Leaks: A Robust Generative Steganography Framework via Prompt-Free Diffusion
Pith reviewed 2026-07-01 05:25 UTC · model grok-4.3
The pith
A prompt-free diffusion model uses style semantics to generate secure stego images without text prompts or leaks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that integrating style semantic priors into a prompt-free diffusion process, supported by a bijective Cascaded Affine Coupling Module and a predictor-corrector refinement step, produces stego images that are visually imperceptible, allow accurate secret recovery, and maintain competitive security and controllability without relying on text prompts.
What carries the argument
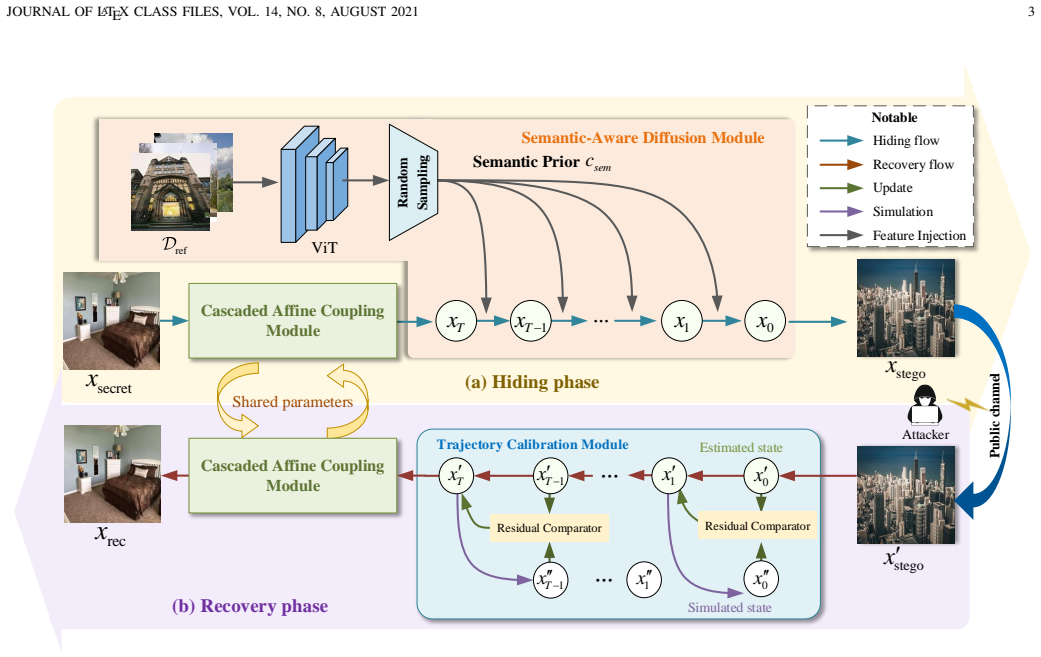
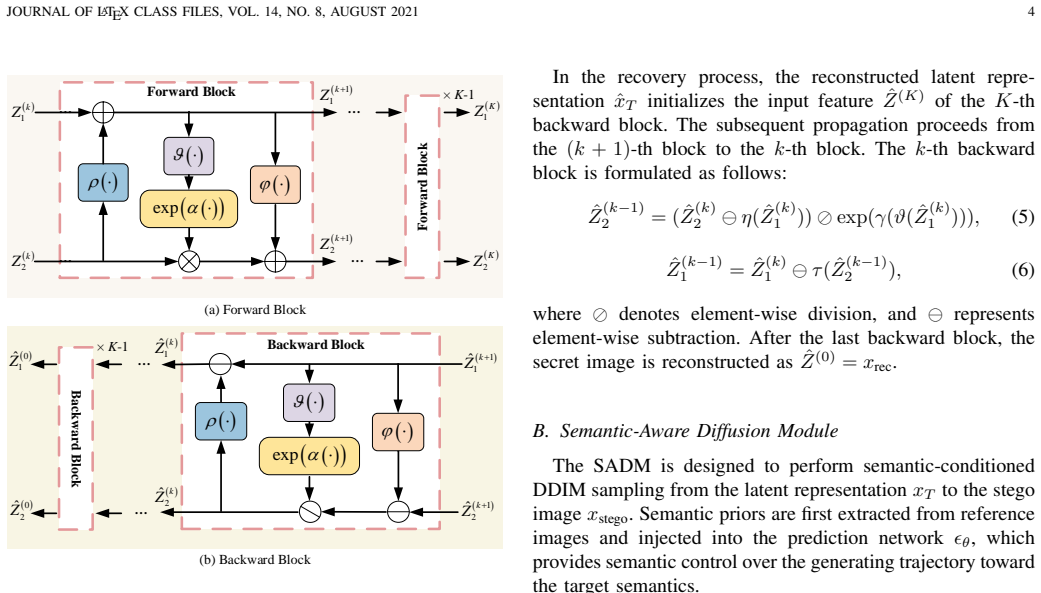
The Cascaded Affine Coupling Module (CACM) creates the bijective mapping between secret image and latent representation; style semantic priors then condition the diffusion trajectory, and the predictor-corrector uses current and predicted states to correct deviations in the unconditioned reverse process.
If this is right
- Stego images can be synthesized directly from secret data without prompt-related inflexibility or leakage risks.
- The deterministic bijective mapping supports reliable secret reconstruction after generation.
- Visual imperceptibility holds because style semantics guide the diffusion trajectory.
- The predictor-corrector mechanism reduces errors that arise in unconditioned reverse diffusion.
- Performance matches state-of-the-art methods on security, accuracy, and controllability metrics.
Where Pith is reading between the lines
- The same style-prior control could be tested on video or 3D diffusion models for hidden-data tasks.
- Avoiding prompts may reduce detectable artifacts that arise from prompt engineering in other generative pipelines.
- The framework suggests a route to embed information in any style-conditioned generative model without explicit conditioning text.
Load-bearing premise
Style semantic priors supply enough control during diffusion to guarantee both visual imperceptibility of the stego image and exact recovery of the secret, while the predictor-corrector can always fix trajectory errors.
What would settle it
An experiment in which a trained discriminator distinguishes generated stego images from natural images at rates well above random chance, or where secret-image reconstruction PSNR or accuracy falls below the reported competitive levels on the test sets.
Figures


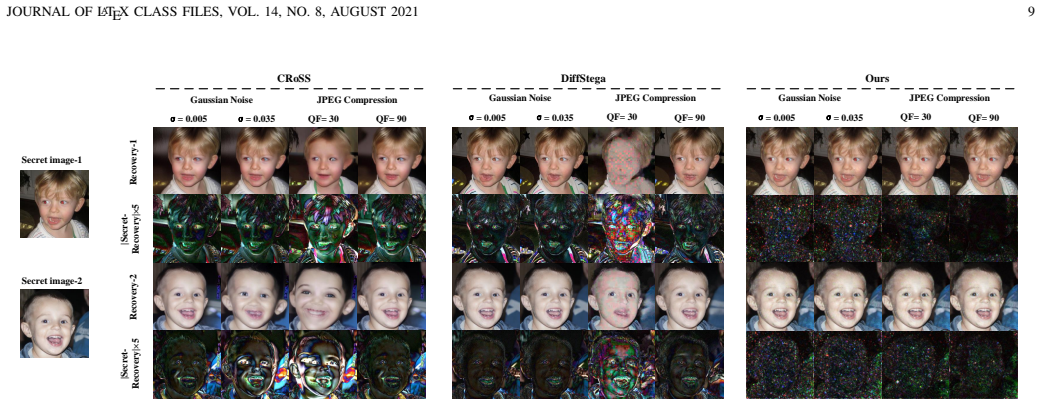
read the original abstract
Generative image steganography synthesizes stego images directly from secret information to achieve inherent security advantages. Latent Diffusion Models (LDMs) have recently emerged as a fundamental image steganography framework that modulates secret latent representations with text prompts. Limited by the inflexibility of text prompts, these methods still struggle to generate high-quality stego images and accurately recover secret images. In this work, we propose a prompt-free diffusion image steganography framework that integrates style semantic priors to control more robust and reliable stego image generation. Specifically, a Cascaded Affine Coupling Module (CACM) establishes a bijective, deterministic mapping between a secret image and its latent representation. Then, style semantics are integrated into the diffusion process to control latent representation and ensure visual imperceptibility in the generated stego images. To mitigate trajectory deviations stemming from the unconditioned reverse process, a predictor-corrector mechanism is introduced to iteratively refine the generation trajectory via feedback from the current and predicted next states. Extensive experimental results show that the proposed method achieves competitive performance compared to state-of-the-art methods in terms of security, secret image reconstruction accuracy and controllability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a prompt-free generative steganography framework using latent diffusion models. It introduces a Cascaded Affine Coupling Module (CACM) to establish a bijective deterministic mapping from secret image to latent, integrates style semantic priors into the diffusion process to control generation and ensure imperceptibility without text prompts, and adds a predictor-corrector mechanism to iteratively correct trajectory deviations during the unconditioned reverse process. The authors claim that extensive experiments demonstrate competitive performance versus state-of-the-art methods on security, secret-image reconstruction accuracy, and controllability.
Significance. If the experimental results and the correctness of the predictor-corrector convergence hold, the approach could meaningfully advance generative steganography by removing dependence on text conditioning while preserving reconstruction fidelity through style priors and feedback control.
major comments (2)
- [§3.3 (predictor-corrector) and §3.2 (CACM)] The central reconstruction claim depends on the predictor-corrector mechanism converging to the exact fixed point required by CACM's deterministic bijection when the reverse process is deliberately unconditioned. No derivation or convergence analysis is supplied showing that the feedback rule from current and predicted states nullifies residual trajectory deviations across the tested distribution.
- [Abstract and §4 (experiments)] The abstract states that 'extensive experimental results show competitive performance' on security, reconstruction accuracy, and controllability, yet the provided text supplies no quantitative metrics, baselines, ablation tables, or statistical tests. This absence makes it impossible to evaluate whether the data actually support the load-bearing performance claims.
minor comments (2)
- [§3.2] Notation for the style-semantic embedding and its injection into the diffusion U-Net should be defined explicitly with an equation.
- [§4] Figure captions should include the exact dataset splits, number of test images, and evaluation metrics used for each reported result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript to incorporate the suggested improvements where they strengthen the work.
read point-by-point responses
-
Referee: [§3.3 (predictor-corrector) and §3.2 (CACM)] The central reconstruction claim depends on the predictor-corrector mechanism converging to the exact fixed point required by CACM's deterministic bijection when the reverse process is deliberately unconditioned. No derivation or convergence analysis is supplied showing that the feedback rule from current and predicted states nullifies residual trajectory deviations across the tested distribution.
Authors: We agree that a formal convergence analysis is necessary to rigorously support the reconstruction guarantee. The current manuscript presents the predictor-corrector mechanism empirically but does not include a derivation. In the revised version we will add a convergence analysis in §3.3 showing that the feedback rule drives the trajectory to the fixed point defined by the CACM bijection for the unconditioned reverse process. revision: yes
-
Referee: [Abstract and §4 (experiments)] The abstract states that 'extensive experimental results show competitive performance' on security, reconstruction accuracy, and controllability, yet the provided text supplies no quantitative metrics, baselines, ablation tables, or statistical tests. This absence makes it impossible to evaluate whether the data actually support the load-bearing performance claims.
Authors: The manuscript's §4 does contain quantitative results, baseline comparisons, and ablation studies; however, if the version reviewed omitted the detailed tables or statistical tests, we will ensure all metrics (PSNR, SSIM, detection rates, etc.), baselines, and statistical significance tests are explicitly presented with clear tables in the revision. revision: partial
Circularity Check
No derivation chain or equations visible; no circularity detected
full rationale
The abstract and provided text state architectural components (CACM for bijective mapping, style semantic integration, predictor-corrector) at a descriptive level but contain no equations, no derivation steps, and no self-citations that could reduce claims to inputs by construction. Without any load-bearing mathematical steps or fitted predictions to inspect, the derivation chain cannot be walked and no circularity is present. The central claims rest on empirical performance assertions that would require external verification rather than internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dopsteg: Program steganography using data-oriented programming,
J. Lv, C. Fu, L. Chen, M. Liu, S. He, S. Jiang, and L. Han, “Dopsteg: Program steganography using data-oriented programming,”Science of Computer Programming, vol. 245, p. 103311, 2025
2025
-
[2]
Dualmodal and multifunctional steganography of three-dimensional integral imaging for the internet of medical things,
H. Zeng, Y . Xing, S.-T. Kim, and X. Li, “Dualmodal and multifunctional steganography of three-dimensional integral imaging for the internet of medical things,”Signal Processing, p. 110217, 2025
2025
-
[3]
Face video steganography for privacy-protection automatic depression assessment,
X. Ni, Z. Wu, L. Liu, and S. Song, “Face video steganography for privacy-protection automatic depression assessment,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 80–86
2025
-
[4]
Generative steganography network,
P. Wei, S. Li, X. Zhang, G. Luo, Z. Qian, and Q. Zhou, “Generative steganography network,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 1621–1629
2022
-
[5]
Coverless image steganography: a survey,
J. Qin, Y . Luo, X. Xiang, Y . Tan, and H. Huang, “Coverless image steganography: a survey,”IEEE Access, vol. 7, pp. 171 372–171 394, 2019
2019
-
[6]
Generative adversarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in Neural Information Processing Systems, vol. 27, 2014
2014
-
[7]
Glow: Generative flow with invertible 1x1 convolutions,
D. P. Kingma and P. Dhariwal, “Glow: Generative flow with invertible 1x1 convolutions,”Advances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[8]
An improved steganography without embedding based on attention gan,
C. Yu, D. Hu, S. Zheng, W. Jiang, M. Li, and Z.-q. Zhao, “An improved steganography without embedding based on attention gan,”Peer-to-Peer Networking and Applications, vol. 14, no. 3, pp. 1446–1457, 2021
2021
-
[9]
Generative steganographic flow,
P. Wei, G. Luo, Q. Song, X. Zhang, Z. Qian, and S. Li, “Generative steganographic flow,” inIEEE International Conference on Multimedia and Expo, 2022, pp. 1–6
2022
-
[10]
Image disentanglement autoencoder for steganography without embedding,
X. Liu, Z. Ma, J. Ma, J. Zhang, G. Schaefer, and H. Fang, “Image disentanglement autoencoder for steganography without embedding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2303–2312
2022
-
[11]
A robust coverless steganography based on generative adversarial networks and gradient descent approximation,
F. Peng, G. Chen, and M. Long, “A robust coverless steganography based on generative adversarial networks and gradient descent approximation,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 9, pp. 5817–5829, 2022
2022
-
[12]
Cross: Diffusion model makes controllable, robust and secure image steganography,
J. Yu, X. Zhang, Y . Xu, and J. Zhang, “Cross: Diffusion model makes controllable, robust and secure image steganography,”Advances in Neural Information Processing Systems, vol. 36, pp. 80 730–80 743, 2023
2023
-
[13]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2022, pp. 10 684–10 695
2022
-
[14]
Diffusion- based hierarchical image steganography,
Y . Xu, X. Zhang, X. Meng, C. Mou, and J. Zhang, “Diffusion- based hierarchical image steganography,” in2025 IEEE International Conference on Multimedia and Expo, 2025, pp. 1–6
2025
-
[15]
Robust generative steganography for image hiding using concatenated mappings,
L. Chen, B. Feng, Z. Xia, W. Lu, and J. Weng, “Robust generative steganography for image hiding using concatenated mappings,”IEEE Transactions on Information Forensics and Security, 2025
2025
-
[16]
Image-to-image steganography based on multimodal generative model,
J. Jiang, Z. Wang, and X. Zhang, “Image-to-image steganography based on multimodal generative model,”Signal Processing, vol. 238, p. 110106, 2026
2026
-
[17]
Diffstega: towards universal training-free coverless image steganogra- phy with diffusion models,
Y . Yang, Z. Liu, J. Jia, Z. Gao, Y . Li, W. Sun, X. Liu, and G. Zhai, “Diffstega: towards universal training-free coverless image steganogra- phy with diffusion models,”arXiv preprint arXiv:2407.10459, 2024
-
[18]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3836–3847
2023
-
[19]
Prompt- free diffusion: Taking
X. Xu, J. Guo, Z. Wang, G. Huang, I. Essa, and H. Shi, “Prompt- free diffusion: Taking” text” out of text-to-image diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 8682–8692
2024
-
[20]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang, “Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models,” arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Provably secure generative steganography based on adjustable orthogonal mapping,
Q. Zhang and F. Huang, “Provably secure generative steganography based on adjustable orthogonal mapping,”IEEE Transactions on De- pendable and Secure Computing, 2025
2025
-
[22]
Null- text inversion for editing real images using guided diffusion models,
R. Mokady, A. Hertz, K. Aberman, Y . Pritch, and D. Cohen-Or, “Null- text inversion for editing real images using guided diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, June 2023, pp. 6038–6047
2023
-
[23]
Edict: Exact diffusion inversion via coupled transformations,
B. Wallace, A. Gokul, and N. Naik, “Edict: Exact diffusion inversion via coupled transformations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, June 2023, pp. 22 532– 22 541
2023
-
[24]
Establishing robust generative image steganography via popular stable diffusion,
X. Hu, S. Li, Q. Ying, W. Peng, X. Zhang, and Z. Qian, “Establishing robust generative image steganography via popular stable diffusion,” IEEE Transactions on Information Forensics and Security, vol. 19, pp. 8094–8108, 2024
2024
-
[25]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[26]
Hiding images in plain sight: Deep steganography,
S. Baluja, “Hiding images in plain sight: Deep steganography,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[27]
Hiding images within images,
S. Baluja, “Hiding images within images,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 7, pp. 1685–1697, 2020
2020
-
[28]
Hidden: Hiding data with deep networks,
J. Zhu, R. Kaplan, J. Johnson, and L. Fei-Fei, “Hidden: Hiding data with deep networks,” inProceedings of the European Conference on Computer Vision, September 2018
2018
-
[29]
SteganoGAN: High Capacity Image Steganography with GANs
K. A. Zhang, A. Cuesta-Infante, L. Xu, and K. Veeramachaneni, “Steganogan: High capacity image steganography with gans,”arXiv preprint arXiv:1901.03892, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[30]
Large-capacity image steganography based on invertible neural networks,
S.-P. Lu, R. Wang, T. Zhong, and P. L. Rosin, “Large-capacity image steganography based on invertible neural networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 816–10 825. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11
2021
-
[31]
Hinet: Deep image hiding by invertible network,
J. Jing, X. Deng, M. Xu, J. Wang, and Z. Guan, “Hinet: Deep image hiding by invertible network,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4733–4742
2021
-
[32]
Deepmih: Deep invertible network for multiple image hiding,
Z. Guan, J. Jing, X. Deng, M. Xu, L. Jiang, Z. Zhang, and Y . Li, “Deepmih: Deep invertible network for multiple image hiding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 1, pp. 372–390, 2022
2022
-
[33]
iscmis: Spatial-channel attention based deep invertible network for multi-image steganography,
F. Li, Y . Sheng, X. Zhang, and C. Qin, “iscmis: Spatial-channel attention based deep invertible network for multi-image steganography,”IEEE Transactions on Multimedia, vol. 26, pp. 3137–3152, 2023
2023
-
[34]
Mutual information guided invertible image hiding network,
K. Zhang, F. Xiao, J. Cai, and X. Gao, “Mutual information guided invertible image hiding network,”Engineering Applications of Artificial Intelligence, vol. 162, p. 112343, 2025
2025
-
[35]
Structural design of convolutional neural networks for steganalysis,
G. Xu, H.-Z. Wu, and Y .-Q. Shi, “Structural design of convolutional neural networks for steganalysis,”IEEE Signal Processing Letters, vol. 23, no. 5, pp. 708–712, 2016
2016
-
[36]
A siamese cnn for image steganalysis,
W. You, H. Zhang, and X. Zhao, “A siamese cnn for image steganalysis,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 291–306, 2020
2020
-
[37]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[38]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in Neural Information Processing Systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[39]
Simple diffusion: End-to- end diffusion for high resolution images,
E. Hoogeboom, J. Heek, and T. Salimans, “Simple diffusion: End-to- end diffusion for high resolution images,” inInternational Conference on Machine Learning, 2023, pp. 13 213–13 232
2023
-
[40]
Diffir: Efficient diffusion model for image restoration,
B. Xia, Y . Zhang, S. Wang, Y . Wang, X. Wu, Y . Tian, W. Yang, and L. Van Gool, “Diffir: Efficient diffusion model for image restoration,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 13 095–13 105
2023
-
[41]
Generative diffusion prior for unified image restoration and enhancement,
B. Fei, Z. Lyu, L. Pan, J. Zhang, W. Yang, T. Luo, B. Zhang, and B. Dai, “Generative diffusion prior for unified image restoration and enhancement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9935–9946
2023
-
[42]
Improved generative steganography based on diffusion model,
Q. Zhou, P. Wei, Z. Qian, X. Zhang, and S. Li, “Improved generative steganography based on diffusion model,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 7, pp. 6494–6507, 2025
2025
-
[43]
Generative image steganog- raphy based on text-to-image multimodal generative model,
J. Jiang, Z. Wang, Z. Yuan, and X. Zhang, “Generative image steganog- raphy based on text-to-image multimodal generative model,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 9, pp. 8907–8916, 2025
2025
-
[44]
Coverless image steganog- raphy based on semantic-controlled text-to-image generation,
X. Li, L. Chen, T. Fu, Z. Fu, and Y . Gao, “Coverless image steganog- raphy based on semantic-controlled text-to-image generation,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 8, pp. 8391–8405, 2025
2025
-
[45]
Robust generative steganography based on image mapping,
Q. Zhang and F. Huang, “Robust generative steganography based on image mapping,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 12, pp. 13 543–13 555, 2024
2024
-
[46]
Provably secure robust image steganography,
Z. Yang, K. Chen, K. Zeng, W. Zhang, and N. Yu, “Provably secure robust image steganography,”IEEE Transactions on Multimedia, vol. 26, pp. 5040–5053, 2023
2023
-
[47]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps,
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu, “Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps,”Advances in Neural Information Processing Systems, vol. 35, pp. 5775–5787, 2022
2022
-
[48]
A style-based generator architecture for generative adversarial networks,
T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, June 2019
2019
-
[49]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
F. Yu, A. Seff, Y . Zhang, S. Song, T. Funkhouser, and J. Xiao, “Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop,”arXiv preprint arXiv:1506.03365, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[50]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[51]
A feature-enriched completely blind image quality evaluator,
L. Zhang, L. Zhang, and A. C. Bovik, “A feature-enriched completely blind image quality evaluator,”IEEE Transactions on Image Processing, vol. 24, no. 8, pp. 2579–2591, 2015
2015
-
[52]
StegExpose - A Tool for Detecting LSB Steganography
B. Boehm, “Stegexpose-a tool for detecting lsb steganography,”arXiv preprint arXiv:1410.6656, 2014. Jingwen Caireceived the M.E. degree in com- puter technology in 2022 from the Guilin Uni- versity of Electronic Technology, Guilin, China, where she is currently working toward the Ph.D. degree in computer technology with the School of Computer Science, Xia...
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.