Think While You Map: Asynchronous Vision-Language Agents for Incremental 3D Scene Graphs
Pith reviewed 2026-07-01 06:13 UTC · model grok-4.3
The pith
Asynchronous vision-language agents enrich 3D scene graphs incrementally while mapping proceeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
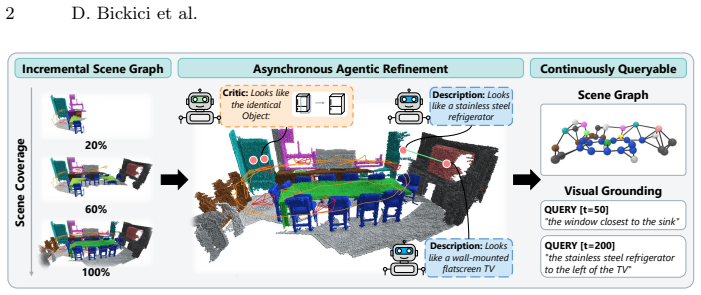
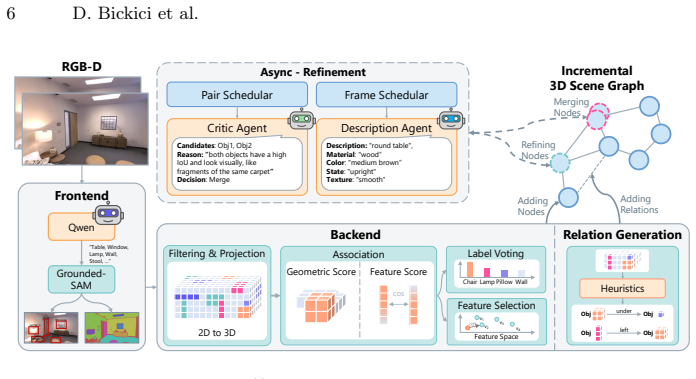
An asynchronous framework separates lightweight online mapping from heavyweight semantic refinement by vision-language models, allowing the scene graph to be queryable during exploration while progressively gaining semantic richness through semantic loop closure and attribute attachment.
What carries the argument
probabilistic voxel-based backbone that maintains stable object identities incrementally, combined with background VLM agents and a multi-target frame scheduler
If this is right
- The resulting scene graph is queryable during exploration.
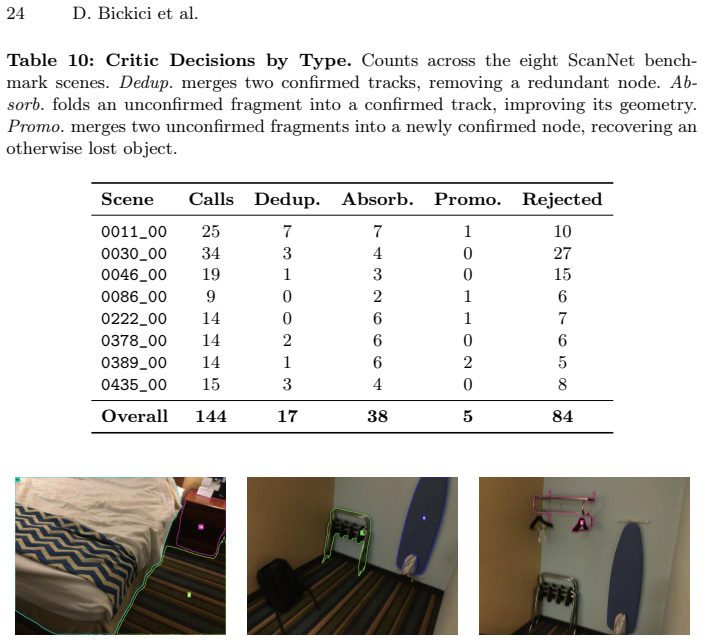
- It resolves duplicate object tracks through semantic loop closure.
- Fine-grained visual attributes and spatial relations are derived between objects.
- It matches or outperforms existing methods on semantic segmentation on ScanNet and Replica.
- It surpasses prior state-of-the-art on visual grounding benchmarks by 15.3 to 18.8 A@0.25.
Where Pith is reading between the lines
- This approach could support robots that need to understand and query their environment in real time without waiting for post-processing.
- Amortizing VLM costs over informative frames might generalize to other expensive perception tasks.
- Semantic loop closure could be tested in longer, more complex environments to check for drift accumulation.
Load-bearing premise
The probabilistic voxel-based backbone maintains stable object identities incrementally without drift that would require later correction by the VLM agents.
What would settle it
Observing significant object identity drift in extended mapping sequences on datasets like ScanNet without corresponding VLM corrections would falsify the stability claim.
Figures




read the original abstract
Open-vocabulary 3D scene graph methods typically operate in two stages: first reconstruct, then enrich with vision-language models, leaving the graph unqueryable during exploration. We argue that this sequential coupling is unnecessary and propose an asynchronous architecture in which lightweight online mapping runs concurrently with heavyweight semantic refinement. A probabilistic voxel-based backbone maintains stable object identities incrementally, while background VLM agents progressively enrich the graph. This framework resolves duplicate object tracks through semantic loop closure, attaches fine-grained visual attributes and derives spatial relations between objects. A multi-target frame scheduler amortizes VLM cost by selecting a small set of informative frames that jointly cover multiple targets. The resulting scene graph is queryable during exploration and grows in semantic richness over time. Our method matches or outperforms existing open-vocabulary 3D scene graph methods on semantic segmentation (ScanNet, Replica) and surpasses the prior state-of-the-art across three visual grounding benchmarks (Sr3D+, Nr3D, ScanRefer) by 15.3 to 18.8 A@0.25. Project page: https://denizbickici.github.io/thinkgraphs/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an asynchronous architecture for open-vocabulary 3D scene graph construction in which a lightweight probabilistic voxel-based backbone performs incremental online mapping to maintain object identities, while background VLM agents enrich the graph with semantics, attributes, and relations. Semantic loop closure resolves duplicates, and a multi-target frame scheduler selects informative frames to amortize VLM cost. The resulting graph is claimed to be queryable during exploration. Experiments report that the method matches or exceeds prior open-vocabulary scene graph methods on semantic segmentation (ScanNet, Replica) and surpasses prior SOTA on three visual grounding benchmarks (Sr3D+, Nr3D, ScanRefer) by 15.3–18.8 A@0.25.
Significance. If the asynchronous decoupling and identity stability hold, the work offers a practical route to queryable scene graphs during exploration rather than post-hoc reconstruction, which could benefit robotics and AR systems that require online semantic queries. The reported benchmark gains on standard datasets provide initial evidence of utility, though the absence of ablations and identity-stability metrics limits assessment of whether gains derive from the architecture or implementation choices.
major comments (3)
- [Method (backbone description) and Experiments] The central claim that the probabilistic voxel backbone 'maintains stable object identities incrementally' (abstract and method overview) lacks any reported quantitative metric of identity persistence, such as ID-switch rate, voxel-to-object assignment consistency across frames, or drift statistics over full trajectories. Without this, it is unclear whether the reported grounding gains require the online asynchronous property or could be achieved with offline post-hoc cleanup.
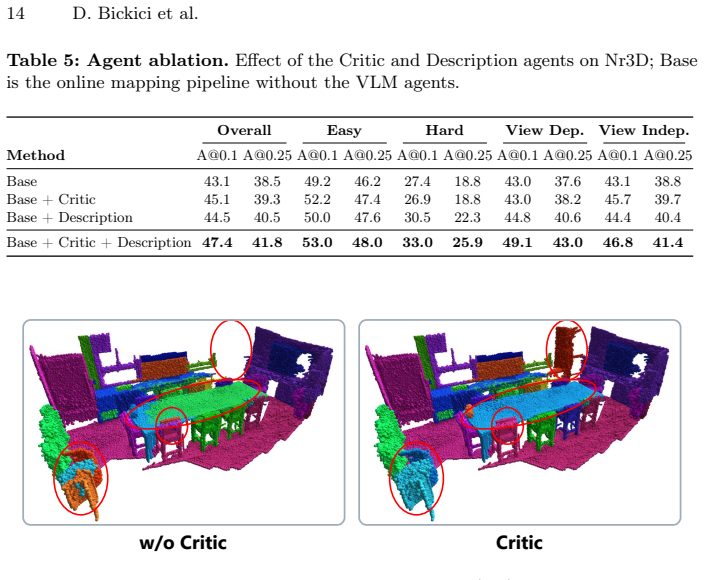
- [Experiments] No ablation studies isolate the contribution of semantic loop closure versus the VLM agents or the frame scheduler (Experiments section). This makes it difficult to determine whether the 15.3–18.8 A@0.25 gains on grounding benchmarks are attributable to the asynchronous design or to other factors such as VLM choice or post-processing.
- [Experiments and Discussion] The manuscript provides no error analysis or failure-case breakdown on the grounding benchmarks (e.g., cases where identity drift would force retroactive corrections). This is load-bearing for the claim that the graph remains reliably queryable during exploration.
minor comments (2)
- [Method] Notation for the probabilistic voxel representation and the multi-target scheduler could be clarified with a single diagram or pseudocode listing the key variables.
- [Abstract and Introduction] The abstract and introduction would benefit from an explicit statement of the computational budget (e.g., VLM calls per second or frame selection rate) to contextualize the amortization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important gaps in quantitative validation of the backbone's identity stability, component contributions, and error analysis. We will revise the manuscript to address these points directly while preserving the core asynchronous architecture and reported results.
read point-by-point responses
-
Referee: [Method (backbone description) and Experiments] The central claim that the probabilistic voxel backbone 'maintains stable object identities incrementally' (abstract and method overview) lacks any reported quantitative metric of identity persistence, such as ID-switch rate, voxel-to-object assignment consistency across frames, or drift statistics over full trajectories. Without this, it is unclear whether the reported grounding gains require the online asynchronous property or could be achieved with offline post-hoc cleanup.
Authors: We agree that explicit identity-persistence metrics would strengthen the presentation. The probabilistic voxel backbone maintains object identities through per-voxel Bayesian occupancy and label updates that favor temporal consistency, with semantic loop closure explicitly resolving duplicate tracks. The grounding benchmark gains (which penalize identity errors) provide indirect support for stability under the online regime. In revision we will add ID-switch rate, voxel-to-object assignment consistency, and trajectory drift statistics computed on the ScanNet and Replica sequences to quantify this property and clarify the contribution of the asynchronous design. revision: yes
-
Referee: [Experiments] No ablation studies isolate the contribution of semantic loop closure versus the VLM agents or the frame scheduler (Experiments section). This makes it difficult to determine whether the 15.3–18.8 A@0.25 gains on grounding benchmarks are attributable to the asynchronous design or to other factors such as VLM choice or post-processing.
Authors: We will add the requested ablations in the revised Experiments section. These will include controlled variants that disable semantic loop closure, the background VLM agents, and the multi-target frame scheduler individually while keeping all other components fixed, allowing direct measurement of each module's contribution to the reported grounding improvements. revision: yes
-
Referee: [Experiments and Discussion] The manuscript provides no error analysis or failure-case breakdown on the grounding benchmarks (e.g., cases where identity drift would force retroactive corrections). This is load-bearing for the claim that the graph remains reliably queryable during exploration.
Authors: We will include a new error-analysis subsection in the revised manuscript. It will present a breakdown of failure cases on Sr3D+, Nr3D, and ScanRefer, with particular attention to instances of potential identity drift and how semantic loop closure and the asynchronous update schedule mitigate retroactive corrections, thereby supporting the claim of reliable online queryability. revision: yes
Circularity Check
No circularity; empirical systems paper with independent benchmark claims
full rationale
The paper describes an asynchronous architecture using a probabilistic voxel backbone for incremental mapping and background VLM agents for semantic enrichment, with results on semantic segmentation (ScanNet, Replica) and visual grounding (Sr3D+, Nr3D, ScanRefer). No equations, fitted parameters, self-definitional relations, or load-bearing self-citations appear in the provided text that would reduce any claimed performance or property to a construction from its own inputs. The contribution is presented as an empirical systems integration whose validity rests on external benchmark comparisons rather than internal redefinition or renaming of known results. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Computer Vision – ECCV 2020, vol
Achlioptas, P., Abdelreheem, A., Xia, F., Elhoseiny, M., Guibas, L.: ReferIt3D: Neural Listeners for Fine-Grained 3D Object Identification in Real-World Scenes. In: Computer Vision – ECCV 2020, vol. 12346, pp. 422–440. Springer International Publishing, Cham (2020).https://doi.org/10.1007/978-3-030-58452-8_25
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[3]
IEEE Robotics and Automation Letters8(8), 4927–4934 (2023).https://doi.org/10
Bavle,H.,Sanchez-Lopez,J.L.,Shaheer,M.,Civera,J.,Voos,H.:S-Graphs+:Real- Time Localization and Mapping Leveraging Hierarchical Representations. IEEE Robotics and Automation Letters8(8), 4927–4934 (2023).https://doi.org/10. 1109/LRA.2023.3290512 16 D. Bickici et al
-
[4]
Chen, B., Xia, F., Ichter, B., Rao, K., Gopalakrishnan, K., Ryoo, M., Stone, A., Kappler, D.: Open-vocabulary Queryable Scene Representations for Real World Planning. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 11509–11522. IEEE, London, United Kingdom (2023).https://doi. org/10.1109/ICRA48891.2023.10161534
-
[5]
In: Computer Vision – ECCV 2020, vol
Chen, D.Z., Chang, A.X., Nießner, M.: ScanRefer: 3D Object Localization in RGB- D Scans Using Natural Language. In: Computer Vision – ECCV 2020, vol. 12365, pp. 202–221. Springer International Publishing, Cham (2020).https://doi.org/ 10.1007/978-3-030-58565-5_13
-
[6]
In: 2017 IEEE Con- ference on Computer Vision and Pattern Recognition (CVPR)
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scan- Net: Richly-Annotated 3D Reconstructions of Indoor Scenes. In: 2017 IEEE Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 2432–2443. IEEE, Honolulu, HI (2017).https://doi.org/10.1109/CVPR.2017.261
-
[7]
In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Deng, Y., Yao, B., Tang, Y., Zhou, T., Yang, Y., Yue, Y.: Openvox: Real- time instance-level open-vocabulary probabilistic voxel representation. In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 1305–1311 (2025).https://doi.org/10.1109/IROS60139.2025.11246455
-
[8]
In: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD)
Ester, M., Kriegel, H.P., Sander, J., Xu, X.: A density-based algorithm for discov- ering clusters in large spatial databases with noise. In: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD). pp. 226–231. AAAI Press, Portland, Oregon (1996)
1996
-
[9]
Image Vision Comput.149(C) (2024).https: //doi.org/10.1016/j.imavis.2024.105171
Fang, Y., Sun, Q., Wang, X., Huang, T., Wang, X., Cao, Y.: Eva-02: A visual representation for neon genesis. Image Vision Comput.149(C) (2024).https: //doi.org/10.1016/j.imavis.2024.105171
-
[10]
Feng, M., Yan, C., Wu, Z., Dong, W., Wang, Y., Mian, A.: History-enhanced 3d scene graph reasoning from rgb-d sequences. IEEE Transactions on Circuits and Systems for Video Technology35(8), 7667–7682 (2025).https://doi.org/10. 1109/TCSVT.2025.3548308
-
[11]
Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K.M., Sen, B., Agarwal, A., Rivera, C., Paul, W., Ellis, K., Chellappa, R., Gan, C., De Melo, C.M., Tenenbaum, J.B., Torralba, A., Shkurti, F., Paull, L.: ConceptGraphs: Open-Vocabulary 3D SceneGraphsforPerceptionandPlanning.In:2024IEEEInternationalConference on Robotics and Automation (ICRA). pp. 5021–5...
-
[12]
Huang, C., Mees, O., Zeng, A., Burgard, W.: Visual Language Maps for Robot Navigation. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 10608–10615 (2023).https://doi.org/10.1109/ICRA48891.2023. 10160969
-
[13]
In: Pro- ceedings of the 33rd ACM International Conference on Multimedia (ACM MM)
Huang, X., Huang, Y.J., Zhang, Y., Tian, W., Feng, R., Zhang, Y., Xie, Y., Li, Y., Zhang, L.: Open-set image tagging with multi-grained text supervision. In: Pro- ceedings of the 33rd ACM International Conference on Multimedia (ACM MM). p. 4117–4126. Association for Computing Machinery, New York, NY, USA (2025). https://doi.org/10.1145/3746027.3755316
-
[14]
In: Robotics: Science and Systems XVIII
Hughes, N., Chang, Y., Carlone, L.: Hydra: A Real-time Spatial Perception System for 3D Scene Graph Construction and Optimization. In: Robotics: Science and Systems XVIII. Robotics: Science and Systems Foundation (2022).https://doi. org/10.15607/RSS.2022.XVIII.050
-
[15]
In: Robotics: Science and Systems XIX
Jatavallabhula, K., Kuwajerwala, A., Gu, Q., Omama, M., Iyer, G., Saryazdi, S., Chen, T., Maalouf, A., Li, S., Keetha, N., Tewari, A., Tenenbaum, J., Melo, C., Krishna, M., Paull, L., Shkurti, F., Torralba, A.: ConceptFusion: Open-set multi- Think While You Map 17 modal 3D mapping. In: Robotics: Science and Systems XIX. Robotics: Science and Systems Found...
-
[16]
Kerr, J., Kim, C.M., Goldberg, K., Kanazawa, A., Tancik, M.: LERF: Lan- guage Embedded Radiance Fields. In: 2023 IEEE/CVF International Confer- ence on Computer Vision (ICCV). pp. 19672–19682. IEEE, Paris, France (2023). https://doi.org/10.1109/ICCV51070.2023.01807
-
[17]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Koch, S., Vaskevicius, N., Colosi, M., Hermosilla, P., Ropinski, T.: Open3dsg: Open-vocabulary 3d scene graphs from point clouds with queryable objects and open-set relationships. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14183–14193 (2024).https://doi.org/10. 1109/CVPR52733.2024.01345
-
[18]
IEEE Robotics and Automation Letters6(4), 7041–7048 (2021).https://doi.org/10.1109/LRA.2021.3097242
Lin,S.,Wang,J.,Xu,M.,Zhao,H.,Chen,Z.:TopologyAwareObject-LevelSeman- tic Mapping Towards More Robust Loop Closure. IEEE Robotics and Automation Letters6(4), 7041–7048 (2021).https://doi.org/10.1109/LRA.2021.3097242
-
[19]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Linok, S., Zemskova, T., Ladanova, S., Titkov, R., Yudin, D., Monastyrny, M., Valenkov, A.: Beyond Bare Queries: Open-Vocabulary Object Grounding with 3D Scene Graph. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 13582–13589 (2025).https://doi.org/10.1109/ICRA55743.2025. 11128059
-
[20]
In: 2025 IEEE International Conference on Robotics and Automa- tion (ICRA)
Liu, P., Guo, Z., Warke, M., Chintala, S., Paxton, C., Shafiullah, N.M.M., Pinto, L.: Dynamem: Online Dynamic Spatio-Semantic Memory for Open World Mobile Manipulation. In: 2025 IEEE International Conference on Robotics and Automa- tion (ICRA). pp. 13346–13355 (2025).https://doi.org/10.1109/ICRA55743. 2025.11127619
-
[21]
In: Computer Vision – ECCV 2024, vol
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., Zhu, J., Zhang, L.: Grounding DINO: Marrying DINO with Grounded Pre-training for Open-Set Object Detection. In: Computer Vision – ECCV 2024, vol. 15105, pp. 38–55. Springer Nature Switzerland, Cham (2025).https://doi. org/10.1007/978-3-031-72970-6_3
-
[22]
In: 2019 International Conference on Robotics and Au- tomation (ICRA)
Liu, Y., Petillot, Y., Lane, D., Wang, S.: Global Localization with Object-Level Semantics and Topology. In: 2019 International Conference on Robotics and Au- tomation (ICRA). pp. 4909–4915. IEEE, Montreal, QC, Canada (2019).https: //doi.org/10.1109/ICRA.2019.8794475
-
[23]
In: International Conference on Learning Representations (ICLR) (2023)
Ma, X., Yong, S., Zheng, Z., Li, Q., Liang, Y., Zhu, S.C., Huang, S.: Sqa3d: Sit- uated question answering in 3d scenes. In: International Conference on Learning Representations (ICLR) (2023)
2023
-
[24]
IEEE Robotics and Automation Letters9(10), 8921–8928 (2024)
Maggio, D., Chang, Y., Hughes, N., Trang, M., Griffith, D., Dougherty, C., Cristo- falo, E., Schmid, L., Carlone, L.: Clio: Real-Time Task-Driven Open-Set 3D Scene Graphs. IEEE Robotics and Automation Letters9(10), 8921–8928 (2024). https://doi.org/10.1109/LRA.2024.3451395
-
[25]
In: 2018 International Conference on 3D Vision (3DV)
McCormac, J., Clark, R., Bloesch, M., Davison, A., Leutenegger, S.: Fusion++: Volumetric object-level slam. In: 2018 International Conference on 3D Vision (3DV). pp. 32–41 (2018).https://doi.org/10.1109/3DV.2018.00015
-
[26]
In: International Conference on 3D Vision, 3DV 2025, Singapore, March 25- 28, 2025
Mei, G., Riz, L., Wang, Y., Poiesi, F.: Vocabulary-Free 3D Instance Segmentation with Vision-Language Assistant. In: 2025 International Conference on 3D Vision (3DV). pp. 1197–1210 (2025).https://doi.org/10.1109/3DV66043.2025.00114
-
[27]
Meta: The Llama 4 herd: The beginning of a new era of natively multi- modal AI innovation (2025),https://ai.meta.com/blog/llama-4-multimodal- intelligence/
2025
-
[28]
OpenAI: GPT-4o System Card (2024).https://doi.org/10.48550/arXiv.2410. 21276 18 D. Bickici et al
-
[29]
OpenAI: OpenAI GPT-5 System Card (2025).https://doi.org/10.48550/ arXiv.2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
OpenAI: Introducing GPT-5.4 (2026),https://openai.com/index/introducing- gpt-5-4/
2026
-
[31]
Transactions on Ma- chine Learning Research (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Syn- naeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual fe...
2024
-
[32]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Peng, S., Genova, K., Jiang, C., Tagliasacchi, A., Pollefeys, M., Funkhouser, T.: OpenScene: 3D Scene Understanding with Open Vocabularies. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 815–824. IEEE, Vancouver, BC, Canada (2023).https://doi.org/10.1109/CVPR52729. 2023.00085
-
[33]
In: Robotics: Science and Systems (RSS) (2025).https://doi.org/10.15607/RSS.2025.XXI
Peterson, M.B., Jia, Y.X., Tian, Y., Thomas, A., How, J.P.: Roman: Open-set object map alignment for robust view-invariant global localization. In: Robotics: Science and Systems (RSS) (2025).https://doi.org/10.15607/RSS.2025.XXI. 029
-
[34]
In: Proceedings of the 38th International Conference on Machine Learning (ICML)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transfer- able visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning (ICML). vol. 139, pp. 8748–8763. PMLR (2021)
2021
-
[35]
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C.Y., Girshick, R., Dollár, P., Feichtenhofer, C.: SAM 2: Segment Anything in Images and Videos (2024).https://doi.org/10.48550/ARXIV.2408.00714
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.00714 2024
-
[36]
Reimers, N., Gurevych, I.: Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natu- ral Language Processing (EMNLP-IJCNLP). pp. 3982–3992. Association for Com- putational Linguistics, Hong Kong, China (2019)...
2019
-
[37]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., Zeng, Z., Zhang, H., Li, F., Yang, J., Li, H., Jiang, Q., Zhang, L.: Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks (2024). https://doi.org/10.48550/arXiv.2401.14159
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.14159 2024
-
[38]
In: 2025 International Conference on Machine Learning and Applications (ICMLA)
Renz, M., Igelbrink, F., Atzmueller, M.: Integrating prior observations for incre- mental 3d scene graph prediction. In: 2025 International Conference on Machine Learning and Applications (ICMLA). pp. 887–892 (2025).https://doi.org/10. 1109/ICMLA66185.2025.00132
-
[39]
Rosinol, A., Abate, M., Chang, Y., Carlone, L.: Kimera: an Open-Source Library for Real-Time Metric-Semantic Localization and Mapping. In: 2020 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 1689–1696 (2020). https://doi.org/10.1109/ICRA40945.2020.9196885
-
[40]
Rosinol, A., Violette, A., Abate, M., Hughes, N., Chang, Y., Shi, J., Gupta, A., Carlone, L.: Kimera: From SLAM to spatial perception with 3D dynamic scene graphs. The International Journal of Robotics Research40(12-14), 1510–1546 (2021).https://doi.org/10.1177/02783649211056674 Think While You Map 19
-
[41]
In: 2017 IEEE International Conference on Robotics and Au- tomation (ICRA)
Runz, M., Agapito, L.: Co-fusion: Real-time segmentation, tracking and fusion of multiple objects. In: 2017 IEEE International Conference on Robotics and Au- tomation (ICRA). pp. 4471–4478. IEEE, Singapore, Singapore (2017).https: //doi.org/10.1109/ICRA.2017.7989518
-
[42]
Runz, M., Buffier, M., Agapito, L.: MaskFusion: Real-Time Recognition, Track- ing and Reconstruction of Multiple Moving Objects. In: 2018 IEEE International SymposiumonMixedandAugmentedReality(ISMAR).pp.10–20.IEEE,Munich, Germany (2018).https://doi.org/10.1109/ISMAR.2018.00024
-
[43]
In: Robotics: Science and Systems XIX (2023).https://doi.org/10.15607/RSS.2023.XIX.074
Shafiullah, N.M.M., Paxton, C., Pinto, L., Chintala, S., Szlam, A.: CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory. In: Robotics: Science and Systems XIX (2023).https://doi.org/10.15607/RSS.2023.XIX.074
-
[44]
Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur- Artal, R., Ren, C., Verma, S., Clarkson, A., Yan, M., Budge, B., Yan, Y., Pan, X., Yon, J., Zou, Y., Leon, K., Carter, N., Briales, J., Gillingham, T., Mueggler, E., Pesqueira, L., Savva, M., Batra, D., Strasdat, H.M., Nardi, R.D., Goesele, M., Lovegrove, S., Newcombe, R.:...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.05797 2019
-
[45]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems (NeurIPS)
Takmaz, A., Fedele, E., Sumner, R.W., Pollefeys, M., Tombari, F., Engelmann, F.: Openmask3d: open-vocabulary 3d instance segmentation. In: Proceedings of the 37th International Conference on Neural Information Processing Systems (NeurIPS). Curran Associates Inc., Red Hook, NY, USA (2023)
2023
-
[46]
In: 2025 IEEE/CVF International Con- ference on Computer Vision (ICCV)
Wang, Z., Su, Y., Li, C., Wang, D., Huang, Y., Li, X., Zhao, B.: Open-vocabulary octree-graph for 3d scene understanding. In: 2025 IEEE/CVF International Con- ference on Computer Vision (ICCV). pp. 7037–7047 (2025).https://doi.org/10. 1109/ICCV51701.2025.00661
-
[47]
In: Robotics: Science and Systems XX
Werby, A., Huang, C., Büchner, M., Valada, A., Burgard, W.: Hierarchical Open- Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation. In: Robotics: Science and Systems XX. Robotics: Science and Systems Foundation (2024).https://doi.org/10.15607/RSS.2024.XX.077
-
[48]
In���� �������� ���������� �� �������� ������ ��� ������� ����������� ������
Wu, S.C., Tateno, K., Navab, N., Tombari, F.: Incremental 3D Semantic Scene Graph Prediction from RGB Sequences. In: 2023 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 5064–5074. IEEE, Vancouver, BC, Canada (2023).https://doi.org/10.1109/CVPR52729.2023.00490
-
[49]
In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021
Wu, S.C., Wald, J., Tateno, K., Navab, N., Tombari, F.: SceneGraphFusion: Incre- mental 3D Scene Graph Prediction from RGB-D Sequences. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7511–7521. IEEE, Nashville, TN, USA (2021).https://doi.org/10.1109/CVPR46437.2021. 00743
-
[51]
In: 2024 IEEE International Conference on Robotics and Automa- tion (ICRA)
Yang,J.,Chen,X.,Qian,S.,Madaan,N.,Iyengar,M.,Fouhey,D.F.,Chai,J.:LLM- Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent. In: 2024 IEEE International Conference on Robotics and Automa- tion (ICRA). pp. 7694–7701 (2024).https://doi.org/10.1109/ICRA57147.2024. 10610443
-
[52]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Yang, J., Zhang, H., Li, F., Zou, X., Li, C., Gao, J.: Set-of-Mark Prompting Un- leashes Extraordinary Visual Grounding in GPT-4V (2023).https://doi.org/ 10.48550/arXiv.2310.11441 20 D. Bickici et al
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.11441 2023
-
[53]
Zhang, C., Delitzas, A., Wang, F., Zhang, R., Ji, X., Pollefeys, M., Engelmann, F.: Open-Vocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025).https://doi.org/10.1109/CVPR52734.2025.01807 Think While You Map 21 Think While You Map: Asynchronou...
-
[54]
"label": A specific, fine-grained noun (e.g., ’winged armchair’ instead of ’chair’, ’ceramic vase’ instead of ’decor’). 30 D. Bickici et al
-
[55]
attributes
"attributes": - "material": (e.g., wood, velvet, glass, plastic) - "color": (Dominant colors) - "state": (e.g., open, closed, folded, dirty, wet, empty) - "texture": (e.g., glossy, matte, rough, knitted) Constraint: - Do NOT hallucinate attributes not visible in the images. - If an object is completely unclear, set attributes to null. - Output pure JSON m...
-
[56]
Select the object ID that best matches the query
-
[57]
–- User –- Below is a 3D scene composed of objects and edges
Provide a short, factual explanation. –- User –- Below is a 3D scene composed of objects and edges. Each edge is represented as [subject_id, predicate, object_id, distance_m (optional), compass (optional)]. {scene_line} {edge_line} query={utterance} I Full implementation details For completeness, Tab. 13 summarizes the key implementation parameters used i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.