SimpleSearch-VL: A Simple Recipe for Multimodal Agentic Deep Search
Pith reviewed 2026-07-01 05:59 UTC · model grok-4.3
The pith
A lightweight training recipe using 7K trajectories lets open multimodal agents match Gemini-3-Pro on search tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
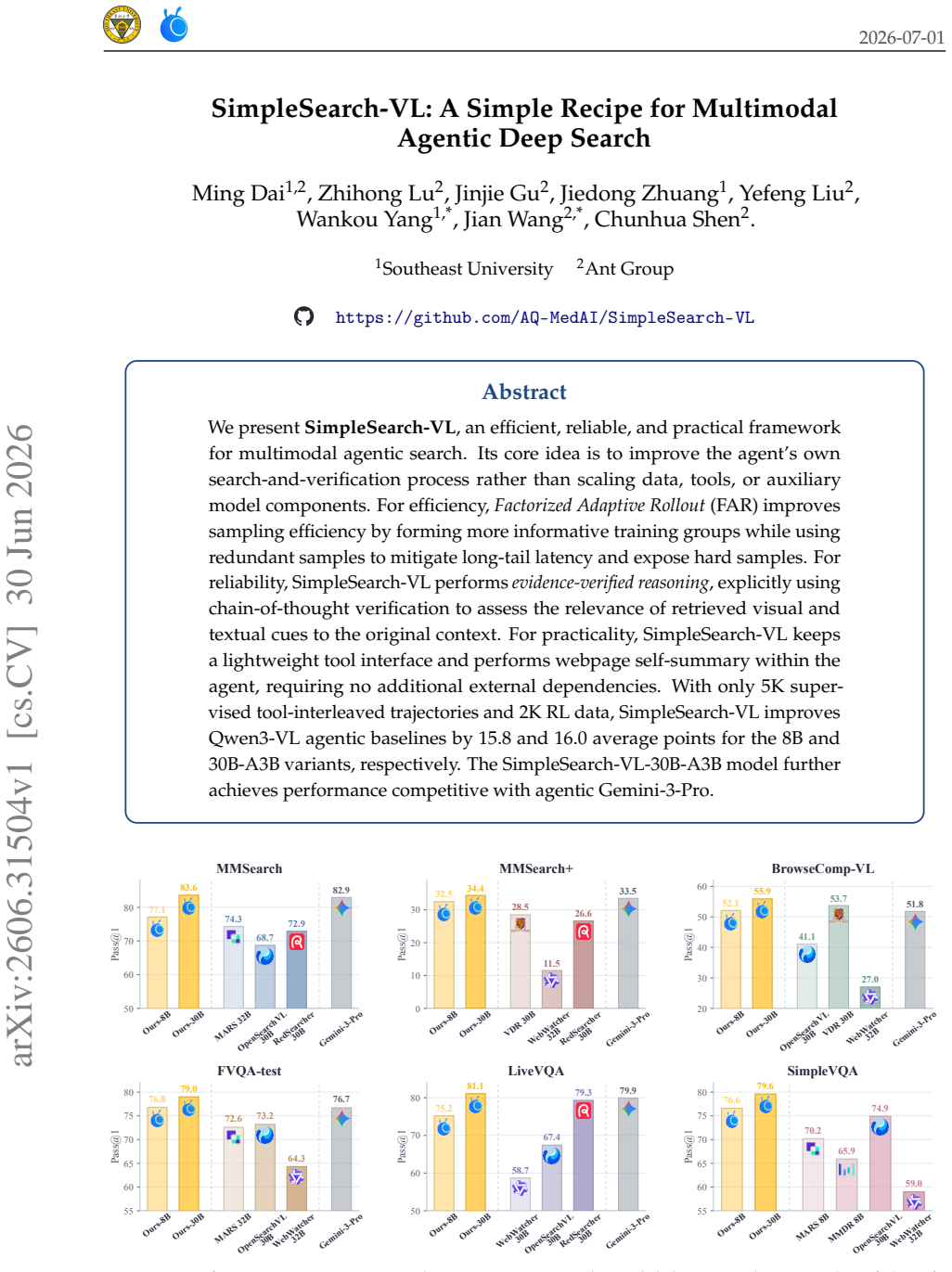
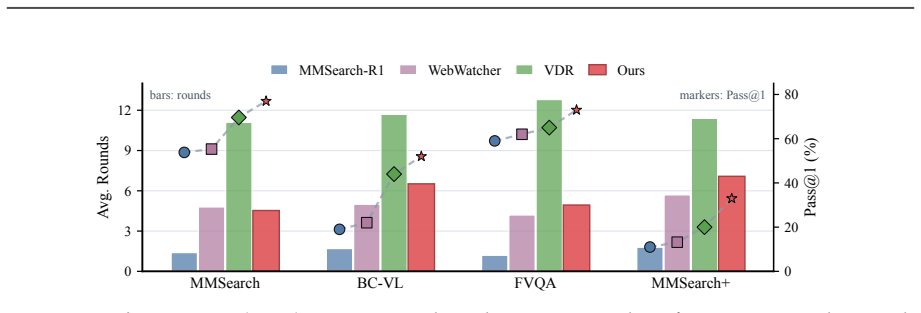
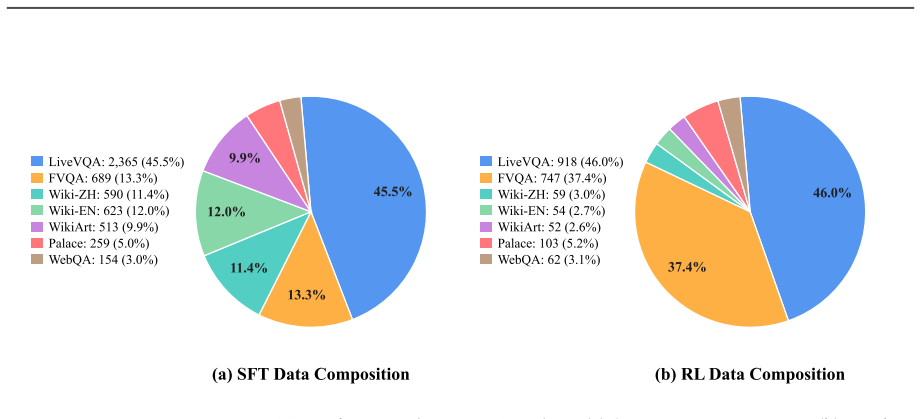
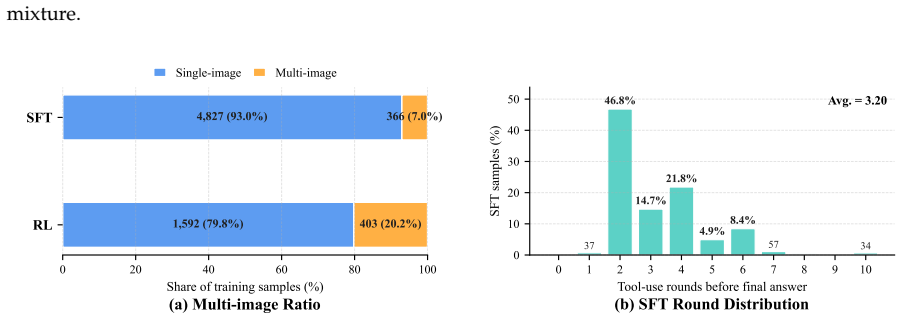
The central claim is that Factorized Adaptive Rollout, evidence-verified reasoning, and in-agent webpage self-summary together allow an agent trained on 5K supervised tool-interleaved trajectories and 2K RL data to improve Qwen3-VL agentic baselines by 15.8 and 16.0 average points for the 8B and 30B-A3B variants, with the larger model reaching performance competitive with agentic Gemini-3-Pro.
What carries the argument
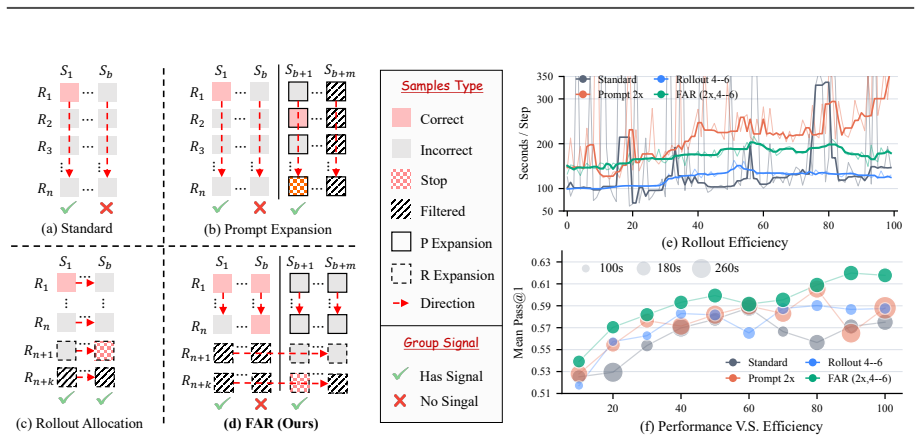
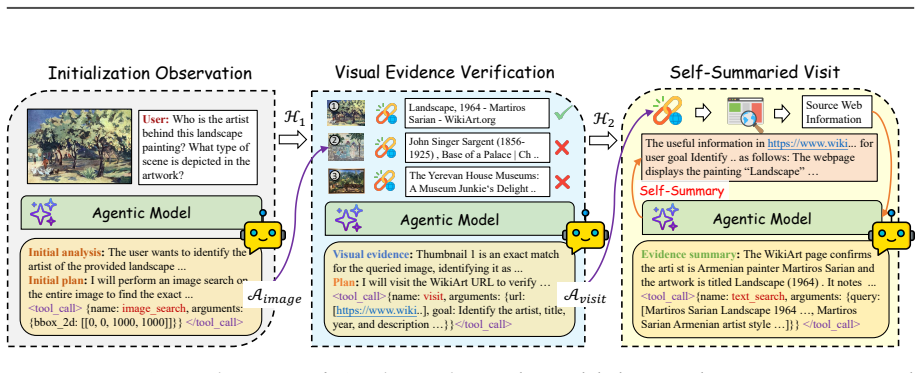
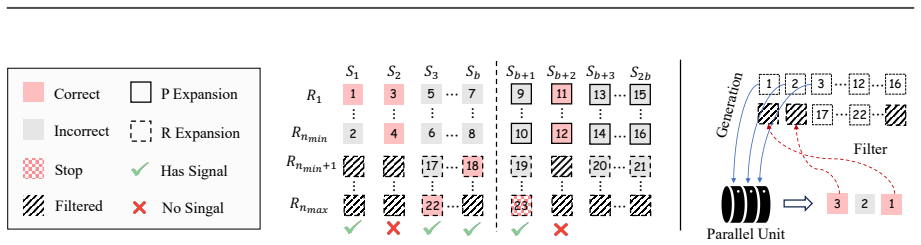
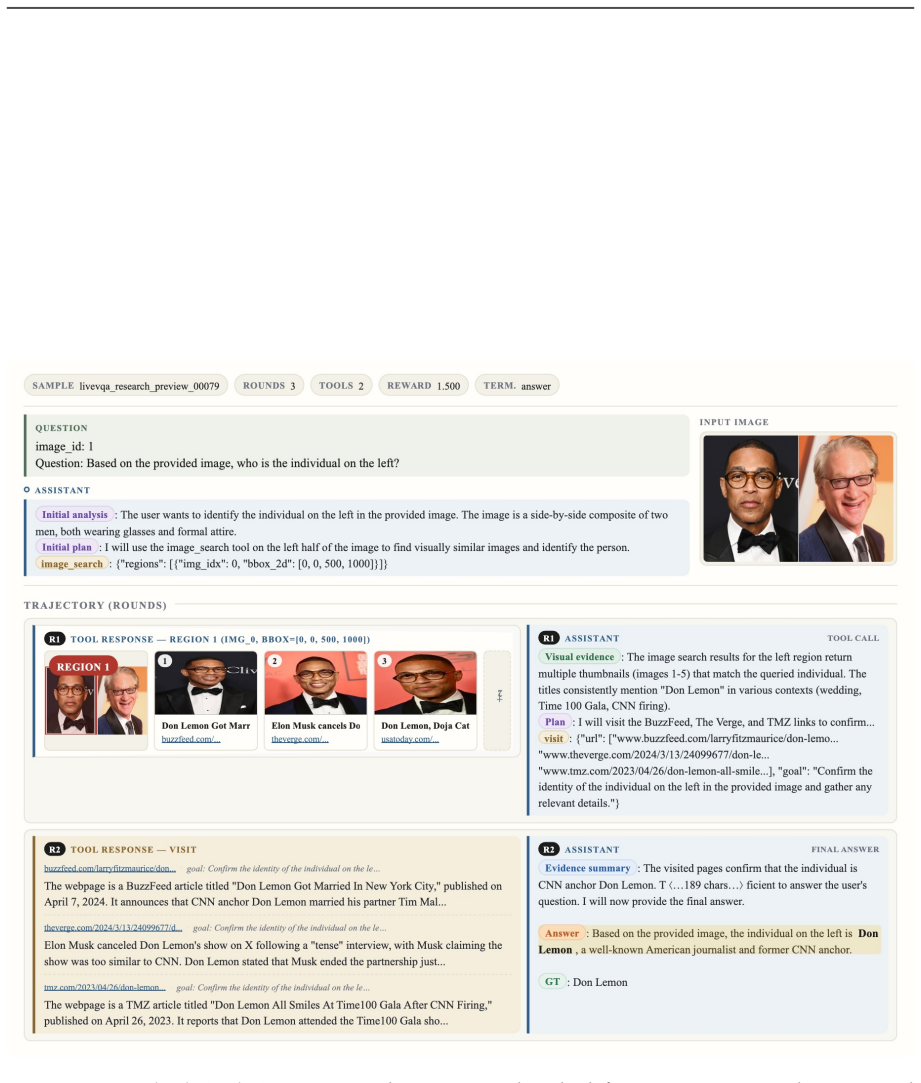
Factorized Adaptive Rollout (FAR) that forms informative training groups while recycling redundant samples to reduce latency and surface hard cases, paired with evidence-verified chain-of-thought reasoning that scores the relevance of each retrieved visual and textual cue to the original query.
If this is right
- Multimodal agents can reach competitive search performance without external auxiliary models or large additional datasets.
- Verification steps inserted into the reasoning chain measurably reduce errors when agents must judge retrieved images and text.
- Keeping summary generation inside the agent removes the need for separate summarization services.
- Adaptive rollout strategies improve sample efficiency even when total training data stays small.
- The same three components can be applied to other base vision-language models without architectural changes.
Where Pith is reading between the lines
- If the gains transfer to other open VLMs, the recipe offers a low-cost path to stronger agentic search across model families.
- The emphasis on internal verification may extend to non-search agent tasks where agents must judge the utility of retrieved evidence.
- Lightweight self-contained agents could lower deployment costs for applications that currently rely on closed-model APIs.
- Testing FAR on longer-horizon tasks would reveal whether the latency-mitigation benefit scales beyond the reported search benchmarks.
Load-bearing premise
The reported gains come from the proposed rollout, verification, and self-summary steps rather than from hidden differences in evaluation setup, data selection, or how the baselines were run.
What would settle it
Reproduce the exact Qwen3-VL agent baselines and SimpleSearch-VL models on the same test sets with identical tool interfaces and prompt templates to check whether the 15-plus-point average gains remain.
Figures

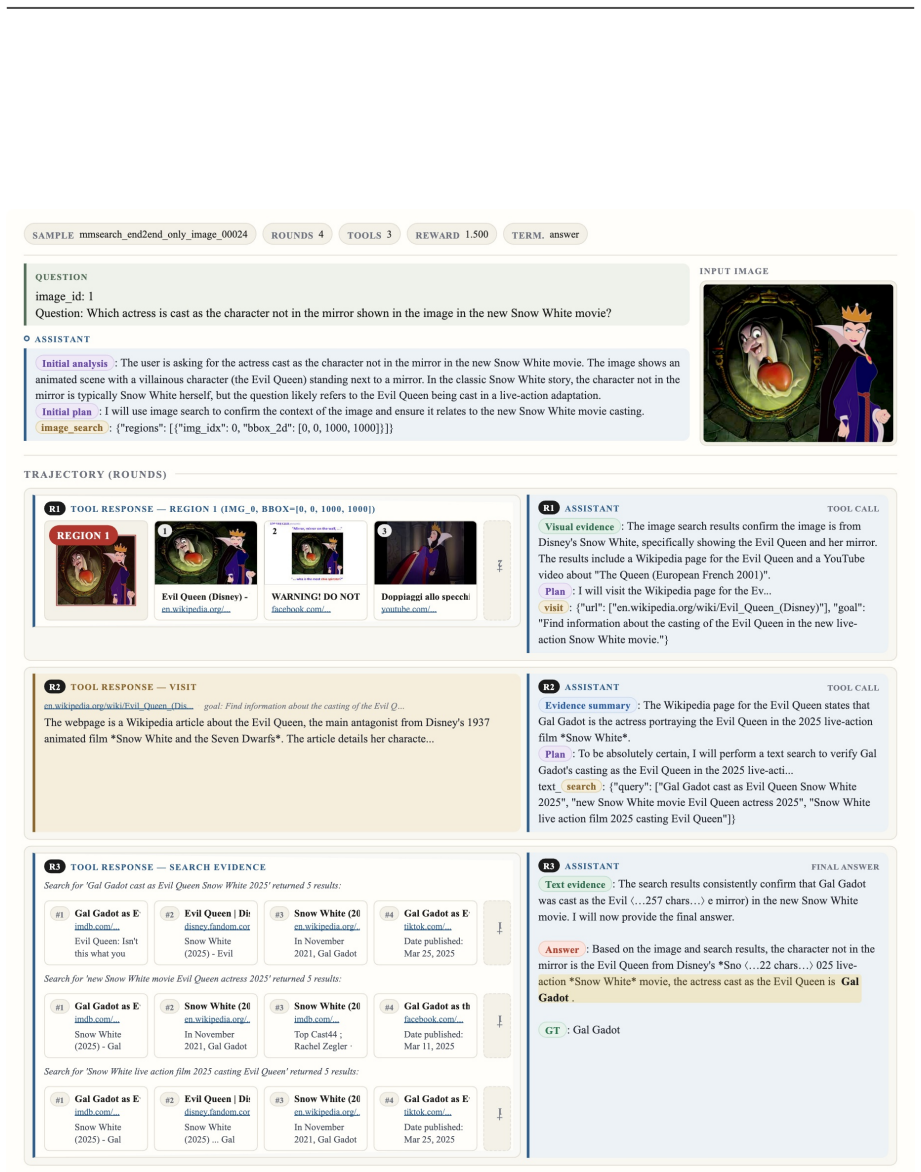
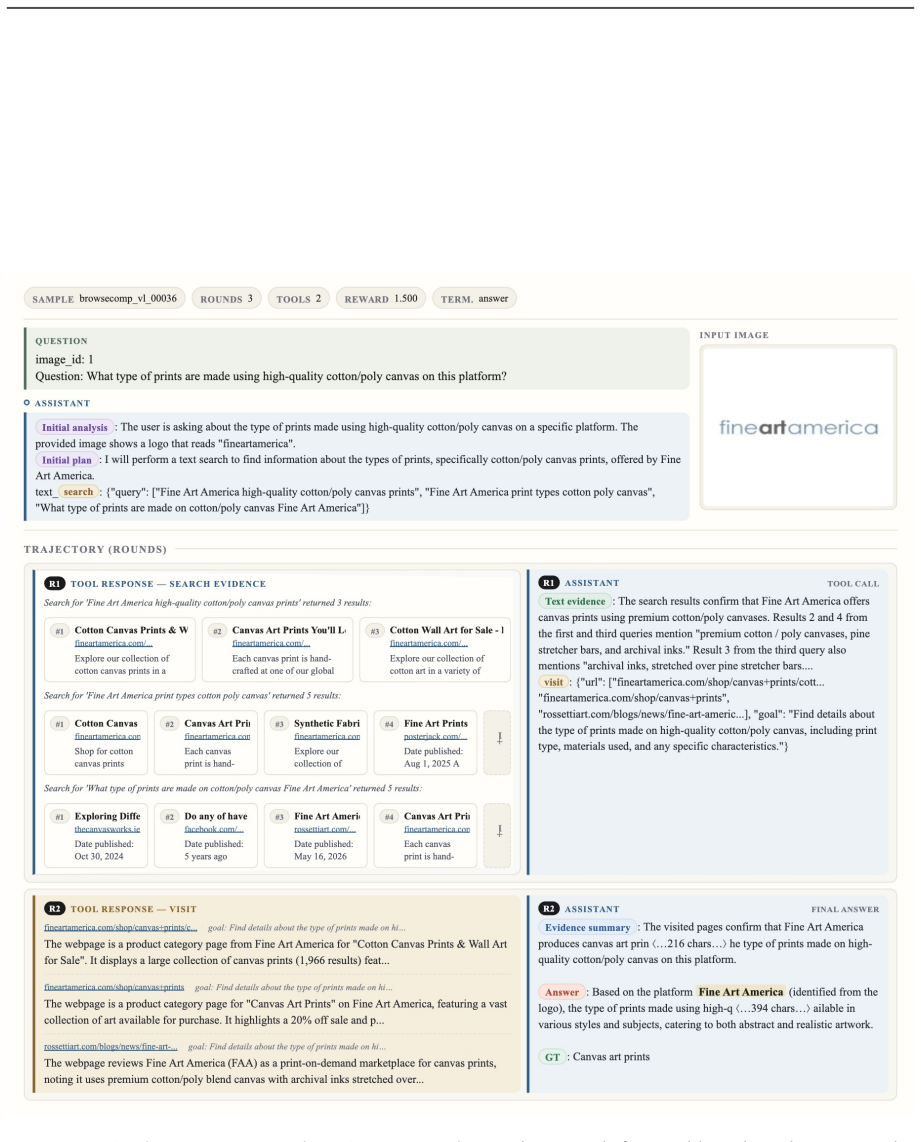
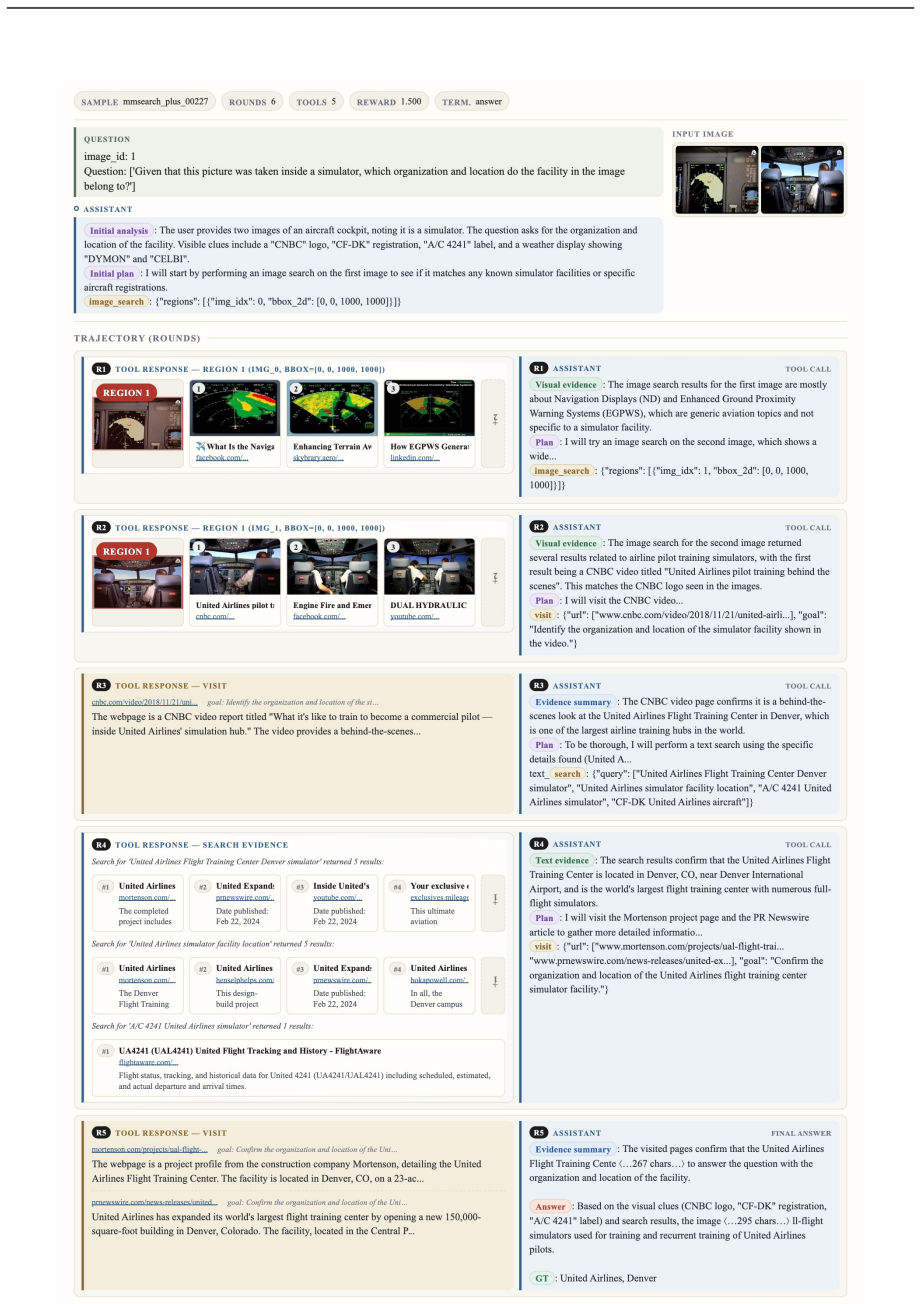
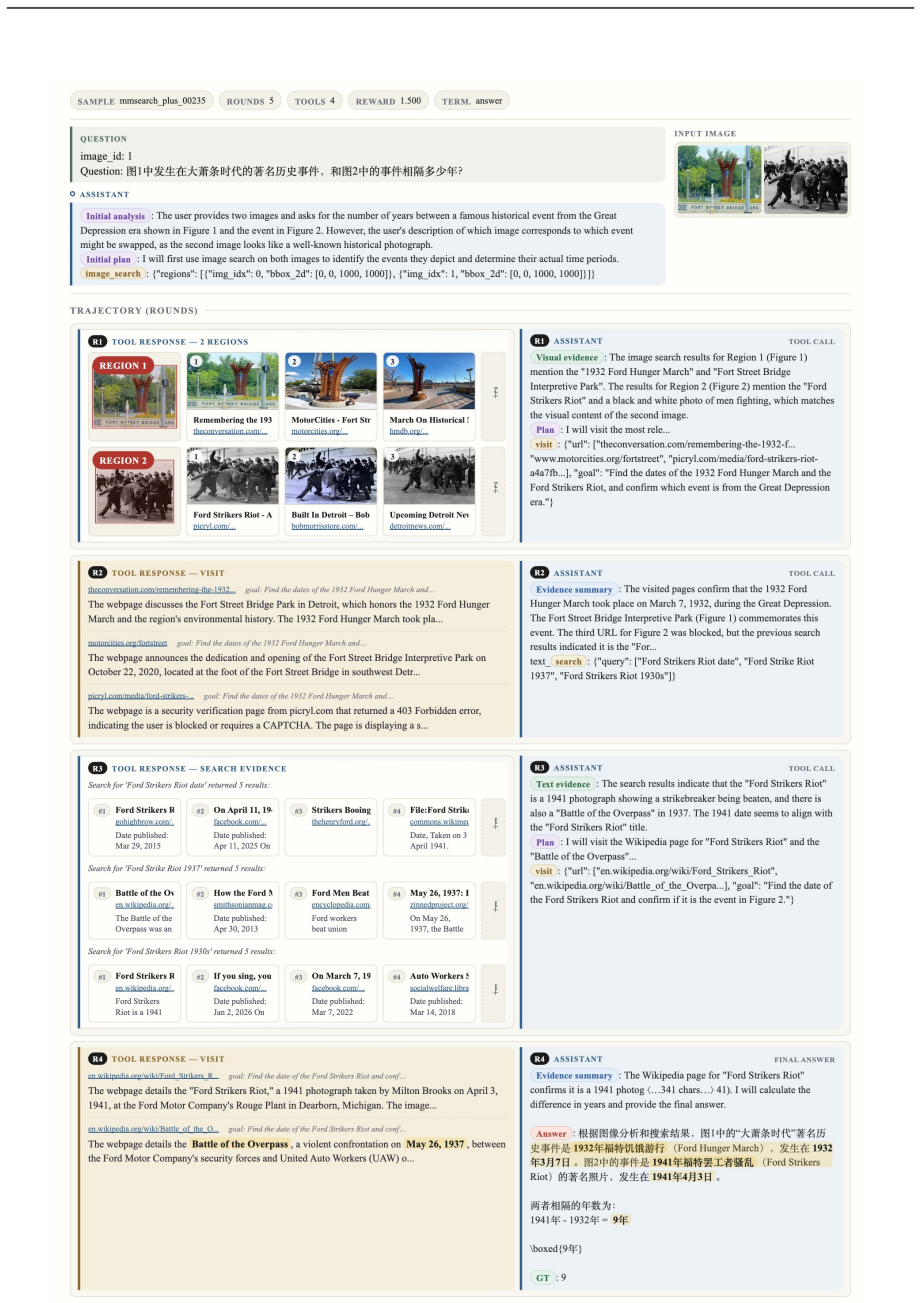

read the original abstract
We present SimpleSearch-VL, an efficient, reliable, and practical framework for multimodal agentic search. Its core idea is to improve the agent's own search-and-verification process rather than scaling data, tools, or auxiliary model components. For efficiency, Factorized Adaptive Rollout (FAR) improves sampling efficiency by forming more informative training groups while using redundant samples to mitigate long-tail latency and expose hard samples. For reliability, SimpleSearch-VL performs evidence-verified reasoning, explicitly using chain-of-thought verification to assess the relevance of retrieved visual and textual cues to the original context. For practicality, SimpleSearch-VL keeps a lightweight tool interface and performs webpage self-summary within the agent, requiring no additional external dependencies. With only 5K supervised tool-interleaved trajectories and 2K RL data, SimpleSearch-VL improves Qwen3-VL agentic baselines by 15.8 and 16.0 average points for the 8B and 30B-A3B variants, respectively. The SimpleSearch-VL-30B-A3B model further achieves performance competitive with agentic Gemini-3-Pro.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SimpleSearch-VL, a multimodal agentic search framework whose core contributions are Factorized Adaptive Rollout (FAR) for sampling efficiency, evidence-verified chain-of-thought reasoning for reliability, and in-agent webpage self-summary for practicality. Using only 5K supervised tool-interleaved trajectories and 2K RL samples, the method is reported to improve Qwen3-VL agentic baselines by 15.8 and 16.0 average points on the 8B and 30B-A3B variants respectively, with the larger model reaching performance competitive with agentic Gemini-3-Pro.
Significance. If the reported gains are shown to be robustly attributable to the three proposed components under identical evaluation conditions, the work would offer a practical, low-data recipe for improving multimodal agents without auxiliary models or external dependencies. The emphasis on efficiency via FAR and internal self-summary is a clear strength for deployment-oriented research.
major comments (2)
- [Abstract] Abstract: The central claim attributes the 15.8/16.0-point lifts to FAR, evidence-verified reasoning, and lightweight self-summary, yet provides no information on whether the Qwen3-VL baselines were re-implemented with identical tool interfaces, prompt formats, retrieval corpora, and scoring rules. Without this, the attribution cannot be verified and the numerical improvements do not yet support the causal claim.
- [Experimental section] Experimental section (assumed §4 or equivalent): No details are supplied on statistical significance, variance across runs, or controls for post-hoc data selection. The soundness of the 15.8/16.0-point gains therefore cannot be assessed from the provided information.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the concerns about baseline equivalence and experimental robustness below, and will revise the manuscript to improve clarity on these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the 15.8/16.0-point lifts to FAR, evidence-verified reasoning, and lightweight self-summary, yet provides no information on whether the Qwen3-VL baselines were re-implemented with identical tool interfaces, prompt formats, retrieval corpora, and scoring rules. Without this, the attribution cannot be verified and the numerical improvements do not yet support the causal claim.
Authors: We re-implemented the Qwen3-VL baselines using identical tool interfaces, prompt formats, retrieval corpora, and scoring rules to ensure fair attribution of gains to the proposed components (FAR, evidence-verified reasoning, and self-summary). This equivalence is stated in the experimental setup. We will add an explicit clarifying sentence to the abstract and expand the relevant paragraph in the introduction. revision: yes
-
Referee: [Experimental section] Experimental section (assumed §4 or equivalent): No details are supplied on statistical significance, variance across runs, or controls for post-hoc data selection. The soundness of the 15.8/16.0-point gains therefore cannot be assessed from the provided information.
Authors: The training trajectories were fixed before evaluation with no post-hoc selection. Main results reflect averages over three independent runs with different seeds, yielding consistent gains. We will add a dedicated paragraph in the experimental section reporting the number of runs, observed variance where available, and confirmation of the fixed data protocol. revision: yes
Circularity Check
No circularity: empirical performance claims rest on reported training data and baselines without reduction to fitted inputs or self-citations.
full rationale
The paper presents an empirical framework using supervised trajectories and RL data to train a multimodal agent, claiming gains from components like FAR and evidence-verified reasoning. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims concern measured improvements over baselines rather than any derivation that reduces by construction to its inputs. This is the standard case of a self-contained empirical report whose validity depends on experimental controls, not definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.22019 , year=
VRAG-RL: Empower Vision-Perception-Based RAG for Visually Rich Information Understanding via Iterative Reasoning with Reinforcement Learning , author=. arXiv preprint arXiv:2505.22019 , year=
-
[2]
Thinking with Images
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning , author=. 2026 , eprint=
2026
-
[3]
Wikipedia , howpublished=
-
[4]
Team, Anthropic , title=
-
[5]
2025 , eprint=
A Survey on LLM-as-a-Judge , author=. 2025 , eprint=
2025
-
[6]
arXiv preprint arXiv:2504.07956 , year=
Vcr-bench: A comprehensive evaluation framework for video chain-of-thought reasoning , author=. arXiv preprint arXiv:2504.07956 , year=
-
[7]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[8]
arXiv preprint arXiv:2503.17736 , year=
V2P-Bench: Evaluating Video-Language Understanding with Visual Prompts for Better Human-Model Interaction , author=. arXiv preprint arXiv:2503.17736 , year=
-
[9]
arXiv preprint arXiv:2510.01304 , year=
Agentic Jigsaw Interaction Learning for Enhancing Visual Perception and Reasoning in Vision-Language Models , author=. arXiv preprint arXiv:2510.01304 , year=
-
[10]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents
Visrag: Vision-based retrieval-augmented generation on multi-modality documents , author=. arXiv preprint arXiv:2410.10594 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[13]
European Conference on Computer Vision , pages=
Sharegpt4v: Improving large multi-modal models with better captions , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[14]
Advances in Neural Information Processing Systems , volume=
Sharegpt4video: Improving video understanding and generation with better captions , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Mmsearch: Unveiling the potential of large models as multi-modal search engines , author=
-
[17]
arXiv preprint arXiv:2601.03193 , year=
UniCorn: Towards Self-Improving Unified Multimodal Models through Self-Generated Supervision , author=. arXiv preprint arXiv:2601.03193 , year=
-
[18]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Enhancing Large Vision-Language Models with Ultra-Detailed Image Caption Generation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[19]
arXiv preprint arXiv:2511.22134 , year=
DualVLA: Building a Generalizable Embodied Agent via Partial Decoupling of Reasoning and Action , author=. arXiv preprint arXiv:2511.22134 , year=
-
[20]
arXiv preprint arXiv:2506.13977 , year=
CRITICTOOL: Evaluating Self-Critique Capabilities of Large Language Models in Tool-Calling Error Scenarios , author=. arXiv preprint arXiv:2506.13977 , year=
-
[21]
arXiv preprint arXiv:2509.06945 , year=
Interleaving reasoning for better text-to-image generation , author=. arXiv preprint arXiv:2509.06945 , year=
-
[22]
arXiv preprint arXiv:2504.05288 , year=
LiveVQA: Live Visual Knowledge Seeking , author=. arXiv preprint arXiv:2504.05288 , year=
-
[23]
arXiv preprint arXiv:2512.02395 , year=
Skywork-R1V4: Toward Agentic Multimodal Intelligence through Interleaved Thinking with Images and DeepResearch , author=. arXiv preprint arXiv:2512.02395 , year=
-
[24]
arXiv preprint arXiv:2504.07165 , year=
Perception in reflection , author=. arXiv preprint arXiv:2504.07165 , year=
-
[25]
2025 , eprint=
PALADIN: Self-Correcting Language Model Agents to Cure Tool-Failure Cases , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
Where LLM Agents Fail and How They can Learn From Failures , author=. 2025 , eprint=
2025
-
[27]
Neurocomputing , pages=
RE-GRPO: Leveraging hard negative cases through large language model guided self training , author=. Neurocomputing , pages=. 2025 , publisher=
2025
-
[28]
2026 , eprint=
On Group Relative Policy Optimization Collapse in Agent Search: The Lazy Likelihood-Displacement , author=. 2026 , eprint=
2026
-
[29]
2026 , eprint=
When Right Meets Wrong: Bilateral Context Conditioning with Reward-Confidence Correction for GRPO , author=. 2026 , eprint=
2026
-
[30]
2026 , eprint=
CoRPO: Adding a Correctness Bias to GRPO Improves Generalization , author=. 2026 , eprint=
2026
-
[31]
2026 , eprint=
WS-GRPO: Weakly-Supervised Group-Relative Policy Optimization for Rollout-Efficient Reasoning , author=. 2026 , eprint=
2026
-
[32]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[33]
arXiv preprint arXiv:2602.13179 , year=
Fix Before Search: Benchmarking Agentic Query Visual Pre-processing in Multimodal Retrieval-augmented Generation , author=. arXiv preprint arXiv:2602.13179 , year=
-
[34]
arXiv preprint arXiv:2603.01050 , year=
Mm-deepresearch: A simple and effective multimodal agentic search baseline , author=. arXiv preprint arXiv:2603.01050 , year=
-
[35]
2025 , eprint=
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning , author=. 2025 , eprint=
2025
-
[36]
MMSearch-R1: Incentivizing LMMs to Search
MMSearch-R1: Incentivizing LMMs to Search , author=. arXiv preprint arXiv:2506.20670 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
2026 , eprint=
OpenVLThinkerV2: A Generalist Multimodal Reasoning Model for Multi-domain Visual Tasks , author=. 2026 , eprint=
2026
-
[38]
2026 , eprint=
Kimi K2.5: Visual Agentic Intelligence , author=. 2026 , eprint=
2026
-
[39]
arXiv preprint arXiv:2510.12801 , year=
Deepmmsearch-r1: Empowering multimodal llms in multimodal web search , author=. arXiv preprint arXiv:2510.12801 , year=
-
[40]
WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
Webwatcher: Breaking new frontier of vision-language deep research agent , author=. arXiv preprint arXiv:2508.05748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
DeepEyesV2: Toward Agentic Multimodal Model
DeepEyesV2: Toward Agentic Multimodal Model , author=. arXiv preprint arXiv:2511.05271 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Tongyi DeepResearch Technical Report
Tongyi deepresearch technical report , author=. arXiv preprint arXiv:2510.24701 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2505.22648 , year=
Webdancer: Towards autonomous information seeking agency , author=. arXiv preprint arXiv:2505.22648 , year=
-
[44]
WebSailor: Navigating Super-human Reasoning for Web Agent
WebSailor: Navigating Super-human Reasoning for Web Agent , author=. arXiv preprint arXiv:2507.02592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
arXiv preprint arXiv:2507.15061 , year=
Webshaper: Agentically data synthesizing via information-seeking formalization , author=. arXiv preprint arXiv:2507.15061 , year=
-
[46]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Simplevqa: Multimodal factuality evaluation for multimodal large language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[47]
IEEE transactions on pattern analysis and machine intelligence , volume=
Fvqa: Fact-based visual question answering , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2017 , publisher=
2017
-
[48]
arXiv preprint arXiv:2302.11713 , year=
Can pre-trained vision and language models answer visual information-seeking questions? , author=. arXiv preprint arXiv:2302.11713 , year=
-
[49]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[52]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[53]
arXiv preprint arXiv:2501.07572 , year=
Webwalker: Benchmarking llms in web traversal , author=. arXiv preprint arXiv:2501.07572 , year=
-
[54]
2022 , eprint=
WebQA: Multihop and Multimodal QA , author=. 2022 , eprint=
2022
-
[55]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[56]
2025 , note=
rLLM: A Framework for Post-Training Language Agents , author=. 2025 , note=
2025
-
[57]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[58]
Deepswe: Training a fully open-sourced, state-of-the-art coding agent by scaling rl, Jul 2025 , author=
2025
-
[59]
AdaTooler-V: Adaptive Tool-Use for Images and Videos
AdaTooler-V: Adaptive Tool-Use for Images and Videos , author=. arXiv preprint arXiv:2512.16918 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
arXiv preprint arXiv:2502.01600 , year=
Reinforcement learning for long-horizon interactive llm agents , author=. arXiv preprint arXiv:2502.01600 , year=
-
[61]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms , author=. arXiv preprint arXiv:2402.14740 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
arXiv preprint arXiv:2510.26788 , year=
Defeating the training-inference mismatch via fp16 , author=. arXiv preprint arXiv:2510.26788 , year=
-
[63]
arXiv preprint arXiv:2508.21475 , year=
MMSearch-Plus: Benchmarking Provenance-Aware Search for Multimodal Browsing Agents , author=. arXiv preprint arXiv:2508.21475 , year=
-
[64]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Video-R1: Reinforcing Video Reasoning in MLLMs
Video-r1: Reinforcing video reasoning in mllms , author=. arXiv preprint arXiv:2503.21776 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
preprint , year=
Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models , author=. preprint , year=
-
[68]
Exploring Reasoning Reward Model for Agents
Exploring Reasoning Reward Model for Agents , author=. arXiv preprint arXiv:2601.22154 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
arXiv preprint arXiv:2506.04207 , year=
Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning , author=. arXiv preprint arXiv:2506.04207 , year=
-
[70]
arXiv preprint arXiv:2510.08457 , year=
ARES: Multimodal Adaptive Reasoning via Difficulty-Aware Token-Level Entropy Shaping , author=. arXiv preprint arXiv:2510.08457 , year=
-
[71]
arXiv preprint arXiv:2603.29620 , year=
Unify-Agent: A Unified Multimodal Agent for World-Grounded Image Synthesis , author=. arXiv preprint arXiv:2603.29620 , year=
-
[72]
Gen-Searcher: Reinforcing Agentic Search for Image Generation
Gen-Searcher: Reinforcing Agentic Search for Image Generation , author=. arXiv preprint arXiv:2603.28767 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
arXiv preprint arXiv:2601.22060 , year=
Vision-deepresearch: Incentivizing deepresearch capability in multimodal large language models , author=. arXiv preprint arXiv:2601.22060 , year=
-
[74]
OneThinker: All-in-one Reasoning Model for Image and Video
Onethinker: All-in-one reasoning model for image and video , author=. arXiv preprint arXiv:2512.03043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
2026 , eprint=
AdaReasoner: Dynamic Tool Orchestration for Iterative Visual Reasoning , author=. 2026 , eprint=
2026
-
[76]
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
2025 , eprint=
Agentic Reinforced Policy Optimization , author=. 2025 , eprint=
2025
-
[78]
2025 , eprint=
WebSailor: Navigating Super-human Reasoning for Web Agent , author=. 2025 , eprint=
2025
-
[79]
arXiv preprint arXiv:2505.14246 , year=
Visual Agentic Reinforcement Fine-Tuning , author=. arXiv preprint arXiv:2505.14246 , year=
-
[80]
arXiv preprint arXiv:2512.24330 , year=
SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning , author=. arXiv preprint arXiv:2512.24330 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.