Mitigating Positional Leakage in 3D Masked Autoencoders for Robust Representation Learning
Pith reviewed 2026-07-01 05:45 UTC · model grok-4.3
The pith
Decoder over-reliance on position weakens semantic features in 3D masked autoencoders; MPL-MAE counters this with recalibrated embeddings and gated interfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
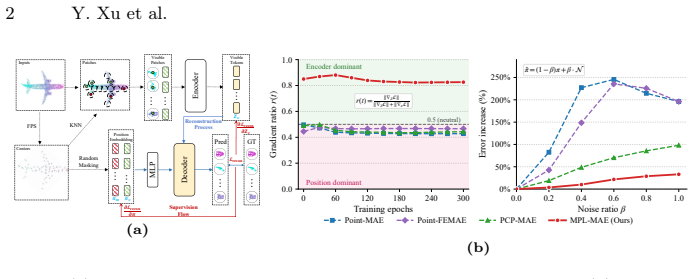
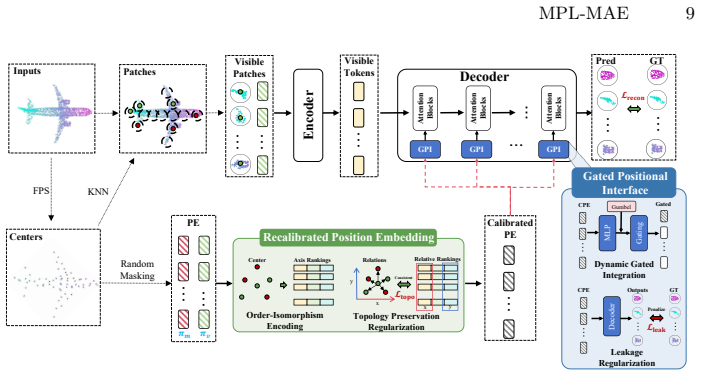
The decoder in existing 3D MAE frameworks tends to over-rely on positional information, which weakens semantic representation learning and leads to suboptimal feature quality. MPL-MAE mitigates this by introducing a recalibrated positional embedding module that suppresses metric-dominant coordinate signals while preserving geometric topology, together with a gated positional interface module that dynamically regulates positional injection during reconstruction; the two modules together promote a more balanced interaction between spatial priors and semantic features.
What carries the argument
Recalibrated positional embedding module and gated positional interface module, which together suppress over-reliance on coordinates while keeping geometric structure during decoder reconstruction.
If this is right
- The encoder produces features that carry more semantic information usable across classification, segmentation, and detection tasks.
- Reconstruction quality remains high while positional signals are dynamically limited rather than removed outright.
- The same encoder can be frozen and transferred to new 3D tasks with less performance drop than in prior MAE setups.
- Overall training yields representations that interact more evenly with both spatial and semantic signals.
Where Pith is reading between the lines
- The gated interface could be tested on other coordinate-reconstruction objectives, such as surface reconstruction or scene completion, to check whether leakage is a broader issue.
- If the recalibration preserves topology, the method might also reduce sensitivity to coordinate noise or scaling differences in real-world scans.
- Similar positional over-reliance may appear in non-MAE 3D self-supervised methods that decode coordinates, suggesting a general design pattern rather than an MAE-specific fix.
Load-bearing premise
Suppressing metric-dominant coordinate signals while preserving geometric topology will shift the decoder toward semantic encoder features rather than simply replacing one form of leakage with another.
What would settle it
Training both a standard 3D MAE and MPL-MAE on identical data and benchmarks, then measuring downstream task accuracy; if MPL-MAE shows no gain or a drop, the claim that the modules improve semantic representation quality would be contradicted.
Figures
read the original abstract
Masked autoencoding has emerged as a prominent paradigm for self-supervised learning on 3D point clouds, achieving competitive performance across downstream tasks. Unlike its 2D counterpart, 3D masked autoencoding directly reconstructs spatial coordinates, making it inherently susceptible to positional leakage. In this work, we identify that the decoder in existing 3D MAE frameworks tends to over-rely on positional information, which weakens semantic representation learning and leads to suboptimal feature quality. To address this issue, we propose MPL-MAE, a masked point learning framework that mitigates positional over-reliance while enhancing the utilization of encoder features. Specifically, we introduce a recalibrated positional embedding module that suppresses metric-dominant coordinate signals while preserving geometric topology, together with a gated positional interface module that dynamically regulates positional injection during reconstruction. These designs promote a more balanced interaction between spatial priors and semantic features, yielding robust and informative representations. Extensive experiments across downstream tasks demonstrate that MPL-MAE consistently achieves competitive performance, validating its effectiveness. Code is available at https://github.com/yanx57/MPL-MAE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies that 3D masked autoencoders are susceptible to positional leakage because they reconstruct spatial coordinates directly, causing the decoder to over-rely on positional information at the expense of semantic features. It proposes MPL-MAE, which introduces a recalibrated positional embedding module (suppressing metric-dominant coordinate signals while preserving geometric topology) and a gated positional interface module (dynamically regulating positional injection). These are claimed to yield a more balanced interaction between spatial priors and semantic features, producing robust representations that achieve competitive performance on downstream tasks. Code is released at https://github.com/yanx57/MPL-MAE.
Significance. If the proposed modules demonstrably strengthen semantic encoder features rather than merely shifting the decoder's coordinate-reconstruction pathway, the work could improve representation quality in 3D self-supervised learning. The public release of code supports reproducibility and is a clear strength.
major comments (1)
- [Abstract] Abstract: the claim that the recalibrated embedding and gated interface 'promote a more balanced interaction between spatial priors and semantic features' lacks any supporting quantitative evidence, ablation results, or metrics (such as semantic vs. positional reconstruction error, feature similarity scores, or decoder attention maps). Because the reconstruction target remains coordinates, it is unclear whether the modules mitigate over-reliance or simply reparameterize it under a different gating scheme.
minor comments (1)
- [Abstract] Abstract: the statement 'extensive experiments across downstream tasks demonstrate that MPL-MAE consistently achieves competitive performance' provides no specific datasets, baselines, or numerical improvements, making it impossible to evaluate the strength of the empirical support from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the recalibrated embedding and gated interface 'promote a more balanced interaction between spatial priors and semantic features' lacks any supporting quantitative evidence, ablation results, or metrics (such as semantic vs. positional reconstruction error, feature similarity scores, or decoder attention maps). Because the reconstruction target remains coordinates, it is unclear whether the modules mitigate over-reliance or simply reparameterize it under a different gating scheme.
Authors: We agree that the abstract claim would be strengthened by direct quantitative support. The manuscript currently demonstrates effectiveness via competitive downstream task results, which serve as indirect evidence of improved semantic encoder features. To address the specific request, we will revise the manuscript to include additional metrics (e.g., feature similarity to semantic labels and decoder attention visualizations) and clarify how the modules reduce positional over-reliance in the encoder rather than simply altering the decoder pathway. These additions will appear in the experiments and method sections. revision: yes
Circularity Check
No circularity: proposal introduces new modules without reducing claims to fitted inputs or self-citations
full rationale
The paper's core contribution is a descriptive proposal of two new modules (recalibrated positional embedding and gated positional interface) to address positional leakage in 3D MAE. No equations, derivations, or parameter-fitting steps are presented in the provided text that would allow any claimed prediction or result to reduce by construction to the inputs. The abstract and description contain no self-citations used as load-bearing uniqueness theorems, no ansatz smuggling, and no renaming of known results as novel derivations. The reconstruction target remains coordinates, but the argument does not claim a mathematical equivalence or statistical forcing that collapses the method onto its own data fits. This is a standard engineering proposal whose validity rests on external experiments rather than internal definitional closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Afham, M., Dissanayake, I., Dissanayake, D., Dharmasiri, A., Thilakarathna, K., Rodrigo, R.: Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 9902–9912 (2022)
2022
-
[2]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Armeni, I., Sener, O., Zamir, A.R., Jiang, H., Brilakis, I.K., Fischer, M., Savarese, S.: 3d semantic parsing of large-scale indoor spaces. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1534–1543 (2016)
2016
-
[3]
ShapeNet: An Information-Rich 3D Model Repository
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., Xiao, J., Yi, L., Yu, F.: Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, A., Zhang, K., Zhang, R., Wang, Z., Lu, Y., Guo, Y., Zhang, S.: PiMAE: Point cloud and image interactive masked autoencoders for 3D object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5291–5301 (2023)
2023
-
[5]
In: Advances in Neural In- formation Processing Systems (2023)
Chen, G., Wang, M., Yang, Y., Yu, K., Yuan, L., Yue, Y.: Pointgpt: Auto- regressively generative pre-training from point clouds. In: Advances in Neural In- formation Processing Systems (2023)
2023
-
[6]
Chhipa, P.C., Upadhyay, R., Saini, R., Lindqvist, L., Nordenskjold, R., Uchida, S., Liwicki, M.: Depth contrast: Self-supervised pretraining on 3DPM images for miningmaterialclassification.In:ProceedingsoftheEuropeanConferenceonCom- puter Vision Workshops. pp. 212–227 (2022)
2022
-
[7]
Dong, R., Qi, Z., Zhang, L., Zhang, J., Sun, J., Ge, Z., Yi, L., Ma, K.: Autoen- coders as Cross-Modal teachers: Can pretrained 2D image transformers help 3D representation learning? In: Proceedings of the International Conference on Learn- ing Representations (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fan, H., Su, H., Guibas, L.: A point set generation network for 3d object recon- struction from a single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2463–2471 (2017)
2017
-
[9]
In: Advances in Neural Information Processing Systems (2020)
Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P.H., Buchatskaya, E., Do- ersch, C., Pires, B.A., Guo, Z.D., Azar, M.G., Piot, B., Kavukcuoglu, K., Munos, R., Valko, M.: Bootstrap your own latent a new approach to self-supervised learn- ing. In: Advances in Neural Information Processing Systems (2020)
2020
-
[10]
In: Proceedings of the International Joint Conference on Artificial Intelligence (2023)
Guo, Z., Zhang, R., Qiu, L., Li, X., Heng, P.A.: Joint-mae: 2d-3d joint masked autoencoders for 3d point cloud pre-training. In: Proceedings of the International Joint Conference on Artificial Intelligence (2023)
2023
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hou, J., Graham, B., Nießner, M., Xie, S.: Exploring data-efficient 3d scene un- derstanding with contrastive scene contexts. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15587–15597 (2021)
2021
-
[12]
In: Proceedings of the IEEE/CVF international conference on computer vision
Huang, S., Xie, Y., Zhu, S.C., Zhu, Y.: Spatio-temporal self-supervised representa- tion learning for 3d point clouds. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6535–6545 (2021)
2021
-
[13]
In: Advances in Neural Information Processing Systems (2022)
Li, G., Zheng, H., Liu, D., Wang, C., Su, B., Zheng, C.: Semmae: Semantic-guided masking for learning masked autoencoders. In: Advances in Neural Information Processing Systems (2022)
2022
-
[14]
In: Proceedings of the European Conference on Computer Vision
Liu, H., Cai, M., Lee, Y.J.: Masked discrimination for self-supervised learning on point clouds. In: Proceedings of the European Conference on Computer Vision. pp. 657–675 (2022) MPL-MAE 17
2022
-
[15]
IEEE Transactions on Multime- dia26, 3897–3908 (2024)
Liu, J., Wu, Y., Gong, M., Liu, Z., Miao, Q., Ma, W.: Inter-modal masked autoen- coder for self-supervised learning on point clouds. IEEE Transactions on Multime- dia26, 3897–3908 (2024)
2024
-
[16]
Journal of Visual Communication and Image Representation115, 104675 (2026)
Liu, X., Wang, F., Chen, Z., Dong, X.: Dcmae: A dual-branch contrastive masked autoencoder for 3d object detection. Journal of Visual Communication and Image Representation115, 104675 (2026)
2026
-
[17]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
SGDR: Stochastic Gradient Descent with Warm Restarts
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Luo, C., Yang, X., Yuille, A.: Self-supervised pillar motion learning for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3183–3192 (2021)
2021
-
[20]
In: Proceedings of the Conference on Robot Learning (2021)
Mersch, B., Chen, X., Behley, J., Stachniss, C.: Self-supervised point cloud pre- diction using 3d spatio-temporal convolutional networks. In: Proceedings of the Conference on Robot Learning (2021)
2021
-
[21]
arXiv preprint arXiv:2206.09900 (2023)
Min, C., Xu, X., Zhao, D., Xiao, L., Nie, Y., Dai, B.: Occupancy-mae: Self- supervised pre-training large-scale lidar point clouds with masked occupancy au- toencoders. arXiv preprint arXiv:2206.09900 (2023)
-
[22]
In: Proceedings of the European Conference on Computer Vision
Pang, Y., Wang, W., Tay, F.E.H., Liu, W., Tian, Y., Yuan, L.: Masked autoen- coders for point cloud self-supervised learning. In: Proceedings of the European Conference on Computer Vision. pp. 604–621 (2022)
2022
-
[23]
IEEE Transactions on Automation Science and Engineering19(4), 3639–3648 (2022)
Peng, G., Ren, Z., Wang, H., Li, X., Khyam, M.O.: A self-supervised learning-based 6-dof grasp planning method for manipulator. IEEE Transactions on Automation Science and Engineering19(4), 3639–3648 (2022)
2022
-
[24]
Neural Networks108, 533–543 (2018)
Phan, A.V., Le Nguyen, M., Nguyen, Y.L.H., Bui, L.T.: Dgcnn: A convolutional neural network over large-scale labeled graphs. Neural Networks108, 533–543 (2018)
2018
-
[25]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 652–660 (2017)
2017
-
[26]
Advances in neural information processing systems30(2017)
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learn- ing on point sets in a metric space. Advances in neural information processing systems30(2017)
2017
-
[27]
In: Proceedings of the International Conference on Machine Learning (2023)
Qi, Z., Dong, R., Fan, G., Ge, Z., Zhang, X., Ma, K., Yi, L.: Contrast with recon- struct: Contrastive 3d representation learning guided by generative pretraining. In: Proceedings of the International Conference on Machine Learning (2023)
2023
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sautier, C., Puy, G., Gidaris, S., Boulch, A., Bursuc, A., Marlet, R.: Image-to-lidar self-supervised distillation for autonomous driving data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9891– 9901 (2022)
2022
-
[29]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Uy, M.A., Pham, Q.H., Hua, B.S., Nguyen, T., Yeung, S.K.: Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1588–1597 (2019)
2019
-
[30]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Wang, H., Liu, Q., Yue, X., Lasenby, J., Kusner, M.J.: Unsupervised point cloud pre-training via occlusion completion. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 9782–9792 (2021)
2021
-
[31]
In: Proceedings of the European Conference on Computer Vision
Wang, H., Bao, Y., Pan, P., Li, Z., Liu, X., Yang, R., Huang, D.: Multi-modal relation distillation for unified 3D representation learning. In: Proceedings of the European Conference on Computer Vision. pp. 364–381 (2024) 18 Y. Xu et al
2024
-
[32]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wang, Y., Solomon, J.M.: Deep closest point: Learning representations for point cloud registration. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3522–3531 (2019)
2019
-
[33]
In: Proceedings of the European Conference on Computer Vision
Wu,W.,Wang,Z.Y.,Li,Z.,Liu,W.,Fuxin,L.:Pointpwc-net:Costvolumeonpoint clouds for (self-)supervised scene flow estimation. In: Proceedings of the European Conference on Computer Vision. pp. 88–107 (2020)
2020
-
[34]
In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition
Wu, X., Wen, X., Liu, X., Zhao, H.: Masked scene contrast: A scalable framework for unsupervised 3d representation learning. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 9415–9424 (2023)
2023
-
[35]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., Xiao, J.: 3d shapenets: A deep representation for volumetric shapes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1912–1920 (2015)
1912
-
[36]
In: European conference on computer vision
Xie, S., Gu, J., Guo, D., Qi, C.R., Guibas, L., Litany, O.: Pointcontrast: Unsuper- vised pre-training for 3d point cloud understanding. In: European conference on computer vision. pp. 574–591 (2020)
2020
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xue, L., Gao, M., Xing, C., Martín-Martín, R., Wu, J., Xiong, C., Xu, R., Niebles, J.C., Savarese, S.: Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1179–1189 (2023)
2023
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xue, L., Yu, N., Zhang, S., Panagopoulou, A., Li, J., Martín-Martín, R., Wu, J., Xiong, C., Xu, R., Niebles, J.C., et al.: Ulip-2: Towards scalable multimodal pre- training for 3d understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 27091–27101 (2024)
2024
-
[39]
IEEE/ASME Transactions on Mechatronics29(1), 625–635 (2023)
Yu, S., Zhai, D.H., Xia, Y.: Robotic grasp detection based on category-level ob- ject pose estimation with Self-Supervised learning. IEEE/ASME Transactions on Mechatronics29(1), 625–635 (2023)
2023
-
[40]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, X., Tang, L., Rao, Y., Huang, T., Zhou, J., Lu, J.: Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19291–19300 (2022)
2022
-
[41]
In: Proceedings of the AAAI conference on artificial intelligence
Zha, Y., Ji, H., Li, J., Li, R., Dai, T., Chen, B., Wang, Z., Xia, S.T.: Towards compact 3d representations via point feature enhancement masked autoencoders. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 6962– 6970 (2024)
2024
-
[42]
In: Advances in Neural Information Processing Systems
Zhang, R., Guo, Z., Fang, R., Zhao, B., Wang, D., Qiao, Y., Li, H., Gao, P.: Point- m2ae: Multi-scale masked autoencoders for hierarchical point cloud pre-training. In: Advances in Neural Information Processing Systems. vol. 35, pp. 27061–27074 (2022)
2022
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, R., Wang, L., Qiao, Y., Gao, P., Li, H.: Learning 3d representations from 2d pre-trained models via image-to-point masked autoencoders. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21769– 21780 (2023)
2023
-
[44]
In: Advances in Neural Information Processing Systems
Zhang, X., Zhang, S., Yan, J.: Pcp-mae: Learning to predict centers for point masked autoencoders. In: Advances in Neural Information Processing Systems. vol. 37, pp. 80303–80327 (2024)
2024
-
[45]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
Zhang, X., Zhang, S., Yan, J.: Towards more diverse and challenging pre-training for point cloud learning: Self-supervised cross reconstruction with decoupled views. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
2025
-
[46]
In: Proceedings of the International Conference on Learning Representations (2023)
Zhou, J., Wang, J., Ma, B., Liu, Y.S., Huang, T., Wang, X.: Uni3d: Exploring unified 3d representation at scale. In: Proceedings of the International Conference on Learning Representations (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.