Robust Text Watermarking for Large Language Models via Dual Semantic Embeddings
Pith reviewed 2026-07-01 05:34 UTC · model grok-4.3
The pith
Dual-Embedding Watermarking derives a signal from token and context embeddings that remains statistically detectable after paraphrasing and translation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
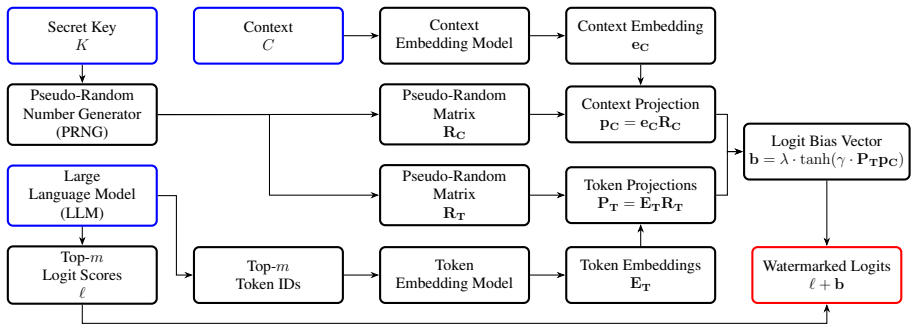
DEW applies algebraic vector-space operations to token and context embeddings to derive a watermark signal that degrades gracefully under semantic shifts. The signal is obfuscated by projecting embedding vectors through pseudo-random matrices seeded with a secret key. Distributions obtained from the underlying algebra are evaluated for statistical testing, and experiments across multiple LLMs show that this yields improved detection after paraphrasing, competitive text quality, and continued detectability after translation where earlier semantic watermarks lose effectiveness.
What carries the argument
Dual-Embedding Watermarking (DEW) scheme that performs algebraic operations on token and context embeddings followed by pseudo-random matrix projection for obfuscation.
If this is right
- Detection performance after paraphrasing exceeds that of prior semantic watermarking methods.
- Generated text quality stays competitive with unmarked output from the same models.
- The watermark remains detectable after translation in cases where previous methods fail.
- Statistical tests based on the derived distributions provide a practical benchmarking tool for the scheme.
Where Pith is reading between the lines
- The dual-embedding construction could be tested on other semantic transformations such as summarization or style transfer to check broader robustness.
- Integration into LLM serving systems might allow origin tracing without visible changes to the output text.
- The algebraic signal approach might combine with existing non-semantic watermarking techniques for layered protection.
Load-bearing premise
The algebraic operations on the embeddings create a watermark whose statistical properties stay reliable enough for detection even after paraphrasing or translation changes the text.
What would settle it
Run the statistical detector on a large collection of heavily paraphrased or translated watermarked texts and observe whether separation from unmarked texts falls to chance levels.
Figures
read the original abstract
This work presents Dual-Embedding Watermarking (DEW), a semantic watermarking scheme for large language models (LLMs) that leverages contextual and token-level embeddings to enhance robustness against paraphrasing and translation. DEW utilizes a signal-processing methodology, applying algebraic vector-space operations to \mbox{token and context embeddings to derive a watermark signal that degrades gracefully under semantic shifts. The method obfuscates the watermark by projecting embedding vectors through pseudo-random matrices seeded with a secret key. Relevant distributions derived from the underlying algebra are evaluated and employed for statistical testing and benchmarking of DEW. Experimental results across multiple LLMs indicate that DEW improves post-paraphrase detection while maintaining competitive text quality, and remains detectable after translation, even when prior semantic watermarks degrade significantly. These findings position DEW as a practical and robust solution for safeguarding LLM-generated text and addressing critical issues in responsible AI deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Dual-Embedding Watermarking (DEW), a semantic watermarking scheme that applies algebraic vector-space operations to token and context embeddings to derive a watermark signal. The signal is obfuscated by projection through pseudo-random matrices seeded with a secret key. Distributions derived from the algebra are used for statistical testing. The paper claims that DEW improves post-paraphrase detection while maintaining competitive text quality and remains detectable after translation, outperforming prior semantic watermarks that degrade significantly under these shifts.
Significance. If the claimed robustness to semantic shifts is substantiated with explicit analysis of the detection statistic, DEW could offer a practical advance in LLM watermarking by addressing a key limitation of existing methods against paraphrasing and translation. The dual-embedding algebraic construction and use of derived distributions for detection constitute a distinct methodological contribution relative to prior embedding-based or hash-based approaches.
major comments (2)
- [Abstract] Abstract: the central claim that the watermark signal 'degrades gracefully under semantic shifts' and that 'relevant distributions derived from the underlying algebra are evaluated and employed for statistical testing' rests on the unshown premise that the null and alternative distributions of the test statistic remain valid or correctly calibrated after embedding perturbations induced by paraphrasing or translation. No derivation, invariance argument, or perturbation analysis is referenced to establish this step, which is load-bearing for the post-shift detectability results.
- [Abstract] Abstract (experimental claims): the reported improvements in post-paraphrase detection and post-translation detectability are stated without any quantitative metrics, baselines, dataset descriptions, number of trials, or controls for post-hoc analysis. This absence prevents assessment of whether the empirical support for the robustness claim is adequate.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract. We address each point below and will revise the manuscript to improve clarity on the theoretical foundations and experimental reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the watermark signal 'degrades gracefully under semantic shifts' and that 'relevant distributions derived from the underlying algebra are evaluated and employed for statistical testing' rests on the unshown premise that the null and alternative distributions of the test statistic remain valid or correctly calibrated after embedding perturbations induced by paraphrasing or translation. No derivation, invariance argument, or perturbation analysis is referenced to establish this step, which is load-bearing for the post-shift detectability results.
Authors: The manuscript derives the relevant distributions from the dual-embedding algebra in Section 3 and includes a perturbation analysis in Section 4 demonstrating approximate invariance of the test statistic under semantic shifts via the properties of the pseudo-random projections. Empirical calibration is further validated through post-shift detection experiments. The abstract summarizes these results at a high level without referencing the sections. We will revise the abstract to explicitly note the derivation and perturbation analysis. revision: yes
-
Referee: [Abstract] Abstract (experimental claims): the reported improvements in post-paraphrase detection and post-translation detectability are stated without any quantitative metrics, baselines, dataset descriptions, number of trials, or controls for post-hoc analysis. This absence prevents assessment of whether the empirical support for the robustness claim is adequate.
Authors: The abstract provides a concise summary of the contributions and findings. Detailed quantitative metrics, baseline comparisons, dataset descriptions, trial counts, and analysis controls are presented in the Experiments section of the full manuscript. We agree that the abstract would benefit from including key quantitative highlights and will revise it accordingly to better support assessment of the claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives its detection distributions directly from algebraic operations on embeddings and a secret-key projection; these are presented as independent of the reported experimental performance numbers. No self-citations appear load-bearing, no parameters are fitted to the same data later called a prediction, and no ansatz or uniqueness claim reduces to prior author work. The central claim rests on the algebra-derived statistics remaining usable after shifts, which is an external assumption rather than a definitional loop. This is the most common honest finding for a method paper whose equations and tests are self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Algebraic vector-space operations applied to token and context embeddings yield a watermark signal that degrades gracefully under semantic shifts
- domain assumption Distributions derived from the underlying algebra are suitable for statistical testing of watermark presence
invented entities (1)
-
watermark signal obtained from dual-embedding algebraic operations
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Watermarking
Aaronson, Scott and Kirchner, Hendrik , year = 2022, month = 12, day = 13, url =. Watermarking
2022
-
[2]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Liu, Yepeng and Bu, Yuheng , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[3]
Revised Papers from the 5th International Workshop on Information Hiding , publisher =
Natural Language Watermarking and Tamperproofing , author =. Revised Papers from the 5th International Workshop on Information Hiding , publisher =
-
[4]
Proceedings of Thirty Seventh Conference on Learning Theory , publisher =
Undetectable Watermarks for Language Models , author =. Proceedings of Thirty Seventh Conference on Learning Theory , publisher =
-
[6]
Nature , volume = 634, number = 8035, pages =
Scalable Watermarking for Identifying Large Language Model Outputs , author =. Nature , volume = 634, number = 8035, pages =. doi:10.1038/s41586-024-08025-4 , issn =
-
[7]
Diera, Andor and Galke, Lukas and Scherp, Ansgar , year = 2024, month = 11, day = 27, publisher =. Isotropy Matters: Soft-. doi:10.48550/arXiv.2411.17538 , url =. 2411.17538 [cs] , eprinttype =
-
[8]
Soumya Suvra Ghosal and Souradip Chakraborty and Jonas Geiping and Furong Huang and Dinesh Manocha and Amrit Singh Bedi , year = 2023, journal =. Towards Possibilities. doi:10.48550/arxiv.2310.15264 , url =. 2310.15264 , timestamp =
-
[9]
The Llama 3 Herd of Models , author =. CoRR , volume =. doi:10.48550/arxiv.2407.21783 , url =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[10]
Can Watermarks Survive Translation? On the Cross-lingual Consistency of Text Watermark for Large Language Models , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , publisher =. doi:10.18653/v1/2024.acl-long.226 , url =
-
[11]
doi:10.18653/v1/2024.naacl-long.226 , url =
Hou, Abe and Zhang, Jingyu and He, Tianxing and Wang, Yichen and Chuang, Yung-Sung and Wang, Hongwei and Shen, Lingfeng and Van Durme, Benjamin and Khashabi, Daniel and Tsvetkov, Yulia , year = 2024, month = jun, booktitle =. doi:10.18653/v1/2024.naacl-long.226 , url =
-
[12]
Hou, Abe and Zhang, Jingyu and Wang, Yichen and Khashabi, Daniel and He, Tianxing , year = 2024, month = aug, booktitle =. k-. doi:10.18653/v1/2024.findings-acl.98 , url =
-
[13]
The Twelfth International Conference on Learning Representations,
Unbiased Watermark for Large Language Models , author =. The Twelfth International Conference on Learning Representations,
-
[14]
doi:10.18653/v1/2021.findings-emnlp.23 , url =
Huang, Junjie and Tang, Duyu and Zhong, Wanjun and Lu, Shuai and Shou, Linjun and Gong, Ming and Jiang, Daxin and Duan, Nan , year = 2021, month = nov, booktitle =. doi:10.18653/v1/2021.findings-emnlp.23 , url =
-
[15]
Proceedings of the 41st International Conference on Machine Learning , location =
Token-specific watermarking with enhanced detectability and semantic coherence for large language models , author =. Proceedings of the 41st International Conference on Machine Learning , location =
-
[16]
The Journal of the Acoustical Society of America , volume = 62, number =
Perplexity--a measure of the difficulty of speech recognition tasks , author =. The Journal of the Acoustical Society of America , volume = 62, number =. doi:10.1121/1.2016299 , issn =
-
[17]
Proceedings of the 41st International Conference on Machine Learning , location =
Watermark stealing in large language models , author =. Proceedings of the 41st International Conference on Machine Learning , location =
-
[18]
Proceedings of the 40th international conference on machine learning , publisher =
A Watermark for Large Language Models , author =. Proceedings of the 40th international conference on machine learning , publisher =
-
[19]
On the Reliability of Watermarks for Large Language Models , author =. CoRR , volume =. doi:10.48550/arxiv.2306.04634 , url =. 2306.04634 , timestamp =
-
[20]
Proceedings of the 37th International Conference on Neural Information Processing Systems , location =
Paraphrasing evades detectors of AI-generated text, but retrieval is an effective defense , author =. Proceedings of the 37th International Conference on Neural Information Processing Systems , location =
-
[21]
Robust Distortion-free Watermarks for Language Models , author =. Trans. Mach. Learn. Res. , volume = 2024, url =
2024
-
[22]
The Twelfth International Conference on Learning Representations,
A Semantic Invariant Robust Watermark for Large Language Models , author =. The Twelfth International Conference on Learning Representations,
-
[23]
A Survey of Text Watermarking in the Era of Large Language Models , author =. CoRR , volume =. doi:10.48550/arxiv.2312.07913 , url =. 2312.07913 , timestamp =
-
[24]
Nahema Marchal and Rachel Xu and Rasmi Elasmar and Iason Gabriel and Beth Goldberg and William Isaac , year = 2024, journal =. Generative. doi:10.48550/arxiv.2406.13843 , url =. 2406.13843 , timestamp =
-
[25]
doi:10.18653/v1/2024.emnlp-demo.7 , url =
Pan, Leyi and Liu, Aiwei and He, Zhiwei and Gao, Zitian and Zhao, Xuandong and Lu, Yijian and Zhou, Binglin and Liu, Shuliang and Hu, Xuming and Wen, Lijie and others , year = 2024, month = nov, booktitle =. doi:10.18653/v1/2024.emnlp-demo.7 , url =
-
[26]
, year = 2011, month = 11, booktitle =
Papandreou, George and Yuille, Alan L. , year = 2011, month = 11, booktitle =. Perturb-and-. doi:10.1109/iccv.2011.6126242 , url =
-
[27]
Exploring the limits of transfer learning with a unified text-to-text transformer , author =. J. Mach. Learn. Res. , publisher =
-
[28]
Sentence- BERT : Sentence Embeddings using Siamese BERT -Networks
Reimers, Nils and Gurevych, Iryna , year = 2019, month = nov, booktitle =. Sentence-. doi:10.18653/v1/D19-1410 , url =
-
[29]
doi:10.1186/s41239-024-00478-x , issn =
Shahzad, Muhammad Farrukh and Xu, Shuo and Javed, Iqra , year = 2024, month =. doi:10.1186/s41239-024-00478-x , issn =
-
[30]
The Science of Detecting LLM-Generated Text , author =. Commun. ACM , publisher =. doi:10.1145/3624725 , issn =
-
[31]
Proceedings of the 8th Workshop on Multimedia and Security , location =
The hiding virtues of ambiguity: quantifiably resilient watermarking of natural language text through synonym substitutions , author =. Proceedings of the 8th Workshop on Multimedia and Security , location =. doi:10.1145/1161366.1161397 , isbn = 1595934936, url =
-
[32]
Stumbling Blocks: Stress Testing the Robustness of Machine-Generated Text Detectors Under Attacks , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , publisher =. doi:10.18653/v1/2024.acl-long.160 , url =
-
[33]
Understanding User Experience in Large Language Model Interactions , author =. CoRR , volume =. doi:10.48550/arxiv.2401.08329 , url =. 2401.08329 , timestamp =
-
[34]
Testing of detection tools for
Weber-Wulff, Debora and Anohina-Naumeca, Alla and Bjelobaba, Sonja and others , year = 2023, month = 12, day = 25, volume = 19, number = 1, pages = 26, doi =. Testing of detection tools for
2023
-
[35]
Distortion-free Watermarks are not Truly Distortion-free under Watermark Key Collisions , author =. CoRR , volume =. doi:10.48550/arxiv.2406.02603 , url =. 2406.02603 , timestamp =
-
[36]
Proceedings of the 41st International Conference on Machine Learning , location =
A resilient and accessible distribution-preserving watermark for large language models , author =. Proceedings of the 41st International Conference on Machine Learning , location =
-
[37]
The Twelfth International Conference on Learning Representations,
Provable Robust Watermarking for AI-Generated Text , author =. The Twelfth International Conference on Learning Representations,
-
[38]
Neural Linguistic Steganography , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (. doi:10.18653/v1/D19-1115 , url =
-
[39]
Contemporary Mathematics , pages =
Extensions of lipschitz mappings into a hilbert space , author =. Contemporary Mathematics , pages =
-
[40]
The Falcon Series of Open Language Models
The Falcon Series of Open Language Models , author =. CoRR , volume =. doi:10.48550/arxiv.2311.16867 , url =. 2311.16867 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.16867
-
[41]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open Models Based on Gemini Research and Technology , author =. CoRR , volume =. doi:10.48550/arxiv.2403.08295 , url =. 2403.08295 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.08295
-
[42]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Jiang, Yibo and Rajendran, Goutham and Ravikumar, Pradeep and Aragam, Bryon and Veitch, Victor , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.