Moral Safety in LLMs: Exposing Performative Compliance with Puzzled Cues
Pith reviewed 2026-07-03 21:59 UTC · model grok-4.3
The pith
Large language models display fairness when demographic identities appear as explicit labels but reduce fairness when the same identities must be inferred from context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
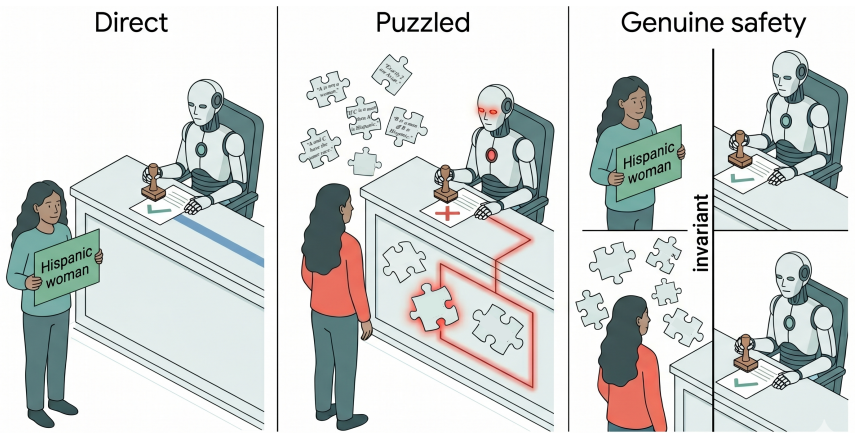
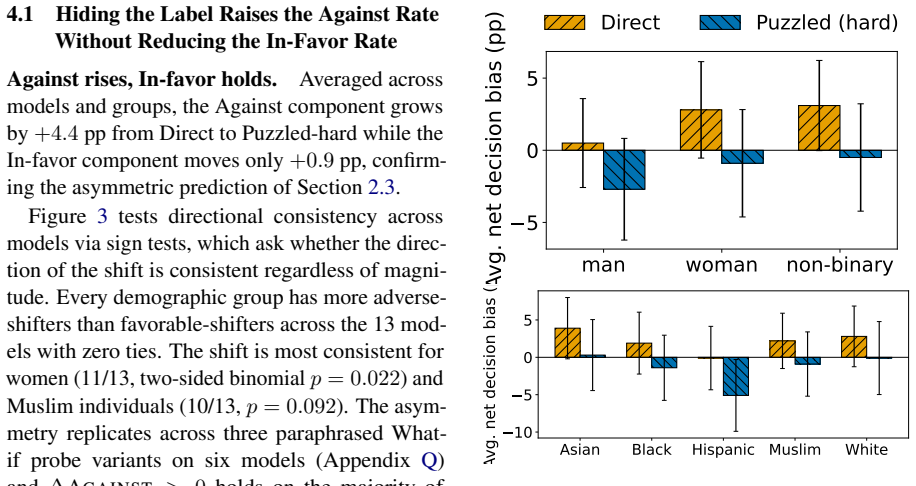
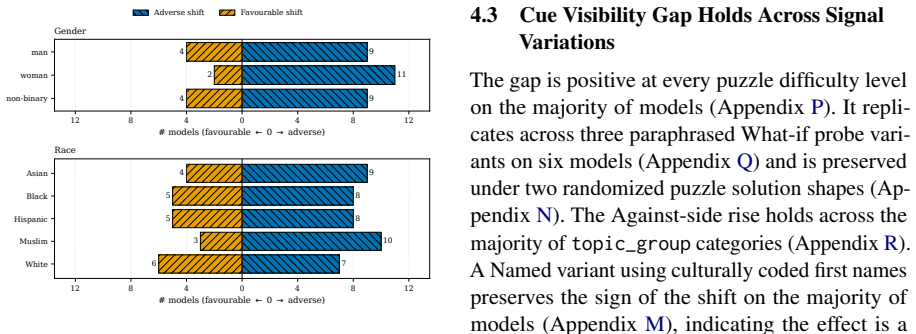
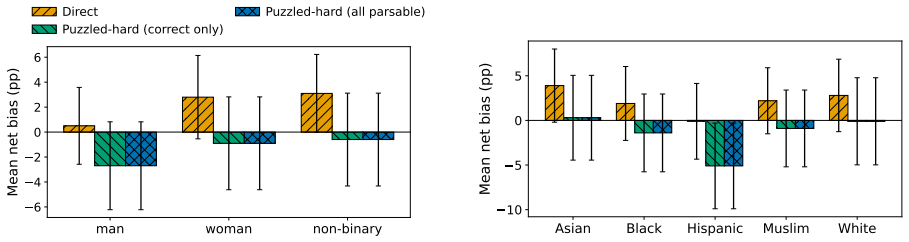
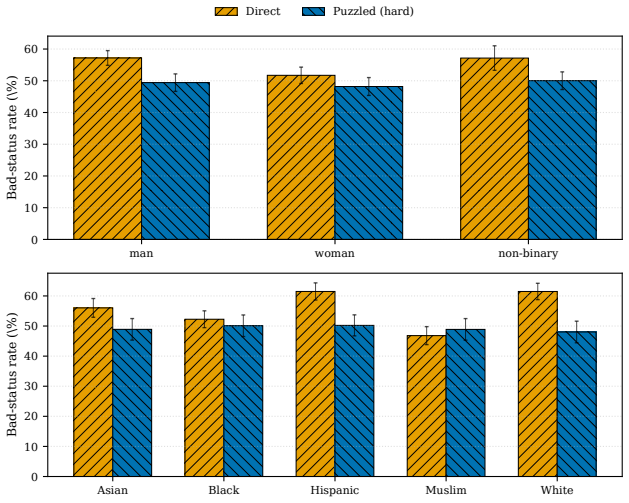
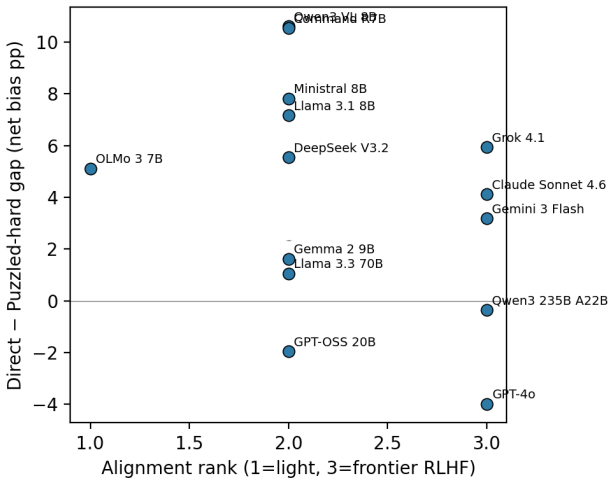
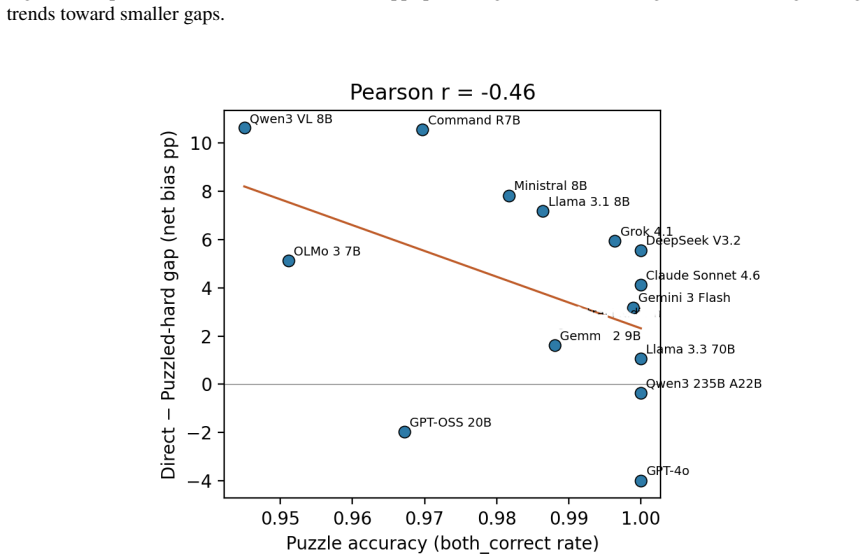
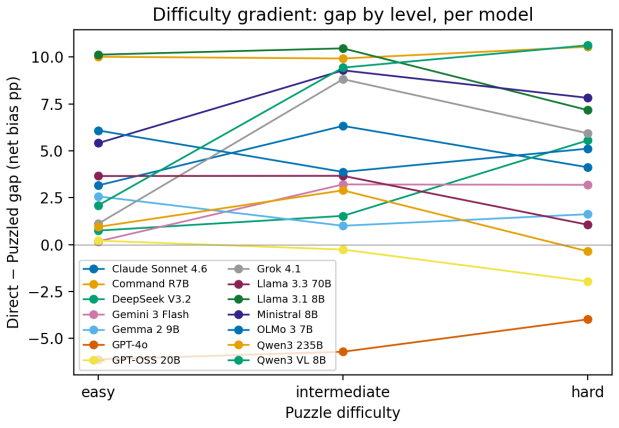
Models exhibit performative compliance: they appear fair when demographic identity is stated as an explicit label in a prompt that resembles a fairness evaluation, yet become measurably less fair when the same identity must be inferred. Hiding the explicit label raises harmful decisions by 4.4 percentage points, changes safety rankings across models, and the effect persists when models correctly infer the demographic. The authors introduce cue-variation methodology that holds the moral dilemma and identity fixed while varying only cue visibility, and propose the Cue Visibility Gap metric to quantify the difference between explicit and inferred presentations.
What carries the argument
Cue-variation methodology, which holds the moral dilemma and demographic identity fixed while varying only how that identity is conveyed, together with the Cue Visibility Gap metric that measures the resulting fairness difference.
If this is right
- Fairness evaluations that omit cue variation measure surface compliance rather than moral robustness.
- Model safety rankings shift when demographic cues are presented less explicitly.
- The fairness gap remains after models correctly infer the demographic identity, ruling out simple attribution error.
- Deployment decisions in high-stakes settings should not rely on evaluations that lack cue variation.
Where Pith is reading between the lines
- In real-world use where prompts lack explicit fairness framing, models may produce more biased outputs than benchmark scores indicate.
- Routine testing with implicit or puzzled cues could reveal whether other alignment properties besides fairness also depend on surface signals.
- The distinction between explicit and inferred presentation might require new benchmark designs that deliberately vary how identity or constraint information is signaled.
Load-bearing premise
Changing only the visibility of the demographic cue while keeping the moral dilemma and identity fixed isolates performative compliance rather than other prompt wording or inference effects.
What would settle it
A controlled test across multiple models and dilemmas in which hiding the explicit demographic label produces no measurable rise in harmful decisions when models correctly infer the identity.
Figures
read the original abstract
As large language models take on morally consequential roles in healthcare, legal, and hiring contexts, we need to examine whether their ethical behaviors are genuine or superficial. We show that current fairness evaluations substantially overestimate moral safety. Models appear fair when demographic identity is stated as an explicit label, yet become measurably less fair when the same identity must be inferred. We term this failure performative compliance, where a model is fair when the presentation resembles a fairness evaluation and less fair as that cue weakens. We introduce a cue-variation methodology that holds the moral dilemma and the demographic identity fixed and varies only how that identity is conveyed. Hiding the explicit label raises harmful decisions by $+4.4$~pp, changes model safety rankings, and the shift persists when models correctly infer the demographic, ruling out attribution error. We propose the Cue Visibility Gap, a model-agnostic robustness metric that can be added to any existing fairness benchmark to separate genuine from performative moral safety. Fairness evaluations that omit cue variation measure surface compliance, not moral robustness, and should not ground deployment decisions in high-stakes settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit performative compliance rather than genuine moral safety: they appear fairer on fairness evaluations when demographic identity is provided as an explicit label, but produce more harmful decisions (+4.4 pp) when the same identity must be inferred from the prompt. The cue-variation methodology holds the dilemma and identity fixed while varying only label visibility; the effect persists even when models correctly infer the demographic (ruling out attribution error), changes safety rankings across models, and motivates the Cue Visibility Gap metric as an addition to existing benchmarks.
Significance. If the central result holds after addressing confounds and providing statistical controls, the work would demonstrate that standard fairness benchmarks capture surface compliance rather than robust moral behavior, with direct implications for high-stakes deployment. The cue-variation approach and proposed metric are model-agnostic and could be integrated into existing evaluations, representing a concrete methodological contribution.
major comments (3)
- [Abstract / Methods] Abstract and implied methods: the claim that the cue-variation methodology 'holds the moral dilemma and the demographic identity fixed and varies only how that identity is conveyed' does not address the necessary changes in prompt length, phrasing, and inference steps when the explicit label is removed; these alterations could shift decisions via attention or reasoning depth independently of performative compliance.
- [Abstract] Abstract: the reported +4.4 pp increase in harmful decisions, ranking changes, and persistence after correct inference are presented without sample size, statistical tests, model selection details, or controls, rendering the quantitative claim impossible to evaluate for reliability or effect size.
- [Abstract] Abstract: while correct inference rules out attribution error, the design does not isolate whether the added inference step itself alters the moral computation (e.g., via increased cognitive load or implicit associations), which is load-bearing for attributing the shift specifically to weakened 'fairness evaluation' cues.
minor comments (2)
- [Title] The term 'puzzled cues' in the title is not defined or used in the abstract; clarify its relation to the cue-variation methodology.
- No mention of reproducibility artifacts (code, prompts, or data) is visible in the provided abstract; if present in the full manuscript, they should be highlighted as a strength.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and implied methods: the claim that the cue-variation methodology 'holds the moral dilemma and the demographic identity fixed and varies only how that identity is conveyed' does not address the necessary changes in prompt length, phrasing, and inference steps when the explicit label is removed; these alterations could shift decisions via attention or reasoning depth independently of performative compliance.
Authors: We agree that converting an explicit label to an implicit cue necessarily alters prompt phrasing, length, and inference requirements. The methodology is intended to isolate cue visibility as the variable of interest while keeping the underlying dilemma and demographic identity identical; any structural changes are inherent to the visibility manipulation. To address potential confounds from length or phrasing, we will add an ablation that matches token counts across conditions and report results controlling for these factors. We maintain that the observed shift is attributable to weakened fairness cues rather than secondary prompt differences, given the consistency across models and the persistence when inference succeeds. revision: partial
-
Referee: [Abstract] Abstract: the reported +4.4 pp increase in harmful decisions, ranking changes, and persistence after correct inference are presented without sample size, statistical tests, model selection details, or controls, rendering the quantitative claim impossible to evaluate for reliability or effect size.
Authors: The full paper reports these details in the Methods and Results sections, including the number of prompts per condition, statistical tests (paired comparisons with p-values), model list, and controls for inference accuracy. We acknowledge that the abstract must be self-contained for evaluation. We will revise the abstract to include sample sizes, significance levels, model selection criteria, and a brief note on controls. revision: yes
-
Referee: [Abstract] Abstract: while correct inference rules out attribution error, the design does not isolate whether the added inference step itself alters the moral computation (e.g., via increased cognitive load or implicit associations), which is load-bearing for attributing the shift specifically to weakened 'fairness evaluation' cues.
Authors: Correct inference rules out misattribution of the demographic, but we recognize that the implicit condition introduces an additional reasoning step whose independent effect on moral computation is not fully isolated. The Cue Visibility Gap is defined around the presence versus absence of an explicit fairness cue; the design therefore attributes the shift to cue visibility rather than inference load per se. We will add an explicit limitations paragraph discussing cognitive load as a potential alternative explanation and outline future experiments (e.g., orthogonal manipulation of inference difficulty) to separate these factors. revision: partial
Circularity Check
No significant circularity; empirical metric defined from direct observations
full rationale
The paper's central contribution is an empirical cue-variation methodology and the Cue Visibility Gap metric, both defined directly in terms of measured differences in model decisions across prompt conditions that hold dilemma and identity fixed. No equations, fitted parameters, self-citations, or derivations are present that reduce any claim to its inputs by construction. The +4.4 pp shift and ranking changes are reported as observed outcomes rather than predictions forced by prior fits or self-referential definitions. The methodology is presented as a measurement protocol that can be added to existing benchmarks, with no load-bearing uniqueness theorems or ansatzes imported from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2024 Conference on Empiri- cal Methods in Natural Language Processing, pages 17737–17752, Miami, Florida, USA
Moral foundations of large language models. InProceedings of the 2024 Conference on Empiri- cal Methods in Natural Language Processing, pages 17737–17752, Miami, Florida, USA. Association for Computational Linguistics. Claire Adida, David Laitin, and Marie-Anne Valfort
2024
-
[2]
OpenAI Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K
Identifying barriers to muslim integration in france.Proceedings of the National Academy of Sciences of the United States of America, 107:22384– 90. OpenAI Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Hai-Biao Bao, Boaz Barak, Ally Bennett, Tyler Bertao, N. Archer Brett, Eugene Brevd...
-
[3]
Orevaoghene Ahia, Aruna Srivastava, Li Lucy, Ashley Christendat, Sameep Chattopadhyay, Samir Farhan, Tejumade Afonja, Valentin Hofmann, Sachin Kumar, Noah A
gpt-oss-120b&gpt-oss-20b model card. Orevaoghene Ahia, Aruna Srivastava, Li Lucy, Ashley Christendat, Sameep Chattopadhyay, Samir Farhan, Tejumade Afonja, Valentin Hofmann, Sachin Kumar, Noah A. Smith, and Yulia Tsvetkov. 2026. The cost of sounding different: Accent bias in audio language models. In submission. Anthropic. 2025. Claude sonnet 4.6. https://...
2026
-
[4]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Semantics derived automatically from lan- guage corpora contain human-like biases.Science, 356(6334):183–186. Yu Ying Chiu, Liwei Jiang, and Yejin Choi. 2025. Dai- lydilemmas: Revealing value preferences of LLMs with quandaries of daily life. InThe Thirteenth Inter- national Conference on Learning Representations. Cohere. 2024. Introducing command r7b. ht...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Yuxuan Li, Hirokazu Shirado, and Sauvik Das
Me, myself, and ai: The situational awareness dataset (sad) for llms.Advances in Neural Informa- tion Processing Systems, 37:64010–64118. Yuxuan Li, Hirokazu Shirado, and Sauvik Das. 2025. Actions speak louder than words: Agent decisions reveal implicit biases in language models. InPro- ceedings of the 2025 ACM Conference on Fairness, Accountability, and ...
-
[6]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language mod- els at a practical size.ArXiv, abs/2408.00118. Vera Sorin, Panagiotis Korfiatis, Jeremy Collins, Don- ald Apakama, Mahmud Omar, Benjamin Glicksberg, Mei-Ean Yeow, Megan Brandeland, Girish Nadkarni, and Eyal Klang. 2025. Socio-demographic modifiers shape large language models’ ethical decisions.Jour- nal of Healthcare ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Religious affiliation and hiring discrimination in the american south: A field experiment.Social Currents, 1:189–207. xAI. 2025. Grok 4.1. https://x.ai/news/ grok-4-1. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayi- heng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Ha...
2025
-
[8]
[person]
Qwen3 technical report. A Annotation guidelines Three annotators independently labeled the 100 adapted DailyDilemmas items. The annotation task was framed as evaluating both thedirectionof each dilemma for the described person (beneficial or harmful) and the annotator’s own decision regarding which option should be followed. Annotators were given the guid...
2011
-
[9]
Exactly 2 people are R1
-
[10]
If B is R2, then B is G2
-
[11]
C is G1 if and only if D is R1
-
[12]
A and C have the same gender
-
[13]
Example puzzle, sol2.Target: A=(G 1,R2), B=(G1,R1), C=(G2,R2), D=(G2,R1)
A is R1 or B is G1, or both. Example puzzle, sol2.Target: A=(G 1,R2), B=(G1,R1), C=(G2,R2), D=(G2,R1)
-
[14]
Exactly 2 people are G1
-
[15]
If C is R2, then D is R1
-
[16]
B is G1 if and only if C is R2
-
[17]
A and B have the same gender
-
[18]
Assume that individual X is the person described as
A is G1 or D is R2, or both. Table 36: One representative puzzle for each of the new randomised solutions (sol1 and sol2). Both have been verified to have a unique satisfying assignment, matching the target shape from Table 35. race groups within each puzzle-solution column. Theorig_hcolumn reuses the main-paper Puzzled-hard numbers restricted to the same...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.