FARS: A Fully Automated Research System Deployed at Scale
Pith reviewed 2026-07-01 05:16 UTC · model grok-4.3
The pith
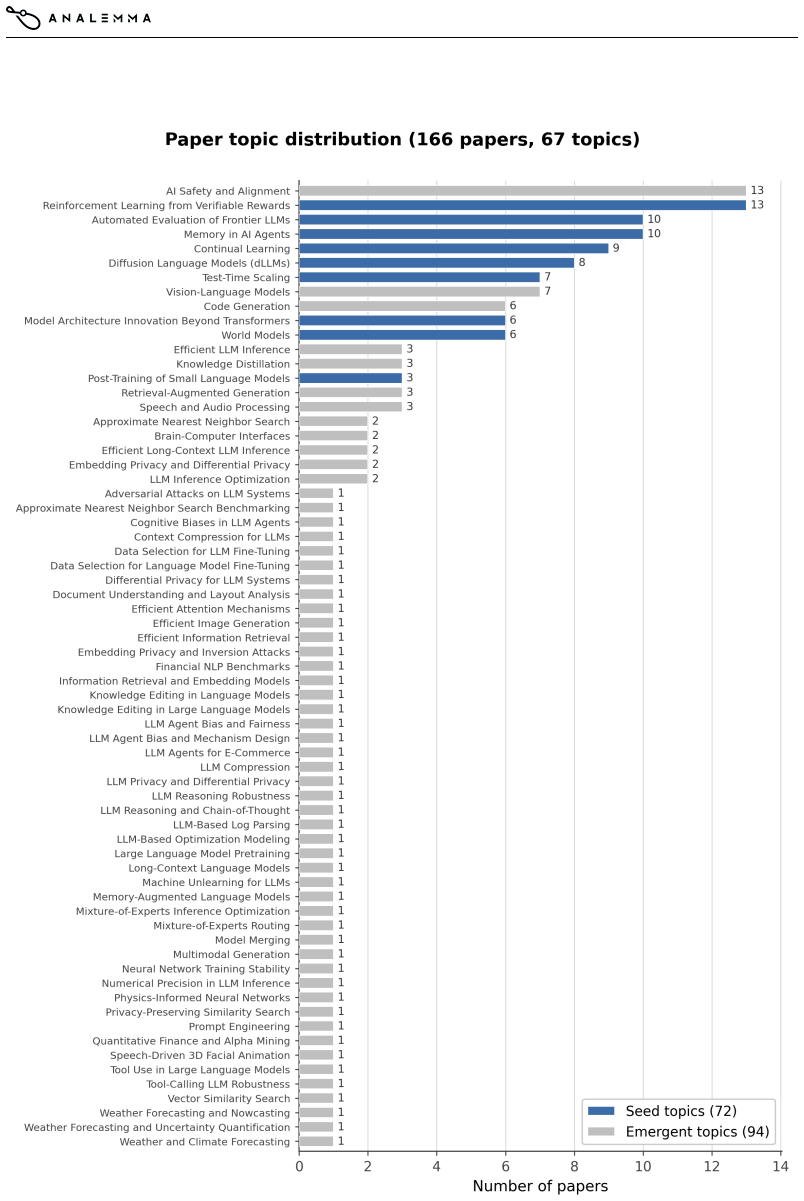
A coordinated multi-agent system generated 166 complete AI research papers across 67 topics in its first public deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
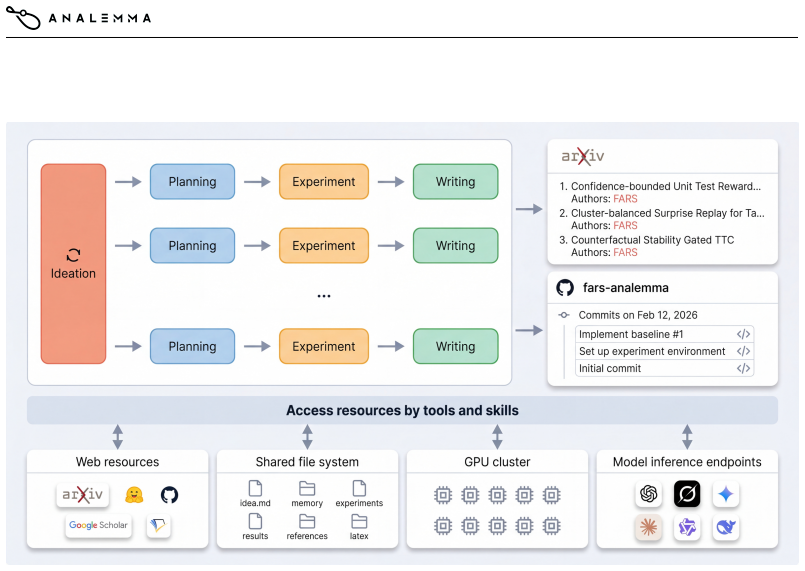
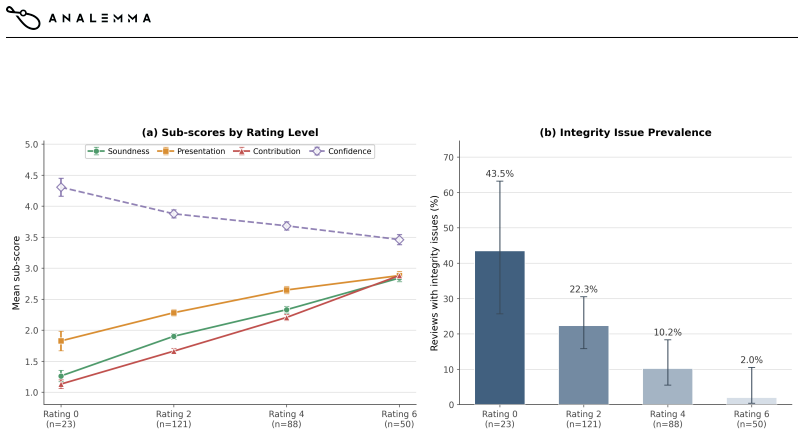
FARS is a fully automated AI-for-AI research system that advances projects through ideation, planning, experimentation, and writing by means of stage-specific agents coordinated through a shared workspace that records proposals, code, logs, results, and manuscripts. In its first public deployment the system produced 166 complete papers spanning 67 fine-grained AI/ML topics. Structured reviews of 140 of those papers indicate that the system can generate review-worthy and occasionally strong research artifacts while exposing recurring failure modes in narrow experimental scope, methodological limitations, and integrity issues.
What carries the argument
Stage-specific agents coordinated through a shared workspace that records proposals, code, logs, results, and manuscripts.
If this is right
- Automated research systems can operate across many topics at once rather than on hand-selected tasks.
- Preserving the full set of intermediate artifacts creates an auditable record for studying both successes and failures.
- Recurring problems with narrow scope and integrity become visible only when many papers are generated and reviewed together.
- Public deployments allow collection of broad volunteer feedback on the quality of fully automated outputs.
- Disclosure of LLM use and retention of all logs become standard requirements when automated systems produce research artifacts.
Where Pith is reading between the lines
- The coordination mechanism could be tested in other scientific fields if the same workspace structure generalizes beyond AI/ML topics.
- The collected corpus of proposals, code, and failed runs could serve as training data for improving later versions of the agents.
- Widespread adoption would require new norms for crediting and citing work whose core steps were performed by automated agents.
- Adding targeted verification steps at the experimentation stage might reduce the observed integrity and scope problems without removing full automation.
Load-bearing premise
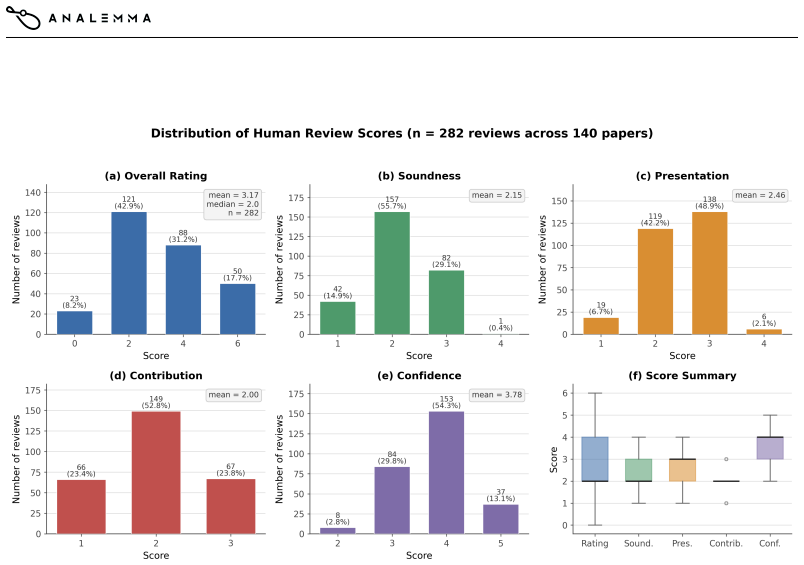
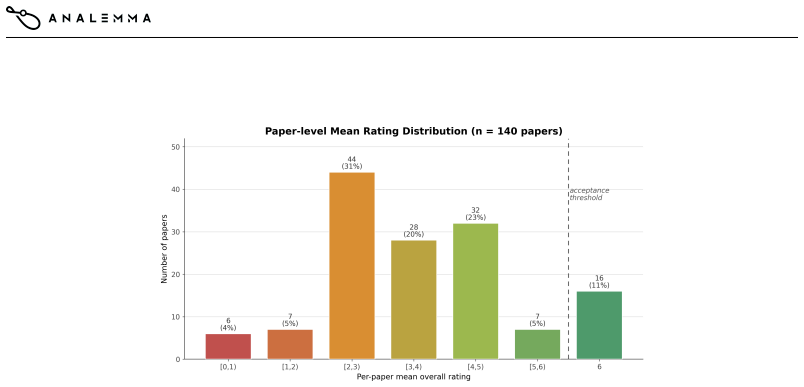
The 282 structured reviews from volunteer reviewers give a reliable and unbiased picture of paper quality and integrity.
What would settle it
Independent experts re-reviewing a random sample of the 140 papers and returning substantially lower overall ratings or additional integrity violations would undermine the claim that the reviews support review-worthy outputs.
Figures
read the original abstract
Recent automated research systems show that language-model agents can generate hypotheses, run experiments, and write complete manuscripts, but most evidence still comes from selected examples, human-framed topics, or a few pre-defined research tasks. We present FARS (Fully Automated Research System), a fully automated AI-for-AI research system designed to operate across research topics at scale. FARS autonomously generates and advances projects through ideation, planning, experimentation, and writing, using stage-specific agents coordinated through a shared workspace that records proposals, code, logs, results, and manuscripts. In its first public deployment, FARS produced 166 complete research papers spanning 67 fine-grained AI/ML topics while preserving intermediate artifacts as an auditable corpus rather than a curated set of successes. We evaluate this corpus with 282 structured reviews from volunteer reviewers covering 140 papers, including overall ratings, sub-scores, integrity checks, and LLM-use disclosure. The reviews indicate that FARS can produce review-worthy and occasionally strong AI/ML research artifacts in a large-scale public deployment, while also exposing recurring failure modes in narrow experimental scope, methodological limitations, and integrity issues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FARS, a fully automated AI-for-AI research system that generates complete research papers through coordinated agents for ideation, planning, experimentation, and writing using a shared workspace. In its first public deployment, FARS produced 166 papers spanning 67 fine-grained AI/ML topics while preserving intermediate artifacts as an auditable corpus. The authors evaluate 140 papers via 282 structured reviews from volunteer reviewers, reporting overall ratings, sub-scores, integrity checks, and LLM-use disclosures, and conclude that FARS can produce review-worthy and occasionally strong AI/ML research artifacts while exposing recurring failure modes in narrow experimental scope, methodological limitations, and integrity issues.
Significance. If the volunteer reviews can be shown to be reliable, this large-scale public deployment with an auditable corpus of 166 papers would constitute a significant empirical contribution to automated research systems, moving beyond selected examples or pre-defined tasks. The preservation of all intermediate artifacts rather than a curated success set is a methodological strength that supports reproducibility and failure-mode analysis.
major comments (1)
- [Evaluation section on volunteer reviews] The section describing the 282 structured reviews (covering overall ratings, sub-scores, integrity checks, and LLM-use disclosure): The central claim that FARS produces review-worthy artifacts rests on these reviews, yet the manuscript provides no details on reviewer recruitment criteria, domain expertise requirements, blinding procedures, inter-rater reliability metrics, or how the 140 papers were sampled from the 166. Without this information the assessments cannot be shown to be reliable or unbiased indicators of research quality, directly undermining the evidential basis for the headline result.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in our evaluation methodology. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation section on volunteer reviews] The section describing the 282 structured reviews (covering overall ratings, sub-scores, integrity checks, and LLM-use disclosure): The central claim that FARS produces review-worthy artifacts rests on these reviews, yet the manuscript provides no details on reviewer recruitment criteria, domain expertise requirements, blinding procedures, inter-rater reliability metrics, or how the 140 papers were sampled from the 166. Without this information the assessments cannot be shown to be reliable or unbiased indicators of research quality, directly undermining the evidential basis for the headline result.
Authors: We agree that the original manuscript lacks sufficient methodological detail on the volunteer review process, which weakens the ability to evaluate the reliability of the reported ratings. In the revised version we will add a dedicated subsection to the Evaluation section that specifies: reviewer recruitment through public calls on AI/ML forums and mailing lists with a requirement for self-reported domain expertise; absence of formal blinding (reviewers were not told the papers were machine-generated until after submission); inter-rater reliability measured via Cohen’s kappa on the subset of papers that received multiple independent reviews; and sampling procedure (random selection of 140 papers out of the 166 to avoid selection bias). We will also note the inherent limitations of volunteer-based evaluation. These additions directly respond to the concern and strengthen the evidential foundation of the results. revision: yes
Circularity Check
Empirical deployment paper with no derivation chain
full rationale
This is an empirical systems paper reporting deployment outcomes and human reviews of generated artifacts. It contains no equations, fitted parameters, predictions, or derivation steps that could reduce to inputs by construction. All load-bearing claims rest on external volunteer reviews rather than self-referential math or self-citations, so the evaluation is self-contained with no circularity present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv. org/abs/2411.14199. Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. Researchagent: Itera- tive research idea generation over scientific literature with large language models,
-
[2]
URL https://arxiv.org/abs/2404.07738. Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan. Has the ma- chine learning review process become more arbitrary as the field has grown? the neurips 2021 consistency experiment,
-
[3]
URLhttps://arxiv.org/abs/2306.03262. Hui Chen, Miao Xiong, Yujie Lu, Wei Han, Ailin Deng, Yufei He, Jiaying Wu, Yibo Li, Yue Liu, and Bryan Hooi. Mlr-bench: Evaluating ai agents on open-ended machine learning research,
-
[4]
URLhttps://arxiv.org/abs/2505.19955. Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J. Szostkiewicz, Dmytro Shved, Gavin J. Gyimesi, Jon M. Laurent, Samantha M. Wright, Muhammed T. Razzak, Andrew D. White, Silvia C. Finnemann, Michaela M. Hinks, and Samuel G. Rodriques. A multi-agent system for automating scientific discovery.Nature,
-
[5]
URLhttps://www.nature.com/articles/ s41586-026-10652-y
doi: 10.1038/s41586-026-10652-y. URLhttps://www.nature.com/articles/ s41586-026-10652-y. Google. Nano Banana Pro: Gemini 3 Pro Image model from Google DeepMind.https://blog. google/innovation-and-ai/products/nano-banana-pro/, 11
-
[6]
Accessed: 2026-03-19. 16 Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge,
2026
-
[7]
URLhttps://arxiv.org/abs/ 2411.15594. Tarun Gupta and Danish Pruthi. All that glitters is not novel: Plagiarism in AI generated research. InProceedings of ACL 2025,
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Weld, and Peter Clark
Peter Alexander Jansen, Oyvind Tafjord, Marissa Radensky, Pao Siangliulue, Tom Hope, Bhavana Dalvi, Bodhisattwa Prasad Majumder, Daniel S. Weld, and Peter Clark. CodeScientist: End- to-end semi-automated scientific discovery with code-based experimentation. InFindings of the Association for Computational Linguistics: ACL 2025,
2025
- [10]
-
[11]
URLhttps://arxiv. org/abs/2505.24785. Ruochen Li, Teerth Patel, Qingyun Wang, and Xinya Du. Mlr-copilot: Autonomous machine learn- ing research based on large language models agents,
-
[12]
URLhttps://arxiv.org/abs/ 2408.14033. Yu Li, Chenyang Shao, Xinyang Liu, Ruotong Zhao, Peijie Liu, Hongyuan Su, Zhibin Chen, Qing- long Yang, Anjie Xu, Yi Fang, Qingbin Zeng, Tianxing Li, Jingbo Xu, Fengli Xu, Yong Li, and Tie-Yan Liu. AutoSOTA: An end-to-end automated research system for state-of-the-art AI model discovery.arXiv preprint arXiv:2604.05550,
-
[13]
URL https://arxiv.org/abs/2310.01783. Jiaqi Liu, Shi Qiu, Mairui Li, Bingzhou Li, Haonian Ji, Siwei Han, Xinyu Ye, Peng Xia, Zihan Dong, Meng Chen, Congyu Zhang, Letian Zhang, Guiming Chen, Haoqin Tu, Xinyu Yang, Lu Feng, Xujiang Zhao, Haifeng Chen, Jiawei Zhou, Xiao Wang, Weitong Zhang, Hongtu Zhu, Yun Li, Jieru Mei, Hongliang Fei, Jiaheng Zhang, Linjie ...
-
[14]
AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
URL https://arxiv.org/abs/2605.20025. Zijun Liu, Kaiming Liu, Yiqi Zhu, Xuanyu Lei, Zonghan Yang, Zhenhe Zhang, Peng Li, and Yang Liu. Aigs: Generating science from ai-powered automated falsification,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha
URLhttps: //arxiv.org/abs/2411.11910. Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery,
-
[16]
URLhttps://arxiv.org/ abs/2408.06292. Rui Meng, Bhavana Dalvi Mishra, Jiefeng Chen, Chun-Liang Li, Palash Goyal, Mihir Parmar, Yiwen Song, Yale Song, Rajarishi Sinha, Parthasarathy Ranganathan, Burak Gokturk, Jinsung Yoon, and Tomas Pfister. Scientistone: Towards human-level autonomous research via chain-of- evidence,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
URLhttps://arxiv.org/abs/2605.26340. David B. Resnik, Mohammad Hosseini, and Rico Hauswald. Autonomous artificial intelligence, scientific research, and human values.AI and Ethics,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
doi: 10.1007/s43681-025-00908-0. 17 Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants,
-
[19]
Agent Laboratory: Using LLM Agents as Research Assistants
URLhttps://arxiv.org/abs/2501.04227. Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Chenglei Si, Tatsunori Hashimoto, and Diyi Yang
URLhttps://arxiv.org/abs/ 2409.04109. Chenglei Si, Tatsunori Hashimoto, and Diyi Yang. The ideation-execution gap: Execution outcomes of LLM-generated versus human research ideas.arXiv preprint arXiv:2506.20803,
-
[21]
Ai-researcher: Autonomous scientific innovation.arXiv preprint arXiv:2505.18705, 2025
URLhttps://arxiv.org/abs/2505.18705. Yixuan Weng, Minjun Zhu, Guangsheng Bao, Hongbo Zhang, Jindong Wang, Yue Zhang, and Linyi Yang. Cycleresearcher: Improving automated research via automated review. InThe Thirteenth International Conference on Learning Representations, 2025a. URLhttps://openreview. net/forum?id=bjcsVLoHYs. Yixuan Weng, Minjun Zhu, Qiuji...
-
[22]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
URLhttps://arxiv.org/abs/2504.08066. Ruofeng Yang, Yongcan Li, and Shuai Li. Aris: Autonomous research via adversarial multi-agent collaboration,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
URLhttps://arxiv.org/abs/2605.03042. Jianxiang Yu, Zichen Ding, Jiaqi Tan, Kangyang Luo, Zhenmin Weng, Chenghua Gong, Long Zeng, Renjing Cui, Chengcheng Han, Qiushi Sun, Zhiyong Wu, Yunshi Lan, and Xiang Li. Automated peer reviewing in paper sea: Standardization, evaluation, and analysis,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
URLhttps: //arxiv.org/abs/2407.12857. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena,
-
[25]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
URLhttps://arxiv.org/ abs/2306.05685. Kunlun Zhu, Jiaxun Zhang, Ziheng Qi, et al. SafeScientist: Toward risk-aware scientific discoveries by LLM agents.arXiv preprint arXiv:2505.23559,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
A DEPLOYMENTTOPICDISTRIBUTION Figure 5 groups the 166 generated papers by whether they fall under the nine seed topics provided at launch or under emergent topics discovered during autonomous exploration. B INTEGRITYFAILUREMODES The AI Integrity Audit in our review standard (Section 5.1) asks reviewers to verify each manuscript against its own source arti...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.