WIDER-FAIR: An Annotated Version of the WIDER-FACE Dataset for Fairness Evaluation
Pith reviewed 2026-07-01 05:35 UTC · model grok-4.3
The pith
WIDER-FAIR annotations show face detection models perform worse on Black faces and that excluding them from training widens fairness gaps more than any other group.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
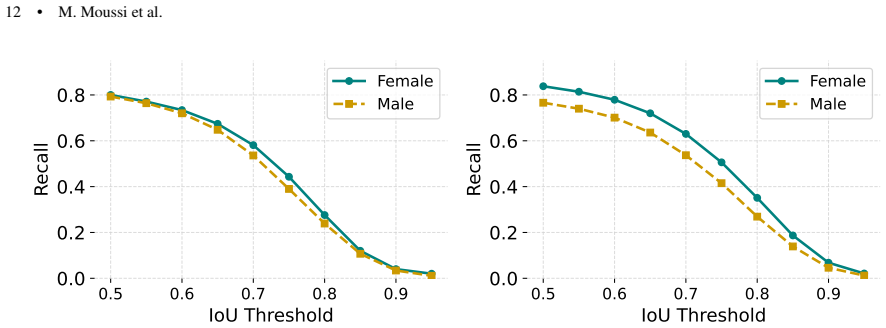
By manually annotating WIDER-FACE with perceived ethnicity (Asian, Black, Indian, White) and sex, the authors enable ablation experiments that establish lower detection performance for Black faces and show that excluding the Black group from training increases fairness disparity more than excluding any other ethnic group.
What carries the argument
The WIDER-FAIR dataset of 16,256 images with manual annotations of perceived ethnicity and sex, used to support training ablations and fairness measurements on a YOLOv5 detector.
If this is right
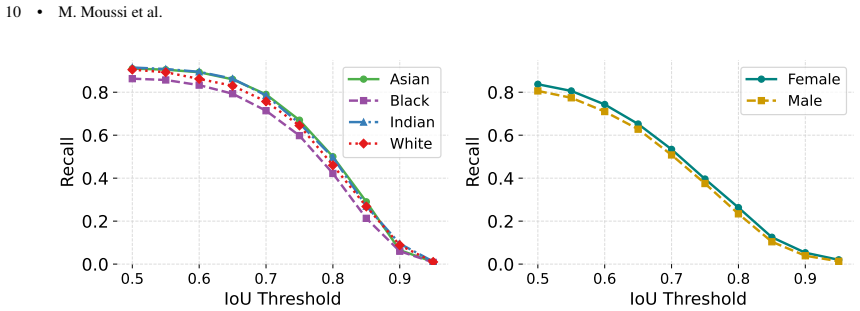
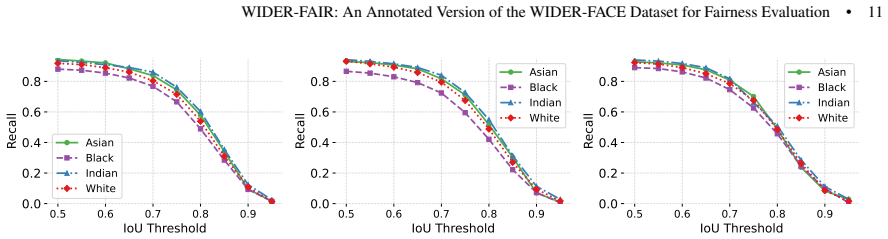
- Face detection accuracy varies across the four annotated ethnic groups.
- Black faces exhibit the lowest detection performance among the groups tested.
- Excluding Black faces from training data produces a larger fairness disparity than excluding Asian, Indian, or White faces.
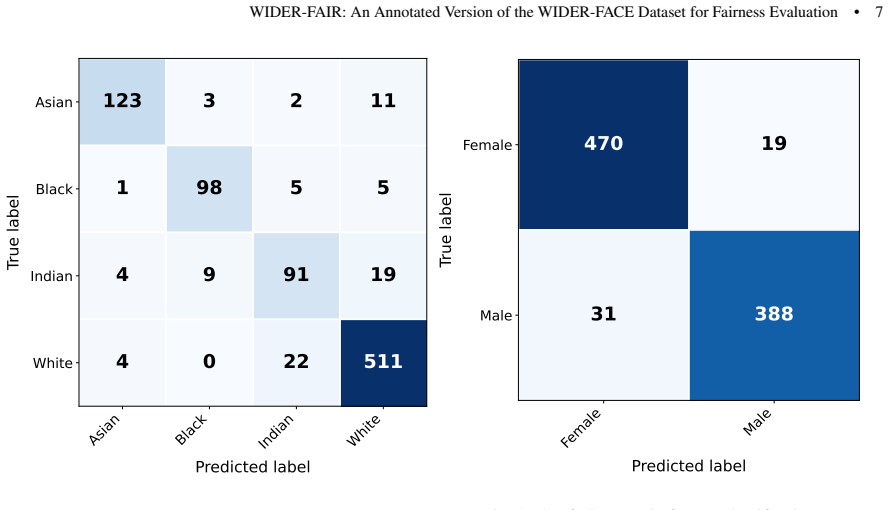
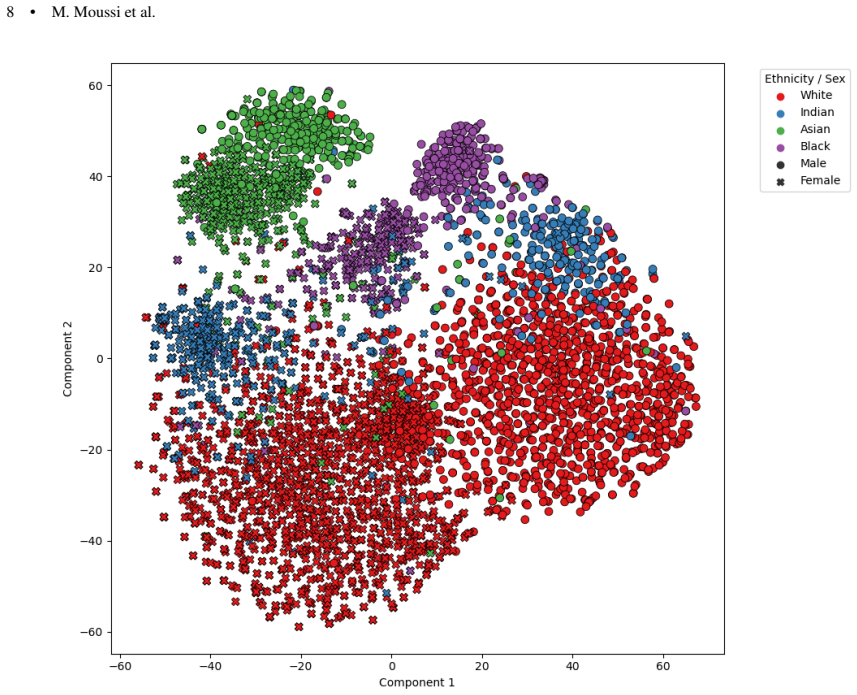
- Embedding-based checks and visualization support the internal consistency of the added annotations.
Where Pith is reading between the lines
- The same annotation process could be applied to other detection benchmarks to check whether the Black-face performance pattern appears across different model families.
- The results point to the value of ensuring Black faces are well represented in training sets to limit disparity growth.
- Future experiments might test whether the observed gaps persist when the detector is evaluated on images captured under different lighting or pose conditions.
Load-bearing premise
The manual annotations of perceived ethnicity and sex are sufficiently accurate and consistent to support reliable conclusions about model performance differences across groups.
What would settle it
Re-annotating a substantial subset of the faces with a new set of human labelers and retraining the detector to find that the Black-face performance gap disappears or that another group produces a larger disparity increase when excluded.
Figures

read the original abstract
The deployment of face detection models in real-world applications raises important fairness concerns, as these systems may showcase performance disparities across demographic groups. A key obstacle to studying and mitigating such biases is the lack of face detection datasets with sensitive feature annotations. To address this gap, we introduce WIDER-FAIR, a new dataset built on the widely used WIDER-FACE benchmark, manually annotated with the perceived ethnicity and sex of each face. The dataset contains 16,256 images annotated across four ethnic groups: Asian, Black, Indian, and White, and two sex categories. We assess the quality and coherence of the annotations using face embeddings, a K-Nearest Neighbors classifier, and a t-SNE visualization, all of which support the consistency of the labeling process. As a demonstration of the dataset's potential, we train a YOLOv5 model and perform ablation studies on each sensitive feature. Among other findings, our experiments show that detection performance is notably lower for faces of Black individuals, and that excluding this group from training increases fairness disparity more than excluding any other ethnic group. These observations illustrate the value of demographically annotated datasets for understanding and evaluating bias in face detection models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WIDER-FAIR, a manually annotated extension of the WIDER-FACE dataset providing perceived ethnicity (Asian, Black, Indian, White) and sex labels for faces in 16,256 images. Annotations are assessed for coherence via face embeddings, KNN classification, and t-SNE visualization. As a use case, the authors train a YOLOv5 detector and run ablation studies on demographic subsets, reporting notably lower detection performance on Black faces and that excluding the Black group from training increases fairness disparity more than exclusion of any other ethnic group.
Significance. If the ethnicity annotations prove sufficiently accurate, the dataset would be a useful resource for fairness research in face detection, directly addressing the lack of demographically labeled benchmarks. The embedding-based consistency checks are a methodological strength, and the ablation findings on group-specific impacts could inform targeted bias mitigation if the labels hold. The work is otherwise standard in its use of existing detectors and metrics.
major comments (1)
- [§3] §3 (Annotation process and validation): The manuscript reports that embeddings + KNN + t-SNE support label consistency, yet provides no inter-annotator agreement statistics, annotation guidelines for ambiguous cases, number of annotators, or error rates against any external reference. Because the central claims (lower AP on Black faces; largest disparity increase when Black group is ablated) rest on the correctness of the four ethnicity labels rather than mere internal coherence, this omission is load-bearing; systematic mislabeling correlated with pose, lighting, or annotator bias would directly confound the §4 ablation results.
minor comments (2)
- [Abstract] The abstract states the dataset contains 16,256 images but does not clarify whether this is the full WIDER-FACE subset or a filtered portion; adding this detail would improve reproducibility.
- [Figure 3] Figure captions for the t-SNE plots should explicitly state the embedding model and distance metric used, as these choices affect interpretation of cluster separation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the annotation validation. We address the concern regarding §3 below, providing clarification on our approach while acknowledging areas where additional details can be supplied.
read point-by-point responses
-
Referee: [§3] §3 (Annotation process and validation): The manuscript reports that embeddings + KNN + t-SNE support label consistency, yet provides no inter-annotator agreement statistics, annotation guidelines for ambiguous cases, number of annotators, or error rates against any external reference. Because the central claims (lower AP on Black faces; largest disparity increase when Black group is ablated) rest on the correctness of the four ethnicity labels rather than mere internal coherence, this omission is load-bearing; systematic mislabeling correlated with pose, lighting, or annotator bias would directly confound the §4 ablation results.
Authors: We agree that the manuscript would benefit from more explicit details on the annotation process. The ethnicity and sex labels are perceived attributes assigned based on visual inspection of the images, following standard practices in fairness datasets where no objective ground truth exists. The embedding + KNN + t-SNE analysis was selected specifically to demonstrate internal label coherence via an objective, data-driven method that does not rely on external references (which are unavailable for perceived ethnicity on this scale). We did not compute inter-annotator agreement because the process involved a single primary annotator with review for ambiguous cases, and guidelines were informal visual criteria rather than a formalized document. We will revise §3 to report the number of annotators involved, summarize the annotation criteria used, and expand the discussion of why embedding-based validation was prioritized over IAA for this task. However, we cannot provide error rates against an external reference, as none was collected or available. revision: partial
- Error rates against any external reference for the ethnicity labels, as no such reference dataset or ground truth was used or available during annotation.
Circularity Check
No circularity; purely empirical annotation and ablation study with no derivations or self-referential fits.
full rationale
The paper introduces manual annotations for ethnicity and sex on WIDER-FACE, validates label coherence via embeddings/KNN/t-SNE (internal consistency check only), trains YOLOv5, and runs group-exclusion ablations. No equations, no fitted parameters renamed as predictions, no self-citation chains, and no ansatz or uniqueness claims appear in the provided text. The central claims rest on new data collection and standard supervised training, making the work self-contained against external benchmarks without any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency. PMLR, 77–91
2018
-
[2]
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. 2020. Retinaface: Single-shot multi-level face localisation in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5203–5212
2020
-
[3]
Tausif Diwan, G Anirudh, and Jitendra V Tembhurne. 2023. Object detection using YOLO: challenges, architectural successors, datasets and applications.multimedia Tools and Applications82, 6 (2023), 9243–9275
2023
-
[4]
European Parliament and Council of the European Union. 2024. Regulation (EU) 2024/1689 of 13 June 2024 Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act). https://eur-lex.europa.eu/eli/reg/2024/1689/oj/eng
2024
-
[5]
Kimmo Karkkainen and Jungseock Joo. 2021. Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 1548–1558
2021
-
[6]
Davis E King. 2009. Dlib-ml: A machine learning toolkit.The Journal of Machine Learning Research10 (2009), 1755–1758
2009
-
[7]
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. 2021. A survey on bias and fairness in machine learning.ACM computing surveys (CSUR)54, 6 (2021), 1–35
2021
-
[8]
Hanna F Menezes, Arthur SC Ferreira, Eanes T Pereira, and Herman M Gomes. 2021. Bias and fairness in face detection. In2021 34th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI). IEEE, 247–254. Proceedings of ECAF’26. September 02 – September 04, 2026. Ghent, BE. 14 • M. Moussi et al
2021
-
[9]
Surbhi Mittal, Kartik Thakral, Puspita Majumdar, Mayank Vatsa, and Richa Singh. 2023. Are face detection models biased?. In2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 1–7
2023
- [10]
-
[11]
Delong Qi, Weijun Tan, Qi Yao, and Jingfeng Liu. 2022. YOLO5Face: Why reinventing a face detector. InEuropean Conference on Computer Vision. Springer, 228–244
2022
-
[12]
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. 2016. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition. 779–788
2016
-
[13]
Benoît Ronval, Siegfried Nijssen, and Ludwig Bothmann. 2024. Can generative AI-based data balancing mitigate unfairness issues in machine learning?. InEWAF
2024
-
[14]
Juan Terven, Diana-Margarita Córdova-Esparza, and Julio-Alejandro Romero-González. 2023. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas.Machine learning and knowledge extraction5, 4 (2023), 1680–1716
2023
-
[15]
Bart Thomee, David A Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. 2016. Yfcc100m: The new data in multimedia research.Commun. ACM59, 2 (2016), 64–73
2016
-
[16]
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE.Journal of machine learning research9, 11 (2008)
2008
-
[17]
Benjamin Wilson, Judy Hoffman, and Jamie Morgenstern. 2019. Predictive inequity in object detection.arXiv preprint arXiv:1902.11097 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
Shuo Yang, Ping Luo, Chen-Change Loy, and Xiaoou Tang. 2016. Wider face: A face detection benchmark. InProceedings of the IEEE conference on computer vision and pattern recognition. 5525–5533
2016
-
[19]
Yu Yang, Aayush Gupta, Jianwei Feng, Prateek Singhal, Vivek Yadav, Yue Wu, Pradeep Natarajan, Varsha Hedau, and Jungseock Joo
-
[20]
InAIES 2022
Enhancing fairness in face detection in computer vision systems by demographic bias mitigation. InAIES 2022. https://www. amazon.science/publications/enhancing-fairness-in-face-detection-in-computer-vision-systems-by-demographic-bias-mitigation
2022
-
[21]
Stefanos Zafeiriou, Cha Zhang, and Zhengyou Zhang. 2015. A survey on face detection in the wild: past, present and future.Computer Vision and Image Understanding138 (2015), 1–24
2015
-
[22]
Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, and Yu Qiao. 2016. Joint face detection and alignment using multitask cascaded convolutional networks.IEEE signal processing letters23, 10 (2016), 1499–1503. Proceedings of ECAF’26. September 02 – September 04, 2026. Ghent, BE
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.