JETO-Bench: A Reproducible Benchmark for Execution Time Improvement Patches in Java
Pith reviewed 2026-07-01 04:08 UTC · model grok-4.3
The pith
A configurable tool builds the first reusable benchmarks of execution time patches in real-world Java projects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
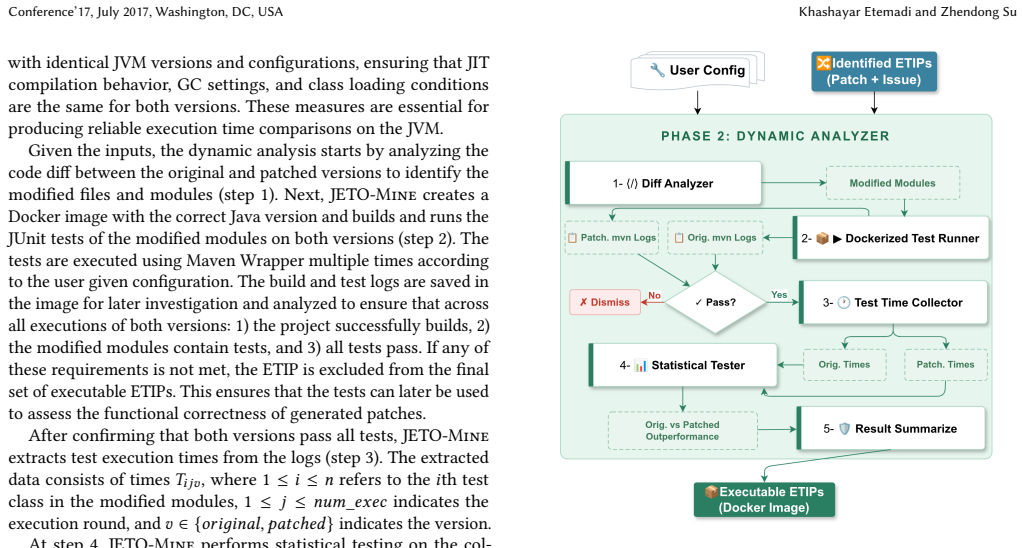
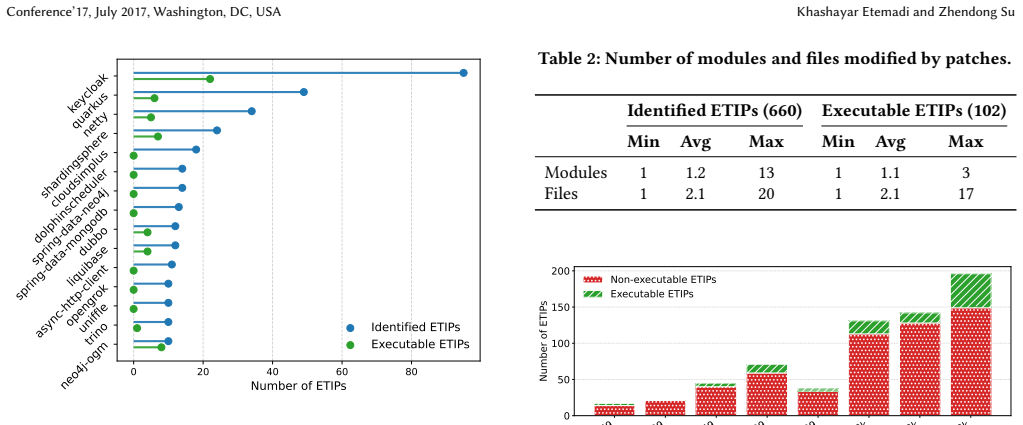
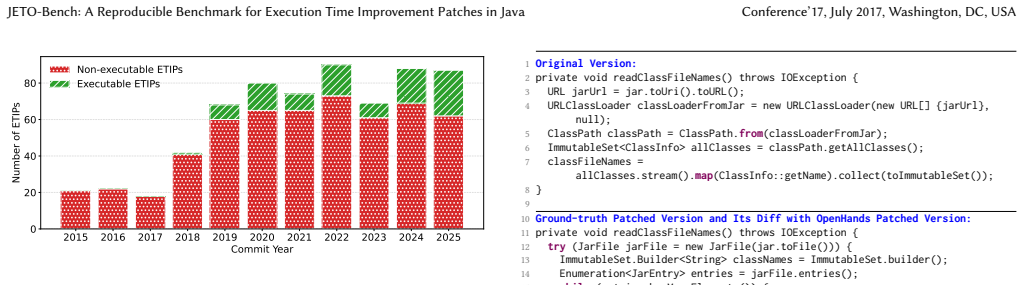
JETO-Mine is the first configurable and reusable tool for automatically creating reproducible benchmarks of execution time improvement patches in real-world Java projects. It employs a three-phase pipeline: static analysis that crawls GitHub repositories and identifies candidates using user-defined filters and an LLM-based issue classifier, dynamic analysis that wraps the identified patches in Docker images for fully reproducible execution and performs statistical testing to find objective evidence of execution time improvement, and an evaluation harness that enables quantitative assessment of both generated patches and generated tests. Using JETO-Mine to scan 11 years of development history
What carries the argument
JETO-Mine three-phase pipeline that identifies ETIPs via static analysis with LLM classification, verifies them through Docker-wrapped dynamic statistical testing, and supplies an evaluation harness.
If this is right
- Researchers can reuse JETO-Mine with arbitrary filters and statistical thresholds to collect new benchmarks indefinitely.
- The 91 cases allow quantitative evaluation of automated repair tools, with one agent succeeding on 13 of them.
- Open-source Java projects rarely ship tests that capture execution time improvements.
- The approach extends beyond fixed benchmarks by enabling continuous addition of new patches.
- The lack of performance tests points to a gap that test-generation methods could address.
Where Pith is reading between the lines
- The same mining pipeline could be ported to other languages to produce comparable cross-language performance benchmarks.
- The verified cases could be mined further to extract recurring patterns in how developers optimize Java execution time.
- The benchmark supplies a concrete testbed for measuring how well repair agents generalize when the target language changes.
- Future extensions might integrate automated generation of performance-focused tests directly into the harness.
Load-bearing premise
The LLM-based issue classifier in the static analysis phase and the subsequent manual verification step together produce a low rate of false-positive ETIPs, such that the 91 executable cases are representative of genuine execution time improvements.
What would settle it
Re-executing the dynamic analysis phase on the 91 cases and finding that a majority fail to show statistically significant execution time reductions would show the benchmark contains many non-genuine patches.
Figures


read the original abstract
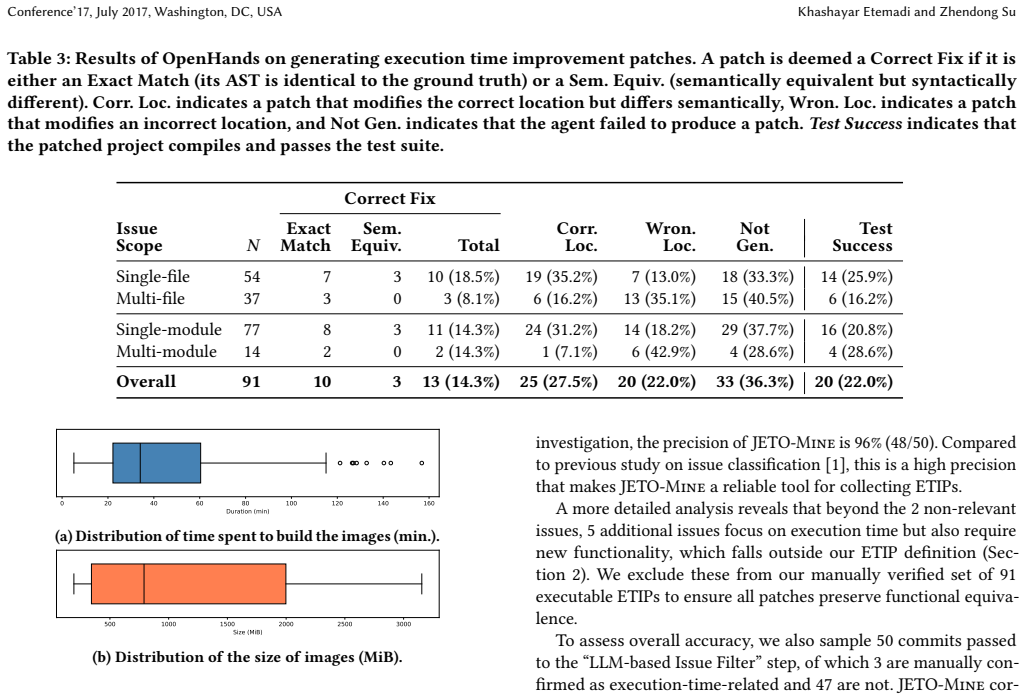
Automated fixing of performance issues is gaining increasing attention. However, existing benchmarks of execution time improvement patches are fixed datasets that target Python, C++, or .NET and cannot be extended to new patches according to user-defined configurations. In this paper, we present JETO-Mine, the first configurable and reusable tool for automatically creating reproducible benchmarks of execution time improvement patches (ETIPs) in real-world Java projects. JETO-Mine employs a three-phase pipeline: a static analysis phase that crawls GitHub repositories and identifies ETIPs using user-defined filters and an LLM-based issue classifier, a dynamic analysis phase that wraps the identified ETIPs in Docker images for fully reproducible execution and performs statistical testing to find objective evidence of execution time improvement, and an evaluation harness that enables quantitative assessment of both generated patches and generated tests. Unlike existing benchmarks, JETO-Mine is designed as a reusable tool that allows researchers continuously collect new benchmarks with their own desired filters and statistical rigor levels. We use JETO-Mine to build JETO-Bench, a benchmark of 660 identified ETIPs and 91 manually verified executable ETIPs collected from 174 open-source Java repositories. To build JETO-Bench, JETO-Mine scans 11 years of open-source development history and nearly 1.8 million commits. We run OpenHands, a leading open-source coding agent, on the 91 manually verified executable ETIPs in JETO-Bench and find that it correctly fixes 14.3% (13/91) of the issues, aligning with results reported by similar studies on other programming languages. Our results also reveal that open-source Java projects largely lack tests that demonstrate execution time improvements, presenting an opportunity for future research in test generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JETO-Mine, a configurable and reusable tool for mining reproducible benchmarks of execution time improvement patches (ETIPs) from real-world Java projects via a three-phase pipeline (static analysis with GitHub crawling, user filters, and LLM issue classifier; dynamic analysis with Docker containers and statistical testing; evaluation harness). Applied to 174 repositories and 1.8M commits, it yields JETO-Bench containing 660 identified ETIPs and 91 manually verified executable ones. Evaluation of the OpenHands agent on the 91 cases shows a 14.3% (13/91) fix rate, consistent with prior work on other languages, while noting the scarcity of performance-improvement tests in Java projects.
Significance. If the verification pipeline reliably isolates genuine ETIPs, the work supplies the first extensible Java benchmark in this space, enabling researchers to generate custom datasets with controllable rigor. The reported fix rate provides a comparable baseline across languages, and the identified gap in test coverage for performance patches is a concrete direction for follow-on research. The tool's design as reusable infrastructure (rather than a one-time dataset) is a notable strength.
major comments (2)
- [Abstract and static analysis phase] Abstract and §3 (static analysis phase): the LLM-based issue classifier is central to producing the 660 candidates, yet no precision, recall, or validation metrics against a labeled subset are reported. Without these, it is impossible to bound the false-positive rate that propagates into the 91 verified cases.
- [Abstract and dynamic analysis phase] Abstract and §4 (dynamic analysis and manual verification): the manuscript states that statistical testing yields 'objective evidence of execution time improvement' and that 91 cases are 'manually verified,' but supplies neither the exact statistical procedure/thresholds, inter-rater agreement statistics, nor explicit exclusion criteria. These details are load-bearing for the claim that JETO-Bench contains representative, genuine ETIPs.
minor comments (1)
- [Abstract] The abstract could more explicitly state how many of the 660 candidates survived the dynamic statistical test versus how many were removed during manual verification.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that greater transparency on the LLM classifier validation and on the statistical/manual verification procedures is warranted. We respond point-by-point below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and static analysis phase] Abstract and §3 (static analysis phase): the LLM-based issue classifier is central to producing the 660 candidates, yet no precision, recall, or validation metrics against a labeled subset are reported. Without these, it is impossible to bound the false-positive rate that propagates into the 91 verified cases.
Authors: We agree that precision, recall, and related metrics for the LLM-based issue classifier are necessary to quantify its contribution to the candidate pool and to bound downstream false positives. In the revised version we will add a dedicated evaluation subsection in §3 that reports results on a manually labeled subset (including precision, recall, F1, and a confusion matrix). This addition will directly address the concern. revision: yes
-
Referee: [Abstract and dynamic analysis phase] Abstract and §4 (dynamic analysis and manual verification): the manuscript states that statistical testing yields 'objective evidence of execution time improvement' and that 91 cases are 'manually verified,' but supplies neither the exact statistical procedure/thresholds, inter-rater agreement statistics, nor explicit exclusion criteria. These details are load-bearing for the claim that JETO-Bench contains representative, genuine ETIPs.
Authors: We concur that the exact statistical procedures, thresholds, exclusion criteria, and verification process must be documented. We will expand §4 with: (i) the precise statistical tests and thresholds applied (e.g., test name, p-value cutoff, minimum relative improvement), (ii) the full list of exclusion criteria used to arrive at the 91 executable cases, and (iii) a description of the manual verification workflow. If multiple raters participated we will add inter-rater agreement statistics; if verification was performed by a single author we will state this explicitly as a limitation. These clarifications will be added without altering the reported numbers. revision: yes
Circularity Check
Empirical benchmark construction with no circular derivations
full rationale
The paper describes construction of JETO-Mine and JETO-Bench via crawling GitHub, LLM-based classification, Docker-wrapped dynamic statistical testing, and manual verification of 91 ETIPs. No equations, fitted parameters, predictions, or self-citations appear in the derivation chain. Central results (91 cases, 14.3% fix rate on OpenHands) rest on external public repositories and an independent agent, satisfying the self-contained benchmark criterion. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption An LLM can be used to classify GitHub issues as describing execution time improvements with sufficient accuracy for benchmark construction.
- domain assumption Docker-wrapped execution plus statistical testing provides objective evidence of execution time improvement.
Reference graph
Works this paper leans on
-
[1]
Gabriel Aracena, Kyle Luster, Fabio Santos, Igor Steinmacher, and Marco A Gerosa
-
[2]
Applying large language models to issue classification: Revisiting with extended data and new models.Science of Computer Programming246 (2025), 103333
2025
-
[3]
Stephen M Blackburn, Robin Garner, Chris Hoffmann, Asjad M Khang, Kathryn S McKinley, Rotem Bentzur, Amer Diwan, Daniel Feinberg, Daniel Frampton, Samuel Z Guyer, et al. 2006. The DaCapo benchmarks: Java benchmarking devel- opment and analysis. InProceedings of the 21st annual ACM SIGPLAN conference on Object-oriented programming systems, languages, and a...
2006
-
[4]
Aymeric Blot and Justyna Petke. 2025. A comprehensive survey of benchmarks for improvement of software’s non-functional properties.Comput. Surveys57, 7 (2025), 1–36
2025
-
[5]
Tristan Coignion, Clément Quinton, and Romain Rouvoy. 2024. A performance study of llm-generated code on leetcode. InProceedings of the 28th international conference on evaluation and assessment in software engineering. 79–89
2024
- [6]
-
[7]
Mingzhe Du, Luu A Tuan, Bin Ji, Qian Liu, and See-Kiong Ng. 2024. Mercury: A code efficiency benchmark for code large language models.Advances in Neural Information Processing Systems37 (2024), 16601–16622
2024
-
[8]
2016.IntroClassJava: A benchmark of 297 small and buggy Java programs
Thomas Durieux and Martin Monperrus. 2016.IntroClassJava: A benchmark of 297 small and buggy Java programs. Ph. D. Dissertation. Universite Lille 1
2016
-
[9]
Khashayar Etemadi, Nicolas Harrand, Simon Larsen, Haris Adzemovic, Henry Lu- ong Phu, Ashutosh Verma, Fernanda Madeiral, Douglas Wikström, and Martin Monperrus. 2022. Sorald: Automatic patch suggestions for sonarqube static analysis violations.IEEE Transactions on Dependable and Secure Computing20, 4 (2022), 2794–2810
2022
-
[10]
2026.Replication package.https://github
Khashayar Etemadi and Zhendong Su. 2026.Replication package.https://github. com/khesoem/JETO-Bench
2026
-
[11]
Zhiyuan Fan, Kirill Vasilevski, Dayi Lin, Boyuan Chen, Yihao Chen, Zhiqing Zhong, Jie M. Zhang, Pinjia He, and Ahmed E. Hassan. 2025. SWE-Effi: Re-Evaluating Software AI Agent System Effectiveness Under Resource Con- straints.ArXivabs/2509.09853 (2025). https://api.semanticscholar.org/CorpusID: 281310248
-
[12]
Michael Fu, Chakkrit Tantithamthavorn, Trung Le, Van Nguyen, and Dinh Phung
-
[13]
InProceedings of the 30th ACM joint european software engineering conference and symposium on the foundations of software engineering
Vulrepair: a t5-based automated software vulnerability repair. InProceedings of the 30th ACM joint european software engineering conference and symposium on the foundations of software engineering. 935–947
-
[14]
Qing Gao, Yingfei Xiong, Yaqing Mi, Lu Zhang, Weikun Yang, Zhaoping Zhou, Bing Xie, and Hong Mei. 2015. Safe memory-leak fixing for c programs. In2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Vol. 1. IEEE, 459–470
2015
- [15]
-
[16]
Spandan Garg, Roshanak Zilouchian Moghaddam, Colin B Clement, Neel Sun- daresan, and Chen Wu. 2022. Deepdev-perf: a deep learning-based approach for improving software performance. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 948–958
2022
- [17]
-
[18]
Spandan Garg, Roshanak Zilouchian Moghaddam, and Neel Sundaresan. 2025. Rapgen: An approach for fixing code inefficiencies in zero-shot. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 124–135
2025
-
[19]
Andy Georges, Dries Buytaert, and Lieven Eeckhout. 2007. Statistically rigorous java performance evaluation.ACM SIGPLAN Notices42, 10 (2007), 57–76
2007
-
[20]
Mohammadreza Ghanavati, Diego Costa, Janos Seboek, David Lo, and Artur Andrzejak. 2020. Memory and resource leak defects and their repairs in Java projects.Empirical Software Engineering25, 1 (2020), 678–718
2020
- [21]
- [22]
-
[23]
Dong HUANG, Jianbo Dai, Han Weng, Puzhen Wu, Yuhao QING, Heming Cui, Zhijiang Guo, and Jie Zhang. 2024. EffiLearner: Enhancing Efficiency of Generated Code via Self-Optimization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=KhwOuB0fs9
2024
-
[24]
Dong Huang, Yuhao Qing, Weiyi Shang, Heming Cui, and Jie M Zhang. 2024. Ef- fibench: Benchmarking the efficiency of automatically generated code.Advances in Neural Information Processing Systems37 (2024), 11506–11544
2024
-
[25]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. SWE-bench: Can Language Models Resolve Real- World GitHub Issues?ArXivabs/2310.06770 (2023). https://api.semanticscholar. org/CorpusID:263829697
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
René Just, Darioush Jalali, and Michael D Ernst. 2014. Defects4J: A database of ex- isting faults to enable controlled testing studies for Java programs. InProceedings of the 2014 international symposium on software testing and analysis. 437–440
2014
-
[27]
Derrick Lin, James Koppel, Angela Chen, and Armando Solar-Lezama. 2017. QuixBugs: A multi-lingual program repair benchmark set based on the Quixey Challenge. InProceedings Companion of the 2017 ACM SIGPLAN international conference on systems, programming, languages, and applications: software for humanity. 55–56
2017
- [28]
-
[29]
Jeffrey Jian Ma, Milad Hashemi, Amir Yazdanbakhsh, Kevin Swersky, Ofir Press, Enhui Li, Vijay Janapa Reddi, and Parthasarathy Ranganathan. 2025. SWE- fficiency: Can Language Models Optimize Real-World Repositories on Real Work- loads?arXiv preprint arXiv:2511.06090(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
-
[31]
Fernanda Madeiral, Simon Urli, Marcelo Maia, and Martin Monperrus. 2019. Bears: An extensible java bug benchmark for automatic program repair studies. In2019 IEEE 26th international conference on software analysis, evolution and reengineering (SANER). IEEE, 468–478
2019
-
[32]
Anne Ouyang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher Re, and Azalia Mirhoseini. 2025. KernelBench: Can LLMs Write Efficient GPU Kernels?. InForty-second International Conference on Machine Learning. https: //openreview.net/forum?id=yeoN1iQT1x
2025
- [33]
- [34]
-
[35]
Ripon K Saha, Yingjun Lyu, Wing Lam, Hiroaki Yoshida, and Mukul R Prasad. 2018. Bugs. jar: A large-scale, diverse dataset of real-world java bugs. InProceedings of the 15th international conference on mining software repositories. 10–13
2018
- [36]
-
[37]
Marija Selakovic and Michael Pradel. 2015. Poster: Automatically fixing real- world JavaScript performance bugs. In2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Vol. 2. IEEE, 811–812
2015
- [38]
- [39]
-
[40]
Michele Tufano, Cody Watson, Gabriele Bavota, Massimiliano Di Penta, Martin White, and Denys Poshyvanyk. 2019. An empirical study on learning bug-fixing patches in the wild via neural machine translation.ACM Transactions on Software Engineering and Methodology (TOSEM)28, 4 (2019), 1–29
2019
-
[41]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
2025
-
[42]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. De- mystifying LLM-Based Software Engineering Agents.Proc. ACM Softw. Eng.2, FSE, Article FSE037 (June 2025), 24 pages. doi:10.1145/3715754
-
[43]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[44]
Jiuding Yang, Shengyao Lu, Hongxuan Liu, Shayan Shirahmad Gale Bagi, Zahra Fazel, Tomasz Czajkowski, and Di Niu. 2025. PerfCoder: Large Language Models for Interpretable Code Performance Optimization.arXiv preprint arXiv:2512.14018 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
He Ye, Matias Martinez, and Martin Monperrus. 2022. Neural program repair with execution-based backpropagation. InProceedings of the 44th international conference on software engineering. 1506–1518. Conference’17, July 2017, Washington, DC, USA Khashayar Etemadi and Zhendong Su
2022
-
[46]
Lirong Yi, Gregory Gay, and Philipp Leitner. 2025. An Experimental Study of Real- Life LLM-Proposed Performance Improvements.arXiv preprint arXiv:2510.15494 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Quanjun Zhang, Chunrong Fang, Yuxiang Ma, Weisong Sun, and Zhenyu Chen
-
[48]
A survey of learning-based automated program repair.ACM Transactions on Software Engineering and Methodology33, 2 (2023), 1–69
2023
-
[49]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- tocoderover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592–1604
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.