CHERRY: Compressed Hierarchical Experts with Recurrent Representational Yield
Pith reviewed 2026-07-01 05:44 UTC · model grok-4.3
The pith
Selective supervision on 15% of tokens recovers 67% of full loss reduction in language models through positive gradient coupling in shared weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
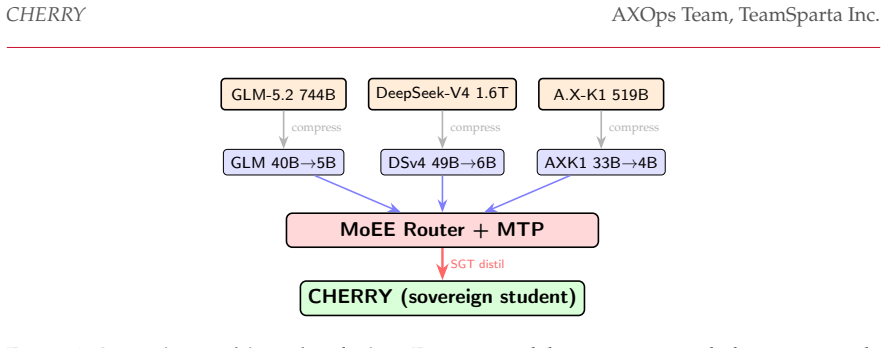
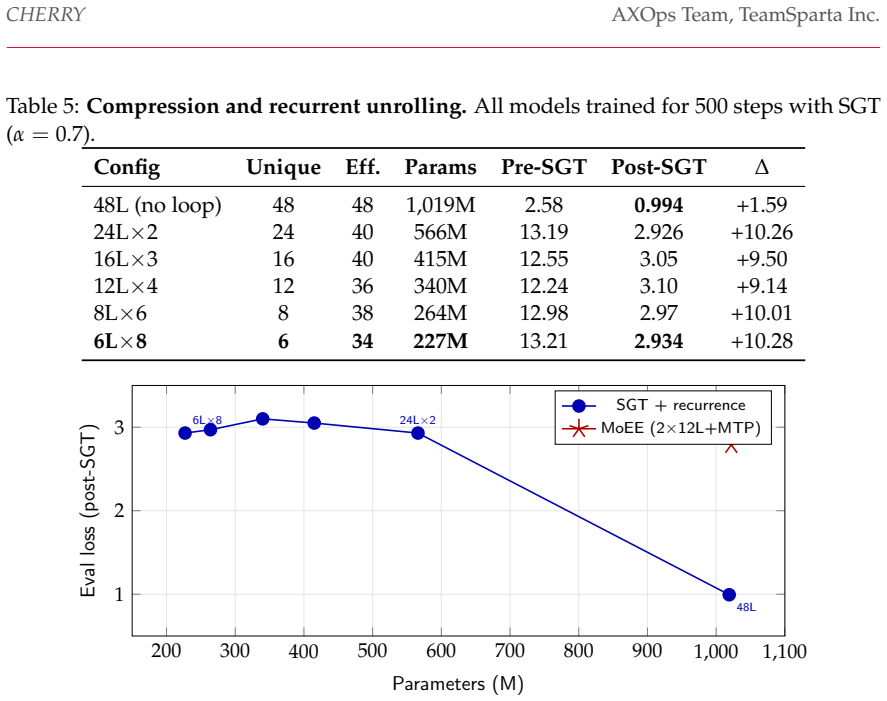
Selective Ground Truth Token Training concentrates supervision on roughly 15% of tokens yet recovers about 67% of full-sequence loss reduction because the gradient coupling coefficient gamma-bar equals 0.72; the effect is guaranteed when this coefficient is positive and collapses on shuffled text. A 48-layer transformer compressed to six layers and restored by 34 recurrent unrollings reaches held-out loss 2.934, within noise of a 566M dense model at 2.926. A two-expert mixture of these compressed models reaches loss 2.789, outperforming the best single compressed model at 2.926.
What carries the argument
Selective Ground Truth Token Training (SGT) that exploits positive gradient coupling (gamma-bar = 0.72) across position-shared weights, combined with recurrent unrolling after layer averaging for depth compression and Mixture of Efficient Experts (MoEE) fusion.
Load-bearing premise
The improvement on unsupervised tokens stems from natural-language structure that produces positive gradient coupling in the shared weights.
What would settle it
Repeating the selective-training runs on shuffled text and finding either no loss reduction on unsupervised tokens or a non-positive gradient coupling coefficient would falsify the central efficiency claim.
Figures
read the original abstract
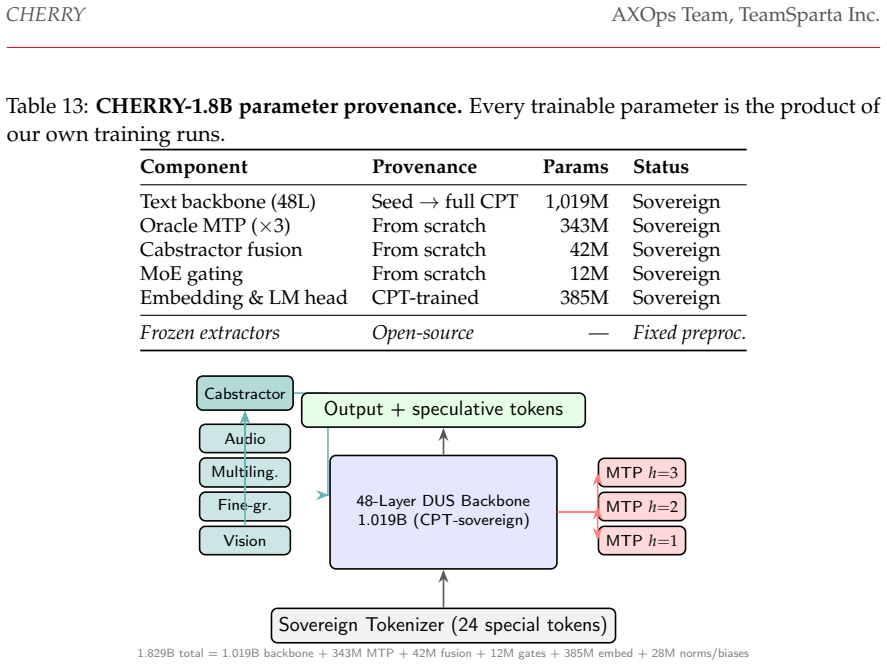
We study three complementary techniques for training compute-efficient language models. (1) Selective supervision and per-token efficiency. Selective Ground Truth Token Training (SGT) concentrates supervision on the ~15% of output tokens that carry semantic payload. Through positive gradient coupling in position-shared transformer weights -- a token-level instance of auxiliary-task transfer -- the remaining 85% of unsupervised tokens still improve substantially, giving a 4.5x per-supervised-token efficiency (at the step-100 eval optimum, ~67% of the full-sequence loss reduction is recovered from 15% of the supervision). We prove that this improvement on unsupervised tokens is guaranteed whenever the gradient coupling coefficient gamma-bar = 0.72 is positive (Theorem 1), and show the effect is a property of natural-language structure: it collapses on shuffled text. (2) Depth compression with recurrent recovery. A 48-layer, 1B-parameter transformer is compressed to 6 layers (227M) by averaging adjacent layers and restored through learned recurrent unrolling. With 34 effective recurrent layers it reaches a held-out loss of 2.934, within measurement noise of a 566M dense model at 2.926 -- a 2.5x reduction in parameters. (3) Fusion of compressed experts. Assembling several compressed models as a Mixture of Efficient Experts (MoEE) with multi-token prediction improves over each single expert at comparable active parameters: a 2-expert MoEE reaches loss 2.789 versus 2.926 for the best single compressed model. We validate these techniques on CHERRY-1.8B, a Korean foundation model whose every trainable parameter derives from our own training runs. We are explicit throughout about the scope of the evidence (one model family, Korean data, loss-based metrics) and about which claims are established versus prospective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces three techniques for compute-efficient language model training on the CHERRY-1.8B Korean model: (1) Selective Ground Truth Token Training (SGT) that supervises ~15% of tokens yet recovers ~67% of full-sequence loss reduction via positive gradient coupling (gamma-bar=0.72), with Theorem 1 guaranteeing unsupervised-token improvement conditional on gamma-bar>0 and the effect collapsing on shuffled text; (2) depth compression of a 48-layer model to 6 layers via averaging and recurrent unrolling, achieving loss 2.934 comparable to a 566M dense model; (3) Mixture of Efficient Experts (MoEE) with multi-token prediction, where a 2-expert variant reaches loss 2.789. The work explicitly limits claims to one model family, Korean data, and loss metrics.
Significance. If the empirical results and conditional theorem hold, SGT provides a measured 4.5x per-supervised-token efficiency gain with a general guarantee, the recurrent compression delivers a 2.5x parameter reduction at comparable loss, and MoEE demonstrates gains from fusing compressed experts. The explicit scope statement and focus on falsifiable loss metrics are strengths. These techniques could meaningfully advance parameter- and supervision-efficient training if the gradient-coupling mechanism proves robust beyond the reported setting.
major comments (1)
- [Abstract and Theorem 1 section] Abstract and the section presenting Theorem 1 plus the shuffled-text experiment: the interpretation that positive gamma-bar arises specifically from natural-language structure (rather than generic token-transition statistics) rests on the shuffled-text collapse. Shuffling destroys both higher-order semantics and local co-occurrence statistics simultaneously; without an intermediate control preserving n-gram or bigram distributions while disrupting only long-range order, the attribution to linguistic structure is not isolated. This affects the explanatory claim for why the 4.5x efficiency appears on natural text, even though the conditional guarantee of Theorem 1 itself remains intact.
minor comments (1)
- Ensure all reported scalars (gamma-bar=0.72, 15% token fraction, 67% recovery, step-100 optimum, loss values 2.789/2.926/2.934) are explicitly cross-referenced to the exact experimental tables, figures, or appendix derivations where they are computed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the interpretability of our SGT results. The single major comment concerns the strength of the attribution in the abstract and Theorem 1 section. We address it point-by-point below.
read point-by-point responses
-
Referee: [Abstract and Theorem 1 section] Abstract and the section presenting Theorem 1 plus the shuffled-text experiment: the interpretation that positive gamma-bar arises specifically from natural-language structure (rather than generic token-transition statistics) rests on the shuffled-text collapse. Shuffling destroys both higher-order semantics and local co-occurrence statistics simultaneously; without an intermediate control preserving n-gram or bigram distributions while disrupting only long-range order, the attribution to linguistic structure is not isolated. This affects the explanatory claim for why the 4.5x efficiency appears on natural text, even though the conditional guarantee of Theorem 1 itself remains intact.
Authors: We agree that the shuffled-text experiment does not isolate higher-order linguistic structure from local token-transition statistics, as random shuffling disrupts both simultaneously. The current control only demonstrates that the positive gamma-bar (and thus the efficiency gain) depends on the original sequential token statistics rather than on fully randomized transitions. We will revise the abstract and the relevant section to state that the effect is a property of the preserved token co-occurrence structure in natural text (as shown by the collapse under shuffling), without claiming isolation of long-range semantics. This keeps Theorem 1 and all empirical results unchanged while removing the over-attribution. We will also add a brief note that n-gram-preserving controls would be a useful direction for future work. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper measures the gradient coupling coefficient gamma-bar empirically (reported as 0.72) and states a theorem guaranteeing improvement on unsupervised tokens conditional on gamma-bar > 0. The claim that the effect stems from natural-language structure is backed by the shuffled-text control experiment. No quoted step reduces a claimed prediction or result to a fitted parameter by the paper's own equations, nor does any load-bearing premise rely on self-citation chains, imported uniqueness theorems, or ansatzes smuggled via prior work. The techniques are validated directly on the authors' own runs with explicit scope limitations, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- gamma-bar =
0.72
- supervised token fraction =
~0.15
axioms (1)
- domain assumption Improvement on unsupervised tokens is guaranteed whenever gradient coupling coefficient gamma-bar is positive (Theorem 1).
Reference graph
Works this paper leans on
-
[1]
ICML41–48 (2009)
Bengio, Y.et al.Curriculum learning.Proc. ICML41–48 (2009)
2009
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
Chen, C.et al.Accelerating large language model decoding with speculative sampling. Preprint athttps://arxiv.org/abs/2302.01318(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
DeepSeek-V3 technical report.Preprint at https://arxiv.org/abs/2412
DeepSeek-AI. DeepSeek-V3 technical report.Preprint at https://arxiv.org/abs/2412. 19437(2024)
2024
-
[4]
DeepSeek-V4: Towards real-world expertise in reasoning and coding
DeepSeek-AI. DeepSeek-V4: Towards real-world expertise in reasoning and coding. Technical Report(2026)
2026
-
[5]
ICLR(2019)
Dehghani, M.et al.Universal transformers.Proc. ICLR(2019)
2019
-
[6]
BERT: Pre-training of deep bidi- rectional transformers for language understanding.Proc
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT: Pre-training of deep bidi- rectional transformers for language understanding.Proc. NAACL-HLT, pp. 4171–4186 (2019)
2019
-
[7]
& Shazeer, N
Fedus, W., Zoph, B. & Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.JMLR23(120), 1–39 (2022)
2022
-
[8]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Geiping, J.et al.Scaling up test-time compute with latent reasoning: A recurrent depth approach.Advances in Neural Information Processing Systems(NeurIPS 2025). https://arxiv.org/abs/2502.05171
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
ICML(2024)
Gloeckle, F.et al.Better & faster large language models via multi-token prediction.Proc. ICML(2024)
2024
-
[10]
Gromov, A., Tirumala, K., Shapourian, H., Glorioso, P . & Roberts, D. A. The unreason- able ineffectiveness of the deeper layers.Proc. ICLR(2025). https://arxiv.org/abs/ 2403.17887. 25 CHERRYAXOps Team, TeamSparta Inc
-
[11]
& Dao, T
Gu, A. & Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. Proc. Conference on Language Modeling (COLM)(2024). https://arxiv.org/abs/2312. 00752
2024
-
[12]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature645, 633–638 (2025)
Guo, D.et al.(DeepSeek-AI). DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature645, 633–638 (2025). https://doi.org/10.1038/ s41586-025-09422-z
2025
-
[13]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O. & Dean, J. Distilling the knowledge in a neural network.NIPS 2014 Deep Learning Workshop.https://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[14]
& Hongler, C
Jacot, A., Gabriel, F. & Hongler, C. Neural tangent kernel: Convergence and generaliza- tion in neural networks.Advances in Neural Information Processing Systems31(NeurIPS 2018)
2018
-
[15]
arXiv preprint arXiv:1910.00762 , year=
Jiang, A. H., Wong, D. L.-K., Zhou, G.,et al.Accelerating deep learning by focusing on the biggest losers.Preprint athttps://arxiv.org/abs/1910.00762(2019)
-
[16]
Jiao, X.et al.TinyBERT: Distilling BERT for natural language understanding.Findings of EMNLP(2020)
2020
-
[17]
Scaling Laws for Neural Language Models
Kaplan, J.et al.Scaling laws for neural language models.Preprint at https://arxiv. org/abs/2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[18]
and Fleuret, F
Katharopoulos, A. and Fleuret, F. Not all samples are created equal: Deep learning with importance sampling.Proc. ICML, pp. 2530–2539 (2018)
2018
-
[19]
NAACL-HLT Industry Track(2024)
Kim, D.et al.SOLAR 10.7B: Scaling large language models with simple yet effective depth up-scaling.Proc. NAACL-HLT Industry Track(2024). https://arxiv.org/abs/ 2312.15166
-
[20]
& Soricut, R
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P . & Soricut, R. ALBERT: A lite BERT for self-supervised learning of language representations.Proc. ICLR(2020)
2020
-
[21]
& Matias, Y
Leviathan, Y., Kalman, M. & Matias, Y. Fast inference from transformers via speculative decoding.Proc. ICML(2023)
2023
-
[22]
EXAONE 3.5: Series of large language models for real-world use cases
LG AI Research. EXAONE 3.5: Series of large language models for real-world use cases. Preprint athttps://arxiv.org/abs/2412.04862(2024)
- [23]
-
[24]
ICLR(2024)
Lightman, H., Kosaraju, V ., Burda, Y.,et al.Let’s verify step by step.Proc. ICLR(2024)
2024
-
[25]
IEEE ICCV2980–2988 (2017)
Lin, T.-Y.et al.Focal loss for dense object detection.Proc. IEEE ICCV2980–2988 (2017)
2017
-
[26]
https://arxiv.org/abs/2404
Lin, Z.et al.Not all tokens are what you need for pretraining.Advances in Neural Information Processing Systems37(NeurIPS 2024, Oral). https://arxiv.org/abs/2404. 07965
2024
-
[27]
ICML(2024)
Liu, Z.et al.MobileLLM: Optimizing sub-billion parameter language models for on- device use cases.Proc. ICML(2024). 26 CHERRYAXOps Team, TeamSparta Inc
2024
-
[28]
& Hutter, F
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization.Proc. ICLR(2019)
2019
-
[29]
Ma, X.et al.LLM-Pruner: On the structural pruning of large language models.Advances in Neural Information Processing Systems36(NeurIPS 2023)
2023
- [30]
-
[31]
ICML(2022)
Mindermann, S., Brauner, J., Razzak, M.,et al.Prioritized training on points that are learnable, worth learning, and not yet learnt.Proc. ICML(2022)
2022
-
[32]
MiniMax-M3: Native multimodal mixture-of-experts.Technical Report (2026)
MiniMax AI. MiniMax-M3: Native multimodal mixture-of-experts.Technical Report (2026)
2026
-
[33]
HyperCLOVA X technical report.Preprint at https://arxiv.org/abs/2404.01954(2024)
NAVER Cloud HyperCLOVA X Team. HyperCLOVA X technical report.Preprint at https://arxiv.org/abs/2404.01954(2024)
-
[34]
NVFP4: A 4-bit floating-point format for efficient low-precision inference
NVIDIA. NVFP4: A 4-bit floating-point format for efficient low-precision inference. NVIDIA Technical Report(2025)
2025
-
[35]
Peng, B.et al.RWKV: Reinventing RNNs for the transformer era.Findings of EMNLP (2023), 14048–14077
2023
-
[36]
Radford, A.et al.Language models are unsupervised multitask learners.OpenAI Blog (2019)
2019
-
[37]
Raffel, C., Shazeer, N., Roberts, A.,et al.Exploring the limits of transfer learning with a unified text-to-text transformer.JMLR21(140):1–67 (2020)
2020
-
[38]
& Birch, A
Sennrich, R., Haddow, B. & Birch, A. Neural machine translation of rare words with subword units.Proc. ACL1715–1725 (2016)
2016
-
[39]
ICLR(2017)
Shazeer, N.et al.Outrageously large neural networks: The sparsely-gated mixture-of- experts layer.Proc. ICLR(2017)
2017
-
[40]
A.X-K1: A sovereign Korean foundation model.Preprint at https://arxiv
SK Telecom. A.X-K1: A sovereign Korean foundation model.Preprint at https://arxiv. org/abs/2601.09200(2026)
-
[41]
Vaswani, A.et al.Attention is all you need.Advances in Neural Information Processing Systems30(NeurIPS 2017), 5998–6008
2017
-
[42]
Wang, W.et al.MiniLMv2: Multi-head self-attention relation distillation for compressing pretrained transformers.Findings of ACL(2021)
2021
-
[43]
Y.,et al.Model soups: Averaging weights of multiple fine-tuned models improves accuracy without increasing inference time.Proc
Wortsman, M., Ilharco, G., Gadre, S. Y.,et al.Model soups: Averaging weights of multiple fine-tuned models improves accuracy without increasing inference time.Proc. ICML(2022)
2022
-
[44]
& Finn, C
Yu, T., Kumar, S., Gupta, A., Levine, S., Hausman, K. & Finn, C. Gradient surgery for multi-task learning.Advances in Neural Information Processing Systems33(NeurIPS 2020)
2020
-
[45]
GLM-5.2: A 744B parameter sparse model with IndexShare attention
Zhipu AI (Z.ai). GLM-5.2: A 744B parameter sparse model with IndexShare attention. Technical Report(2026). 27 CHERRYAXOps Team, TeamSparta Inc. Appendix A Notation Table A.1:Notation used throughout the paper. Symbol Meaning FFull token set: all positions in a response GGround Truth token set (|G|/|F | ≈0.15) ¯GNon-GT token set:F \ G G ∗ Super GT: single ...
2026
-
[46]
Factual tokens alone achieve 75% of full SGT performanceat 41% of the GT budget, confirming that factual entities are the highest-ROI supervision targets
-
[47]
4.5× for full SGT), consistent with the hypothesis that CoT pivots carry disproportionate semantic load
Reasoning tokens yield the highest per-token ROI(8.9× vs. 4.5× for full SGT), consistent with the hypothesis that CoT pivots carry disproportionate semantic load
-
[48]
This confirms that SSGT is best suited for installingspecific capabilities(self-correction, verification) rather than general- purpose training
Self-correction (SSGT) tokens achieve11.3 × ROI—the highest among all categories— but the absolute eval loss (2.13) is furthest from full SGT. This confirms that SSGT is best suited for installingspecific capabilities(self-correction, verification) rather than general- purpose training
-
[49]
All single-category runs show W> 1, confirming that wave propagation operates regardless of which GT category provides the supervision signal. C Depth compression C.1 Compression-recovery trajectory Observation.Recovery is remarkably uniform across compression levels (81–84%), sug- gesting that adjacent-layer merging preserves the model’s essential struct...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.