Generative Lane Topology Reasoning via Autoregressive Model with Geometry Prior
Pith reviewed 2026-07-01 06:07 UTC · model grok-4.3
The pith
An autoregressive transformer pre-trained on millions of map scenes learns lane graph geometry priors that transfer via a perception adapter to produce more consistent and complete lane topologies from sensor data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
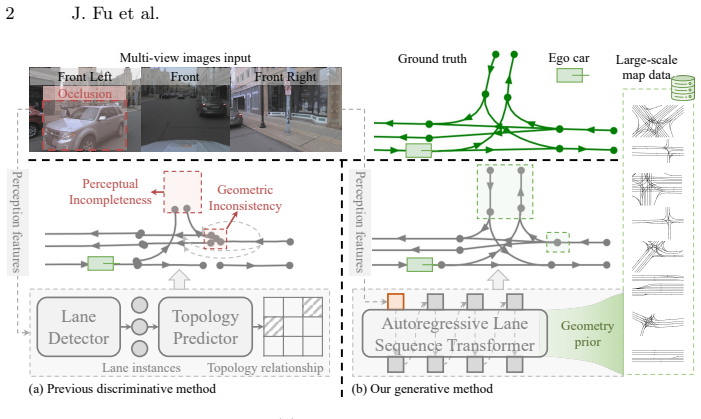
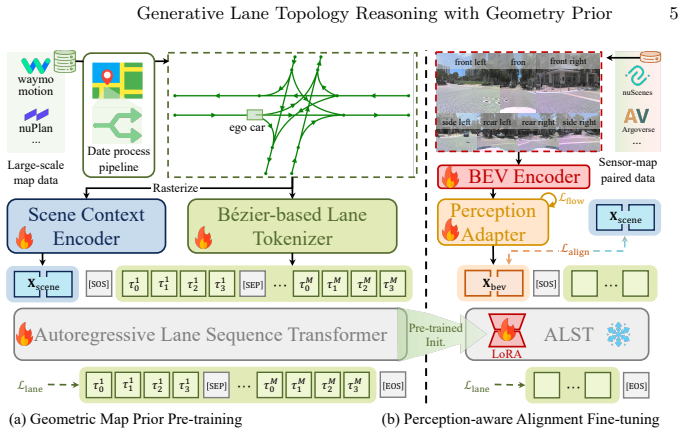
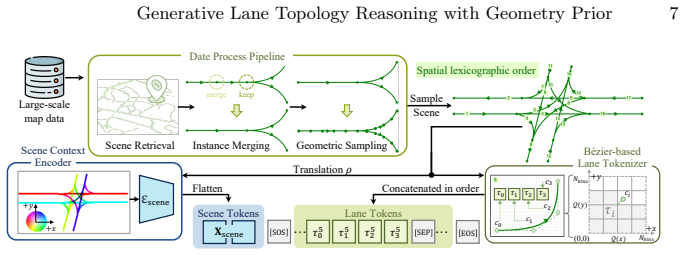
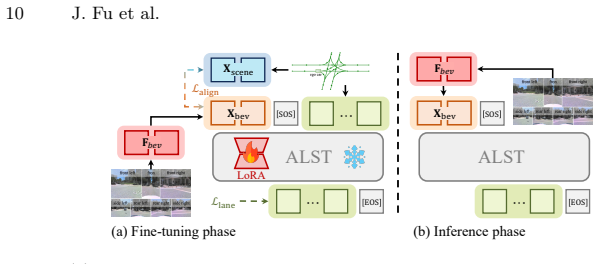
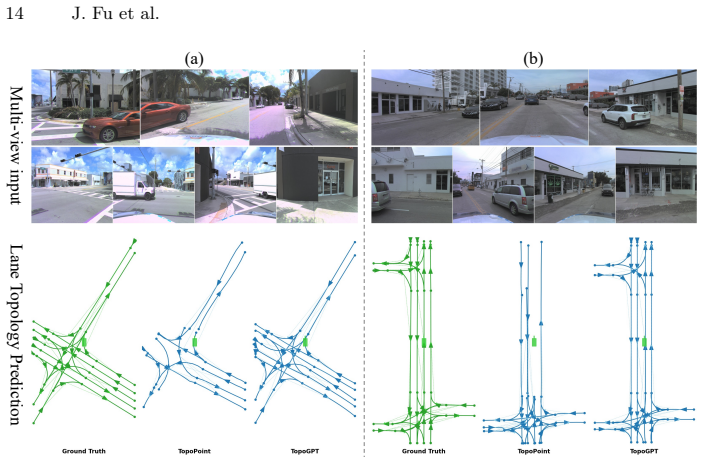
Pre-training an autoregressive lane sequence transformer on tokenized lane graphs from 3.3 million map scenes via scene-conditioned next-token prediction endows the model with a geometry prior over lane structures; a perception adapter then aligns BEV features extracted from multi-view images with the pre-trained scene condition, transferring the prior to produce lane graphs that are geometrically consistent at endpoints and structurally complete despite occlusions.
What carries the argument
Autoregressive lane sequence transformer pre-trained via scene-conditioned next-token prediction on tokenized lane graphs, plus a perception adapter that aligns BEV features to the pre-trained scene tokens.
If this is right
- Lane graphs exhibit geometric consistency at connected endpoints rather than independent per-lane errors.
- Graphs remain structurally complete even when individual lanes are occluded in the input images.
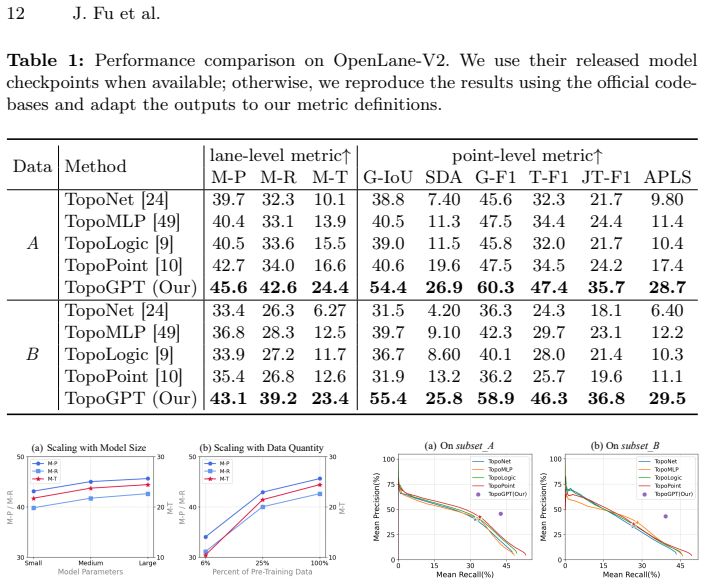
- Average performance rises by 6.4 points on lane-level metrics and 11.6 points on point-level metrics on OpenLane-V2.
- The same pre-training plus adaptation pipeline can be applied to other sensor modalities once their BEV features are aligned to the scene tokens.
Where Pith is reading between the lines
- Similar autoregressive pre-training on large map corpora could supply priors for other structured prediction tasks such as traffic-sign topology or drivable-area connectivity.
- The 3.3-million-scene map dataset may serve as a reusable resource for learning additional geometric or topological priors beyond lane graphs.
- Because generation is sequential, inference latency may increase with the number of lanes; parallel decoding or caching strategies would be needed for real-time use.
Load-bearing premise
The geometry prior learned from map data transfers effectively to real sensor observations through the perception adapter without major loss of effectiveness.
What would settle it
Training the same architecture from scratch on OpenLane-V2 without the 3.3-million-scene map pre-training step and measuring whether lane-level and point-level scores drop to the level of prior detection-association methods.
Figures

read the original abstract
Lane topology reasoning aims to construct a lane graph from onboard sensor observations. Existing methods follow a detection and association paradigm that treats each lane instance independently, leading to geometric inconsistency at connected endpoints and incomplete graphs due to visual occlusions. To address these issues, we propose TopoGPT, a generative framework that learns the geometry prior from typical lane graph structures through autoregressive sequence modeling. Specifically, we construct a large-scale map dataset comprising 3.3M scenes. For each lane graph, a lane tokenizer serializes it into discrete tokens, while a scene context encoder converts it into a rasterized image and extracts global features as scene tokens. We pre-train an autoregressive lane sequence transformer via scene-conditioned next-token prediction, endowing the model with the geometry prior over lane graph structures. Building upon this prior, a perception adapter aligns BEV features from multi-view images with the pre-trained scene condition, transferring the learned geometry prior to sensor-based lane graph prediction. On the OpenLane-V2 benchmark, TopoGPT outperforms existing methods by an average of +6.4 on lane-level and +11.6 on point-level metrics, and produces geometrically consistent and structurally complete lane graphs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TopoGPT, a generative framework for lane topology reasoning from onboard sensors. It pre-trains an autoregressive transformer on 3.3M map scenes via scene-conditioned next-token prediction after tokenizing lane graphs and encoding rasterized scene context, thereby learning a geometry prior over lane structures. A perception adapter then aligns BEV features extracted from multi-view images with the pre-trained scene conditioning to transfer the prior, yielding lane graphs that are claimed to be geometrically consistent and structurally complete. On OpenLane-V2 the method reports average gains of +6.4 on lane-level metrics and +11.6 on point-level metrics over prior detection-and-association baselines.
Significance. If the transfer of the autoregressive prior succeeds without substantial degradation, the work offers a principled way to mitigate endpoint inconsistency and occlusion-induced incompleteness that plague independent-lane detectors. The scale of the map pre-training corpus (3.3M scenes) and the explicit separation of prior learning from perception are notable strengths that could influence future topology-reasoning pipelines in autonomous driving.
major comments (2)
- [perception adapter and experimental results] The central claim that the learned geometry prior transfers effectively through the perception adapter rests on the assumption that adapter-aligned BEV features lie in the same token space as the rasterized map scene tokens. No ablation that isolates the contribution of the pre-trained autoregressive transformer from the adapter architecture or from other modeling choices is described; without such a control it remains unclear whether the reported +6.4 / +11.6 gains derive from the generative prior or from the adapter itself.
- [perception adapter] The manuscript states that the adapter 'aligns BEV features … with the pre-trained scene condition,' yet provides no quantitative measure (e.g., token-space distance, reconstruction error on held-out map scenes, or distribution-shift statistics) demonstrating that the alignment preserves the next-token prediction behavior learned during pre-training.
minor comments (2)
- [introduction / method overview] The abstract and introduction would benefit from an explicit statement of the lane tokenizer vocabulary size and the rasterization resolution used for scene context encoding.
- [figures] Figure captions should clarify whether the visualized lane graphs are produced by the full TopoGPT pipeline or by an oracle adapter; this affects interpretation of geometric consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the scale of our pre-training corpus and the separation of prior learning from perception. We address the two major comments below and will revise the manuscript to strengthen the evidence for the perception adapter.
read point-by-point responses
-
Referee: The central claim that the learned geometry prior transfers effectively through the perception adapter rests on the assumption that adapter-aligned BEV features lie in the same token space as the rasterized map scene tokens. No ablation that isolates the contribution of the pre-trained autoregressive transformer from the adapter architecture or from other modeling choices is described; without such a control it remains unclear whether the reported +6.4 / +11.6 gains derive from the generative prior or from the adapter itself.
Authors: We agree that an ablation isolating the pre-trained autoregressive transformer is required to substantiate the contribution of the geometry prior. In the revised manuscript we will add experiments that train the full pipeline from scratch (without map pre-training) and compare against the pre-trained TopoGPT, thereby quantifying how much of the reported gains is attributable to the transferred prior versus the adapter architecture alone. revision: yes
-
Referee: The manuscript states that the adapter 'aligns BEV features … with the pre-trained scene condition,' yet provides no quantitative measure (e.g., token-space distance, reconstruction error on held-out map scenes, or distribution-shift statistics) demonstrating that the alignment preserves the next-token prediction behavior learned during pre-training.
Authors: We acknowledge the absence of quantitative alignment diagnostics. In the revision we will report next-token prediction accuracy on held-out map scenes when the scene-conditioning tokens are replaced by adapter-aligned BEV features, together with a simple distribution-shift statistic (e.g., mean cosine distance in the token embedding space), to verify that the pre-trained next-token behavior is largely retained. revision: yes
Circularity Check
No significant circularity; derivation relies on external map pre-training and benchmark evaluation
full rationale
The paper pre-trains an autoregressive transformer on a separately constructed 3.3M-scene map dataset using scene-conditioned next-token prediction to learn a geometry prior, then applies a perception adapter to transfer it to BEV features from multi-view images. Evaluation occurs on the external OpenLane-V2 benchmark with reported gains of +6.4 lane-level and +11.6 point-level. No self-definitional steps, fitted inputs called predictions, load-bearing self-citations, or uniqueness theorems appear in the derivation chain; the adapter and benchmark provide independent transfer and measurement steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: CVPR (2023)
Büchner, M., Zürn, J., Todoran, I., Valada, A., Burgard, W.: Learning and aggre- gating lane graphs for urban automated driving. In: CVPR (2023)
2023
-
[2]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Caesar, H., Kabzan, J., Tan, K.S., Fong, W.K., Wolff, E.M., Lang, A.H., Fletcher, L., Beijbom, O., Omari, S.: nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
In: ICCV (2021) 16 J
Can, Y.B., Liniger, A., Paudel, D.P., Van Gool, L.: Structured bird’s-eye-view traffic scene understanding from onboard images. In: ICCV (2021) 16 J. Fu et al
2021
-
[4]
In: ICLR (2022)
Chen, T., Saxena, S., Li, L., Fleet, D.J., Hinton, G.E.: Pix2seq: A language mod- eling framework for object detection. In: ICLR (2022)
2022
-
[5]
In: ECCV (2024)
Chitta, K., Dauner, D., Geiger, A.: SLEDGE: synthesizing driving environments with generative models and rule-based traffic. In: ECCV (2024)
2024
-
[6]
In: ICCV (2021)
Ettinger, S., Cheng, S., Caine, B., Liu, C., Zhao, H., Pradhan, S., Chai, Y., Sapp, B., Qi, C.R., Zhou, Y., Yang, Z., Chouard, A., Sun, P., Ngiam, J., Vasudevan, V., McCauley, A., Shlens, J., Anguelov, D.: Large scale interactive motion forecasting for autonomous driving : The waymo open motion dataset. In: ICCV (2021)
2021
-
[7]
In: ICRA (2024)
Fu, J., Gao, C., Wang, Z., Yang, L., Wang, X., Mu, B., Liu, S.: Eliminating cross- modal conflicts in bev space for lidar-camera 3d object detection. In: ICRA (2024)
2024
-
[8]
In: CVPR (2025)
Fu, J., Gong, Y., Wang, L., Zhang, S., Zhou, X., Liu, S.: Generative map priors for collaborative bev semantic segmentation. In: CVPR (2025)
2025
-
[9]
In: NeurIPS (2024)
Fu, Y., Liao, W., Liu, X., Xu, H., Ma, Y., Zhang, Y., Dai, F.: Topologic: An interpretable pipeline for lane topology reasoning on driving scenes. In: NeurIPS (2024)
2024
-
[10]
In: NeurIPS (2025)
Fu, Y., Liu, X., Li, T., Ma, Y., Zhang, Y., Dai, F.: Topopoint: Enhance topology reasoning via endpoint detection in autonomous driving. In: NeurIPS (2025)
2025
-
[11]
In: ICRA (2024)
Gao, W., Fu, J., Shen, Y., Jing, H., Chen, S., Zheng, N.: Complementing onboard sensors with satellite maps: A new perspective for hd map construction. In: ICRA (2024)
2024
-
[12]
In: ECCV (2024)
Han, Y., Yu, K., Li, Z.: Continuity preserving online centerline graph learning. In: ECCV (2024)
2024
-
[13]
Harley, A.W., Fang, Z., Li, J., Ambrus, R., Fragkiadaki, K.: Simple-bev: What really matters for multi-sensor bev perception? In: ICRA (2023)
2023
-
[14]
In: ICCV (2025)
He, J., Yu, Q., Liu, Q., Chen, L.C.: Flowtok: Flowing seamlessly across text and image tokens. In: ICCV (2025)
2025
-
[15]
In: CVPR (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
2016
-
[16]
In: WACV (2022)
He, S., Balakrishnan, H.: Lane-level street map extraction from aerial imagery. In: WACV (2022)
2022
-
[17]
IEEE RAL (2025)
Jia, P., Luo, Z., Wen, T., Yang, M., Jiang, K., Cui, L., Yang, D.: Enhancing lane segment perception and topology reasoning with crowdsourcing trajectory priors. IEEE RAL (2025)
2025
-
[18]
IEEE RAL (2024)
Jia, P., Wen, T., Luo, Z., Yang, M., Jiang, K., Liu, Z., Tang, X., Lei, Z., Cui, L., Zhang, B., et al.: Diffmap: Enhancing map segmentation with map prior using diffusion model. IEEE RAL (2024)
2024
-
[19]
IEEE RAL (2024)
Jiang, Z., Zhu, Z., Li, P., Gao, H., Yuan, T., Shi, Y., Zhao, H., Zhao, H.: P-mapnet: Far-seeing map generator enhanced by both sdmap and hdmap priors. IEEE RAL (2024)
2024
-
[20]
In: ECCV (2024)
Le, D.T., Shi, H., Cai, J., Rezatofighi, H.: Diffusion model for robust multi-sensor fusion in 3d object detection and bev segmentation. In: ECCV (2024)
2024
-
[21]
IEEE TCSVT (2026)
Li, H., Gao, Y., Liu, S., Wang, Y., Liu, B., Mu, B.: Unified modeling of lane and lane topology for driving scene reasoning. IEEE TCSVT (2026)
2026
-
[22]
In: ACM MM (2025)
Li,H.,Huang,S.,Xu,L.,Gao,Y.,Mu,B.,Liu,S.:Ratopo:Improvinglanetopology reasoning via redundancy assignment. In: ACM MM (2025)
2025
-
[23]
arXiv preprint arXiv:2406.03105 (2024)
Li, H., Huang, Z., Wang, Z., Rong, W., Wang, N., Liu, S.: Enhancing 3d lane detec- tion and topology reasoning with 2d lane priors. arXiv preprint arXiv:2406.03105 (2024)
-
[24]
arXiv preprint arXiv:2304.05277 (2023) Generative Lane Topology Reasoning with Geometry Prior 17
Li, T., Chen, L., Wang, H., Li, Y., Yang, J., Geng, X., Jiang, S., Wang, Y., Xu, H., Xu, C., et al.: Graph-based topology reasoning for driving scenes. arXiv preprint arXiv:2304.05277 (2023) Generative Lane Topology Reasoning with Geometry Prior 17
-
[25]
In: ECCV (2024)
Liao, B., Chen, S., Jiang, B., Cheng, T., Zhang, Q., Liu, W., Huang, C., Wang, X.: Lane graph as path: Continuity-preserving path-wise modeling for online lane graph construction. In: ECCV (2024)
2024
-
[26]
In: CVPR (2025)
Liu, Q., Yin, X., Yuille, A.L., Brown, A., Singh, M.: Flowing from words to pixels: A noise-free framework for cross-modality evolution. In: CVPR (2025)
2025
-
[27]
In: ICML (2023)
Liu, Y., Yuan, T., Wang, Y., Wang, Y., Zhao, H.: Vectormapnet: End-to-end vec- torized hd map learning. In: ICML (2023)
2023
-
[28]
IEEE TPAMI (2025)
Lu, J., Nie, M., Zhang, B., Peng, R., Cai, X., Xu, H., Li, H., Wen, F., Zhang, W., Zhang, L.: Translating images to road network: A sequence-to-sequence perspec- tive. IEEE TPAMI (2025)
2025
-
[29]
In: ICCV (2023)
Lu, J., Peng, R., Cai, X., Xu, H., Li, H., Wen, F., Zhang, W., Zhang, L.: Translating images to road network: A non-autoregressive sequence-to-sequence approach. In: ICCV (2023)
2023
-
[30]
In: ICRA (2024)
Luo,K.Z.,Weng,X.,Wang,Y.,Wu,S.,Li,J.,Weinberger,K.Q.,Wang,Y.,Pavone, M.: Augmenting lane perception and topology understanding with standard defi- nition navigation maps. In: ICRA (2024)
2024
-
[31]
In: CVPR (2025)
Lv, C., Qi, M., Liu, L., Ma, H.: T2sg: Traffic topology scene graph for topology reasoning in autonomous driving. In: CVPR (2025)
2025
-
[32]
In: ECCV (2024)
Ma, Z., Liang, S., Wen, Y., Lu, W., Wan, G.: Roadpainter: Points are ideal navi- gators for topology transformer. In: ECCV (2024)
2024
-
[33]
In: IROS (2025)
Monninger, T., Zhang, Z., Mo, Z., Anwar, M.Z., Staab, S., Ding, S.: Mapdiffusion: Generative diffusion for vectorized online hd map construction and uncertainty estimation in autonomous driving. In: IROS (2025)
2025
-
[34]
IEEE RAL (2022)
Ort, T., Walls, J.M., Parkison, S.A., Gilitschenski, I., Rus, D.: Maplite 2.0: Online hd map inference using a prior sd map. IEEE RAL (2022)
2022
-
[35]
In: ICCV (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV (2023)
2023
-
[36]
IEEE RAL (2025)
Pei, M., Shan, J., Li, P., Shi, J., Huo, J., Gao, Y., Shen, S.: SEPT: standard- definition map enhanced scene perception and topology reasoning for autonomous driving. IEEE RAL (2025)
2025
-
[37]
In: AAAI (2024)
Peng, R., Cai, X., Xu, H., Lu, J., Wen, F., Zhang, W., Zhang, L.: Lanegraph2seq: Lane topology extraction with language model via vertex-edge encoding and con- nectivity enhancement. In: AAAI (2024)
2024
-
[38]
In: IROS (2025)
Pham, K.S., Witte, C., Behley, J., Betz, J., Stachniss, C.: Coherent online road topology estimation and reasoning with standard-definition maps. In: IROS (2025)
2025
-
[39]
In: ACM MM (2024)
Rong, F., Peng, W., Lan, M., Zhang, Q., Zhang, L.: Driving scene understanding with traffic scene-assisted topology graph transformer. In: ACM MM (2024)
2024
-
[40]
In: CVPR (2025)
Rowe, L., Girgis, R., Gosselin, A., Paull, L., Pal, C., Heide, F.: Scenario dreamer: Vectorized latent diffusion for generating driving simulation environments. In: CVPR (2025)
2025
-
[41]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
In: NeurIPS (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: NeurIPS (2017)
2017
-
[43]
In: NeurIPS (2023)
Wang, H., Li, T., Li, Y., Chen, L., Sima, C., Liu, Z., Wang, B., Jia, P., Wang, Y., Jiang, S., Wen, F., Xu, H., Luo, P., Yan, J., Zhang, W., Li, H.: Openlane-v2: A topology reasoning benchmark for unified 3d HD mapping. In: NeurIPS (2023)
2023
-
[44]
In: NeurIPS (2024) 18 J
Wang, L., Zhao, Y., Zhang, Z., Feng, J., Liu, S., Kang, B.: Image understanding makes for a good tokenizer for image generation. In: NeurIPS (2024) 18 J. Fu et al
2024
-
[45]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
In: ICCV (2025)
Wang, Z., Zhang, W., Zhang, W., Tan, X., Liu, H., Wang, Y., Li, G.: Lanediffusion: Improving centerline graph learning via prior injected BEV feature generation. In: ICCV (2025)
2025
-
[47]
In: ICCV (2023)
Wang, Z., Huang, Z., Fu, J., Wang, N., Liu, S.: Object as query: Lifting any 2d object detector to 3d detection. In: ICCV (2023)
2023
-
[48]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Wilson, B., Qi, W., Agarwal, T., Lambert, J., Singh, J., Khandelwal, S., Pan, B., Kumar, R., Hartnett, A., Pontes, J.K., et al.: Argoverse 2: Next generation datasets for self-driving perception and forecasting. arXiv preprint arXiv:2301.00493 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
In: ICLR (2024)
Wu, D., Chang, J., Jia, F., Liu, Y., Wang, T., Shen, J.: Topomlp: A simple yet strong pipeline for driving topology reasoning. In: ICLR (2024)
2024
-
[50]
In: ICCV (2025)
Xie, M., Zeng, S., Chang, X., Liu, X., Pan, Z., Xu, M., Wei, X.: Seqgrowgraph: Learning lane topology as a chain of graph expansions. In: ICCV (2025)
2025
-
[51]
In: ICRA (2023)
Xu, Z., Liu, Y., Sun, Y., Liu, M., Wang, L.: Centerlinedet: Centerline graph de- tection for road lanes with vehicle-mounted sensors by transformer for hd map generation. In: ICRA (2023)
2023
-
[52]
In: AAAI (2025)
Yang, Y., Luo, Y., He, B., Li, E., Cao, Z., Zheng, C., Mei, S., Li, Z.: Topo2seq: Enhanced topology reasoning via topology sequence learning. In: AAAI (2025)
2025
-
[53]
In: ICRA (2025)
Ye, J., Paz, D., Zhang, H., Guo, Y., Huang, X., Christensen, H.I., Wang, Y., Ren, L.: Smart: Advancing scalable map priors for driving topology reasoning. In: ICRA (2025)
2025
-
[54]
arXiv preprint arXiv:2409.05352 (2024)
Zeng, S., Chang, X., Liu, X., Yuan, Y., Liang, S., Pan, Z., Xu, M., Wei, X.: Pri- ordrive: Enhancing online hd mapping with unified vector priors. arXiv preprint arXiv:2409.05352 (2024)
-
[55]
In: ICCV (2023)
Zhu, X., Zyrianov, V., Liu, Z., Wang, S.: Mapprior: Bird’s-eye view map layout estimation with generative models. In: ICCV (2023)
2023
-
[56]
IEEE RAL (2021)
Zürn, J., Vertens, J., Burgard, W.: Lane graph estimation for scene understanding in urban driving. IEEE RAL (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.