RESOLVE: A Multi-Resolution and Multi-Modal Dataset for Roadside Cooperative Perception
Pith reviewed 2026-07-01 05:44 UTC · model grok-4.3
The pith
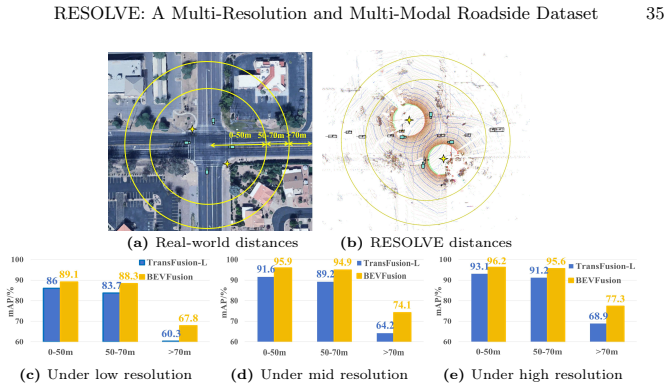
RESOLVE dataset enables controlled tests of roadside 3D perception across three fixed LiDAR resolutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RESOLVE supplies synchronized multi-resolution LiDAR and camera data from roadside views along with manual annotations to enable systematic evaluation of unimodal and fusion architectures for 3D detection and tracking under controlled point sparsity shifts.
What carries the argument
The RESOLVE dataset's three fixed LiDAR resolution levels captured with otherwise identical sensing parameters, cameras, and scene conditions.
If this is right
- Multimodal fusion recovers detection performance lost to reduced LiDAR point density.
- Architectures can be compared without confounding from uncontrolled resolution changes.
- Designers can directly assess cost savings from deploying lower-resolution roadside sensors.
- Effects of training at one resolution and inferring at another become measurable.
- Performance trends hold across detection, tracking, and diverse lighting or weather.
Where Pith is reading between the lines
- The same fixed-factor collection approach could be repeated with added radar or different intersection layouts to test broader generalizability.
- The released benchmark code makes it straightforward to evaluate new models on the existing resolution variants.
- Insights on sparsity compensation could inform sensor fusion choices in vehicle-to-infrastructure networks beyond this single site.
- Similar controlled multi-resolution captures might reveal whether the observed fusion benefits transfer to other perception tasks such as segmentation.
Load-bearing premise
The 220,000 manual bounding box annotations remain accurate and consistent when the same scenes are captured at different LiDAR resolutions and under changing conditions.
What would settle it
Re-annotating a held-out subset of frames using only the lowest-resolution point clouds and finding average IoU agreement below 0.7 with the original labels.
Figures
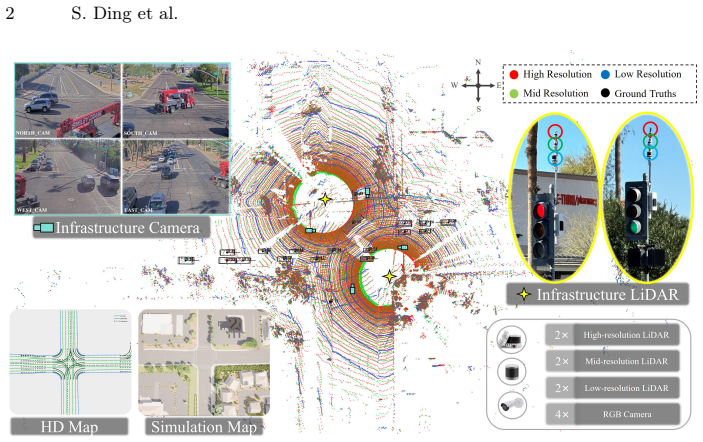
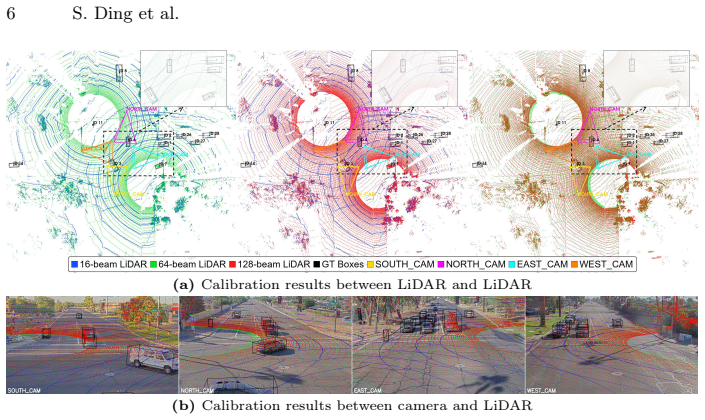
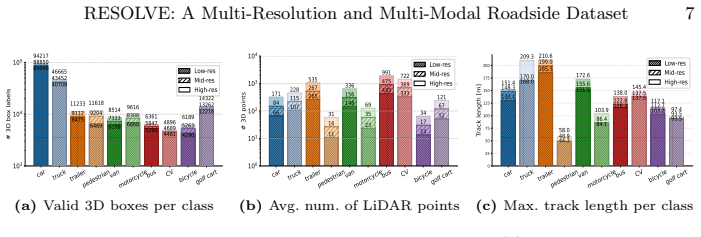
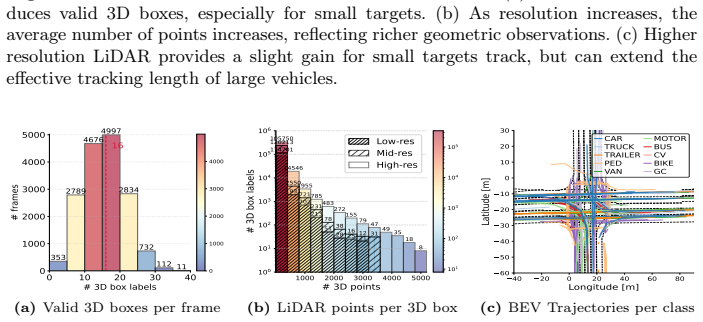
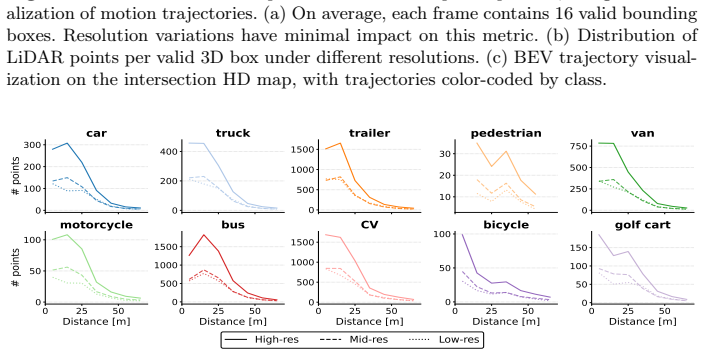
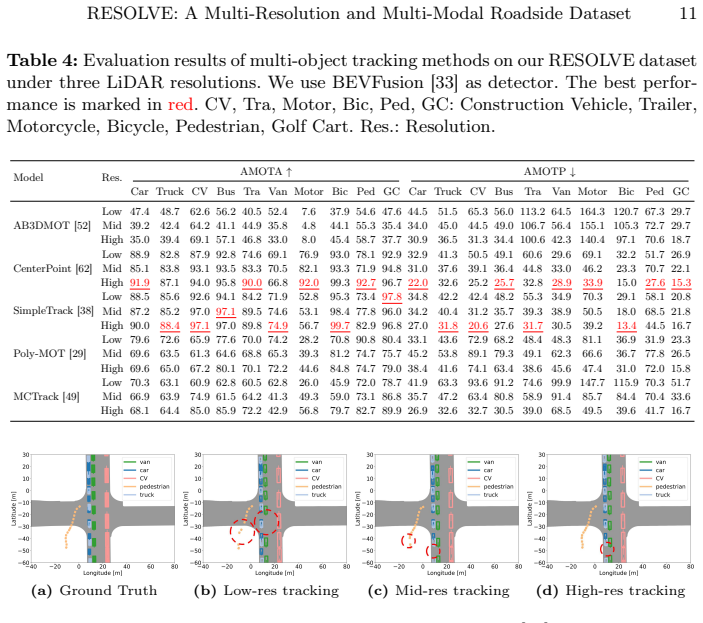
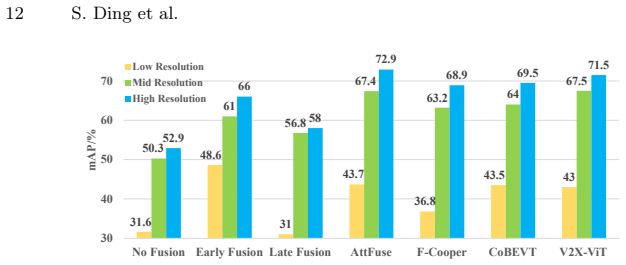
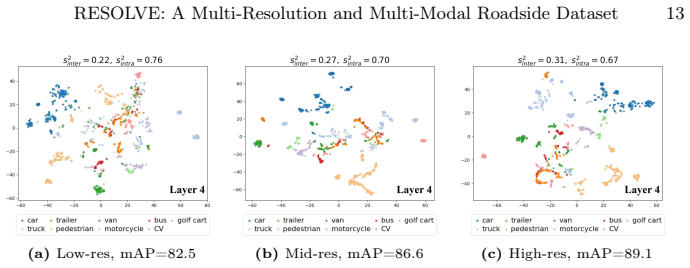
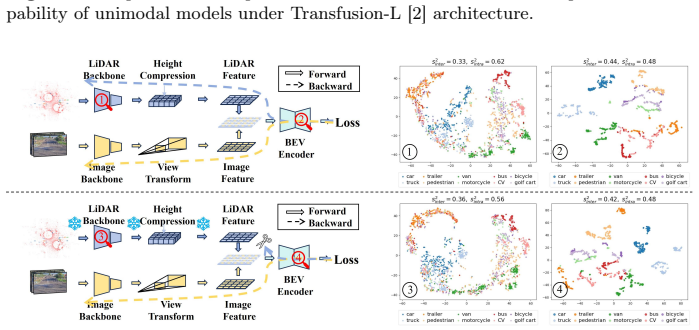
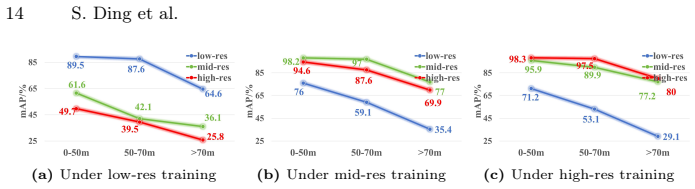








read the original abstract
LiDAR has increasingly been integrated into traffic cameras to expand coverage and mitigate occlusion in roadside cooperative perception. However, how unimodal and camera-LiDAR fusion architectures behave under variations in LiDAR point sparsity induced by sensor configurations and scene-dependent sensing conditions remains underexplored. We introduce RESOLVE, a large-scale real-world benchmark dataset featuring multi-resolution roadside LiDAR and synchronized camera-LiDAR sensing for systematic evaluation of unimodal and fusion-based architectures in roadside 3D detection and tracking. RESOLVE contains over 100k images and 26k point cloud frames with 220k manually annotated bounding boxes, captured at a real-world urban intersection across diverse lighting and weather conditions and spanning 10 classes of traffic participants. In particular, RESOLVE enables controlled evaluation across three LiDAR resolution levels while keeping all other sensing and environmental factors fixed. This allows fair cross-architecture comparisons under point cloud distribution shifts resulting from resolution variations, sensing distance, and training-inference resolution mismatches. Results from extensive benchmark experiments reveal insights into how multimodal fusion can compensate for LiDAR point sparsity, offering clues for designing cost-efficient roadside multimodal perception. The dataset and benchmark codes are available at https://github.com/ASU-Suo-Lab/RESOLVE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RESOLVE, a real-world roadside dataset with synchronized multi-resolution LiDAR (three levels) and camera data captured at an urban intersection under varied lighting/weather. It contains >100k images, 26k point-cloud frames, and 220k manually annotated 3D bounding boxes across 10 classes. The central claim is that the dataset supports controlled evaluation of unimodal and camera-LiDAR fusion architectures for 3D detection/tracking by varying only LiDAR resolution while fixing all other sensing and environmental factors, thereby isolating distribution-shift effects; benchmark experiments and public code/data release are also provided.
Significance. A dataset enabling controlled isolation of LiDAR resolution effects in roadside cooperative perception would be a useful addition to the field, particularly given the public release of data and benchmark code. If annotation consistency across resolutions can be verified, the resource would support reproducible cross-architecture comparisons under realistic point-density shifts and training-inference mismatches.
major comments (1)
- [Abstract] Abstract and dataset description: The claim that RESOLVE 'enables controlled evaluation across three LiDAR resolution levels while keeping all other sensing and environmental factors fixed' is load-bearing for the paper's contribution. However, no information is supplied on the annotation protocol for the 220k boxes—specifically, whether boxes were annotated independently on each resolution's point cloud, propagated from the highest-resolution scan, or adjusted per resolution. No inter-resolution agreement statistics, inter-annotator agreement, or per-resolution quality metrics are reported. Without these, performance differences cannot be unambiguously attributed to resolution-induced distribution shift.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concern about the annotation protocol below and will revise the manuscript accordingly to strengthen the support for our central claim.
read point-by-point responses
-
Referee: [Abstract] Abstract and dataset description: The claim that RESOLVE 'enables controlled evaluation across three LiDAR resolution levels while keeping all other sensing and environmental factors fixed' is load-bearing for the paper's contribution. However, no information is supplied on the annotation protocol for the 220k boxes—specifically, whether boxes were annotated independently on each resolution's point cloud, propagated from the highest-resolution scan, or adjusted per resolution. No inter-resolution agreement statistics, inter-annotator agreement, or per-resolution quality metrics are reported. Without these, performance differences cannot be unambiguously attributed to resolution-induced distribution shift.
Authors: We agree that the manuscript does not currently supply details on the annotation protocol across resolutions, inter-annotator agreement, or per-resolution quality metrics. This information is necessary to fully support the claim of controlled evaluation by isolating resolution effects. In the revised manuscript we will add a dedicated subsection describing the annotation process (including whether annotations were performed independently per resolution or propagated with adjustments), along with the requested agreement and quality statistics. These additions will enable readers to assess attribution of performance differences to distribution shift. revision: yes
Circularity Check
No derivation chain present; dataset release only
full rationale
The manuscript introduces a multi-resolution roadside perception dataset and benchmark protocol. No equations, fitted parameters, predictions, or first-principles derivations appear in the abstract or described full text. Claims about controlled evaluation rest on the physical data collection and manual annotation process rather than any self-referential construction. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results occur. This is the expected 0 outcome for a data-release paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manual bounding-box annotations are sufficiently accurate and consistent for quantitative benchmarking across sensor resolutions.
Reference graph
Works this paper leans on
-
[1]
Ahmad, F., Shin, C.S., Pang, W., Leong, B., Ghosh, P., Govindan, R.: Coopera- tive infrastructure perception. In: Ninth IEEE/ACM International Conference on Internet-of-Things Design and Implementation, IoTDI 2024, Hong Kong, May 13- 16, 2024. pp. 61–72 (2024).https://doi.org/10.1109/IOTDI61053.2024.00010
-
[2]
Bai, X., Hu, Z., Zhu, X., Huang, Q., Chen, Y., Fu, H., Tai, C.: Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 1080–1089 (2022).https://doi.org/10.1109/ CVPR52688.2022.00116
-
[3]
In: 2022 IEEE 25th International Conference on Intelligent Trans- portation Systems (ITSC)
Bai, Z., Wu, G., Barth, M.J., Liu, Y., Sisbot, E.A., Oguchi, K.: Pillargrid: Deep learning-based cooperative perception for 3d object detection from onboard- roadside lidar. In: 2022 IEEE 25th International Conference on Intelligent Trans- portation Systems (ITSC). p. 1743–1749. IEEE (Oct 2022).https://doi.org/10. 1109/itsc55140.2022.9921947
-
[4]
Bai, Z., Wu, G., Barth, M.J., Liu, Y., Sisbot, E.A., Oguchi, K.: Vinet: Lightweight, scalable, and heterogeneous cooperative perception for 3d object detection. Me- chanical Systems and Signal Processing204, 110723 (2023).https://doi.org/ 10.1016/j.ymssp.2023.110723
-
[5]
Besl, P.J., McKay, N.D.: Method for registration of 3-D shapes. In: Schenker, P.S. (ed.) Sensor Fusion IV: Control Paradigms and Data Structures. vol. 1611, pp. 586 – 606. International Society for Optics and Photonics, SPIE (1992).https: //doi.org/10.1117/12.57955
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
2020
-
[7]
Cai, X., Jiang, W., Xu, R., Zhao, W., Ma, J., Liu, S., Li, Y.: Analyzing infrastruc- ture lidar placement with realistic lidar simulation library. In: 2023 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 5581–5587 (2023). https://doi.org/10.1109/ICRA48891.2023.10161027
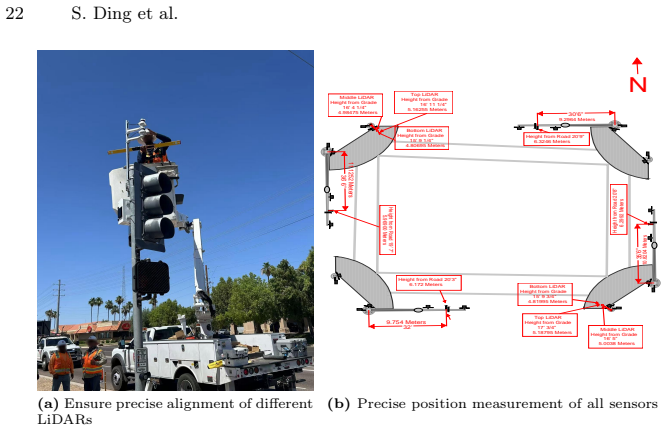
-
[8]
In: Proceedings of the 4th ACM/IEEE Symposium on Edge Com- puting
Chen, Q., Ma, X., Tang, S., Guo, J., Yang, Q., Fu, S.: F-cooper: feature based cooperative perception for autonomous vehicle edge computing system using 3d point clouds. In: Proceedings of the 4th ACM/IEEE Symposium on Edge Com- puting. p. 88–100. SEC ’19, Association for Computing Machinery, New York, NY, USA (2019),https://doi.org/10.1145/3318216.3363300
-
[9]
Contributors, M.: MMDetection3D: OpenMMLab next-generation platform for general 3D object detection.https://github.com/open- mmlab/mmdetection3d (2020), accessed: 25 Jun 2026
2020
-
[10]
Corral-Soto, E.R., Grandhi, A., He, Y.Y., Rochan, M., Liu, B.: Improving lidar 3d object detection via range-based point cloud density optimization (2023),https: //arxiv.org/abs/2306.05663, accessed: 25 Jun 2026 16 S. Ding et al
-
[11]
Creß,C.,Bing,Z.,Knoll,A.C.:Intelligenttransportationsystemsusingroadsidein- frastructure: A literature survey. IEEE Transactions on Intelligent Transportation Systems25(7), 6309–6327 (2024).https://doi.org/10.1109/TITS.2023.3343434
-
[12]
Official Journal of the European Union, L 119, 4 May 2016, pp
European Parliament and Council of the European Union: Regulation (eu) 2016/679 of the european parliament and of the council of 27 april 2016 (general data protection regulation). Official Journal of the European Union, L 119, 4 May 2016, pp. 1–88 (2016),https://eur-lex.europa.eu/eli/reg/2016/679/oj/eng, cELEX: 32016R0679; accessed 25 Jun 2026
2016
-
[13]
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The KITTI dataset. Int. J. Robotics Res.32(11), 1231–1237 (2013).https://doi.org/10. 1177/0278364913491297
2013
-
[14]
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces (2024),https://arxiv.org/abs/2312.00752, accessed: 25 Jun 2026
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Hadgi, S., Li, L., Ovsjanikov, M.: To supervise or not to supervise: Understanding and addressing the key challenges of point cloud transfer learning. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29- October 4, 2024, Proceedings, Part LXXVIII. pp. 146–163 (2024).https://doi. org/10.1007/978-3-031-73229-4_9
-
[16]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hao, R., Fan, S., Dai, Y., Zhang, Z., Li, C., Wang, Y., Yu, H., Yang, W., Yuan, J., Nie, Z.: Rcooper: A real-world large-scale dataset for roadside cooperative per- ception. In: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 22347–22357 (2024). https://doi.org/10.1109/CVPR52733.2024.02109
-
[17]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24,
He, C., Li, R., Li, S., Zhang, L.: Voxel set transformer: A set-to-set approach to 3d object detection from point clouds. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24,
2022
-
[18]
pp. 8407–8417 (2022).https://doi.org/10.1109/CVPR52688.2022.00823
-
[19]
He, Y., Cao, P., Suo, D., Liu, X.: A joint optimization of beam distribution and de- ployment for roadside lidar systems to maximize vehicle perception. IEEE Transac- tions on Intelligent Vehicles10(2), 1300–1314 (2025).https://doi.org/10.1109/ TIV.2024.3426524
-
[20]
Hu,J.S.K.,Kuai,T.,Waslander,S.L.:Pointdensity-awarevoxelsforlidar3dobject detection. In: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 8459–8468 (2022). https://doi.org/10.1109/CVPR52688.2022.00828
-
[21]
In���� �������� ���������� �� �������� ������ ��� ������� ����������� ������
Hu, Q., Liu, D., Hu, W.: Density-insensitive unsupervised domain adaption on 3d object detection. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 17556– 17566 (2023).https://doi.org/10.1109/CVPR52729.2023.01684
-
[22]
In: The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Hu, Y., Lu, Y., Xu, R., Xie, W., Chen, S., Wang, Y.: Collaboration helps camera overtake lidar in 3d detection. In: The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
- [23]
-
[24]
Jiang, W., Xiang, H., Cai, X., Xu, R., Ma, J., Li, Y., Lee, G.H., Liu, S.: Optimiz- ing the placement of roadside lidars for autonomous driving. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 18335–18344 (2023). https://doi.org/10.1109/ICCV51070.2023.01685 RESOLVE: A Multi-Resolution and Multi-Modal Roadside Dataset 17
-
[25]
Field Robotics2, 1156–1176 (2022).https://doi.org/10.55417/fr.2022038
Krammer, A., Schöller, C., Gulati, D., Lakshminarasimhan, V., Kurz, F., Rosen- baum, D., Lenz, C., Knoll, A.: Providentia — a large-scale sensor system for the assistance of autonomous vehicles and its evaluation. Field Robotics2, 1156–1176 (2022).https://doi.org/10.55417/fr.2022038
-
[26]
In: 50 Years of Integer Programming 1958-2008 - From the Early Years to the State-of-the-Art, pp
Kuhn, H.W.: The hungarian method for the assignment problem. In: 50 Years of Integer Programming 1958-2008 - From the Early Years to the State-of-the-Art, pp. 29–47. Springer (2010).https://doi.org/10.1007/978-3-540-68279-0_2
-
[27]
In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20,
Lang, A.H., Vora, S., Caesar, H., Zhou, L., Yang, J., Beijbom, O.: Pointpillars: Fast encoders for object detection from point clouds. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20,
2019
-
[28]
12697–12705 (2019).https://doi.org/10.1109/CVPR.2019.01298
pp. 12697–12705 (2019).https://doi.org/10.1109/CVPR.2019.01298
-
[29]
Li, H., Cao, B., Liang, Z., Li, W., Oh, J., Chen, Y., Liang, S., Zhou, H., Ma, C., Liu, J., Li, Z., Zhang, P., Long, K., Liu, M., Jiang, J., Yu, C., Liu, S., Yu, H., Li, X.: Cats-v2v: A real-world vehicle-to-vehicle cooperative perception dataset with complex adverse traffic scenarios (2025),https://arxiv.org/abs/2511.11168, accessed: 25 Jun 2026
-
[30]
Li, S., Ma, L., Li, X.: Domain generalization of 3d object detection by density- resampling. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LXIV. pp. 456–473 (2024). https://doi.org/10.1007/978-3-031-73039-9_26
-
[31]
In: 2023 IEEE/RSJ Interna- tionalConferenceonIntelligentRobotsandSystems(IROS).pp.7742–7749(2023)
Li, X., Xie, T., Liu, D., Gao, J., Dai, K., Jiang, Z., Zhao, L., Wang, K.: Poly- mot: A polyhedral framework for 3d multi-object tracking. In: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 9391– 9398 (2023).https://doi.org/10.1109/IROS55552.2023.10341778
-
[32]
Scott Armstrong, ed.Expert Opinions in Forecasting: The Role of the Delphi Technique
Liu, C., Zhu, M., Ma, C.: H-v2x: A large scale highway dataset for bev percep- tion. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part I. Lecture Notes in Computer Science, vol. 15059, pp. 139–157. Springer (2024).https://doi.org/10.1007/978- 3-031-73232-4_8
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Liu, C., Zhu, M., Zhang, Z., Song, L., Zhao, X., Luo, Q., Wang, Q., Guo, C., Su, K.: Tad-e2e: A large-scale end-to-end autonomous driving dataset. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 26600– 26609 (October 2025)
2025
-
[34]
Liu, Z., Hou, J., Wang, X., Ye, X., Wang, J., Zhao, H., Bai, X.: LION: linear group RNN for 3d object detection in point clouds. In: Advances in Neural Informa- tion Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 (2024)
2024
-
[35]
Liu, Z., Tang, H., Amini, A., Yang, X., Mao, H., Rus, D.L., Han, S.: Bevfu- sion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In: IEEE International Conference on Robotics and Automation, ICRA 2023, London, UK, May 29 - June 2, 2023. pp. 2774–2781 (2023).https://doi.org/10.1109/ ICRA48891.2023.10160968
-
[36]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22,
Ma, C., Qiao, L., Zhu, C., Liu, K., Kong, Z., Li, Q., Zhou, X., Kan, Y., Wu, W.: Holovic: Large-scale dataset and benchmark for multi-sensor holographic intersec- tion and vehicle-infrastructure cooperative. In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22,
2024
-
[37]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
pp. 22129–22138 (2024).https://doi.org/10.1109/CVPR52733.2024.02089
-
[38]
Journal of Machine Learning Research9, 2579–2605 (11 2008) 18 S
van der Maaten, L., Hinton, G., Rachmad, Y.: Visualizing data using t-sne. Journal of Machine Learning Research9, 2579–2605 (11 2008) 18 S. Ding et al
2008
-
[39]
Science Robotics7(66), eabm6074 (2022).https://doi.org/10.1126/scirobotics.abm6074
Macenski, S., Foote, T., Gerkey, B., Lalancette, C., Woodall, W.: Robot operat- ing system 2: Design, architecture, and uses in the wild. Science Robotics7(66), eabm6074 (2022).https://doi.org/10.1126/scirobotics.abm6074
-
[40]
society for industrial & applied mathematics (2004)
Madsen, K., Nielsen, H.B., Tingleff, O.: Methods for non-linear least squares prob- lems (2nd ed.). society for industrial & applied mathematics (2004)
2004
-
[41]
Pang, Z., Li, Z., Wang, N.: Simpletrack: Understanding and rethinking 3d multi- object tracking. In: Computer Vision - ECCV 2022 Workshops - Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part I. pp. 680–696 (2022).https://doi.org/ 10.1007/978-3-031-25056-9_43
-
[42]
In: 2023 IEEE 26th International Con- ference on Intelligent Transportation Systems (ITSC)
Qu, A., Huang, X., Suo, D.: Seip: Simulation-based design and evaluation of infrastructure-based collective perception. In: 2023 IEEE 26th International Con- ference on Intelligent Transportation Systems (ITSC). pp. 3871–3878 (2023). https://doi.org/10.1109/ITSC57777.2023.10422006
- [43]
-
[44]
Sekaran, K.C., Geisler, M., Rößle, D., Mohan, A., Cremers, D., Utschick, W., Botsch,M.,Huber,W.,Schön,T.:Urbaning-v2x:Alarge-scalemulti-vehicle,multi- infrastructure dataset across multiple intersections for cooperative perception. In: Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2025, Ne...
2025
-
[45]
Momentum Contrast for Unsupervised Visual Representation Learning
Sun,P.,Kretzschmar,H.,Dotiwalla,X.,Chouard,A.,Patnaik,V.,Tsui,P.,Guo,J., Zhou, Y., Chai, Y., Caine, B., Vasudevan, V., Han, W., Ngiam, J., Zhao, H., Timo- feev, A., Ettinger, S., Krivokon, M., Gao, A., Joshi, A., Zhang, Y., Shlens, J., Chen, Z., Anguelov, D.: Scalability in perception for autonomous driving: Waymo open dataset. In: 2020 IEEE/CVF Conferenc...
-
[46]
Team, O.D.: Openpcdet: An open-source toolbox for 3d object detection from point clouds.https://github.com/open-mmlab/OpenPCDet(2020), accessed: 25 Jun 2026
2020
-
[47]
In: Proceedings of the 31st International Conference on Neural Information Processing Systems
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. p. 6000–6010. NIPS’17, Curran Associates Inc., Red Hook, NY, USA (2017)
2017
-
[48]
Wang, B., Meng, S., Zhang, L., Wang, C., Huang, J., Li, Y., Ren, H., Xiao, Y., Peng, Y., Ji, J., Zhang, Y., Zhang, Y.: Corp: A multi-modal dataset for campus- oriented roadside perception tasks (2024),https://arxiv.org/abs/2404.03191, accessed: 25 Jun 2026
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, H., Shi, C., Shi, S., Lei, M., Wang, S., He, D., Schiele, B., Wang, L.: DSVT: dynamic sparse voxel transformer with rotated sets. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 13520–13529 (2023).https://doi.org/10.1109/CVPR52729. 2023.01299
-
[50]
Wang, H., Tang, H., Shi, S., Li, A., Li, Z., Schiele, B., Wang, L.: Unitr: A uni- fied and efficient multi-modal transformer for bird’s-eye-view representation. In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 6769–6779 (2023).https://doi.org/10.1109/ ICCV51070.2023.00625 RESOLVE: A Multi-Resolutio...
-
[51]
In: 2022 In- ternational Conference on Robotics and Automation (ICRA)
Wang, H., Zhang, X., Li, Z., Li, J., Wang, K., Lei, Z., Haibing, R.: Ips300+: a challenging multi-modal data sets for intersection perception system. In: 2022 In- ternational Conference on Robotics and Automation (ICRA). p. 2539–2545 (2022). https://doi.org/10.1109/ICRA46639.2022.9811699
-
[52]
In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Wang, X., Qi, S., Zhao, J., Zhou, H., Zhang, S., Wang, G., Tu, K., Guo, S., Zhao, J., Li,J.,Qin,H.,Yang,M.:Mctrack:Aunified3dmulti-objecttrackingframeworkfor autonomous driving. In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 4551–4558 (2025).https://doi.org/10.1109/ IROS60139.2025.11245874
-
[53]
In: 2025 IEEE/CVF International Con- ference on Computer Vision (ICCV)
Wei, S., Luo, C., Luo, Y.: Boosting multimodal learning via disentangled gra- dient learning. In: IEEE/CVF International Conference on Computer Vision, ICCV 2025, Honolulu, HI, USA, October 19-25, 2025. pp. 1–10 (2025).https: //doi.org/10.1109/ICCV51701.2025.02124
-
[54]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Wei, Y., Wei, Z., Rao, Y., Li, J., Zhou, J., Lu, J.: Lidar distillation: Bridging the beam-induced domain gap for 3d object detection. In: Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceed- ings, Part XXXIX. pp. 179–195 (2022).https://doi.org/10.1007/978-3-031- 19842-7_11
-
[55]
In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Weng, X., Wang, J., Held, D., Kitani, K.: 3d multi-object tracking: A baseline and new evaluation metrics. In: IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2020, Las Vegas, NV, USA, October 24, 2020 - January 24, 2021. pp. 10359–10366 (2020).https://doi.org/10.1109/IROS45743.2020. 9341164
-
[56]
Xiang, H., Zheng, Z., Xia, X., Xu, R., Gao, L., Zhou, Z., Han, X., Ji, X., Li, M., Meng, Z., Jin, L., Lei, M., Ma, Z., He, Z., Ma, H., Yuan, Y., Zhao, Y., Ma, J.: V2x-real: A large-scale dataset for vehicle-to-everything cooperative per- ception. In: Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceed...
-
[57]
IEEE Transactions on Multimedia26, 5536–5547 (2024).https://doi.org/10.1109/TMM.2023.3335879
Xiao, A., Guan, D., Zhang, X., Lu, S.: Domain adaptive lidar point cloud segmenta- tion with 3d spatial consistency. IEEE Transactions on Multimedia26, 5536–5547 (2024).https://doi.org/10.1109/TMM.2023.3335879
-
[58]
In: Conference on Robot Learning, CoRL 2022, 14-18 December 2022, Auckland, New Zealand
Xu, R., Tu, Z., Xiang, H., Shao, W., Zhou, B., Ma, J.: Cobevt: Cooperative bird’s eye view semantic segmentation with sparse transformers. In: Conference on Robot Learning, CoRL 2022, 14-18 December 2022, Auckland, New Zealand. pp. 989– 1000 (2022),https://proceedings.mlr.press/v205/xu23a.html, accessed: 25 Jun 2026
2022
-
[59]
In: The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) (2023)
Xu, R., Xia, X., Li, J., Li, H., Zhang, S., Tu, Z., Meng, Z., Xiang, H., Dong, X., Song, R., Yu, H., Zhou, B., Ma, J.: V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception. In: The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) (2023)
2023
-
[60]
Xu, R., Xiang, H., Tu, Z., Xia, X., Yang, M., Ma, J.: V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. In: Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXXIX. pp. 107–124 (2022).https://doi.org/10.1007/978-3-031-19842- 7_7
-
[61]
In: 2022 In- ternational Conference on Robotics and Automation (ICRA)
Xu, R., Xiang, H., Xia, X., Han, X., Li, J., Ma, J.: OPV2V: an open bench- mark dataset and fusion pipeline for perception with vehicle-to-vehicle commu- nication. In: 2022 International Conference on Robotics and Automation, ICRA 20 S. Ding et al. 2022, Philadelphia, PA, USA, May 23-27, 2022. pp. 2583–2589 (2022).https: //doi.org/10.1109/ICRA46639.2022.9812038
-
[62]
Sen- sors18(10) (2018).https://doi.org/10.3390/s18103337
Yan, Y., Mao, Y., Li, B.: Second: Sparsely embedded convolutional detection. Sen- sors18(10) (2018).https://doi.org/10.3390/s18103337
-
[63]
Advances in Neural Information Processing Systems (NeurIPS) (2025)
Yang, L., Zhang, X., Li, J., Wang, C., Ma, J., Song, Z., Zhao, T., Song, Z., Wang, L., Zhou, M., Shen, Y., Lv, C.: V2x-radar: A multi-modal dataset with 4d radar for cooperative perception. Advances in Neural Information Processing Systems (NeurIPS) (2025)
2025
-
[64]
Ye, X., Shu, M., Li, H., Shi, Y., Li, Y., Wang, G., Tan, X., Ding, E.: Rope3D: The Roadside Perception Dataset for Autonomous Driving and Monocular 3D Object Detection Task. In: Conference on Computer Vision and Pattern Recognition. pp. 21341–21350 (2022).https://doi.org/10.1109/CVPR52688.2022.02065
-
[65]
In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021
Yin, T., Zhou, X., Krähenbühl, P.: Center-based 3d object detection and tracking. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. pp. 11784–11793 (2021).https://doi.org/10.1109/ CVPR46437.2021.01161
-
[66]
Yongqiang, D., Dengjiang, W., Gang, C., Bing, M., Xijia, G., Yajun, W., Jian- chao, L., Yanming, F., Juanjuan, L.: Baai-vanjee roadside dataset: Towards the connected automated vehicle highway technologies in challenging environments of china (2021),https://arxiv.org/abs/2105.14370, accessed: 25 Jun 2026
-
[67]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, H., Luo, Y., Shu, M., Huo, Y., Yang, Z., Shi, Y., Guo, Z., Li, H., Hu, X., Yuan, J., Nie, Z.: Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21361–21370 (2022)
2022
-
[68]
Zhang, G., Fan, L., He, C., Lei, Z., Zhang, Z., Zhang, L.: Voxel mamba: Group-free statespacemodelsforpointcloudbased3dobjectdetection.In:AdvancesinNeural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 (2024)
2024
-
[69]
A flexible new technique for camera calibration
Zhang, Z.: A flexible new technique for camera calibration. IEEE Transactions on Pattern Analysis and Machine Intelligence22(11), 1330–1334 (2000).https: //doi.org/10.1109/34.888718
-
[70]
Zhu, L.Z.Y.L.A.L.L.L.R.M.B.B.M.: Omnihd-scenes: A next-generation multimodal dataset for autonomous driving. IEEE transactions on pattern analysis and ma- chine intelligence48 6, 7032–7049 (2026).https://doi.org/10.1109/TPAMI. 2026.3663672
-
[71]
In: European Conference on Computer Vision
Zhu, X., Sheng, H., Cai, S., Deng, B., Yang, S., Liang, Q., Chen, K., Gao, L., Song, J., Ye, J.: Roscenes: A large-scale multi-view 3d dataset for roadside perception. In: European Conference on Computer Vision. pp. 331–347. Springer (2024)
2024
-
[72]
In: 2023 IEEE 26th International Con- ference on Intelligent Transportation Systems (ITSC)
Zimmer, W., Creß, C., Nguyen, H.T., Knoll, A.C.: Tumtraf intersection dataset: All you need for urban 3d camera-lidar roadside perception. In: 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC). pp. 1030– 1037 (2023).https://doi.org/10.1109/ITSC57777.2023.10422289
-
[73]
9.754 Meters 6.172 Meters 36' 6
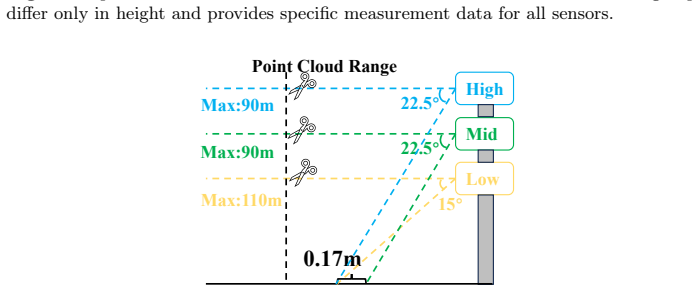
Zimmer, W., Wardana, G.A., Sritharan, S., Zhou, X., Song, R., Knoll, A.C.: Tum- traf v2x cooperative perception dataset. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 22668–22677 (2024) RESOLVE: A Multi-Resolution and Multi-Modal Roadside Dataset 21 Appendix A Sensor Setup This section provides more details of sensor setup...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.