DigitalCoach: Communication and Grounding Gaps in Human and Agentic Computer Use Coaching
Pith reviewed 2026-07-01 05:32 UTC · model grok-4.3
The pith
Models coach computer users with more direct instructions but fewer explanations and with advice poorly grounded in screen visuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
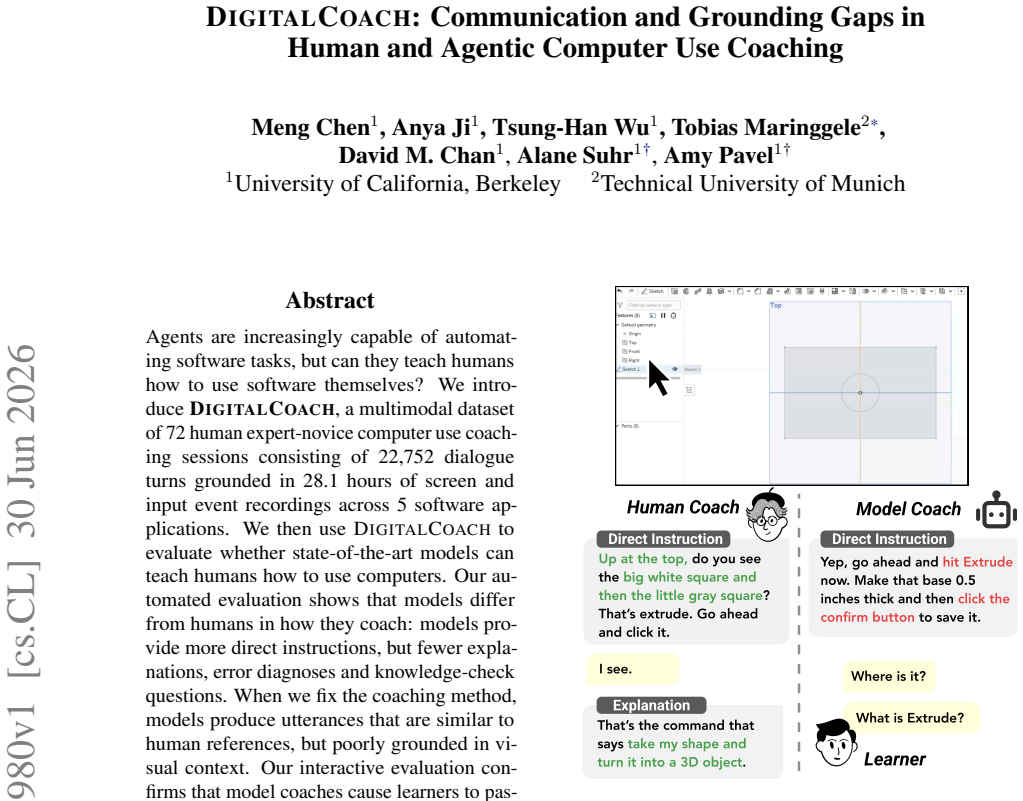
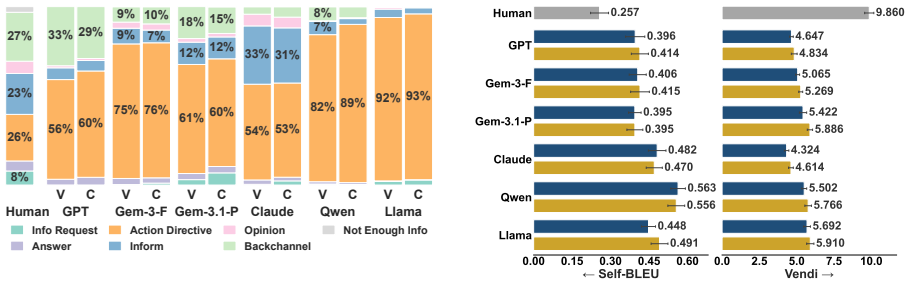
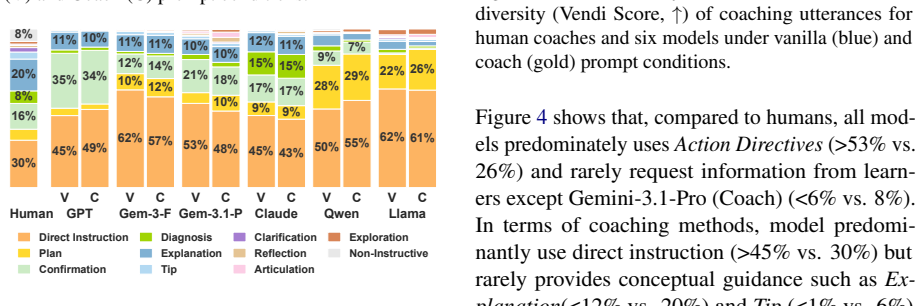
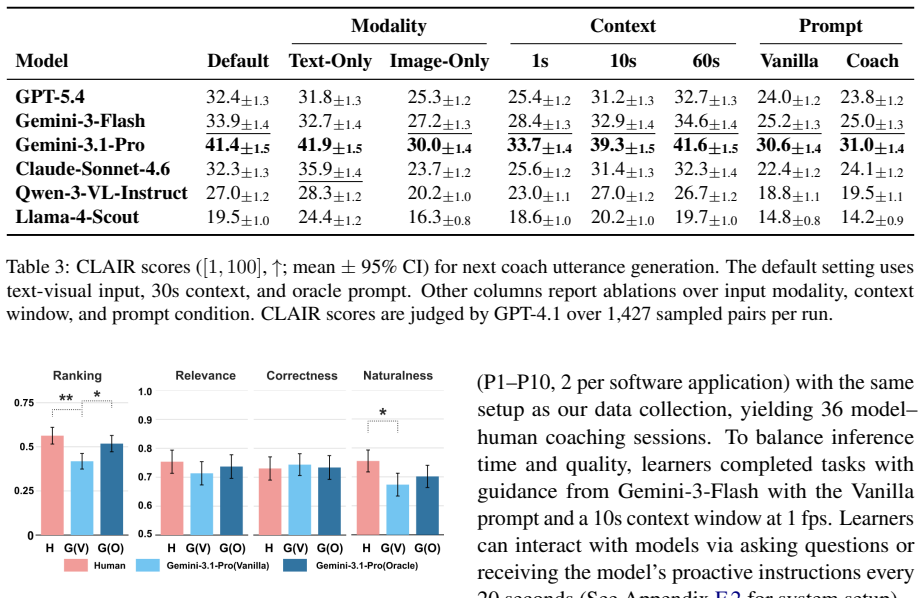
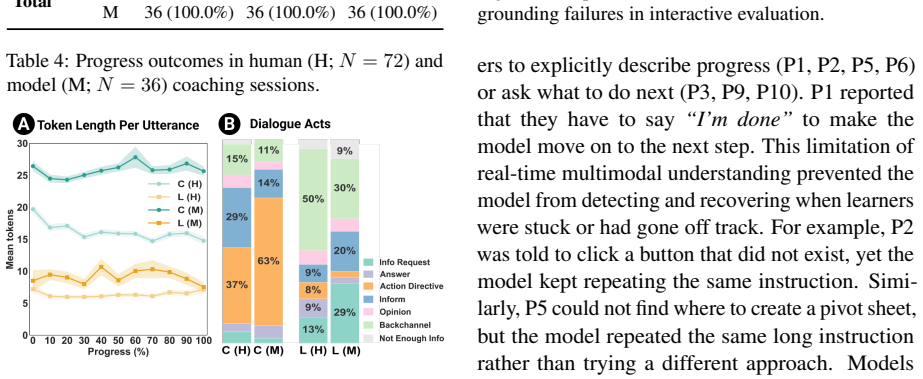
DigitalCoach is a multimodal dataset of 72 human expert-novice computer use coaching sessions consisting of 22,752 dialogue turns grounded in 28.1 hours of screen and input event recordings across five software applications. Automated evaluation shows that models differ from humans in how they coach: models provide more direct instructions, but fewer explanations, error diagnoses, and knowledge-check questions. When we fix the coaching method, models produce utterances similar to human references yet poorly grounded in visual context. Interactive evaluation confirms that model coaches cause learners to passively follow instructions without deeper engagement and fall short in visual grounding
What carries the argument
DigitalCoach dataset of human coaching sessions with screen recordings, used to run both automated metric comparisons and interactive learner studies against model-generated coaching.
If this is right
- Coaching agents will require stronger visual grounding to produce instructions that reference actual screen content.
- Agents will need to increase production of explanations, error diagnoses, and knowledge-check questions to align with observed human coaching patterns.
- Learner engagement metrics will improve only when models shift away from direct-instruction dominance toward more interactive dialogue.
- The dataset supplies training data for agents that support collaborative rather than purely directive computer-use assistance.
Where Pith is reading between the lines
- The grounding failures may stem from training regimes that do not explicitly link generated language to dynamic screen states during coaching.
- Similar evaluation methods could be applied to other agent tasks that require referencing a shared visual workspace, such as remote technical support.
- Expanding the dataset to additional applications and novice populations would test whether the communication differences hold more broadly.
Load-bearing premise
The patterns observed in the 72 sessions across five applications represent typical differences between human and model coaching behavior.
What would settle it
A controlled study using a new collection of coaching sessions in which state-of-the-art models match human rates of explanations, error diagnoses, knowledge-check questions, and visual grounding accuracy would falsify the reported gaps.
Figures


read the original abstract
Agents are increasingly capable of automating software tasks, but can they teach humans how to use software themselves? We introduce DigitalCoach, a multimodal dataset of 72 human expert-novice computer use coaching sessions consisting of 22,752 dialogue turns grounded in 28.1 hours of screen and input event recordings across five software applications. We use DigitalCoach to evaluate whether state-of-the-art models can teach humans how to use computers. Automated evaluation shows that models differ from humans in how they coach: models provide more direct instructions, but fewer explanations, error diagnoses, and knowledge-check questions. When we fix the coaching method, models produce utterances similar to human references yet poorly grounded in visual context. Interactive evaluation confirms that model coaches cause learners to passively follow instructions without deeper engagement and fall short in visual grounding. DigitalCoach lays a foundation for collaborative and proactive computer use coaching agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DigitalCoach, a multimodal dataset of 72 expert-novice computer-use coaching sessions (22,752 turns, 28.1 hours) across five applications. It uses automated and interactive evaluations to claim that state-of-the-art models differ from humans by providing more direct instructions but fewer explanations, error diagnoses, and knowledge-check questions; when coaching method is fixed, model utterances match human references in style but are poorly grounded in visual context, resulting in passive learner engagement.
Significance. If the empirical distinctions hold after methodological clarification, the work would usefully document communication and visual-grounding gaps in current agents for coaching tasks and supply a grounded dataset that could benchmark future proactive coaching systems. The scale of the collected sessions and the dual automated-plus-interactive evaluation protocol are concrete strengths.
major comments (2)
- [Evaluation sections] The central quantitative claims rest on automated labeling of utterance types (direct instructions, explanations, error diagnoses, knowledge-check questions) and visual-grounding metrics, yet the manuscript provides no definitions of these categories, no inter-annotator agreement figures, and no accuracy/validation results for the automated classifiers. These omissions are load-bearing for the reported model-human differences.
- [Dataset description] The generalizability claim—that models systematically differ from humans in coaching style and grounding—rests on 72 sessions across only five applications. No cross-application statistical tests, diversity analysis of novice error types, or external validation of the sample are reported, leaving open the possibility that observed deltas are artifacts of the particular UI patterns or task structures chosen.
minor comments (1)
- [Abstract] The abstract would benefit from a single sentence stating the number and identity of the models evaluated and the main baselines used.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important areas for methodological clarification and we will revise the manuscript to address them directly.
read point-by-point responses
-
Referee: [Evaluation sections] The central quantitative claims rest on automated labeling of utterance types (direct instructions, explanations, error diagnoses, knowledge-check questions) and visual-grounding metrics, yet the manuscript provides no definitions of these categories, no inter-annotator agreement figures, and no accuracy/validation results for the automated classifiers. These omissions are load-bearing for the reported model-human differences.
Authors: We agree that the manuscript currently lacks explicit definitions of the utterance categories and validation details for the automated classifiers. In the revision we will add a new subsection that (1) provides formal definitions for each category, (2) reports inter-annotator agreement from a human validation study performed on a random subset of turns, and (3) presents accuracy and confusion-matrix results comparing the automated labels to human judgments. These additions will make the quantitative claims fully reproducible and address the load-bearing concern. revision: yes
-
Referee: [Dataset description] The generalizability claim—that models systematically differ from humans in coaching style and grounding—rests on 72 sessions across only five applications. No cross-application statistical tests, diversity analysis of novice error types, or external validation of the sample are reported, leaving open the possibility that observed deltas are artifacts of the particular UI patterns or task structures chosen.
Authors: The five applications were deliberately selected to span distinct UI paradigms, yet we acknowledge that the absence of cross-application analyses leaves generalizability open to question. We will add (a) per-application breakdowns and statistical tests for consistency of the model-human differences and (b) a summary of novice error-type diversity across the five domains. While expanding the dataset to additional applications is outside the scope of the present work, these new analyses will directly test whether the observed patterns are robust or UI-specific. revision: partial
Circularity Check
No circularity: empirical dataset collection and direct comparison
full rationale
The paper collects a new dataset of 72 coaching sessions and reports automated metrics plus interactive evaluations comparing model vs. human behavior. No equations, fitted parameters, ansatzes, or derivations appear in the provided text. Central claims rest on direct observation of the collected data rather than any reduction to prior self-citations or inputs by construction. Self-citations (if any) are not invoked as uniqueness theorems or load-bearing justifications for the evaluation methodology. This is standard empirical work whose validity hinges on data representativeness, not on definitional or self-referential loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2021 Conference on Empirical Methods in Nat- ural Language Processing, pages 1112–1125, Online and Punta Cana, Dominican Republic
MindCraft: Theory of mind modeling for situ- ated dialogue in collaborative tasks. InProceedings of the 2021 Conference on Empirical Methods in Nat- ural Language Processing, pages 1112–1125, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics. Apratim Bhattacharyya, Bicheng Xu, Sanjay Haresh, Reza Pourreza, Litian Liu, Su...
2021
-
[2]
Cambridge University Press, Cambridge. Mark G Core and James Allen. 1997. Coding dialogs with the damsl annotation scheme. InAAAI fall sym- posium on communicative action in humans and ma- chines, volume 56, pages 28–35. Boston, MA. Joseph L. Fleiss and Jacob Cohen. 1973. The Equiva- lence of Weighted Kappa and the Intraclass Correla- tion Coefficient as ...
-
[3]
Grounding gaps in language model genera- tions. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 1: Long Papers), pages 6279–6296. Mayank Sharma, Roy Pea, and Hari Subramonyam
2024
-
[4]
ConvoLearn: A Dataset of Constructivist Tutor-Student Dialogue. Shannon Zejiang Shen, Valerie Chen, Ken Gu, Alexis Ross, Zixian Ma, Jillian Ross, Alex Gu, Chen- glei Si, Wayne Chi, Andi Peng, Jocelyn J. Shen, Ameet Talwalkar, Tongshuang Wu, and David Son- tag. 2025. Completion $\neq$ Collaboration: Scal- ing Collaborative Effort with Agents.arXiv preprint...
-
[5]
Genartist: Multimodal LLM as an agent for unified image generation and editing. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Sys- tems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. Zora Zhiruo Wang, Yijia Shao, Omar Shaikh, Daniel Fried, Graham Neubig, and Diyi Yang. 2025. ...
-
[6]
Alright, now we want to rename this to. . .Card
OpenReview.net. 12 Appendix Our appendix is organized as follows: • Appendix A provides detailed statistics and linguistic examples of the dataset. • Appendix B outlines the experimental plat- form setup and facilitation scripts. • Appendix C catalogs the specific software tasks across the five tested domains. • Appendix D details the human-in-the-loop tr...
2010
-
[7]
Split the utterance if there is a pause of 2 sec- onds or longer
-
[8]
(a) Descending pitch can be a hint that an utterance is ending
Use changes in intonation and what can be inferred from the semantics to decide whether to split for shorter pauses. (a) Descending pitch can be a hint that an utterance is ending. Figure D.1: Transcription correction interface. Editor can see the dialogue transcript alongside screen record- ing. They can use the interface to edit, split, merge each utter...
-
[9]
Context from the other speaker can also help (e.g., if one half of the utterance is respond- ing directly to the other speaker, it may make sense to split)
-
[10]
more practice would be helpful to re-enforce the things I learnt,
Use the multimodal context to decide whether to split. (a) If a short pause coincides with a visible action in the screen state, this can be evi- dence for a new utterance. (b) If the screen state remains unchanged and there is only a pause shorter than 2 seconds, the utterances of the same speaker should generally be merged. D.3 Transcript Correction Int...
-
[11]
Listen to the audio carefully
-
[12]
Fix mistranscriptions only
For each objectin array order, produce the wording that best matches what is spoken in the corresponding time range. Fix mistranscriptions only
-
[13]
The number of strings you output must equal {n} (one corrected line per input object)
DoNOTinvent new utterances, merge, or split segments. The number of strings you output must equal {n} (one corrected line per input object)
-
[14]
DoNOTchange punctuation style unnecessarily; natural English is fine
-
[15]
ONLY correct the "text" field; keep the same timing, speaker, and id
-
[16]
Use , to indicate short speech pauses or hesitation
-
[17]
to indicate a longer pause or hesitation
Use ... to indicate a longer pause or hesitation
-
[18]
Use – to indicate a trail off or being interrupted by another speaker
-
[19]
The first letter of the first word in the "text" field should be capitalized. Output requirements: - Return ONLY valid JSON: a single array of {n} strings. - String i is the corrected "text" for input object i (same order as the reference array). - No markdown, no code fences, no keys other than the array itself. Good Examples: - "bit, there’s pill." -> "...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.