Automated Background Swapping for Robustness against Spurious Backgrounds
Pith reviewed 2026-07-01 05:36 UTC · model grok-4.3
The pith
AutoBackSwap trains a secondary network on a few hundred patch labels to separate foreground from background, inpaints new backgrounds, and augments data by swapping them, making classifiers robust to spurious backgrounds even when no train
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoBackSwap uses a secondary network to disentangle the foreground and background, followed by infilling to synthesize complete backgrounds, and finally combines different foregrounds and inpainted backgrounds to augment the training data. Patch-wise labeling of just a few hundred samples suffices to train the secondary network and automatically augment the full training dataset on challenging image classification tasks. In contrast to many previous methods, AutoBackSwap proves very effective even if there is not a single sample in the training data breaking the spurious correlation.
What carries the argument
The secondary network trained on patch-wise labels to disentangle foreground from background, followed by inpainting and foreground-background recombination for data augmentation.
If this is right
- Classifiers trained on the augmented data exhibit reduced dependence on background features that lack causal links to the label.
- The augmentation process succeeds on tasks where every training image shares the same spurious background correlation.
- Performance exceeds that of prior methods for mitigating spurious background correlations across multiple image classification benchmarks.
- Only a few hundred patch-labeled examples are required to enable the full augmentation pipeline on large datasets.
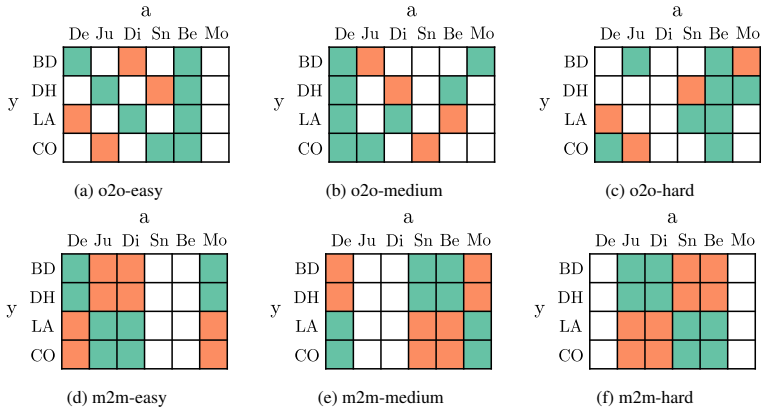
Where Pith is reading between the lines
- The same minimal-label separation step could be tested on other spurious cues such as lighting or texture if a comparable patch annotation scheme is defined.
- If the inpainting step preserves object identity accurately, the method might reduce the need for fully diverse training sets in other domains that admit foreground-background separation.
- One could measure whether the quality of the secondary network's masks directly predicts the final classifier's robustness gain on held-out data.
Load-bearing premise
Patch-wise labeling of just a few hundred samples suffices to train the secondary network to disentangle foreground and background well enough for effective data augmentation on the full dataset.
What would settle it
A controlled test on a dataset where the secondary network, despite the provided patch labels, produces foreground masks that still contain background pixels and where the resulting augmented classifier shows no robustness gain over the baseline.
Figures

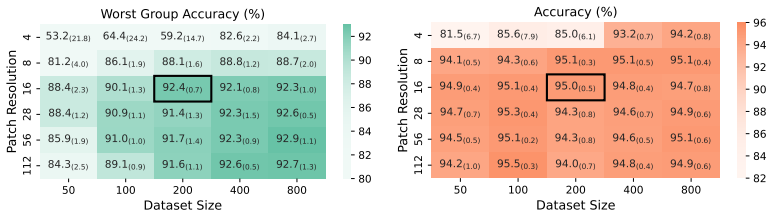
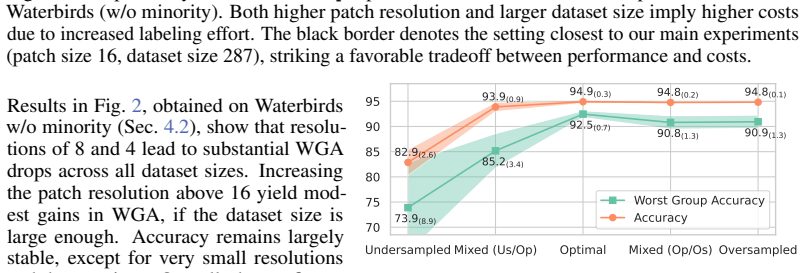
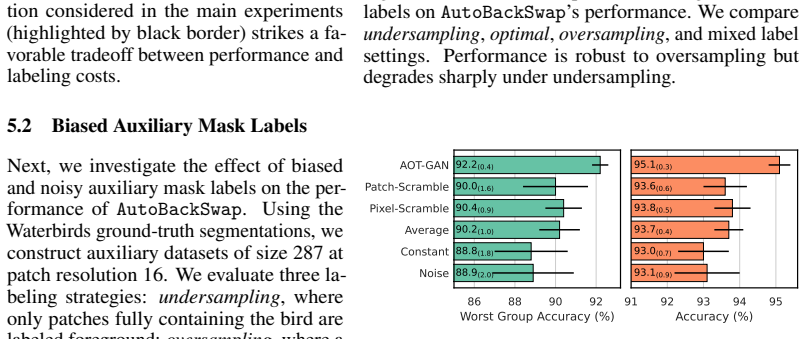

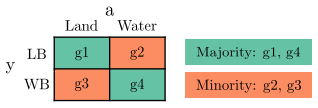





read the original abstract
Classifiers based on Deep Neural Networks exhibit strong performance across domains, yet can fail catastrophically if they rely on spurious correlations, i.e., features that are predictive of the target label in the training data but are not causally linked and thus fail to generalize. For the vision domain, many such spurious correlations manifest themselves within the background of the image, where only the foreground is predictive of the class label. In this paper, we introduce Automated Background Swapping (AutoBackSwap) to reduce the reliance of classifiers on such spurious backgrounds. AutoBackSwap uses a secondary network to disentangle the foreground and background, followed by infilling to synthesize complete backgrounds, and finally combines different foregrounds and inpainted backgrounds to augment the training data. We find that patch-wise labeling of just a few hundred samples suffices to train the secondary network and automatically augment the full training dataset on challenging image classification tasks. In contrast to many previous methods, AutoBackSwap proves very effective even if there is not a single sample in the training data breaking the spurious correlation. Across a range of image classification tasks with spurious backgrounds, AutoBackSwap consistently outperforms prior methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Automated Background Swapping (AutoBackSwap), which trains a secondary network on patch-wise labels from a few hundred samples to disentangle foreground from background, uses infilling to synthesize complete backgrounds, and augments the training set by swapping foregrounds with these backgrounds. The central claim is that this consistently outperforms prior methods on image classification tasks with spurious backgrounds, and remains effective even when the training data contains zero samples that break the spurious correlation.
Significance. If the empirical results hold, the method offers a low-supervision route to robustness against background shortcuts that is more practical than methods requiring explicit counterexamples. The use of a secondary network for targeted augmentation could influence data-centric robustness techniques in computer vision, provided the disentanglement step generalizes reliably from limited labels.
major comments (2)
- [Abstract, §3] Abstract and §3 (method description): the claim that patch-wise labeling of a few hundred samples suffices for the secondary network to produce masks that enable effective augmentation across the full dataset is load-bearing for the zero-counterexample result, yet no quantitative segmentation metrics (e.g., IoU on held-out patches or foreground masks) or ablation on label count are referenced to demonstrate that the network does not simply overfit the correlated distribution.
- [Abstract] Abstract: the statement that AutoBackSwap 'consistently outperforms prior methods' even with zero breaking samples requires evidence that the generated augmentations actually break the correlation rather than preserve it; without reported foreground-mask accuracy or correlation-strength measurements before/after augmentation, the outperformance cannot be attributed to the proposed mechanism.
minor comments (2)
- [§3] Notation for the secondary network and infilling steps should be introduced with explicit equations rather than prose descriptions to allow reproducibility.
- [§4] The paper should clarify whether the patch-wise labels are obtained via a fixed protocol or require human annotation, as this affects the claimed practicality.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where we will revise the manuscript to strengthen the supporting evidence.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method description): the claim that patch-wise labeling of a few hundred samples suffices for the secondary network to produce masks that enable effective augmentation across the full dataset is load-bearing for the zero-counterexample result, yet no quantitative segmentation metrics (e.g., IoU on held-out patches or foreground masks) or ablation on label count are referenced to demonstrate that the network does not simply overfit the correlated distribution.
Authors: We agree that quantitative segmentation metrics and a label-count ablation would provide stronger support for the claim that a few hundred patch-wise labels suffice without overfitting. The current manuscript primarily demonstrates effectiveness via downstream classification accuracy. In the revision we will add IoU scores on held-out patches together with an ablation varying the number of labeled samples. revision: yes
-
Referee: [Abstract] Abstract: the statement that AutoBackSwap 'consistently outperforms prior methods' even with zero breaking samples requires evidence that the generated augmentations actually break the correlation rather than preserve it; without reported foreground-mask accuracy or correlation-strength measurements before/after augmentation, the outperformance cannot be attributed to the proposed mechanism.
Authors: The reported gains are measured by classification robustness under spurious backgrounds. To more directly link the gains to correlation breaking, the revision will include foreground-mask accuracy on held-out data and pre-/post-augmentation measurements of spurious correlation strength (e.g., background-class mutual information). revision: yes
Circularity Check
No circularity: empirical augmentation method with independent experimental validation
full rationale
The paper describes an empirical pipeline (secondary network trained on patch-wise labels from a few hundred samples, followed by infilling and foreground-background swapping for augmentation) whose effectiveness is evaluated via downstream classification accuracy on spurious-correlation benchmarks. No equations, uniqueness theorems, or first-principles derivations are presented that reduce by construction to fitted parameters or self-citations. The central claim (outperformance even with zero decorrelated samples) rests on the generalization behavior of the trained segmenter, which is an empirical hypothesis tested experimentally rather than a definitional or fitted tautology. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A secondary network trained on limited patch-wise labels can reliably disentangle foreground and background for downstream augmentation.
Reference graph
Works this paper leans on
-
[1]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization. arXiv, 1907.02893,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Bransby, Arian Beqiri, Woo-Jin Cho Kim, Jorge Oliveira, Agisilaos Chartsias, and Alberto Gomez
Kit M. Bransby, Arian Beqiri, Woo-Jin Cho Kim, Jorge Oliveira, Agisilaos Chartsias, and Alberto Gomez. BackMix: Mitigating Shortcut Learning in Echocardiography with Minimal Supervision . Inproceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024,
2024
-
[4]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Spawrious: A benchmark for fine control of spurious correlation biases.arXiv, 2303.05470,
Aengus Lynch, Gbètondji J-S Dovonon, Jean Kaddour, and Ricardo Silva. Spawrious: A benchmark for fine control of spurious correlation biases.arXiv, 2303.05470,
-
[7]
Hidden stratification causes clinically meaningful failures in machine learning for medical imaging.Proc ACM Conf Health Inference Learn (2020),
Luke Oakden-Rayner, Jared Dunnmon, Gustavo Carneiro, and Christopher Ré. Hidden stratification causes clinically meaningful failures in machine learning for medical imaging.Proc ACM Conf Health Inference Learn (2020),
2020
-
[8]
BARACK: Partially supervised group robustness with guarantees
Nimit Sharad Sohoni, Maziar Sanjabi, Nicolas Ballas, Aditya Grover, Shaoliang Nie, Hamed Firooz, and Christopher Re. BARACK: Partially supervised group robustness with guarantees. InICML 2022: Workshop on Spurious Correlations, Invariance and Stability,
2022
-
[9]
Deep coral: Correlation alignment for deep domain adaptation
Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. In ECCV 2016 Workshops,
2016
-
[10]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Huggingface’s transformers: St...
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[11]
We discuss both potential positive and negative societal implications below
A Broader Impact This work addresses the problem of spurious correlations in image classifiers, with direct relevance to high-stakes deployment contexts. We discuss both potential positive and negative societal implications below. Positive impacts.Deep neural networks deployed in consequential domains, medical imaging, autonomous driving, and facial recog...
2018
-
[12]
trained until convergence
Detector training.In all experiments, we use an EfficientNet-B0 backbone and replace the final layer such that the model predicts the foreground likelihood for each output patch. Training is performed using binary cross-entropy on foreground/background masks. We optimize using SGD with momentum, where learning rate, weight decay, and momentum are selected...
2018
-
[13]
in the main experiments and to construct certain conditions for ablations on AutoBackSwap. AutoBackSwap does not use the ground-truth segmentation maps in the main experiments, but only relies on 287 hand-labeled patch-wise masks to train the detector for foreground / background disentanglement on the full training dataset. Hand-labeling was done by a sin...
2023
-
[14]
[2023], regarding which groups belong to which difficulty level
Note that for the many-to-many settings, there is a discrepancy between the description in the paper and the official implementation by Lynch et al. [2023], regarding which groups belong to which difficulty level. We chose to follow the official implementation. Segmentation masks required for the Chang et al
2023
-
[15]
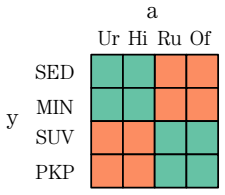
The aim is to classify different vehicle types, thus the target classes areY = {sedan, minivan, SUV, pickup truck}
(Licensed under Apache-2.0). The aim is to classify different vehicle types, thus the target classes areY = {sedan, minivan, SUV, pickup truck}. Images are generated in different environments, yielding the spurious context attributes A = {urban, highway, rural, off-road}, for a total of 16 possible target–context group combinations. We consider the many-t...
2023
-
[16]
This controlled generation process allows us to vary contextual cues while preserving the semantic target label
Prompts specify both the vehicle class and the desired context while enforcing consistent framing and viewing perspectives. This controlled generation process allows us to vary contextual cues while preserving the semantic target label. E Hyperparameter Tuning We manually tuned AutoBackSwap and baselines using both WGA and Acc on the validation dataset. O...
2020
-
[17]
We report theWGAand theAccover the four groups
and ViT as base models. We report theWGAand theAccover the four groups. Best result bold, second best underlined. Statistics computed over five independent runs. Method ResNet50 ViT w minority w/o minority w minority w/o minority WGA Acc WGA Acc WGA Acc WGA Acc ERM74.9 (3.3) 93.6(0.4) 33.4(4.4) 68.4(1.9) 63.1(10.4) 90.1(0.6) 21.4(1.3) 62.5(1.8) + Heavy Au...
2016
-
[18]
(2021) Chang et al
H Detailed Comparison to Prior Work H.1 Chang et al. (2021) Chang et al
2021
-
[19]
Their method generates augmented factual and counter- factual samples and optimizes two additional auxiliary losses on those
propose counterfactual and factual/invariant data augmentation based on ground- truth bounding boxes or segmentation masks. Their method generates augmented factual and counter- factual samples and optimizes two additional auxiliary losses on those. In contrast, AutoBackSwap requires only a small auxiliary dataset with coarse patch-level labels and uses i...
2025
-
[20]
This is opposite to our approach, where the foreground region is extracted and pasted onto infilled backgrounds
introduce a background-mixing strategy called BackMix based on class activation maps, where foreground regions are masked and background patches are extracted and pasted onto target images. This is opposite to our approach, where the foreground region is extracted and pasted onto infilled backgrounds. Their approach focuses on open-set recognition and rel...
2024
-
[21]
propose a background-mixing strategy also called BackMix for echocardiog- raphy, assuming access to foreground masks in a semi-supervised medical imaging setting. Their method samples random backgrounds for each foreground, where infilling of the remaining back- ground can be trivially done by inserting zeros due to the data structure and applying additio...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.