SkillSelect-Serve: Budget-Controllable and QoS-Aware Skill Service Recommendation and Composition for Small LLM Agents
Pith reviewed 2026-07-02 23:43 UTC · model grok-4.3
The pith
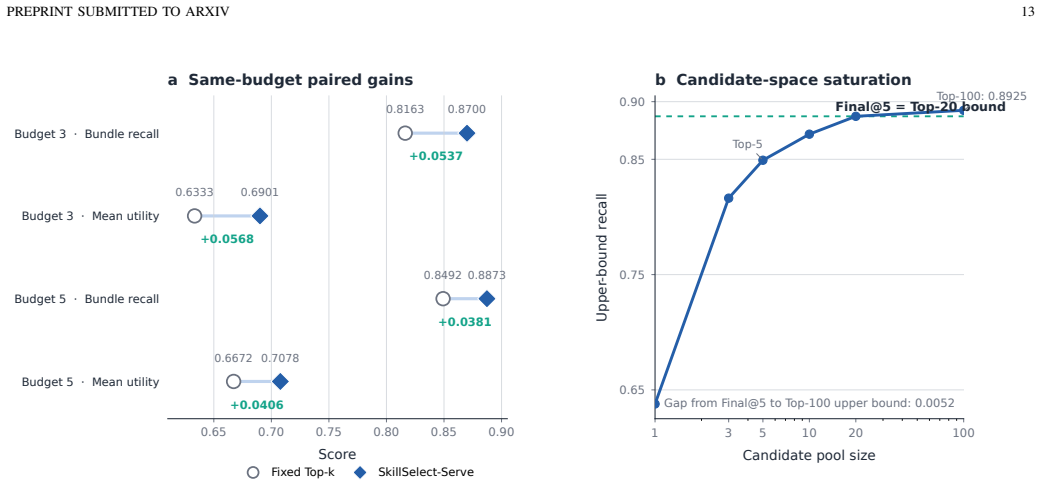
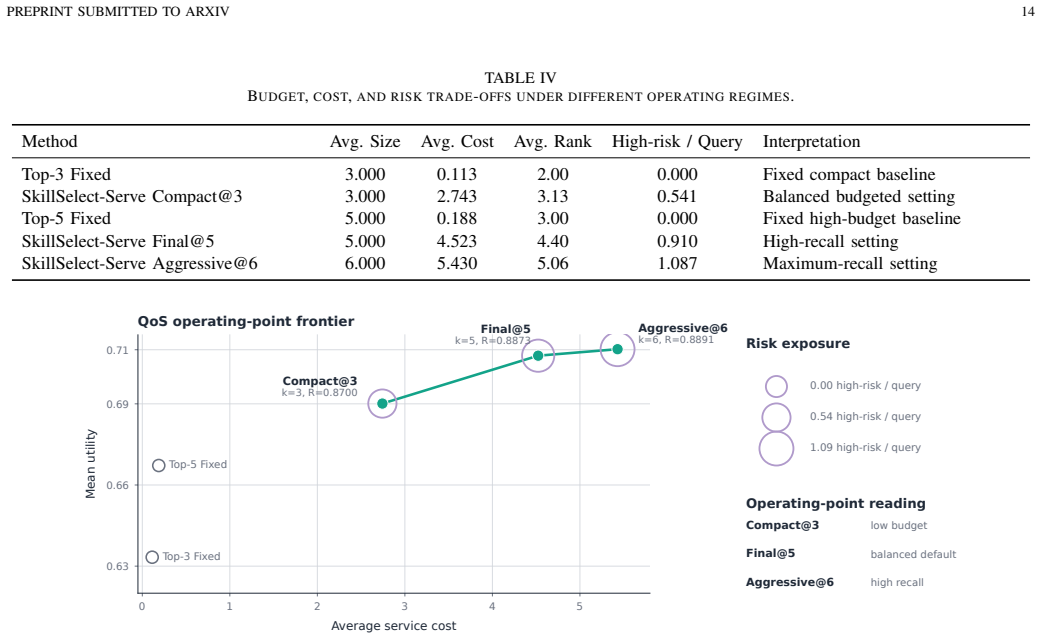
SkillSelect-Serve models skills as services to produce budget-controllable, QoS-aware bundles that raise recall and utility over fixed top-k retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
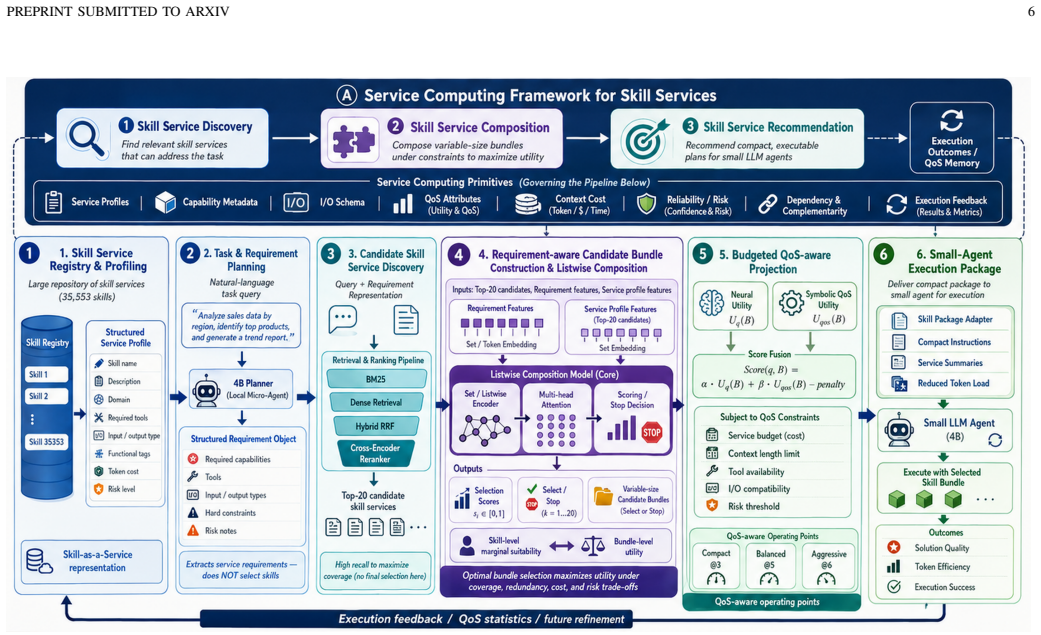
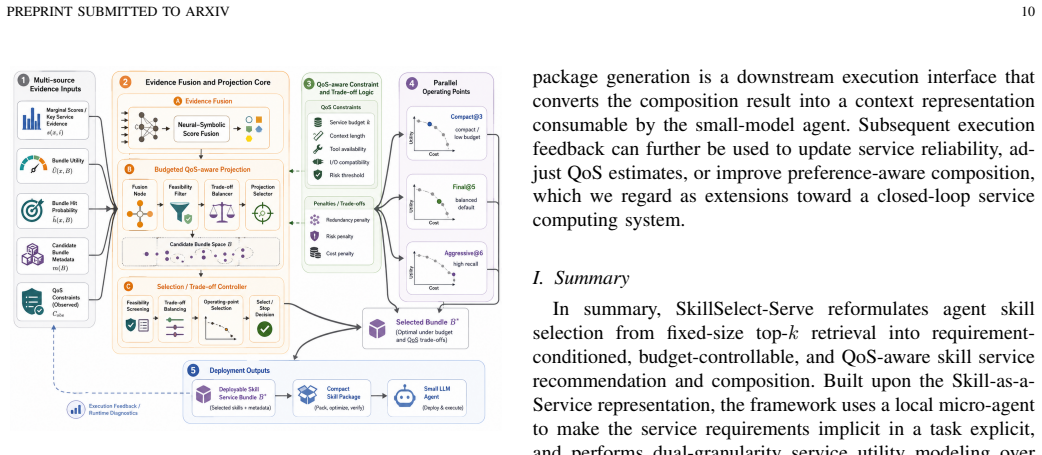
SkillSelect-Serve formulates agent skill selection as Skill Service Recommendation and Composition. Raw skills become structured Skill Services with functional descriptions, dependencies, context cost, risk, and QoS-related attributes. A local Micro-Agent Requirement Planner converts natural-language tasks into structured service requirements. A shared discovery backbone retrieves candidate services, after which dual-granularity utility modeling performs skill-level marginal suitability estimation and bundle-level calibration for coverage, redundancy, cost, and risk trade-offs.
What carries the argument
Dual-granularity utility modeling that combines skill-level marginal suitability estimation with bundle-level calibration over coverage, redundancy, cost, and risk.
If this is right
- Bundles can be assembled to meet explicit budget limits while still improving recall over fixed top-k lists.
- QoS attributes such as risk and cost become first-class inputs to the selection process rather than post-hoc filters.
- The same discovery backbone and utility model can be reused across different task queries without retraining per query.
- Small LLM agents gain a controllable way to trade coverage against context length and failure risk inside one selection step.
Where Pith is reading between the lines
- The approach could extend to dynamic registries where new skills are added continuously, provided the planner can update requirements without full re-indexing.
- If the service representation step proves reliable, similar structuring might help other retrieval settings that currently rely on embedding similarity alone.
- The dual-granularity split suggests a testable separation: skill-level scores could be pre-computed offline while bundle calibration runs at query time.
Load-bearing premise
Raw skills can be faithfully represented as structured Skill Services whose functional descriptions, dependencies, context cost, risk, and QoS attributes are accurate and sufficient for the Micro-Agent Requirement Planner to generate reliable service requirements from natural language.
What would settle it
An experiment that replaces the structured Skill Service attributes with noisy or incomplete versions and measures whether bundle recall and mean utility fall below the fixed top-k baselines on the same 35,353-skill registry and 586 queries.
Figures

read the original abstract
Reusable skill libraries are becoming important infrastructure for large language model (LLM) agents, yet existing selection methods often treat skills as retrievable documents and return fixed top-k lists. This paper presents SkillSelect-Serve, a budget-controllable and QoS-aware framework that formulates agent skill selection as Skill Service Recommendation and Composition. SkillSelect-Serve represents raw skills as structured Skill Services with functional descriptions, dependencies, context cost, risk, and QoS-related attributes. A local Micro-Agent Requirement Planner converts natural-language tasks into structured service requirements, while a shared discovery backbone retrieves candidate services from a large registry. The framework then performs dual-granularity utility modeling with skill-level marginal suitability estimation and bundle-level calibration for coverage, redundancy, cost, and risk trade-offs. Experiments on 35,353 skills and 586 task queries show that SkillSelect-Serve consistently improves same-budget bundle recall and mean utility over fixed top-k retrieval baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillSelect-Serve, a framework that models raw skills as structured Skill Services (with functional descriptions, dependencies, context cost, risk, and QoS attributes), employs a Micro-Agent Requirement Planner to convert natural-language tasks into service requirements, retrieves candidates via a shared backbone, and applies dual-granularity utility modeling (skill-level marginal suitability plus bundle-level calibration for coverage, redundancy, cost, and risk). Experiments on a registry of 35,353 skills and 586 task queries claim consistent gains in same-budget bundle recall and mean utility over fixed top-k retrieval baselines.
Significance. If the structured Skill Service attributes prove accurate and the utility modeling is robust, the approach could advance controllable, QoS-aware skill composition for resource-constrained LLM agents beyond standard retrieval. The scale of the registry and the budget-controllable formulation are potentially useful contributions to the skill-library infrastructure problem in agent systems.
major comments (2)
- Abstract and method description: the central performance claim (improved same-budget bundle recall and mean utility) rests on dual-granularity utility modeling that directly uses the structured attributes (cost, risk, QoS, dependencies). No account is given of how the 35,353 skills were converted into Skill Services—whether attributes were manually curated, LLM-generated, or heuristically derived—nor any validation against ground truth. Systematic errors in these attributes would render the Micro-Agent Requirement Planner outputs and subsequent marginal-suitability + bundle-calibration steps unreliable, making observed gains potentially artifacts of the synthetic representation rather than genuine QoS-aware selection.
- Abstract: experimental details are absent on baseline implementations (how fixed top-k retrieval was realized and whether it had access to the same structured attributes), utility calculation, presence of error bars, statistical significance tests, or sensitivity to post-hoc choices. Without these, the claim that SkillSelect-Serve “consistently improves” over baselines cannot be evaluated from the provided evidence.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: Abstract and method description: the central performance claim (improved same-budget bundle recall and mean utility) rests on dual-granularity utility modeling that directly uses the structured attributes (cost, risk, QoS, dependencies). No account is given of how the 35,353 skills were converted into Skill Services—whether attributes were manually curated, LLM-generated, or heuristically derived—nor any validation against ground truth. Systematic errors in these attributes would render the Micro-Agent Requirement Planner outputs and subsequent marginal-suitability + bundle-calibration steps unreliable, making observed gains potentially artifacts of the synthetic representation rather than genuine QoS-aware selection.
Authors: We agree that the derivation process for the Skill Service attributes is not sufficiently detailed in the current manuscript. This is a valid concern as it affects the interpretability of the results. In the revised manuscript, we will add a dedicated subsection (likely in Section 3 or 4) that explicitly describes how the 35,353 skills were converted into structured Skill Services, including the method used (e.g., LLM-assisted annotation with human oversight or heuristic rules), and any validation performed against ground truth or inter-annotator agreement. This will allow readers to assess potential biases or artifacts. revision: yes
-
Referee: Abstract: experimental details are absent on baseline implementations (how fixed top-k retrieval was realized and whether it had access to the same structured attributes), utility calculation, presence of error bars, statistical significance tests, or sensitivity to post-hoc choices. Without these, the claim that SkillSelect-Serve “consistently improves” over baselines cannot be evaluated from the provided evidence.
Authors: We acknowledge the lack of detailed experimental information in the abstract and main text. The revised version will include expanded descriptions in the Experiments section covering: (1) exact implementation of the fixed top-k baseline and whether it uses the same structured attributes, (2) the precise formulas and procedures for utility calculation at both granularities, (3) reporting of standard deviations or error bars across runs, (4) results of statistical significance tests (e.g., paired t-tests or Wilcoxon), and (5) sensitivity analysis to key hyperparameters or post-hoc decisions. These additions will make the evaluation more transparent and reproducible. revision: yes
Circularity Check
No circularity: empirical framework with independent experimental claims
full rationale
The paper presents SkillSelect-Serve as a system that takes raw skills, converts them to structured Skill Services (an input step), runs a Micro-Agent Requirement Planner, and performs utility modeling before comparing results to fixed top-k baselines on 35,353 skills and 586 queries. No equations, fitted parameters, or derivations are shown that reduce any claimed prediction or result to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The experimental gains are reported as direct comparisons against external baselines, making the derivation chain self-contained against those benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,”arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face,
Y . Shen, K. Song, X. Tan, D. Li, W. Lu, and Y . Zhuang, “Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face,”Advances in Neural Information Processing Systems, vol. 36, pp. 38 154–38 180, 2023
2023
-
[3]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in neural informa- tion processing systems, vol. 36, pp. 68 539–68 551, 2023
2023
-
[4]
Toolllm: Facilitating large language models to master 16000+ real-world apis,
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qianet al., “Toolllm: Facilitating large language models to master 16000+ real-world apis,” inThe twelfth international conference on learning representations, 2023
2023
-
[5]
Api-bank: A comprehensive benchmark for tool-augmented llms,
M. Li, Y . Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y . Li, “Api-bank: A comprehensive benchmark for tool-augmented llms,” in Proceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 3102–3116
2023
-
[6]
Service- oriented computing: State of the art and research challenges,
M. P. Papazoglou, P. Traverso, S. Dustdar, and F. Leymann, “Service- oriented computing: State of the art and research challenges,”Computer, vol. 40, no. 11, pp. 38–45, 2007. PREPRINT SUBMITTED TO ARXIV 22
2007
-
[7]
Qos-aware middleware for web services composition,
L. Zeng, B. Benatallah, A. H. Ngu, M. Dumas, J. Kalagnanam, and H. Chang, “Qos-aware middleware for web services composition,”IEEE Transactions on software engineering, vol. 30, no. 5, pp. 311–327, 2004
2004
-
[8]
A service computing manifesto: the next 10 years,
A. Bouguettaya, M. Singh, M. Huhns, Q. Z. Sheng, H. Dong, Q. Yu, A. G. Neiat, S. Mistry, B. Benatallah, B. Medjahedet al., “A service computing manifesto: the next 10 years,”Communications of the ACM, vol. 60, no. 4, pp. 64–72, 2017
2017
-
[9]
Robertson and H
S. Robertson and H. Zaragoza,The probabilistic relevance framework: BM25 and beyond. Now Publishers Inc, 2009, vol. 4
2009
-
[10]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), 2019, pp. 3982–3992
2019
-
[11]
R. Nogueira and K. Cho, “Passage re-ranking with bert,”arXiv preprint arXiv:1901.04085, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[12]
Greedy function approximation: a gradient boosting machine,
J. H. Friedman, “Greedy function approximation: a gradient boosting machine,”Annals of statistics, pp. 1189–1232, 2001
2001
-
[13]
Web service composition: a survey of techniques and tools,
A. L. Lemos, F. Daniel, and B. Benatallah, “Web service composition: a survey of techniques and tools,”ACM Computing Surveys (CSUR), vol. 48, no. 3, pp. 1–41, 2015
2015
-
[14]
Qos-aware service composition: A retrospective,
L. Zeng, B. Benatallah, M. Dumas, J. Kalagnanam, and A. H. Ngu, “Qos-aware service composition: A retrospective,”IEEE Transactions on Software Engineering, vol. 51, no. 3, pp. 836–841, 2025
2025
-
[15]
Web service composition in mobile environment: a survey of techniques,
C. B. Njima, C. G. Guegan, Y . Gamha, and L. B. Romdhane, “Web service composition in mobile environment: a survey of techniques,” IEEE Transactions on Services Computing, vol. 17, no. 2, pp. 689–704, 2024
2024
-
[16]
Service package recommendation for mashup creation via mashup textual description mining,
Q. Gu, J. Cao, and Q. Peng, “Service package recommendation for mashup creation via mashup textual description mining,” in2016 IEEE international conference on web services (ICWS). IEEE, 2016, pp. 452–459
2016
-
[17]
Csbr: A compositional semantics-based service bundle recommendation approach for mashup development,
Q. Gu, J. Cao, and Y . Liu, “Csbr: A compositional semantics-based service bundle recommendation approach for mashup development,” IEEE Transactions on Services Computing, vol. 15, no. 6, pp. 3170– 3183, 2021
2021
-
[18]
Dysr: A dynamic graph neural network based service bundle recommendation model for mashup creation,
M. Liu, Z. Tu, H. Xu, X. Xu, and Z. Wang, “Dysr: A dynamic graph neural network based service bundle recommendation model for mashup creation,”IEEE Transactions on Services Computing, vol. 16, no. 4, pp. 2592–2605, 2023
2023
-
[19]
Dawar: Diversity-aware web apis recommendation for mashup creation based on correlation graph,
W. Gong, X. Zhang, Y . Chen, Q. He, A. Beheshti, X. Xu, C. Yan, and L. Qi, “Dawar: Diversity-aware web apis recommendation for mashup creation based on correlation graph,” inProceedings of the 45th international ACM SIGIR conference on Research and Development in information retrieval, 2022, pp. 395–404
2022
-
[20]
Sehgn: Semantic-enhanced heterogeneous graph network for web api recom- mendation,
X. Wang, M. Xi, Y . Li, X. Pan, Y . Wu, S. Deng, and J. Yin, “Sehgn: Semantic-enhanced heterogeneous graph network for web api recom- mendation,”IEEE Transactions on Services Computing, vol. 17, no. 5, pp. 2836–2849, 2024
2024
-
[21]
Web service recommendation via combining topic-aware heterogeneous graph repre- sentation and interactive semantic enhancement,
B. Cao, Q. Peng, X. Xie, Z. Peng, J. Liu, and Z. Zheng, “Web service recommendation via combining topic-aware heterogeneous graph repre- sentation and interactive semantic enhancement,”IEEE Transactions on Services Computing, vol. 17, no. 6, pp. 4451–4466, 2024
2024
-
[22]
Mashup-oriented api recommendation via pre-trained heterogeneous information networks,
M. Tang, F. Xie, S. Lian, J. Mai, and S. Li, “Mashup-oriented api recommendation via pre-trained heterogeneous information networks,” Information and Software Technology, vol. 169, p. 107428, 2024
2024
-
[23]
C-da w ar: Towards diversity-aware web apis recommendation for mashup creation based on contrastive learning,
Y . Wang, L. Yang, W. Gong, M. Khosravi, M. Khan, and W. Rafique, “C-da w ar: Towards diversity-aware web apis recommendation for mashup creation based on contrastive learning,”Tsinghua Science and Technology, 2025
2025
-
[24]
Api recommendation for mashup creation: A comprehensive survey,
H. Alhosaini, S. Alharbi, X. Wang, and G. Xu, “Api recommendation for mashup creation: A comprehensive survey,”The Computer Journal, vol. 67, no. 5, pp. 1920–1940, 2024
1920
-
[25]
Llm enhanced representation for cold start service recommendation,
D. Rong, L. Yao, Y . Zheng, S. Yu, X. Xu, M. Liu, and Z. Wang, “Llm enhanced representation for cold start service recommendation,” inInternational Conference on Service-Oriented Computing. Springer, 2024, pp. 153–167
2024
-
[26]
Llmsrec: Large language model with service network augmentation for web service recommendation,
Q. Peng, B. Cao, X. Xie, H. Ye, J. Liu, and Z. Li, “Llmsrec: Large language model with service network augmentation for web service recommendation,”Knowledge-Based Systems, vol. 323, p. 113710, 2025
2025
-
[27]
Llm-cosr: Noise-resistant service recommendation via llm-augmented graph contrastive learning,
Y . Zhu, Z. Lin, J. Fan, M. Liu, and Z. Wang, “Llm-cosr: Noise-resistant service recommendation via llm-augmented graph contrastive learning,” in2025 IEEE International Conference on Web Services (ICWS). IEEE, 2025, pp. 1–10
2025
-
[28]
Mars: A multi-agent collaborative reasoning framework for service recommenda- tion,
M. Liu, Z. Yin, C. Tian, S. Yu, T. Cai, Z. Xu, and Z. Wang, “Mars: A multi-agent collaborative reasoning framework for service recommenda- tion,”IEEE Transactions on Services Computing, 2026
2026
-
[29]
Toolllm: Facilitating large language models to master 16000+ real-world apis,
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qianet al., “Toolllm: Facilitating large language models to master 16000+ real-world apis,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 9695–9717
2024
-
[30]
Gorilla: Large language model connected with massive apis,
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive apis,”Advances in Neural Information Processing Systems, vol. 37, pp. 126 544–126 565, 2024
2024
-
[31]
Y . Song, W. Xiong, D. Zhu, W. Wu, H. Qian, M. Song, H. Huang, C. Li, K. Wang, R. Yaoet al., “Restgpt: Connecting large language models with real-world restful apis,”arXiv preprint arXiv:2306.06624, 2023
-
[32]
Enhancing tool retrieval with iterative feedback from large language models,
Q. Xu, Y . Li, H. Xia, and W. Li, “Enhancing tool retrieval with iterative feedback from large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 9609–9619
2024
-
[33]
Toolgen: Unified tool retrieval and calling via generation,
R. Wang, X. Han, L. Ji, S. Wang, T. Baldwin, and H. Li, “Toolgen: Unified tool retrieval and calling via generation,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 73 473– 73 498
2025
-
[34]
Reciprocal rank fusion outperforms condorcet and individual rank learning methods,
G. V . Cormack, C. L. Clarke, and S. Buettcher, “Reciprocal rank fusion outperforms condorcet and individual rank learning methods,” inProceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, 2009, pp. 758–759
2009
-
[35]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[36]
Bundle recommenda- tion with graph convolutional networks,
J. Chang, C. Gao, X. He, D. Jin, and Y . Li, “Bundle recommenda- tion with graph convolutional networks,” inProceedings of the 43rd international ACM SIGIR conference on Research and development in Information Retrieval, 2020, pp. 1673–1676
2020
-
[37]
A survey on bundle recommendation: Methods, applications, and challenges,
M. Sun, L. Li, M. Li, X. Tao, D. Zhang, Q. Xie, P. Wang, and J. X. Huang, “A survey on bundle recommendation: Methods, applications, and challenges,”ACM Computing Surveys, 2024
2024
-
[38]
Bundle mcr: Towards conversational bundle recommendation,
Z. He, H. Zhao, T. Yu, S. Kim, F. Du, and J. McAuley, “Bundle mcr: Towards conversational bundle recommendation,” inProceedings of the 16th ACM Conference on Recommender Systems, 2022, pp. 288–298
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.