Learning User-Aware Recall: Personalized Retrieval in Long-Term Conversational Memory
Pith reviewed 2026-07-02 23:04 UTC · model grok-4.3
The pith
Deriving an explicit user profile from memories serves as a personalized prior to make retrieval user-aware, with further gains from training a query rewriter via policy optimization on retrieval and answer feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
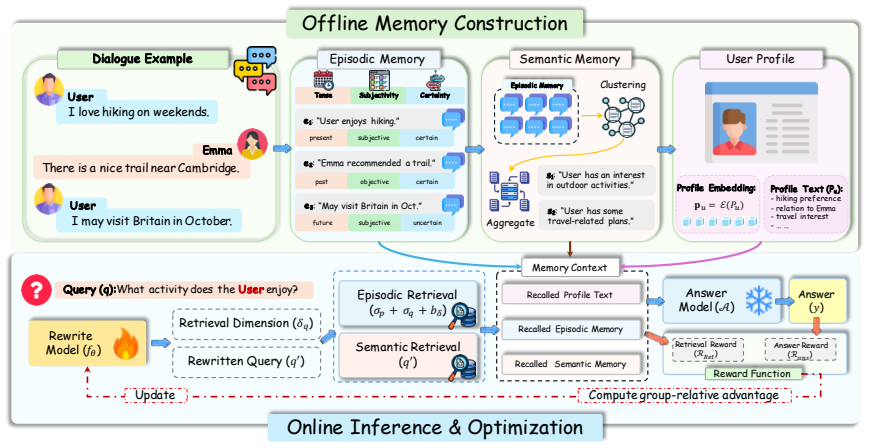
PPRO derives an explicit user profile from accumulated memories to serve as a personalized prior in memory ranking, making retrieval user-aware, and trains a query rewriter with Group Relative Policy Optimization using retrieval and answer quality feedback while keeping the memory banks and answer model fixed, yielding consistent gains over baselines on long-term memory benchmarks.
What carries the argument
The user profile derived from episodic and semantic memory banks, which provides a personalized prior for ranking retrieved memories, together with Group Relative Policy Optimization training of the query rewriter.
If this is right
- Memory retrieval accounts for stable user attributes, preferences, and relationships in addition to query similarity.
- The query rewriter can be optimized using feedback on both evidence retrieval quality and downstream answer quality without altering the memory banks or answer model.
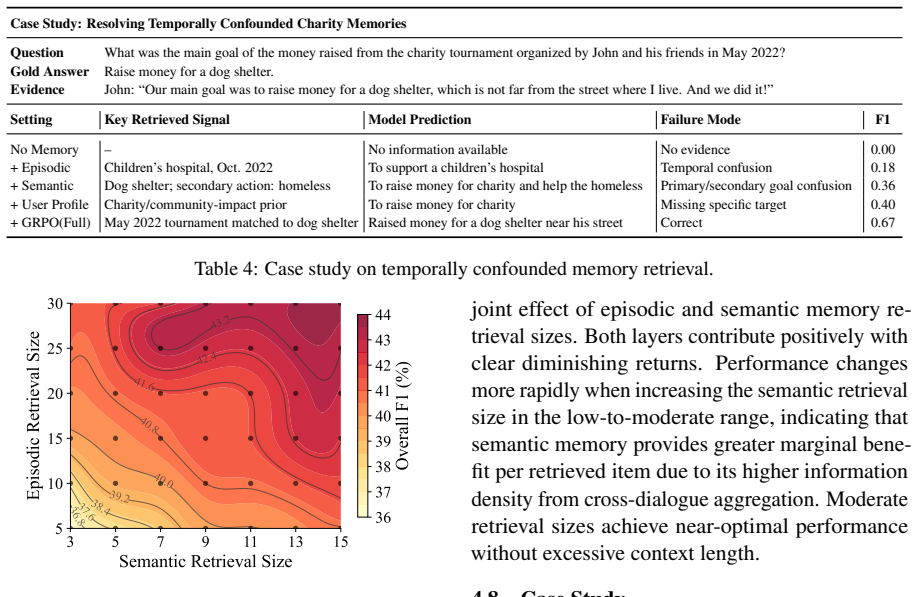
- Both profile-guided ranking and retrieval-oriented rewriting make independent contributions to performance.
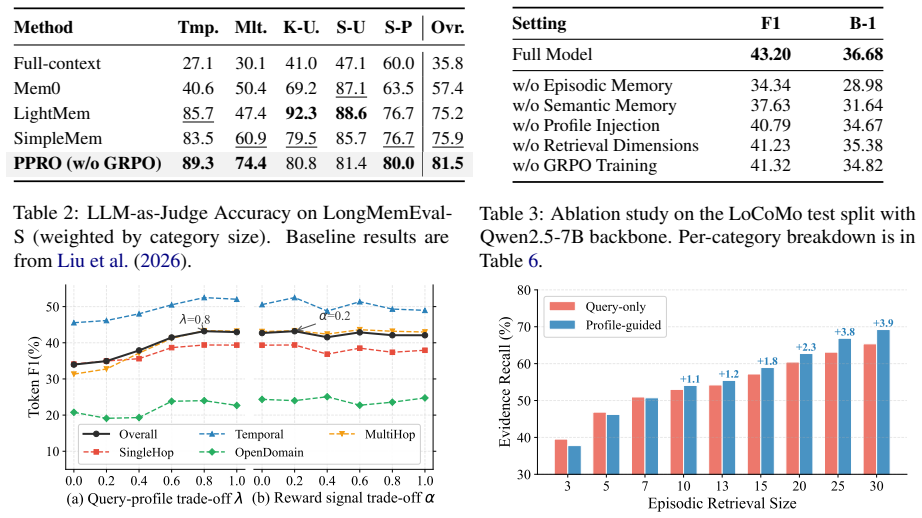
- The framework produces consistent gains over training-free memory systems and training-based baselines on long-term conversation benchmarks.
Where Pith is reading between the lines
- If profiles remain stable over long dialogues, the method could support agents that maintain consistent personalization across sessions without repeated profile updates.
- The separation between profile construction and retrieval optimization opens the possibility of swapping in different profile extraction methods while keeping the ranking and rewriting components fixed.
- Applying the same profile-prior approach to multi-user settings would require mechanisms to isolate and protect individual profiles during shared retrieval.
- Testing whether the gains hold when memory banks grow to millions of entries would clarify the scalability of profile-guided ranking.
Load-bearing premise
A stable and accurate user profile can be reliably derived from dialogue histories and provides an independent, non-redundant signal that improves ranking beyond query similarity alone.
What would settle it
An experiment on LoCoMo or LongMemEval-S showing no gain or a loss in retrieval accuracy and answer quality when the user profile prior is removed or when the trained rewriter is replaced by an untrained version would falsify the central claim.
Figures

read the original abstract
Long-term conversational agents are expected to remember past interactions, but memory is useful only when the right evidence is recalled for the right user. Existing memory-augmented LLM agents have made progress in building compact memory banks, yet retrieval is still often driven by query-centered similarity or fixed ranking rules, leaving user-conditioned relevance underexplored. To address this gap, we propose Profile-guided Personalized Retrieval Optimization (PPRO), a retrieval-centric framework that makes memory retrieval both user-aware and optimizable. PPRO builds episodic and semantic memory banks from dialogue histories and derives a user profile from accumulated memories. The profile serves as an explicit personalized prior in memory ranking, allowing retrieval to account for stable user attributes, preferences, and relationships. PPRO further trains a query rewriter with Group Relative Policy Optimization, using both evidence retrieval quality and downstream answer quality as feedback while keeping the memory banks and answer model fixed. Experiments on LoCoMo and LongMemEval-S show consistent gains over training-free memory systems and training-based baselines. Ablation studies further show that both profile-guided ranking and retrieval-oriented rewriting contribute substantially to performance, highlighting retrieval optimization as a key factor in personalized long-term memory use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Profile-guided Personalized Retrieval Optimization (PPRO) for long-term conversational agents. It constructs episodic and semantic memory banks from dialogue histories, derives an explicit user profile from accumulated memories to serve as a personalized prior in memory ranking, and trains a query rewriter via Group Relative Policy Optimization (GRPO) using feedback from both retrieval quality and downstream answer quality while keeping memory banks and the answer model fixed. Experiments on LoCoMo and LongMemEval-S report consistent gains over training-free and training-based baselines, with ablations isolating the contributions of profile-guided ranking and retrieval-oriented rewriting.
Significance. If the results hold, the work meaningfully advances personalized retrieval in memory-augmented LLM agents by making retrieval explicitly user-aware through a derived profile prior and by optimizing the retrieval process itself via RL feedback. The ablation studies that isolate the profile's independent contribution and the retrieval rewriter's role provide concrete evidence supporting the central claim that user-conditioned relevance improves recall beyond query similarity alone. This framework is practical because it keeps the memory banks and answer model fixed during optimization.
minor comments (3)
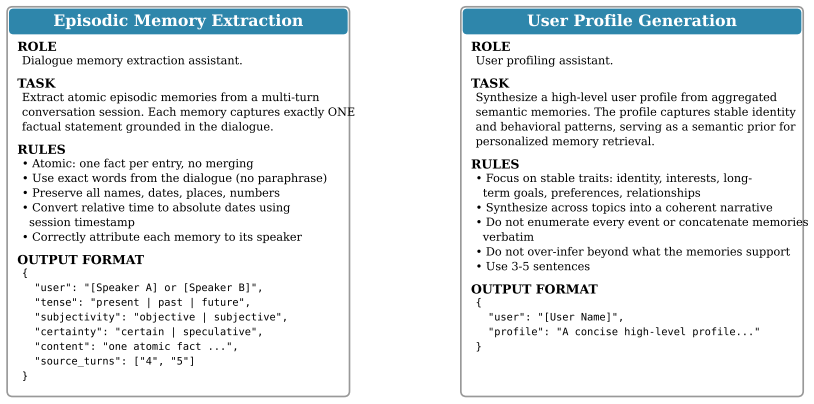
- §3.1: The construction of the user profile from episodic and semantic memories is described at a high level; adding a concrete example of profile attributes extracted from a sample dialogue history would improve reproducibility.
- Table 2: The ablation rows for profile-guided ranking report absolute gains but do not include standard deviations or statistical significance tests across multiple runs; this would strengthen the claim that the profile supplies a non-redundant signal.
- Figure 3: The visualization of GRPO training dynamics would benefit from clearer axis labels indicating whether the x-axis represents training steps or number of dialogue turns.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on Profile-guided Personalized Retrieval Optimization (PPRO) and for recommending minor revision. The report accurately captures the framework's use of an explicit user profile as a personalized prior and the application of GRPO for retrieval-oriented query rewriting. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper constructs a user profile from accumulated dialogue memories and employs it as a prior in ranking, then optimizes a query rewriter via GRPO with external feedback from both retrieval quality and downstream answer quality while holding memory banks and the answer model fixed. Ablation studies on LoCoMo and LongMemEval-S isolate the profile-guided ranking contribution versus query-only baselines and report measurable independent gains, confirming the profile signal is tested rather than assumed by construction. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation; the framework remains self-contained against external benchmarks.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.