Lost in the Tail: Addressing Geographic Imbalance in Urban Visual Place Recognition
Pith reviewed 2026-07-02 19:53 UTC · model grok-4.3
The pith
Rebalancing gradients across head and tail classes corrects geographic bias in urban visual place recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
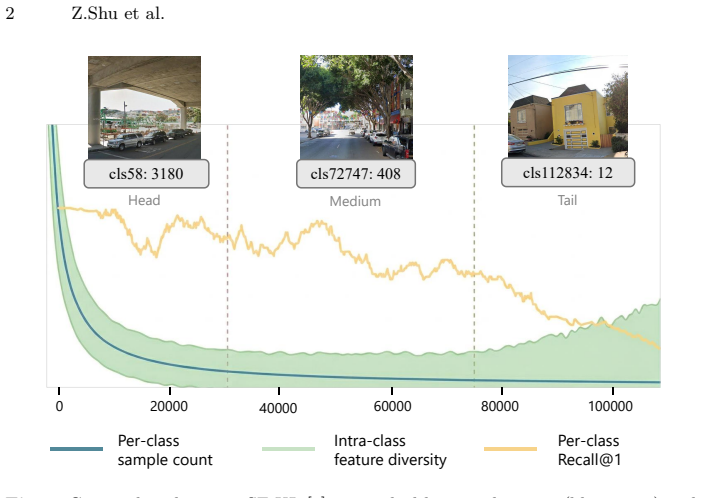
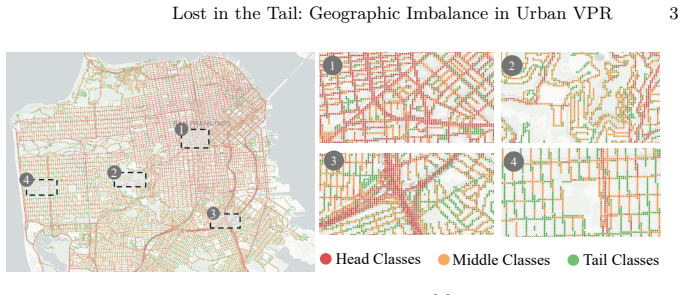
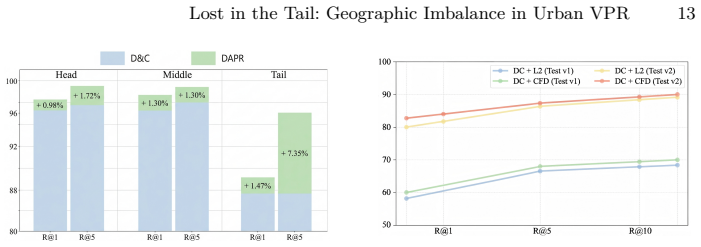
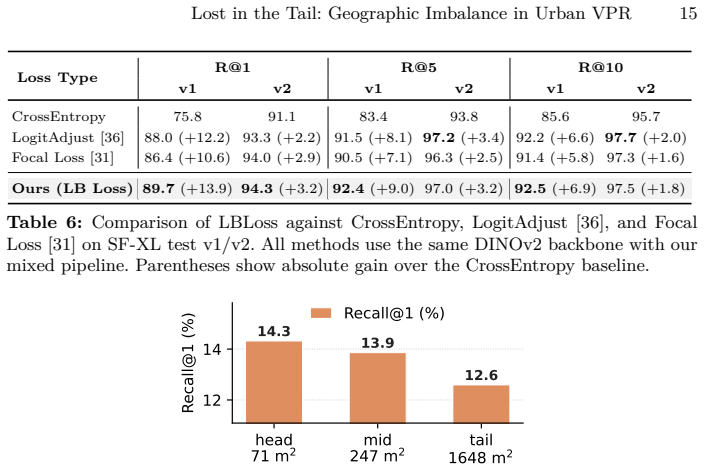
Urban-scale VPR suffers from long-tailed imbalance that biases models toward locations with abundant images. Distribution-Aware Place Recognition addresses this as a model-agnostic plug-in by rebalancing gradient contributions across head and tail classes and, within classification-retrieval pipelines, applying multi-scale distance search to compute per-class distributional compactness, which yields 18.3% improvement on SF-XL test set v1 and 6.7% on v2 while providing consistent gains across methods and benchmarks.
What carries the argument
Distribution-Aware Place Recognition (DAPR) as a model-agnostic plug-in framework that rebalances gradient contributions across head and tail classes and applies multi-scale distance search for per-class distributional compactness.
If this is right
- Delivers 18.3% higher performance than the prior baseline on SF-XL test set v1.
- Delivers 6.7% higher performance on SF-XL test set v2.
- Improves multiple existing VPR methods when added as a plug-in module on SF-XL, MSLS and Pitts30k.
- Reduces the systematic favoritism toward frequently photographed locations.
Where Pith is reading between the lines
- Methods like DAPR could help other computer vision tasks that face similar long-tailed geographic data distributions.
- Real-world deployment in cities could extend reliable place recognition to less-visited areas.
- Dataset creators might use the identified imbalance metrics to design more balanced collection strategies.
Load-bearing premise
Rebalancing gradients and multi-scale search will improve tail class performance without introducing new biases or requiring dataset-specific tuning.
What would settle it
An experiment showing that DAPR produces no gain over the baseline when tested on a new urban VPR dataset with a different long-tail structure would falsify the claim of broad generalizability.
Figures

read the original abstract
Urban-scale Visual Place Recognition (VPR) aims to identify the geographic location of a query image by matching it against a geo-tagged database. While recent methods achieve impressive performance, they overlook a serious long-tailed problem hidden in urban-scale datasets, which biases the model towards locations with abundant images and ignores less-visited areas, causing models to systematically favor frequently photographed locations while failing in sparsely covered areas. In this paper, we systematically characterize this imbalance challenge and propose Distribution-Aware Place Recognition (DAPR), a model-agnostic plug-in framework that rebalances gradient contributions across head and tail classes. Additionally, within classification-retrieval pipelines, DAPR applies a multi-scale distance search mechanism to compute per-class distributional compactness, providing complementary gains at the retrieval stage. On the large-scale SF-XL benchmark, our framework outperforms the previous classification-retrieval baseline by 18.3% on test set v1, and 6.7% on test set v2. As a plug-in module, it achieves consistent improvements across representative VPR methods on SF-XL, MSLS, and Pitts30k, demonstrating broad generalizability across different methods and benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a long-tailed geographic imbalance in urban visual place recognition (VPR) datasets that biases models toward frequently photographed locations. It proposes Distribution-Aware Place Recognition (DAPR), a model-agnostic plug-in framework that rebalances gradient contributions across head and tail classes; within classification-retrieval pipelines it additionally applies multi-scale distance search to compute per-class distributional compactness. On the SF-XL benchmark the method reports 18.3% and 6.7% gains over a prior classification-retrieval baseline on test sets v1 and v2 respectively, together with consistent plug-in improvements on representative VPR methods across SF-XL, MSLS and Pitts30k.
Significance. If the performance claims hold under controlled conditions, the work draws attention to an under-studied practical failure mode in large-scale urban VPR and supplies a lightweight, model-agnostic remedy. The explicit multi-benchmark evaluation and plug-in design are positive features that facilitate adoption.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the headline improvements (18.3% on SF-XL v1, 6.7% on v2) and the claim of consistent plug-in gains are presented without any description of experimental controls, error bars, statistical significance tests, or ablation studies that isolate the contribution of gradient rebalancing versus multi-scale search; this information is required to substantiate the central empirical claim.
- [Abstract] Abstract: the assertion that DAPR is model-agnostic and yields complementary gains without new biases rests on the premise that rebalancing weights, scale sets and compactness thresholds are held fixed across SF-XL, MSLS and Pitts30k; no statement confirms whether these hyperparameters were re-optimized per dataset, which directly affects the interpretation of the reported generalizability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical substantiation and clearer statements on generalizability. We address each major comment below and will incorporate the requested clarifications and additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline improvements (18.3% on SF-XL v1, 6.7% on v2) and the claim of consistent plug-in gains are presented without any description of experimental controls, error bars, statistical significance tests, or ablation studies that isolate the contribution of gradient rebalancing versus multi-scale search; this information is required to substantiate the central empirical claim.
Authors: We agree that the current presentation lacks explicit documentation of experimental controls, error bars, statistical significance, and component-wise ablations. To address this, the revised manuscript will include: (i) ablation tables isolating gradient rebalancing from multi-scale distance search, (ii) error bars from multiple random seeds where computationally feasible, and (iii) statistical significance tests (e.g., paired t-tests) on the reported gains. These additions will be placed in the Experiments section with corresponding updates to the abstract. revision: yes
-
Referee: [Abstract] Abstract: the assertion that DAPR is model-agnostic and yields complementary gains without new biases rests on the premise that rebalancing weights, scale sets and compactness thresholds are held fixed across SF-XL, MSLS and Pitts30k; no statement confirms whether these hyperparameters were re-optimized per dataset, which directly affects the interpretation of the reported generalizability.
Authors: The hyperparameters (rebalancing weights, scale sets, and compactness thresholds) were held fixed across all three benchmarks precisely to demonstrate the plug-in, model-agnostic character of DAPR without per-dataset retuning. We will add an explicit statement to this effect in both the abstract and the method description in the revised manuscript to remove any ambiguity regarding generalizability. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes an empirical plug-in framework (DAPR) for rebalancing gradients and multi-scale search in VPR, with all performance claims presented as measured outcomes on external benchmarks (SF-XL, MSLS, Pitts30k). No equations, derivations, or predictions are shown that reduce by construction to fitted inputs or self-citations; the central claims rest on benchmark results rather than any self-referential mechanism, satisfying the default expectation of a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neurocomputing513, 194–203 (2022)
Ali-bey, A., Chaib-draa, B., Giguère, P.: Gsv-cities: Toward appropriate supervised visual place recognition. Neurocomputing513, 194–203 (2022)
2022
-
[2]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Ali-Bey, A., Chaib-Draa, B., Giguere, P.: Mixvpr: Feature mixing for visual place recognition. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 2998–3007 (2023)
2023
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ali-Bey, A., Chaib-draa, B., Giguère, P.: Boq: A place is worth a bag of learnable queries. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17794–17803 (2024)
2024
-
[4]
Anderson, C.: The long tail: why the future of business is selling less of more
-
[5]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
Arandjelovic, R., Gronat, P., Torii, A., Pajdla, T., Sivic, J.: Netvlad: Cnn ar- chitecture for weakly supervised place recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
2016
-
[6]
In: Proceedings of the IEEE international conference on computer vision
Babenko, A., Lempitsky, V.: Aggregating local deep features for image retrieval. In: Proceedings of the IEEE international conference on computer vision. pp. 1269– 1277 (2015)
2015
-
[7]
Barbarani, G., Mostafa, M., Bayramov, H., Trivigno, G., Berton, G., Masone, C., Caputo, B.: Are local features all you need for cross-domain visual place recog- nition? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6155–6165 (2023)
2023
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Berton, G., Masone, C.: Megaloc: One retrieval to place them all. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2861–2867 (2025)
2025
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Berton, G., Masone, C., Caputo, B.: Rethinking visual geo-localization for large- scale applications. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4878–4888 (2022)
2022
-
[10]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Berton, G., Masone, C., Paolicelli, V., Caputo, B.: Viewpoint invariant dense matching for visual geolocalization. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 12169–12178 (2021)
2021
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Berton, G., Mereu, R., Trivigno, G., Masone, C., Csurka, G., Sattler, T., Caputo, B.: Deep visual geo-localization benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5396–5407 (2022)
2022
-
[12]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Berton, G., Trivigno, G., Caputo, B., Masone, C.: Eigenplaces: Training viewpoint robust models for visual place recognition. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 11080–11090 (2023)
2023
-
[13]
In: ICASSP 2021-2021 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP)
Chen, D., Chen, Y., Li, Y., Mao, F., He, Y., Xue, H.: Self-supervised learning for few-shot image classification. In: ICASSP 2021-2021 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP). pp. 1745–1749. IEEE (2021)
2021
-
[14]
In: European conference on computer vision
Chu, P., Bian, X., Liu, S., Ling, H.: Feature space augmentation for long-tailed data. In: European conference on computer vision. pp. 694–710. Springer (2020)
2020
-
[15]
The annals of Statistics pp
Feuerverger, A., Mureika, R.A.: The empirical characteristic function and its ap- plications. The annals of Statistics pp. 88–97 (1977)
1977
-
[16]
In: European Conference on Computer Vision
Garg, K., Puligilla, S.S., Kolathaya, S., Krishna, M., Garg, S.: Revisit anything: Visual place recognition via image segment retrieval. In: European Conference on Computer Vision. pp. 326–343. Springer (2024)
2024
-
[17]
In: European conference on computer vision
Ge, Y., Wang, H., Zhu, F., Zhao, R., Li, H.: Self-supervising fine-grained region similarities for large-scale image localization. In: European conference on computer vision. pp. 369–386. Springer (2020) Lost in the Tail: Geographic Imbalance in Urban VPR 17
2020
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Haas, L., Skreta, M., Alberti, S., Finn, C.: Pigeon: Predicting image geolocations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12893–12902 (2024)
2024
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hausler, S., Garg, S., Xu, M., Milford, M., Fischer, T.: Patch-netvlad: Multi-scale fusion of locally-global descriptors for place recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14141– 14152 (2021)
2021
-
[20]
IEEE Access (2024)
Hu, J., Nie, J., Ning, Z., Feng, C., Wang, L., Li, J., Cheng, S.: Enhancing visual place recognition with hybrid attention mechanisms in mixvpr. IEEE Access (2024)
2024
-
[21]
Hu, S., Feng, M., Nguyen, R.M., Lee, G.H.: Cvm-net: Cross-view matching net- workforimage-basedground-to-aerialgeo-localization.In:ProceedingsoftheIEEE Conference on Computer Vision and Pattern Recognition. pp. 7258–7267 (2018)
2018
-
[22]
In: European Conference on Computer Vision
Izquierdo, S., Civera, J.: Close, but not there: Boosting geographic distance sen- sitivity in visual place recognition. In: European Conference on Computer Vision. pp. 240–257. Springer (2024)
2024
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Izquierdo,S.,Civera,J.:Optimaltransportaggregationforvisualplacerecognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 17658–17668 (June 2024)
2024
-
[24]
In: Proceedings of the IEEE Conference on Computer Vi- sion and Pattern Recognition
Jin Kim, H., Dunn, E., Frahm, J.M.: Learned contextual feature reweighting for image geo-localization. In: Proceedings of the IEEE Conference on Computer Vi- sion and Pattern Recognition. pp. 2136–2145 (2017)
2017
-
[25]
In: 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition
Jégou, H., Douze, M., Schmid, C., Pérez, P.: Aggregating local descriptors into a compact image representation. In: 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. pp. 3304–3311 (2010).https://doi. org/10.1109/CVPR.2010.5540039
-
[26]
In: Eighth In- ternational Conference on Learning Representations (ICLR) (2020)
Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., Kalantidis, Y.: Decoupling representation and classifier for long-tailed recognition. In: Eighth In- ternational Conference on Learning Representations (ICLR) (2020)
2020
-
[27]
IEEE Robotics and Automation Letters9(2), 1286–1293 (2023)
Keetha, N., Mishra, A., Karhade, J., Jatavallabhula, K.M., Scherer, S., Krishna, M., Garg, S.: Anyloc: Towards universal visual place recognition. IEEE Robotics and Automation Letters9(2), 1286–1293 (2023)
2023
-
[28]
In: European Conference on Computer Vision
Khaliq, A., Xu, M., Hausler, S., Milford, M., Garg, S.: Vlad-buff: burst-aware fast feature aggregation for visual place recognition. In: European Conference on Computer Vision. pp. 447–466. Springer (2024)
2024
-
[29]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, M., Cheung, Y.m., Lu, Y.: Long-tailed visual recognition via gaussian clouded logit adjustment. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6929–6938 (2022)
2022
-
[31]
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection.In:ProceedingsoftheIEEEinternationalconferenceoncomputervision. pp. 2980–2988 (2017)
2017
-
[32]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, L., Li, H., Dai, Y.: Stochastic attraction-repulsion embedding for large scale image localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2570–2579 (2019)
2019
-
[33]
Advances in Neural Information Processing Systems38, 85096–85124 (2026)
Lu, F., Jin, T., Ye, C., Lan, X., Liu, Y., Yuan, C.: Towards implicit aggregation: Robust image representation for place recognition in the transformer era. Advances in Neural Information Processing Systems38, 85096–85124 (2026)
2026
-
[34]
In: Proceed- 18 Z.Shu et al
Lu, F., Lan, X., Zhang, L., Jiang, D., Wang, Y., Yuan, C.: Cricavpr: Cross-image correlation-aware representation learning for visual place recognition. In: Proceed- 18 Z.Shu et al. ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16772–16782 (2024)
2024
-
[35]
In: The Twelfth Interna- tional Conference on Learning Representations (2024)
Lu, F., Zhang, L., Lan, X., Dong, S., Wang, Y., Yuan, C.: Towards seamless adap- tation of pre-trained models for visual place recognition. In: The Twelfth Interna- tional Conference on Learning Representations (2024)
2024
-
[36]
In: International Conference on Learning Represen- tations (2020)
Menon, A.K., Jayasumana, S., Rawat, A.S., Jain, H., Veit, A., Kumar, S.: Long-tail learning via logit adjustment. In: International Conference on Learning Represen- tations (2020)
2020
-
[37]
In: Proceedings of the European conference on computer vision (ECCV)
Muller-Budack, E., Pustu-Iren, K., Ewerth, R.: Geolocation estimation of photos using a hierarchical model and scene classification. In: Proceedings of the European conference on computer vision (ECCV). pp. 563–579 (2018)
2018
-
[38]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
In: International Conference on Image Analysis and Processing
Paolicelli, V., Tavera, A., Masone, C., Berton, G., Caputo, B.: Learning seman- tics for visual place recognition through multi-scale attention. In: International Conference on Image Analysis and Processing. pp. 454–466. Springer (2022)
2022
-
[40]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peng, G., Zhang, J., Li, H., Wang, D.: Attentional pyramid pooling of salient visual residuals for place recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 885–894 (2021)
2021
-
[41]
IEEE transactions on pattern analysis and machine intelligence 41(7), 1655–1668 (2018)
Radenović, F., Tolias, G., Chum, O.: Fine-tuning cnn image retrieval with no human annotation. IEEE transactions on pattern analysis and machine intelligence 41(7), 1655–1668 (2018)
2018
-
[42]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Seo, P.H., Weyand, T., Sim, J., Han, B.: Cplanet: Enhancing image geolocalization by combinatorial partitioning of maps. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 536–551 (2018)
2018
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Sferrazza, D., Berton, G., Trivigno, G., Masone, C.: To match or not to match: Revisiting image matching for reliable visual place recognition. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2849–2860 (2025)
2025
-
[44]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Shao, S., Chen, K., Karpur, A., Cui, Q., Araujo, A., Cao, B.: Global features are all you need for image retrieval and reranking. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11036–11046 (2023)
2023
-
[45]
Shi, J.X., Wei, T., Xiang, Y., Li, Y.F.: How re-sampling helps for long-tail learning? Advances in Neural Information Processing Systems36, 75669–75687 (2023)
2023
-
[46]
In: Workshop on Long-Term Auton- omy, IEEE International Conference on Robotics and Automation (ICRA) (2013)
Sünderhauf, N., Neubert, P., Protzel, P.: Are we there yet? challenging SeqSLAM on a 3000km journey across all four seasons. In: Workshop on Long-Term Auton- omy, IEEE International Conference on Robotics and Automation (ICRA) (2013)
2013
-
[47]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Torii, A., Arandjelovic, R., Sivic, J., Okutomi, M., Pajdla, T.: 24/7 place recogni- tion by view synthesis. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1808–1817 (2015)
2015
-
[48]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Trivigno, G., Berton, G., Aragon, J., Caputo, B., Masone, C.: Divide&classify: Fine-grained classification for city-wide visual geo-localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11142– 11152 (October 2023)
2023
-
[49]
In: International Conference on Learning Representations
Tzachor, I., Lerner, B., Levy, M., Green, M., Berkovitz Shalev, T., Habib, G., Samuel, D., Zailer, N., Shimshi, O., Darshan, N., et al.: Effovpr: Effective founda- tion model utilization for visual place recognition. In: International Conference on Learning Representations. vol. 2025, pp. 42817–42839 (2025)
2025
-
[50]
In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=RzY9qQHUXy
Wang, B., Wang, P., Xu, W., Wang, X., Zhang, Y., Wang, K., Wang, Y.: Kill two birds with one stone: Rethinking data augmentation for deep long-tailed learn- Lost in the Tail: Geographic Imbalance in Urban VPR 19 ing. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=RzY9qQHUXy
2024
-
[51]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Wang, H., Wang, Y., Zhou, Z., Ji, X., Gong, D., Zhou, J., Li, Z., Liu, W.: Cosface: Large margin cosine loss for deep face recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5265–5274 (2018)
2018
-
[52]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, R., Shen, Y., Zuo, W., Zhou, S., Zheng, N.: Transvpr: Transformer-based place recognition with multi-level attention aggregation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13648– 13657 (2022)
2022
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, S., Yang, Y., Liu, Z., Sun, C., Hu, X., He, C., Zhang, L.: Dataset distillation with neural characteristic function: A minmax perspective. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 25570–25580 (June 2025)
2025
-
[54]
Advances in Neural Information Processing Systems36, 48417–48430 (2023)
Wang, Z., Xu, Q., Yang, Z., He, Y., Cao, X., Huang, Q.: A unified generalization analysis of re-weighting and logit-adjustment for imbalanced learning. Advances in Neural Information Processing Systems36, 48417–48430 (2023)
2023
-
[55]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Wang, Z., Xu, Q., Yang, Z., Xu, Z., Zhang, L., Cao, X., Huang, Q.: A unified per- spective for loss-oriented imbalanced learning via localization. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[56]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Warburg, F., Hauberg, S., Lopez-Antequera, M., Gargallo, P., Kuang, Y., Civera, J.: Mapillary street-level sequences: A dataset for lifelong place recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 2626–2635 (2020)
2020
-
[57]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV)
Warburg, F., Jørgensen, M., Civera, J., Hauberg, S.: Bayesian triplet loss: Uncer- tainty quantification in image retrieval. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV). pp. 12158–12168 (2021)
2021
-
[58]
In: European conference on computer vision
Weyand, T., Kostrikov, I., Philbin, J.: Planet-photo geolocation with convolutional neural networks. In: European conference on computer vision. pp. 37–55. Springer (2016)
2016
-
[59]
In: European conference on computer vision
Wu, T., Huang, Q., Liu, Z., Wang, Y., Lin, D.: Distribution-balanced loss for multi- label classification in long-tailed datasets. In: European conference on computer vision. pp. 162–178. Springer (2020)
2020
-
[60]
In: Forty-first International Conference on Machine Learning (2024)
Yang, Z., Xu, Q., Wang, Z., Li, S., Han, B., Bao, S., Cao, X., Huang, Q.: Harnessing hierarchical label distribution variations in test agnostic long-tail recognition. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[61]
ACM Transactions on Human-Robot Interaction14(2), 1–36 (2024)
Ye, X., Robert, L.P.: A human–security robot interaction literature review. ACM Transactions on Human-Robot Interaction14(2), 1–36 (2024)
2024
-
[62]
Pattern Recognition161, 111200 (2025)
Yu, H., Du, Y., Wu, J.: Reviving undersampling for long-tailed learning. Pattern Recognition161, 111200 (2025)
2025
-
[63]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zaffar, M., Nan, L., Kooij, J.F.P.: On the estimation of image-matching uncer- tainty in visual place recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 17743–17753 (2024)
2024
-
[64]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Zhang, H., Chen, X., Jing, H., Zheng, Y., Wu, Y., Jin, C.: Etr: An efficient trans- former for re-ranking in visual place recognition. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 5665–5674 (2023)
2023
-
[65]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, S., Mao, H., Chen, Q., Kim, Y.: Efficient visual place recognition through multimodal semantic knowledge integration. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 5601–5610 (2025)
2025
-
[66]
IEEE transactions on pattern analysis and machine intelligence45(9), 10795– 10816 (2023) 20 Z.Shu et al
Zhang, Y., Kang, B., Hooi, B., Yan, S., Feng, J.: Deep long-tailed learning: A sur- vey. IEEE transactions on pattern analysis and machine intelligence45(9), 10795– 10816 (2023) 20 Z.Shu et al
2023
-
[67]
In: Proceedings of the AAAI conference on artificial intelligence
Zhao, Y., Chen, W., Tan, X., Huang, K., Zhu, J.: Adaptive logit adjustment loss for long-tailed visual recognition. In: Proceedings of the AAAI conference on artificial intelligence. vol. 36, pp. 3472–3480 (2022)
2022
-
[68]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, S., Yang, L., Chen, C., Shah, M., Shen, X., Wang, H.: R2former: Unified retrieval and reranking transformer for place recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19370– 19380 (2023)
2023
-
[69]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, S., Yang, T., Chen, C.: Vigor: Cross-view image geo-localization beyond one- to-one retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3640–3649 (2021) Lost in the Tail: Geographic Imbalance in Urban VPR 1 Lost in the Tail: Addressing Geographic Imbalance in Urban Visual Place Recognition Supplementa...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.