The Illusion of Safety: Multi-Tier Verification of AI vs. Human C++ Code
Pith reviewed 2026-07-02 17:48 UTC · model grok-4.3
The pith
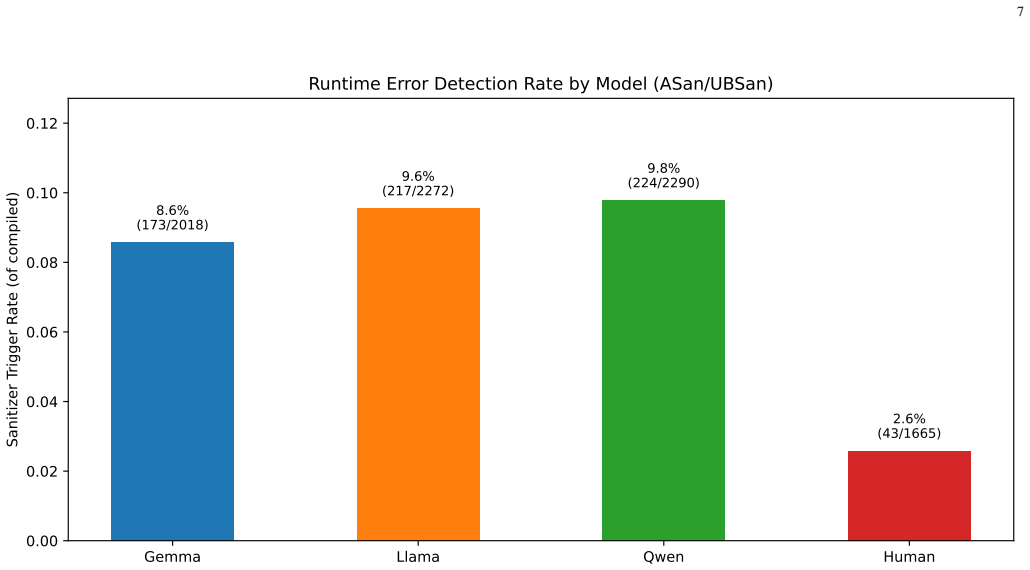
AI-generated C++ code triggers confirmed runtime violations at roughly twice the rate of human code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
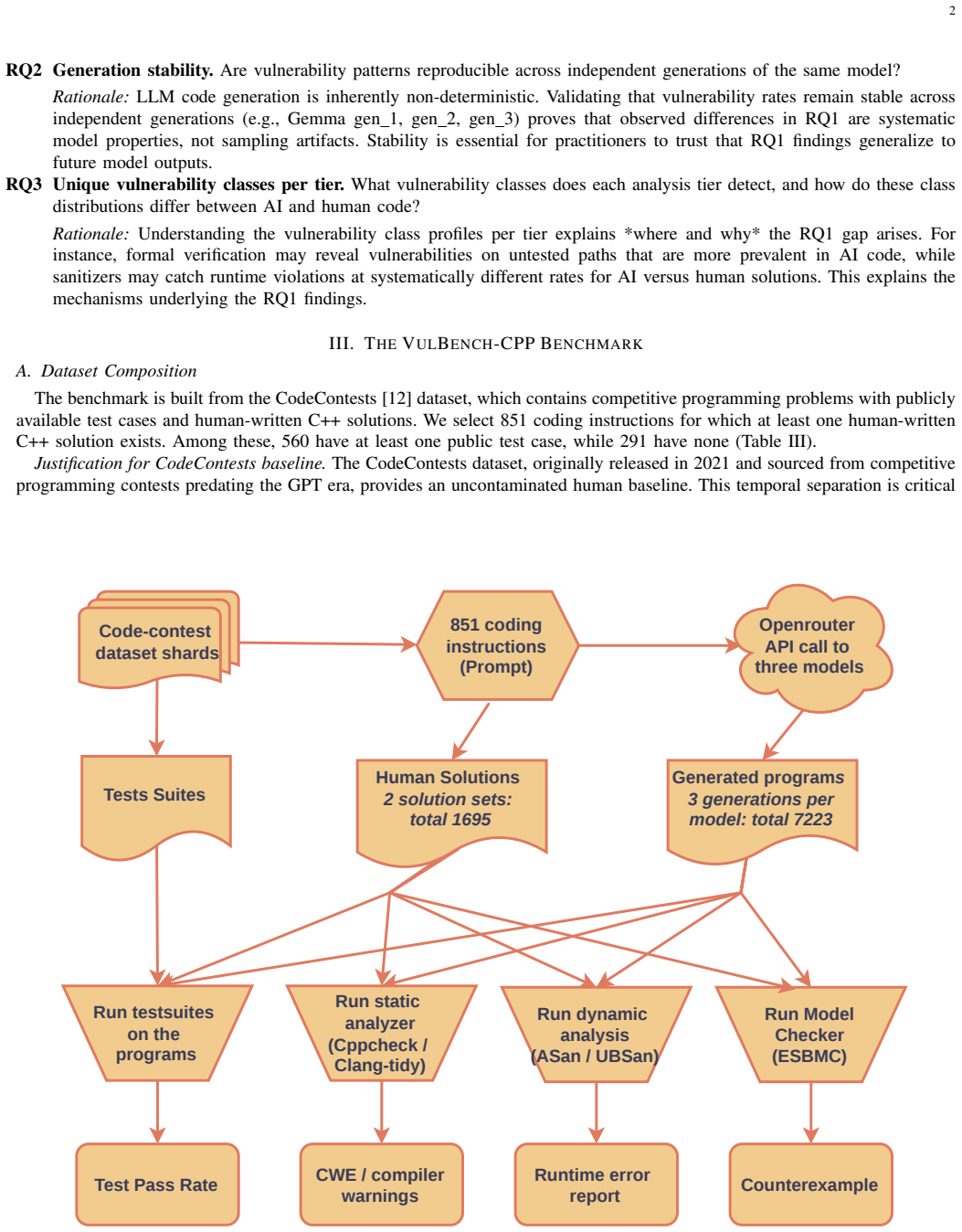
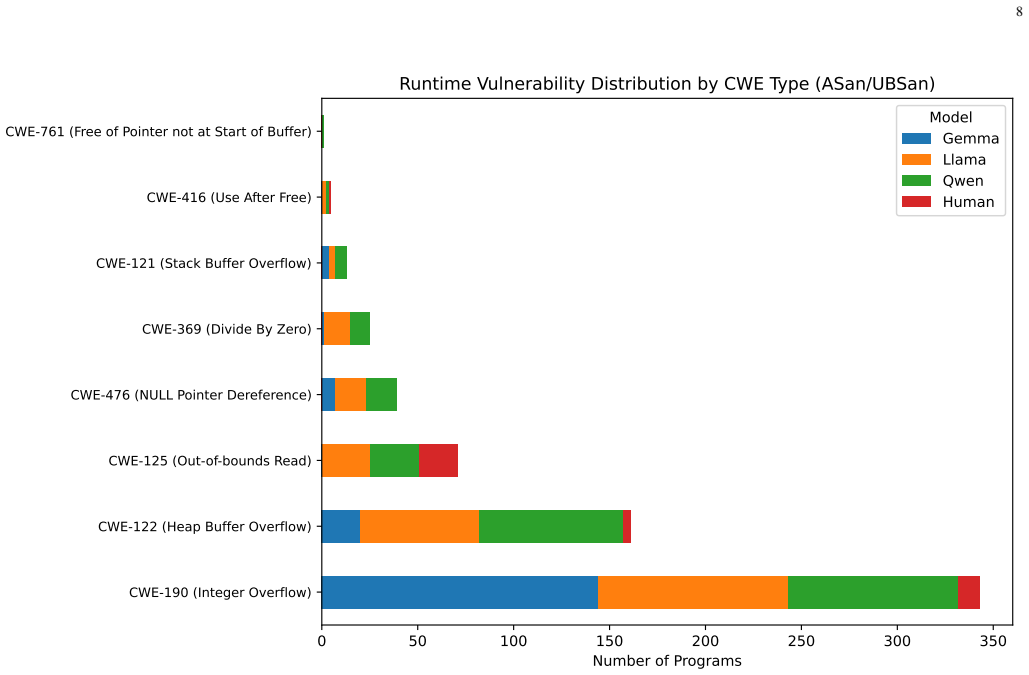
On the VULBENCH-CPP benchmark of 8,918 C++ programs generated by three open-weight LLMs and by human authors, four-tier verification (functional testing, static analysis with cppcheck and clang-tidy, dynamic analysis with ASan/UBSan, and bounded model checking with ESBMC) shows AI code roughly twice as likely to trigger a confirmed runtime violation as human code after accounting for shared-task correlations and controlling for length and test pass rate. Static analysis alone masks the gap because longer code produces more warnings regardless of origin, and the tiers detect different violation classes, so no single tier suffices.
What carries the argument
VULBENCH-CPP benchmark of 8,918 programs with four verification tiers (functional testing, static analysis, dynamic analysis via ASan/UBSan, bounded model checking via ESBMC) applied while controlling for task-level correlations.
If this is right
- Static analysis alone cannot be trusted to compare AI and human code safety because length effects and distinct violation classes mask real differences.
- Combined dynamic and model-checking verification is required to expose the elevated risk in AI-generated C++.
- The roughly twofold gap appears consistently across the three LLMs and across independent generations.
- No single verification tier captures all violation types, so safety claims based on one method are incomplete.
Where Pith is reading between the lines
- Teams that rely on LLMs for C++ components in security-sensitive systems should default to runtime verification rather than static checks alone.
- The result raises the possibility that current LLM training objectives do not sufficiently penalize memory-unsafe patterns that survive functional tests.
- Extending the same multi-tier protocol to other memory-unsafe languages or to larger codebases would test whether the gap generalizes beyond competitive-programming tasks.
Load-bearing premise
Dynamic analysis and bounded model checking detect real exploitable violations without enough false negatives or positives to reverse the AI-versus-human comparison.
What would settle it
Re-running the same programs with alternative dynamic or unbounded checkers that yields no measurable difference in confirmed violation rates between AI and human solutions.
Figures
read the original abstract
Large language models increasingly generate C++, a memory-unsafe language where a single overlooked violation can become an exploitable bug. Yet most security evaluations of AI-generated code rely on static analysis alone, which flags warnings without confirming runtime violations or reasoning about untested paths. We ask whether AI-generated C++ is measurably less safe than human-written code, and whether common verification tools agree on the risk. We introduce VULBENCH-CPP, a benchmark of 8,918 C++ programs from three open-weight LLMs (Gemma 3 27B IT, LLaMA 3.3 70B Instruct, Qwen 2.5 Coder 32B Instruct) and human authors across 851 competitive-programming tasks. Each program is annotated by four verification tiers: functional testing, static analysis (cppcheck, clang-tidy), dynamic analysis (ASan/UBSan), and bounded model checking (ESBMC). Accounting for the correlation among solutions to a shared task, we find that AI-generated code is roughly twice as likely as human code to trigger a confirmed runtime violation, even after controlling for code length and test pass-rate. Under static analysis the two look equally safe, but this is misleading: the apparent similarity reflects code length rather than real safety, and the tiers detect largely different classes of violation, so no single tier is sufficient. The gap is consistent across independent generations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VULBENCH-CPP, a benchmark of 8,918 C++ programs from three LLMs (Gemma 3 27B IT, LLaMA 3.3 70B Instruct, Qwen 2.5 Coder 32B Instruct) and human authors across 851 competitive-programming tasks. Each program receives annotations from four verification tiers (functional testing, static analysis via cppcheck/clang-tidy, dynamic analysis via ASan/UBSan, and bounded model checking via ESBMC). After accounting for task-level correlation and controlling for code length and test pass-rate, the central claim is that AI-generated code is roughly twice as likely as human code to trigger a confirmed runtime violation; static analysis alone shows no difference, but the tiers detect largely different violation classes.
Significance. If the multi-tier comparison holds after addressing detection uniformity, the work supplies concrete empirical evidence that static analysis is insufficient for assessing AI code safety in memory-unsafe languages and that dynamic plus model-checking tiers reveal a measurable gap. The benchmark construction, use of multiple independent LLMs, and explicit controls for task correlation are strengths that would make the dataset and methodology reusable for follow-on studies.
major comments (2)
- [Abstract / Methods (verification tiers)] Abstract and Methods (verification tiers description): The headline factor-of-two result equates 'confirmed runtime violation' with triggers from ASan/UBSan plus ESBMC, yet the manuscript provides no per-origin (AI vs. human) detection coverage statistics or false-negative calibration on injected faults. Because these tools are path- and bound-sensitive, systematic differences in control-flow complexity between AI and human solutions (even after length/pass-rate controls) could produce differential false-negative rates that artifactually inflate the reported gap; this assumption is load-bearing for the central claim.
- [Results] Results (correlation accounting): The claim that the gap persists 'after accounting for the correlation among solutions to a shared task' is presented without specifying the statistical model (e.g., mixed-effects logistic regression, task-level clustering) or reporting the adjusted odds ratio with confidence intervals; without these details it is impossible to assess whether the factor-of-two survives the correction or is sensitive to modeling choices.
minor comments (1)
- [Abstract] The abstract states that 'the tiers detect largely different classes' but does not include a table or figure quantifying the overlap (or lack thereof) between tiers; adding such a breakdown would improve clarity without altering the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions where the manuscript can be strengthened without misrepresenting the existing analysis.
read point-by-point responses
-
Referee: Abstract and Methods (verification tiers description): The headline factor-of-two result equates 'confirmed runtime violation' with triggers from ASan/UBSan plus ESBMC, yet the manuscript provides no per-origin (AI vs. human) detection coverage statistics or false-negative calibration on injected faults. Because these tools are path- and bound-sensitive, systematic differences in control-flow complexity between AI and human solutions (even after length/pass-rate controls) could produce differential false-negative rates that artifactually inflate the reported gap; this assumption is load-bearing for the central claim.
Authors: We agree that explicit per-origin detection coverage and false-negative calibration would strengthen the claims. The current controls for code length and test pass-rate serve as proxies for complexity, and the gap remains consistent across three independent LLMs. However, the manuscript does not report per-origin coverage statistics or perform fault-injection calibration. In revision we will add origin-stratified detection coverage tables and a dedicated limitations paragraph on path- and bound-sensitivity of the dynamic and model-checking tiers. Full fault-injection calibration lies beyond the present experimental scope and will be noted as such. revision: partial
-
Referee: Results (correlation accounting): The claim that the gap persists 'after accounting for the correlation among solutions to a shared task' is presented without specifying the statistical model (e.g., mixed-effects logistic regression, task-level clustering) or reporting the adjusted odds ratio with confidence intervals; without these details it is impossible to assess whether the factor-of-two survives the correction or is sensitive to modeling choices.
Authors: We will revise the Results section to state explicitly that a mixed-effects logistic regression with task as a random effect was used to account for within-task correlation. The revised text will also report the adjusted odds ratio and 95% confidence interval, allowing readers to evaluate the robustness of the factor-of-two finding under the chosen model. revision: yes
Circularity Check
No circularity: empirical measurement using external verification tools
full rationale
The paper performs an empirical comparison of violation rates between AI-generated and human C++ code using independently developed tools (cppcheck, clang-tidy, ASan/UBSan, ESBMC) on a fixed benchmark of 8,918 programs. No equations, fitted parameters, or predictions are defined in terms of the target result. The central claim (roughly 2x higher violation rate for AI code after controls) is a direct statistical measurement from tool outputs, not a reduction to self-citations or ansatzes. Self-citations, if present, are not load-bearing for the comparison. The derivation chain is self-contained against external benchmarks and falsifiable data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The verification tools cppcheck, clang-tidy, ASan/UBSan, and ESBMC correctly identify violations in the generated programs without substantial systematic bias between AI and human code.
Reference graph
Works this paper leans on
-
[1]
A survey on large language models for code generation,
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A survey on large language models for code generation,”ACM Transactions on Software Engineering and Methodology, vol. 35, no. 2, pp. 1–72, 2026
2026
-
[2]
Octoverse: The state of open source and ai,
GitHub, “Octoverse: The state of open source and ai,” GitHub, Tech. Rep., 2024. [Online]. Available: https://octoverse.github.com/
2024
-
[3]
Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,” vol. 68, no. 2. ACM New York, NY , USA, 2025, pp. 96–105
2025
-
[4]
SoK: Eternal war in memory,
L. Szekeres, M. Payer, T. Wei, and D. Song, “SoK: Eternal war in memory,” in2013 IEEE Symposium on Security and Privacy (S&P). IEEE, 2013, pp. 48–62
2013
-
[5]
How secure is code generated by ChatGPT?
R. Khoury, A. R. Avila, J. Brunelle, and B. M. Camara, “How secure is code generated by ChatGPT?” in2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2023, pp. 2445–2450
2023
-
[6]
An empirical study of code smells in transformer-based code generation techniques,
M. L. Siddiq and J. C. S. Santos, “An empirical study of code smells in transformer-based code generation techniques,” inProceedings of the 22nd IEEE International Working Conference on Source Code Analysis and Manipulation (SCAM ’22). IEEE, 2022, pp. 71–82
2022
-
[7]
Rethinking the evaluation of secure code generation,
S.-C. Dai, J. Xu, and G. Tao, “Rethinking the evaluation of secure code generation,” inProceedings of the 48th International Conference on Software Engineering (ICSE ’26). Rio de Janeiro, Brazil: ACM/IEEE, 2026, to appear
2026
-
[8]
The formai dataset: Generative ai in software security through the lens of formal verification,
N. Tihanyi, T. Bisztray, R. Jain, M. A. Ferrag, L. C. Cordeiro, and V . Mavroeidis, “The formai dataset: Generative ai in software security through the lens of formal verification,” inProceedings of the 19th International Conference on Predictive Models and Data Analytics in Software Engineering, ser. PROMISE 2023. New York, NY , USA: Association for Comp...
-
[9]
How secure is ai-generated code: a large-scale comparison of large language models,
N. Tihanyi, T. Bisztray, M. A. Ferrag, R. Jain, and L. C. Cordeiro, “How secure is ai-generated code: a large-scale comparison of large language models,” Empirical Software Engineering, vol. 30, no. 2, p. 47, 2025
2025
-
[10]
Secodeplt: A unified platform for evaluating the security of code genai,
Y . Nie, Z. Wang, Y . Yang, R. Jiang, Y . Tang, X. Davies, Y . Gal, B. Li, W. Guo, and D. Song, “Secodeplt: A unified platform for evaluating the security of code genai,”arXiv preprint arXiv:2410.11096, 2024
-
[11]
ESBMC 5.0: An industrial-strength C model checker,
M. R. Gadelha, F. R. Monteiro, J. Morse, L. C. Cordeiro, B. Fischer, and D. A. Nicole, “ESBMC 5.0: An industrial-strength C model checker,” in Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering (ASE). ACM, 2018, pp. 888–891
2018
-
[12]
Competition-level code generation with alphacode,
Y . Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lagoet al., “Competition-level code generation with alphacode,”Science, vol. 378, no. 6624, pp. 1092–1097, 2022
2022
-
[13]
Gemma 3,
G. Team, “Gemma 3,” 2025. [Online]. Available: https://goo.gle/Gemma3Report
2025
-
[14]
Meta-llama-3.3-70b-instruct,
Meta, “Meta-llama-3.3-70b-instruct,” https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct, 2024
2024
-
[15]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Danget al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Openrouter: A unified interface for llms,
OpenRouter, “Openrouter: A unified interface for llms,” 2024. [Online]. Available: https://openrouter.ai/
2024
-
[17]
Cppcheck: A tool for static C/C++ code analysis,
D. Marjam ¨aki, “Cppcheck: A tool for static C/C++ code analysis,” http://cppcheck.sourceforge.net, 2007, accessed: December 15, 2025
2007
-
[18]
Common weakness enumeration,
The MITRE Corporation, “Common weakness enumeration,” 2024, accessed: February 2026. [Online]. Available: https://cwe.mitre.org/
2024
-
[19]
Clang-tidy — extra clang tools documentation,
LLVM Project, “Clang-tidy — extra clang tools documentation,” https://clang.llvm.org/extra/clang-tidy/, 2024, accessed: January 2026
2024
-
[20]
AddressSanitizer: A fast address sanity checker,
K. Serebryany, D. Bruening, A. Potapenko, and D. Vyukov, “AddressSanitizer: A fast address sanity checker,” in2012 USENIX Annual Technical Conference (USENIX ATC), 2012, pp. 309–318
2012
-
[21]
[Online]
LLVM Project,UndefinedBehaviorSanitizer, 2024, accessed: February 2026. [Online]. Available: https://clang.llvm.org/docs/UndefinedBehaviorSanitizer. html
2024
-
[22]
MemorySanitizer: Fast detector of uninitialized memory use in C++,
E. Stepanov and K. Serebryany, “MemorySanitizer: Fast detector of uninitialized memory use in C++,” in2015 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2015, pp. 46–55
2015
-
[23]
A few billion lines of code later: Using static analysis to find bugs in the real world,
A. Bessey, K. Block, B. Chelf, A. Chou, B. Fulton, S. Hallem, C. Henri-Gros, A. Kamsky, S. McPeak, and D. Engler, “A few billion lines of code later: Using static analysis to find bugs in the real world,”Communications of the ACM, vol. 53, no. 2, pp. 66–75, 2010
2010
-
[24]
A systematic mapping study on technical debt and its management,
Z. Liet al., “A systematic mapping study on technical debt and its management,”Journal of Systems and Software, 2015
2015
-
[25]
LLMSecEval: A dataset of natural language prompts for security evaluations,
C. Tony, M. Mutas, M. A. Ferrag, and L. C. Cordeiro, “LLMSecEval: A dataset of natural language prompts for security evaluations,” inProceedings of the 20th International Conference on Mining Software Repositories (MSR ’23), Data Showcase Track. IEEE, 2023
2023
-
[26]
Do users write more insecure code with AI assistants?
N. Perry, M. Srivastava, D. Kumar, and D. Boneh, “Do users write more insecure code with AI assistants?” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security (CCS ’23). ACM, 2023, pp. 2785–2799
2023
-
[27]
Lost at C: A user study on the security implications of large language model code assistants,
G. Sandoval, H. Pearce, T. Nys, R. Karri, S. Garg, and B. Dolan-Gavitt, “Lost at C: A user study on the security implications of large language model code assistants,” in32nd USENIX Security Symposium (USENIX Security ’23). USENIX Association, 2023, pp. 2205–2222
2023
-
[28]
Is GitHub Copilot as bad as humans at introducing vulnerabilities in code?
O. Asare, M. Nagappan, and N. Abutaleb, “Is GitHub Copilot as bad as humans at introducing vulnerabilities in code?”Empirical Software Engineering, vol. 28, no. 6, p. 129, 2023
2023
-
[29]
SafeGenBench: A benchmark framework for security vulnerability detection in LLM- generated code,
X. Li, J. Ding, C. Peng, B. Zhao, X. Gao, H. Gao, and X. Gu, “SafeGenBench: A benchmark framework for security vulnerability detection in LLM- generated code,” inProceedings of the 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL ’25), Volume 1: Long Papers. Association for Computational Linguist...
2025
-
[30]
Large language models for code analysis: Do LLMs really do their job?
C. Fang, N. Miao, S. Srivastav, J. Liu, R. Zhang, R. Fang, Asmita, R. Tsang, N. Nazari, H. Wang, and H. Homayoun, “Large language models for code analysis: Do LLMs really do their job?” in33rd USENIX Security Symposium (USENIX Security ’24). USENIX Association, 2024. 14
2024
-
[31]
OpenAI, “GPT-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Code Llama: Open Foundation Models for Code
B. Rozi `ere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remezet al., “Code Llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Measuring coding challenge competence with APPS,
D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, and J. Steinhardt, “Measuring coding challenge competence with APPS,” inProceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021
2021
-
[35]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton, “Program synthesis with large language models,”arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[36]
Symbolic model checking without BDDs,
A. Biere, A. Cimatti, E. M. Clarke, and Y . Zhu, “Symbolic model checking without BDDs,” inProceedings of the 5th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS). Springer, 1999, pp. 193–207
1999
-
[37]
Z3: An efficient SMT solver,
L. de Moura and N. Bjørner, “Z3: An efficient SMT solver,” inProceedings of the 14th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS). Springer, 2008, pp. 337–340
2008
-
[38]
ESBMC v6.0: Verifying C programs using k-induction and invariant inference,
M. R. Gadelha, F. R. Monteiro, L. C. Cordeiro, and D. A. Nicole, “ESBMC v6.0: Verifying C programs using k-induction and invariant inference,” International Journal on Software Tools for Technology Transfer, vol. 23, pp. 857–872, 2021
2021
-
[39]
State of the art in software verification and witness validation: SV-COMP 2024,
D. Beyer, “State of the art in software verification and witness validation: SV-COMP 2024,” inProceedings of the 30th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS). Springer, 2024, pp. 299–329
2024
-
[40]
CBMC – C bounded model checker,
D. Kroening and M. Tautschnig, “CBMC – C bounded model checker,” inProceedings of the 20th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS). Springer, 2014, pp. 389–391
2014
-
[41]
An empirical study of the non-determinism of chatgpt in code generation,
S. Ouyang, J. M. Zhang, M. Harman, and M. Wang, “An empirical study of the non-determinism of chatgpt in code generation,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 2, pp. 42:1–42:28, Jan. 2025
2025
-
[42]
HumanEvalComm: Benchmarking the communication competence of code generation for LLMs and LLM agent,
J. J. Wu and F. H. Fard, “HumanEvalComm: Benchmarking the communication competence of code generation for LLMs and LLM agent,”ACM Transactions on Software Engineering and Methodology, 2025, arXiv:2406.00215
-
[43]
Studying how configurations impact code generation in LLMs: The case of ChatGPT,
B. Donato, L. Mariani, D. Micucci, and O. Riganelli, “Studying how configurations impact code generation in LLMs: The case of ChatGPT,” in Proceedings of the 33rd IEEE/ACM International Conference on Program Comprehension (ICPC ’25), Research Track. ACM/IEEE, 2025
2025
-
[44]
Will it survive? deciphering the fate of ai-generated code in open source,
M. Rahman and E. Shihab, “Will it survive? deciphering the fate of ai-generated code in open source,”arXiv preprint arXiv:2601.16809, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.