EVOTS: Evolutionary Transformer Search for Time Series Forecasting
Pith reviewed 2026-07-02 19:48 UTC · model grok-4.3
The pith
Evolutionary search discovers competitive Transformer architectures for time series forecasting without hand-crafted rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
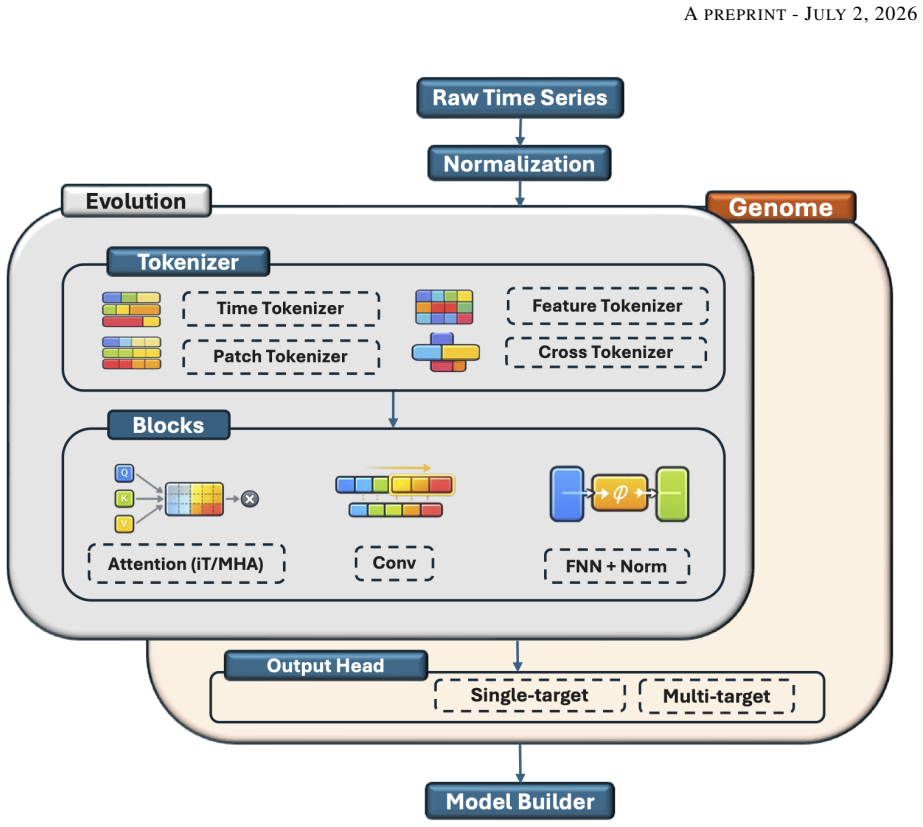
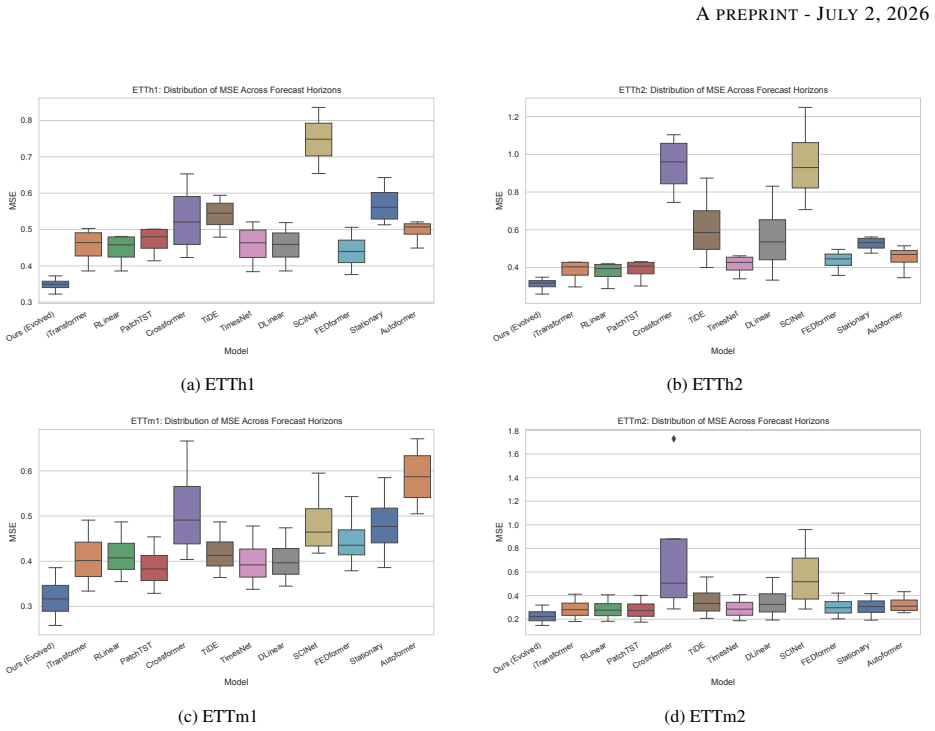
EVOTS encodes architectures as modular genomes allowing flexible composition of attention, feed-forward, and projection components, then applies evolutionary search with a repair mechanism that enforces validity. In experiments on ETTh1, ETTh2, ETTm1, and ETTm2 under univariate-to-univariate, multivariate-to-univariate, and multivariate-to-multivariate regimes with horizons 96 to 720, the evolved models reach competitive or improved MSE relative to a strong Transformer baseline in the multivariate-to-multivariate case.
What carries the argument
modular genome representation with repair mechanism that enforces structural validity to enable exploration of diverse architectures
If this is right
- Evolved architectures remain competitive across univariate-to-univariate and multivariate-to-univariate settings as well.
- Performance holds for forecast horizons of 96, 192, 336, and 720 steps.
- Wall-clock training times stay within ranges that indicate practical computational cost.
- The search process operates without hand-crafted design rules yet produces valid high-performing models.
Where Pith is reading between the lines
- The same genome-plus-repair approach could be tested on other sequence tasks such as natural language or audio modeling.
- If the evolved models generalize to unseen datasets outside the ETT family, the method would reduce dependence on task-specific manual tuning.
- Extending the genome to include additional operator types or different evolutionary selection pressures would be a direct next experiment.
Load-bearing premise
The modular genome representation together with the repair mechanism enables effective exploration of a diverse architecture space without relying on hand-crafted design rules.
What would settle it
If repeated evolutionary runs on the ETTm1 or ETTm2 datasets in the multivariate-to-multivariate setting produce architectures whose MSE is consistently higher than the fixed Transformer baseline across the tested horizons, the performance claim would be falsified.
Figures
read the original abstract
Evolutionary neural architecture design for multivariate time-series forecasting remains underexplored, with most approaches relying on fixed Transformer architectures despite substantial variation across tasks and forecasting settings. This paper introduces an evolutionary neural architecture search framework for discovering task-adaptive Transformer-like models for time-series forecasting (EVOTS). Architectures are encoded using a modular genome representation that enables flexible composition of attention, feed-forward, and projection components, while a repair mechanism enforces structural validity throughout the evolutionary process. This formulation allows effective exploration of a diverse architecture space without relying on hand-crafted design rules. The proposed approach is evaluated on four benchmark datasets from the ETT family (ETTh1, ETTh2, ETTm1, and ETTm2) under multiple forecasting settings, including univariate-to-univariate, multivariate-to-univariate, and multivariate-to-multivariate prediction, with horizons of 96, 192, 336, and 720. In the multivariate-to-multivariate setting, the evolved architectures achieve competitive and, in several cases, improved mean squared error relative to a strong Transformer-based baseline. Additional analyses examine performance differences across forecasting settings and report wall-clock training time to provide a coarse indication of computational cost. Overall, the results demonstrate that evolutionary search can effectively discover flexible and high-performing Transformer-like architectures for multivariate time-series forecasting within practical runtime constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EVOTS, an evolutionary neural architecture search framework for discovering task-adaptive Transformer-like models for multivariate time-series forecasting. Architectures are encoded via a modular genome representation with a repair mechanism to enforce validity; the method is evaluated on the four ETT benchmark datasets under univariate-to-univariate, multivariate-to-univariate, and multivariate-to-multivariate settings with horizons 96/192/336/720. The central empirical claim is that, in the multivariate-to-multivariate setting, the evolved models achieve competitive and in several cases improved MSE relative to a strong Transformer baseline, while additional analyses address performance differences across settings and wall-clock training time.
Significance. If the empirical claims hold under proper statistical controls, the work would provide evidence that evolutionary search with a modular genome can discover flexible, high-performing Transformer variants for time-series forecasting without hand-crafted rules, addressing an underexplored area. The practical runtime results and multi-setting evaluation would further strengthen the contribution, though the current presentation leaves the robustness of the performance gains open to question.
major comments (2)
- [Abstract / Experimental results] Abstract and experimental results section: the reported MSE improvements in the multivariate-to-multivariate setting are presented as single point estimates from the evolutionary search process. Because initialization, mutation, crossover, and selection are stochastic, the absence of multiple independent runs, standard deviations, or statistical significance tests (e.g., paired t-tests or Wilcoxon tests against the baseline) makes it impossible to determine whether observed gains reflect systematic superiority or lucky trajectories; this directly undermines the central claim.
- [Experimental results] Experimental setup (baseline implementation and data handling): the abstract states competitive MSE results but provides no details on how the Transformer baseline was implemented, whether hyperparameter search was performed for it, the precise train/validation/test splits, or any statistical testing protocol. These omissions are load-bearing for the comparison claim and must be supplied with sufficient specificity to allow reproduction.
minor comments (2)
- [Method] The description of the repair mechanism and genome representation would benefit from a small illustrative example (e.g., a before/after repair diagram) to clarify how structural validity is maintained without hand-crafted rules.
- [Experimental results] Wall-clock training time is reported as a coarse cost indicator; it would be clearer to also report the number of evaluated architectures or total search budget in FLOPs or GPU-hours for context.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of statistical robustness and reproducibility. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results section: the reported MSE improvements in the multivariate-to-multivariate setting are presented as single point estimates from the evolutionary search process. Because initialization, mutation, crossover, and selection are stochastic, the absence of multiple independent runs, standard deviations, or statistical significance tests (e.g., paired t-tests or Wilcoxon tests against the baseline) makes it impossible to determine whether observed gains reflect systematic superiority or lucky trajectories; this directly undermines the central claim.
Authors: We agree that single-run point estimates limit the strength of the claims given the stochastic nature of the evolutionary process. In the revised manuscript, we will report results from multiple independent evolutionary runs (at least five per setting), include means and standard deviations, and add statistical significance tests (Wilcoxon signed-rank tests) comparing evolved models to the baseline. These additions will be placed in the experimental results section and reflected in an updated abstract. revision: yes
-
Referee: [Experimental results] Experimental setup (baseline implementation and data handling): the abstract states competitive MSE results but provides no details on how the Transformer baseline was implemented, whether hyperparameter search was performed for it, the precise train/validation/test splits, or any statistical testing protocol. These omissions are load-bearing for the comparison claim and must be supplied with sufficient specificity to allow reproduction.
Authors: We acknowledge the need for greater specificity. The revised version will expand the experimental setup subsection to include: (i) the exact Transformer baseline architecture and hyperparameters, (ii) whether and how hyperparameter tuning was performed for the baseline, (iii) the precise train/validation/test split ratios and any preprocessing steps for the ETT datasets, and (iv) the full statistical testing protocol. This information will enable full reproduction of the comparisons. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external baseline comparisons
full rationale
The paper introduces an evolutionary NAS framework (EVOTS) for Transformer-like models in time-series forecasting and evaluates it empirically on ETT benchmarks under multiple settings. The central claim of competitive or improved MSE in the multivariate-to-multivariate case is supported by direct comparison to a fixed Transformer baseline, with no mathematical derivation, fitted parameters renamed as predictions, or self-citation chains that reduce the result to its own inputs. The modular genome and repair mechanism are design choices whose effectiveness is assessed via external benchmarks rather than by construction. This is a standard empirical NAS study with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
itransformer: Inverted transformers are effective for time series forecasting,
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “itransformer: Inverted transformers are effective for time series forecasting,” inInternational Conference on Representation Learning(B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, eds.), vol. 2024, pp. 11116–11140, 2024
2024
-
[2]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[3]
Informer: Beyond efficient transformer for long sequence time-series forecasting,
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond efficient transformer for long sequence time-series forecasting,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, pp. 11106–11115, 2021
2021
-
[4]
Temporal fusion transformers for interpretable multi-horizon time series forecasting,
B. Lim, S. Ö. Arık, N. Loeff, and T. Pfister, “Temporal fusion transformers for interpretable multi-horizon time series forecasting,”International journal of forecasting, vol. 37, no. 4, pp. 1748–1764, 2021
2021
-
[5]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,”Advances in neural information processing systems, vol. 34, pp. 22419–22430, 2021
2021
-
[6]
Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting,
Y . Zhang and J. Yan, “Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[7]
Large language models are zero-shot time series forecasters,
N. Gruver, M. Finzi, S. Qiu, and A. G. Wilson, “Large language models are zero-shot time series forecasters,” Advances in Neural Information Processing Systems, vol. 36, pp. 19622–19635, 2023
2023
-
[8]
Promptcast: A new prompt-based learning paradigm for time series forecasting,
H. Xue and F. D. Salim, “Promptcast: A new prompt-based learning paradigm for time series forecasting,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 6851–6864, 2023
2023
-
[9]
One fits all: Power general time series analysis by pretrained lm,
T. Zhou, P. Niu, L. Sun, R. Jin,et al., “One fits all: Power general time series analysis by pretrained lm,”Advances in neural information processing systems, vol. 36, pp. 43322–43355, 2023
2023
-
[10]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y . Zhang, X. Shi, P.-Y . Chen, Y . Liang, Y .-F. Li, S. Pan,et al., “Time-llm: Time series forecasting by reprogramming large language models,”arXiv preprint arXiv:2310.01728, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Lag-llama: Towards foundation models for time series forecasting,
K. Rasul, A. Ashok, A. R. Williams, A. Khorasani, G. Adamopoulos, R. Bhagwatkar, M. Biloš, H. Ghonia, N. Hassen, A. Schneider,et al., “Lag-llama: Towards foundation models for time series forecasting,” inR0-FoMo: Robustness of Few-shot and Zero-shot Learning in Large Foundation Models, 2023
2023
-
[12]
Moment: A family of open time-series foundation models,
M. Goswami, K. Szafer, A. Choudhry, Y . Cai, S. Li, and A. Dubrawski, “Moment: A family of open time-series foundation models,”arXiv preprint arXiv:2402.03885, 2024
-
[13]
A decoder-only foundation model for time-series forecasting,
A. Das, W. Kong, R. Sen, and Y . Zhou, “A decoder-only foundation model for time-series forecasting,” in Forty-first International Conference on Machine Learning, 2024
2024
-
[14]
Unified training of universal time series forecasting transformers, 2024,
G. Woo, C. Liu, A. Kumar, C. Xiong, S. Savarese, and D. Sahoo, “Unified training of universal time series forecasting transformers, 2024,”URL https://arxiv. org/abs/2402.02592, vol. 7, 2024
-
[15]
Chronos: Learning the language of time series,
A. F. Ansari, L. Stella, C. Turkmen, X. Zhang, P. Mercado, H. Shen, O. Shchur, S. S. Rangapuram, S. Pineda Arango, S. Kapoor, J. Zschiegner, D. C. Maddix, M. W. Mahoney, K. Torkkola, A. Gordon Wil- son, M. Bohlke-Schneider, and Y . Wang, “Chronos: Learning the language of time series,”Transactions on Machine Learning Research, 2024
2024
-
[16]
Chronos-2: From Univariate to Universal Forecasting
A. F. Ansari, O. Shchur, J. Küken, A. Auer, B. Han, P. Mercado, S. S. Rangapuram, H. Shen, L. Stella, X. Zhang, M. Goswami, S. Kapoor, D. C. Maddix, P. Guerron, T. Hu, J. Yin, N. Erickson, P. M. Desai, H. Wang, H. Rangwala, G. Karypis, Y . Wang, and M. Bohlke-Schneider, “Chronos-2: From univariate to universal forecasting,”arXiv preprint arXiv:2510.15821, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Forecastpfn: Synthetically-trained zero-shot forecasting,
S. Dooley, G. S. Khurana, C. Mohapatra, S. V . Naidu, and C. White, “Forecastpfn: Synthetically-trained zero-shot forecasting,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[18]
From tables to time: How tabpfn-v2 outperforms specialized time series forecasting models,
S. B. Hoo, S. Müller, D. Salinas, and F. Hutter, “From tables to time: How tabpfn-v2 outperforms specialized time series forecasting models,” 2025
2025
-
[19]
Neural architecture search: A survey,
T. Elsken, J. H. Metzen, and F. Hutter, “Neural architecture search: A survey,”Journal of Machine Learning Research, vol. 20, no. 55, pp. 1–21, 2019. 12 APREPRINT- JULY2, 2026
2019
-
[20]
Evolving neural networks through augmenting topologies,
K. O. Stanley and R. Miikkulainen, “Evolving neural networks through augmenting topologies,”Evolutionary computation, vol. 10, no. 2, pp. 99–127, 2002
2002
-
[21]
Investigating recurrent neural network memory structures using neuro- evolution,
A. Ororbia, A. ElSaid, and T. Desell, “Investigating recurrent neural network memory structures using neuro- evolution,” inProceedings of the genetic and evolutionary computation conference, pp. 446–455, 2019
2019
-
[22]
Exa-gp: Unifying graph-based genetic programming and neuroevo- lution for explainable time series forecasting,
J. Murphy, D. Kar, J. Karns, and T. Desell, “Exa-gp: Unifying graph-based genetic programming and neuroevo- lution for explainable time series forecasting,” inProceedings of the Genetic and Evolutionary Computation Conference Companion, pp. 523–526, 2024
2024
-
[23]
Ant-based neural topology search (ants) for optimizing recurrent networks,
A. ElSaid, A. G. Ororbia, and T. J. Desell, “Ant-based neural topology search (ants) for optimizing recurrent networks,” inInternational Conference on the Applications of Evolutionary Computation (Part of EvoStar), pp. 626–641, Springer, 2020
2020
-
[24]
Continuous ant-based neural topology search,
A. ElSaid, J. Karns, Z. Lyu, A. G. Ororbia, and T. Desell, “Continuous ant-based neural topology search,” in International Conference on the Applications of Evolutionary Computation (Part of EvoStar), pp. 291–306, Springer, 2021
2021
-
[25]
Cg-cants-n: A versatile graph-based framework for scalable and adaptive problem solving across domains,
A. ElSaid and T. Desell, “Cg-cants-n: A versatile graph-based framework for scalable and adaptive problem solving across domains,” inProceedings of the Genetic and Evolutionary Computation Conference Companion, pp. 263–266, 2025
2025
-
[26]
Nsga-net: neural architecture search using multi-objective genetic algorithm,
Z. Lu, I. Whalen, V . Boddeti, Y . Dhebar, K. Deb, E. Goodman, and W. Banzhaf, “Nsga-net: neural architecture search using multi-objective genetic algorithm,” inProceedings of the genetic and evolutionary computation conference, pp. 419–427, 2019
2019
-
[27]
Regularized evolution for image classifier architecture search,
E. Real, A. Aggarwal, Y . Huang, and Q. V . Le, “Regularized evolution for image classifier architecture search,” in Proceedings of the aaai conference on artificial intelligence, vol. 33, pp. 4780–4789, 2019
2019
-
[28]
Efficient neural architecture search via parameters sharing,
H. Pham, M. Guan, B. Zoph, Q. Le, and J. Dean, “Efficient neural architecture search via parameters sharing,” in International conference on machine learning, pp. 4095–4104, PMLR, 2018
2018
-
[29]
DARTS: Differentiable Architecture Search
H. Liu, K. Simonyan, and Y . Yang, “Darts: Differentiable architecture search,”arXiv preprint arXiv:1806.09055, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
The evolved transformer,
D. So, Q. Le, and C. Liang, “The evolved transformer,” inInternational conference on machine learning, pp. 5877–5886, PMLR, 2019
2019
-
[31]
Searching the search space of vision transformer,
M. Chen, K. Wu, B. Ni, H. Peng, B. Liu, J. Fu, H. Chao, and H. Ling, “Searching the search space of vision transformer,”Advances in Neural Information Processing Systems, vol. 34, pp. 8714–8726, 2021
2021
-
[32]
Nasvit: Neural architecture search for efficient vision transformers with gradient conflict-aware supernet training,
C. Gong and D. Wang, “Nasvit: Neural architecture search for efficient vision transformers with gradient conflict-aware supernet training,”ICLR Proceedings 2022, 2022
2022
-
[33]
M. D. V ose,The Simple Genetic Algorithm: Foundations and Theory. The MIT Press, 08 1999
1999
-
[34]
Designing neural networks through neuroevolution,
K. O. Stanley, J. Clune, J. Lehman, and R. Miikkulainen, “Designing neural networks through neuroevolution,” Nature Machine Intelligence, vol. 1, no. 1, pp. 24–35, 2019. 13
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.