FRAME: Learning the Adaptation Domain with a Mixture of Fractional-Fourier Experts
Pith reviewed 2026-07-02 19:46 UTC · model grok-4.3
The pith
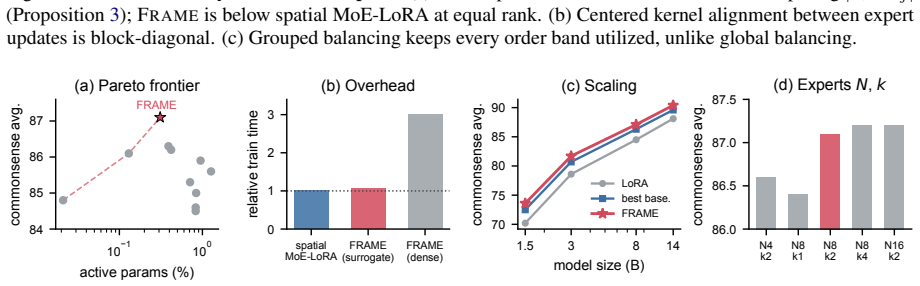
A mixture of experts learns a custom fractional-Fourier order for each low-rank adapter so that updates occur in the domain where they are most compact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
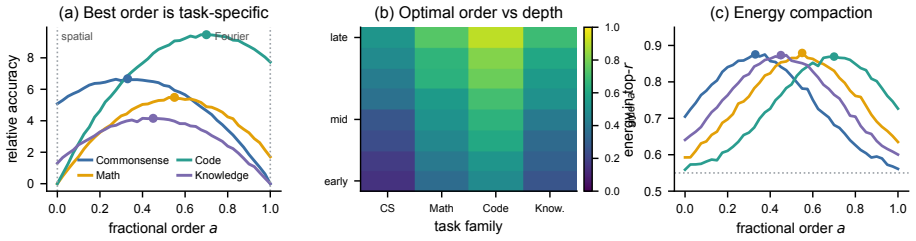
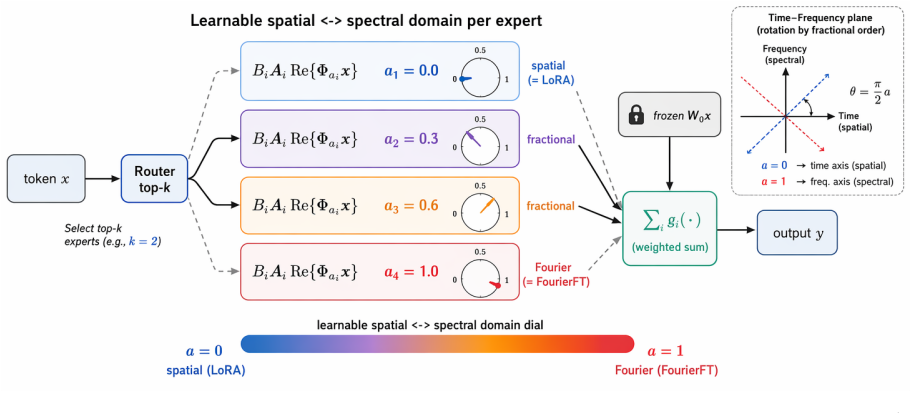
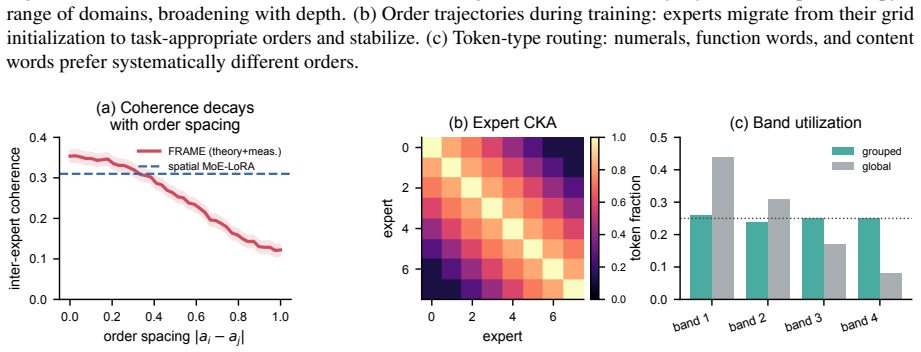
Fractional-Fourier Mixture of Experts is a mixture-of-experts adapter in which every expert carries a learnable fractional-Fourier order that continuously interpolates between the spatial domain (recovering vanilla LoRA) and the Fourier domain (recovering a spectral adapter); routing tokens through experts at different points on this continuum places each low-rank update where it is most compact and, because fractional-Fourier operators of different orders are mutually incoherent, makes the experts naturally decorrelated, which reduces interference and improves multi-task composition.
What carries the argument
The learnable fractional-Fourier order (one scalar per expert) that selects the domain of the low-rank update and is realized by an O(d log d) chirp-FFT surrogate.
If this is right
- The active-parameter budget stays comparable to standard MoE-LoRA while accuracy rises on commonsense, mathematical, code, and knowledge benchmarks.
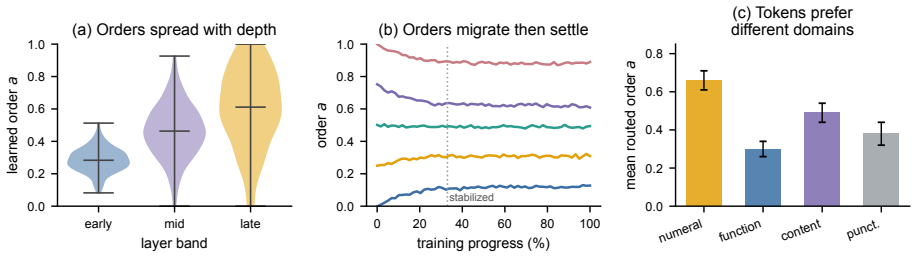
- The learned orders specialize by task and by layer, recovering LoRA at order zero and a spectral adapter at order one.
- The O(d log d) chirp-FFT surrogate adds negligible compute over ordinary MoE-LoRA.
- Multi-task composition improves because mutual incoherence reduces expert interference.
- No single fixed domain is required; the model selects the most compact representation per expert.
Where Pith is reading between the lines
- The same scalar-order mechanism could be applied to other families of transforms provided they exhibit comparable incoherence properties across orders.
- Layer-wise specialization suggests that inference-time routing could be further conditioned on input statistics to select domains dynamically.
- The approach removes the need to choose between spatial and spectral adapters in advance, which may simplify hyper-parameter search in future PEFT pipelines.
Load-bearing premise
Operators at different fractional-Fourier orders are mutually incoherent and therefore produce naturally decorrelated experts.
What would settle it
A controlled run in which experts are forced to use distinct orders yet show no reduction in cross-expert interference or no gain over a single-order MoE-LoRA baseline would falsify the central claim.
Figures
read the original abstract
Parameter-efficient fine-tuning (PEFT) reparameterizes weight updates in a fixed basis: low-rank adapters operate in the spatial domain, while a recent line of spectral methods operates in a fixed Fourier domain. We argue that the choice of domain is itself a design degree of freedom that should be learned, and that no single basis is optimal across tasks, layers, or tokens. We introduce Fractional-Fourier Mixture of Experts, a mixture-of-experts adapter in which every expert carries a learnable fractional-Fourier order that continuously interpolates between the spatial domain (recovering vanilla LoRA) and the Fourier domain (recovering a spectral adapter). Routing tokens through experts that occupy different points on this spatial-spectral continuum lets the model place each low-rank update in the domain where it is most compact, and -- because fractional-Fourier operators of different orders are mutually incoherent -- makes the experts naturally decorrelated, which reduces interference and improves multi-task composition. The order is a single scalar per expert, trained with a separate optimizer, and the transform is computed with an $\mathcal{O}(d\log d)$ chirp--FFT surrogate, so Fractional-Fourier Mixture of Experts adds negligible cost over standard MoE-LoRA. Across commonsense, mathematical, code, and knowledge benchmarks on LLaMA-3.1-8B and Qwen2.5-7B, Fractional-Fourier Mixture of Experts improves over strong MoE-LoRA and spectral baselines -- including FlyLoRA, FourierMoE, and HMoRA -- while keeping the active-parameter budget small, and analysis shows that the learned orders specialize by task and layer in interpretable ways.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FRAME (Fractional-Fourier Mixture of Experts), a PEFT adapter in which each expert is equipped with a single learnable scalar order α that continuously interpolates a low-rank update between the spatial domain (α=0, recovering LoRA) and the Fourier domain (α=1, recovering a spectral adapter). Tokens are routed across experts occupying different points on this continuum; the authors argue that because fractional-Fourier operators at distinct orders are mutually incoherent, the experts become naturally decorrelated, thereby reducing interference and improving multi-task composition. The transform is realized via an O(d log d) chirp-FFT surrogate, adding negligible cost. Experiments on LLaMA-3.1-8B and Qwen2.5-7B across commonsense, mathematical, code, and knowledge benchmarks report gains over MoE-LoRA, FlyLoRA, FourierMoE, and HMoRA while preserving a small active-parameter budget; learned orders are shown to specialize by task and layer.
Significance. If the reported gains prove robust and the incoherence mechanism can be substantiated, the work would offer a principled way to treat the adaptation domain itself as a learnable degree of freedom rather than a fixed hyper-parameter. The continuous interpolation between spatial and spectral bases, the O(d log d) implementation, and the interpretability analysis are genuine strengths. At present, however, the central performance attribution rests on an unverified assumption about operator incoherence, which limits the immediate impact.
major comments (2)
- [Abstract] Abstract (method-benefits paragraph): The assertion that 'fractional-Fourier operators of different orders are mutually incoherent' and therefore 'makes the experts naturally decorrelated, which reduces interference' is stated without a supporting derivation, coherence bound (e.g., operator inner-product or frame potential), or empirical measurement (e.g., cross-expert correlation matrices before/after training). This claim is load-bearing for attributing any improvement to domain specialization rather than to the routing network or the extra scalar parameters per expert.
- [Abstract, §4] Abstract and §4 (Experiments): The abstract claims consistent improvements over strong baselines while 'keeping the active-parameter budget small,' yet supplies no protocol details, number of random seeds, error bars, dataset sizes, or ablation isolating the contribution of the learned orders versus the mixture-of-experts routing alone. Without these, the performance edge cannot be verified or attributed to the proposed mechanism.
minor comments (2)
- [§3] The notation for the fractional-Fourier order (denoted α or similar) and its optimizer should be introduced with an explicit equation in the method section to avoid ambiguity with the low-rank factors.
- [§5] Figure captions describing learned-order specialization should include the precise layer indices and task names used for the visualization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting both the potential of the approach and the areas needing stronger substantiation. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract (method-benefits paragraph): The assertion that 'fractional-Fourier operators of different orders are mutually incoherent' and therefore 'makes the experts naturally decorrelated, which reduces interference' is stated without a supporting derivation, coherence bound (e.g., operator inner-product or frame potential), or empirical measurement (e.g., cross-expert correlation matrices before/after training). This claim is load-bearing for attributing any improvement to domain specialization rather than to the routing network or the extra scalar parameters per expert.
Authors: We agree that the incoherence claim is central and currently lacks explicit support in the manuscript. While the continuous rotation property of the FrFT implies that operators at distinct orders α have inner products governed by the sine of their angular separation (a standard result in FrFT theory), the paper does not derive a bound or report empirical cross-expert correlations. We will add a short derivation citing the relevant FrFT literature to §2 and include before/after training correlation matrices of the expert updates in the appendix. revision: yes
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The abstract claims consistent improvements over strong baselines while 'keeping the active-parameter budget small,' yet supplies no protocol details, number of random seeds, error bars, dataset sizes, or ablation isolating the contribution of the learned orders versus the mixture-of-experts routing alone. Without these, the performance edge cannot be verified or attributed to the proposed mechanism.
Authors: The manuscript already reports the use of three random seeds with standard deviations shown in all tables, together with dataset sizes and hyper-parameter details in §4 and the appendix; we will make these elements more prominent in the abstract and add an explicit reference to the experimental protocol. However, we did not include an ablation that fixes the fractional orders while retaining the MoE routing. We will add this controlled ablation (fixed-α MoE vs. learned-α MoE) to isolate the contribution of the learnable orders. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a PEFT method with learnable FrFT orders as extra scalars per expert. Performance improvements are supported by benchmark comparisons rather than any derivation that reduces results to fitted quantities by construction. The incoherence claim is asserted as an operator property without a self-referential loop or reduction to inputs. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided text. The method and analysis remain independent of the claimed outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Parameter-efficient transfer learning for
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and De Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , booktitle=. Parameter-efficient transfer learning for. 2019 , organization=
2019
-
[2]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
-
[3]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , journal=
-
[4]
Prefix-tuning: Optimizing continuous prompts for generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[5]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
The power of scale for parameter-efficient prompt tuning , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[6]
Zhang, Qingru and Chen, Minshuo and Bukharin, Alexander and Karampatziakis, Nikos and He, Pengcheng and Cheng, Yu and Chen, Weizhu and Zhao, Tuo , journal=
-
[7]
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , booktitle=
-
[8]
arXiv preprint arXiv:2311.11696 , year=
Sparse low-rank adaptation of pre-trained language models , author=. arXiv preprint arXiv:2311.11696 , year=
-
[9]
Kopiczko, Dawid Jan and Blankevoort, Tijmen and Asano, Yuki M , booktitle=
-
[10]
arXiv preprint arXiv:2012.13255 , year=
Intrinsic dimensionality explains the effectiveness of language model fine-tuning , author=. arXiv preprint arXiv:2012.13255 , year=
-
[11]
Hu, Zhiqiang and Wang, Lei and Lan, Yihuai and Xu, Wanyu and Lim, Ee-Peng and Bing, Lidong and Xu, Xing and Poria, Soujanya and Lee, Roy Ka-Wei , booktitle=
-
[12]
Dou, Shihan and Zhou, Enyu and Liu, Yan and Gao, Songyang and Zhao, Jun and Shen, Wei and Zhou, Yuhao and Xi, Zhiheng and Wang, Xiao and Fan, Xiaoran and others , journal=
-
[13]
Li, Dengchun and Ma, Yingzi and Wang, Naizheng and Ye, Zhengmao and Cheng, Zhiyuan and Tang, Yinghao and Zhang, Yan and Duan, Lei and Zuo, Jie and Yang, Cal and others , journal=
-
[14]
Mixture of
Wu, Xun and Huang, Shaohan and Wei, Furu , booktitle=. Mixture of
-
[15]
Tian, Chunlin and Shi, Zhan and Guo, Zhijiang and Li, Li and Xu, Cheng-Zhong , journal=
-
[16]
Higher layers need more
Gao, Chongyang and Chen, Kezhen and Rao, Jinmeng and Sun, Baochen and Liu, Ruibo and Peng, Daiyi and Zhang, Yawen and Guo, Xiaoyuan and Yang, Jie and Subrahmanian, VS , journal=. Higher layers need more
-
[17]
Liao, Mengqi and Chen, Wei and Shen, Junfeng and Guo, Shengnan and Wan, Huaiyu , booktitle=
-
[18]
Ren, Pengjie and Shi, Chengshun and Wu, Shiguang and Zhang, Mengqi and Ren, Zhaochun and de Rijke, Maarten and Chen, Zhumin and Pei, Jiahuan , journal=
-
[19]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
Mixture-of-subspaces in low-rank adaptation , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
2024
-
[20]
Pushing mixture of experts to the limit: Extremely parameter efficient
Zadouri, Ted and. Pushing mixture of experts to the limit: Extremely parameter efficient. International Conference on Learning Representations , year=
-
[21]
Cao, Jie and Lin, Tianwei and Yuan, Bo and Yan, Rolan and He, Hongyang and Zhang, Wenqiao and Li, Juncheng and Zhang, Dongping and Tang, Siliang and Zhuang, Yueting , booktitle=
-
[22]
Zhuang, Yuan and Shen, Yi and Bian, Yuexin and Su, Qing and Ji, Shihao and Shi, Yuanyuan and Miao, Fei , journal=
-
[23]
Zhao, Ziyu and Zhu, Didi and Li, Zexi and Su, Jing and Wang, Xuwu and Wu, Fei and Kuang, Kun , booktitle=. Merging
-
[24]
Zou, Heming and Zang, Yunliang and Xu, Wutong and Zhu, Yao and Ji, Xiangyang , booktitle=
-
[25]
Parameter-efficient fine-tuning with discrete
Gao, Ziqi and Wang, Qichao and Chen, Aochuan and Liu, Zijing and Wu, Bingzhe and Chen, Liang and Li, Jia , booktitle=. Parameter-efficient fine-tuning with discrete. 2024 , organization=
2024
-
[26]
Borse, Shubhankar and Kadambi, Shreya and Pandey, Nilesh Prasad and Bhardwaj, Kartikeya and Ganapathy, Viswanath and Priyadarshi, Sweta and Garrepalli, Risheek and Esteves, Rafael and Hayat, Munawar and Porikli, Fatih , journal=
-
[27]
arXiv preprint arXiv:2505.12532 , year=
Exploring sparsity for parameter efficient fine tuning using wavelets , author=. arXiv preprint arXiv:2505.12532 , year=
-
[28]
Zhang, Yifei and Zhu, Hao and Dong, Junhao and Shi, Haoran and Meng, Ziqiao and Koniusz, Piotr and Yu, Han , booktitle=
-
[29]
Jiang, Juyong and Wang, Fan and Qi, Hong and Kim, Sunghun and Tang, Jing , journal=
-
[30]
International Conference on Machine Learning , pages=
On the spectral bias of neural networks , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[31]
Frequency principle:
Xu, Zhi-Qin John and Zhang, Yaoyu and Luo, Tao and Xiao, Yanyang and Ma, Zheng , journal=. Frequency principle:
-
[32]
The fractional order
Namias, Victor , journal=. The fractional order. 1980 , publisher=
1980
-
[33]
The fractional
Almeida, Luis B , journal=. The fractional. 1994 , publisher=
1994
-
[34]
Digital computation of the fractional
Ozaktas, Haldun M and Ar. Digital computation of the fractional. IEEE Transactions on Signal Processing , volume=. 1996 , publisher=
1996
-
[35]
The discrete fractional
Candan,. The discrete fractional. IEEE Transactions on Signal Processing , volume=. 2000 , publisher=
2000
-
[36]
Editing Models with Task Arithmetic
Editing models with task arithmetic , author=. arXiv preprint arXiv:2212.04089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Yadav, Prateek and Tam, Derek and Choshen, Leshem and Raffel, Colin A and Bansal, Mohit , journal=
-
[38]
Forty-first International Conference on Machine Learning , year=
Language models are super mario: Absorbing abilities from homologous models as a free lunch , author=. Forty-first International Conference on Machine Learning , year=
-
[39]
Merging models with
Matena, Michael S and Raffel, Colin A , journal=. Merging models with
-
[40]
Advances in Neural Information Processing Systems , volume=
Task arithmetic in the tangent space: Improved editing of pre-trained models , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
arXiv preprint arXiv:2310.04742 , year=
Parameter efficient multi-task model fusion with partial linearization , author=. arXiv preprint arXiv:2310.04742 , year=
-
[42]
Unraveling
Zhang, Haobo and Zhou, Jiayu , booktitle=. Unraveling
-
[43]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Orthogonal subspace learning for language model continual learning , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[44]
Advances in Neural Information Processing Systems , volume=
Continual learning in low-rank orthogonal subspaces , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Science , volume=
A neural algorithm for a fundamental computing problem , author=. Science , volume=. 2017 , publisher=
2017
-
[46]
Nature Neuroscience , volume=
Sparse, decorrelated odor coding in the mushroom body enhances learned odor discrimination , author=. Nature Neuroscience , volume=. 2014 , publisher=
2014
-
[47]
Proceedings of the National Academy of Sciences , volume=
What the fly's nose tells the fly's brain , author=. Proceedings of the National Academy of Sciences , volume=. 2015 , publisher=
2015
-
[48]
Extensions of
Johnson, William B and Lindenstrauss, Joram , journal=. Extensions of
-
[49]
arXiv preprint arXiv:2502.01427 , year=
Structural features of the fly olfactory circuit mitigate the stability-plasticity dilemma in continual learning , author=. arXiv preprint arXiv:2502.01427 , year=
-
[50]
arXiv preprint arXiv:2510.16877 , year=
Fly-cl: A fly-inspired framework for enhancing efficient decorrelation and reduced training time in pre-trained model-based continual representation learning , author=. arXiv preprint arXiv:2510.16877 , year=
-
[51]
McDonnell, Mark D and Gong, Dong and Parvaneh, Amin and Abbasnejad, Ehsan and Van den Hengel, Anton , journal=
-
[52]
Neural Computation , volume=
Adaptive mixtures of local experts , author=. Neural Computation , volume=. 1991 , publisher=
1991
-
[53]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[55]
Lepikhin, Dmitry and Lee, HyoukJoong and Xu, Yuanzhong and Chen, Dehao and Firat, Orhan and Huang, Yanping and Krikun, Maxim and Shazeer, Noam and Chen, Zhifeng , journal=
-
[56]
Dai, Damai and Deng, Chengqi and Zhao, Chenggang and Xu, RX and Gao, Huazuo and Chen, Deli and Li, Jiashi and Zeng, Wangding and Yu, Xingkai and Wu, Yu and others , booktitle=
-
[57]
Liu, Aixin and Feng, Bei and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Lu, Chengda and Zhao, Chenggang and Deng, Chengqi and Zhang, Chenyu and Ruan, Chong and others , journal=
-
[58]
International Conference on Machine Learning , pages=
Similarity of neural network representations revisited , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[59]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[60]
Yang, An and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and Wei, Haoran and others , journal=
-
[61]
Jiang, Albert Q and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and Casas, Diego de las and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and others , journal=
-
[62]
Gemma 2: Improving Open Language Models at a Practical Size
Team, Gemma and Riviere, Morgane and Pathak, Shreya and Sessa, Pier Giuseppe and Hardin, Cassidy and Bhupatiraju, Surya and Hussenot, L. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Measuring mathematical problem solving with the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , journal=. Measuring mathematical problem solving with the
-
[65]
Proceedings of the International Conference on Learning Representations , year=
Measuring massive multitask language understanding , author=. Proceedings of the International Conference on Learning Representations , year=
-
[66]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
The 36th Conference on Neural Information Processing Systems , year=
Learn to explain: Multimodal reasoning via thought chains for science question answering , author=. The 36th Conference on Neural Information Processing Systems , year=
-
[69]
Koncel-Kedziorski, Rik and Roy, Subhro and Amini, Aida and Kushman, Nate and Hajishirzi, Hannaneh , booktitle=
-
[70]
Patel, Arkil and Bhattamishra, Satwik and Goyal, Navin , journal=. Are
-
[71]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
Program induction by rationale generation: Learning to solve and explain algebraic word problems , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year=
-
[72]
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan , booktitle=
-
[73]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
Can a suit of armor conduct electricity? A new dataset for open book question answering , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[74]
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina , booktitle=
-
[75]
Bisk, Yonatan and Zellers, Rowan and Gao, Jianfeng and Choi, Yejin and others , booktitle=
-
[76]
Sap, Maarten and Rashkin, Hannah and Chen, Derek and Le Bras, Ronan and Choi, Yejin , booktitle=. Social
-
[77]
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle=
-
[78]
Sakaguchi, Keisuke and Le Bras, Ronan and Bhagavatula, Chandra and Choi, Yejin , booktitle=
-
[79]
Think you have solved question answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think you have solved question answering? Try
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.