ALEE: Any-Language Evaluation of Embeddings via English-Centric Minimal Pairs
Pith reviewed 2026-07-02 19:08 UTC · model grok-4.3
The pith
ALEE generates English AMR minimal pairs and their translations to diagnose embedding performance across 275+ languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
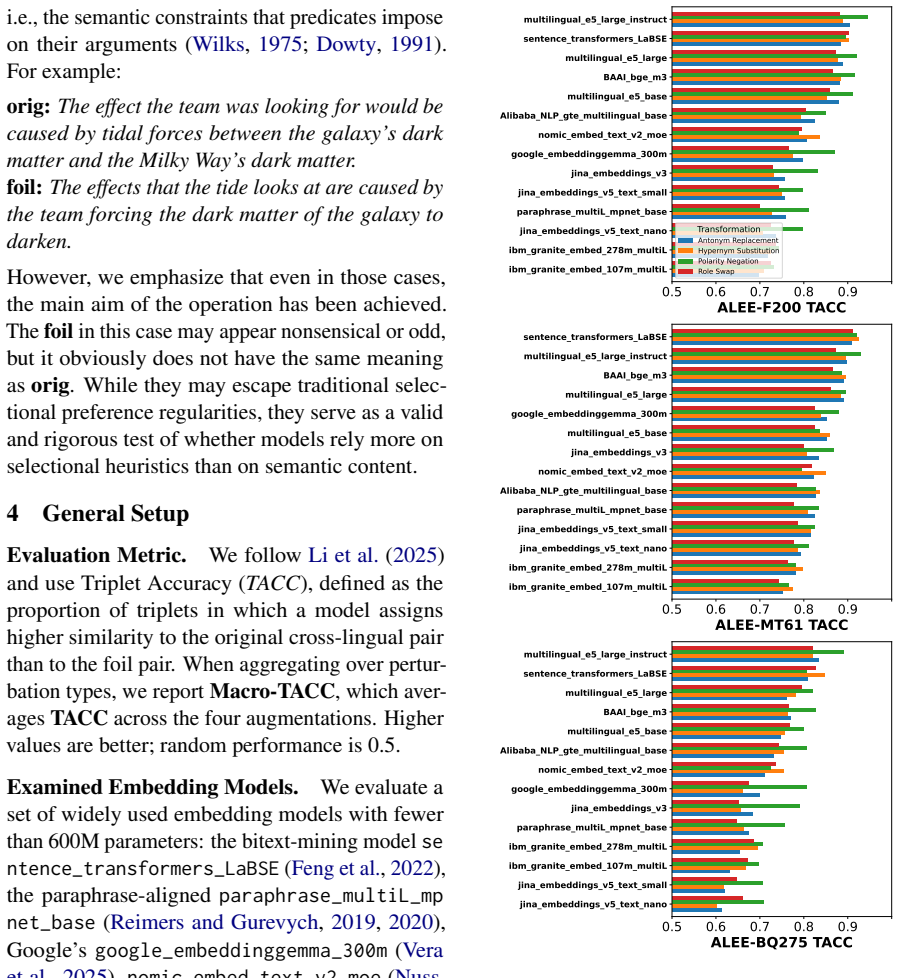
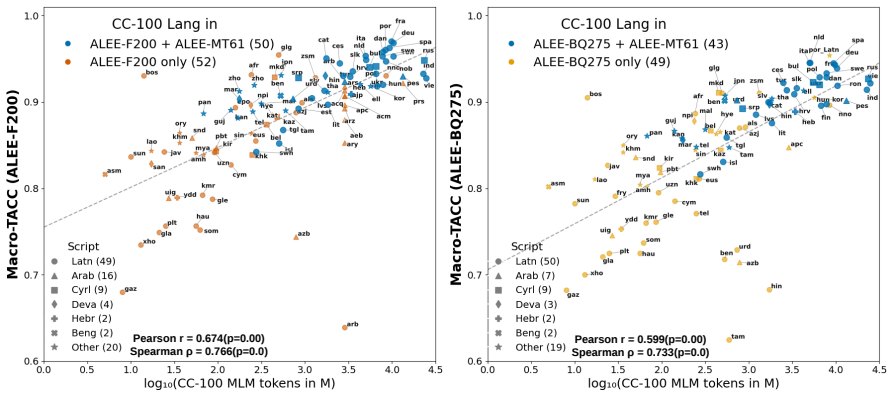
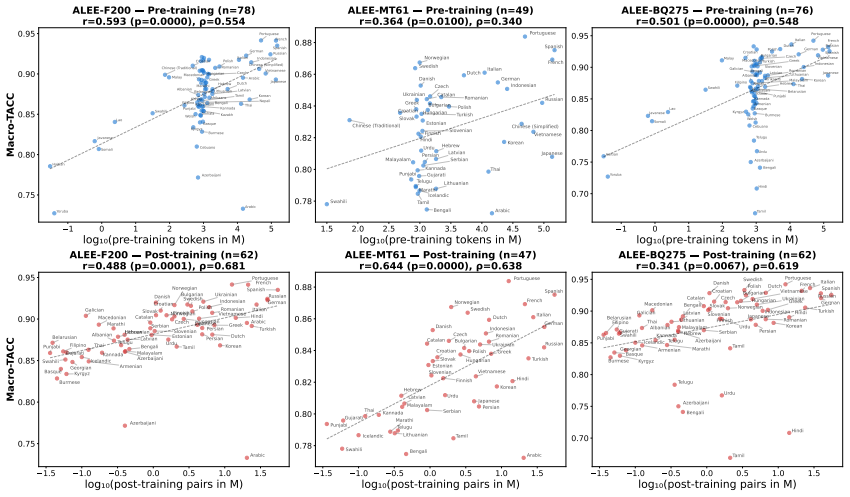
ALEE extends prior minimal-pair methods to the cross-lingual and paragraph setting by using AMR to create English pairs that isolate specific semantic distinctions and then translating those pairs. When applied to many embedding models across three parallel datasets covering more than 275 languages, the resulting scores expose consistent performance gaps that track language prevalence in training resources and subword tokenization practices, indicating that current embeddings still lack uniform cross-lingual semantic fidelity.
What carries the argument
AMR-generated English minimal pairs with controlled fine-grained semantic shifts, paired with translations into target languages for cross-lingual comparison.
If this is right
- Targeted diagnostics become feasible for embedding models in any language supplied with English parallel data.
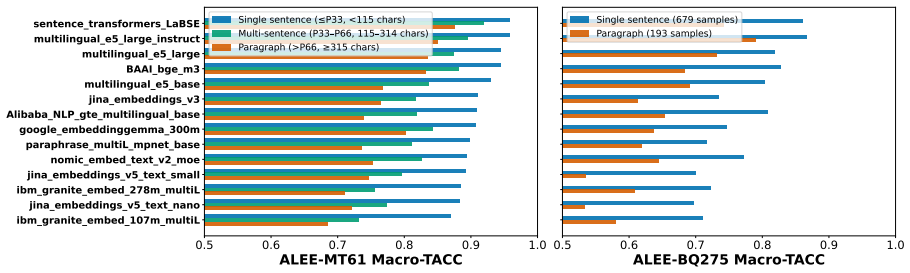
- Scores vary substantially by language, by text length, and by linguistic phenomenon.
- Gaps in cross-lingual semantic representation track language prevalence in training resources and subword tokenization.
- The same framework supports evaluation at both sentence and paragraph levels across three large parallel datasets.
Where Pith is reading between the lines
- The observed correlations suggest that increasing training data volume for low-prevalence languages would narrow the measured gaps.
- The method could be used to compare tokenization schemes by holding the underlying model fixed and varying only the vocabulary.
- Extending ALEE to measure how well models handle phenomena that are rare in English but common in the target language would test an implicit boundary of the English-centric design.
Load-bearing premise
Translations of the AMR-generated English minimal pairs faithfully preserve the controlled fine-grained semantic shifts without introducing artifacts or losing the intended meaning distinctions in the target languages.
What would settle it
A direct comparison in which human raters judge semantic similarity on the translated pairs and those human ratings fail to align with the ordering produced by embedding cosine scores would show that the controlled distinctions are not preserved.
Figures



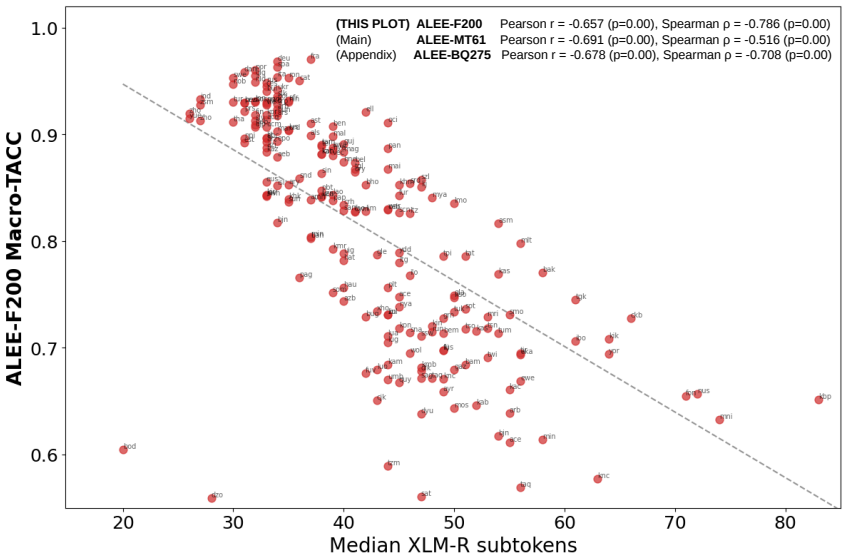
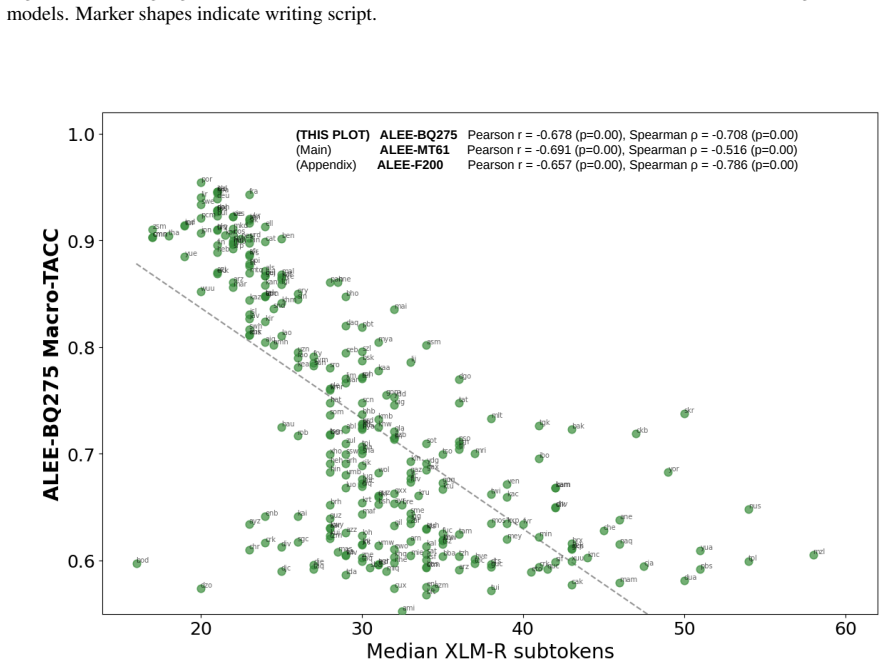
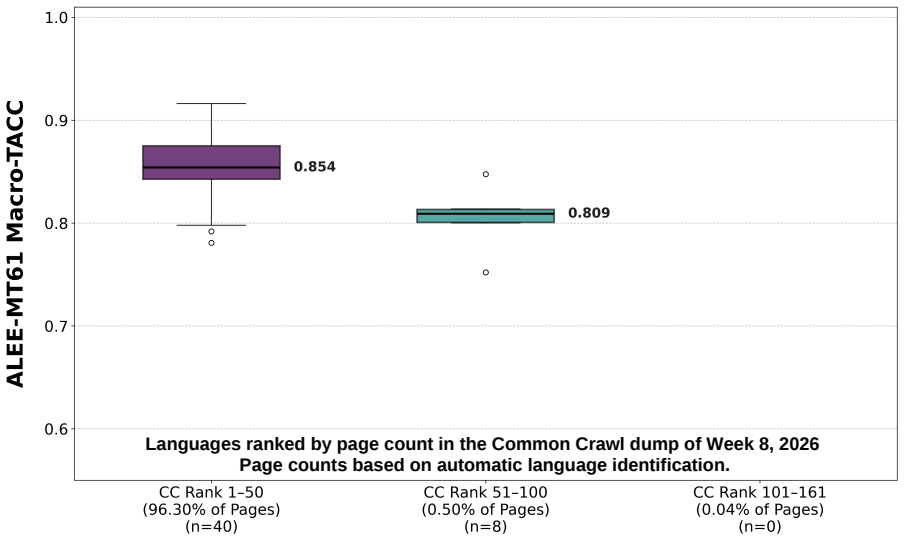
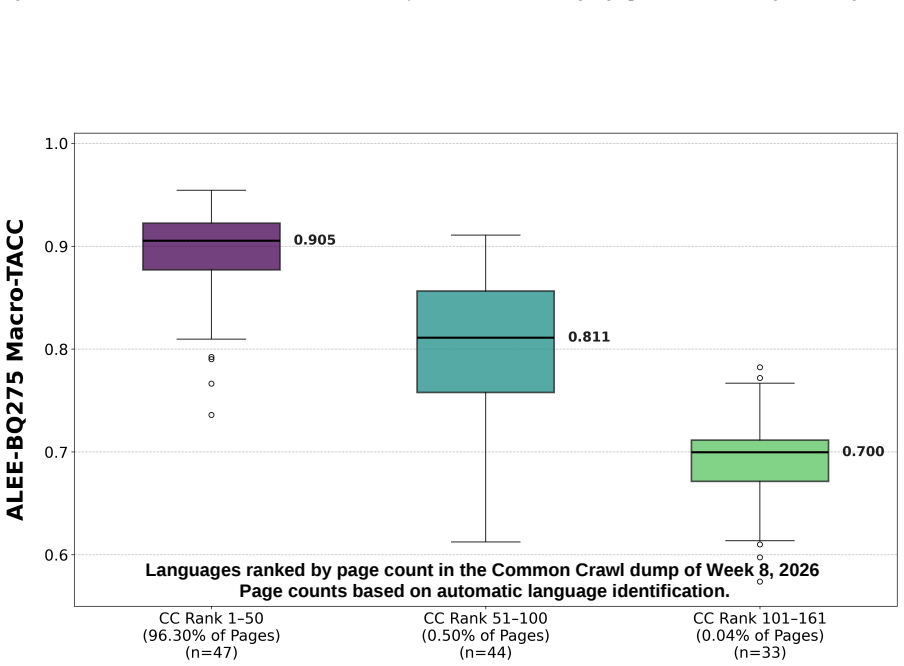
read the original abstract
Text embeddings are standard for semantic similarity tasks, yet their evaluation remains an open challenge. Current benchmarks are static, cover only a limited set of languages, are often domain-specific, susceptible to overfitting, and poorly representative of low-resource languages. To address these limitations, we introduce ALEE, a framework that extends Sentence Smith (Li et al., 2025) to the cross-lingual and paragraph level. ALEE uses Abstract Meaning Representations (AMR) to generate English minimal pairs with controlled, fine-grained semantic shifts, which are paired with translations in target languages. This approach enables targeted diagnostics for models in any language with English parallel data. We conduct a large-scale empirical study across a diverse set of embedding models and 275+ languages spanning three parallel datasets. On ALEE, performance varies substantially across languages, text lengths, and linguistic phenomena, exposing persistent gaps in cross-lingual semantic representation that track language prevalence in training resources and subword tokenization. We release ALEE at https://github.com/Andrian0s/any-lang-embed-eval
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ALEE, a framework extending Sentence Smith to cross-lingual and paragraph-level evaluation. It generates controlled English minimal pairs via AMR, translates them to target languages, and uses the resulting pairs to diagnose embedding models across 275+ languages and three parallel datasets. The central empirical claim is that performance varies substantially by language, text length, and linguistic phenomenon, with gaps tracking training-data prevalence and subword tokenization.
Significance. If the translations faithfully preserve the intended fine-grained semantic contrasts, ALEE would supply a scalable, language-agnostic diagnostic that addresses the static, limited-coverage, and overfitting problems of existing embedding benchmarks while reaching low-resource languages.
major comments (2)
- [Abstract] Abstract: the claim that ALEE 'exposes persistent gaps in cross-lingual semantic representation' rests on the unverified assumption that translations of the AMR minimal pairs preserve the controlled semantic shifts without introducing artifacts or losing distinctions. No translation-quality controls, back-translation checks, or human fidelity ratings are described, which directly threatens the targeted-diagnostic interpretation, especially for low-resource languages where MT quality is lower.
- [Abstract] Abstract: the reported empirical variation across languages, lengths, and phenomena is presented without any mention of statistical significance testing, data-exclusion criteria, or sensitivity to implementation choices in the translation pipeline, leaving the load-bearing cross-lingual claims difficult to evaluate for robustness.
minor comments (1)
- [Abstract] The citation 'Sentence Smith (Li et al., 2025)' appears in the abstract; the reference list should confirm whether this is a published or forthcoming work and provide full bibliographic details.
Simulated Author's Rebuttal
We thank the referee for highlighting these important methodological concerns. We agree that explicit translation fidelity verification and statistical robustness checks would strengthen the paper's claims. Below we respond point-by-point and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that ALEE 'exposes persistent gaps in cross-lingual semantic representation' rests on the unverified assumption that translations of the AMR minimal pairs preserve the controlled semantic shifts without introducing artifacts or losing distinctions. No translation-quality controls, back-translation checks, or human fidelity ratings are described, which directly threatens the targeted-diagnostic interpretation, especially for low-resource languages where MT quality is lower.
Authors: We acknowledge that the current manuscript does not include dedicated translation-quality controls or fidelity ratings for the minimal-pair contrasts. The translations are taken directly from three established parallel corpora rather than generated via MT for the study; however, we did not verify that the fine-grained semantic distinctions survive translation. We will add a new subsection on translation fidelity that reports (1) back-translation consistency on a stratified sample of pairs, (2) automatic semantic similarity scores between English and translated pairs, and (3) a discussion of known limitations for languages with lower-quality parallel data. This will be accompanied by a clearer statement of the assumption and its scope. revision: yes
-
Referee: [Abstract] Abstract: the reported empirical variation across languages, lengths, and phenomena is presented without any mention of statistical significance testing, data-exclusion criteria, or sensitivity to implementation choices in the translation pipeline, leaving the load-bearing cross-lingual claims difficult to evaluate for robustness.
Authors: We agree that the absence of statistical testing and explicit robustness checks weakens the presentation. In the revision we will (a) report statistical significance (paired t-tests or Wilcoxon tests with multiple-comparison correction) for the main cross-lingual, length, and phenomenon contrasts, (b) state data-exclusion criteria (minimum number of valid pairs per language, removal of languages with <50 pairs), and (c) add a sensitivity analysis that re-runs key results after excluding the lowest-quality parallel dataset. Because the translation step is fixed by the choice of parallel corpora, the sensitivity analysis will focus on dataset choice rather than an arbitrary MT pipeline. revision: yes
Circularity Check
No significant circularity: ALEE is an independent evaluation framework
full rationale
The paper introduces ALEE as a new evaluation framework that extends Sentence Smith (Li et al., 2025) by generating AMR-based English minimal pairs and pairing them with translations. No equations, fitted parameters, or predictions that reduce to inputs by construction are described. The central claims rest on empirical results across 275+ languages rather than any self-definitional, fitted-input, or self-citation load-bearing step. The cited prior work is independent and is being extended, not invoked as a uniqueness theorem or ansatz that forces the result. This is a standard case of an evaluation tool whose validity depends on external assumptions (e.g., translation fidelity) but whose derivation chain does not collapse into its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption AMR representations can be used to generate English minimal pairs with fine-grained, controlled semantic shifts
- domain assumption Translations into target languages preserve the semantic distinctions introduced in the English AMR pairs
Reference graph
Works this paper leans on
-
[1]
How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , month=. 2021 , address=. doi:10.18653/v1/2021.acl-long.243 , pages=
-
[2]
language , volume=
Thematic proto-roles and argument selection , author=. language , volume=. 1991 , url=
1991
-
[3]
Similar, but why? A Toolkit for Explaining Text Similarity
Opitz, Juri and Michail, Andrianos and Moeller, Lucas and Pad \'o , Sebastian and Clematide, Simon. Similar, but why? A Toolkit for Explaining Text Similarity. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 3: System Demonstrations). 2026. doi:10.18653/v1/2026.eacl-demo.16
-
[4]
Transactions of the Association for Computational Linguistics , volume=
Jumelet, Jaap and Weissweiler, Leonie and Nivre, Joakim and Bisazza, Arianna , title=. Transactions of the Association for Computational Linguistics , volume=. 2026 , month=. doi:10.1162/TACL.a.600 , url=
-
[5]
A Survey of the State of Explainable
Danilevsky, Marina and Qian, Kun and Aharonov, Ranit and Katsis, Yannis and Kawas, Ban and Sen, Prithviraj , editor=. A Survey of the State of Explainable. Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing , month=. 2020 ...
-
[6]
Zhu, Xunjie and de Melo, Gerard , editor=. Sentence Analogies:. Proceedings of the 28th International Conference on Computational Linguistics , month=. 2020 , address=. doi:10.18653/v1/2020.coling-main.300 , pages=
-
[7]
Exploring Semantic Properties of Sentence Embeddings , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , month=. 2018 , address=. doi:10.18653/v1/P18-2100 , pages=
-
[8]
2018 , language=
Manual of Romance Sociolinguistics , author=. 2018 , language=
2018
-
[9]
2004 , language=
Romansh: Facts & figures , author=. 2004 , language=
2004
-
[10]
Richtlinien für die Gestaltung einer gesamtbündnerromanischen Schriftsprache :
Schmid, Heinrich , address=. Richtlinien für die Gestaltung einer gesamtbündnerromanischen Schriftsprache :. Richtlinien für die Gestaltung einer gesamtbündnerromanischen Schriftsprache Rumantsch grischun , edition=. 1982 , isbn=
1982
-
[11]
2010 , language=
Atlas of the world's languages in danger , author=. 2010 , language=
2010
-
[12]
Wilks, Yorick , title=. 1975 , issue_date=. doi:10.1145/360762.360770 , journal=
-
[13]
and Ullman, Jeffrey D
Aho, Alfred V. and Ullman, Jeffrey D. , title=. 1972 , isbn=
1972
-
[14]
Interpretable Text Embeddings and Text Similarity Explanation:
Opitz, Juri and Moeller, Lucas and Michail, Andrianos and Pad. Interpretable Text Embeddings and Text Similarity Explanation:. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month=. 2025 , address=. doi:10.18653/v1/2025.emnlp-main.1135 , pages=
-
[15]
Chandra and Dexter C
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year=. Alternation , journal=
-
[16]
Andrew, Galen and Gao, Jianfeng , title=. 2007 , isbn=. doi:10.1145/1273496.1273501 , booktitle=
-
[17]
1997 , publisher=
Dan Gusfield , title=. 1997 , publisher=
1997
-
[18]
Tetreault , title=
Mohammad Sadegh Rasooli and Joel R. Tetreault , title=. Computing Research Repository , volume=. 2015 , url=
2015
-
[19]
Journal of Machine Learning Research , year=
Rie Kubota Ando and Tong Zhang , title=. Journal of Machine Learning Research , year=
-
[20]
Li, Hongji and Michail, Andrianos and Gubelmann, Reto and Clematide, Simon and Opitz, Juri , editor=. Sentence Smith:. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month=. 2025 , address=. doi:10.18653/v1/2025.emnlp-main.1343 , pages=
-
[21]
Dawn Lawrie and James Mayfield and Eugene Yang and Andrew Yates and Sean MacAvaney and Ronak Pradeep and Scott Miller and Paul McNamee and Luca Soldani , year=. 2511.14758 , archiveprefix=
-
[22]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , month=
Lewis, Patrick and Oguz, Barlas and Rinott, Ruty and Riedel, Sebastian and Schwenk, Holger , editor=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , month=. 2020 , address=. doi:10.18653/v1/2020.acl-main.653 , pages=
-
[23]
Bonifacio, Luiz and Abonizio, Hugo and Fadaee, Marzieh and Nogueira, Rodrigo , title=. 2022 , isbn=. doi:10.1145/3477495.3531863 , booktitle=
-
[24]
Proceedings of the 11th International Workshop on Semantic Evaluation (
Cer, Daniel and Diab, Mona and Agirre, Eneko and Lopez-Gazpio, I. Proceedings of the 11th International Workshop on Semantic Evaluation (. 2017 , address=. doi:10.18653/v1/S17-2001 , pages=
-
[25]
Zweigenbaum, Pierre and Sharoff, Serge and Rapp, Reinhard , editor=. Overview of the Second. Proceedings of the 10th Workshop on Building and Using Comparable Corpora , month=. 2017 , address=. doi:10.18653/v1/W17-2512 , pages=
-
[26]
Examining Multilingual Embedding Models Cross-Lingually Through
Michail, Andrianos and Clematide, Simon and Sennrich, Rico , editor=. Examining Multilingual Embedding Models Cross-Lingually Through. Findings of the Association for Computational Linguistics: EMNLP 2025 , month=. 2025 , address=. doi:10.18653/v1/2025.findings-emnlp.115 , pages=
-
[27]
Magomere, Jabez and La Malfa, Emanuele and Tonneau, Manuel and Kazemi, Ashkan and Hale, Scott A. , editor=. When Claims Evolve:. Findings of the Association for Computational Linguistics: ACL 2025 , month=. 2025 , address=. doi:10.18653/v1/2025.findings-acl.1150 , pages=
-
[28]
No Language Left Behind: Scaling Human-Centered Machine Translation
NLLB Team and Marta R. Costa-jussà and others , year=. No Language Left Behind:. 2207.04672 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Findings of the Association for Computational Linguistics: ACL 2025 , month=
Deutsch, Daniel and Briakou, Eleftheria and Caswell, Isaac Rayburn and Finkelstein, Mara and Galor, Rebecca and Juraska, Juraj and Kovacs, Geza and Lui, Alison and Rei, Ricardo and Riesa, Jason and Rijhwani, Shruti and Riley, Parker and Salesky, Elizabeth and Trabelsi, Firas and Winkler, Stephanie and Zhang, Biao and Freitag, Markus , editor=. Findings of...
-
[30]
Vamvas, Jannis and P. Expanding the. Proceedings of the Tenth Conference on Machine Translation , month=. 2025 , address=. doi:10.18653/v1/2025.wmt-1.79 , pages=
-
[31]
International Conference on Learning Representations , editor=
Enevoldsen, Kenneth and Chung, Isaac and Kerboua, Imene and Kardos, M\'. International Conference on Learning Representations , editor=
-
[32]
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , month=. 2020 , address=. doi:10.18653/v1/2020.emnlp-main.365 , pages=
-
[33]
jina-embeddings-v5-text: Task-Targeted Embedding Distillation
Mohammad Kalim Akram and Saba Sturua and Nastia Havriushenko and Quentin Herreros and Michael Günther and Maximilian Werk and Han Xiao , year=. jina-embeddings-v5-text:. 2602.15547 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Multilingual E5 Text Embeddings: A Technical Report
Liang Wang and Nan Yang and Xiaolong Huang and Linjun Yang and Rangan Majumder and Furu Wei , year=. Multilingual E5 Text Embeddings:. 2402.05672 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
EmbeddingGemma: Powerful and Lightweight Text Representations
Henrique Schechter Vera and Sahil Dua and Biao Zhang and Daniel Salz and Ryan Mullins and Sindhu Raghuram Panyam and Sara Smoot and Iftekhar Naim and Joe Zou and Feiyang Chen and Daniel Cer and Alice Lisak and Min Choi and Lucas Gonzalez and Omar Sanseviero and Glenn Cameron and Ian Ballantyne and Kat Black and Kaifeng Chen and Weiyi Wang and Zhe Li and G...
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and Zhang, Meishan and Li, Wenjie and Zhang, Min , editor=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , month=. 2024 , address=. doi:10.186...
-
[37]
2025 , eprint=
Training Sparse Mixture Of Experts Text Embedding Models , author=. 2025 , eprint=
2025
-
[38]
2025 , eprint=
Granite Embedding Models , author=. 2025 , eprint=
2025
-
[39]
Information Representation Fairness in Long-Document Embeddings: The Peculiar Interaction of Positional and Language Bias
Schuhmacher, Elias and Michail, Andrianos and Opitz, Juri and Sennrich, Rico and Clematide, Simon. Information Representation Fairness in Long-Document Embeddings: The Peculiar Interaction of Positional and Language Bias. Findings of the A ssociation for C omputational L inguistics: ACL 2026. 2026
2026
-
[40]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , month=
Unsupervised Cross-lingual Representation Learning at Scale , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , month=. 2020 , address=. doi:10.18653/v1/2020.acl-main.747 , pages=
-
[41]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month=
Andrews, Pierre and Artetxe, Mikel and Meglioli, Mariano Coria and Costa-juss. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month=. 2025 , address=. doi:10.18653/v1/2025.emnlp-main.1400 , pages=
-
[42]
Omnilingual
The Omnilingual MT Team and Belen Alastruey and Niyati Bafna and Andrea Caciolai and Kevin Heffernan and Artyom Kozhevnikov and Christophe Ropers and Eduardo S. Omnilingual. 2026 , eprint=
2026
-
[43]
2025 , eprint=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. 2025 , eprint=
2025
-
[44]
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[45]
IEEE Trans
Fangzhi Xu and Qika Lin and Jiawei Han and Tianzhe Zhao and Jun Liu and Erik Cambria , title=. IEEE Trans. Knowl. Data Eng. , volume=. 2025 , month=
2025
-
[46]
Fodor, James and De Deyne, Simon and Suzuki, Shinsuke. Compositionality and Sentence Meaning: Comparing Semantic Parsing and Transformers on a Challenging Sentence Similarity Dataset. Computational Linguistics. 2025. doi:10.1162/coli_a_00536
-
[47]
Minji Kim and Whanhee Cho and Soohyeong Kim and Yong Suk Choi , title=. Adv. Intell. Syst. , volume=. 2024 , month=
2024
-
[48]
When Truth Matters - Addressing Pragmatic Categories in Natural Language Inference (
Gubelmann, Reto and Kalouli, Aikaterini-lida and Niklaus, Christina and Handschuh, Siegfried , editor=. When Truth Matters - Addressing Pragmatic Categories in Natural Language Inference (. Proceedings of the 12th Joint Conference on Lexical and Computational Semantics (*SEM 2023) , month=. 2023 , address=. doi:10.18653/v1/2023.starsem-1.4 , pages=
-
[49]
Interpretable Text Embeddings and Text Similarity Explanation:
Opitz, Juri and M. Interpretable Text Embeddings and Text Similarity Explanation:. EMNLP 2025 , year=
2025
-
[50]
Proceedings of the 15th International Conference on Computational Semantics , month=
Opitz, Juri and Wein, Shira and Steen, Julius and Frank, Anette and Schneider, Nathan , editor=. Proceedings of the 15th International Conference on Computational Semantics , month=. 2023 , address=
2023
-
[51]
Bhagat, Rahul and Hovy, Eduard , journal=. 2013 , address=. doi:10.1162/COLI_a_00166 , pages=
-
[52]
Zhou, Jianing and Bhat, Suma , editor=. Paraphrase Generation:. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , month=. 2021 , address=. doi:10.18653/v1/2021.emnlp-main.414 , pages=
-
[53]
ArXiv , year=
Mistral 7B , author=. ArXiv , year=
-
[54]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Towards general text embeddings with multi-stage contrastive learning , author=. arXiv preprint arXiv:2308.03281 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Paraphrasing evades detectors of
Krishna, Kalpesh and Song, Yixiao and Karpinska, Marzena and Wieting, John and Iyyer, Mohit , booktitle=. Paraphrasing evades detectors of
-
[57]
Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , month=
A large annotated corpus for learning natural language inference , author=. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , month=. 2015 , address=. doi:10.18653/v1/D15-1075 , pages=
-
[58]
Benchmark Probing:
Chunyuan Deng and Yilun Zhao and Xiangru Tang and Mark Gerstein and Arman Cohan , booktitle=. Benchmark Probing:. 2024 , url=
2024
-
[59]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , month=
Syntactic Data Augmentation Increases Robustness to Inference Heuristics , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , month=. 2020 , address=. doi:10.18653/v1/2020.acl-main.212 , pages=
-
[60]
Linguistically-Informed Transformations (
Li, Chuanrong and Shengshuo, Lin and Liu, Zeyu and Wu, Xinyi and Zhou, Xuhui and Steinert-Threlkeld, Shane , editor=. Linguistically-Informed Transformations (. Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP , month=. 2020 , address=. doi:10.18653/v1/2020.blackboxnlp-1.12 , pages=
-
[61]
Parmar, Mihir and Patel, Nisarg and Varshney, Neeraj and Nakamura, Mutsumi and Luo, Man and Mashetty, Santosh and Mitra, Arindam and Baral, Chitta , year=. Proceedings of the 62nd. doi:10.18653/v1/2024.acl-long.739 , urldate=
-
[62]
Translate, then Parse! A Strong Baseline for Cross-Lingual
Uhrig, Sarah and Garcia, Yoalli and Opitz, Juri and Frank, Anette , editor=. Translate, then Parse! A Strong Baseline for Cross-Lingual. Proceedings of the 17th International Conference on Parsing Technologies and the IWPT 2021 Shared Task on Parsing into Enhanced Universal Dependencies (IWPT 2021) , month=. 2021 , address=. doi:10.18653/v1/2021.iwpt-1.6 , pages=
-
[63]
Palmer, Martha and Gildea, Daniel and Kingsbury, Paul , journal=. The. 2005 , url=. doi:10.1162/0891201053630264 , pages=
-
[64]
Proceedings of the 9th Workshop on Representation Learning for NLP (RepL4NLP-2024) , month=
Tracking linguistic information in transformer-based sentence embeddings through targeted sparsification , author=. Proceedings of the 9th Workshop on Representation Learning for NLP (RepL4NLP-2024) , month=. 2024 , address=
2024
-
[65]
Proceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024) , month=
Exploring Syntactic Information in Sentence Embeddings through Multilingual Subject-verb Agreement , author=. Proceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024) , month=. 2024 , address=
2024
-
[66]
Exploring
Nastase, Vivi and Samo, Giuseppe and Jiang, Chunyang and Merlo, Paola , editor=. Exploring. Proceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024) , month=. 2024 , address=
2024
-
[67]
Annotation of Tense and Aspect Semantics for Sentential
Donatelli, Lucia and Regan, Michael and Croft, William and Schneider, Nathan , editor=. Annotation of Tense and Aspect Semantics for Sentential. Proceedings of the Joint Workshop on Linguistic Annotation, Multiword Expressions and Constructions (. 2018 , address=
2018
-
[68]
Journal of Child Language , volume=
The development of sentence planning , author=. Journal of Child Language , volume=. 1990 , doi=
1990
-
[69]
, booktitle=
Kasper, Robert T. , booktitle=. A Flexible Interface for Linking Applications to. 1989 , url=
1989
-
[70]
First Conference on Language Modeling , year=
Description-Based Text Similarity , author=. First Conference on Language Modeling , year=
-
[71]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month=
Natural Language Decompositions of Implicit Content Enable Better Text Representations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month=. 2023 , address=. doi:10.18653/v1/2023.emnlp-main.815 , pages=
-
[72]
Fan, Lizhou and Hua, Wenyue and Li, Lingyao and Ling, Haoyang and Zhang, Yongfeng , editor=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month=. 2024 , address=. doi:10.18653/v1/2024.acl-long.225 , pages=
-
[73]
Interfacing an English text generator with a German
Bateman, John and Kasper, Robert and Sch. Interfacing an English text generator with a German. Interaktion und Kommunikation mit dem Computer: Jahrestagung der Gesellschaft f. 1990 , organization=
1990
-
[74]
Mann and Christian M
William C. Mann and Christian M. I. M. Matthiessen , title =. 1983 , url =
1983
-
[75]
Strategic Computing - Natural Language Workshop: Proceedings of a Workshop Held at Marina del Rey, California, May 1-2, 1986 , year=
A Logical-Form and Knowledge-Base Design for Natural Language Generation , author=. Strategic Computing - Natural Language Workshop: Proceedings of a Workshop Held at Marina del Rey, California, May 1-2, 1986 , year=
1986
-
[76]
Opitz, Juri and Frank, Anette , editor=. Better. Proceedings of the 3rd Workshop on Evaluation and Comparison of NLP Systems , month=. 2022 , address=. doi:10.18653/v1/2022.eval4nlp-1.4 , pages=
-
[77]
Manning, Emma and Wein, Shira and Schneider, Nathan , editor=. A Human Evaluation of. Proceedings of the 28th International Conference on Computational Linguistics , month=. 2020 , address=. doi:10.18653/v1/2020.coling-main.420 , pages=
-
[78]
Modeling Quantification and Scope in
Pustejovsky, James and Lai, Ken and Xue, Nianwen , editor=. Modeling Quantification and Scope in. Proceedings of the First International Workshop on Designing Meaning Representations , month=. 2019 , address=. doi:10.18653/v1/W19-3303 , pages=
-
[79]
Ambiguity and Disagreement in
Wein, Shira , editor=. Ambiguity and Disagreement in. Proceedings of Context and Meaning: Navigating Disagreements in NLP Annotation , month=. 2025 , address=
2025
-
[80]
Proceedings of the 31st International Conference on Computational Linguistics , month=
Michail, Andrianos and Clematide, Simon and Opitz, Juri , editor=. Proceedings of the 31st International Conference on Computational Linguistics , month=. 2025 , address=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.