Homogenization of ell₂-Adversarial Training in High-Dimensions: Exact Dynamics under Stochastic Gradient Descent
Pith reviewed 2026-07-02 17:28 UTC · model grok-4.3
The pith
ℓ2-adversarial training dynamics under streaming SGD reduce exactly to a closed system of ODEs in the high-dimensional limit, and no constant learning rate produces monotone descent of the adversarial risk for single-class least squares.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
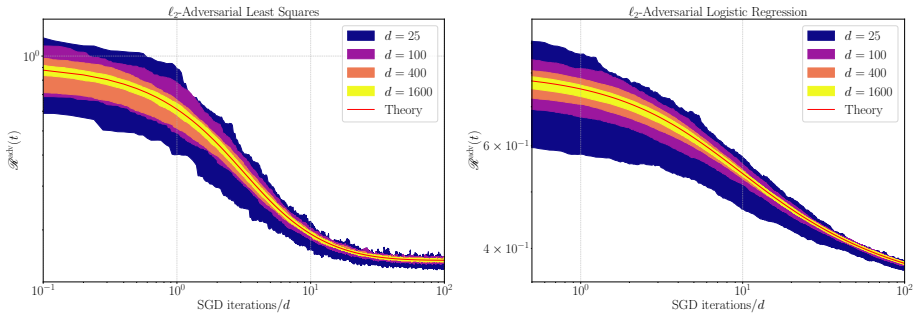
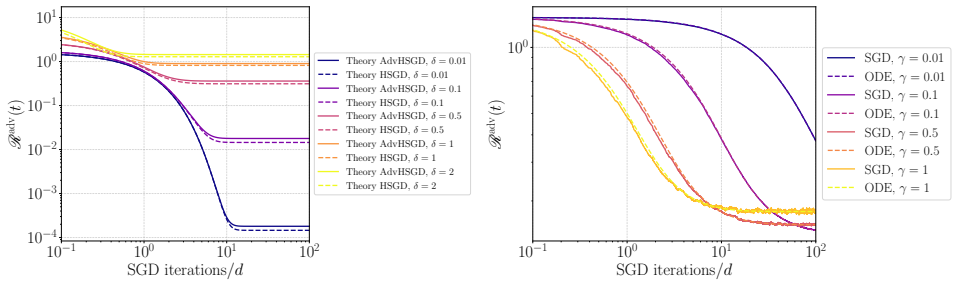
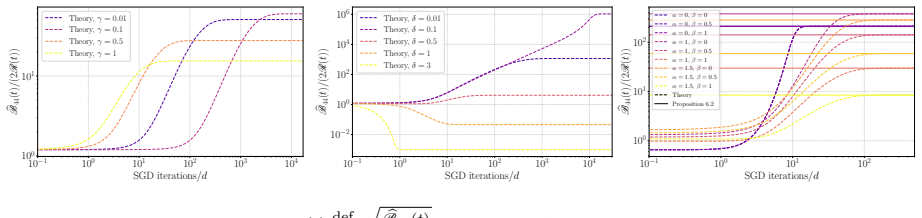
In the high-dimensional limit, statistics of the SGD iterates for ℓ2-adversarial training of single-index models on Gaussian mixtures admit deterministic equivalents given by the solution to a closed system of ODEs. For single-class ℓ2-adversarial least squares these ODEs imply that the adversarial risk does not descend monotonically for any fixed learning rate; the limiting risk and iterate are characterized by a fixed-point equation equivalent to ridge regression with the limiting effective regularization parameter of SGD.
What carries the argument
The closed system of ODEs that supplies deterministic equivalents for the adversarial risk, distance to optimality, and other statistics of the SGD iterates.
If this is right
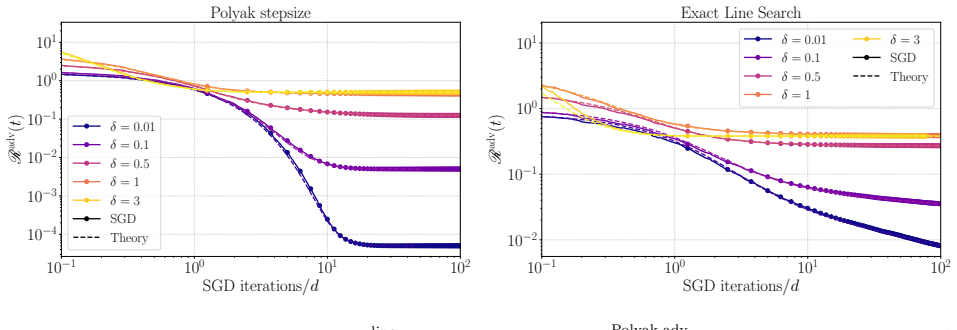
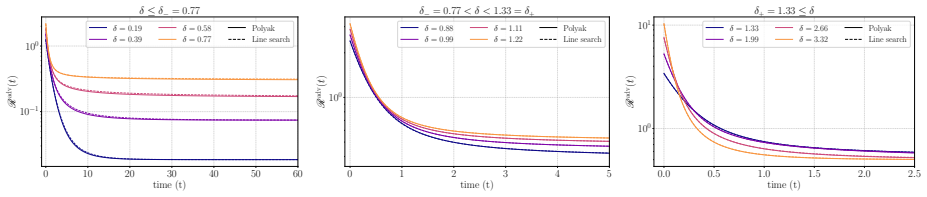
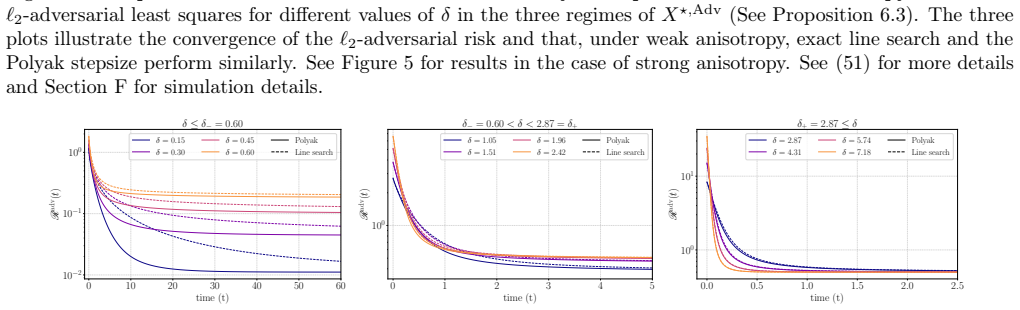
- Anisotropic covariance and mismatch between ridge parameters are the dominant sources of suboptimality of exact line search relative to the Polyak stepsize.
- The evolution of adversarial risk under the derived SDE is equivalent, up to dimension-free constants, to the evolution of standard least-squares SGD with an adaptive learning rate and adaptive ℓ2-regularization.
- When the dynamics converge, the limiting adversarial risk and the limiting SGD iterate are jointly determined by a fixed-point equation whose solution is the ridge-regression estimator with regularization equal to the limiting effective regularization of SGD.
Where Pith is reading between the lines
- The ODE reduction could be used to design learning-rate schedules that achieve faster convergence than either Polyak or exact line search.
- The equivalence to an adaptive-regularization problem suggests that adversarial training may be re-interpreted as implicit regularization whose strength evolves with the iterates.
- The same homogenization technique may extend to multi-class settings or to other adversarial norms once the corresponding single-index loss is substituted into the ODE system.
Load-bearing premise
The high-dimensional limit with data from Gaussian mixtures and single-index models under streaming SGD permits derivation of deterministic equivalents via a closed system of ODEs.
What would settle it
Finite-dimensional simulations in which the measured adversarial risk trajectory deviates from the ODE solution by more than dimension-free constants, or in which a constant learning rate produces strictly monotone descent of the adversarial risk, would falsify the deterministic-equivalent claim.
Figures



read the original abstract
We develop a framework for analyzing the learning dynamics of $\ell_2$-adversarial training of single-index models on Gaussian mixtures in the high-dimensional limit under streaming stochastic gradient descent (SGD). We derive deterministic equivalents for a broad class of statistics of the SGD iterates, including the adversarial risk and distance to adversarial optimality, in terms of the solution to a system of ODEs. We use them to study two idealized learning rate schedules: the Polyak stepsize and exact line search. In the case of $\ell_2$-adversarial least squares with a single class, we show that, unlike noiseless standard least squares, no constant learning rate guarantees monotone descent of SGD towards a minimizer of the adversarial risk. We identify anisotropic covariance and a mismatch in ridge parameters as the main sources of suboptimality of exact line search relative to the Polyak stepsize. We also introduce a stochastic differential equation (SDE), called adversarial homogenized SGD, that captures the evolution of statistics of the iterates of SGD. For $\ell_2$-adversarial least squares, using this SDE, we show the evolution of the risk is equivalent, up to dimension-free constants, to that of SGD on standard least squares with an adaptive learning rate and adaptive $\ell_2$-regularization. When the dynamics converge, the limiting adversarial risk and SGD iterate are determined by a fixed-point equation, with the limiting iterate being equivalent to the solution of a ridge regression problem whose regularization parameter is the limiting effective regularization of SGD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a framework for analyzing the high-dimensional dynamics of ℓ₂-adversarial training for single-index models on Gaussian mixtures under streaming SGD. It derives deterministic equivalents for statistics of the SGD iterates (including adversarial risk and distance to optimality) in terms of the solution to a closed system of ODEs. The work studies Polyak stepsize and exact line search, shows that no constant learning rate guarantees monotone descent of the adversarial risk for single-class ℓ₂-adversarial least squares, introduces an adversarial homogenized SGD SDE, establishes an equivalence (up to dimension-free constants) between the risk evolution and that of standard least squares with adaptive learning rate and ℓ₂-regularization, and characterizes convergence via a fixed-point equation whose solution corresponds to ridge regression with the limiting effective regularization parameter.
Significance. If the derivations hold, the results supply an exact high-dimensional characterization of adversarial training dynamics, which is a significant contribution to optimization theory in adversarial settings. Credit is due for obtaining a closed ODE system yielding deterministic equivalents and for the adversarial homogenized SGD SDE that captures iterate statistics; these enable precise analysis of idealized schedules and the identification of anisotropic covariance together with ridge-parameter mismatch as the sources of exact-line-search suboptimality. The equivalence to an adaptively regularized problem and the fixed-point characterization of the limit are also strengths.
minor comments (2)
- [Limiting behavior (abstract and associated section)] The abstract states that the limiting iterate is equivalent to the solution of a ridge regression problem whose regularization parameter is the limiting effective regularization of SGD. Clarifying whether this parameter is obtained by solving an independent equation or is extracted from the ODE trajectory would remove any appearance of circularity in the fixed-point description.
- [SDE introduction] The term 'adversarial homogenized SGD' is introduced for the SDE; a brief comparison to existing homogenized-SGD constructions in the literature would improve readability for readers familiar with the non-adversarial case.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of its contributions, and recommendation for minor revision. No specific major comments were raised.
Circularity Check
No significant circularity; derivation self-contained via high-dim limits
full rationale
The paper derives deterministic equivalents and a closed ODE system for SGD statistics in the high-dimensional Gaussian-mixture/single-index setting under streaming SGD. This is a standard homogenization technique that produces an independent dynamical system whose solutions are then analyzed for risk behavior and fixed points. The limiting fixed-point equation for adversarial risk and the effective regularization parameter arises as the equilibrium of the derived ODEs, not by redefining inputs or fitting to the target quantity. No self-citation load-bearing step, ansatz smuggling, or reduction of a prediction to a fitted input is present in the abstract or described chain. The central claim on non-monotonicity under constant learning rates follows from solving the independent ODE system and is externally falsifiable via the high-dim limit assumptions.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption High-dimensional limit (dimension o ∞) yields deterministic equivalents
- domain assumption Data generated from Gaussian mixtures
- domain assumption Streaming (one-pass) stochastic gradient descent
invented entities (1)
-
adversarial homogenized SGD (SDE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Luca Arnaboldi, Ludovic Stephan, Florent Krzakala, and Bruno Loureiro. From high-dimensional and mean- field dynamics to dimensionless ODEs: A unifying approach to SGD in two-layers networks.arXiv preprint arXiv:2302.05882, 2023
-
[2]
Escaping mediocrity: how two-layer networks learn hard generalized linear models with sgd, 2024
Luca Arnaboldi, Florent Krzakala, Bruno Loureiro, and Ludovic Stephan. Escaping mediocrity: how two-layer networks learn hard generalized linear models with sgd, 2024. URLhttps://arxiv.org/abs/2305.18502
-
[3]
High-dimensional limit theorems for sgd: Effective dynamics and critical scaling, 2023
Gerard Ben Arous, Reza Gheissari, and Aukosh Jagannath. High-dimensional limit theorems for sgd: Effective dynamics and critical scaling, 2023. URLhttps://arxiv.org/abs/2206.04030
-
[4]
Local geometry of high-dimensional mixture models: Effective spectral theory and dynamical transitions, 2026
Gerard Ben Arous, Reza Gheissari, Jiaoyang Huang, and Aukosh Jagannath. Local geometry of high-dimensional mixture models: Effective spectral theory and dynamical transitions, 2026. URLhttps://arxiv.org/abs/2502. 15655. 43
2026
-
[5]
Courier Corporation, 2004
Krishna B Athreya, Peter E Ney, and PE Ney.Branching processes. Courier Corporation, 2004
2004
-
[6]
Recent advances in adversarial training for adversarial robustness
Tao Bai, Jinqi Luo, Jun Zhao, Bihan Wen, and Qian Wang. Recent advances in adversarial training for adversarial robustness. In Zhi-Hua Zhou, editor,Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 4312–4321. International Joint Conferences on Artificial Intelligence Organization, 8 2021. doi: 10.24963...
-
[7]
Krishnakumar Balasubramanian, Promit Ghosal, and Ye He. High-dimensional scaling limits and fluctuations of online least-squares sgd with smooth covariance, 2024. URLhttps://arxiv.org/abs/2304.00707
-
[8]
High-dimensional limit theorems for SGD: Effective dynamics and critical scaling
Gerard Ben Arous, Reza Gheissari, and Aukosh Jagannath. High-dimensional limit theorems for SGD: Effective dynamics and critical scaling. InAdvances in Neural Information Processing Systems, volume 35, pages 25349–25362, New York, 2022. Curran Associates, Inc
2022
-
[9]
Lower bounds on adversarial robustness from optimal transport, 2019
Arjun Nitin Bhagoji, Daniel Cullina, and Prateek Mittal. Lower bounds on adversarial robustness from optimal transport, 2019. URLhttps://arxiv.org/abs/1909.12272
-
[10]
On-line learning with a perceptron.Europhysics Letters, 28(7):525, 1994
Michael Biehl and Peter Riegler. On-line learning with a perceptron.Europhysics Letters, 28(7):525, 1994
1994
-
[11]
Learning by on-line gradient descent.Journal of Physics A: Mathematical and general, 28(3):643, 1995
Michael Biehl and Holm Schwarze. Learning by on-line gradient descent.Journal of Physics A: Mathematical and general, 28(3):643, 1995
1995
-
[12]
Learning curves for sgd on structured features, 2022
Blake Bordelon and Cengiz Pehlevan. Learning curves for sgd on structured features, 2022. URL https: //arxiv.org/abs/2106.02713
-
[13]
The high-dimensional asymptotics of first order methods with random data
Michael Celentano, Chen Cheng, and Andrea Montanari. The high-dimensional asymptotics of first order methods with random data, 2026. URLhttps://arxiv.org/abs/2112.07572
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Sharp global convergence guarantees for iterative nonconvex optimization with random data.Ann
Kabir Aladin Chandrasekher, Ashwin Pananjady, and Christos Thrampoulidis. Sharp global convergence guarantees for iterative nonconvex optimization with random data.Ann. Statist., 51(1):179–210, 2023. ISSN 0090-5364,2168-8966. doi: 10.1214/22-aos2246. URLhttps://doi.org/10.1214/22-aos2246
-
[15]
Robust overfitting may be mitigated by properly learned smoothening
Tianlong Chen, Zhenyu Zhang, Sijia Liu, Shiyu Chang, and Zhangyang Wang. Robust overfitting may be mitigated by properly learned smoothening. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=qZzy5urZw9
2021
-
[16]
Why adversarial training can hurt robust accuracy, 2022
Jacob Clarysse, Julia Hörrmann, and Fanny Yang. Why adversarial training can hurt robust accuracy, 2022. URLhttps://arxiv.org/abs/2203.02006
-
[17]
High-dimensional limit of one-pass SGD on least squares
Elizabeth Collins-Woodfin and Elliot Paquette. High-dimensional limit of one-pass SGD on least squares. Electronic Communications in Probability, 29:1–15, 2024. doi: 10.1214/23-ECP571
-
[18]
Exact dynamics of multi-class stochastic gradient descent, 2025
Elizabeth Collins-Woodfin and Inbar Seroussi. Exact dynamics of multi-class stochastic gradient descent, 2025. URLhttps://arxiv.org/abs/2510.14074
-
[19]
Elizabeth Collins-Woodfin, Courtney Paquette, Elliot Paquette, and Inbar Seroussi. Hitting the high-dimensional notes: an ode for sgd learning dynamics on glms and multi-index models.Information and Inference: A Journal of the IMA, 13(4):iaae028, 12 2024. ISSN 2049-8772. doi: 10.1093/imaiai/iaae028. URL https: //doi.org/10.1093/imaiai/iaae028
-
[20]
The high line: Exact risk and learning rate curves of stochastic adaptive learning rate algorithms
Elizabeth Collins-Woodfin, Inbar Seroussi, Begoña García Malaxechebarría, Andrew Mackenzie, Elliot Paquette, and Courtney Paquette. The high line: Exact risk and learning rate curves of stochastic adaptive learning rate algorithms. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=4VWnC5unAV
2024
- [21]
- [22]
-
[23]
Sharp statistical guarantees for adversarially robust gaussian classification, 2020
Chen Dan, Yuting Wei, and Pradeep Ravikumar. Sharp statistical guarantees for adversarially robust gaussian classification, 2020. URLhttps://arxiv.org/abs/2006.16384. 44
-
[24]
Yatin Dandi, Emanuele Troiani, Luca Arnaboldi, Luca Pesce, Lenka Zdeborová, and Florent Krzakala. The benefits of reusing batches for gradient descent in two-layer networks: Breaking the curse of information and leap exponents.arXiv preprint arXiv:2402.03220, 2024
-
[25]
John M. Danskin. The theory of max-min and its application to weapons allocation problems. 1967. URL https://api.semanticscholar.org/CorpusID:122915464
1967
-
[26]
Provable tradeoffs in adversarially robust classification, 2022
Edgar Dobriban, Hamed Hassani, David Hong, and Alexander Robey. Provable tradeoffs in adversarially robust classification, 2022. URLhttps://arxiv.org/abs/2006.05161
-
[27]
Precise accuracy / robustness tradeoffs in regression: Case of general norms
Elvis Dohmatob and Meyer Scetbon. Precise accuracy / robustness tradeoffs in regression: Case of general norms. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learn...
2024
-
[28]
Zhou Fan and Leda Wang. High-dimensional learning dynamics of multi-pass stochastic gradient descent in multi-index models, 2026. URLhttps://arxiv.org/abs/2601.21093
-
[29]
Analysis of classifiers’ robustness to adversarial perturbations
Alhussein Fawzi, Omar Fawzi, and Pascal Frossard. Analysis of classifiers’ robustness to adversarial perturbations. Mach. Learn., 107(3):481–508, March 2018. ISSN 0885-6125. doi: 10.1007/s10994-017-5663-3. URLhttps: //doi.org/10.1007/s10994-017-5663-3
-
[30]
Cédric Gerbelot, Emanuele Troiani, Francesca Mignacco, Florent Krzakala, and Lenka Zdeborová. Rigorous dynamical mean-field theory for stochastic gradient descent methods.SIAM Journal on Mathematics of Data Science, 6(2):400–427, 2024. doi: 10.1137/23M1594388. URLhttps://doi.org/10.1137/23M1594388
-
[31]
Dynamics of stochastic gradient descent for two-layer neural networks in the teacher-student setup.Advances in neural information processing systems, 32, 2019
Sebastian Goldt, Madhu Advani, Andrew M Saxe, Florent Krzakala, and Lenka Zdeborová. Dynamics of stochastic gradient descent for two-layer neural networks in the teacher-student setup.Advances in neural information processing systems, 32, 2019
2019
-
[32]
Modeling the influence of data structure on learning in neural networks: The hidden manifold model.Physical Review X, 10(4):041044, 2020
Sebastian Goldt, Marc Mézard, Florent Krzakala, and Lenka Zdeborová. Modeling the influence of data structure on learning in neural networks: The hidden manifold model.Physical Review X, 10(4):041044, 2020
2020
-
[33]
The gaussian equivalence of generative models for learning with shallow neural networks
Sebastian Goldt, Bruno Loureiro, Galen Reeves, Florent Krzakala, Marc Mézard, and Lenka Zdeborová. The gaussian equivalence of generative models for learning with shallow neural networks. InMathematical and Scientific Machine Learning, pages 426–471, New York, New York, USA, 2022. PMLR
2022
-
[34]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. In Yoshua Bengio and Yann LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URLhttp://arxiv.org/abs/1412. 6572
2015
-
[35]
Adversarial training for gradient descent: Analysis through its continuous- time approximation, 2023
Haotian Gu, Xin Guo, and Xinyu Li. Adversarial training for gradient descent: Analysis through its continuous- time approximation, 2023. URLhttps://arxiv.org/abs/2105.08037
-
[36]
Hamed Hassani and Adel Javanmard. The curse of overparametrization in adversarial training: Precise analysis of robust generalization for random features regression, 2024. URLhttps://arxiv.org/abs/2201.05149
-
[37]
Adversarial examples are not bugs, they are features
Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. Adversarial examples are not bugs, they are features. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché- Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://...
2019
-
[38]
Precise statistical analysis of classification accuracies for adversarial training, 2022
Adel Javanmard and Mahdi Soltanolkotabi. Precise statistical analysis of classification accuracies for adversarial training, 2022. URLhttps://arxiv.org/abs/2010.11213
-
[39]
Precise tradeoffs in adversarial training for linear regression, 2020
Adel Javanmard, Mahdi Soltanolkotabi, and Hamed Hassani. Precise tradeoffs in adversarial training for linear regression, 2020. URLhttps://arxiv.org/abs/2002.10477. 45
-
[40]
Adversarial attacks and defences competition
Alexey Kurakin, Ian Goodfellow, Samy Bengio, Yinpeng Dong, Fangzhou Liao, Ming Liang, Tianyu Pang, Jun Zhu, Xiaolin Hu, Cihang Xie, Jianyu Wang, Zhishuai Zhang, Zhou Ren, Alan Yuille, Sangxia Huang, Yao Zhao, Yuzhe Zhao, Zhonglin Han, Junjiajia Long, Yerkebulan Berdibekov, Takuya Akiba, Seiya Tokui, and Motoki Abe. Adversarial attacks and defences competi...
2018
-
[41]
Cheng, Courtney Paquette, and Elliot Paquette
Kiwon Lee, Andrew N. Cheng, Courtney Paquette, and Elliot Paquette. Trajectory of Mini-Batch Momentum: Batch Size Saturation and Convergence in High Dimensions.To Appear in NeurIPS 2022, art. arXiv:2206.01029, June 2022
-
[42]
Qianxiao Li, Cheng Tai, and Weinan E. Stochastic modified equations and dynamics of stochastic gradient algorithms i: Mathematical foundations, 2018. URLhttps://arxiv.org/abs/1811.01558
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Stochastic polyak step-size for SGD: An adaptive learning rate for fast convergence
Nicolas Loizou, Sharan Vaswani, Issam Hadj Laradji, and Simon Lacoste-Julien. Stochastic polyak step-size for SGD: An adaptive learning rate for fast convergence. InInternational Conference on Artificial Intelligence and Statistics, pages 1306–1314. PMLR, 2021
2021
-
[44]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net,
2018
-
[45]
URLhttps://openreview.net/forum?id=rJzIBfZAb
-
[46]
To clip or not to clip: the dynamics of sgd with gradient clipping in high-dimensions, 2024
Noah Marshall, Ke Liang Xiao, Atish Agarwala, and Elliot Paquette. To clip or not to clip: the dynamics of sgd with gradient clipping in high-dimensions, 2024. URLhttps://arxiv.org/abs/2406.11733
-
[47]
Francesca Mignacco, Florent Krzakala, Pierfrancesco Urbani, and Lenka Zdeborová. Dynamical mean-field theory for stochastic gradient descent in gaussian mixture classification*.Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124008, December 2021. ISSN 1742-5468. doi: 10.1088/1742-5468/ac3a80. URL http://dx.doi.org/10.1088/1742-5468/ac3a80
-
[48]
Bag of tricks for adversarial training, 2021
Tianyu Pang, Xiao Yang, Yinpeng Dong, Hang Su, and Jun Zhu. Bag of tricks for adversarial training, 2021. URLhttps://arxiv.org/abs/2010.00467
-
[49]
Paquette, K
C. Paquette, K. Lee, F. Pedregosa, and E. Paquette. SGD in the Large: Average-case Analysis, Asymptotics, and Stepsize Criticality. InProceedings of Thirty Fourth Conference on Learning Theory (COLT), volume 134, pages 3548–3626, 2021
2021
-
[50]
Courtney Paquette, Elliot Paquette, Ben Adlam, and Jeffrey Pennington. Homogenization of SGD in high- dimensions: Exact dynamics and generalization properties.arXiv e-prints, art. arXiv:2205.07069, May 2022
-
[51]
P.E. Protter.Stochastic integration and differential equations, volume 21 ofStochastic Modelling and Applied Probability. Springer-Verlag, Berlin, 2005. doi: 10.1007/978-3-662-10061-5. URLhttps://doi.org/10.1007/ 978-3-662-10061-5
-
[52]
Understanding and mitigating the tradeoff between robustness and accuracy, 2020
Aditi Raghunathan, Sang Michael Xie, Fanny Yang, John Duchi, and Percy Liang. Understanding and mitigating the tradeoff between robustness and accuracy, 2020. URLhttps://arxiv.org/abs/2002.10716
-
[53]
Classifying high-dimensional gaussian mixtures: Where kernel methods fail and neural networks succeed, 2021
Maria Refinetti, Sebastian Goldt, Florent Krzakala, and Lenka Zdeborová. Classifying high-dimensional gaussian mixtures: Where kernel methods fail and neural networks succeed, 2021. URLhttps://arxiv.org/abs/2102. 11742
2021
-
[54]
Regularization properties of adversarially-trained linear regression
Antonio Ribeiro, Dave Zachariah, Francis Bach, and Thomas Schön. Regularization properties of adversarially-trained linear regression. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 23658–23670. Curran Associates, Inc., 2023. URL https://proceedings.neurip...
2023
-
[55]
Ribeiro, Thomas B
Antonio H. Ribeiro, Thomas B. Schön, Dave Zachariah, and Francis Bach. Efficient optimization algorithms for linear adversarial training. In Yingzhen Li, Stephan Mandt, Shipra Agrawal, and Emtiyaz Khan, editors, Proceedings of The 28th International Conference on Artificial Intelligence and Statistics, volume258ofProceedings of Machine Learning Research, ...
2025
-
[56]
Antônio H. Ribeiro and Thomas B. Schön. Overparameterized linear regression under adversarial attacks.IEEE Transactions on Signal Processing, 71:601–614, 2023. doi: 10.1109/TSP.2023.3246228
-
[57]
Ribeiro, Dave Zachariah, Francis Bach, and Thomas B
Antônio H. Ribeiro, Dave Zachariah, Francis Bach, and Thomas B. Schön. Regularization properties of adversarially-trained linear regression, 2023. URLhttps://arxiv.org/abs/2310.10807
-
[58]
Leslie Rice, Eric Wong, and J. Zico Kolter. Overfitting in adversarially robust deep learning, 2020. URL https://arxiv.org/abs/2002.11569
-
[59]
Dynamics of on-line gradient descent learning for multilayer neural networks
David Saad and Sara Solla. Dynamics of on-line gradient descent learning for multilayer neural networks. In Advances in Neural Information Processing Systems, volume 8. MIT Press, 1995
1995
-
[60]
Exact solution for on-line learning in multilayer neural networks.Physical Review Letters, 74(21):4337, 1995
David Saad and Sara A Solla. Exact solution for on-line learning in multilayer neural networks.Physical Review Letters, 74(21):4337, 1995
1995
-
[61]
Davis, Gavin Taylor, and Tom Goldstein
Ali Shafahi, Mahyar Najibi, Amin Ghiasi, Zheng Xu, John Dickerson, Christoph Studer, Larry S. Davis, Gavin Taylor, and Tom Goldstein. Adversarial training for free!, 2019. URLhttps://arxiv.org/abs/1904.12843
-
[62]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. InInternational Conference on Learning Representations (ICLR), January 2014
2014
-
[63]
Asymptotic behavior of adversarial training in binary classification, 2021
Hossein Taheri, Ramtin Pedarsani, and Christos Thrampoulidis. Asymptotic behavior of adversarial training in binary classification, 2021. URLhttps://arxiv.org/abs/2010.13275
-
[64]
A high dimensional statistical model for adversarial training: Geometry and trade-offs, 2024
Kasimir Tanner, Matteo Vilucchio, Bruno Loureiro, and Florent Krzakala. A high dimensional statistical model for adversarial training: Geometry and trade-offs, 2024. URLhttps://arxiv.org/abs/2402.05674
-
[65]
Vershynin.High-dimensional probability: An introduction with applications in data science
R. Vershynin.High-dimensional probability: An introduction with applications in data science. Cambridge University Press, Cambridge, UK, 2018. doi: 10.1017/9781108231596. URL https://doi.org/10.1017/ 9781108231596
-
[66]
Matteo Vilucchio, Nikolaos Tsilivis, Bruno Loureiro, and Julia Kempe. On the geometry of regularization in adversarial training: High-dimensional asymptotics and generalization bounds, 2024. URLhttps://arxiv.org/ abs/2410.16073
-
[67]
A solvable high-dimensional model of GAN
Chuang Wang, Hong Hu, and Yue Lu. A solvable high-dimensional model of GAN. InAdvances in Neural Information Processing Systems, volume 32, New York, 2019. Curran Associates, Inc
2019
-
[68]
More than a toy: Random matrix models predict how real- world neural representations generalize
Alexander Wei, Wei Hu, and Jacob Steinhardt. More than a toy: Random matrix models predict how real- world neural representations generalize. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learn...
2022
-
[69]
Ke Liang Xiao, Noah Marshall, Atish Agarwala, and Elliot Paquette. Exact risk curves of signsgd in high- dimensions: Quantifying preconditioning and noise-compression effects, 2026. URLhttps://arxiv.org/abs/ 2411.12135
-
[70]
Adversarially robust estimate and risk analysis in linear regression
Yue Xing, Ruizhi Zhang, and Guang Cheng. Adversarially robust estimate and risk analysis in linear regression. In Arindam Banerjee and Kenji Fukumizu, editors,Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 ofProceedings of Machine Learning Research, pages 514–522. PMLR, 13–15 Apr 2021. URLhttps://pro...
2021
-
[71]
Data-dependence of plateau phenomenon in learning with neural network— statistical mechanical analysis
Yuki Yoshida and Masato Okada. Data-dependence of plateau phenomenon in learning with neural network— statistical mechanical analysis. InAdvances in Neural Information Processing Systems, volume 32, New York,
-
[72]
Curran Associates, Inc
-
[73]
Adversarial examples: Attacks and defenses for deep learning
Xiaoyong Yuan, Pan He, Qile Zhu, and Xiaolin Li. Adversarial examples: Attacks and defenses for deep learning. IEEE Transactions on Neural Networks and Learning Systems, 30(9):2805–2824, 2019. doi: 10.1109/TNNLS. 2018.2886017
-
[74]
Adversarially robust generalization just requires more unlabeled data, 2019
Runtian Zhai, Tianle Cai, Di He, Chen Dan, Kun He, John Hopcroft, and Liwei Wang. Adversarially robust generalization just requires more unlabeled data, 2019. URLhttps://arxiv.org/abs/1906.00555. 47 A Preliminaries for the Proofs The results in this section build upon [18, 19] in order to fit the current framework. We refer the reader to Section 3 of [19]...
-
[75]
Recall we also defined the norm∥ · ∥Γ for a continuous functionH:C 2 →R 4×4: ∥H∥Γ = max z∈Γ2 ∥H(z)∥
Recall for z∈ Γ2, we writez = (z1, z2)and when integrating over allz1 simultaneously, we write for any functionf:C 2 →C I f(z)Dz def = −1 4π2 I Γ2 f(z) dz1 dz2. Recall we also defined the norm∥ · ∥Γ for a continuous functionH:C 2 →R 4×4: ∥H∥Γ = max z∈Γ2 ∥H(z)∥. In the next subsections, we will control the error terms which arise in the Doob decompositions...
-
[76]
65 In the following proof of Proposition A.3, we build upon Proposition A.3 of [19] and Lemma 10 in [18]
Thus, it follows from Azuma’s inequality and a union bound as done in (292) that, with overwhelming probability sup 0≤k≤T d |MGrad k |< d − 1 2 +(3+α)ζ.(308) Hence for any arbitrarily small value ofζ < 1 2(3+α), the result follows. 65 In the following proof of Proposition A.3, we build upon Proposition A.3 of [19] and Lemma 10 in [18]. Proposition A.3(Hes...
-
[77]
(337) which impliesF k,i −F β k,i = 0with overwhelming probability
Hence, for sufficiently large dwe have P(|Fk,i −F β k,i|>0)≤Cexp −Ω(dmin(β 2, β)) . (337) which impliesF k,i −F β k,i = 0with overwhelming probability. It then follows from a union bound that T dX k=1 |Fk,Ik+1 −F β k,Ik+1 |= 0,(338) with overwhelming probability. We omit the proof that|E [Fk,i −F β k,i]| is exponentially small ind, since the steps are alm...
-
[78]
It is then easy to see that∥Πk,i∥2 ≤ 2. Before proceeding with the proof, we introduce the definition of the nuclear norm ∥A∥∗ def = sup ∥B∥op=1 ⟨A, B⟩.(341) SinceQ k,i is a matrix with orthonormal columns, note that∥Πk,i∥∗ ≤2. Recall from (266) the definition ofEHess k E Hess k (φ) = γ2 k d2 2X i=1 pi(f ′ i(gk,i))2 · − ⟨∇2φ(Xk), p KiΠk,i p Ki⟩ +⟨∇ 2φ( ˆX...
-
[79]
Analogously to [20], we call this learning rate thePolyak stepsize
and should be compared to the greedy learning rateγPolyak,⋆(t)that maximizes the decrease ofD2(t)at each iteration: γPolyak,⋆(t) ∈argmin γ dD2(t). Analogously to [20], we call this learning rate thePolyak stepsize. Solving forγ k andγ(t)respectively in (399) and (400), we obtain the following closed forms for the Polyak learning rate γPolyak,∗ k = 1 2 γSt...
-
[80]
Hence, the ratio L∞,d F∞,d converges uniformly on[q−, q+]to L∞ F∞ as d→ ∞
Since F∞,d to F∞ converges uniformly on[q−, q+]as d→ ∞ , for sufficiently larged it follows thatF∞,d > 0for all[ q−, q+]. Hence, the ratio L∞,d F∞,d converges uniformly on[q−, q+]to L∞ F∞ as d→ ∞ . Since the function G(q)is continuous on[q −, q+], combining all these results we conclude that sup q∈[q−,q+] |Hd(q)−H(q)| − → d→∞ 0.(517) Now, take any subsequ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.