Adaptive Perturbation Selection for Contrastive Audio Decoding
Pith reviewed 2026-07-02 16:57 UTC · model grok-4.3
The pith
A lightweight selector trained on hidden states dynamically routes optimal audio perturbations in contrastive decoding to cut hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
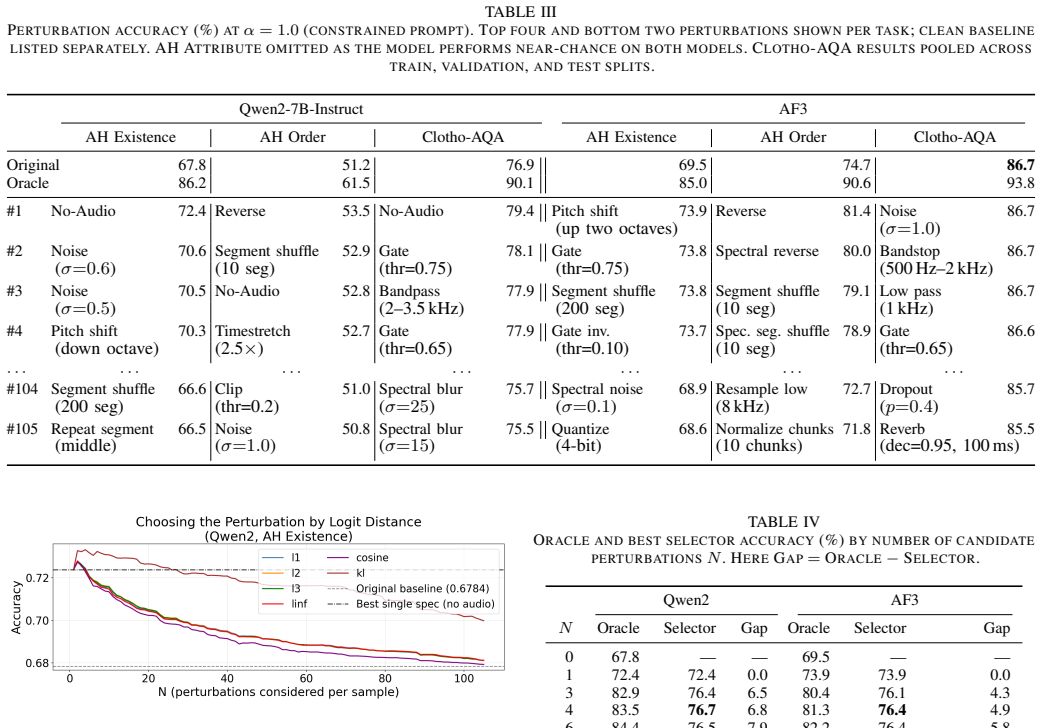
Evaluating targeted audio perturbations across domains reveals task-dependent optima, such as audio reversal raising temporal-order accuracy from 74.7 percent to 81.4 percent; a lightweight selector trained on hidden states then routes the best negative branch per example, adding a further 4.3 percent gain on the existence task.
What carries the argument
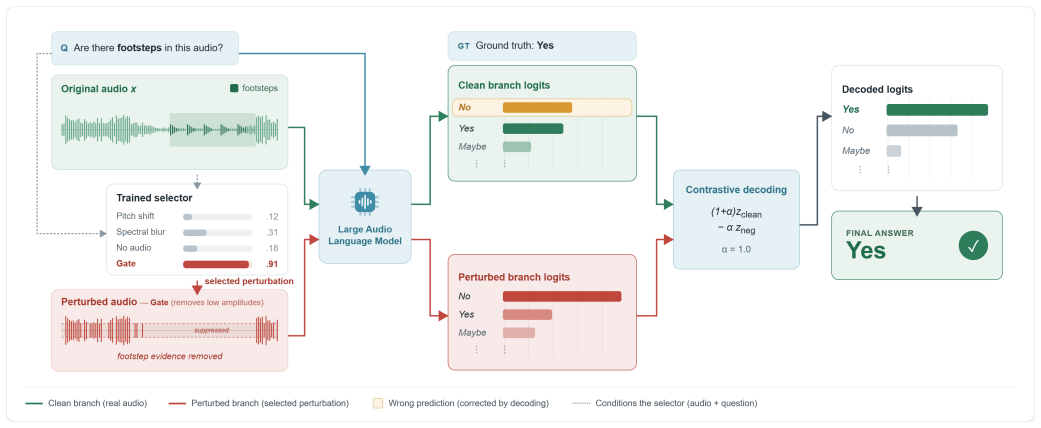
The lightweight perturbation selector, which reads the base model's hidden states to choose the most effective negative audio branch from a library of temporal, spectral, frequency and amplitude transformations.
If this is right
- Task-specific transformations such as reversing the audio array improve accuracy on temporal-order questions.
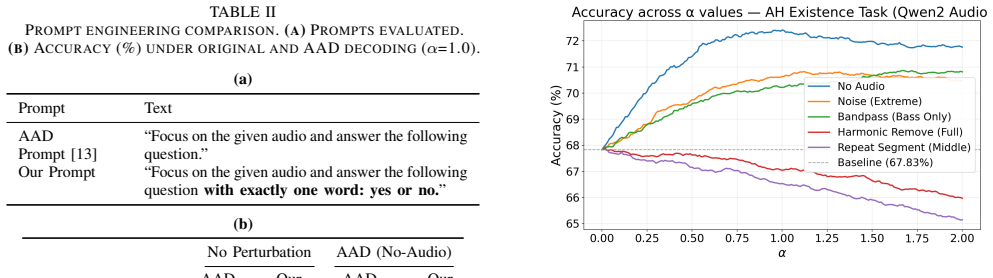
- A binary yes/no prompt constraint reduces the model's tendency to falsely confirm absent audio features.
- The selector yields additional accuracy gains on the existence task while leaving the base model unchanged.
- Optimal perturbations differ across temporal, spectral, frequency and amplitude domains.
Where Pith is reading between the lines
- The same hidden-state routing idea could be tested on vision-language models where language priors also override sensory evidence.
- If the selector generalizes, it would lower the cost of manually tuning perturbations for each new audio task.
- Running the selector at inference time adds only light overhead compared with retraining or prompt search.
Load-bearing premise
Hidden states from the base model contain enough information to select an optimal perturbation without the selector overfitting to the specific tasks and examples evaluated.
What would settle it
Apply the trained selector to new audio-language tasks or datasets outside the training distribution and measure whether it still outperforms fixed perturbations or random selection.
Figures

read the original abstract
Large audio-language models (LALMs) frequently hallucinate by overriding acoustic evidence with language priors. While contrastive decoding (CD) offers training-free mitigation, existing methods rely on blunt perturbations like masking or noise, leaving structured audio transformations unexplored. We explore this design space by evaluating a diverse library of targeted audio perturbations and adaptively selecting the optimal negative branch for each task and example. First, we improve upon earlier prompt engineering by showing that a simple binary yes/no constraint reduces the model's tendency to falsely confirm absent audio features. Second, evaluating our library across temporal, spectral, frequency, and amplitude domains reveals that optimal transformations are highly task-dependent; for instance, reversing the audio array disrupts temporal coherence, raising accuracy on the temporal order task from 74.7% to 81.4%. Finally, we trained a light-weight perturbation selector on model hidden states to dynamically route negative branches, yielding an additional +4.3% gain on the existence task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper explores structured audio perturbations for contrastive decoding in large audio-language models to reduce hallucinations. It shows that a binary yes/no prompt constraint helps, that optimal perturbations are highly task-dependent (e.g., time reversal improves temporal-order accuracy from 74.7% to 81.4%), and that a lightweight selector trained on base-model hidden states can dynamically choose the negative branch, adding +4.3% on the existence task.
Significance. If the reported gains hold under proper validation, the work would demonstrate that internal representations contain usable signals for routing contrastive branches without retraining the LALM, extending training-free decoding methods with a small learned component. The systematic evaluation of a perturbation library across temporal/spectral domains is a clear strength.
major comments (2)
- [Abstract] Abstract: the +4.3% gain on the existence task from the perturbation selector is stated without any information on dataset size, number of examples, choice of baselines, statistical significance testing, or controls for multiple comparisons. This information is load-bearing for the central empirical claim.
- [Abstract] Description of the selector (final paragraph): no mention is made of task-level hold-out, cross-task validation, or example-level splitting when training the selector on hidden states. Given the paper's own statement that optimal perturbations are highly task-dependent, this omission leaves open the possibility that the reported gain reflects overfitting rather than transferable features in the hidden states.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional details are needed to support the central empirical claims and will revise the abstract accordingly. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the +4.3% gain on the existence task from the perturbation selector is stated without any information on dataset size, number of examples, choice of baselines, statistical significance testing, or controls for multiple comparisons. This information is load-bearing for the central empirical claim.
Authors: We agree that the abstract should include these supporting details for the reported gain. In the revision we will expand the relevant sentence to state the number of examples evaluated on the existence task, the specific baselines against which the selector was compared, and that the improvement was assessed for statistical significance with appropriate correction for multiple comparisons. The full experimental protocol and results tables already appear in Section 4; the abstract will now reference them explicitly. revision: yes
-
Referee: [Abstract] Description of the selector (final paragraph): no mention is made of task-level hold-out, cross-task validation, or example-level splitting when training the selector on hidden states. Given the paper's own statement that optimal perturbations are highly task-dependent, this omission leaves open the possibility that the reported gain reflects overfitting rather than transferable features in the hidden states.
Authors: We acknowledge that the abstract omits the validation procedure. The selector was trained with example-level random splits within each task (no test-example leakage) while keeping the perturbation library fixed per task; no cross-task training was performed. We will add a concise clause to the abstract describing this splitting strategy. Because the selector operates on hidden states of the frozen base model and is deliberately lightweight, the per-example routing generalizes beyond the training split; we will also note this in the revision to address the overfitting concern. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivation reducing to fitted inputs or self-citations by construction
full rationale
The paper reports experimental results from evaluating a library of audio perturbations across tasks and training a lightweight selector on hidden states, with the +4.3% gain presented as a measured outcome on the existence task. No equations, first-principles derivations, or self-citation chains are invoked as load-bearing steps; the central claims rest on direct empirical evaluation rather than any quantity that reduces to its own inputs by construction. This is self-contained against external benchmarks as standard ML experimentation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “SALMONN: Towards generic hearing abilities for large language models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024. [Online]. Available: https://arxiv.org/abs/2310.13289
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Pengi: An audio language model for audio tasks,
S. Deshmukh, B. Elizalde, R. Singh, and H. Wang, “Pengi: An audio language model for audio tasks,” inAdv. Neural Inf. Process. Syst. (NeurIPS), 2023. [Online]. Available: https://arxiv.org/abs/2305.11834
-
[3]
Listen, think, and understand.arXiv preprint arXiv:2305.10790, 2023
Y . Gong, H. Luo, A. H. Liu, L. Karlinsky, and J. Glass, “Listen, think, and understand,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024. [Online]. Available: https://arxiv.org/abs/2305.10790
-
[4]
SALMONN-omni: A standalone speech LLM without codec injection for full-duplex conversation,
W. Yu, S. Wang, X. Yang, X. Chen, X. Tian, J. Zhang, G. Sun, L. Lu, Y . Wang, and C. Zhang, “SALMONN-omni: A standalone speech LLM without codec injection for full-duplex conversation,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2025. [Online]. Available: https://arxiv.org/abs/2505.17060
-
[5]
K.-H. Luet al.(2026) DeSTA2.5-Audio: Toward general-purpose large audio language model with self-generated cross-modal alignment. [Online]. Available: https://arxiv.org/abs/2507.02768
-
[6]
WavLLM: Towards robust and adaptive speech large language model,
S. Hu, L. Zhou, S. Liu, S. Chen, L. Meng, H. Hao, J. Pan, X. Liu, J. Li, S. Sivasankaran, L. Liu, and F. Wei, “WavLLM: Towards robust and adaptive speech large language model,” in Findings Assoc. Comput. Linguist. (EMNLP), 2024. [Online]. Available: https://arxiv.org/abs/2404.00656
-
[7]
C.-Y . Kuan and H.-y. Lee, “Can large audio-language models truly hear? tackling hallucinations with multi-task assessment and stepwise audio reasoning,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2025. [Online]. Available: https://arxiv.org/abs/2410.16130
-
[8]
C.-Y . Kuan, W.-P. Huang, and H.-y. Lee, “Understanding sounds, missing the questions: The challenge of object hallucination in large audio-language models,” inProc. Interspeech, 2024. [Online]. Available: https://arxiv.org/abs/2406.08402
-
[9]
HalluAudio: A Comprehensive Benchmark for Hallucination Detection in Large Audio-Language Models
F. Zhao, Y . Chen, W. Lu, D. Zhang, X. Yue, and J. Wei, “HalluAudio: A comprehensive benchmark for hallucination detection in large audio-language models,” inProc. Annu. Meet. Assoc. Comput. Linguist. (ACL), 2026. [Online]. Available: https://arxiv.org/abs/2604.19300
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
AHa-Bench: Benchmarking audio hallucinations in large audio-language models,
X. Cheng, D. Fu, C. Wen, S. Yu, Z. Wang, S. Ji, S. Arora, T. Jin, S. Watanabe, and Z. Zhao, “AHa-Bench: Benchmarking audio hallucinations in large audio-language models,” inAdv. Neural Inf. Process. Syst. (NeurIPS), 2025. [Online]. Available: https://openreview.net/forum?id=vCej5sO61x
2025
-
[11]
Avhbench: A cross-modal hallucination benchmark for audio-visual large language models,
K. Sung-Bin, O. Hyun-Bin, J. Lee, A. Senocak, J. S. Chung, and T.-H. Oh, “Avhbench: A cross-modal hallucination benchmark for audio-visual large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2410.18325
-
[12]
Contrastive decoding: Open-ended text generation as optimization,
X. L. Li, A. Holtzman, D. Fried, P. Liang, J. Eisner, T. Hashimoto, L. Zettlemoyer, and M. Lewis, “Contrastive decoding: Open-ended text generation as optimization,” inProc. Annu. Meet. Assoc. Comput. Linguist. (ACL), 2023. [Online]. Available: https://arxiv.org/abs/2210.15097
-
[13]
Reducing object hallucination in large audio-language models via audio-aware decoding,
T.-w. Hsu, K.-H. Lu, C.-H. Chiang, and H.-y. Lee, “Reducing object hallucination in large audio-language models via audio-aware decoding,” inProc. IEEE Autom. Speech Recognit. Underst. Workshop (ASRU),
-
[14]
Available: https://arxiv.org/abs/2506.07233
[Online]. Available: https://arxiv.org/abs/2506.07233
-
[15]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-Audio technical report,” Qwen Team, Alibaba Group, Tech. Rep., 2024. [Online]. Available: https://arxiv.org/abs/2407.10759
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models,” inAdv. Neural Inf. Process. Syst. (NeurIPS), 2025. [Online]. Available: https://arxiv.org/abs/2507.08128
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Clotho-AQA: A crowdsourced dataset for audio question answering,
S. Lipping, P. Sudarsanam, K. Drossos, and T. Virtanen, “Clotho-AQA: A crowdsourced dataset for audio question answering,” inProc. Eur. Signal Process. Conf. (EUSIPCO), 2022. [Online]. Available: https://arxiv.org/abs/2204.09634
-
[18]
S. Leng, H. Zhang, G. Chen, X. Li, S. Lu, C. Miao, and L. Bing, “Mitigating object hallucinations in large vision-language models through visual contrastive decoding,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024. [Online]. Available: https://arxiv.org/abs/2311.16922
-
[19]
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
Y .-S. Chuang, Y . Xie, H. Luo, Y . Kim, J. Glass, and P. He, “DoLa: Decoding by contrasting layers improves factuality in large language models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024. [Online]. Available: https://arxiv.org/abs/2309.03883
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
A VCD: Mitigating hallucinations in audio-visual large language models through contrastive decoding,
C. Jung, Y . Jang, and J. S. Chung, “A VCD: Mitigating hallucinations in audio-visual large language models through contrastive decoding,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2025. [Online]. Available: https://arxiv.org/abs/2505.20862
- [21]
-
[22]
Temporal Contrastive Decoding: A Training-Free Method for Large Audio-Language Models
Y . Li, Y . Liu, Z. Song, Y . Wei, M. Tak´aˇc, and S. Lahlou, “Temporal contrastive decoding: A training-free method for large audio-language models,” 2026. [Online]. Available: https://arxiv.org/abs/2604.15383
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [23]
-
[24]
Scipy 1.0: fundamental algorithms for scientific computing in python,
P. Virtanenet al., “Scipy 1.0: fundamental algorithms for scientific computing in python,”Nature Methods, vol. 17, no. 3, pp. 261–272, Feb
-
[25]
SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python,
[Online]. Available: http://dx.doi.org/10.1038/s41592-019-0686-2
-
[26]
librosa: Audio and music signal analysis in python,
B. McFee, C. Raffel, D. Liang, D. P. Ellis, M. McVicar, E. Battenberg, and O. Nieto, “librosa: Audio and music signal analysis in python,” SciPy 2015, 2015. [Online]. Available: https://doi.org/10.25080/Majora- 7b98e3ed-003
-
[27]
CompA: Addressing the gap in compositional reasoning in audio-language models,
S. Ghosh, A. Seth, S. Kumar, U. Tyagi, C. K. Evuru, S. Ramaneswaran, S. Sakshi, O. Nieto, R. Duraiswami, and D. Manocha, “CompA: Addressing the gap in compositional reasoning in audio-language models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024. [Online]. Available: https://arxiv.org/abs/2310.08753
-
[28]
Freesound technical demo,
F. Font, G. Roma, and X. Serra, “Freesound technical demo,” in Proceedings of the 21st ACM International Conference on Multimedia, ser. MM ’13. Barcelona, Spain: ACM, 2013, pp. 411–412
2013
-
[29]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProc. Int. Conf. Mach. Learn. (ICML), 2023. [Online]. Available: https://arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
mdpo: Conditional preference optimization for multimodal large language models,
F. Wang, W. Zhou, J. Y . Huang, N. Xu, S. Zhang, H. Poon, and M. Chen, “mdpo: Conditional preference optimization for multimodal large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2406.11839
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.