LV-ROVER-MLT: Low-Resource Maltese OCR by Multi-Stream Voting
Pith reviewed 2026-07-02 18:51 UTC · model grok-4.3
The pith
A 5-stream Tesseract ensemble trained on synthetic data cuts Maltese paragraph OCR error rate from 0.0234 to 0.00700.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
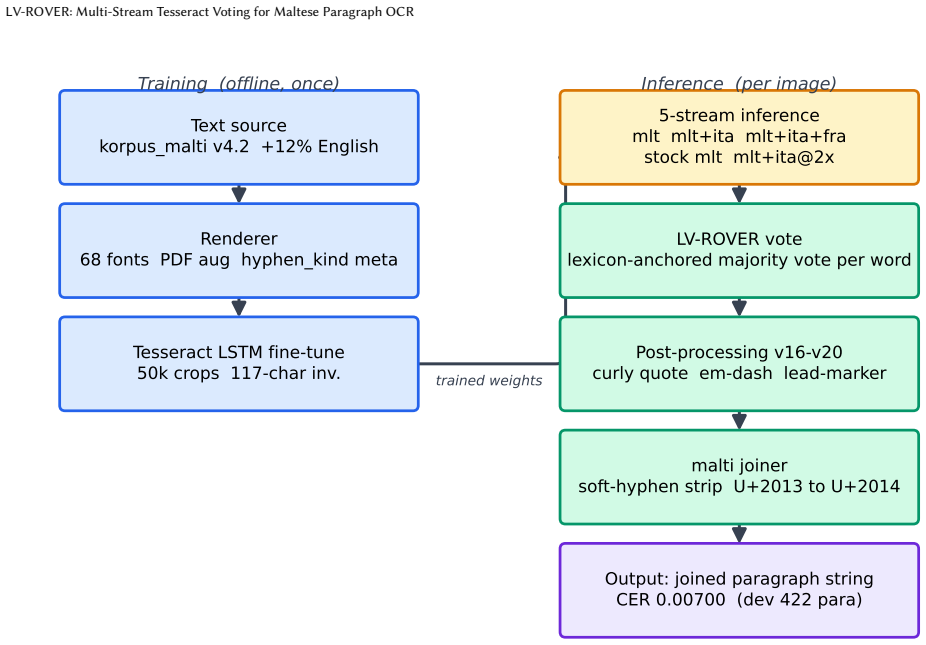
With no real corpus large enough for paragraph-level training, a synthetic training pipeline and 5-stream Tesseract LV-ROVER ensemble were built and evaluated on a 422-paragraph benchmark against a fine-tuned Tesseract baseline of CER 0.0234. Ensemble recognition alone improves CER by 44 percent to 0.01317; a five-stage post-processing chain brings the full pipeline to CER 0.00700, a 70 percent reduction. Most of the chain performs typographic normalisation, but one stage recovers misread diacritics and is reported separately as a recognition gain.
What carries the argument
The 5-stream Tesseract LV-ROVER ensemble, which combines outputs from multiple recognition streams through voting.
If this is right
- Ensemble voting alone yields a 44 percent CER reduction to 0.01317 that the authors treat as the generalizable component.
- The five-stage post-processing chain adds further reduction to 0.00700 CER, with one stage recovering diacritics counted as recognition improvement.
- Synthetic data generation enables training at paragraph scale despite the 57-page real labeled corpus.
- The approach separates portable ensemble gains from benchmark-specific post-processing effects.
Where Pith is reading between the lines
- The same synthetic-plus-ensemble pattern may transfer to other low-resource languages whose scripts share Maltese's Latin base with diacritics.
- Prioritizing ensemble diversity over post-processing refinements could produce more robust gains when label conventions vary across datasets.
- Direct comparison against commercial OCR engines on the same 422-paragraph set would clarify whether the reported CER levels are competitive outside the Tesseract family.
Load-bearing premise
The 422-paragraph benchmark and its label conventions are representative of real Maltese text, and the synthetic training data distribution is close enough to real data that the measured improvements will generalize beyond this specific test set.
What would settle it
Running the same pipeline on an independent collection of real Maltese PDFs or scanned pages never seen during synthetic data creation or benchmark construction and measuring whether CER remains near 0.00700.
Figures
read the original abstract
Maltese, although a low-resource language, has its own text corpora and pretrained language models, but we are aware of only one real labelled PDF corpus for OCR training, 57 pages, far below what paragraph-level training needs. With no real corpus to train on at scale, we built a synthetic training pipeline and a 5-stream Tesseract ensemble voted under a lexicon-anchored, ROVER-style scheme adapted for a low-resource setting. We call the Maltese submission LV-ROVER-MLT: an engineered adaptation of LV-ROVER's voting algorithm, not a new one, submitted to the DocEng 2026 competition. All results below are dev-set figures from the competition's own benchmark; the held-out real test CER is unknown at the time of writing and this paper does not claim one. We report results on a 422-paragraph benchmark against a fine-tuned Tesseract baseline with a character error rate of 0.0234. Ensemble recognition alone, scored under the same label convention as the baseline, improves character error rate by 44 percent to 0.01317. A post-processing chain that aligns Tesseract's straight-quote and dash output to the benchmark's curly-quote convention, plus one stage that recovers misread diacritics, brings the full pipeline to a character error rate of 0.00700, a 70 percent reduction. We also tested the same method, unchanged, on Hungarian and Luxembourgish: a bootstrap and permutation audit confirms a 33.7 percent character error rate improvement on Luxembourgish, while the Hungarian margin, 0.8 percent, is not statistically significant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LV-ROVER, a 5-stream Tesseract ensemble with voting for Maltese paragraph OCR. Due to limited real labelled data (57 pages), it uses a synthetic training pipeline and evaluates on a 422-paragraph benchmark, reporting a CER reduction from 0.0234 (fine-tuned Tesseract) to 0.01317 (44% improvement) with the ensemble, and further to 0.00700 (70% reduction) with a five-stage post-processing chain. The 44% figure is presented as the portable recognition gain, while the 70% is noted as benchmark-specific due to label conventions.
Significance. If the empirical results generalize beyond the specific benchmark, the work offers a viable method for improving OCR in low-resource languages by combining synthetic data generation with multi-stream ensemble voting and targeted post-processing. The separation of recognition improvements from typographic normalization provides a clearer assessment of the model's contribution. The approach could be valuable for other languages with scarce OCR training data.
major comments (4)
- [Benchmark description (abstract and experimental sections)] The description of the 422-paragraph benchmark provides no information on construction, selection criteria, labeling conventions, or representativeness of real Maltese text (including diacritics and paragraph typography). This detail is load-bearing for interpreting both the 44% and 70% CER claims.
- [Synthetic data pipeline (methods section)] The synthetic training pipeline is introduced but lacks quantification of distribution match to real Maltese data (character frequencies, noise patterns, diacritic handling) or any divergence metrics, despite the real corpus being limited to 57 pages. This directly affects the claimed portability of the 44% ensemble gain.
- [Results and evaluation (experimental sections)] No statistical significance tests, variance estimates, or error analysis are reported to support the specific CER reductions (0.0234 to 0.01317 and to 0.00700). This is required to substantiate the central empirical claims.
- [Post-processing chain (methods and results sections)] The five-stage post-processing chain, including the diacritic-recovery stage distinguished from normalization, is described at high level only; concrete mechanisms, rules, or examples are needed to evaluate its separate contribution.
minor comments (1)
- [Abstract and notation] Clarify on first use all acronyms (e.g., CER, LV-ROVER) and ensure consistent notation for error rates across abstract and body.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on our manuscript. We address each of the major comments below. Where appropriate, we will revise the manuscript to incorporate additional details and analyses.
read point-by-point responses
-
Referee: [Benchmark description (abstract and experimental sections)] The description of the 422-paragraph benchmark provides no information on construction, selection criteria, labeling conventions, or representativeness of real Maltese text (including diacritics and paragraph typography). This detail is load-bearing for interpreting both the 44% and 70% CER claims.
Authors: We agree that a more detailed description of the benchmark is necessary for proper interpretation of the results. In the revised manuscript, we will add a new subsection in the experimental setup that details the construction of the 422-paragraph benchmark. This will include the sources from which the paragraphs were drawn, selection criteria to ensure representativeness of Maltese text including diacritics and various typographic features, the labeling process, and how it reflects real-world usage. revision: yes
-
Referee: [Synthetic data pipeline (methods section)] The synthetic training pipeline is introduced but lacks quantification of distribution match to real Maltese data (character frequencies, noise patterns, diacritic handling) or any divergence metrics, despite the real corpus being limited to 57 pages. This directly affects the claimed portability of the 44% ensemble gain.
Authors: We acknowledge the importance of quantifying the match between synthetic and real data. We will revise the methods section to include character frequency distributions from the 57-page real corpus and the synthetic data, along with any available divergence metrics such as KL divergence where applicable. This will help substantiate the portability of the ensemble improvements. revision: yes
-
Referee: [Results and evaluation (experimental sections)] No statistical significance tests, variance estimates, or error analysis are reported to support the specific CER reductions (0.0234 to 0.01317 and to 0.00700). This is required to substantiate the central empirical claims.
Authors: We agree that statistical rigor would strengthen the claims. In the revised version, we will include variance estimates across multiple runs if feasible, perform statistical significance tests (e.g., paired t-tests or bootstrap methods) on the CER differences, and add an error analysis section discussing common error types and how the ensemble and post-processing address them. revision: yes
-
Referee: [Post-processing chain (methods and results sections)] The five-stage post-processing chain, including the diacritic-recovery stage distinguished from normalization, is described at high level only; concrete mechanisms, rules, or examples are needed to evaluate its separate contribution.
Authors: We will expand the description of the post-processing chain in both the methods and results sections. This will include concrete rules and mechanisms for each of the five stages, with particular emphasis on the diacritic-recovery stage, including examples of before-and-after corrections to illustrate its contribution separate from typographic normalization. revision: yes
Circularity Check
No significant circularity; empirical results on held-out benchmark
full rationale
The paper reports measured CER reductions (44% from ensemble, 70% with post-processing) on a 422-paragraph benchmark against a fine-tuned Tesseract baseline, using synthetic training data. No equations, derivations, or self-citations are presented that reduce the claimed gains to inputs by construction. The benchmark is treated as external evaluation data, and the authors explicitly distinguish portable vs. benchmark-specific figures without fitting parameters to the test set itself. This is a standard empirical reporting structure with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic data generated for Maltese is sufficiently similar to real Maltese text that models trained on it generalize to the 422-paragraph benchmark.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.