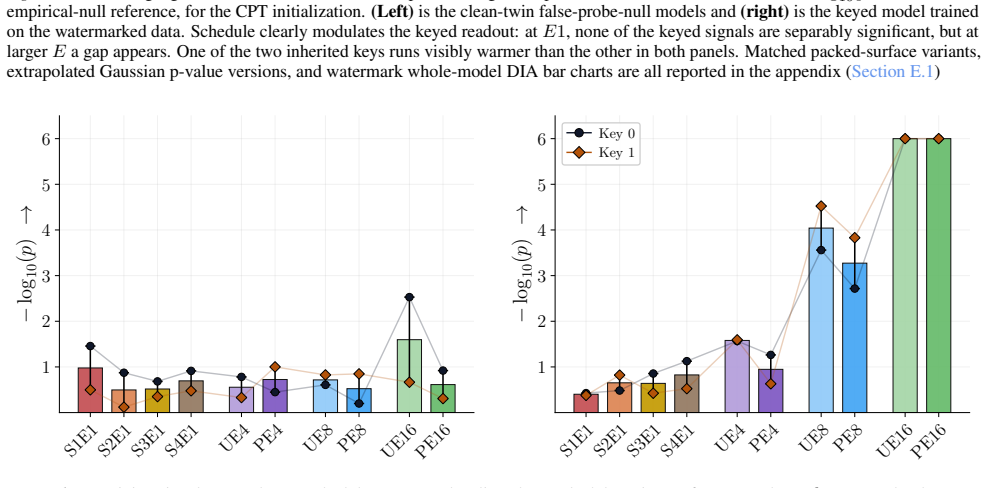
Watermarking for Proprietary Dataset Protection
Pith reviewed 2026-07-02 16:07 UTC · model grok-4.3
The pith
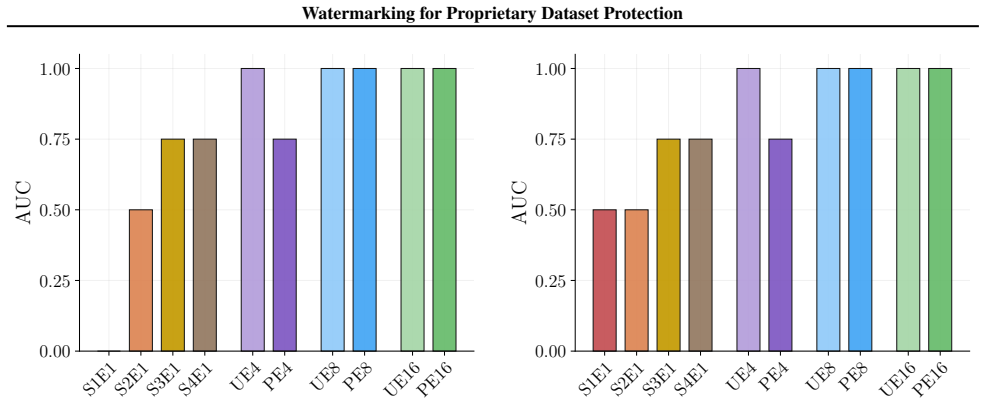
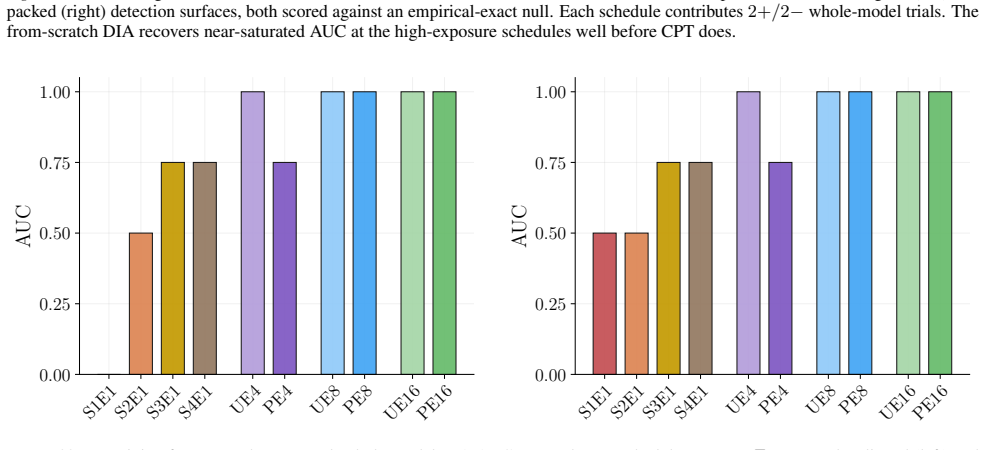
Watermarking allows comparable detection of whether proprietary datasets were used to train language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A watermark-based dataset inference method achieves membership detection performance comparable to loss-based membership inference when subset exposure during training is high enough, relying on residual watermark radioactivity in the trained model.
What carries the argument
Residual watermark radioactivity: the persistence of detectable output watermark signals in models trained on partially watermarked datasets.
If this is right
- Watermarking provides an alternate route to membership detection that does not require direct access to model loss values.
- Detection reliability increases with higher fractions of the proprietary dataset appearing in training.
- The method trades the assumptions of loss-based inference for assumptions about watermark persistence instead.
Where Pith is reading between the lines
- Dataset owners could proactively watermark their data to enable future audits even if only part of it is copied.
- The same principle might apply to non-language generative models if they also retain partial watermark signals.
- It would be useful to test how robust the radioactivity signal remains when training involves data augmentation or filtering steps.
Load-bearing premise
Language models exhibit residual watermark radioactivity under partially watermarked training datasets.
What would settle it
A controlled training run on a dataset with partial watermarking that produces model outputs with no detectable watermark signal above random chance would falsify the core premise.
Figures

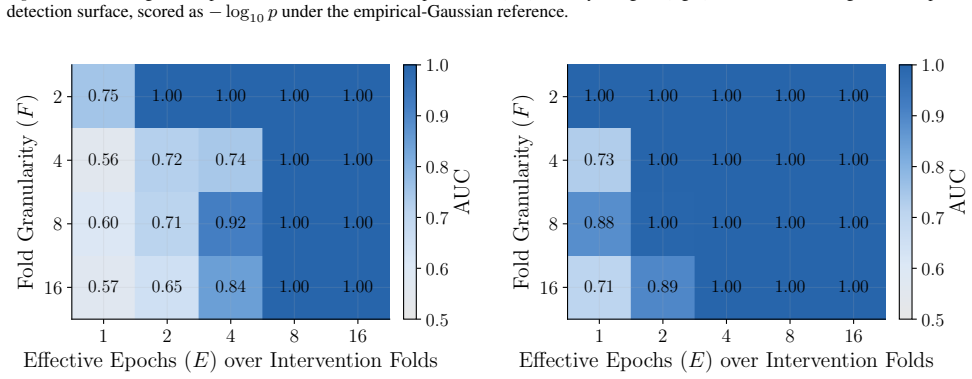
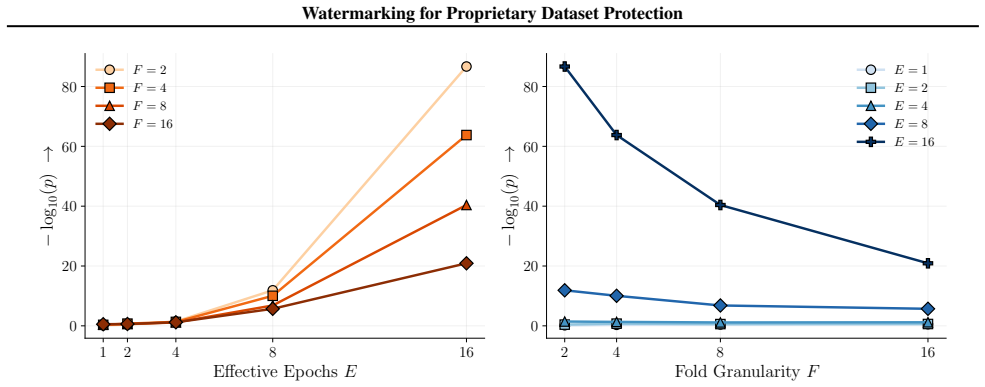
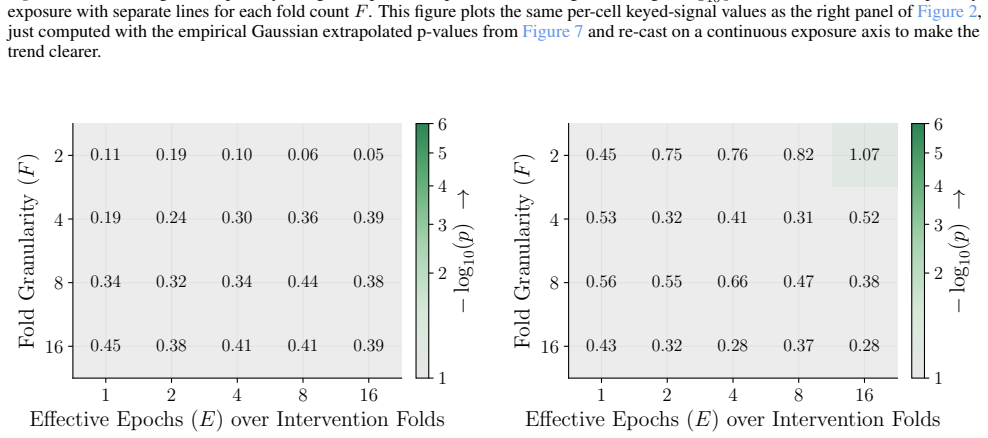
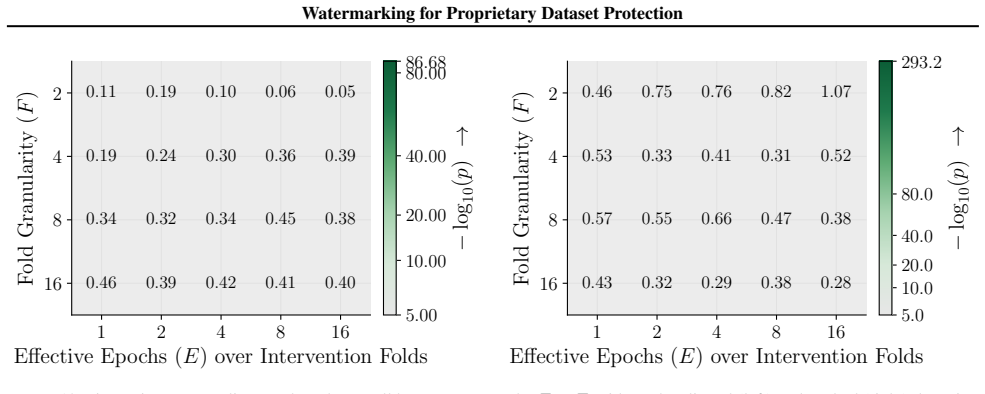
read the original abstract
A growing body of literature suggests that training data membership inference problems are fundamentally hard tasks in modern language modeling settings. We argue that output watermarking techniques are the right gadget to make training membership tests for generative models more tractable, based on prior results showing that language models exhibit residual watermark "radioactivity" under partially watermarked training datasets. We pit a watermark-based dataset inference approach head-to-head against traditional loss-based membership inference methods and show that watermarking can achieve comparable membership detection performance when subset exposure is high enough, under an alternate set of assumptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that output watermarking techniques can make training data membership inference more tractable for generative language models by leveraging residual watermark radioactivity from partially watermarked training datasets. It compares a watermark-based dataset inference method head-to-head against loss-based membership inference and claims comparable detection performance when subset exposure is high enough, under an alternate set of assumptions.
Significance. If the radioactivity effect holds under the relevant conditions, the approach could provide dataset owners with an alternative membership detection tool that operates under different assumptions than loss-based baselines, potentially aiding proprietary data protection. The work explicitly builds on prior radioactivity results rather than introducing new parameter fitting or self-referential definitions.
major comments (2)
- [Abstract] Abstract: The headline claim of 'comparable membership detection performance' when subset exposure is high enough is load-bearing on the assumption that language models exhibit detectable residual watermark radioactivity under partially watermarked training data. The manuscript provides no new experiments, ablation on watermarked fraction, or quantitative tests of radioactivity strength to establish when (or whether) this effect is sufficient to match loss-based methods.
- [Abstract] Abstract: No methods, experimental setup, model scales, watermarking schemes, exposure fractions, or performance metrics (e.g., detection AUC or precision-recall) are described, so it is impossible to evaluate whether the claimed comparability holds or under what precise conditions the 'high enough' threshold occurs.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments. Our manuscript synthesizes prior results on watermark radioactivity to argue for an alternate approach to dataset inference under different assumptions from loss-based methods. We address the points below and will revise the abstract for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of 'comparable membership detection performance' when subset exposure is high enough is load-bearing on the assumption that language models exhibit detectable residual watermark radioactivity under partially watermarked training data. The manuscript provides no new experiments, ablation on watermarked fraction, or quantitative tests of radioactivity strength to establish when (or whether) this effect is sufficient to match loss-based methods.
Authors: The manuscript explicitly builds on established prior results demonstrating residual watermark radioactivity under partially watermarked training data, rather than conducting new experiments. The head-to-head comparison is conceptual, showing that under the assumptions and conditions from those prior works (high subset exposure), watermark-based inference can achieve comparable performance to loss-based methods. We will revise the abstract to explicitly note the reliance on prior radioactivity findings and the alternate assumptions. revision: yes
-
Referee: [Abstract] Abstract: No methods, experimental setup, model scales, watermarking schemes, exposure fractions, or performance metrics (e.g., detection AUC or precision-recall) are described, so it is impossible to evaluate whether the claimed comparability holds or under what precise conditions the 'high enough' threshold occurs.
Authors: As a synthesis of existing literature, the abstract remains high-level and does not repeat the detailed experimental setups, model scales, or metrics from the cited prior works on watermarking and membership inference. The 'high enough' threshold refers to the subset exposure levels where prior radioactivity results show detectable effects. We will update the abstract to reference the specific prior results and conditions more explicitly. revision: yes
Circularity Check
No significant circularity; empirical comparison is self-contained
full rationale
The paper's central claim is an empirical head-to-head comparison showing watermark-based dataset inference can match loss-based methods under high subset exposure, grounded in cited prior observations of watermark radioactivity. No equations, fitted parameters renamed as predictions, or self-definitional steps appear in the provided abstract or description. The radioactivity premise is treated as an external empirical fact from prior work rather than derived within this manuscript, and the performance result is presented as experimental rather than forced by construction or self-citation chains. This is a standard non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption language models exhibit residual watermark radioactivity under partially watermarked training datasets
Reference graph
Works this paper leans on
-
[1]
Membership inference attacks from first prin- ciples
Carlini, N., Chien, S., Nasr, M., Song, S., Terzis, A., and Tramer, F. Membership inference attacks from first prin- ciples. In2022 IEEE symposium on security and privacy (SP), pp. 1897–1914. IEEE,
1914
- [2]
-
[3]
Do Membership Inference Attacks work on Large Language Models?
Duan, M., Suri, A., Mireshghallah, N., Min, S., Shi, W., Zettlemoyer, L., Tsvetkov, Y ., Choi, Y ., Evans, D., and Hajishirzi, H. Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.07841,
-
[4]
A., Jagielski, M., Kaissis, G., Nasr, M., Ghalebikesabi, S., Annamalai, M
Hayes, J., Shumailov, I., Choquette-Choo, C. A., Jagielski, M., Kaissis, G., Nasr, M., Ghalebikesabi, S., Annamalai, M. S. M. S., Mireshghallah, N., Shilov, I., et al. Explor- ing the limits of strong membership inference attacks on large language models.arXiv preprint arXiv:2505.18773,
-
[6]
Kirchenbauer, J., Geiping, J., Wen, Y ., Katz, J., Miers, I., and Goldstein, T
URL https: //arxiv.org/abs/2202.00622. Kirchenbauer, J., Geiping, J., Wen, Y ., Katz, J., Miers, I., and Goldstein, T. A Watermark for Large Language Mod- els. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.),Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine ...
-
[7]
Kirchenbauer, J., Mongkolsupawan, J., Wen, Y ., Goldstein, T., and Ippolito, D
URL https://arxiv.org/abs/2301.10226. Kirchenbauer, J., Mongkolsupawan, J., Wen, Y ., Goldstein, T., and Ippolito, D. A fictional q&a dataset for studying memorization and knowledge acquisition.arXiv preprint arXiv:2506.05639,
- [8]
-
[9]
URL https://arxiv.org/abs/2512.13961. 9 Watermarking for Proprietary Dataset Protection Park, S. M., Georgiev, K., Ilyas, A., Leclerc, G., and Madry, A. Trak: Attributing model behavior at scale. arXiv preprint arXiv:2303.14186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Piet, J., Sitawarin, C., Fang, V ., Mu, N., and Wagner, D
URL https: //arxiv.org/abs/2303.14186. Piet, J., Sitawarin, C., Fang, V ., Mu, N., and Wagner, D. MARKMyWORDS: Analyzing and evaluating language model watermarks. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pp. 68–
-
[11]
Sander, T., Fernandez, P., Durmus, A., Douze, M., and Furon, T
URL https://arxiv.org/abs/ 2312.00273. Sander, T., Fernandez, P., Durmus, A., Douze, M., and Furon, T. Watermarking makes language models ra- dioactive.Advances in Neural Information Process- ing Systems, 37:21079–21113,
-
[12]
Sander, T., Fernandez, P., Mahloujifar, S., Durmus, A., and Guo, C
URL https: //arxiv.org/abs/2402.14904. Sander, T., Fernandez, P., Mahloujifar, S., Durmus, A., and Guo, C. Detecting benchmark contamination through watermarking.arXiv preprint arXiv:2502.17259,
-
[13]
Shi, W., Ajith, A., Xia, M., Huang, Y ., Liu, D., Blevins, T., Chen, D., and Zettlemoyer, L
URLhttps://arxiv.org/abs/2502.17259. Shi, W., Ajith, A., Xia, M., Huang, Y ., Liu, D., Blevins, T., Chen, D., and Zettlemoyer, L. Detecting pretraining data from large language models. InInternational Conference on Learning Representations, volume 2024, pp. 51826– 51843,
-
[14]
Antidistillation Fingerprinting
Xu, Y . E., Kirchenbauer, J., Savani, Y ., Trockman, A., Robey, A., Goldstein, T., Fang, F., and Kolter, J. Z. Antidistillation fingerprinting.arXiv preprint arXiv:2602.03812,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https://arxiv.org/abs/2505.09388. Yeom, S., Giacomelli, I., Fredrikson, M., and Jha, S. Privacy risk in machine learning: Analyzing the connection to overfitting. In2018 IEEE 31st computer security founda- tions symposium (CSF), pp. 268–282. IEEE,
work page internal anchor Pith review Pith/arXiv arXiv
-
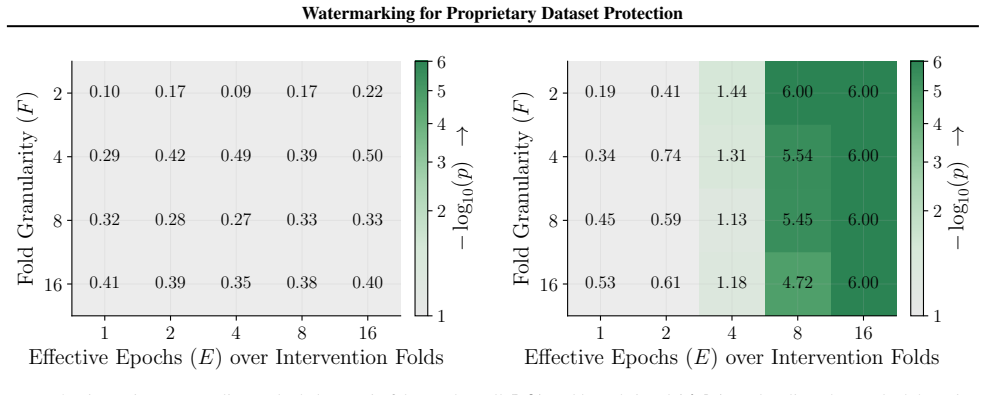
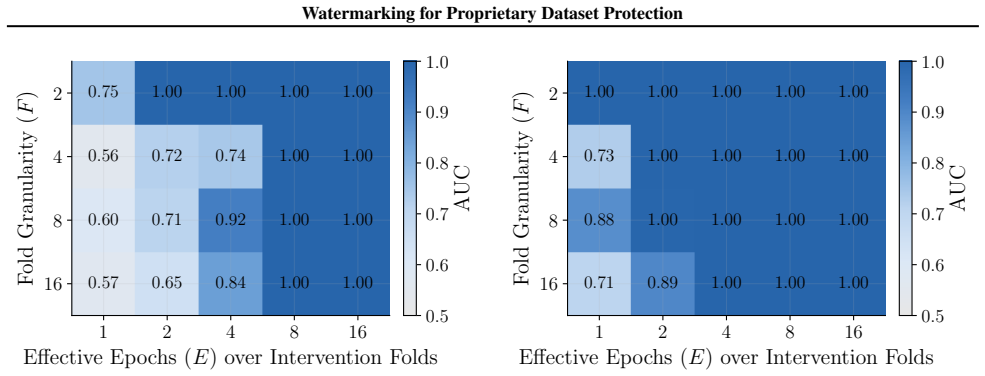
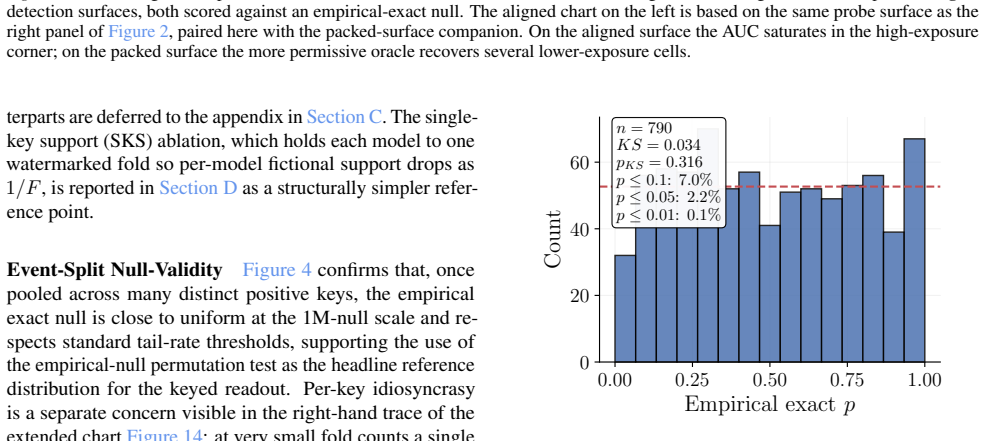
[17]
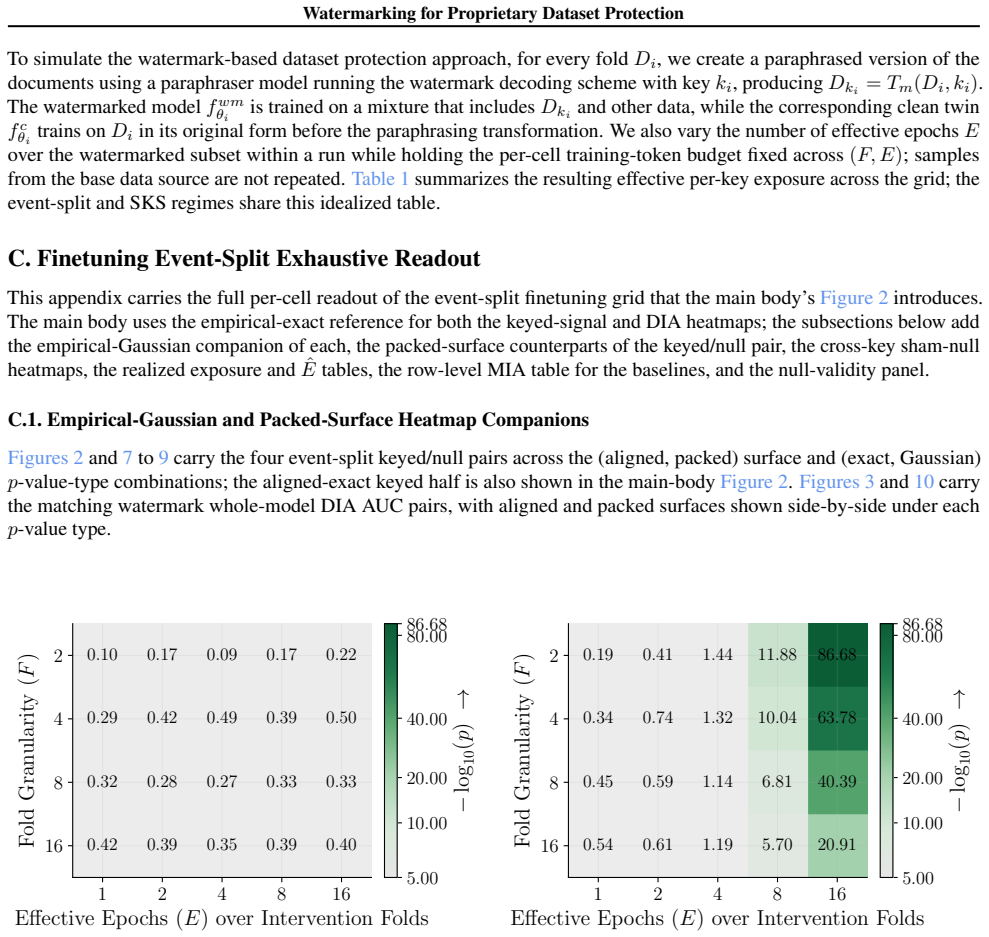
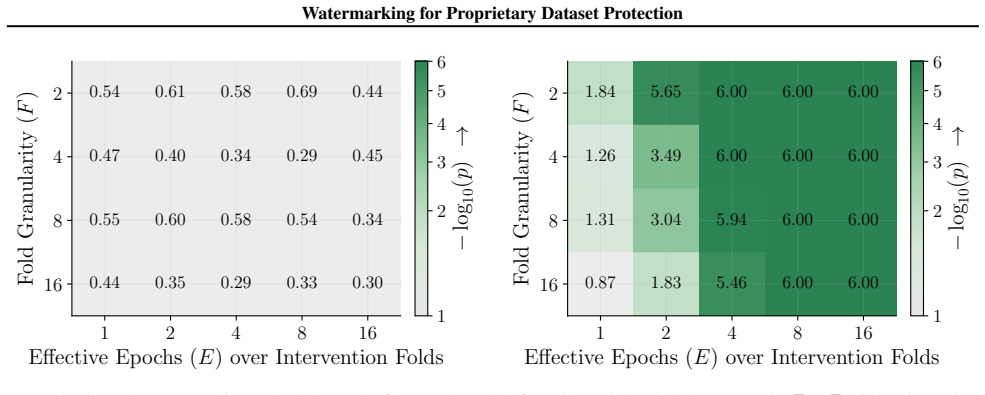
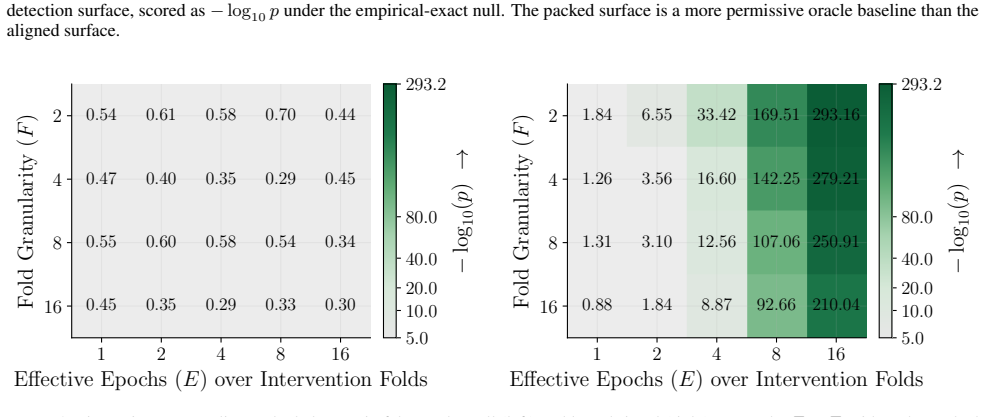
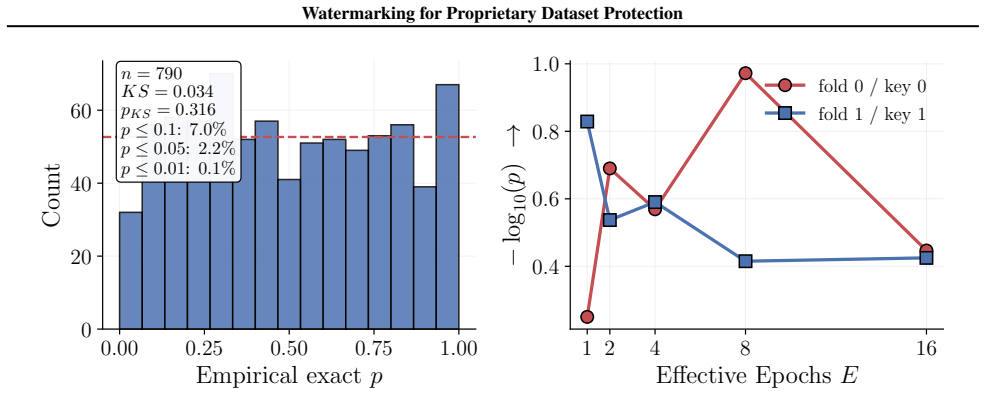
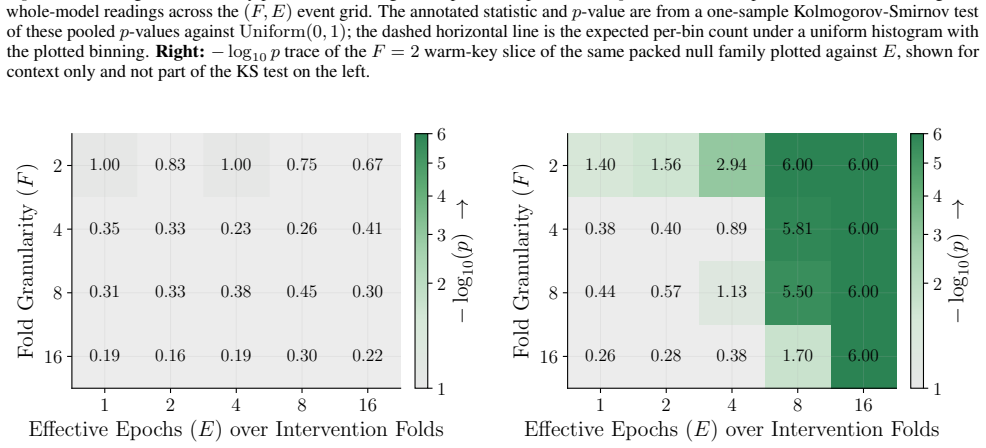
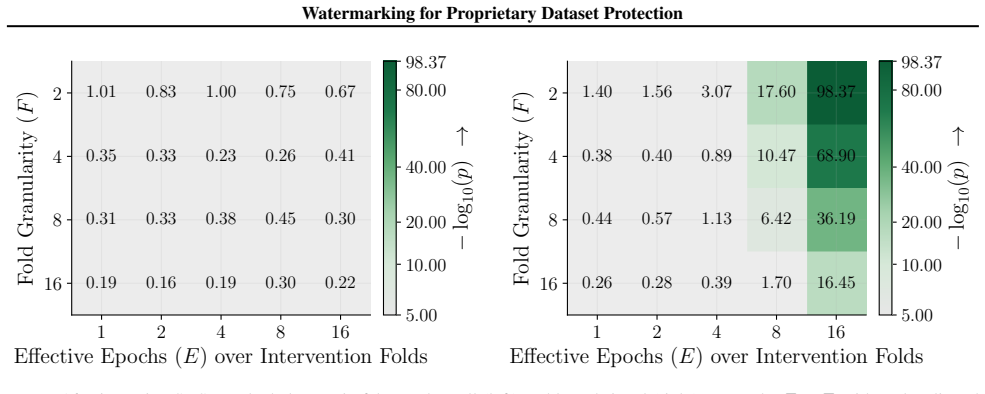
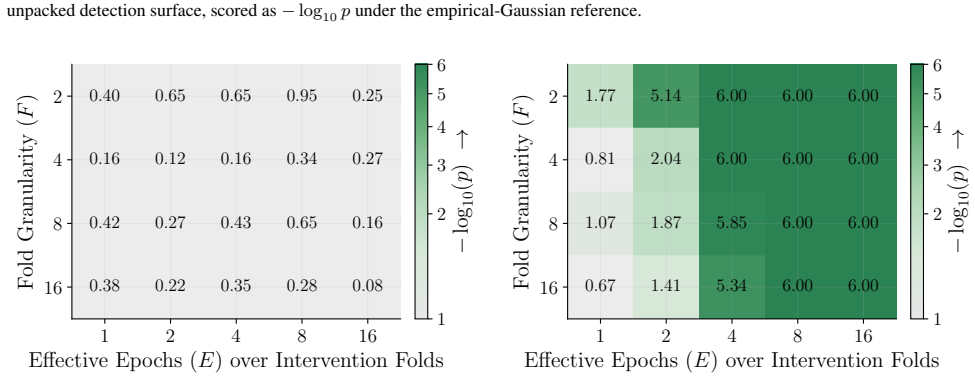
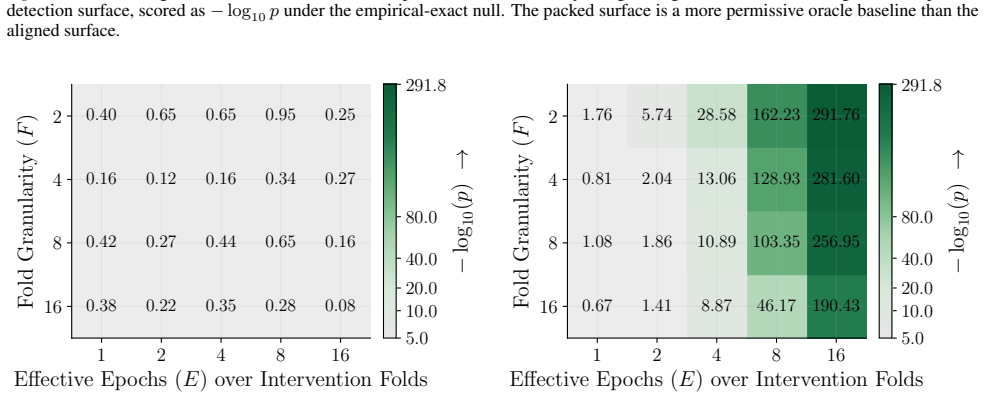
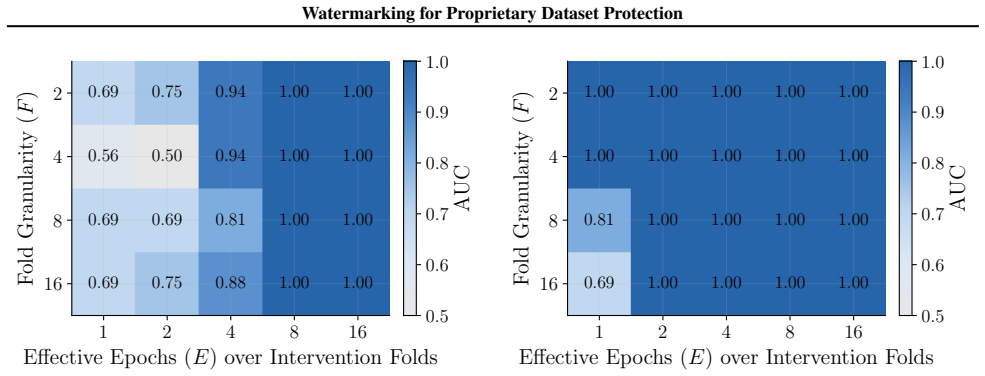
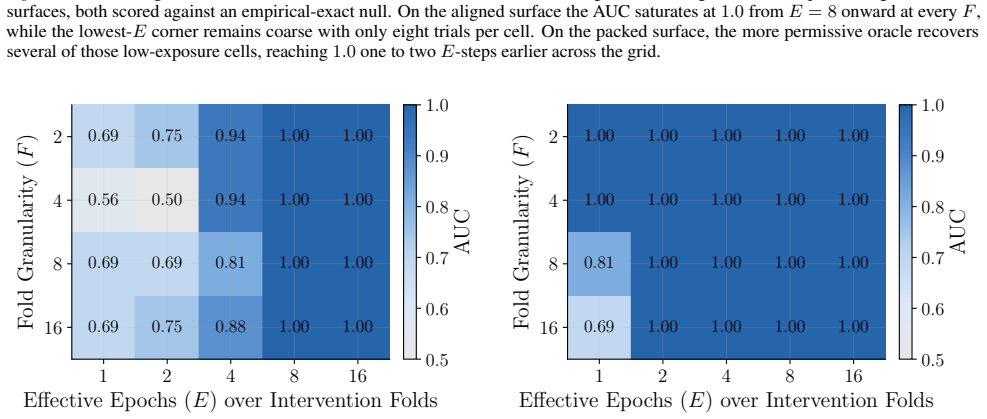
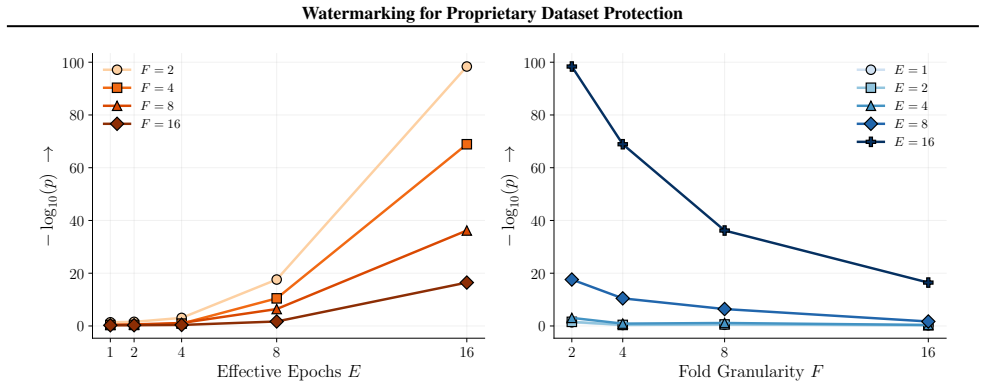
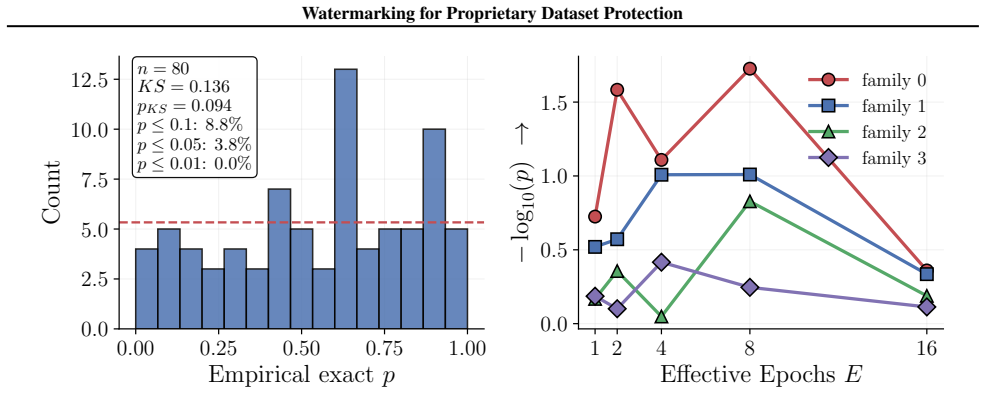
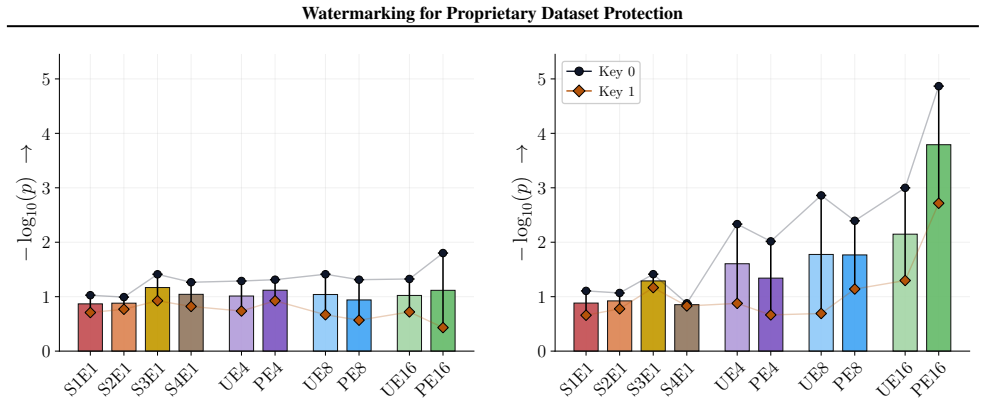
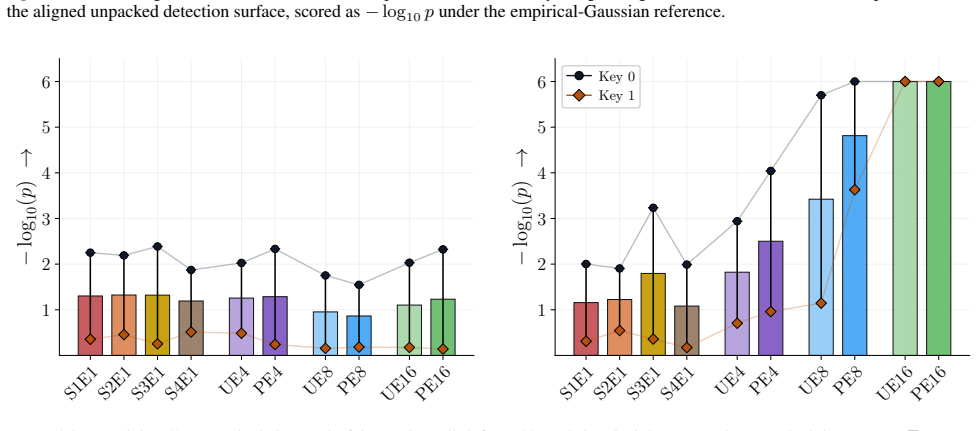
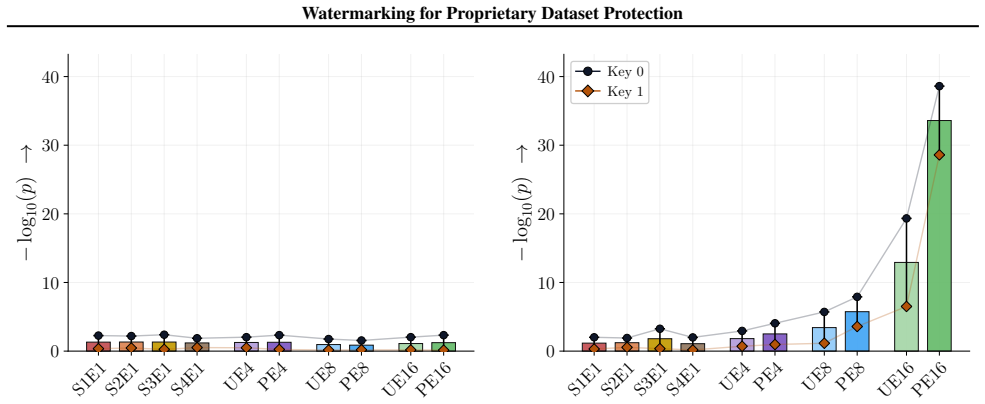
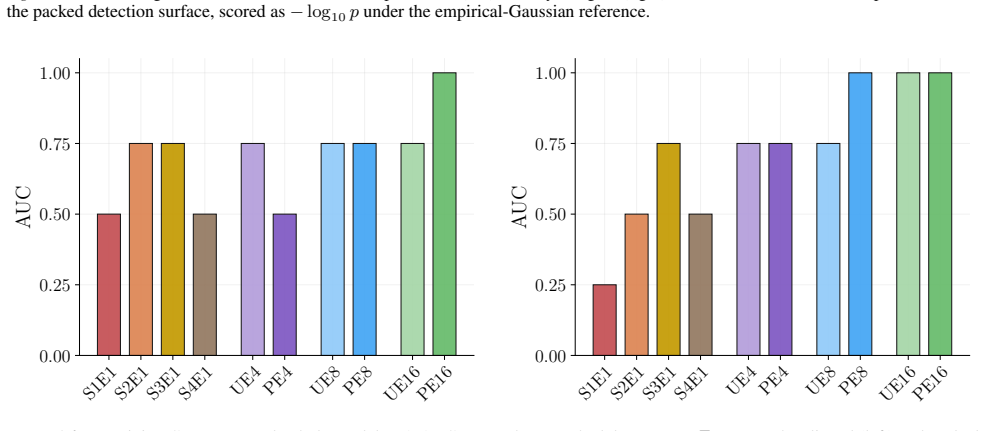
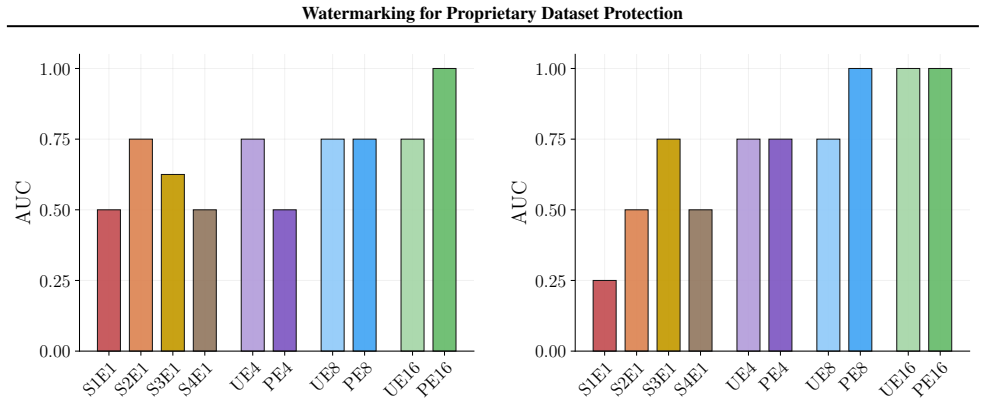
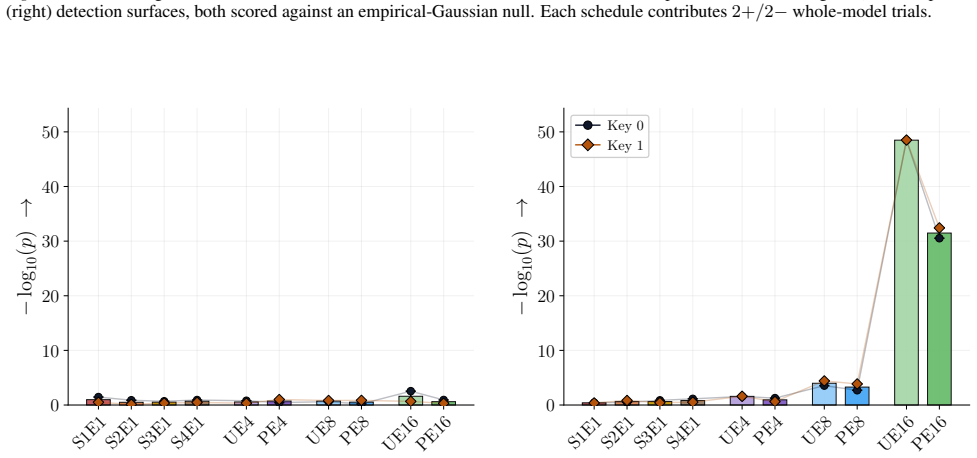
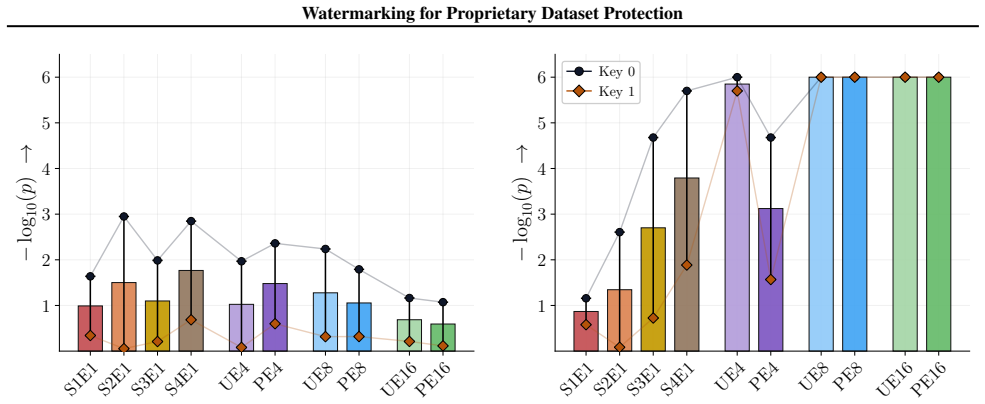
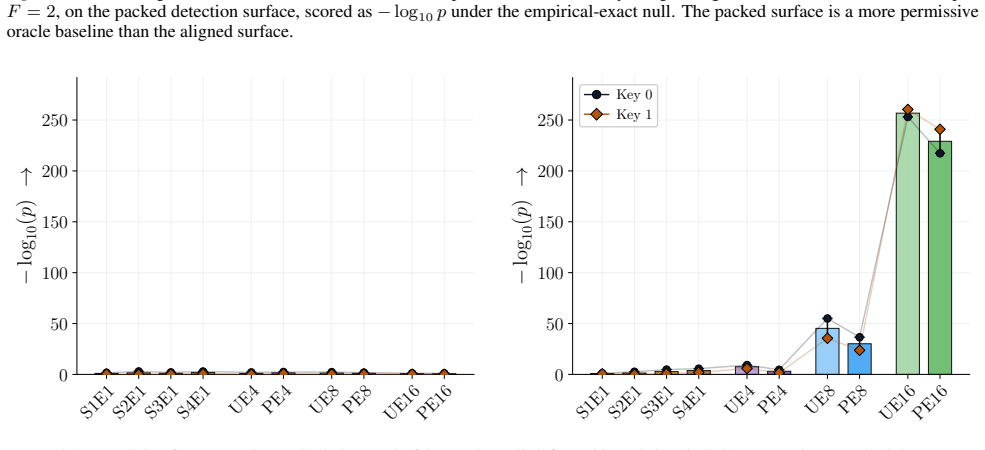
Figures 3 and 10 carry the matching watermark whole-model DIA AUC pairs, with aligned and packed surfaces shown side-by-side under each p-value type. 1 2 4 8 16 Effective Epochs ( E) over Intervention Folds 2 4 8 16Fold Granularity ( F ) 0.10 0.17 0.09 0.17 0.22 0.29 0.42 0.49 0.39 0.50 0.32 0.28 0.27 0.33 0.33 0.42 0.39 0.35 0.39 0.40 5.00 10.00 20.00 40....
1922
-
[18]
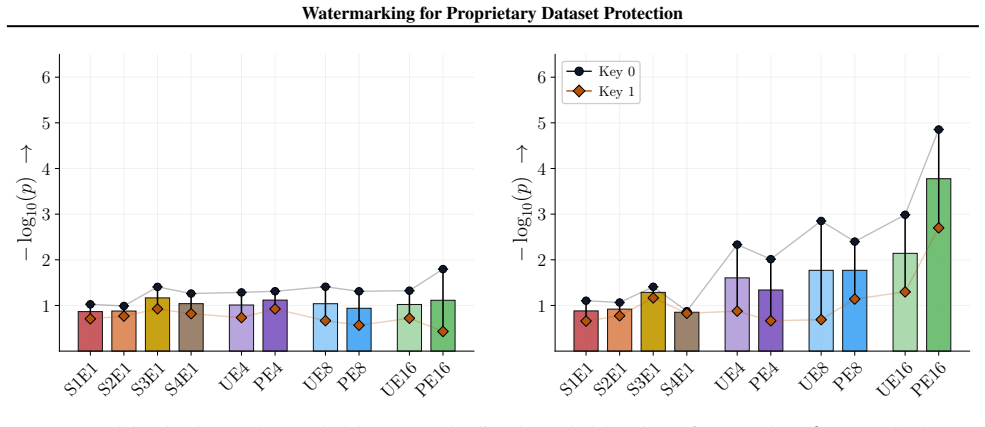
reading-mode
governs both regimes; what differs is sibling support and the per-cell positive/negative trial budget (Table 12). We use SKS as a watermark-only sanity check on the per-key scaling story without sibling-key interference, and run the loss-based and reference-model comparison only on the more realistic event-split regime where the row-level baselines are me...
2024
-
[19]
The discrepancy between idealized and realized values here is the realized overshoot of the watermarked subset’s effective epoch count relative to the planned schedule
Table 10 reports the underlying realized ˆE values. The discrepancy between idealized and realized values here is the realized overshoot of the watermarked subset’s effective epoch count relative to the planned schedule. D.4. SKS Training Scale and Trial Geometry Table 11 reports the per-cell watermarked-token totals (mean, min–max across paired models) a...
2062
-
[20]
The structure is grouped first by initialization regime (CPT then from-scratch), and within each by aligned-then-packed surface, exact-then-Gaussian p-value type, with the watermark whole-model DIA bar pairs trailing each init’s keyed/null block. The split row-level MIA and whole-model DIA baseline tables for both initialization regimes are reported below...
2050
-
[21]
The corresponding idealizedEtargets are the integers in the schedule names (columnEof Table 14)
Tables 19 and 20 report the underlying realized ˆEvalues. The corresponding idealizedEtargets are the integers in the schedule names (columnEof Table 14). E.5. Pretraining Training Scale and Trial Geometry Tables 21 and 22 report the per-schedule watermarked-token totals (mean, min–max across paired models) and the corresponding fraction of each model’s 1...
2050
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.