K-Inverse-RFM: A Modified RFM that Bridges the Gap to Neural Networks for Data-Corrupted Mathematical Tasks
Pith reviewed 2026-07-02 16:04 UTC · model grok-4.3
The pith
A K-Inverse label transformation enables Recursive Feature Machines to match or exceed neural network performance on corrupted mathematical data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Recursive Feature Machines (RFMs) that use the Average Gradient Outer Product (AGOP) for feature learning replicate the dynamics of Feedforward Neural Networks (FNNs) but show significantly lower performance in data-corrupted scenarios. Introducing the K-Inverse transformation on training labels promotes learning in noisy, complexly represented, and class-imbalanced data, enabling RFMs to close the performance gap with FNNs and in some cases even surpass them.
What carries the argument
The K-Inverse transformation, a modification applied to the training labels in Recursive Feature Machines to handle data corruption.
If this is right
- RFMs with K-Inverse can achieve performance levels comparable to FNNs on mathematical tasks with noise or imbalance.
- The transformation works without requiring additional mechanisms beyond the label change.
- Modified RFMs can sometimes outperform standard neural networks in these settings.
- Feature learning similarities between RFMs and FNNs become performance-equivalent after the adjustment.
Where Pith is reading between the lines
- Label preprocessing may be a more general lever for improving kernel methods on real-world data.
- Testing the K-Inverse approach on image or text datasets could reveal if the benefit extends beyond mathematical problems.
- The performance gap between RFMs and FNNs might stem from how labels are represented rather than differences in feature extraction capacity.
Load-bearing premise
The K-Inverse transformation on labels will promote effective learning in noisy, complex, and imbalanced data without any other specified conditions or mechanisms.
What would settle it
Running RFMs with and without K-Inverse on a benchmark mathematical classification task with added noise and measuring if the transformed version fails to improve accuracy over the baseline RFM.
Figures

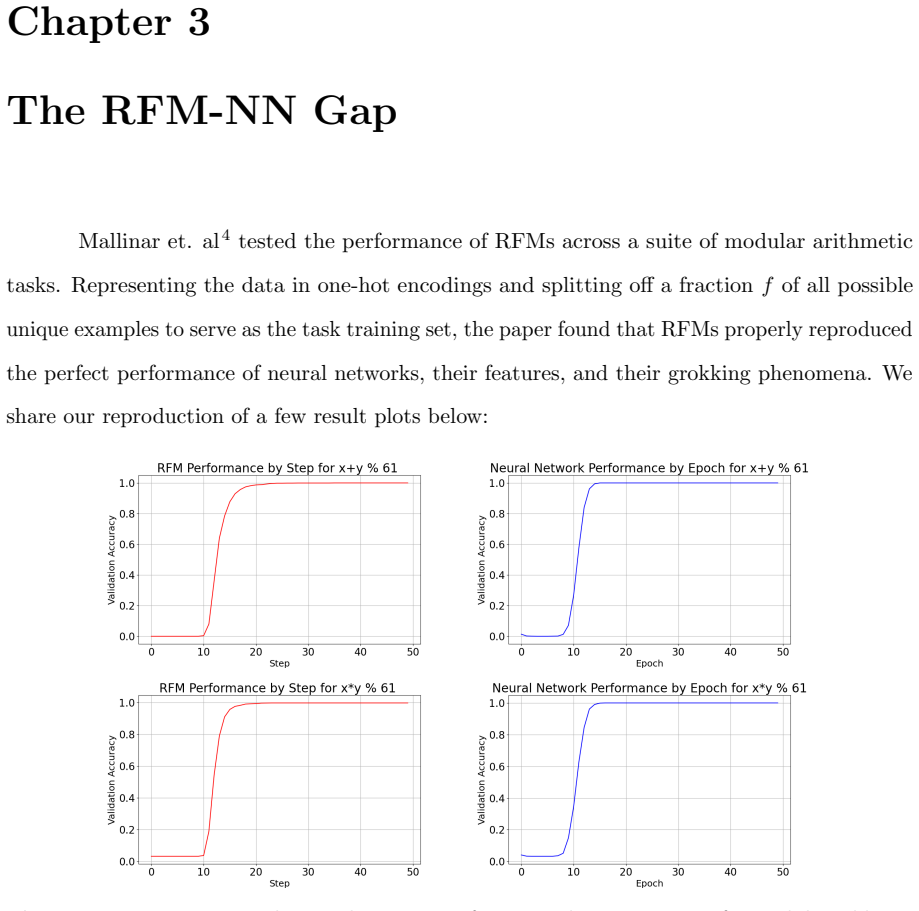
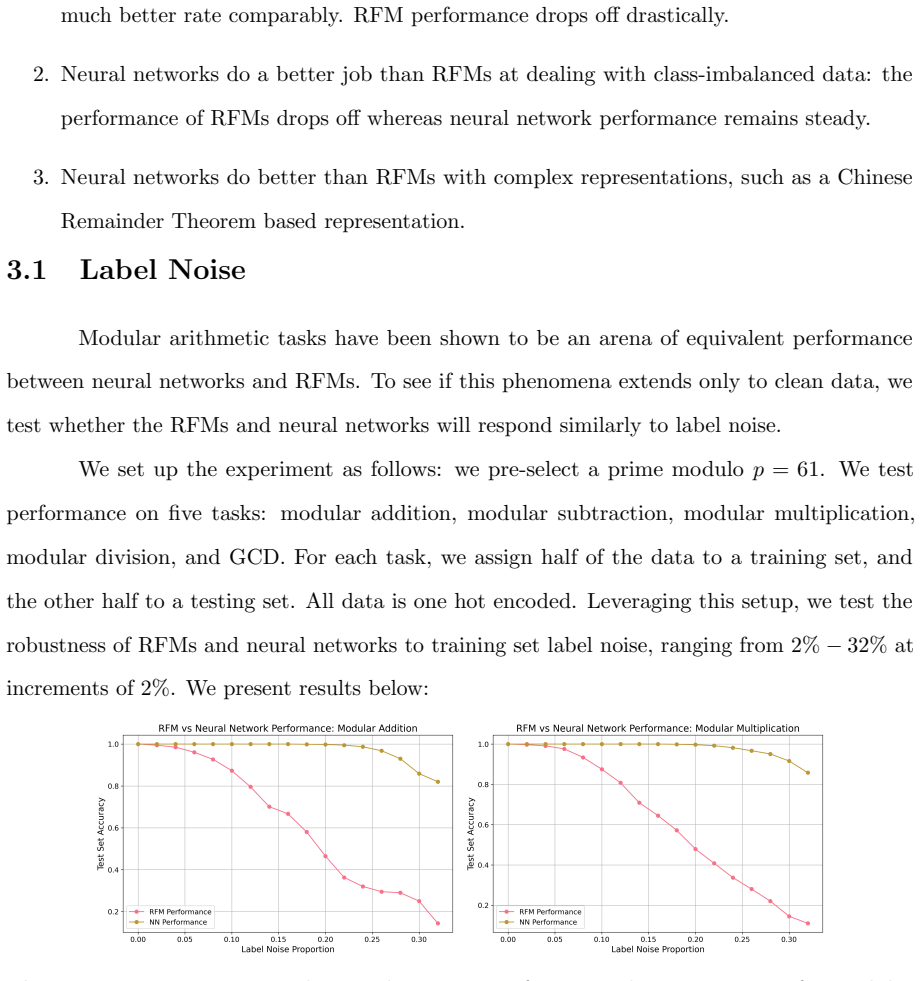
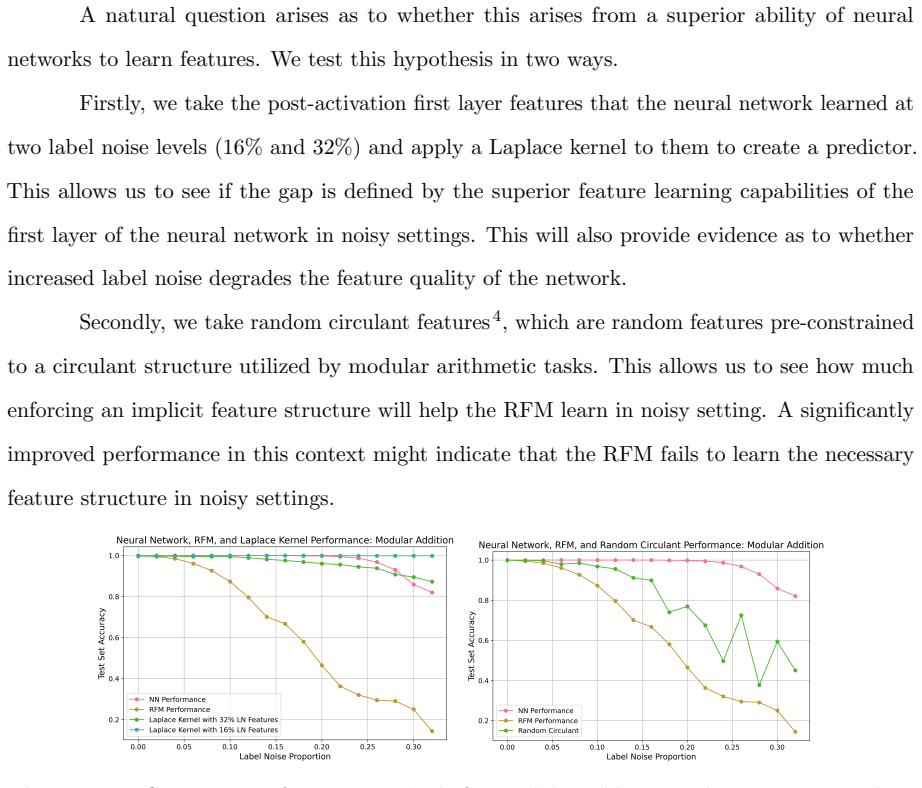
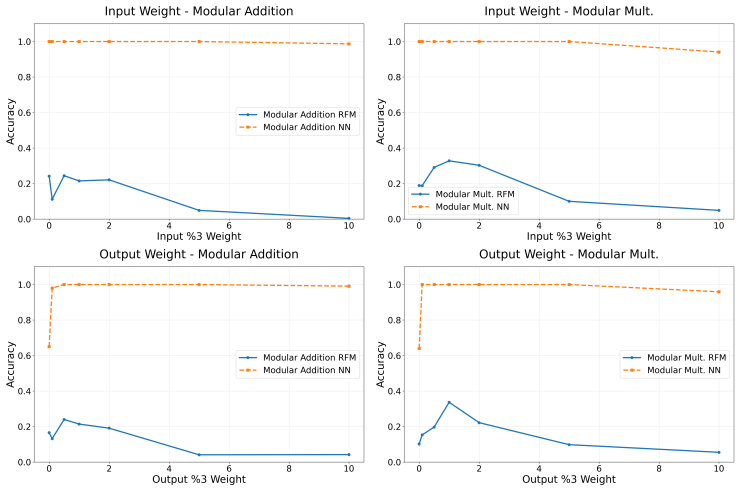
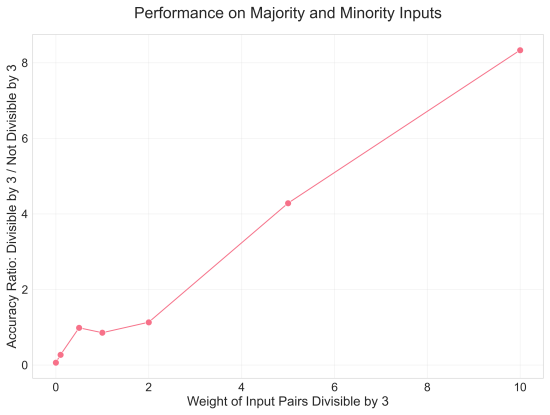

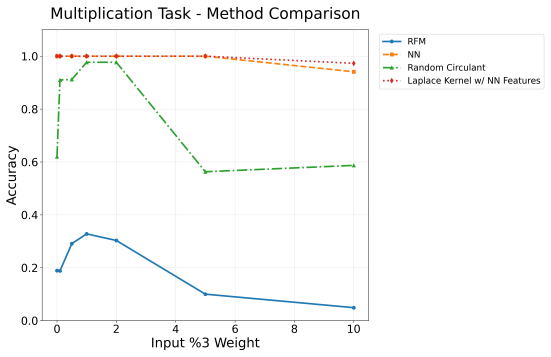
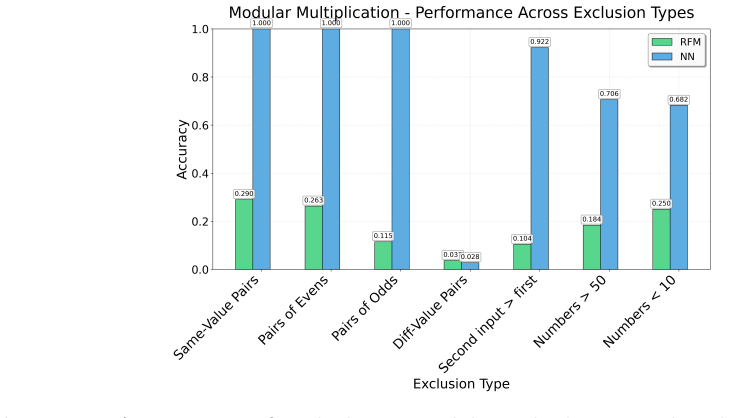
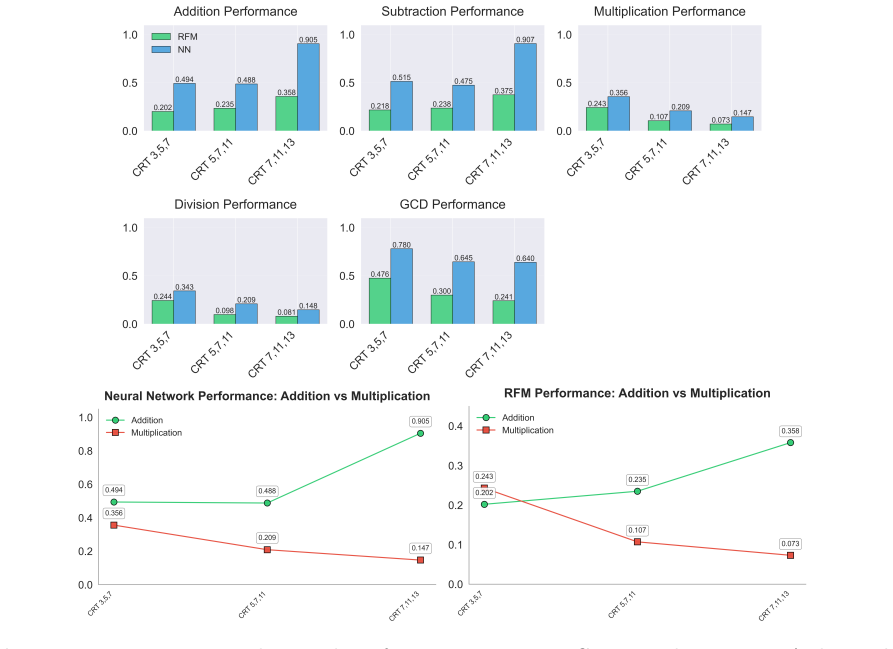
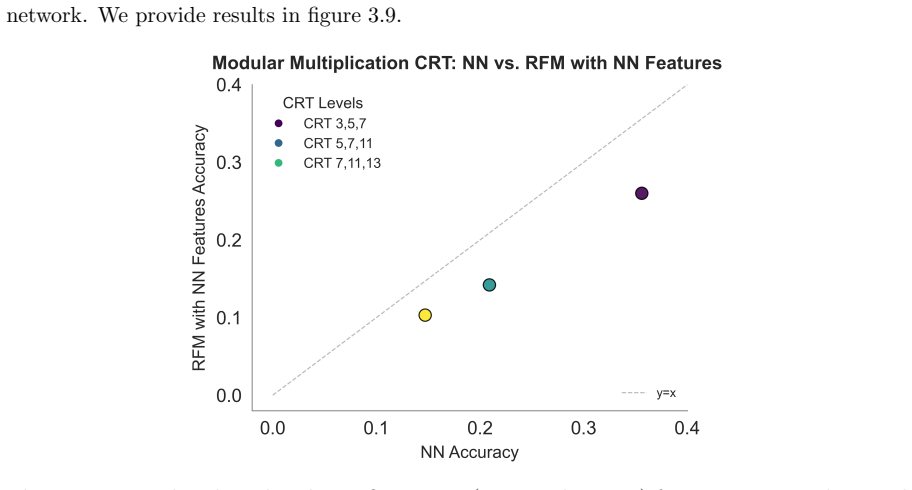
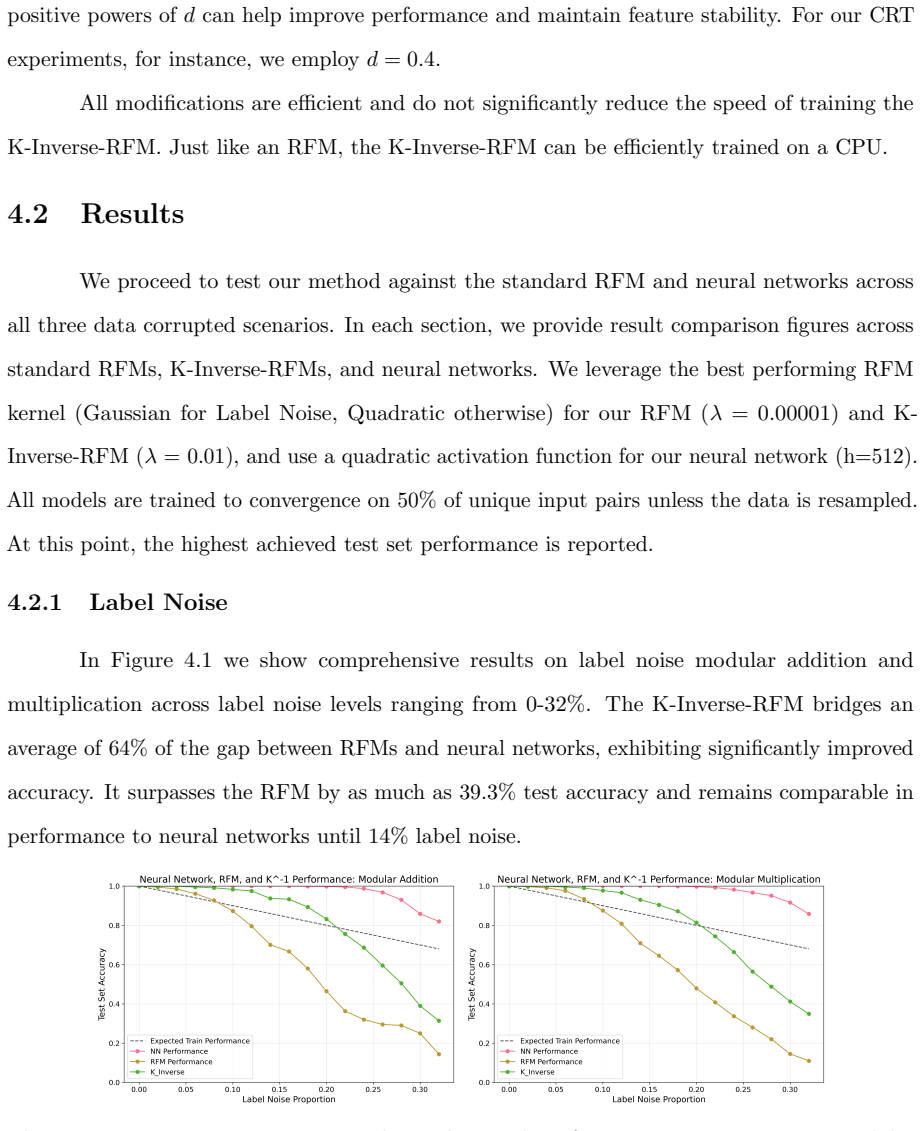
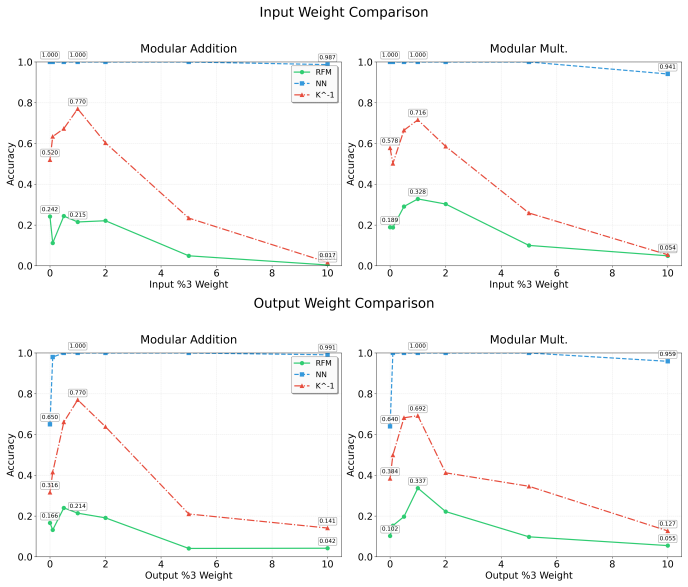
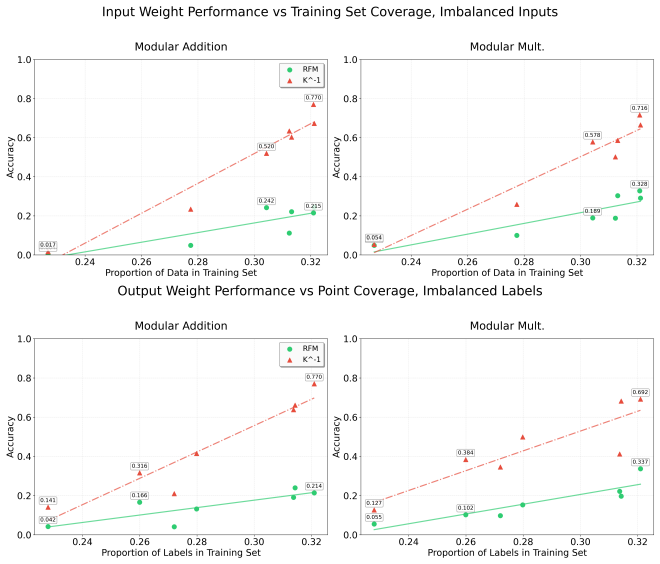
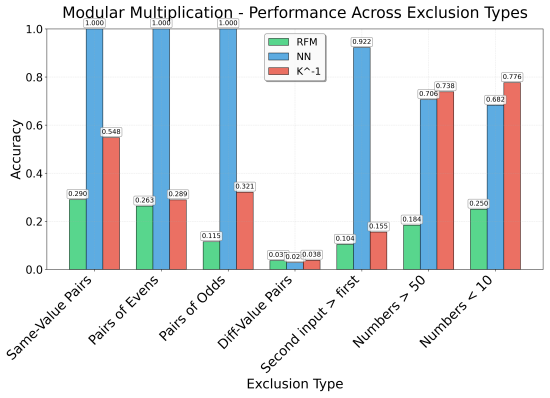
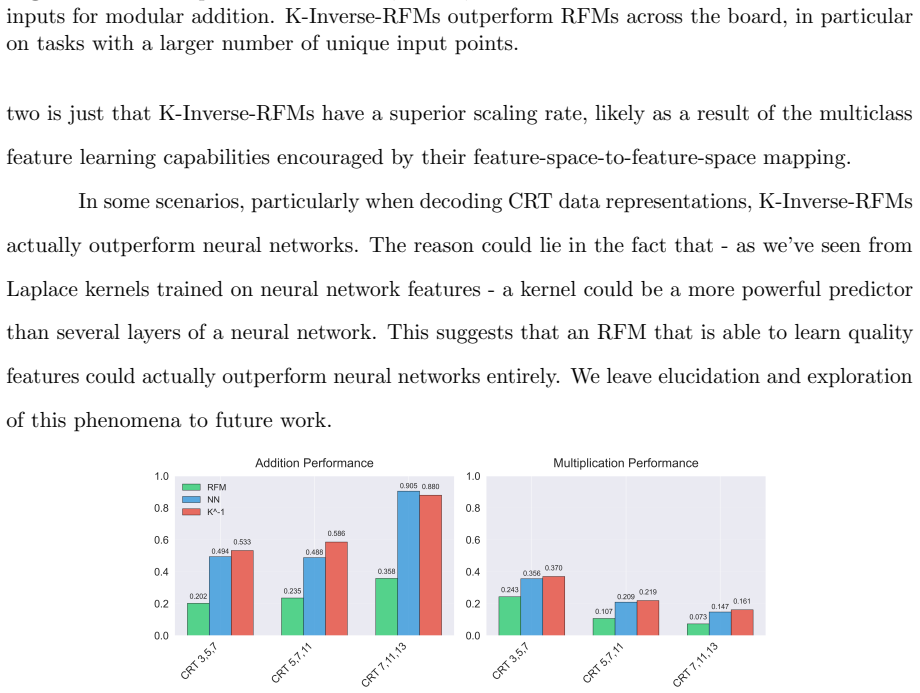
read the original abstract
Recursive Feature Machines (RFMs) are a class of kernel machines that utilize the Average Gradient Outer Product (AGOP) as a mechanism for feature learning. They have been shown to effectively replicate the learning dynamics and feature representations of Feedforward Neural Networks (FNNs) across various settings. However, despite comparable capacity for feature learning and the similarities in the features they acquire, RFMs exhibit significantly lower performance than neural networks in certain data-corrupted scenarios. In this work, we investigate these limitations in mathematical problems. As a solution, we introduce a remarkably effective transformation applied to the training labels which promotes learning in noisy, complexly represented, and class-imbalanced data. This simple yet powerful adjustment enables RFMs to close the performance gap with FNNs and, in some cases, even surpass them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces K-Inverse-RFM, a variant of Recursive Feature Machines (RFMs) that applies a K-Inverse transformation to the training labels. RFMs are kernel machines that use the Average Gradient Outer Product (AGOP) for feature learning and have been shown to replicate aspects of Feedforward Neural Network (FNN) dynamics, yet they underperform FNNs on data-corrupted mathematical tasks involving noise, complex representations, and class imbalance. The central claim is that the proposed label transformation is a simple, effective fix that closes this performance gap and can even allow RFMs to surpass FNNs.
Significance. If the empirical results hold under proper controls, the work would demonstrate that a minimal label-space adjustment can make RFMs competitive with neural networks on corrupted mathematical data without altering the core AGOP-based feature-learning mechanism. This could be useful for settings where kernel methods are preferred for interpretability or theoretical tractability, provided the transformation is shown to be robust across multiple corruption types and task formulations.
major comments (1)
- Abstract: The central claim that the K-Inverse transformation 'promotes learning in noisy, complexly represented, and class-imbalanced data' and 'enables RFMs to close the performance gap with FNNs' is asserted without any experimental details, dataset descriptions, baseline comparisons, or derivation. This prevents evaluation of whether the reported improvement is load-bearing for the claim or an artifact of unspecified conditions.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: Abstract: The central claim that the K-Inverse transformation 'promotes learning in noisy, complexly represented, and class-imbalanced data' and 'enables RFMs to close the performance gap with FNNs' is asserted without any experimental details, dataset descriptions, baseline comparisons, or derivation. This prevents evaluation of whether the reported improvement is load-bearing for the claim or an artifact of unspecified conditions.
Authors: We agree that the abstract, as currently written, is a high-level summary that does not include the requested specifics. While the full experimental details, dataset descriptions, baseline comparisons, and derivation of the K-Inverse transformation appear in Sections 2–4 of the manuscript, we acknowledge that a brief indication of these elements in the abstract would improve readability and allow readers to assess the claims more readily. In the revised version we will expand the abstract with a concise statement of the tasks, corruption types, and main baselines used. revision: yes
Circularity Check
No derivation chain or equations present; purely empirical claim
full rationale
The abstract and description introduce an empirical label transformation (K-Inverse) to improve RFM performance on corrupted data, with no equations, derivations, first-principles results, or load-bearing self-citations provided. The central assertion is an experimental performance improvement rather than any claimed mathematical reduction that could be circular by construction. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adityanarayanan Radhakrishnan, Daniel Beaglehole, Parthe Pandit, and Mikhail Belkin. Mechanism for feature learning in neural networks and backpropagation-free machine learning models.Science, 383(6690):1461–1467, 2024. doi: 10.1126/science.adi5639. URL https: //www.science.org/doi/abs/10.1126/science.adi5639
-
[2]
Kernel methods
Percy Liang. Kernel methods. Stanford CS229T/STAT231: Statistical Learning Theory (Winter 2016), 2016. URL https://web.stanford.edu/class/cs229t/2017/Lectures/percy-notes. pdf. Accessed: 2025-03-18
2016
-
[3]
Wahba.Spline Models for Observational Data, volume 59 ofCBMS-NSF Regional Conference Series in Applied Mathematics
G. Wahba.Spline Models for Observational Data, volume 59 ofCBMS-NSF Regional Conference Series in Applied Mathematics. SIAM, Philadelphia, 1990
1990
-
[4]
Emergence in non-neural models: grokking modular arithmetic via average gradient outer product, 2024
Neil Mallinar, Daniel Beaglehole, Libin Zhu, Adityanarayanan Radhakrishnan, Parthe Pandit, and Mikhail Belkin. Emergence in non-neural models: grokking modular arithmetic via average gradient outer product, 2024. URL https://arxiv.org/abs/2407.20199
-
[5]
Daniel Beaglehole, Adityanarayanan Radhakrishnan, Enric Boix-Adser` a, and Mikhail Belkin. Aggregate and conquer: detecting and steering llm concepts by combining nonlinear predictors over multiple layers, 2025. URL https://arxiv.org/abs/2502.03708
-
[6]
Adityanarayanan Radhakrishnan, Mikhail Belkin, and Dmitriy Drusvyatskiy. Linear recursive feature machines provably recover low-rank matrices.Proceedings of the National Academy of Sciences, 122(13):e2411325122, 2025. doi: 10.1073/pnas.2411325122. URL https://www. pnas.org/doi/abs/10.1073/pnas.2411325122
-
[7]
Average gradient outer product as a mechanism for deep neural collapse
Daniel Beaglehole, Peter S´ uken´ ık, Marco Mondelli, and Mikhail Belkin. Average gradient outer product as a mechanism for deep neural collapse. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 130764–130796. Curran As- sociates, Inc., 2024. U...
2024
-
[8]
The k-inverse rfm framework
Neil Mallinar and Mikhail Belkin. The k-inverse rfm framework. Unpublished manuscript, 2025
2025
-
[9]
Deep learning through the lens of example difficulty
Robert Baldock, Hartmut Maennel, and Behnam Neyshabur. Deep learning through the lens of example difficulty. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman 34 Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 10876–10889. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper files...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.